第28~29讲:文件(因为懂你、所以永恒)
一 文件相关内容
1 什么是文件
是指保存数据的文本,有不同的格式:".exe"--可执行文件、".txt--文本文件"、".ppt--PPT演示文件"、".jpg--图片"、".mp4--音频文件"、".avi--视频文件"
2 python中文件操作的流程:
- 1. 打开文件,得到一个文件句柄并赋值给一个变量 f = open("test.txt","r",encoding="utf-8")
- 2. 通过句柄对文件进行操作 content = f.read()
- 3. 关闭文件 f.close()
需要注意的点:
- 1. 尽管在这里我们说通过python操作(读写)文件,但实际的过程是python不能直接度读写文件,只能通过向操作系统提供的相应接口发出请求,要求打开一个文件对象,然后由操作系统的接口来完成对文件的具体操作。这里的文件句柄即文件描述符,唯一标识了一个文件对象。
- 2. 完整的文件操作一定包含了最后一步关闭处理,否则会造成系统资源的严重浪费,每个程序员都应明确践行这点。
- 3. 对文件进行读写操作时,系统维护了一个指针,指向当前处理完毕后所处文件的位置。
- 可通过f.seek(n) 将文件指针移动到n处,n为0则表示移动到文件开头位置
- 可通过f.tell()来获取当前文件指针的位置
3 文件的基本操作
(1)打开文件:open()方法
(2)读取文件:read()方法
(3)写入、创建:write方法
(4)关闭文件:close()方法
(5)文件重命名:rename()方法——os.rename(current_file_name, new_file_name)
(6)文件删除:remove()方法——os.remove(file_name)
具体内容可参考以下几个网站,因为之前已经了解过,这里就当总结了:
- 我自己的一篇博客:https://www.cnblogs.com/luoxun/p/13217093.html
- 一个超详细、例子超全的博客:https://www.cnblogs.com/linupython/p/6508121.html
- 菜鸟教程:https://www.runoob.com/python/python-files-io.html
- 菜鸟教程:https://www.runoob.com/python/file-methods.html
- 一个超全的教学网站:http://c.biancheng.net/python/file/
4 文件的打开模式
文件的操作需遵循以下规范:句柄变量 = open(文件路径,打开模式,文件编码)
其中文件路径最好定义绝对路径,除非相对路径非常确定,打开模式默认的是r模式,文件编码默认为utf-8。
(1)普通打开模式:
- r模式:只读模式,不可对文件进行写处理。
- w模式:写模式,如果文件不存在则先创建空文件然后写入指定内容,否则则直接覆盖写原文件。注意该模式下不可对文件进行读处理。
- 覆盖写处理:指的是测试文件仅仅保留了write进去的内容
- open文件之后第一次写是覆盖写。close前的第二次写却是追加写。
- a模式:追加模式,写入的内容总是在当前文件的末尾追加进去,无论怎么移动指针。注意该模式下仍然不可对文件进行读处理。
(2)同时读写模式
- r+模式:读写模式,同时具备读和写权限,但写入时默认是把内容写入到文件末尾进行追加写,而不是覆盖写,除非在写入时先把指针移动到文件头。
- w+模式:写读模式,同时具备写和读权限,先创建新的空文件,然后写入内容。该模式实际不常用。
- a+模式:追加内容的同时可读,注意新内容一定是在源文件末尾追加,同时在读取文件内容时文件指针默认就在文件末尾,因此不移动文件指针到文件头部是不能读取到文件内容的。
(3)二进制打开模式
- 二进制文件要以二进制模式进行读取,该模式下打开文件时不能传递编码参数。
- 常见的二进制格式文件有音频、视频、网络传输的文件(ftp二进制传输模式),因此处理这些文件上时需要用到二进制打开模式。
- 常见的二进制打开模式下的操作有rb(读二进制),wb(写二进制)和ab(追加二进制)。
- 需要注意的是:
- wb写入时一定要在write后面调用encode()方法将字符串转换为二进制(字节码)写入,同理rb时如果要输出字符串,则需要在read后面调用decode()将二进制字节码转换为字符串输出,原因是python3中对字节码和字符串进行了严格的区分。
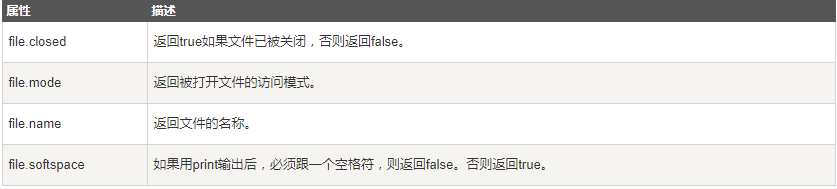
5 文件对象属性
