
第4周小组作业:WordCount优化
本次项目的github地址为:https://github.com/iwannastay/WcPro
PSP表格
|
PSP2.1 |
PSP阶段 |
预估耗时 (分钟) |
实际耗时 (分钟) |
|
Planning |
计划 |
||
|
· Estimate |
· 估计这个任务需要多少时间 |
15 | 15 |
|
Development |
开发 |
||
|
· Analysis |
· 需求分析 (包括学习新技术) |
60 | 60 |
|
· Design Spec |
· 生成设计文档 |
30 | 30 |
|
· Design Review |
· 设计复审 (和同事审核设计文档) |
10 | 10 |
|
· Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
10 | 10 |
|
· Design |
· 具体设计 |
30 | 30 |
|
· Coding |
· 具体编码 |
300 | 200 |
|
· Code Review |
· 代码复审 |
45 | 30 |
|
· Test |
· 测试(自我测试,修改代码,提交修改) |
60 | 40 |
|
Reporting |
报告 |
||
|
· Test Report |
· 测试报告 |
120 | 150 |
|
· Size Measurement |
· 计算工作量 |
15 | 10 |
|
· Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
10 | 10 |
|
合计 |
705 | 595 |
模块编写和测试
这次我负责的是单词统计模块,即将文件中的单词读取并统计其次数,得到中间结果用于后面的排序和输出,接下来对于该模块的设计和测试进行说明。
模块设计
首先在事先设计好的类WcFile中定义好相关属性,这些属性如下所示,作为我们接下来处理所需的参数。
1 class WcFile 2 { 3 private: 4 static int Line_Size; //每行字符上限 5 int Line_Num; //行数 6 char *File_Line; //行字符 7 map<string, int> Word_List; //记录集 8 vector<pair<string, int>> Rank_List; //排序集 9 10 string ResultFile_Name; //输出文件路径 11 fstream File_Stream; //文件流 12 13 string Regex_Name = "[[:alpha:]]+(-[[:alpha:]]+)*"; //正则表达式 14 15 public: 16 string File_Name; //输入文件名,便于测试 17 };
接下来我们在构造方法中加上正则表达式处理部分(正则表达式用于简化对单词的判断):
1 WcFile::WcFile(const char * _filename) 2 { 3 Line_Num = 0; 4 File_Line = (char*)malloc(Line_Size * sizeof(char)); 5 memset(File_Line, 0, Line_Size * sizeof(char)); 6 Rank_List.reserve(100); 7 ResultFile_Name = "result.txt"; 8 Regex_Name = "[[:alpha:]]+(-[[:alpha:]]+)*"; 9 LoadFile(_filename); 10 }
于是当我们创建了一个对象之后,我们利用之前分析得到的需求来进行相关的行处理,代码如下:
1 //文件行处理 2 void WcFile::LineProcess() 3 { 4 regex r(Regex_Name); 5 string test_str = File_Line; 6 for (sregex_iterator it(test_str.begin(), test_str.end(), r), end_it; it != end_it; it++) 7 { 8 string str = it->str(); 9 transform(str.begin(), str.end(), str.begin(), ::tolower); 10 Insert(str); 11 } 12 }
最后我们把所得到的结果构造成列表作为文件属性保存下来。
1 //插入单词记录集 2 void WcFile::Insert(string& _str) 3 { 4 auto iter = Word_List.find(_str); 5 if (iter != Word_List.end()) 6 iter->second++; 7 else 8 Word_List.insert(pair<string, int>(_str, 1)); 9 }
测试用例设计
我们这个功能可以分成两个部分:导入文件、单词识别,因此我们针对这两个不同的功能部分来分别设计测试用例。
测试用例显示如下:
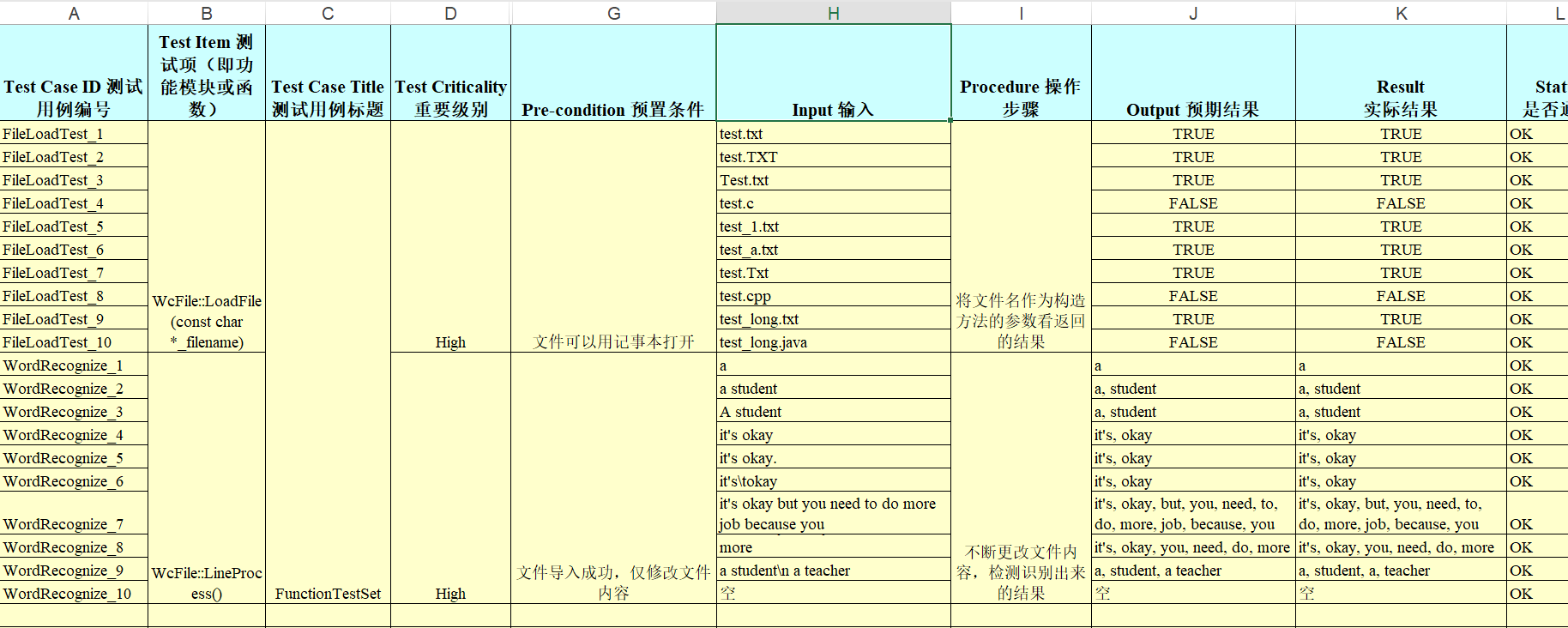
单元测试结果
参考我在github上上传的用例清单,基本上测试都是OK。
扩展任务
1. 开发规范说明
这里的开发规范参考了Google的C++风格指南。
其中对于类定义,变量名,注释等等部分的说明很详细,主要参考的也是相应的部分。我所写的代码也尽量向相应的规范靠拢。
2. 交叉代码评审
我这次参加了17024和17022两位同学的代码评审,两位同学的代码都比较接近上述说明的规范,比如:
1 //文件处理框架 2 void WcFile::MainProcess() 3 { 4 while (!File_Stream.eof()) 5 { 6 File_Stream.getline(File_Line, Line_Size); 7 int num = File_Stream.gcount(); 8 if (num + 1 >= Line_Size&&File_Line[Line_Size - 1] != '\n') 9 { 10 cout << "Line: " << Line_Num + 1 << " is too long" << endl; 11 } 12 Line_Num++; 13 LineProcess(); 14 } 15 RankProcess(); 16 } 17 18 //插入单词记录集 19 void WcFile::Insert(string& _str) 20 { 21 auto iter = Word_List.find(_str); 22 if (iter != Word_List.end()) 23 iter->second++; 24 else 25 Word_List.insert(pair<string, int>(_str, 1)); 26 }
上述代码中变量的定义,注释的内容和形式都比较完整,体现了对规范的遵守和执行;而且代码质量很高,虽然情况比较复杂,但是能尽量考虑周全,代码分布规则,运行结果正确,并且稳定性很好。这说明两位同学都是很负责的。
3. 静态代码扫描
这里使用了开发环境Eclipse的代码静态检查机制,虽然Eclipse使用的是GCC编译器,与其他组员使用VC编译器的不同,但是由于没有采用Windows框架的库函数,运行起来还是没有问题的。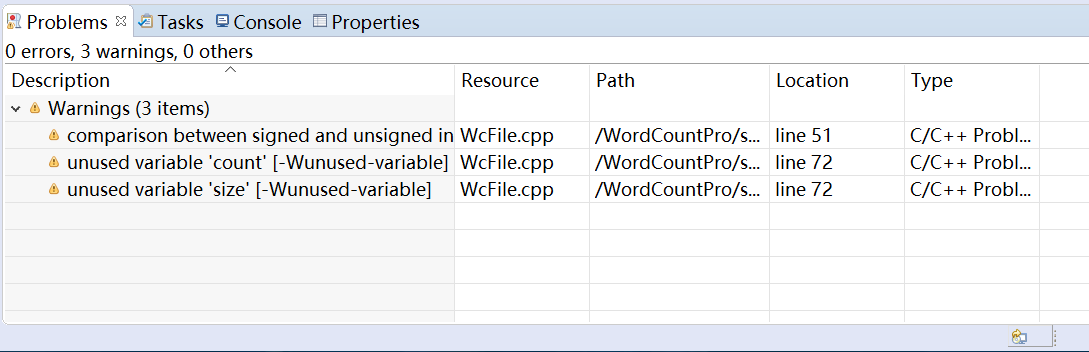
4. 组内代码分析
从大家的代码,测试结果和运行情况来看,我们小组的同学都比较重视代码的规范和健壮性,大家的辛苦没有白费。
小组贡献评价
大家给的评价是0.30,其他同学也做的很好,希望给分的时候也照顾一下其他同学。
小结
在这次小组作业中,我个人感觉确实做了一些事情,虽然还远远不够,但是也还是有很大收获的。不仅在编程方面,更重要的是在软件质量测试和软件工程方法的应用方面有了一定的认识。
posted on 2018-04-07 20:42 ShinMephisto 阅读(202) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号