0-Anaconda:环境和包管理
安装Python之后,就相当于我们买了辆裸车,Anaconda就是改装后的Python“兰博基尼”,集成了很多现成的好用的工具。其实Anaconda就是预装了很多包的python。
Anaconda是什么?
Anaconda是一个用于科学计算的Python发行版,支持 Linux, Mac, Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存、切换以及各种第三方包安装问题。
Anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具。
下载
https://www.anaconda.com/download/
安装
双击exe

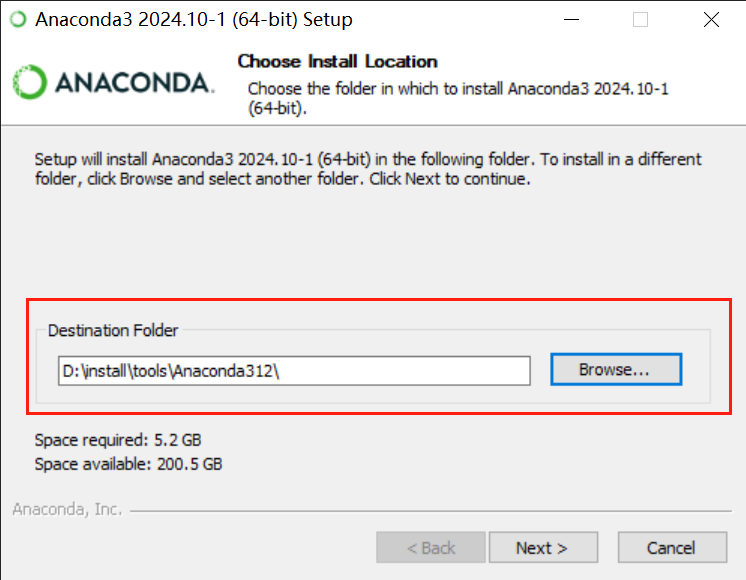
安装完成之后,我们打开开始按钮,会发现如下程序:

Anaconda Navigator:用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在 Navigator 中手工实现
Jupyter notebook:基于web的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程
qtconsole:一个可执行 IPython 的仿终端图形界面程序,相比 Python Shell 界面,qtconsole 可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
spyder:一个使用Python语言、跨平台的、科学运算集成开发环境。
优点
省时省心、分析利器。
官方文档
https://docs.conda.io/en/latest/
常用命令
在不指定 Conda 环境的情况下,conda 命令 仅作用于当前激活的环境中。若未激活任何环境:Conda命令 默认作用于 base(即根环境)中。
conda新一版本命令规律:如果使用全称,就要使用两个“--”,如果使用简称,就要使用一个“-”,例如:
conda create -n newenv python=3.12
#等价写法
conda create --name newenv python=3.12环境管理命令
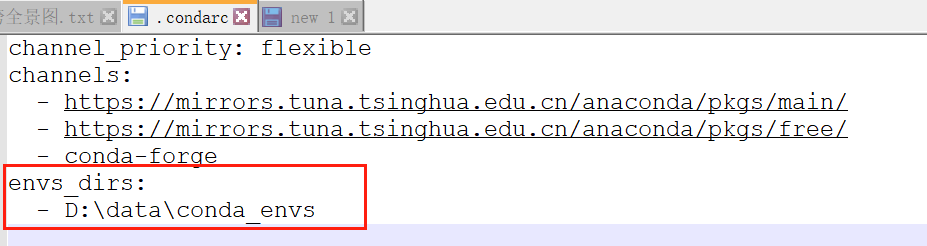
注意,如果要设置环境所在的路径,请在conda创建环境之前,在配置文件“.condarc”里添加:envs_dirs 属性:
conda config --add envs_dirs D:\conda_envs
# 创建环境 conda create -n myenv python=3.9 # 例如: conda create -n myenvironment python numpy pandas # 激活环境 conda activate myenv # 切换回默认环境base: conda activate # 退出环境 conda deactivate # 删除环境 conda env remove -n myenv # 查看所有环境,正在活动环境是带有星号 (*) 的环境,方法1: conda env list # 要查看所有环境的列表,方法2 conda info --envs
conda info -e
包管理命令
