【实战案例】用Pytho(Juypter)分析我的Pixiv数据:第2部分
现在是2024年的7月26日。这一次的分析将承接上一次的结果,并推进到更深入的层次。
1、再次收集数据
改进了上次数据收集方法的不足。上一次是复制网页元素,这一次直接1.保存.html格式网页,2.提取其中的.json数据。上一次太仓促,没仔细看,误以为保存的网页里没有我需要的数据,其实它被塞到一个隐秘的地方,这次是被我找到了:
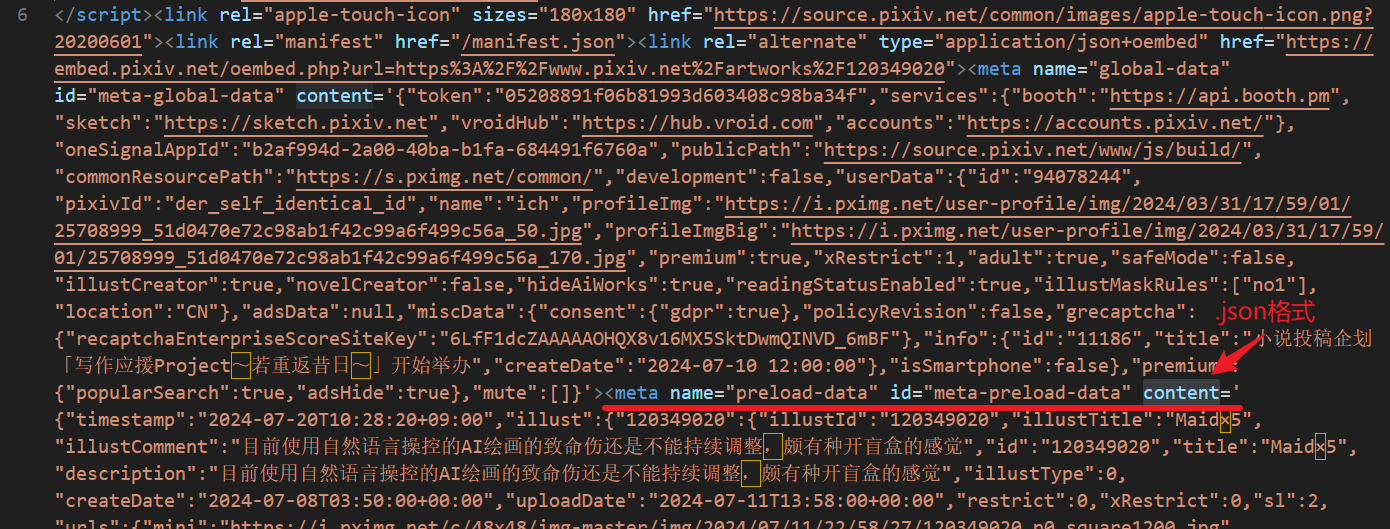
那么提取的代码如下:
import re
import pandas as pd
def get_data(file_path):
pattern = r'"illustId":\s*"(\d+)"'
with open(file_path, encoding = 'utf-8') as file:
page_read = file.read()
page_read = BeautifulSoup(page_read)
meta_tag = page_read.find('meta', {'id': 'meta-preload-data'})
illustId = re.search(pattern, str(meta_tag)).group(1)
meta_data = json.loads(meta_tag['content'])
date_full = meta_data['illust'][illustId]['createDate']
date_pattern = r'\d{4}-\d{2}-\d{2}'
date = re.search(date_pattern, date_full).group(0)
tags = meta_data['illust'][illustId]['tags']
tags = [tag_info['tag'] for tag_info in tags['tags']]
pages = meta_data['illust'][illustId]['pageCount']
views = meta_data['illust'][illustId]['viewCount']
likes = meta_data['illust'][illustId]['likeCount']
bookmarks = meta_data['illust'][illustId]['bookmarkCount']
