

SQL基础语法
SQL基础语法
#登录
mysql -uroot -p
# 输入密码(回车)
? -- 客户端的帮助
\c -- 结束未完成的命令
\s -- 获取服务端的状态Status
\! -- 在MySQL客户端中执行系统的命令
\q -- 退出MySQL客户端
# SQL的规范
## 1. 必须以“;”结尾
## 2. 不区分大小写。show databases; SHOW DATABASES; Show DataBases;
## 3. 规范关键字用大写字母。 库名、表名、字段名都用小写字母。 合理使用反引号
### 一个单词或缩写 单词多时使用下划线 time_zone_transition_type
# DDL 数据定义语言
create database 库名; -- 创建一个使用默认字符集的数据库
show databases; -- 查看所有的数据库
show create database 库名; -- 查看该库的创库语句
alter database school charset utf8; -- 修改数据库的字符集
create database 库名 charset utf8; -- 创建时指定字符集
drop database 库名; -- 删除库和库中所有的数据
# select 执行函数或运算
select now();
select version();
select 23 * 33;
DDL (数据定义语言) (Data Definition Language) 对库和表进行操作
Create 创建库、表、索引、视图、用户
Drop 删除各种结构、库、表、视图、索引、用户
Alter 修改库字符集、表结构、索引、视图、用户、密码
DML (数据操纵语言) (Data Manipulation Language) 对表中的数据进行添加、修改、删除
Insert 添加、插入数据
Update 修改、更新表中的内容
Delete 删除表中的内容
DQL (数据查询语言) (Data Query Language) 对表中数据进行查询操作
Select 根据条件查询内容、可以配合函数使用
DCL (数据控制语言) (Data Control Language) 对数据库进行权限管理、用户管理、事务管理
Use 切换数据库
Grant 权限设置
Revoke 移除权限
DTL (事务控制语言) (Data Transaction Language)
#事务保护(重要操作)
#对重要数据更新,可开启事务(BEGIN;),执行后检查结果,确认正确再提交(COMMIT;),错误则回滚(ROLLBACK;)。
Commit 事务提交
Rollback 回滚
-
库操作
- 查看所有库:show databases ;
- 创建库:create database 库名 charset utf8mb4;
- 删除库:drop database 库名 ;— —当删除库时,库中的所有内容都会被删除
- 修改库的字符集:aalter database 库名 charset utf8mb4 ;
-
表操作
- 查看表结构:
- 查看库中所有的表:show tables ;
- 查看表的结构:desc 表名 ;
- 创建表:
#创建表的语法结构 CREATE TABLE 表名 ( 字段名1 数据类型 [约束条件], 字段名2 数据类型 [约束条件], 字段名 数据类型 [约束1] [约束2] ···, ... [表级约束条件] -- 如主键、外键等跨字段约束 ) [表选项]; -- 如字符集、存储引擎等 # 核心关键字与表名 #CREATE TABLE:创建表的固定开头关键字。 #表名:自定义表名(需符合命名规范,如不含特殊字符,建议用小写字母 + 下划 线,如 student_info)。 #⚠️ 注意:表名不能与 MySQL 保留字(如 SELECT、TABLE)重复,若必须使用需用反引号 ` 包裹(如 `order`)。 #数据类型:指定字段存储的数据类型,常见类型如下: #数值型:INT(整数)、FLOAT(单精度浮点数)、DECIMAL(10,2)(高精度小数,如金额)。 #字符串型:VARCHAR(50)(可变长度字符串,需指定长度)、CHAR(10)(固定长度字符串)、TEXT(长文本)。 #日期时间型:DATE(日期,如 2023-10-01)、DATETIME(日期时间,如 2023-10-01 12:30:00)。 #其他:BOOLEAN(布尔值,实际存储为 1/0)、ENUM('男','女')(枚举类型,只能选指定值)。 #约束条件(字段级约束):对字段的限制规则,常用约束如下: #约束 作用 示例 #NOT NULL 字段值不能为 NULL(必须填写) name VARCHAR(50) NOT NULL #PRIMARY KEY 设为主键(唯一标识,非空且唯一) id INT PRIMARY KEY #AUTO_INCREMENT 数值自动增长(常用于主键) id INT PRIMARY KEY AUTO_INCREMENT #UNIQUE 字段值唯一(允许 NULL,但不能重复) phone VARCHAR(20) UNIQUE #DEFAULT 设置默认值 gender ENUM('男','女') DEFAULT '男' #COMMENT 字段注释(方便理解字段含义) #创建表 user1 CREATE TABLE `test`.`Untitled` ( `ID` int UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '编号', `name` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '姓名\r\n', `age` int NOT NULL COMMENT '年龄', `gender` enum('男','女','未知') CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '性别', `home add` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '家庭住址', `phone number` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '电话号码', `hobby` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '爱好', `mailbox` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL COMMENT '邮箱', PRIMARY KEY (`ID` DESC) USING BTREE ) #查看创表语句 show create table user1 ; CREATE TABLE `user1` ( `ID` int unsigned NOT NULL AUTO_INCREMENT COMMENT '编号', `name` varchar(32) NOT NULL COMMENT '姓名\r\n', `age` int NOT NULL COMMENT '年龄', `gender` enum('男','女','未知') NOT NULL COMMENT '性别', `home add` varchar(255) DEFAULT NULL COMMENT '家庭住址', `phone number` varchar(11) DEFAULT NULL COMMENT '电话号码', `hobby` varchar(255) DEFAULT NULL COMMENT '爱好', `mailbox` varchar(255) DEFAULT NULL COMMENT '邮箱', PRIMARY KEY (`ID` DESC) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci #查看表结构 mysql> desc user1; +--------------+----------------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +--------------+----------------------------+------+-----+---------+----------------+ | ID | int unsigned | NO | PRI | NULL | auto_increment | | name | varchar(32) | NO | | NULL | | | age | int | NO | | NULL | | | gender | enum('男','女','未知') | NO | | NULL | | | home add | varchar(255) | YES | | NULL | | | phone number | varchar(11) | YES | | NULL | | | hobby | varchar(255) | YES | | NULL | | | mailbox | varchar(255) | YES | | NULL | | +--------------+----------------------------+------+-----+---------+----------------+ #Field 字段(列名):字母、数字、下划线,不要和mysql关键字冲突,不要有特殊符号和字符 #Type 数据类型:数字类型、字符类型、日期时间类型、二进制数据、json等···· #Null 是否可为空:YES 可为空,NO不能为空,Not Null #Key 键:主键、外键、唯一 #Default 默认值:在insert时,没有设置内容时,自动添加到内容 #Extra 扩展:例如auto_increment (自动增长) - 查看表结构:
