linux进程和程序
进程的创建和调度
原创作品转载请注明出处 https://github.com/mengning/linuxkernel/
学号245
实验目的
-
实验:从整理上理解进程创建、可执行文件的加载和进程执行进程切换,重点理解分析fork、execve和进程切换
-
阅读理解task_struct数据结构 http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235 ;
-
分析fork函数对应的内核处理过程do_fork,理解创建一个新进程如何创建和修改task_struct数据结构;
-
使用gdb跟踪分析一个fork系统调用内核处理函数do_fork ,验证您对Linux系统创建一个新进程的理解,特别关注新进程是从哪里开始执行的?为什么从那里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
-
理解编译链接的过程和ELF可执行文件格式;
-
编程使用exec*库函数加载一个可执行文件,动态链接分为可执行程序装载时动态链接和运行时动态链接;
-
使用gdb跟踪分析一个execve系统调用内核处理函数do_execve ,验证您对Linux系统加载可执行程序所需处理过程的理解;
-
特别关注新的可执行程序是从哪里开始执行的?为什么execve系统调用返回后新的可执行程序能顺利执行?对于静态链接的可执行程序和动态链接的可执行程序execve系统调用返回时会有什么不同?
-
理解Linux系统中进程调度的时机,可以在内核代码中搜索schedule()函数,看都是哪里调用了schedule(),判断我们课程内容中的总结是否准确;
-
使用gdb跟踪分析一个schedule()函数 ,验证您对Linux系统进程调度与进程切换过程的理解;
-
特别关注并仔细分析switch_to中的汇编代码,理解进程上下文的切换机制,以及与中断上下文切换的关系;
-
撰写一篇博客(署真实姓名或学号最后3位编号),并在博客文章中注明“原创作品转载请注明出处 +
https://github.com/mengning/linuxkernel/ ”,博客内容的具体要求如下:
- 题目自拟,内容围绕Linux系统的执行过程进行;
- 博客中需要使用实验截图
- 博客内容中需要仔细分进程创建、可执行文件的加载和进程执行进程切换
- 总结部分需要阐明自己对Linux系统的执行过程的理解。
- 博客URL提交到https://github.com/mengning/linuxkernel/issues/32 截止日期3月26日24:00
-
进程的创建
再http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#task_struct中1235行我们可以看到一个很长的tast_struct结构体的定义。下图是部分截图:
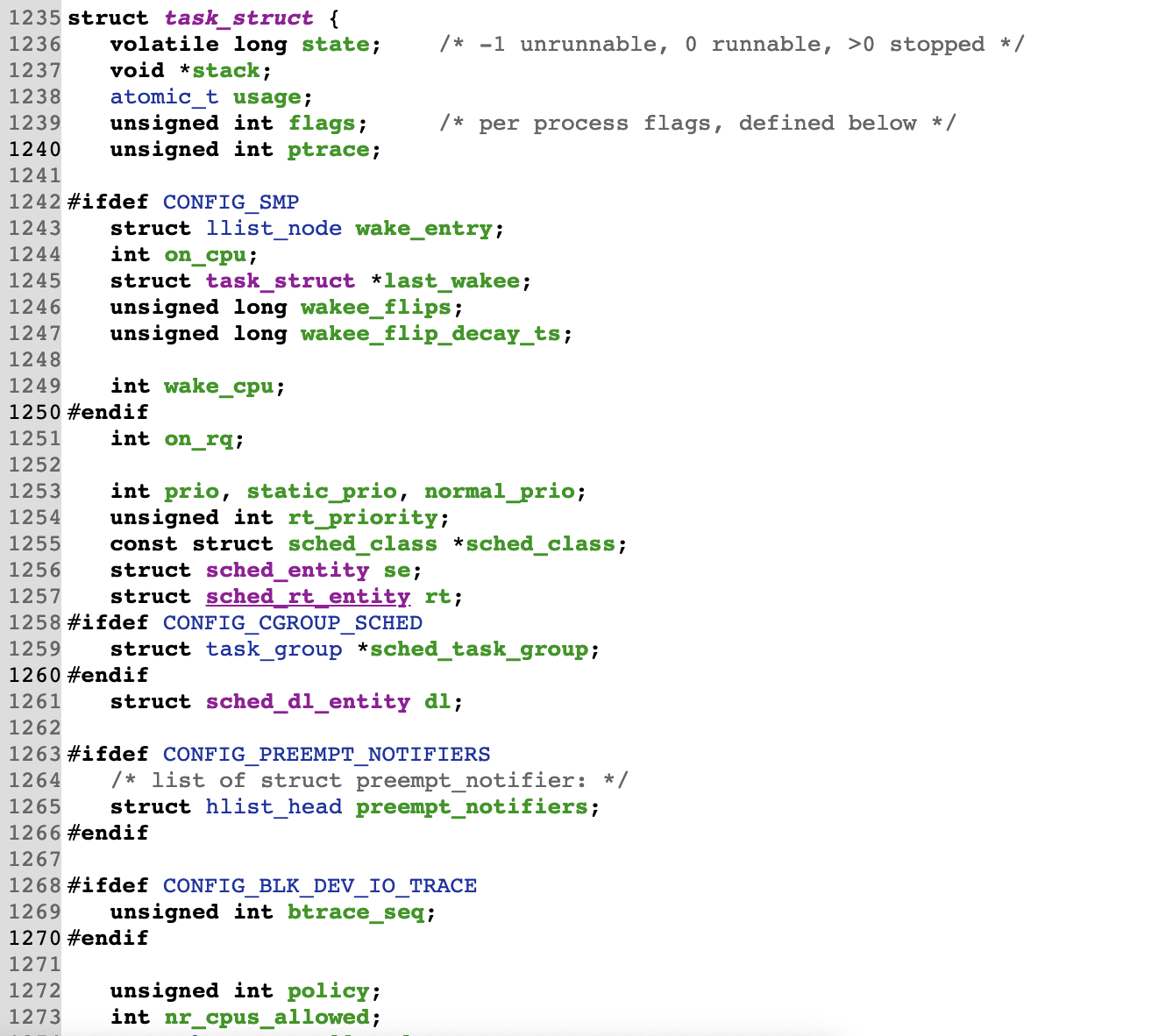