# 搜索可用的包 conda search $SEARCH_TERM # 列出已安装的软件包 conda list --name $ENVIRONMENT_NAME # 查看python安装包 conda list python --name base#(即根环境)中安装包。 # 安装包 conda install $PACKAGE_NAME # 在指定环境安装相关库 conda activate myenvironment conda install matplotlib # 在指定环境安装相关库 conda install --name myenvironment matplotlib # 从特定源安装包 conda install --channel $URL $PACKAGE_NAME # 更新包 conda update --name $ENVIRONMENT_NAME $PACKAGE_NAME # 更新包管理器 conda update conda # 卸载软件包 conda remove --name $ENVIRONMENT_NAME $PACKAGE_NAME conda remove --name myenvironment python scipy # 安装 Python conda install python=x.x # 更新 Python:更新到该系列中的最新版本,因此任何 Python 2.x 都会更新到最新的 2.x,任何 Python 3.x 都会更新到最新的 3.x。 conda update python
更新conda命令
#查看 conda 版本 conda --version #将 conda 更新到最新版本: conda update conda
频道(源)
由于python各种版本库非常多并且复杂,且版本依赖很严重,所以就有了“频道”,意思就是我们都在同一个频道上,肯定不会有错,例如我们做科学计算,使用到numpy,pandas,matplotlib等库,每个库都有很多版本,但是numpy1.0可能和pandas1.2以及matplotlib1.3是“一套”适配版本,但是我们肯定不知道也记不住这麽多版本号,那怎么办?就用频道来解决,conda里面的默认频道“conda-forge”里面就会自动给我们搭配好各种已经验证过的“配方”,各种库直接都是适配的,我们不需要关心版本号,除非有特殊特殊的要求。
当然,由于conda里面的默认频道“conda-forge”地址在海外,所以我们在下载安装库的时候会比较慢,于是就有了国内的各种镜像频道(镜像源),例如,清华以及阿里等等镜像源。我们可以在.condarc文件里面进行源配置。也可以通过命令配置。我们一一讲解
.condarc配置文件
有多个 .condarc 文件?
Conda 在运行时 按优先级加载多个路径的配置文件,这是正常现象。以下是具体原因和影响:
多个Conda 配置文件加载顺序
Conda 会依次从以下位置读取 .condarc(优先级从高到低):
- 当前环境路径(如
D:\install\tools\Anaconda312\envs\your_env\.condarc)- 仅对特定环境生效。
- 用户主目录(如
C:\Users\luzhanshi\.condarc)- 对当前用户的所有 Conda 操作生效。
- Anaconda 根目录(如
D:\install\tools\Anaconda312\.condarc)- 对所有使用该 Anaconda 实例的用户生效。
潜在问题
- 配置冲突:例如,用户主目录和 Anaconda 根目录的
channels列表不一致,可能导致依赖解析混乱。 - 镜像源失效:如果两个文件定义了不同的镜像源(如清华源和官方源),可能引发下载速度或兼容性问题。
如何管理多个 .condarc 文件?