约束条件
用于限制列中存储的数据
## 行级约束
#1.无符号,数字没有负数,仅用于数值类型(如 INT、FLOAT)
unsigned
#示例:
age INT UNSIGNED -- 年龄不能为负数
#2.非空约束,数据不能为空,强制字段必须填写值,不能为 NULL(空值)。
not null
#示例:
name VARCHAR(50) NOT NULL -- 姓名不能为空
#3.主键约束(主关键字),不能为空,不能重复,只能有一个主键或一个联合主键。
primary key
#示例:
id INT PRIMARY KEY -- 单个字段为主键
-- 或联合主键(表级约束写法)
PRIMARY KEY (student_id, course_id) -- 学生ID+课程ID联合唯一标识一条选课记录
#4.唯一约束、唯一索引,确保字段值在表中唯一,但允许为 NULL(且多个 NULL 不冲突)。与主键的区别:一张表可以有多个唯一约束,且不强制非空。常用于 “不能重复但可空” 的字段(如手机号、邮箱,允许用户不填,但填了就不能重复)。
unique
#示例:
phone VARCHAR(20) UNIQUE -- 手机号唯一,可空
#5.外键约束
#主表:被从表(包含外键的表)通过主键关联。
#用于多表关联,用于关联两个表,确保从表(子表)的字段值必须在主表(父表)的关联字段中存在。作用:保证数据一致性(如 “订单表” 的 user_id 必须在 “用户表” 中存在,避免无效的用户 ID)。
foreign key
#示例(订单表关联用户表):
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
-- 外键约束:orders表【从表】的user_id关联users表【主表】的id
FOREIGN KEY (user_id) REFERENCES users(id)
);
#6.外键的级联操作(可选)
#默认情况下,父表的记录被子表关联时不允许删除 / 修改。但可通过级联规则设置关联操作:
ON DELETE CASCADE:删除父表记录时,自动删除子表中关联的记录(如删除用户时,自动删除其所有订单)。
ON UPDATE CASCADE:更新父表主键时,自动更新子表中关联的外键值(如用户 ID 变更时,订单中的用户 ID 同步变更)。
#示例(添加级联删除):
CREATE TABLE order (
order_id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
FOREIGN KEY (user_id) REFERENCES user(id) ON DELETE CASCADE -- 级联删除
);
## 表级约束
#1.数据库查询MySQL8引擎默认为InnoDB(支持事务,安全性高)
engine
#示例:
CREATE TABLE user (
id INT PRIMARY KEY
) ENGINE=InnoDB; -- 指定存储引擎为InnoDB
#2.设置字符集
charset
#示例:
CREATE TABLE user (
name VARCHAR(50)
) CHARSET=utf8mb4; -- 字符集设为utf8mb4
#3.设置字符排序规则,决定字符串的比较和排序规则(如大小写是否敏感、中文排序方式)。与 charset 配套使用,utf8mb4 常见规则:
#utf8mb4_general_ci:通用排序,不区分大小写(默认)。
#utf8mb4_bin:二进制排序,区分大小写(如 'A' 和 'a' 视为不同)。
collate
#示例:
CREATE TABLE user (
name VARCHAR(50)
) CHARSET=utf8mb4 COLLATE=utf8mb4_bin; -- 区分大小写排序
## 其他条件
#1. 自动增长.用于数值类型字段(通常是主键),插入数据时自动生成唯一的递增数值(默认从 1 开始,每次 + 1)。避免手动输入主键,确保唯一性。
auto_increment
#示例:
id INT PRIMARY KEY AUTO_INCREMENT -- 插入时无需指定id,自动生成1、
#2.检测约束
#作用
#限制列中值的范围或条件(MySQL 8.0.16 及以上版本支持 ),用于确保列数据符合特定业务规则 ,比如示例中保证工资字段值大于 0 。
check
#示例
CREATE TABLE employees (
id INT PRIMARY KEY,
salary DECIMAL(10,2) CHECK (salary > 0) -- 工资必须大于 0
);
#3.设置默认值
default
#示例:
gender ENUM('男','女','保密') DEFAULT '保密' -- 未填性别时默认“保密”
#4.设置行或表的备注
comment
#示例:
CREATE TABLE student (
id INT PRIMARY KEY COMMENT '学生唯一ID',
age INT COMMENT '年龄(1-150)'
) COMMENT '存储学生基本信息的表'; -- 表注释
数据完整性(Data Integrity)
完整性指数据库中的数据符合预定规则,不存在无效或错误信息,主要分为四类:
- 实体完整性
确保表中每条记录都是唯一且可识别的,通过主键和唯一约束实现(如学生表中“学号”唯一)。
- 域完整性
确保列中数据符合特定格式或范围,通过数据类型、非空约束、检查约束等实现(如“年龄”必须是正整数)。
- 参照完整性
确保多表之间的 关联关系 合法,通过外键实现(如成绩表的学生必须在学生表中存在)。
- 用户定义完整性
根据业务需求自定义的规则(如“订单金额必须大于0”),可通过CHECK约束或触发器实现。
唯一性(Uniqueness)
唯一性是指表中某个字段的值不允许重复,主要通过两种方式实现:
- 主键(PRIMARY KEY)
- 不仅要求唯一,还不允许NULL,一个表只能有一个主键。
- 示例:id INT PRIMARY KEY
- 唯一约束(UNIQUE)
- 仅要求值唯一,允许NULL(但最多一个NULL),一个表可以有多个唯一约束。
- 示例:email VARCHAR(100) UNIQUE
- 区别:主键是“唯一标识记录”,唯一约束是“确保字段值不重复”,主键本质上是一种特殊的唯一约束(加非空限制)。
总结
- 约束条件是保障数据规则的“工具集”(主键、外键、非空等);
- 外键是约束的一种,专门用于维护表之间的关联关系;
- 完整性是数据符合规则的“状态”(实体、域、参照等维度);
- 唯一性是数据的“属性”,确保字段值不重复(通过主键或唯一约束实现)。
合理使用这些机制,能有效保证数据库数据的准确性、一致性和可靠性。
-
删除表:drop table 表名 ;
-
修改表的结构:alter
### 修改表名
alter table 原始表名 rename to 新的表名;
### 修改字段名和字段类型
> 修改列的属性:change,modify
alter table 表名 change birthday【旧的字段名】 b_day【新的字段名】 date【类型】;
alter table 表名 change b_day【字段名】 b_day【字段名】 datetime【类型】;
### 添加新的字段
alter table 表名 add phone【字段名】 char(11)【类型】;
> 如果你需要指定新增字段的位置,关键字 FIRST (设定位第一列), AFTER 字段名(设定位于某个字段之后)
alter table 表名 add address【字段名称】 varchar(64)【类型】 after name;
### 删除已有的字段
alter table 表名 drop phone【字段名】;
数据类型
- 作用:对数据进行分类,对相同类型的数据给予相同大小的存储空间。