二 一个任务(第29讲)代码讲解
- 题目:
![]()
- record.txt文件
-
![]() View Code
View Code小客服:小甲鱼,今天有客户问你有没有女朋友? 小甲鱼:咦?? 小客服:我跟她说你有女朋友了! 小甲鱼:。。。。。。 小客服:她让你分手后考虑下她!然后我说:"您要买个优盘,我就帮您留意下~" 小甲鱼:然后呢? 小客服:她买了两个,说发一个货就好~ 小甲鱼:呃。。。。。。你真牛! 小客服:那是,谁让我是鱼C最可爱小客服嘛~ 小甲鱼:下次有人想调戏你我不阻止~ 小客服:滚!!! =============================== 小客服:小甲鱼,有个好评很好笑哈。 小甲鱼:哦? 小客服:"有了小甲鱼,以后妈妈再也不用担心我的学习了~" 小甲鱼:哈哈哈,我看到丫,我还发微博了呢~ 小客服:嗯嗯,我看了你的微博丫~ 小甲鱼:哟西~ 小客服:那个有条回复“左手拿著小甲魚,右手拿著打火機,哪裡不會點哪裡,so easy ^_^” 小甲鱼:T_T ============================ 小客服:小甲鱼,今天一个会员想找你 小甲鱼:哦?什么事? 小客服:他说你一个学生月薪已经超过12k了!! 小甲鱼:哪里的? 小客服:上海的 小甲鱼:那正常,哪家公司? 小客服:他没说呀。 小甲鱼:哦 小客服:老大,为什么我工资那么低啊??是时候涨涨工资了!! 小甲鱼:啊,你说什么?我在外边呢,这里好吵吖。。。。。。 小客服:滚!!!
- 最终代码及注释:
-
![]() View Code
View Code1 def save_file(boy,gril,count): # 定义save_file函数,用来将分片后的内容保存到新的文件中 2 file_name_boy = 'boy_' + str(count) + '.txt' # 利用str(count)的值形成不同的文件名:boy1.txt boy2.txt boy3.txt 3 file_name_gril = 'gril_' + str(count) + '.txt' 4 5 boy_file = open(file_name_boy,'w') # 打开文件boy1.txt boy2.txt boy3.txt 6 gril_file = open(file_name_gril,'w') 7 8 boy_file.writelines(boy) # 将列表boy中的值分行写入文件中 9 gril_file.writelines(gril) 10 11 boy_file.close() # 关闭文件 12 gril_file.close() 13 14 def split_file(filename): # 定义split_file函数用来将文件中的内容切片 15 f = open(filename) # 打开文件 16 boy = [] # 用来存储切片后得到的小甲鱼的对话内容 17 gril = [] # 用来存储切片后得到的小客服的对话内容 18 count = 1 # 用来统计文件的个数,即构建不同的文件名 19 for each_line in f: # 依次遍历f文件中的每行内容 20 # print(each_line) # 依次打印每行内容,可省略,这里我是为了看清程序的运行过程加的 21 if each_line[:6] != "======": # 对每行的内容进行切片操作,即保留每行的前6个字符,判断它是否等于6个等号 22 (role,line_spoken) = each_line.split(':',1) # 对每行内容进行切片,利用split方法 23 if role == '小甲鱼': # 根据role的不同的值,将切片后得到的内容分别添加到boy和gril列表中 24 boy.append(line_spoken) 25 else: 26 gril.append(line_spoken) 27 else: 28 print(f"boy = {boy}\n") # 用来查看boy的值,观察运行过程,可不加 29 print(f"gril = {gril}\n") 30 save_file(boy,gril,count) # 如果每行切片后的值为6个等号,则调用save_file函数将boy和gril列表的值分别保存在一个文件中 31 32 boy = [] # 清空boy的值,用来存储下一个文件的内容 33 gril = [] # 清空boy的值,用来存储下一个文件的内容 34 count += 1 # 更新count值 35 print(f"boy = {boy}\n") # 用来查看boy的值,观察运行过程,可不加 36 print(f"gril = {gril}\n") 37 save_file(boy,gril,count) # 调用save_file函数保存最后一个文件的内容 38 f.close() # 关闭文件 39 40 split_file('record.txt') # 调用split_file函数执行程序
