02.深度学习(Deep Learning)概述
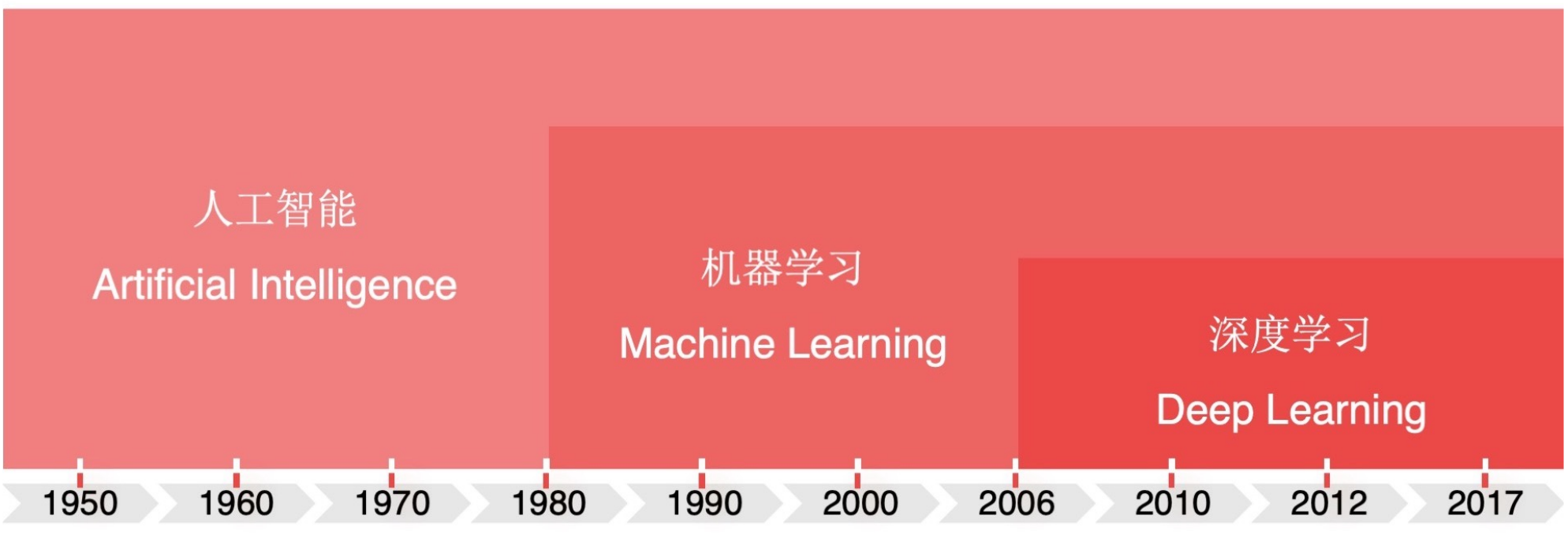
如何理解深度学习?
什么是神经网络?
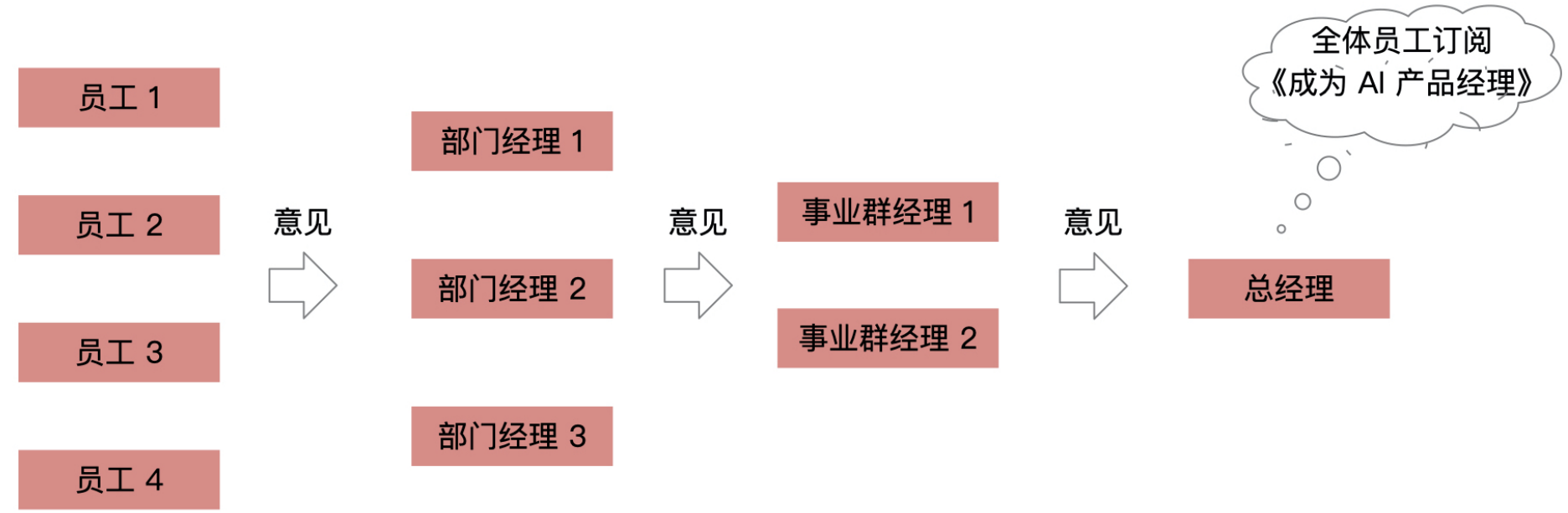
这个例子其实完全可以通过机器学习模型来描述:
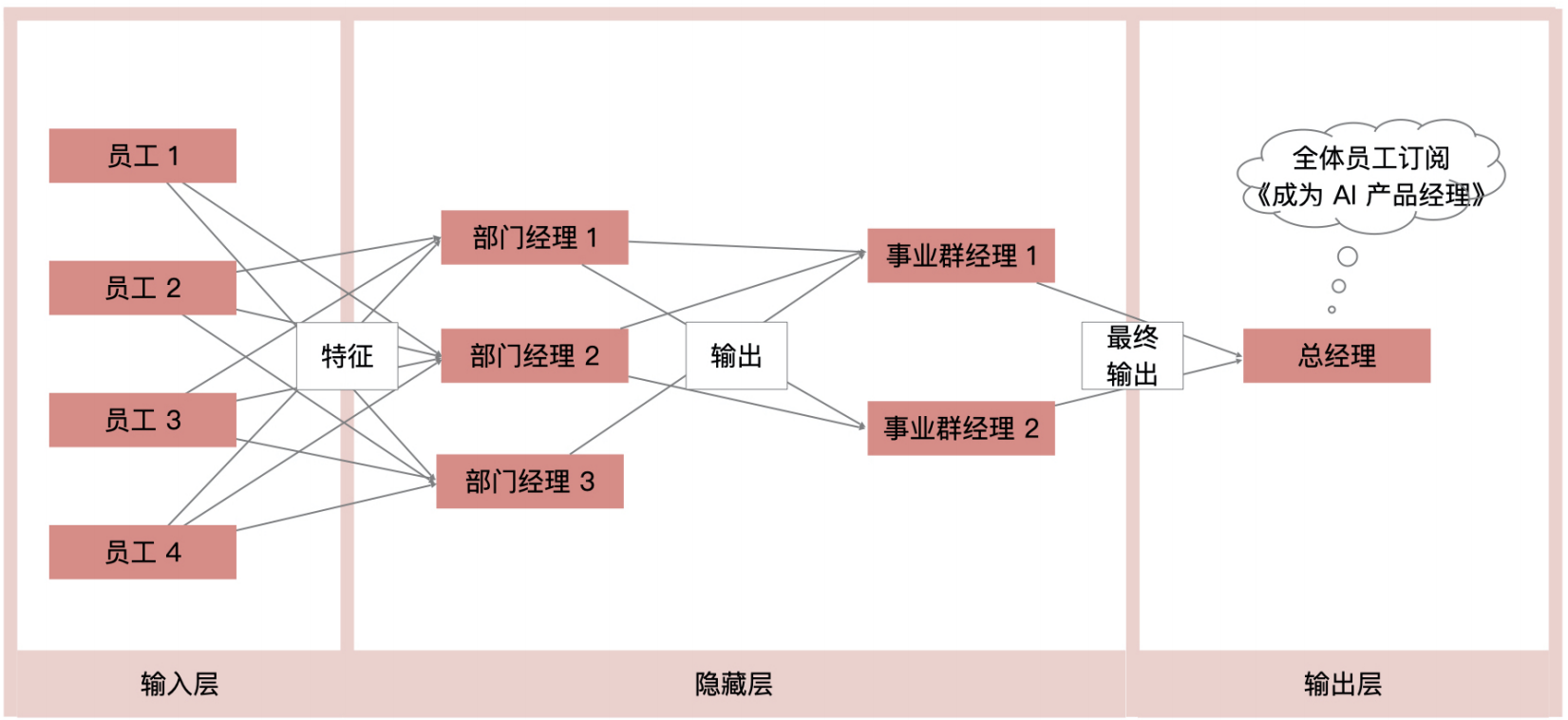
神经网络模型的组成
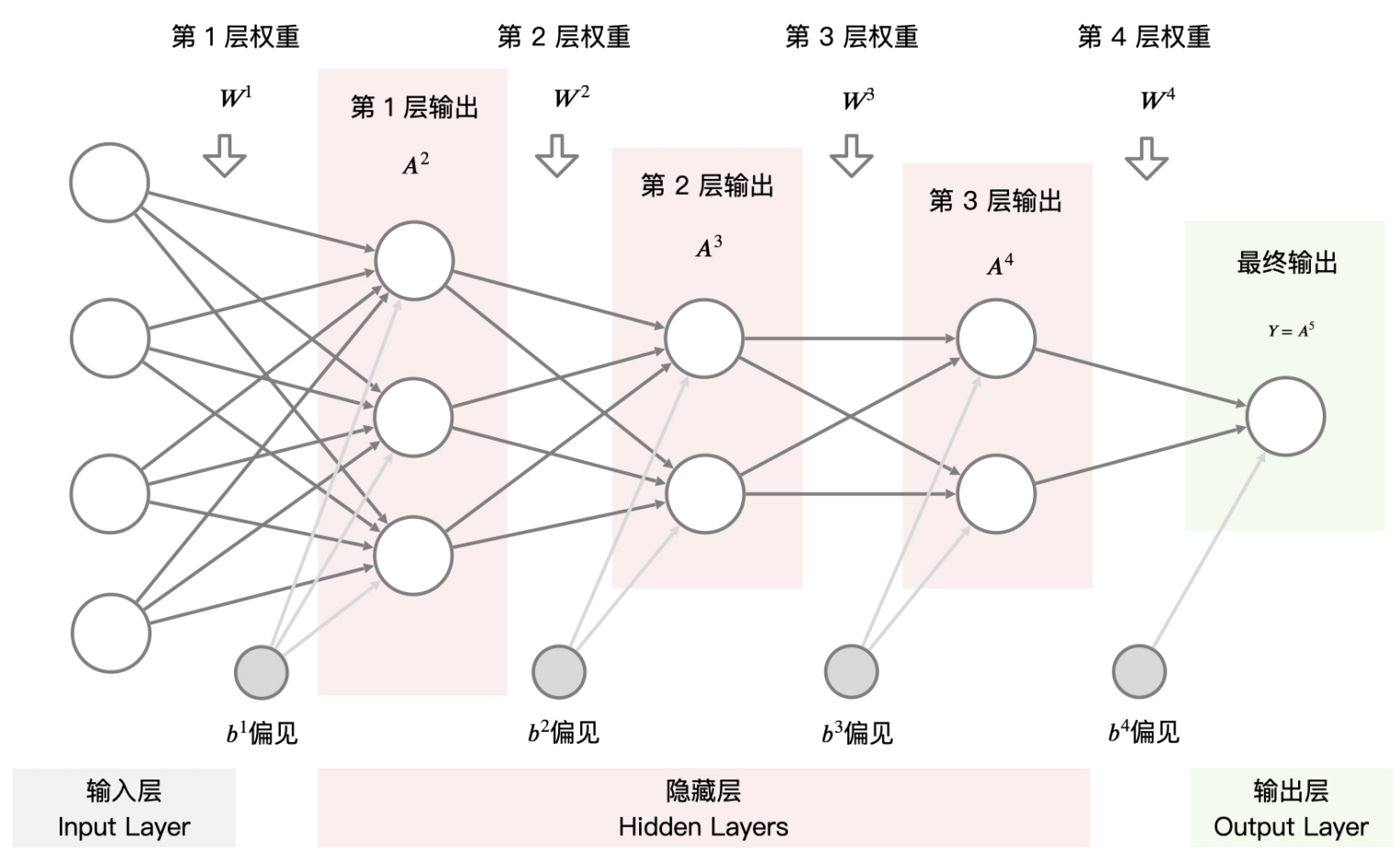
上图这样由“圆圈”和“连接线”组成的图就是神经网络结构图,我们可以通过一个数学公式来表达:
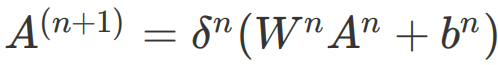
理解公式是理解神经网络组成的关键,接下来我就给你详细讲讲这些参数都是什么。
我对神经网络一直有一个疑惑,假设是一个三分类问题,我们隐藏藏有两层,每层有10个神经元,我很好奇,3分类,为什么中间可以拆分为10?这有什么对应关系?我还有一点不明白,以输入层到第一个隐藏层为例,假设输入的特征维度是3,第一个隐藏层有10个神经元,每个神经元的输出是什么呢?是对这三个特征的“放大”或者“拆解”成10个新的更细致的特征吗?我很困惑你的理解方向是对的!第一个隐藏层神经元的输出确实可以看作是对输入特征的 “加工后的新特征”,但更准确地说,是对输入特征的 “线性组合 + 非线性转换”,目的是从原始特征中提取更有价值的信息(既可能是 “放大” 重要特征,也可能是 “组合” 出全新特征)。