- 分类:整数、浮点数、字符串、时间日期
1.整数类型
| 类型 | 字节 | 范围(有符号) | 范围(无符号) |
|---|---|---|---|
| tinyint | 1 | (-128,127) | (0,255) |
| smallint | 2 | (-32768,32767) | (0,65535) |
| mediumint | 3 | (-8388608,8388607) | (0,16777215) |
| int | 4 | (-2147483 648,2147483647) | (0,4294967295) |
| bigint | 8 | (-9223372036854775808,9223372036854775807) | (0,18446744073709551615) |
2.浮点数和定点数
| 类型 | 大小 | 用途 |
|---|---|---|
| float | 4字节 (小数位过多时不精确,会自动四舍五入) | 单精度浮点数值 |
| double | 8字节 (相对float精确一些) | 双精度浮点数值 |
| decimal | 对decimal(M总长度,D小数长度) ,M>D ,例如:decimal(6,2) 1000.00 decimal是以字符串的方式来存储数字的。 | 小数值 |
3.日期时间
| 类型 | 字节 | 范围 | 格式 | 用途 |
|---|---|---|---|---|
| date | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| time | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| year | 1 | 1901/2155 | YYYY | 年份值 |
| datetime | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| timestamp(时间戳) | 4 | 1970-01-01 00:00:00/2038 结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 | YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
4.字符串类型
| 类型 | 字节 | 用途 |
|---|---|---|
| char(n) | 0-255字节 | 定长字符串,有可能浪费存储空间,但查询效率高,适合存储手机号,身份证号 |
| varchar(n) | 0-65535 字节 | 变长字符串,节约空间,性能不如char,适合存储姓名、密码、地址、简介、标题、短文 |
| tinyblob | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| tinytext | 0-255字节 | 短文本字符串 |
| blob | 0-65 535字节 | 二进制形式的长文本数据 |
| text | 0-65 535字节 | 长文本数据,普通文本,评论,短文 |
| mediumblob | 0-16 777 215字节 | 二进制形式的中等长度文本数据 |
| mediumtext | 0-16 777 215字节 | 中等长度文本数据 |
| longblob | 0-4 294 967 295字节 | 二进制形式的极大文本数据 |
| longtext | 0-4 294 967 295字节 | 极大文本数据,;例如:一本书 |
添加数据 insert
#关键规则:
#字符串类型(如 varchar)的值必须用英文单引号 ' 或双引号 " 包裹。
#所有标点(逗号、分号等)必须用英文格式。
#数值类型(如 int)的值直接写数字,无需加引号。
insert into 表名(列1,列2,....) values(值1,值2...);
insert into 数据库名.表格名(列1,列2,....) values(值1,值2...);
insert into student(id,name,sex,b_day) value(1,'武大郎','男','2000-1-1');
insert into student(id,name,sex,b_day) value(2,'王小二','男','2002-2-2');
insert into student(id,name,sex,b_day) value(3,'张三','男','2003-3-3');
insert into student(id,name,sex,b_day) value(4,'李四','男','2004-4-4');
insert into student(id,name,sex,b_day) value(5,'武则天','女','2005-5-5');
insert into student(id,name,sex,b_day) value(6,'慈禧','女','2006-6-6');
### 查看user表中的信息
#查看表中的所有信息,按数据的存储顺序返回。
select * from user【表名】;#【* 表示所有信息】
#查看某列的内容
select name,sex【列名-多个列名使用逗号隔开】 from student【表名】;
#如需按 ID 升序(1→2→3→4)显示,可添加排序语句:
SELECT * FROM user1 ORDER BY ID ASC; -- ASC 表示升序(默认可省略)
#若需按 ID 降序(4→3→2→1)明确排序:
SELECT * FROM user1 ORDER BY ID DESC; --DESC 表示降序
修改语句 update
修改更新表中已有的数据
## 修改语句必须要加where条件,否则会更新所有行的数据。
update user1【表名】 set gender='女'【修改内容】 where ID=1【条件】;
#关键规则:
#1.WHERE 条件是 “安全开关”
#必须明确添加 WHERE 子句指定更新范围(如 WHERE ID=1),否则会无条件更新表中所有行(比如 UPDATE user1 set gender='女' 会把所有用户的性别改成女)。
#建议用唯一标识字段(如 ID)作为条件,确保只更新目标行(ID 通常是主键,具有唯一性)。
#2.字段名与表名规范
#表名(user1)和列名(gender)需准确,若包含特殊字符(如空格、中文)需用反引号 ` 包裹(如 `home add`)。
#3.字符串值需加引号
#非数值类型的值(如 '女')必须用英文单引号 '' 包裹,数值类型(如 ID=1 中的 1)直接写数字。
#4.执行前建议先查询验证
#更新前先用 SELECT 语句确认条件匹配的行数(如 SELECT * FROM user1 WHERE ID=1),避免误改。
#5.事务保护(重要操作)
#对重要数据更新,可开启事务(BEGIN;),执行后检查结果,确认正确再提交(COMMIT;),错误则回滚(ROLLBACK;):
BEGIN; -- 开启事务
UPDATE user1 set gender='女' where ID=1;
SELECT * FROM user1 WHERE ID=1; -- 验证
COMMIT; -- 确认无误后提交
-- 若错误,执行 ROLLBACK; 撤销操作
删除语句 delete
根据条件删除表中的数据
##删除数据必须要加where条件,否则会删除所有行的数据。
delete from user1【表名】 where id=6【条件】;
# 清空`score`表所有数据(保留表结构)
delete from score【表名】 ;
#truncate (高效,适合清空整个表)
TRUNCATE TABLE score;
安全模式
# mysql安全模式sql_safe_updates是为了防止我们在操作表时的误操作,把全表删除了或者更新了。
# 检查是否开启
mysql> show variables like 'sql_safe_updates';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| sql_safe_updates | OFF |
+------------------+-------+
# 开启安全模式
set sql_safe_updates = 1;
# 关闭安全模式
set sql_safe_updates = 0;
# 自动启动安全模式
vim /etc/my.cnf
# 在[mysqld]下配置一个
init-file=/usr/local/mysql/init-file.sql
vim /usr/local/mysql/init-file.sql
# 在sql脚本文件中添加下列语句
set global sql_safe_updates=1;
