Python字符串str知识大全
Python中的字符串用单引号 ' 或双引号 " 括起来,同时使用反斜杠 \ 转义特殊字符。
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello World!' var2 = "Runoob"
访问字符串中的值
Python 不支持单字符类型,单字符在 Python 中也是作为一个字符串使用。
Python 访问子字符串,可以使用方括号 [] 来截取字符串,字符串的截取的语法格式如下:
变量[头下标:尾下标]索引值以 0 为开始值,-1 为从末尾的开始位置。
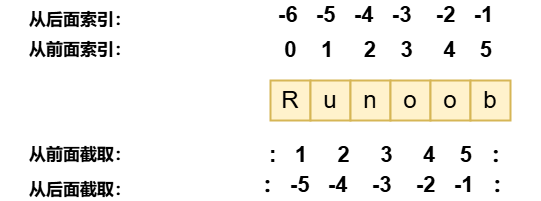

与 C 字符串不同的是,Python 字符串不能被改变。向一个索引位置赋值,比如 word[0] = 'm' 会导致错误。
转义字符
Python 使用反斜杠 \ 转义特殊字符,如果你不想让反斜杠发生转义,可以在字符串前面添加一个 r,表示原始字符串(路径前面一定要加字母‘r‘,防止反斜杠转义。);
转义字符表:
| 转义字符 | 描述 | 实例 |
|---|---|---|
| \(在行尾时) | 续行符 |
|
| \\ | 反斜杠符号 |
|
| \' | 单引号 |
|
| \" | 双引号 |
|
| \a | 响铃 |
|
| \b | 退格(Backspace) |
|
| \000 | 空 |
|
| \n | 换行 |
|
| \v | 纵向制表符 |
|
| \t | 横向制表符 |
|
| \r | 回车(不换行),将 \r 后面的内容移到字符串开头,并逐一替换开头部分的字符,直至将 \r 后面的内容完全替换完成。 |
|
| \f | 换页 |
|
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 |
|
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 |
|
| \other | 其它的字符以普通格式输出 |
\r
\r是Python中的一个转义字符,表示回车符号。它将光标移动到当前行的开头,但不换行。
作用:
\r主要用于以下目的:
光标控制:移动光标到当前行的开头,以便后续输出覆盖或替换现有文本。
终端控制:在终端窗口中,\r可用于清除当前行。
文件读写:在文件写入操作中,\r可用于覆盖或替换文件中现有文本。
使用方法:
要使用\r,只需将其添加到Python字符串中即可。
使用场景:
实时更新文本显示
在命令行或交互式会话中进行行内编辑
清除终端窗口中的当前行
合并多行文本输出到同一行
str="123456789"
print("123456789\rabcd")#abcd
'''
但是在命令行执行结果却是:
>>> print("123456789\rabcd")
abcd56789
>>>
'''
#实现动态进度条
import time
for i in range(1, 101):
print("\rProgress:","="*i,f"{i}%", end='')
time.sleep(0.1)
#实现动态删除字符的过程
str="I love china so much!"
len1 = len(str)
for i in range(len1):
print("\r"+str[:len(str)-i-1]+"|", end='')
time.sleep(0.1)字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b 输出结果: HelloPython |
| * | 重复输出字符串 | a*2 输出结果:HelloHello |
| [] | 通过索引获取字符串中字符 | a[1] 输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则,str[0:2] 是不包含第 3 个字符的。 | a[1:4] 输出结果 ell |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | 'H' in a 输出结果 True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | 'M' not in a 输出结果 True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母 r(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 |
|
| % | 格式字符串 | 请看下一节内容。 |
字符串格式化
%格式化(了解,已过时)
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
#!/usr/bin/python3 print ("我叫 %s 今年 %d 岁!" % ('小明', 10))#我叫 小明 今年 10 岁!
python字符串格式化符号:
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
格式化操作符辅助指令:
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
>>> import math >>> print('常量 PI 的值近似为:%5.3f。' % math.pi) 常量 PI 的值近似为:3.142。
因为 str.format() 是比较新的函数, 大多数的 Python 代码仍然使用 % 操作符。但是因为这种旧式的格式化最终会从该语言中移除, 应该更多的使用 str.format().