保留用户主目录的配置,删除或注释掉 Anaconda 根目录的 .condarc:
del D:\install\tools\Anaconda312\.condarc
使用命令修改配置(避免手动编辑)
# 添加清华镜像源(用户主目录生效) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda config --add channels conda-forge # 设置频道优先级为 flexible conda config --set channel_priority flexible
默认配置文件优先级总结
| 配置文件位置 | 作用范围 | 优先级 |
|---|---|---|
当前环境/.condarc |
仅当前环境 | 最高 |
用户主目录/.condarc |
当前用户所有操作 | 高 |
Anaconda根目录/.condarc |
所有用户 | 低 |
系统级路径(如/etc/.condarc) |
所有用户 | 最低 |
特殊情况
- 环境隔离需求:如果某个项目需要独立配置(如私有镜像源),可在项目(环境)目录下创建
.condarc,仅对该环境的操作生效。 - 多用户服务器:管理员通常在 Anaconda 根目录配置公共镜像源,用户可在自己的目录覆盖配置。
配置文件配置项说明
channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 清华镜像源(免费包) - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ # 清华镜像源(主包) - conda-forge # 社区维护包 - defaults # 官方默认源(可选)(实际指向 repo.anaconda.com/pkgs/main) - https://repo.anaconda.com/pkgs/main # 官方主包源(与 defaults 重复) - https://repo.anaconda.com/pkgs/r # R 语言相关包 - https://repo.anaconda.com/pkgs/msys2 # Windows 系统工具包 #channel_priority:频道优先级模式 channel_priority: strict # 严格按频道顺序解析依赖;strict:仅在高优先级频道中查找所有依赖包,若找不到则失败。flexible:允许跨频道解析依赖(推荐用于多频道环境)。若设置为 strict,混合镜像源和官方源时易引发依赖不兼容。 ssl_verify: true # 启用 SSL 验证(默认)
- 作用:按顺序指定 Conda 搜索包的频道,优先级从上到下递减。
- 问题:
上面配置文件defaults和https://repo.anaconda.com/pkgs/main重复。
channel_priority-
strict的冲突本质:
它要求所有依赖必须来自同一优先级的频道,如果该频道的包版本无法形成完整依赖链(即使其他频道有兼容版本),就会失败。 -
flexible的风险本质:
它允许跨频道组合依赖,但不同频道的包可能因编译环境差异(如 Linux 系统库版本)导致运行时崩溃。例如,从镜像源安装 PyTorch(CUDA 11.3 编译),从官方源安装 TensorFlow(CUDA 11.6 编译),混合使用可能引发 CUDA 错误。
如何选择?
| 场景 | 推荐模式 | 原因 |
|---|---|---|
| 使用单一可信源(如仅官方源或仅镜像源) | strict |
确保依赖全部来自同一来源,避免隐式兼容问题。 |
| 混合多频道(如镜像+官方) | flexible |
允许跨频道解析,但需人工审核关键包(如深度学习框架、CUDA 相关)的来源一致性。 |
| 需要最大兼容性(旧项目维护) | disabled¹ |