# 重启MySQL服务
systemctl restart mysqld
# 开启安全模式后的限制有哪些
1. update语句必须满足如下条件之一才能执行成功
1)使用where子句,并且where子句中列必须为索引列
2)使用limit
3)同时使用where子句和limit(此时where子句中列可以不是索引列)
2. delete语句必须满足如下条件之一才能执行成功
1)使用where子句,并且where子句中列必须为索引列
2)同时使用where子句和limit(此时where子句中列可以不是索引列)
8.DQL数据查询语句
常见的查询条件
#查看表中的所有信息,按数据的存储顺序返回。
select * from user【表名】;#【* 表示所有信息】
#查看某列的内容
select name,sex【列名-多个列名使用逗号隔开】 from student【表名】;
#如需按 ID 升序(1→2→3→4)显示,可添加排序语句:
SELECT * FROM user1 ORDER BY ID ASC; -- ASC 表示升序(默认可省略)
#若需按 ID 降序(4→3→2→1)明确排序:
SELECT * FROM user1 ORDER BY ID DESC; --DESC 表示降序
比较查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 基础比较 | = |
等于 | SELECT * FROM users【表名】 WHERE gender = '男'【条件】; |
!=/<> |
不等于 | SELECT * FROM products【表名】 WHERE category != '服装'【条件】; |
|
>/< |
大于/小于 | SELECT * FROM orders【表名】 WHERE total_amount > 2000【条件】; |
|
>=/<= |
大于等于/小于等于 | SELECT * FROM users【表名】 WHERE age <= 30【条件】; |
select * from users where gender='男';
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 1 | 张三 | 28 | 男 | 北京 | 2023-01-15 09:30:00 |
| 3 | 王五 | 35 | 男 | 广州 | 2023-03-05 10:00:00 |
| 5 | 孙七 | 42 | 男 | 深圳 | 2023-05-10 11:20:00 |
+----+----------+------+--------+--------+---------------------+
-----------------------------------------------------------
select * from users where gender='男';
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 1 | 张三 | 28 | 男 | 北京 | 2023-01-15 09:30:00 |
| 3 | 王五 | 35 | 男 | 广州 | 2023-03-05 10:00:00 |
| 5 | 孙七 | 42 | 男 | 深圳 | 2023-05-10 11:20:00 |
+----+----------+------+--------+--------+---------------------+
-----------------------------------------------------------
select * from orders where total_amount > 2000 ;
+----+---------+------------+----------+--------------+-----------+---------------------+
| id | user_id | product_id | quantity | total_amount | status | create_time |
+----+---------+------------+----------+--------------+-----------+---------------------+
| 1 | 1 | 1 | 1 | 5999.00 | 已完成 | 2023-06-01 10:30:00 |
| 4 | 3 | 2 | 1 | 6999.00 | 已发货 | 2023-06-20 11:20:00 |
| 6 | 5 | 1 | 1 | 5999.00 | 已取消 | 2023-06-18 14:00:00 |
+----+---------+------------+----------+--------------+-----------+---------------------+
-----------------------------------------------------------
select * from users where age >= 30 ;
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 3 | 王五 | 35 | 男 | 广州 | 2023-03-05 10:00:00 |
| 5 | 孙七 | 42 | 男 | 深圳 | 2023-05-10 11:20:00 |
+----+----------+------+--------+--------+---------------------+
范围查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 范围匹配 | BETWEEN ... AND ... |
在指定范围内(包含边界) | SELECT * FROM products【表名】 WHERE price【字段名】 BETWEEN 500 AND 5000【范围】; |
IN (...) |
匹配列表中的任意值 | SELECT * FROM users【表名】 WHERE city【字段名】 IN ('广州', '深圳')【查询值】; |
|
NOT IN (...) |
不匹配列表中的值 | SELECT * FROM orders WHERE status NOT IN ('已取消', '待付款'); |
select * from products where price between 500 and 5000 ;
+----+---------------+----------+--------+-------+
| id | name | category | price | stock |
+----+---------------+----------+--------+-------+
| 4 | Nike运动鞋 | 服装 | 699.00 | 80 |
+----+---------------+----------+--------+-------+
-----------------------------------------------------------
select * from users where city in('广州','深圳') ;
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 3 | 王五 | 35 | 男 | 广州 | 2023-03-05 10:00:00 |
| 5 | 孙七 | 42 | 男 | 深圳 | 2023-05-10 11:20:00 |
+----+----------+------+--------+--------+---------------------+
-----------------------------------------------------------
select * from users where city not in('广州','深圳') ;
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 1 | 张三 | 28 | 男 | 北京 | 2023-01-15 09:30:00 |
| 2 | 李四 | 22 | 女 | 上海 | 2023-02-20 14:15:00 |
| 4 | 赵六 | 19 | 女 | 北京 | 2023-04-18 16:45:00 |
+----+----------+------+--------+--------+---------------------+
模糊查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 模糊查询 | LIKE |