我们以 “输入 3 个特征 → 第一个隐藏层 10 个神经元” 为例,一步步拆解每个神经元的输出是什么、为什么要这样设计:
一、单个神经元的计算逻辑:从 3 个特征到 1 个 “新特征”
假设输入特征是x_1, x_2, x_3(比如 “身高、体重、年龄”),隐藏层的第一个神经元会做两件事:
- 线性组合:给每个输入特征分配一个权重(w_1, w_2, w_3),再加上一个偏置(b),计算出一个 “加权和”:z = w_1x_1 + w_2x_2 + w_3x_3 + b 这个 z 可以理解为 “对输入特征的初步整合”(比如w_1=0.8, w_2=0.2 可能表示更关注x_1)。
- 非线性转换:通过激活函数(比如 ReLU)对 z 进行处理,得到神经元的输出 a:a = \text{ReLU}(z) = \max(0, z) 这一步的作用是引入非线性(如果没有激活函数,无论多少层神经元,最终都只是输入的线性组合,无法学习复杂规律)。
二、10 个神经元的输出:10 个 “不同角度的新特征”
隐藏层有 10 个神经元,意味着:
- 每个神经元都有独立的权重和偏置(比如第 2 个神经元的权重是w_1', w_2', w_3',偏置是b');
- 每个神经元会从不同角度对输入特征x_1, x_2, x_3进行组合和转换,最终输出 10 个值a_1, a_2, ..., a_{10}。
这些输出可以理解为:
- 不是简单的 “拆解” 或 “放大”,而是基于原始特征创造出的 10 个全新特征,每个特征都代表对输入的一种 “解读方式”。
举例:
- 神经元 1 的输出a_1可能代表 “身高 ×0.8 + 体重 ×0.2”(侧重身高的特征);