关闭优先级,完全依赖 Conda 的依赖求解器,可能找到更多解但风险最高。 |
¹ disabled 是更宽松的模式(Conda 早期默认),允许任意混合频道,慎用。
最佳实践
- 优先使用单一频道:通过
conda config --add channels设置唯一源(如清华镜像),避免混合。 - 必要时混合频道:若必须混合,使用
flexible但手动指定关键包的频道,例如:conda install -c defaults pytorch -c mirror numpy
最终建议配置文件内容
channel_priority: flexible
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- conda-forge
显式指定频道
在某些情况下,我们安装较新版本的库时,会遇到错误,因为一些镜像源的同步并没有那么及时,例如:
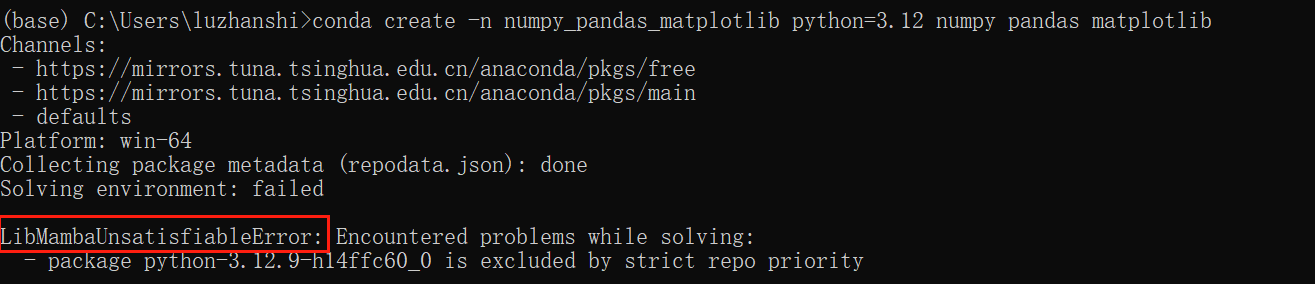
conda create -n numpy_pandas_matplotlib python=3.12 numpy pandas matplotlib
-
频道优先级冲突:
你的.condarc配置中设置了channel_priority: strict,这会强制 Conda 仅在最高优先级的频道中查找所有依赖。
由于anaconda/pkgs/main频道中python=3.13的依赖链不完整(例如缺少兼容的numpy、pandas等包),导致依赖解析失败。 -
包兼容性问题:
Python 3.13 目前处于 预发布阶段,许多科学计算包(如numpy、pandas)尚未提供适配版本,导致无法构建完整环境。
解决办法:强制指定频道(源)
conda create -n numpy_pandas_matplotlib -c conda-forge python=3.12 numpy pandas matplotlib
说明:conda-forge 通常更快适配新版本 Python。
环境使用说明
1.在指定环境运行jupyter
假设我们要学习pandas,我们可以按照以下步骤来进行,首先打开cmd窗口,然后输入以下命令
#创建环境并安装相关库 conda create -n pandas_learn python numpy pandas
#启动改环境 conda activate pandas_learn #在此环境下打开jupyter notebook jupyter notebook
2.从 base 环境启动但使用其他环境内核
- 操作场景:
如果希望从base启动 Jupyter Notebook,但选择myenv环境的内核执行代码。 - 操作步骤
# 在 myenv 中安装 ipykernel conda activate myenv conda install ipykernel # 将 myenv 注册为 Jupyter 内核(仅需一次) python -m ipykernel install --user --name myenv --display-name "MyEnv" # 回到 base 环境启动 Jupyter Notebook conda activate base jupyter notebook
在 Jupyter 中选择内核:
新建 Notebook 时,通过菜单 Kernel → Change kernel → MyEnv 切换到 myenv 环境。
3. 最佳实践
| 场景 | 推荐方法 |
|---|---|
| 长期使用单一环境处理数据 | 直接在目标环境中安装并启动 Jupyter Notebook(无需切换内核) |
| 需要跨多个环境调试代码 | 注册各环境为 Jupyter 内核,从 base 统一启动 Notebook,按需切换内核 |
| 避免环境冲突 | 为每个项目创建独立环境,并通过 ipykernel 管理内核 |