- 我遇到的一个错误讲解(看视频看好多人都遇到了):
- 报错内容:
ValueError: not enough values to unpack (expected 2, got 1) - 原因分析:
- (1)if判断语句:“if each_line[:6] != "======":”出错
- 写代码过程中,等号的个数一定是6个,即跟each_line[:6]切片结果相同,如果将它改成each_line[:9],相应的判断条件里面的等号也要改成9个
- (2)字符串切片语句:“(role,line_spoken) = each_line.split(':',1)”出错
- 语句中的切片字符是冒号,如果自己动手创建record.txt文件中的冒号是中文,在程序代码中是英文,就会出现中英文不对应的情况,程序就会报错
- 原理是:实际并没有对文件中的每行完成切片操作,所以等号右边仍旧只有一行字符串,即一个值,而等号左边有两个变量名,所以会出现不对应的情况
- 报错内容:


三 课后作业
第28讲:
测试题部分
0. 下边只有一种方式不能打开文件,请问是哪一种,为什么?
1 >>> f = open('E:/test.txt', 'w') # A 2 >>> f = open('E:\test.txt', 'w') # B 3 >>> f = open('E://test.txt', 'w') # C 4 >>> f = open('E:\\test.txt', 'w') # D
答:B不能打开文件。
Windows在路径名中既可以接受斜线(/)也可以接受反斜线(\),不过如果使用反斜线作为路径名的分隔符的话,要注意使用双反斜线(\\)进行转义,否则Python会将反斜线进行转义,例如(\n)看成一个换行符,(\t)看作一个制表符等。
1. 打开一个文件我们使用open()函数,通过设置文件的打开模式,决定打开的文件具有那些性质,请问默认的打开模式是什么呢?
答:open()函数默认的打开模式是'rt',即可读、文本的模式打开。
2. 请问 >>> open('E:\\Test.bin', 'xb') 是以什么样的模式打开文件的?
答:以“可写入以及二进制模式”打开文件“E:\\Test.bin”。
这里要注意的是'x'和'w'均是以“可写入”的模式打开文件,但以'x'模式打开的时候,如果路径下已经存在相同的文件名,会抛出异常,而'w'模式的话会直接覆盖同名文件。
因此,'w'模式打开文件会比较危险,容易导致此前的内容遗失,因此使用'w'模式打开文件前先检查该文件名是否已经存在显得非常重要!下节课小甲鱼会教你如何安全的打开一个文件^_^
3. 尽管Python有所谓的“垃圾回收机制”,但对于打开了的文件,在不需要用到的时候我们仍然需要使用f.close()将文件对象“关闭”,这是为什么呢?
答:Python拥有垃圾收集机制,会在文件对象的引用计数降至零的时候自动关闭文件,所以在Python编程里,如果忘记关闭文件并不会造成内存泄漏那么危险。
但并不是说就可以不要关闭文件,如果你对文件进行了写入操作,那么你应该在完成写入之后进行关闭文件。因为Python可能会缓存你写入的数据,如果这中间断电了神马的,那些缓存的数据根本就不会写入到文件中。所以,为了安全起见,要养成使用完文件后立刻关闭的优雅习惯。
4. 如何将一个文件对象(f)中的数据存放进列表中?
答:list(f),是不是非常的方便!
5. 如何迭代打印出文件对象(f)中的每一行数据?
答:直接使用for语句把文件对象迭代出来即可:
1 for each_line in f: 2 print(each_line)
6. 文件对象的内置方法f.read([size=-1])作用是读取文件对象内容,size参数是可选的,那如果设置了size=10,例如f.read(10),将返回什么内容呢?
答:将返回从文件指针开始(注意这里并不是文件头哦)的连续10个字符。
7. 如何获得文件对象(f)当前文件指针的位置?
答:f.tell()会告诉你^_^
8. 还是视频中的那个演示文件(record.txt),请问为何f.seek(45, 0)不会出错,但f.seek(46)就出错了呢?