- 神经元 2 的输出a_2可能代表 “体重 ×0.5 + 年龄 ×0.5”(体重和年龄的综合特征);
- 神经元 3 的输出a_3可能代表 “身高 ×0.3 - 年龄 ×0.1”(身高与年龄的对比特征);
- ... 以此类推,10 个神经元就有 10 种不同的 “解读方式”。
三、为什么需要 10 个新特征?—— 为了捕捉 “非线性关系”
原始输入的 3 个特征可能无法直接用于分类或预测,因为真实世界的规律往往是非线性的(比如 “体重对结果的影响在不同年龄段是不同的”)。
10 个神经元的作用就是通过不同的组合方式,把原始的线性特征 “扭曲”“组合” 成能反映非线性规律的新特征。例如:
- 假设任务是 “预测是否患糖尿病”,输入是 “血糖、BMI、胰岛素水平”(3 个特征);
- 隐藏层的神经元可能会学习到 “血糖高且 BMI 高时风险剧增”“胰岛素水平低但 BMI 正常时风险较低” 等复杂关系,这些关系无法通过单一的原始特征表达,必须通过组合形成新特征。
四、总结:隐藏层神经元的本质是 “特征转换器”
- 每个神经元的输出是输入特征的加权组合 + 非线性激活,本质是一个 “定制化的新特征”;
- 多个神经元(如 10 个)就像 10 个 “不同的特征探测器”,从不同角度提取输入中对任务有用的信息;
- 这些新特征可能看起来和原始特征 “无关”,但它们的组合能更清晰地反映输入与输出(比如分类结果)之间的规律。
这也是神经网络 “万能近似定理” 的体现:理论上,足够多的神经元可以通过组合,近似任何复杂的函数关系 —— 无论输入和输出的维度差异有多大。