模糊匹配,%匹配任意字符,_匹配单个字符 |
SELECT * FROM products WHERE name LIKE '华为%'; |
| 案例: ‘张%’--以张开头大内容 ; ‘%张’--以张结尾的内容 ; ‘%张%’--包含张的内容 ; | SELECT * FROM users WHERE username LIKE '_三%'; |
select * from products where name like '华为%' ;
+----+----------------+----------+---------+-------+
| id | name | category | price | stock |
+----+----------------+----------+---------+-------+
| 2 | 华为MateBook | 电脑 | 6999.00 | 30 |
+----+----------------+----------+---------+-------+
-----------------------------------------------------------
select * from users where username like '_三%';
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 1 | 张三 | 28 | 男 | 北京 | 2023-01-15 09:30:00 |
+----+----------+------+--------+--------+---------------------+
空值判断查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 空值判断 | IS NULL |
字段值为NULL | SELECT * FROM users WHERE age IS NULL; |
IS NOT NULL |
字段值不为NULL | SELECT * FROM products WHERE stock IS NOT NULL; |
select * from users where age is not null ;
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 1 | 张三 | 28 | 男 | 北京 | 2023-01-15 09:30:00 |
| 2 | 李四 | 22 | 女 | 上海 | 2023-02-20 14:15:00 |
| 3 | 王五 | 35 | 男 | 广州 | 2023-03-05 10:00:00 |
| 4 | 赵六 | 19 | 女 | 北京 | 2023-04-18 16:45:00 |
| 5 | 孙七 | 42 | 男 | 深圳 | 2023-05-10 11:20:00 |
+----+----------+------+--------+--------+---------------------+
逻辑组合查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 逻辑组合 | AND |
同时满足多个条件 | SELECT * FROM orders WHERE status = '已完成' AND quantity > 1; |
OR |
满足任意一个条件 | SELECT * FROM users WHERE age < 20 OR gender = '未知'; |
|
NOT |
条件取反 | SELECT * FROM products WHERE NOT price < 100; |
select * from orders where status = '已完成' and quantity > 1 ;
+----+---------+------------+----------+--------------+-----------+---------------------+
| id | user_id | product_id | quantity | total_amount | status | create_time |
+----+---------+------------+----------+--------------+-----------+---------------------+
| 2 | 1 | 3 | 2 | 398.00 | 已完成 | 2023-06-15 15:45:00 |
| 8 | 3 | 5 | 2 | 598.00 | 已完成 | 2023-06-08 13:25:00 |
+----+---------+------------+----------+--------------+-----------+---------------------+
-----------------------------------------------------------
select * from users where age < 20 or gender = '未知' ;
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 4 | 赵六 | 19 | 女 | 北京 | 2023-04-18 16:45:00 |
+----+----------+------+--------+--------+---------------------+
-----------------------------------------------------------
select * from products where not price < 100 ;
+----+----------------+--------------+---------+-------+
| id | name | category | price | stock |
+----+----------------+--------------+---------+-------+
| 1 | iPhone 14 | 手机 | 5999.00 | 50 |
| 2 | 华为MateBook | 电脑 | 6999.00 | 30 |
| 3 | 小米手环 | 智能设备 | 199.00 | 100 |
| 4 | Nike运动鞋 | 服装 | 699.00 | 80 |
| 5 | 机械键盘 | 电脑配件 | 299.00 | 60 |
+----+----------------+--------------+---------+-------+
聚合函数查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 聚合筛选 | HAVING |
对分组结果筛选(需配合GROUP BY) | SELECT user_id, SUM(total_amount) FROM orders GROUP BY user_id HAVING SUM(total_amount) > 5000; |
聚合函数
SUM():计算指定列的总和,一般用于数值类型的列。
SELECT SUM(score) FROM student_score;
AVG():计算指定列的平均值,同样适用于数值类型列。
SELECT AVG(score) FROM student_score;
COUNT():统计符合条件的行数。可以用来统计学生人数。
SELECT COUNT(*) FROM students;
MAX():返回指定列的最大值。
SELECT MAX(score) FROM student_score;
MIN():返回指定列的最小值。
SELECT MIN(score) FROM student_score;
分组查询
# group by
#根据城市分组,统计每个城市有多少人
select city,count(city) from users group by city ;
+--------+-------------+
| city | count(city) |
+--------+-------------+
| 北京 | 2 |
| 上海 | 1 |
| 广州 | 1 |
| 深圳 | 1 |
+--------+-------------+
#,这个查询的作用是:统计每个用户的订单总金额,并且只显示总金额超过 5000 的用户记录。
#GROUP BY:用于对查询结果进行分组。
#HAVING:用于对分组后的结果进行筛选(类似于WHERE,但HAVING用于分组后,可配合聚合函数)。
select user_id,sum(total_amount) from orders group by user_id having sum(total_amt)ount) > 5000 ;