comments = meta_data['illust'][illustId]['commentCount']
page_data = [
file_path[:-5],
date,
str(tags),
pages,
views,
likes,
bookmarks,
comments
]
return page_data
其中的要点是:先用正则表达式找到这张作品的ID,再用这个ID在.json格式的数据里面提取出需要的数据。
要点:
# 找到每个网页的专属ID
pattern = r'"illustId":\s*"(\d+)"'
illustId = re.search(pattern, str(meta_tag)).group(1)
# 结合ID提取.json的数据
tags = meta_data['illust'][illustId]['tags']
pages = meta_data['illust'][illustId]['pageCount']
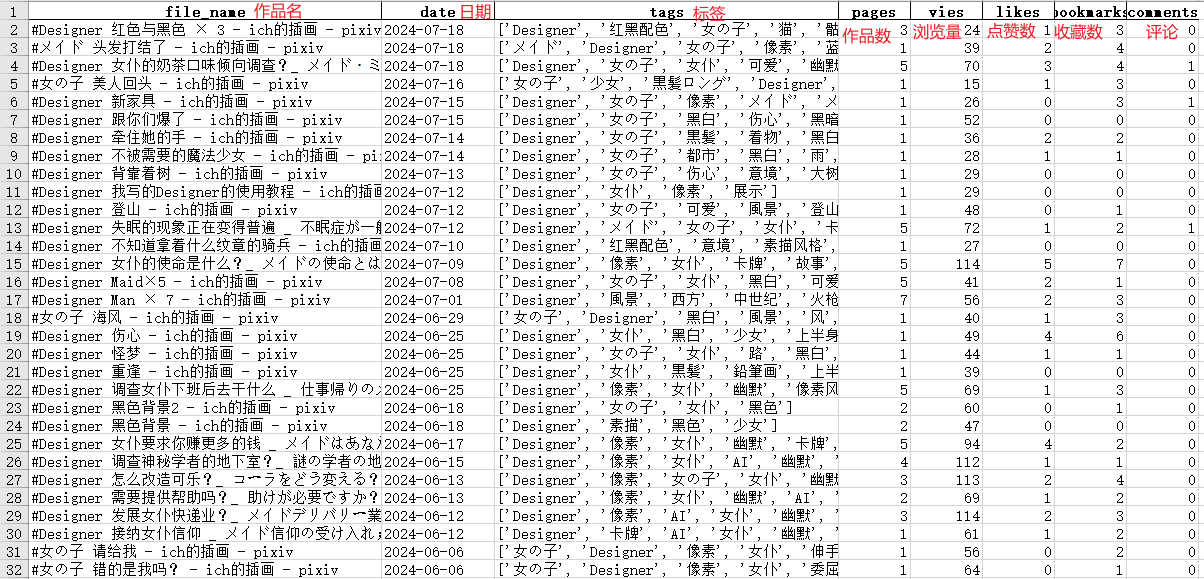
于是紧接着就能得到这样一张表:
2、再次制定评价方法
在上一次的分析中,使用了唯一的评价指标:日均浏览量。但是这个指标不够好,因为日均浏览量高和作品受欢迎不是同义词,还有可能发生叫好不叫座这样的情况。所以这次使用了新指标:赞和收藏的转化量。
公式是:

其中,赞和收藏被当做同质的可合并参数,因为一方面它们同样表达了对作品的好评,另一方面它们又缺乏明显的质的差异,很难区分开在Pixiv中赞和收藏的本质。而转化量指的是多少次的浏览会转化成一次赞或收藏,如果转化量越小,意味着这张作品在相同的曝光度条件下取得了更多的好评,也就是深受欢迎的意思;反之则意味着作品在被浏览的次数相同的情况下,收获的好评更少,意味着不受欢迎。
然后再施加一条限制,至少浏览量在50以上,用于排除极端的情况。如果是要研究小众的倾向的话,应该做相反的限制。但现在并不研究这个。
那么这样就能得到转化量在10以内的作品了:
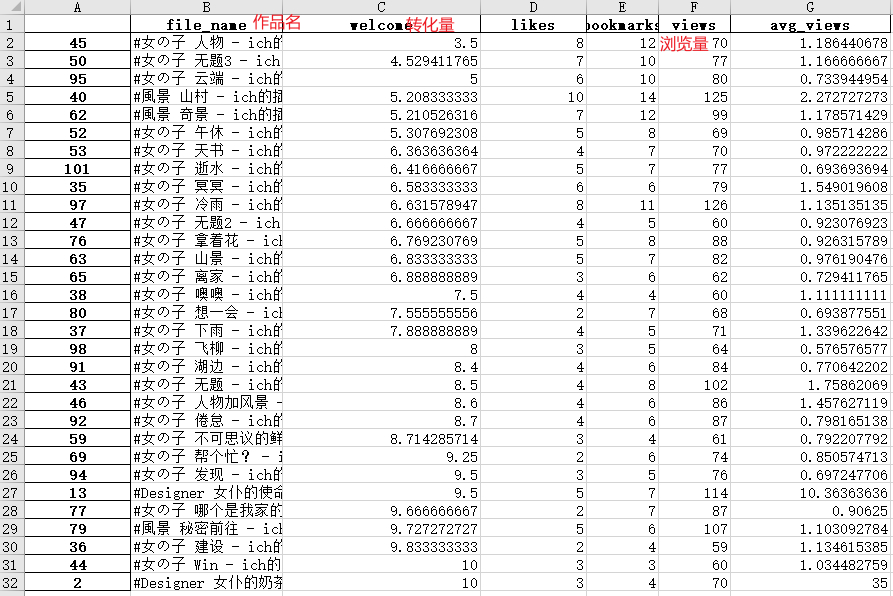
它们是长这样子的:

下一步就是对它们进行观察,提取出它们的共同特征。这就是质的分析方法了,后面就和数据分析说再见了。其中涉及意识形态分析、精神分析、政治经济分析等方法,主要使用辩证法和本质还原,还要结合丰富的实际经验,这就没数据分析什么事情了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号