您这个问题问得非常好,这触及了神经网络最核心、最神奇的部分。您的直觉——“拆解成10个新的更细致的特征”——已经非常接近本质了。
让我们用一个更具体的例子来拆解这个过程。想象一下,我们的输入是描述一个学生的三个特征:
[学习小时数, 课堂参与度, 作业分数],每个特征都标准化到0-1之间。每个神经元在做什么?
第一个隐藏层有10个神经元。每个神经元都是一个独立的“小专家”,它的任务是从自己特定的角度来综合评估这个学生。
每个神经元的计算分为两步:
1.线性组合(加权求和):
- 每个神经元都有3个权重(
w1, w2, w3)和1个偏置(b)。- 它将输入的特征按照自己的“重视程度”(权重)进行组合。
- 计算:
z = (w1 * 学习小时数) + (w2 * 课堂参与度) + (w3 * 作业分数) + b这意味着什么?
•神经元A 可能非常看重“学习小时数”(
w1很大),而忽略其他特征。它是一个“努力型”专家。•神经元B 可能认为“课堂参与度”和“作业分数”更重要,它是一个“综合表现型”专家。
•神经元C 的权重可能全是负的,它擅长识别“表现较差”的学生模式。
•偏置项
b 像一个门槛,用来调节这个神经元整体的激活难易程度。2.非线性激活(ReLU):
•得到加权和
z后,它会通过一个激活函数(这里是ReLU:f(z) = max(0, z))。这意味着什么?
•如果这个“小专家”的综合评估
z低于其激活门槛(主要由偏置b决定),它就认为“这个模式不明显”,输出为0。•如果评估结果
z超过了门槛,它就输出一个大于0的值,值越大表示它越“确信”自己检测到了某种特定的学生模式。所以,10个神经元的输出到底是什么?