+---------+-------------------+
| user_id | sum(total_amount) |
+---------+-------------------+
| 1 | 6397.00 |
| 3 | 7597.00 |
| 5 | 5999.00 |
+---------+-------------------+
#子查询+NOT IN:查询没选课程1的学生ID
# NOT IN 关键字表示 “不在子查询结果集中”
select distinct student_id from score where student_id not in(select student_id from score where course_id=1);
+------------+
| student_id |
+------------+
| 4 |
+------------+
子查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 子查询相关 | EXISTS |
子查询有结果则成立 | SELECT * FROM users WHERE EXISTS (SELECT 1 FROM orders WHERE user_id = users.id); |
NOT EXISTS |
子查询无结果则成立 | SELECT * FROM products WHERE NOT EXISTS (SELECT 1 FROM orders WHERE product_id = products.id); |
子查询:也叫嵌套查询,一般把一个select 查询的结果作为另一个select 的查询条件。
#通过“张三”名字找到其所有的订单。
select * from orders where user_id in(select id from users where username="张三");
+----+---------+------------+----------+--------------+-----------+---------------------+
| id | user_id | product_id | quantity | total_amount | status | create_time |
+----+---------+------------+----------+--------------+-----------+---------------------+
| 1 | 1 | 1 | 1 | 5999.00 | 已完成 | 2023-06-01 10:30:00 |
| 2 | 1 | 3 | 2 | 398.00 | 已完成 | 2023-06-15 15:45:00 |
+----+---------+------------+----------+--------------+-----------+---------------------+
# 子查询+ANY:查询分数高于课程1中任何一个分数的记录
# ANY 关键字表示 “满足子查询结果中的任意一个条件即可”。
select * from score where score > any (select score from score where course_id =1);
+----+------------+-----------+-------+
| id | student_id | course_id | score |
+----+------------+-----------+-------+
| 1 | 1 | 1 | 85 |
| 2 | 2 | 1 | 100 |
| 3 | 1 | 2 | 90 |
| 5 | 4 | 2 | 95 |
+----+------------+-----------+-------+
#子查询+ALL:查询分数高于课程2中所有分数的记录
# ALL 关键字表示 “满足子查询结果中的所有条件”,即主查询的 score 必须大于子查询返回的每一个成绩。
select * from score where score > all (select score from score where course_id =
2) ;
+----+------------+-----------+-------+
| id | student_id | course_id | score |
+----+------------+-----------+-------+
| 2 | 2 | 1 | 100 |
+----+------------+-----------+-------+
#子查询+CASE:查询学生姓名及是否及格
# CASE 表达式
CASE 表达式
WHEN 值1 THEN 结果1
WHEN 值2 THEN 结果2
...
ELSE 默认结果 -- 可选,不满足任何条件时返回
END
select
name ,
(case when sc.score >=60 then '及格' else '不及格' end ) as '是否及格'
from student s left join score sc on s.id = sc.student_id ;
+--------+--------------+
| name | 是否及格 |
+--------+--------------+
| 周八 | 不及格 |
| 孙七 | 不及格 |
| 张三 | 及格 |
| 张三 | 及格 |
| 李四 | 及格 |
| 王五 | 及格 |
| 赵六 | 及格 |
+--------+--------------+
去重查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 去重 | DISTINCT |
筛选唯一值 | SELECT DISTINCT city FROM users; |
#没有去重前的查询
select city from users ;
+--------+
| city |
+--------+
| 北京 |
| 上海 |
| 广州 |
| 北京 |
| 深圳 |
+--------+
#去重后的查询
select distinct city from users ;
+--------+
| city |
+--------+
| 北京 |
| 上海 |
| 广州 |
| 深圳 |
+--------+
排序查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 排序 | ORDER BY 字段 ASC |
按指定字段升序排列(默认) | SELECT * FROM products ORDER BY price ASC; |
ORDER BY 字段 DESC |
按指定字段降序排列 | SELECT * FROM orders ORDER BY create_time DESC; |
|
| 多字段排序 | 先按第一个字段排,再按第二个字段排 | SELECT * FROM users ORDER BY city ASC, age DESC; |
#按价格升序来排序
select * from products order by price ASc ;
+----+----------------+--------------+---------+-------+
| id | name | category | price | stock |
+----+----------------+--------------+---------+-------+
| 3 | 小米手环 | 智能设备 | 199.00 | 100 |
| 5 | 机械键盘 | 电脑配件 | 299.00 | 60 |
| 4 | Nike运动鞋 | 服装 | 699.00 | 80 |
| 1 | iPhone 14 | 手机 | 5999.00 | 50 |
| 2 | 华为MateBook | 电脑 | 6999.00 | 30 |
+----+----------------+--------------+---------+-------+
#按价格降序来排序
select * from products order by price desc ;
+----+----------------+--------------+---------+-------+
| id | name | category | price | stock |
+----+----------------+--------------+---------+-------+
| 2 | 华为MateBook | 电脑 | 6999.00 | 30 |
| 1 | iPhone 14 | 手机 | 5999.00 | 50 |
| 4 | Nike运动鞋 | 服装 | 699.00 | 80 |