进程管理是操作系统提供的最基本的功能之一,为了描述进程,用进程控制块PCB来唯一地定义一个进程。tast_struct中定义了进程的标识、进程的状态、进程的调度策略等。如:状态state用-1、0、>0表示三种状态。其中,各部分依次是:进程的底层信息、指向内存区域描述符的指针、进程相关的tty设备、当前目录、指向文件描述符的指针、接收到的信号。
Fort、vfort、clone都可以用来创建一个新的进程,但其实他们都是调用了do_fork函数实现的。
long do_fork(unsigned long clone_flags,
1624 unsigned long stack_start,
1625 unsigned long stack_size,
1626 int __user *parent_tidptr,
1627 int __user *child_tidptr)
1628{
1629 struct task_struct *p;
1630 int trace = 0;
1631 long nr;
1632
1633 /*
1634 * Determine whether and which event to report to ptracer. When
1635 * called from kernel_thread or CLONE_UNTRACED is explicitly
1636 * requested, no event is reported; otherwise, report if the event
1637 * for the type of forking is enabled.
1638 */
1639 if (!(clone_flags & CLONE_UNTRACED)) {
1640 if (clone_flags & CLONE_VFORK)
1641 trace = PTRACE_EVENT_VFORK;
1642 else if ((clone_flags & CSIGNAL) != SIGCHLD)
1643 trace = PTRACE_EVENT_CLONE;
1644 else
1645 trace = PTRACE_EVENT_FORK;
1646
1647 if (likely(!ptrace_event_enabled(current, trace)))
1648 trace = 0;
1649 }
1650
1651 p = copy_process(clone_flags, stack_start, stack_size,
1652 child_tidptr, NULL, trace);
1653 /*
1654 * Do this prior waking up the new thread - the thread pointer
1655 * might get invalid after that point, if the thread exits quickly.