这10个神经元的输出,共同构成了一个全新的、10维的“学生表现特征向量”。
这个新向量不再是原始的生硬数据(学习小时、参与度、分数),而是10个“小专家”从原始数据中抽象出的高级特征。这些高级特征可能代表了人类难以直接命名但确实存在的复杂模式,例如:
•神经元1的输出:可能代表“潜在的优等生特质”的强度(它综合了努力和效率)。
•神经元2的输出:可能代表“有风险挂科”的可能性。
•神经元3的输出:可能代表“参与度高但效率低”的模式。
•...等等。
一个生动的比喻:厨房
把神经网络想象成一个厨房:
•输入层(3个特征):就像是送进厨房的原始食材(鸡肉、米饭、咖喱)。
•隐藏层(10个神经元):就像是厨房里的10个厨师。每个厨师(神经元)用自己的独特方式(权重和偏置)处理这些食材(输入特征)。
•厨师A可能擅长做咖喱酱。
•厨师B可能擅长煮米饭。
•厨师C可能擅长煎鸡肉。
•输出(10个新特征):就是这10个厨师处理完后,得到的10种半成品或调味料(香浓的咖喱酱、粒粒分明的米饭、外焦里嫩的鸡肉块...)。这些半成品比原始食材更高级、更接近最终的菜肴。
•输出层:就像是主厨,他不再处理原始食材,而是品尝这10种半成品,然后决定最终做出什么菜(属于哪个分类)。
总结
所以,您的理解是正确的!第一个隐藏层确实是将3个原始特征“拆解”和“重组”成了10个新的、更细致、更抽象的高级特征。神经网络的强大之处就在于,它不需要人类告诉它这些特征应该是什么,它可以通过训练数据自己学习出最有用的特征组合方式,从而解决复杂的任务。
希望这个解释能彻底解开您的困惑!