| 5 | 机械键盘 | 电脑配件 | 299.00 | 60 |
| 3 | 小米手环 | 智能设备 | 199.00 | 100 |
+----+----------------+--------------+---------+-------+
#从 users 表中查询所有用户的完整信息,先按 city(城市)升序排序,同一城市的用户再按 age(年龄)降序排序。
select * from users order by city asc ,age desc ;
+----+----------+------+--------+--------+---------------------+
| id | username | age | gender | city | register_time |
+----+----------+------+--------+--------+---------------------+
| 2 | 李四 | 22 | 女 | 上海 | 2023-02-20 14:15:00 |
| 1 | 张三 | 28 | 男 | 北京 | 2023-01-15 09:30:00 |
| 4 | 赵六 | 19 | 女 | 北京 | 2023-04-18 16:45:00 |
| 3 | 王五 | 35 | 男 | 广州 | 2023-03-05 10:00:00 |
| 5 | 孙七 | 42 | 男 | 深圳 | 2023-05-10 11:20:00 |
+----+----------+------+--------+--------+---------------------+
分页查询
| 条件类型 | 运算符/关键字 | 描述说明 | 示例代码 |
|---|---|---|---|
| 分页 | LIMIT 条数 |
只返回前N条记录 | SELECT * FROM products ORDER BY price DESC LIMIT 5; |
LIMIT 起始位置, 条数 |
从指定位置开始返回N条记录(起始从0开始) | SELECT * FROM orders ORDER BY id LIMIT 10, 5; -- 第11-15条记录 |
|
| 分页公式 | 第N页(每页M条):LIMIT(N-1)*M,M |
SELECT * FROM users LIMIT 20, 10; -- 第3页,每页10条 |
#查询 products 表中价格最高的前 5 条商品记录,结果按价格从高到低排序
select * from products order by price desc limit 5 ;
+----+----------------+--------------+---------+-------+
| id | name | category | price | stock |
+----+----------------+--------------+---------+-------+
| 2 | 华为MateBook | 电脑 | 6999.00 | 30 |
| 1 | iPhone 14 | 手机 | 5999.00 | 50 |
| 4 | Nike运动鞋 | 服装 | 699.00 | 80 |
| 5 | 机械键盘 | 电脑配件 | 299.00 | 60 |
| 3 | 小米手环 | 智能设备 | 199.00 | 100 |
+----+----------------+--------------+---------+-------+
#从 orders 表中查询第 3-4 条订单记录 并 按 id 升序排列
SELECT * from orders order by id limit 2 ,2 ;
+----+---------+------------+----------+--------------+-----------+---------------------+
| id | user_id | product_id | quantity | total_amount | status | create_time |
+----+---------+------------+----------+--------------+-----------+---------------------+
| 3 | 2 | 4 | 1 | 699.00 | 已完成 | 2023-06-05 09:15:00 |
| 4 | 3 | 2 | 1 | 6999.00 | 已发货 | 2023-06-20 11:20:00 |
+----+---------+------------+----------+--------------+-----------+---------------------+
关键说明:
-
排序(ORDER BY):
- 必须放在
WHERE之后,LIMIT之前 - 可指定多个排序字段,用逗号分隔
- 字符串按字典顺序排序,日期按时间先后排序
- 必须放在
-
分页(LIMIT):
- 语法格式:
LIMIT [offset,] row_count,offset可选(默认0) - 分页查询通常需要配合
ORDER BY使用,否则分页结果可能不稳定 - 计算第N页数据(每页显示M条)的公式:
LIMIT (N-1)*M, M
- 语法格式:
-
组合使用:
实际场景中经常组合多种条件,例如:-- 分页查询价格100-1000元的"智能设备",按价格降序,取第2页(每页5条) SELECT * FROM products WHERE category = '智能设备' AND price BETWEEN 100 AND 1000 ORDER BY price DESC LIMIT 5, 5;
9.SQL复杂查询
多表连接查询
连接查询:join ··· on
连接查询用于根据表之间的关联关系(通常是外键)从多个表中获取数据。
内连接
# AS 起别名, 可以省略
#定义:只返回两个表中满足连接条件的共有记录,即两表的 “交集” 部分。
#语法:表1 INNER JOIN 表2 ON 连接条件; -- INNER 可省略,简写为 JOIN
#查询所有订单的用户和商品信息
select o.id as 订单ID ,u.username as 用户名 ,p.name as 商品名称 , o.total_amount as 总金额
from orders o
inner join users u on o.user_id = u.id
inner join products p on o.product_id = p.id ;
+----------+-----------+----------------+-----------+
| 订单ID | 用户名 | 商品名称 | 总金额 |
+----------+-----------+----------------+-----------+
| 1 | 张三 | iPhone 14 | 5999.00 |
| 2 | 张三 | 小米手环 | 398.00 |
| 3 | 李四 | Nike运动鞋 | 699.00 |
| 7 | 李四 | 小米手环 | 199.00 |
| 4 | 王五 | 华为MateBook | 6999.00 |
| 8 | 王五 | 机械键盘 | 598.00 |
| 5 | 赵六 | 机械键盘 | 299.00 |
| 6 | 孙七 | iPhone 14 | 5999.00 |
+----------+-----------+----------------+-----------+
# 笛卡尔查询(交叉连接): 将所有表中的所有内容都会排列组合一次,不加关联条件时会产生。
select o.id as 订单ID ,u.username as 用户名 ,p.name as 商品名称 , o.total_amount as 总金额
from orders o
inner join users u
inner join products p ;
# 对关联的结果,进行查询
SELECT
o.id AS 订单ID,
u.username AS 用户名,
p.name AS 商品名称,
o.quantity AS 购买数量,
o.total_amount AS 总金额,
o.create_time AS 下单时间
FROM orders o
INNER JOIN users u ON o.user_id = u.id
INNER JOIN products p ON o.product_id = p.id
WHERE o.status = '已完成'
ORDER BY o.create_time DESC;
+----------+-----------+---------------+--------------+-----------+---------------------+