1656 */
1657 if (!IS_ERR(p)) {
1658 struct completion vfork;
1659 struct pid *pid;
1660
1661 trace_sched_process_fork(current, p);
1662
1663 pid = get_task_pid(p, PIDTYPE_PID);
1664 nr = pid_vnr(pid);
1665
1666 if (clone_flags & CLONE_PARENT_SETTID)
1667 put_user(nr, parent_tidptr);
1668
1669 if (clone_flags & CLONE_VFORK) {
1670 p->vfork_done = &vfork;
1671 init_completion(&vfork);
1672 get_task_struct(p);
1673 }
1674
1675 wake_up_new_task(p);
1676
1677 /* forking complete and child started to run, tell ptracer */
1678 if (unlikely(trace))
1679 ptrace_event_pid(trace, pid);
1680
1681 if (clone_flags & CLONE_VFORK) {
1682 if (!wait_for_vfork_done(p, &vfork))
1683 ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
1684 }
1685
1686 put_pid(pid);
1687 } else {
1688 nr = PTR_ERR(p);
1689 }
1690 return nr;
1691}
从代码中可以看出,do_fork调用了copy_process创建进程,这个函数又很长,大概400行左右。

它做了这么几件事:
- 复制当前的tast_struct;
- 初始化进程,并将状态设为TASK_RUNNING;
- 复制父进程的所有信息;
- 调用
copy_thread初始化子进程的内核栈; - 为新的进程分配设置新的pid;
可执行文件加载
Linux环境下,fork系统调用将会创建一个与当前task完全一样的新task,直到应用程序调用exec*系列的Glibc库函数最终调用execve系统调用之后,Linux内核才开始真正装载ELF可执行文件(映像文件)。execve内核入口为sys_execve,随之调用do_execve将查找这个可执行文件,如果找到则读取ELF可执行文件的前128个字节,然后调用search_binary_handle通过ELF文件头中的e_ident得到可执行文件的Magic Number,判断出这是一个什么类型的可执行文件,并调用不同可执行文件的装载处理程序,对于ELF可执行文件而言,其装载处理程序为load_elf_binary,这个函数将会把execve系统调用的返回地址修改为ELF可执行文件的入口点,对于静态链接得到的ELF文件即文件头中定义的e_entry,对于动态链接得到的ELF可执行文件则是动态链接器。一步一步返回到sys_execve之后,因为返回地址已经被修改为了ELF程序入口地址了,所以系统调用返回到用户态之后,EIP指令寄存器将直接跳转到ELF程序入口地址,程序开始执行,装载完成。
过程如下:
fork -> execve() -> sys_execve() -> do_execve()
进程切换
内核执行进程切换由两步组成:
- 切换全局目录以安装一个新的地址空间;
- 切换内核态堆栈和硬件上下文,因为硬件上下文提供了内核执行新进程所需要的所有信息,包含CPU寄存器。
switch_to()
/* context switching is now performed out-of-line in switch_to.S */
extern struct task_struct *__switch_to(struct task_struct *,
struct task_struct *);
#define switch_to(prev, next, last)\
do {\
((last) = __switch_to((prev), (next)));\
} while (0)
其中调用了__switch_to函数:
__switch_to
__switch_to(
struct task_struct *prev_p,
struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(init_tss, cpu);
bool preload_fpu;
preload_fpu = tsk_used_math(next_p) && next_p->fpu_counter > 5;
__unlazy_fpu(prev_p);
if (preload_fpu)
prefetch(next->xstate);
load_sp0(tss, next);
lazy_save_gs(prev->gs);
load_TLS(next, cpu);
if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl))
set_iopl_mask(next->iopl);
if (unlikely(task_thread_info(prev_p)->flags
& _TIF_WORK_CTXSW_PREV
|| task_thread_info(next_p)->flags
& _TIF_WORK_CTXSW_NEXT))
__switch_to_xtra(prev_p, next_p, tss);
if (preload_fpu)
clts();
arch_end_context_switch(next_p);
if (preload_fpu)
__math_state_restore();
if (prev->gs | next->gs)
lazy_load_gs(next->gs);
percpu_write(current_task, next_p);
return prev_p;
}
在switch_to函数中,prev和next是输入参数,假设内核决定暂停进程A而激活进程B,在schedule函数中,prev指向A的描述符,而next指向B的进程描述符。switch_to宏一旦使A暂停,A的执行流就被冻结。
总结
进程管理是操作系统提供的最基本的功能之一,通过do_fork创建新进程。当内核需要切换到另一个进程时候,需要保存当前进程的所有状态,即当前进程的上下文,这样当再次执行该进程时候,能够恢复之前的状态继续执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号