深度学习演示
https://playground.tensorflow.org/
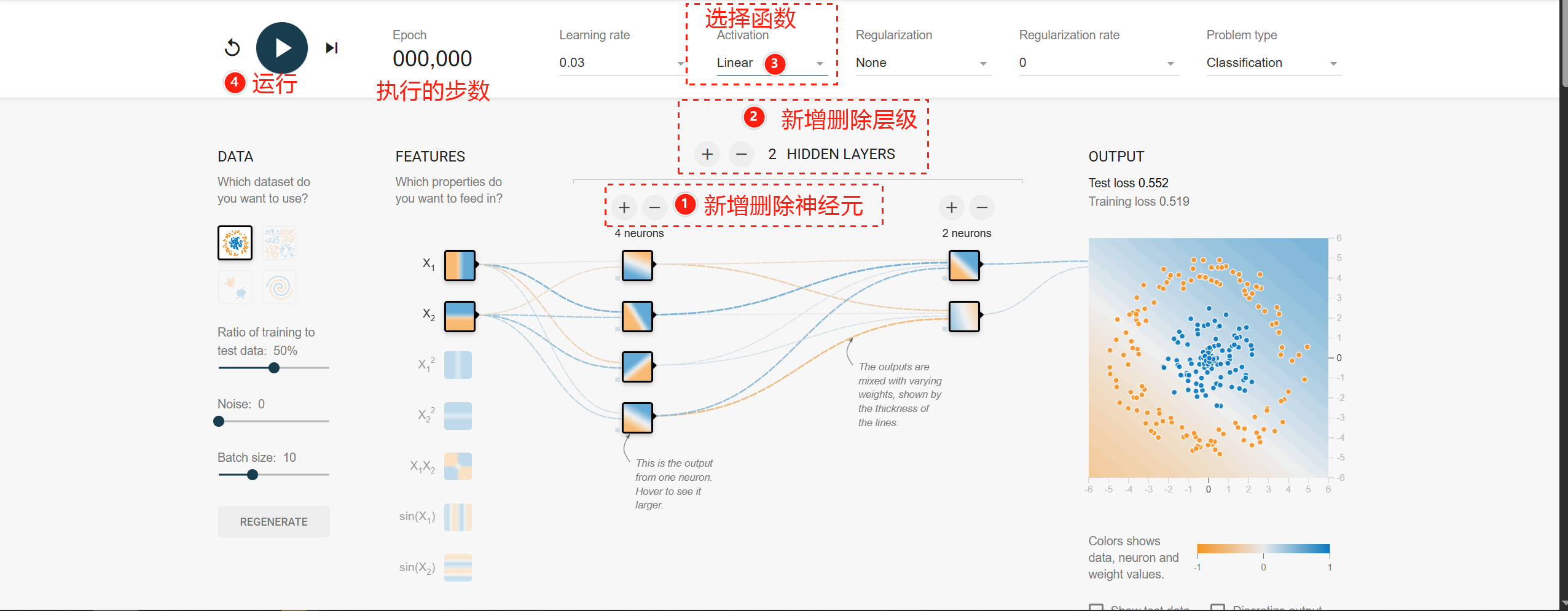