1 >>> f.seek(46) 2 46 3 >>> f.readline() 4 Traceback (most recent call last): 5 File "<pyshell#18>", line 1, in <module> 6 f.readline() 7 UnicodeDecodeError: 'gbk' codec can't decode byte 0xe3 in position 4: illegal multibyte sequence
答:因为使用f.seek()定位的文件指针是按字节为单位进行计算的,演示文件(record.txt)是以GBK进行编码的,按照规则,一个汉字需要占用两个字节,f.seek(45)的位置位于字符“小”的开始位置,因此可以正常打印,而f.seek(46)的位置刚好位于字符“小”的中间位置,因此按照GBK编码的形式无法将其解码!
动动手
第28讲:
0. 尝试将文件( ![]() OpenMe.mp3 )打印到屏幕上
OpenMe.mp3 )打印到屏幕上
1 f = open('OpenMe.mp3') 2 for each_line in f: 3 print(each_line, end='') 4 f.close()
1. 编写代码,将上一题中的文件(OpenMe.mp3)保存为新文件(OpenMe.txt)
1 f1 = open('OpenMe.mp3') 2 f2 = open('OpenMe.txt', 'x') # 使用”x”打开更安全 3 f2.write(f1.read()) 4 f2.close() 5 f1.close()
第29讲:
0. 编写一个程序,接受用户的输入并保存为新的文件,程序实现如图:


1 # -*- encoding:utf-8 -*- 2 def file_write(file_name): 3 f = open(file_name,"w+",encoding = "utf-8") 4 print("请输入内容【单独输入\':w\'保存退出】:") 5 6 while True: 7 write_some = input() 8 if write_some != ':w': 9 f.write(f"{write_some}") 10 else: 11 break 12 f.close() 13 14 file_name = input("请输入文件名:") 15 file_write(file_name)
1. 编写一个程序,比较用户输入的两个文件,如果不同,显示出所有不同处的行号与第一个不同字符的位置,程序实现如图:
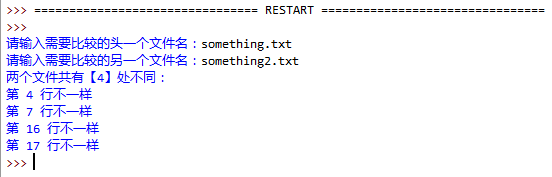
我的代码(功能是不完整的,只有两个文件内容完全不同的时候才能正常运行):
1 # -*- encoding:utf-8 -*- 2 def file_compare(file1,file2): 3 i = 1 4 j = 0 5 f1 = open(file1) 6 f2 = open(file2) 7 while True: 8 string1 = f1.readline() 9 string2 = f2.readline() 10 print(string1) 11 print(string2) 12 if string1 == string2: 13 break 14 else: 15 print(f"第{i}行不一样") 16 j += 1 17 i += 1 18 print(f"两个文件共有【{j}】处不同:") 19 f1.close() 20 f2.close() 21 22 file1 = input("请输入需要比较的头一个文件名:") 23 file2 = input("请输入需要比较的另一个文件名:") 24 file_compare(file1,file2)
小甲鱼的代码:
1 def file_compare(file1, file2): 2 f1 = open(file1) 3 f2 = open(file2) 4 count = 0 # 统计行数 5 differ = [] # 统计不一样的数量 6 7 for line1 in f1: 8 line2 = f2.readline() 9 count += 1 10 if line1 != line2: 11 differ.append(count) 12 13 f1.close() 14 f2.close() 15 return differ 16 17 file1 = input('请输入需要比较的头一个文件名:') 18 file2 = input('请输入需要比较的另一个文件名:') 19 20 differ = file_compare(file1, file2) 21 22 if len(differ) == 0: 23 print('两个文件完全一样!') 24 else: 25 print('两个文件共有【%d】处不同:' % len(differ)) 26 for each in differ: 27 print('第 %d 行不一样' % each)
2 编写一个程序,当用户输入文件名和行数(N)后,将该文件的前N行内容打印到屏幕上,程序实现如图:

我的代码(在小甲鱼的代码基础上,加了一点with语句和easygui编程的内容):
