欠拟合&过拟合
1 定义
过拟合:⼀个假设在训练数据上能够获得⽐其他假设更好的拟合, 但是在测试数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。(模型过于复杂)
⽋拟合:⼀个假设在训练数据上不能获得更好的拟合,并且在测试数据集上也不能很好地拟合数据,此时认为这个假设出现了⽋拟合的现象。(模型过于简单)
天鹅图:
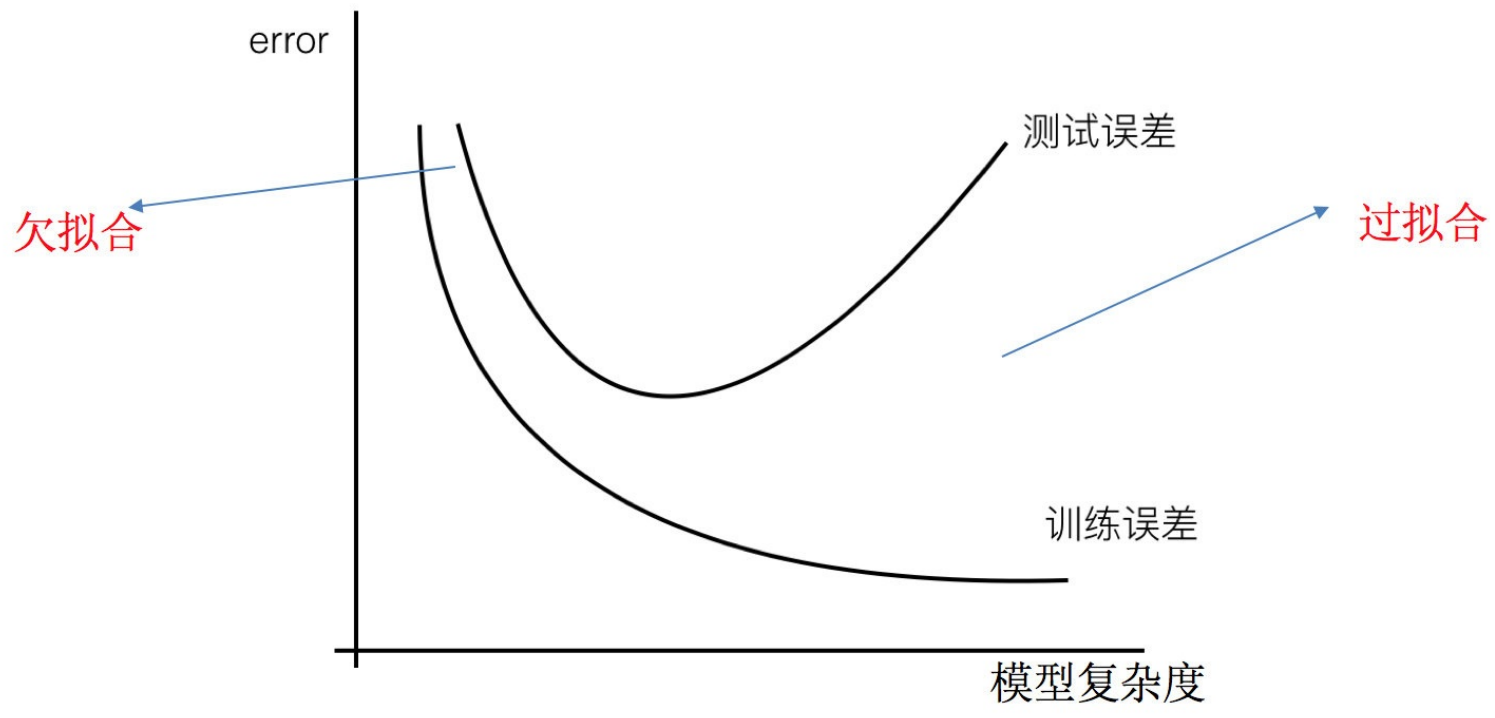
那么是什么原因导致模型复杂?线性回归进⾏训练学习的时候变成模型会变得复杂,这⾥就对应前⾯再说的线性回归的两种关系,⾮线性关系的数据,也就是存在很多⽆⽤的特征或者现实中的事物特征跟⽬标值的关系并不是简单的线性关系。
2 原因以及解决办法
⽋拟合
- 原因:
- 学习到数据的特征过少
- 模型过于简单:使用线性模型拟合非线性关系
- 特征不足:未提供足够相关特征
- 训练不足:迭代次数太少或学习率过低
- 过度正则化:正则化强度过高限制了模型能力
- 解决办法:
-
-
增加模型复杂度
- 添加多项式特征(多项式回归),这个在机器学习算法⾥⾯⽤的很普遍,例如将线性模型通过添加⼆次项或者三次项使模型泛化能⼒更强。
- 使用更强大的模型(如从线性模型切换到树模型)
- 增加神经网络层数或神经元数量
-
特征工程
- 添加更有意义的特征
- 添加其他特征项,有时候我们模型出现⽋拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要⼿段,⽆论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。除上⾯的特征之外,“上下⽂特征”、“平台特征”等等,都可以作为特征添加的⾸选项。
- 创建特征交互项
- 使用特征转换(如对数变换)
- 添加更有意义的特征
-
减少正则化
- 降低L1/L2正则化强度
- 减少dropout比例(神经网络)
- 增大决策树的最大深度
-
过拟合
- 原因:
- 原始特征过多,存在⼀些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
- 模型过于复杂:模型容量远超问题需求
- 训练数据不足:数据量不足以支撑复杂模型
- 特征过多/冗余:包含大量无关或重复特征
- 训练时间过长:在噪声上过度优化
- 正则化不足:未有效约束模型复杂度
- 解决办法:
- 重新清洗数据,导致过拟合的⼀个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
-
-
获取更多数据
- 数据增强(图像旋转/翻转,文本同义词替换)
- 收集更多真实数据,增⼤数据的训练量,还有⼀个原因就是我们⽤于训练的数据量太⼩导致的,训练数据占总数据的⽐例过⼩。
- 特征选择
- 使用递归特征消除(RFE)
- 基于重要性的特征筛选
- 减少特征维度,防⽌维灾难
-
from sklearn.feature_selection import SelectFromModel