4. 补充技巧--后台启动
正常情况下,我们使用cmd启动jupyter之后,我们电脑的cmd窗口必须一直处于打开状态,因为关闭cmd窗口,jupyter服务就会停止:
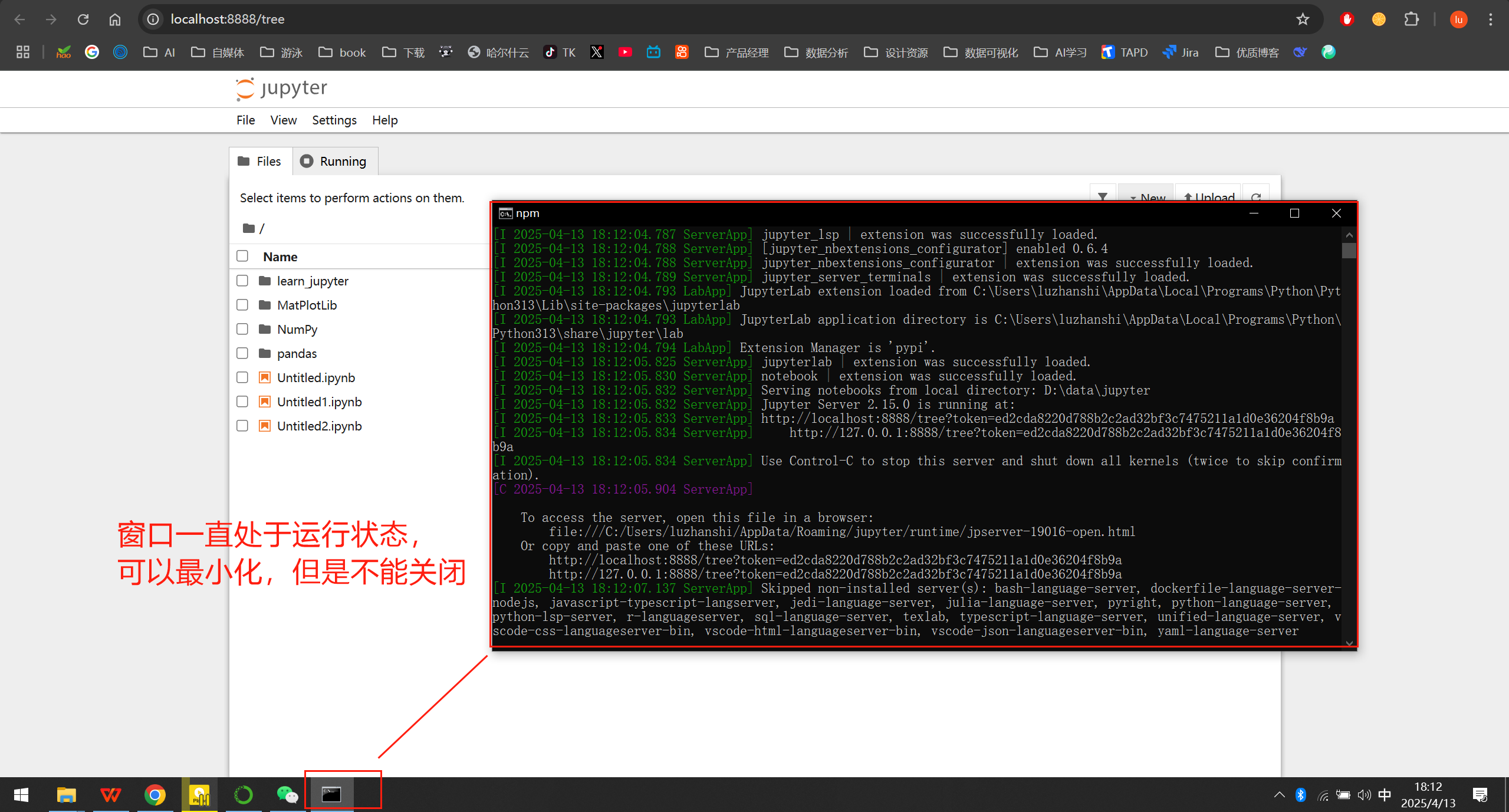
解决方案
- 后台运行 Jupyter Notebook:
使用nohup(Linux/macOS)或start(Windows)命令让进程脱离终端:
# Windows start jupyter notebook # Linux/macOS nohup jupyter notebook &
终止 Jupyter 进程:
若终端已关闭,可通过任务管理器(Windows)或 kill 命令(Linux/macOS)结束进程。
anaconda的替代方案
- 曾是主流:Anaconda 因其预装科学计算库和环境管理功能,曾是数据科学领域的首选工具。
- 现状变化:随着轻量化工具和替代品的崛起,Anaconda 的“全家桶”模式因 体积庞大、启动慢、依赖复杂 逐渐被部分开发者放弃。
在环境管理领域,Anaconda 确实是流行的选择之一(尤其在数据科学领域),但它并非唯一选择,其性能问题也常被用户诟病。以下是详细分析和替代方案建议:
一、Anaconda 速度慢的可能原因
-
图形界面开销
Anaconda Navigator 的 GUI 界面依赖大量前端库(如 Electron 或 Qt),启动时需要加载额外资源,而命令行直接调用jupyter notebook跳过了这些开销,因此更快。 -
预装包过多
Anaconda 默认安装数百个科学计算包(如 NumPy、Pandas 等),占用磁盘空间和内存,可能拖慢整体性能。 -
Conda 解析依赖较慢
Conda 的依赖解析算法在处理复杂环境时可能较慢,尤其当频道(channels)和包版本冲突时。
二、Anaconda 的轻量替代品
以下是更轻量、高效的环境管理工具:
1. Miniconda
-
特点:Anaconda 的极简版,仅包含 Conda、Python 和基础依赖,用户按需安装包。
-
优势:减少预装包,体积更小(~100MB vs Anaconda 的 ~3GB),性能更优。
-
适用场景:需要 Conda 生态但希望轻量化的用户。
2. Mamba
-
特点:Conda 的 C++ 加速替代品,完全兼容 Conda 命令,依赖解析速度提升 10-100 倍。
-
优势:直接替换 Conda,例如
mamba install numpy。 -
适用场景:频繁创建/更新环境的重度 Conda 用户。
- 安装
conda install -n base -c conda-forge mamba mamba install numpy pandas # 替代 conda install
3. venv / virtualenv(Python 原生工具)
-
特点:Python 内置的虚拟环境工具(
venv)或更灵活的第三方工具(virtualenv)。 -
优势:轻量、无需安装额外工具,适合纯 Python 项目。
-
缺点:无法管理非 Python 依赖(如 C 库)。
- 使用:
python -m venv myenv source myenv/bin/activate # Linux/macOS myenv\Scripts\activate # Windows pip install jupyter pandas
4.Poetry
-
特点:结合
pip和虚拟环境,提供依赖锁定(Pipfile.lock/poetry.lock)。依赖管理与打包一体化,精准解决版本冲突。 -
优势:适合纯 Python 应用,依赖管理更规范化。
-
适用场景:Python 库开发或需要严格版本控制的项目。
-
缺点:不适用于需要跨语言依赖(如 R 或 C++ 库)的场景。
- 使用