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
format 格式化函数
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 'hello world' >>> "{0} {1}".format("hello", "world") # 设置指定位置 'hello world' >>> "{1} {0} {1}".format("hello", "world") # 设置指定位置 'world hello world'
也可以设置参数:
print("网站名:{name}, 地址 {url}".format(name="菜鸟教程", url="www.runoob.com"))
# 通过字典设置参数
site = {"name": "菜鸟教程", "url": "www.runoob.com"}
print("网站名:{name}, 地址 {url}".format(**site))
# 通过列表索引设置参数
my_list = ['菜鸟教程', 'www.runoob.com']
print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的:0 表示传递给 format() 的第一个参数(即 my_list)。
# 效果等同于
print("网站名:{0}, 地址 {1}".format(*my_list)) # “*”,解包位置及关键字参数可以任意的结合:
>>> print('站点列表 {0}, {1}, 和 {other}。'.format('Google', 'Runoob', other='Taobao')) 站点列表 Google, Runoob, 和 Taobao。
!a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用于在格式化某个值之前对其进行转化:
>>> import math >>> print('常量 PI 的值近似为: {}。'.format(math.pi)) 常量 PI 的值近似为: 3.141592653589793。 >>> print('常量 PI 的值近似为: {!r}。'.format(math.pi)) 常量 PI 的值近似为: 3.141592653589793。
可选项“: ” 和格式标识符可以跟着字段名。 这就允许对值进行更好的格式化。 下面的例子将 Pi 保留到小数点后三位:
>>> import math >>> print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi))#解释“0:”,0代表第0个位置,0其实可以省略,“:”代表字符串截取,从开头到结尾 常量 PI 的值近似为 3.142。
在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用。
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> for name, number in table.items():
... print('{0:10} ==> {1:10d}'.format(name, number))#这里0和1分别对应name和number
...
Google ==> 1
Runoob ==> 2
Taobao ==> 3
如果你有一个很长的格式化字符串, 而你不想将它们分开, 那么在格式化时通过变量名而非位置会是很好的事情。
最简单的就是传入一个字典, 然后使用方括号 [] 来访问键值 :
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> print('Runoob: {0[Runoob]:d}; Google: {0[Google]:d}; Taobao: {0[Taobao]:d}'.format(table))
Runoob: 2; Google: 1; Taobao: 3
也可以通过在 table 变量前使用 ** 来实现相同的功能:
>>> table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
>>> print('Runoob: {Runoob:d}; Google: {Google:d}; Taobao: {Taobao:d}'.format(**table))
Runoob: 2; Google: 1; Taobao: 3
也可以向 str.format() 传入对象:
#!/usr/bin/python # -*- coding: UTF-8 -*- class AssignValue(object): def __init__(self, value): self.value = value my_value = AssignValue(6) print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
输出结果为:
value 为: 6数字格式化
下表展示了 str.format() 格式化数字的多种方法:
>>> print("{:.2f}".format(3.1415926)) 3.14
| 数字 | 格式 | 输出 | 描述 |
|---|---|---|---|
| 3.1415926 | {:10};数值使用:{:10d} | 3.1415926 | 在 : 后传入一个整数, 可以保证该域至少有这么多的宽度。 用于美化表格时很有用。 |
| 3.1415926 | {:.2f} | 3.14 | 保留小数点后两位 |
| 3.1415926 | {:+.2f} | +3.14 | 带符号保留小数点后两位 |
| -1 | {:-.2f} | -1.00 | 带符号保留小数点后两位 |
| 2.71828 | {:.0f} | 3 | 不带小数 |
| 5 | {:0>2d} | 05 | 数字补零 (填充左边, 宽度为2) |
| 5 | {:x<4d} | 5xxx | 数字补x (填充右边, 宽度为4) |
| 10 | {:x<4d} | 10xx | 数字补x (填充右边, 宽度为4) |
| 1000000 | {:,} | 1,000,000 | 以逗号分隔的数字格式 |
| 0.25 | {:.2%} | 25.00% | 百分比格式 |
| 1000000000 | {:.2e} | 1.00e+09 | 指数记法 |
| 13 | {:>10d} | 13 | 右对齐 (默认, 宽度为10) |
| 13 | {:<10d} | 13 | 左对齐 (宽度为10) |
| 13 | {:^10d} | 13 | 中间对齐 (宽度为10) |
| 11 |
|
|
进制 |
^, <, > 分别是居中、左对齐、右对齐,后面带宽度, : 号后面带填充的字符,只能是一个字符,不指定则默认是用空格填充。
+ 表示在正数前显示 +,负数前显示 -; (空格)表示在正数前加空格
b、d、o、x 分别是二进制、十进制、八进制、十六进制。
此外我们可以使用大括号 {} 来转义大括号,如下实例:
print ("{} 对应的位置是 {{0}}".format("runoob"))#runoob 对应的位置是 {0}
f-string:字面量格式化字符串(优先选择)
f-string 是 python3.6 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
之前我们习惯用百分号 (%):
>>> name = 'Runoob' >>> 'Hello %s' % name 'Hello Runoob'
f-string 格式化字符串以 f 开头,后面跟着字符串,字符串中的表达式用大括号 {} 包起来,它会将变量或表达式计算后的值替换进去,实例如下:
>>> name = 'Runoob' >>> f'Hello {name}' # 替换变量 'Hello Runoob' >>> f'{1+2}' # 使用表达式 '3' >>> w = {'name': 'Runoob', 'url': 'www.runoob.com'} >>> f'{w["name"]}: {w["url"]}' 'Runoob: www.runoob.com'
用了这种方式明显更简单了,不用再去判断使用 %s,还是 %d。
在 Python 3.8 的版本中可以使用 = 符号来拼接运算表达式与结果:
>>> x = 1 >>> print(f'{x+1}') # Python 3.6 2 >>> x = 1 >>> print(f'{x+1=}') # Python 3.8 x+1=2
f-string、str.format()、%选择优先级与推荐场景
-
优先选择
f-string- 条件:Python 3.6+ 环境。
- 优点:简洁、高效、功能强大。
- 适用场景:所有新项目或已升级到 Python 3.6+ 的代码。
-
次选
str.format()- 条件:需兼容 Python 2.6+/3.x,或复杂格式化需求。
- 优点:灵活性强,兼容性广。
- 适用场景:跨版本项目或需要高级格式控制(如对齐、填充)。
-
避免使用
%方法- 原因:官方已不推荐,功能局限,容错性差。
- 适用场景:仅维护旧代码时使用。
三引号
python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符。实例如下
#!/usr/bin/python3 para_str = """这是一个多行字符串的实例 多行字符串可以使用制表符 TAB ( \t )。 也可以使用换行符 [ \n ]。 """ print (para_str)
以上实例执行结果为:
这是一个多行字符串的实例
多行字符串可以使用制表符
TAB ( )。
也可以使用换行符 [
]。
三引号让程序员从引号和特殊字符串的泥潭里面解脱出来,自始至终保持一小块字符串的格式是所谓的WYSIWYG(所见即所得)格式的。
一个典型的用例是,当你需要一块HTML或者SQL时,这时用字符串组合,特殊字符串转义将会非常的繁琐。
errHTML = ''' <HTML><HEAD><TITLE> Friends CGI Demo</TITLE></HEAD> <BODY><H3>ERROR</H3> <B>%s</B><P> <FORM><INPUT TYPE=button VALUE=Back ONCLICK="window.history.back()"></FORM> </BODY></HTML> ''' cursor.execute(''' CREATE TABLE users ( login VARCHAR(8), uid INTEGER, prid INTEGER) ''')
Unicode 字符串
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串。
Python 的字符串内建函数
Python 的字符串常用内建函数如下:
| 序号 | 方法及描述 |
|---|---|
| 1 |
capitalize() |
| 2 | 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 |
count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 |
bytes.decode(encoding="utf-8", errors="strict") Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 |
encode(encoding='UTF-8',errors='strict') 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| 6 |
endswith(suffix, beg=0, end=len(string)) |
| 7 |
把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 |
find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 |
index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 |
检查字符串是否由字母和数字组成,即字符串中的所有字符都是字母或数字。如果字符串至少有一个字符,并且所有字符都是字母或数字,则返回 True;否则返回 False。 |
| 11 |
如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 |
如果字符串只包含数字则返回 True 否则返回 False.. |
| 13 |
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 |
如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 |
如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 |
如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 |
如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 |
以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 |
返回字符串长度 |
| 20 |
返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 |
转换字符串中所有大写字符为小写. |
| 22 |
截掉字符串左边的空格或指定字符。 |
| 23 |
创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 |
返回字符串 str 中最大的字母。 |
| 25 |
返回字符串 str 中最小的字母。 |
| 26 |
把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 |
rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 |
rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 |
返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 |
删除字符串末尾的空格或指定字符。 |
| 31 |
split(str="", num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 |
按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 |
startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 |
在字符串上执行 lstrip()和 rstrip() |
| 35 |
将字符串中大写转换为小写,小写转换为大写 |
| 36 |
返回"标题化"的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 |
translate(table, deletechars="") 根据 table 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 |
转换字符串中的小写字母为大写 |
| 39 |
返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 |
检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号