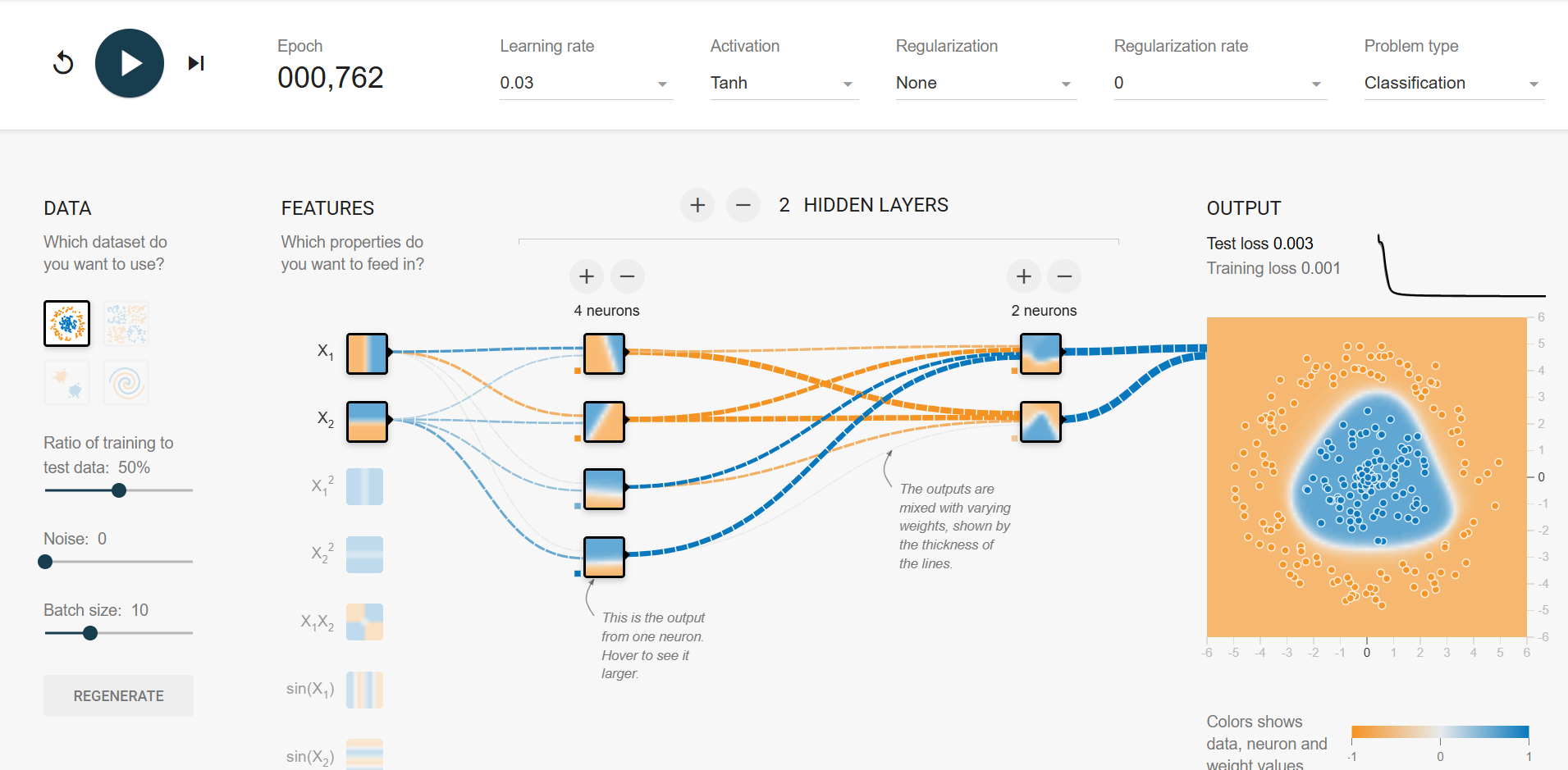
每层作用具体讲解





小结
深度学习模型训练目标
深度学习的应用案例:图像识别是如何实现的?

CNN 是如何实现图像识别的?