pip install poetry poetry new myproject poetry add numpy
5. Docker
-
特点:通过容器化实现环境隔离,确保跨平台一致性。容器化环境隔离,避免污染宿主机。
-
优势:彻底隔离环境,适合复杂依赖或生产部署。
-
缺点:学习成本高,资源占用较大。
- 使用
FROM python:3.9-slim RUN pip install jupyter pandas CMD ["jupyter", "notebook", "--ip=0.0.0.0", "--allow-root"]
6.云 Notebook 服务
- Google Colab:免安装,直接使用 GPU,适合临时实验。
- JupyterLab on Cloud:如 AWS SageMaker、Deepnote。
三、工具对比与推荐
| 工具 | 包管理 | 跨语言支持 | 速度 | 学习成本 | 适用场景 |
|---|---|---|---|---|---|
| Anaconda | Conda | 是 | 慢 | 低 | 数据科学新手 |
| Miniconda | Conda | 是 | 中 | 低 | 需 Conda 但希望轻量化 |
| Mamba | Conda | 是 | 快 | 低 | 频繁操作 Conda 环境的用户 |
| venv | pip | 否 | 快 | 低 | 纯 Python 简单项目 |
| Poetry | pip | 否 | 中 | 中 | Python 项目规范化管理 |
| Docker | 任意 | 是 | 中 | 高 | 复杂依赖或生产环境 |
| 工具 | 优势 | 劣势 | 推荐场景 |
|---|---|---|---|
| Miniconda | 轻量灵活,兼容 Conda 生态 | 依赖解析仍较慢 | 需 Conda 但不想用 Anaconda |
| Mamba | 极速依赖解析,兼容 Conda | 社区资源略少 | 复杂环境快速搭建 |
| venv + pip | 零额外依赖,Python 原生支持 | 依赖冲突需手动解决 | 简单项目或纯 Python 开发 |
| Poetry | 精准依赖管理,适合打包发布 | 学习曲线较陡 | 开发 Python 库或严格版本控制 |
| Docker | 完全隔离,跨平台一致性 | 资源占用高,启动较慢 | 生产环境或复杂依赖隔离 |
四、建议方案
-
日常数据科学开发
使用 Miniconda + Mamba,保留 Conda 生态的同时大幅提升速度。 -
纯 Python 项目
使用 Poetry 或 venv,简化依赖管理。 -
企业级或复杂环境
使用 Docker 确保环境一致性。
五、加速 Anaconda 的额外技巧
-
清理缓存:
conda clean --all -
使用国内镜像源(如清华、中科大源)。
-
避免频繁添加频道(减少依赖冲突)。
通过选择合适的工具和优化配置,可以显著提升环境管理效率。
换国内镜像源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set channel_priority strict
使用 Mamba 加速:
mamba install numpy pandas jupyter
精简环境:避免安装非必要包。
5. 总结
- 弃用 Anaconda 的场景:追求轻量、快速启动、简单项目管理。
- 坚持 Anaconda 的场景:需要开箱即用的科学计算库(如 NumPy、SciPy)或跨平台兼容性。
推荐选择:
- 日常数据分析:Miniconda + Mamba + 国内镜像。
- 开发 Python 库:Poetry 或 venv + pip。
- 深度学习与生产部署:Docker 或云服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号