selector = SelectFromModel(RandomForestClassifier(), threshold='median')-
- 正则化技术
- L1/L2正则化(Lasso/Ridge回归)
- Dropout(神经网络)
- 早停法(Early Stopping)
- 正则化技术
from keras.callbacks import EarlyStopping
early_stop = EarlyStopping(monitor='val_loss', patience=5)-
-
模型简化
- 减少树的最大深度
- 降低神经网络层数
- 增加决策树的min_samples_split
- 集成方法
- Bagging(如随机森林)
- Boosting(如XGBoost)
-
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators=100, max_depth=5)3. 识别方法
from sklearn.model_selection import learning_curve
train_sizes, train_scores, val_scores = learning_curve(model, X, y)欠拟合指标:
- 训练集和测试集的损失/误差都很高
- 学习曲线显示训练和验证误差都高且接近
过拟合指标:
- 训练集误差很低,但测试集误差很高
- 学习曲线显示训练误差低,验证误差高
- 模型在训练数据上准确率>95%,但测试数据<70%
4.实用验证方法
交叉验证:
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5)学习曲线分析:
import matplotlib.pyplot as plt
plt.plot(train_sizes, np.mean(train_scores, axis=1), label='Training')
plt.plot(train_sizes, np.mean(val_scores, axis=1), label='Validation')混淆矩阵分析:
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cm).plot()不同算法的处理策略
| 算法类型 | 欠拟合处理 | 过拟合处理 |
|---|---|---|
| 线性模型 | 添加多项式特征 | 增加正则化强度 |
| 决策树 | 增大最大深度 | 剪枝、限制叶节点样本数 |
| 神经网络 | 增加层数/神经元 | Dropout、权重约束 |
| 集成方法 | 增加基学习器数量 | 限制基学习器复杂度 |
总结
欠拟合和过拟合是机器学习中的核心挑战,理解它们的本质和解决方案至关重要:
- 欠拟合 = 模型太简单 → 增加复杂度
- 过拟合 = 模型太复杂 → 增加约束
- 最佳模型处于两者平衡点
- 使用交叉验证和学习曲线持续监控
- 不同算法需要不同的调优策略
通过系统性地应用这些原则和技术,可以显著提升模型的泛化能力和实际表现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号