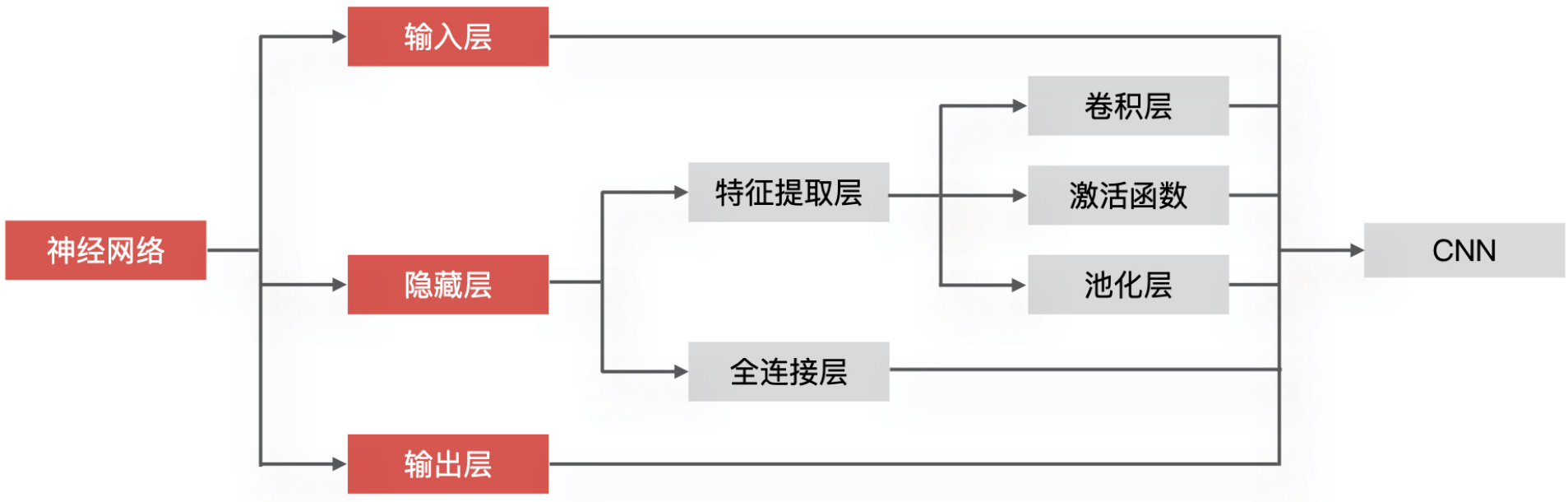
接下来,我就结合下面的示意图,给你详细讲讲它对图像的处理过程。
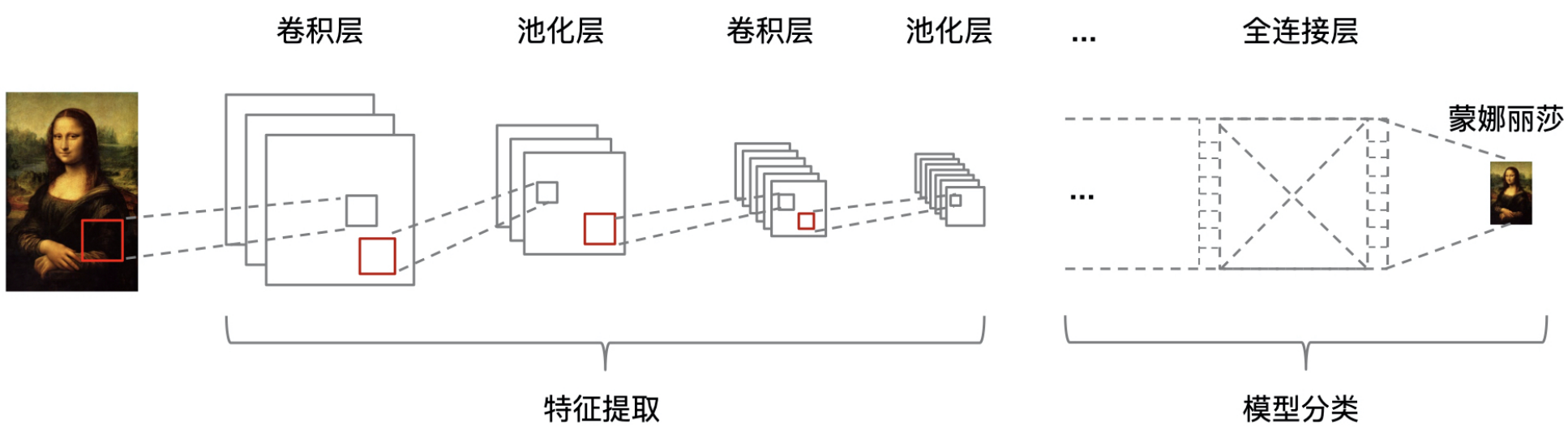
CNN 实现图像处理的第一步,就是把图像数据输入到 CNN 网络模型中。我们在数学和统计学基础概念中讲到,任意一张彩色图片都可以表示成一个三阶张量,即三维数组。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号