1 import easygui as g 2 3 # 在控制台打印 4 def file_view(file_name,line_num): 5 print(f'\n文件{file_name}的前{line_num}内容如下:\n') 6 with open(file_name) as f: 7 for i in range(int(line_num)): 8 print(f.readline(),end=' ') 9 10 # 利用easygui编程 11 def file_view_gui(file_name,line_num): 12 text = '' 13 with open(file_name) as f: 14 title = '显示文件内容' 15 msg = f'\n文件{file_name}的前{line_num}内容如下:\n' 16 for i in range(int(line_num)): 17 TEXT = f.readline() 18 text += f'{TEXT}\n' 19 g.textbox(msg,title,text) 20 21 22 file_name = input(r'请输入要打开的文件(C:\\test.txt):') 23 line_num = input('请输入需要显示该文件前几行:') 24 file_view(file_name,line_num) 25 file_view_gui(file_name,line_num)
3. 呃,不得不说我们的用户变得越来越刁钻了。要求在上一题的基础上扩展,用户可以随意输入需要显示的行数。(如输入13:21打印第13行到第21行,输入:21打印前21行,输入21:则打印从第21行开始到文件结尾所有内容)

小甲鱼的代码:
1 def file_view(file_name,line_num): 2 if line_num.strip() == ':': 3 begin = '1' 4 end = '-1' 5 6 (begin,end) = line_num.split(':') 7 8 if begin == '': 9 begin = '1' 10 if end == '': 11 end = '-1' 12 13 if begin == '1' and end == '-1': 14 prompt = '的全文' 15 elif begin == '1': 16 prompt = f'从开始到{end}' 17 elif end == '-1': 18 prompt = f'从{begin}到结束' 19 else: 20 prompt = f'从第{begin}行到第{end}行' 21 22 print(f'\n{file_name}文件{prompt}的内容如下:') 23 24 begin = int(begin) - 1 25 end = int(end) 26 lines = end - begin 27 28 with open(file_name) as f: 29 for i in range(begin): # 用于将文件指针移动到第begin行处 30 f.readline() 31 32 if lines < 0: 33 print(f.read()) 34 else: 35 for j in range(lines): 36 print(f.readline(),end='') 37 38 file_name = input(r'请输入要打开的文件(C:\\test.txt):') 39 line_num = input('请输入需要显示的行数【格式如 13:21 或 :21 或 21: 或 : 】:') 40 file_view(file_name, line_num)
4. 编写一个程序,实现“全部替换”功能。
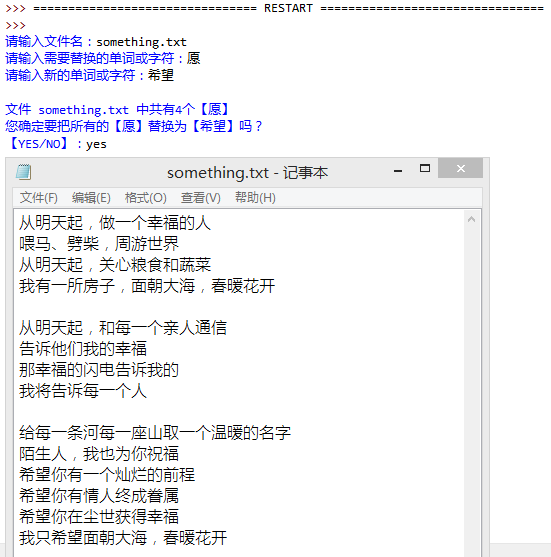
小甲鱼代码:
1 def file_replace(file_name,rep_word,new_word): 2 with open(file_name) as f_read: 3 4 content = [] 5 count = 0 6 7 for eachline in f_read: 8 if rep_word in eachline: 9 count = eachline.count(rep_word) # 感觉应该用这个 10 eachline = eachline.replace(rep_word,new_word) 11 content.append(eachline) 12 13 decide = input(f'\n文件{file_name}中共有{count}个【{rep_word}】\n您确定要把所有的【{rep_word}】替换为【{new_word}】吗?\n【YES/NO】:') 14 15 if decide in ['YES','Yes','yes']: 16 with open(file_name,'w') as f_write: 17 f_write.writelines(content) 18 19 file_name = input('请输入文件名:') 20 rep_word = input('请输入需要替换的单词或字符:') 21 new_word = input('请输入新的单词或字符:') 22 file_replace(file_name,rep_word,new_word)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号