| 订单ID | 用户名 | 商品名称 | 购买数量 | 总金额 | 下单时间 |
+----------+-----------+---------------+--------------+-----------+---------------------+
| 2 | 张三 | 小米手环 | 2 | 398.00 | 2023-06-15 15:45:00 |
| 7 | 李四 | 小米手环 | 1 | 199.00 | 2023-06-10 10:00:00 |
| 8 | 王五 | 机械键盘 | 2 | 598.00 | 2023-06-08 13:25:00 |
| 3 | 李四 | Nike运动鞋 | 1 | 699.00 | 2023-06-05 09:15:00 |
| 1 | 张三 | iPhone 14 | 1 | 5999.00 | 2023-06-01 10:30:00 |
+----------+-----------+---------------+--------------+-----------+---------------------+
外连接
- 左(外)连接(LEFT JOIN)
返回左表【主表】所有记录,以及右表【从表】中匹配条件的记录(右表无匹配时显示NULL)。
#查询所有用户及其订单情况(包括没有订单的用户)
SELECT
u.username AS 用户名,
COUNT(o.id) AS 订单数,
IFNULL(SUM(o.total_amount), 0) AS 总消费
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id, u.username;
+-----------+-----------+-----------+
| 用户名 | 订单数 | 总消费 |
+-----------+-----------+-----------+
| 张三 | 2 | 6397.00 |
| 李四 | 2 | 898.00 |
| 王五 | 2 | 7597.00 |
| 赵六 | 1 | 299.00 |
| 孙七 | 1 | 5999.00 |
+-----------+-----------+-----------+
- 右(外)连接(RIGHT JOIN)
与左连接相反,返回右表所有记录,以及左表中匹配条件的记录。
#查询所有商品及其被购买情况(包括未被购买的商品)
SELECT
p.name AS 商品名称,
IFNULL(SUM(o.quantity), 0) AS 销售总量
FROM orders o
RIGHT JOIN products p ON o.product_id = p.id
GROUP BY p.id, p.name;
+----------------+--------------+
| 商品名称 | 销售总数 |
+----------------+--------------+
| iPhone 14 | 2 |
| 华为MateBook | 1 |
| 小米手环 | 3 |
| Nike运动鞋 | 1 |
| 机械键盘 | 3 |
+----------------+--------------+
自连接(SELF JOIN)
将表与自身进行连接,通常用于处理表中存在层级关系或关联关系的数据。
#查询和"张三"同城市的用户
select u2.username ,u2.city
from users u1
join users u2 on u1.city=u2.city
where u1.username='张三' and u2.username!='张三';
+----------+--------+
| username | city |
+----------+--------+
| 赵六 | 北京 |
+----------+--------+
联合查询(UNION)
联合查询用于将多个SELECT语句的结果集合并为一个结果集,要求各查询的列数和数据类型必须一致。
- union:合并结果集并自动去除重复记录。
#查询价格低于200的商品和年龄小于25的用户
SELECT '商品' AS 类型, name AS 名称, '价格低' AS 描述
FROM products
WHERE price < 200
UNION
SELECT '用户' AS 类型, username AS 名称, '年龄小' AS 描述
FROM users
WHERE age < 25;
+--------+--------------+------------+
| 类型 | 名称 | 描述 |
+--------+--------------+------------+
| 商品 | 小米手环 | 价格低 |
| 用户 | 李四 | 年龄小 |
| 用户 | 赵六 | 年龄小 |
+--------+--------------+------------+
- union all:合并结果集但保留重复记录(效率比UNION高)。
#查询已完成和已取消的订单,区分显示
SELECT '已完成订单' AS 订单类型, id AS 订单ID, create_time AS 时间
FROM orders
WHERE status = '已完成'
UNION ALL
SELECT '已取消订单' AS 订单类型, id AS 订单ID, create_time AS 时间
FROM orders
WHERE status = '已取消'
ORDER BY 时间;
+-----------------+----------+---------------------+
| 订单类型 | 订单ID | 时间 |
+-----------------+----------+---------------------+
| 已完成订单 | 1 | 2023-06-01 10:30:00 |
| 已完成订单 | 3 | 2023-06-05 09:15:00 |
| 已完成订单 | 8 | 2023-06-08 13:25:00 |
| 已完成订单 | 7 | 2023-06-10 10:00:00 |
| 已完成订单 | 2 | 2023-06-15 15:45:00 |
| 已取消订单 | 6 | 2023-06-18 14:00:00 |
+-----------------+----------+---------------------+
连接查询与联合查询的区别
| 特性 | 连接查询(JOIN) | 联合查询(UNION) |
|---|---|---|
| 作用 | 横向关联多个表的数据 | 纵向合并多个查询的结果集 |
| 表关系 | 基于表间关联条件(如外键) | 无关联要求,但列结构需一致 |
| 结果集结构 | 列数为各表列数之和 | 列数与各查询的列数相同 |
| 使用场景 | 需要同时展示多个表的关联信息 | 需要合并多个相似结构的查询结果 |
10.MySQL权限管理
- 设置密码安全级别
# root 根用户 (超级管理员)
# 用户信息表:mysql.user
FLUSH PRIVILEGES;-- 刷新权限
INSTALL PLUGIN validate_password SONAME 'validate_password.so';-- 安装并激活密码规则插件
SHOW VARIABLES LIKE 'validate_password%';-- 进行查看密码强度
SET GLOBAL validate_password_policy = 0;-- 进行设值密码强度为低,但是密码至少8位
# 或者
SET GLOBAL validate_password_policy = LOW;
- 创建用户
## 创建新用户
CREATE USER 用户名@地址【%--代表所有地址】 IDENTIFIED BY [PASSWORD] 密码(字符串) ;
## 增加本地用户
CREATE USER 'tom'@'localhost' IDENTIFIED BY '12345678';
## 增加远程用户
CREATE USER 'tom'@'%' IDENTIFIED BY '12345678';
#MySQL中的用户由两部分组成
username 例如:root
host 例如:localhost(本机)、192.168.25.20、192.168.25.%、%
‘tom’@‘localhost’和‘tom’@‘%’ 主机名不同,不是同一个用户
#查看所有用户
select host,user from mysql.user ;
- 修改用户名
## 修改用户
RENAME USER old_user TO new_user;-- 重命名用户
RENAME USER tom TO tom2;
- 修改密码
## MySQL5版本修改密码
#root修改自己的密码
set password = password(‘密码’);
#修改其他用户的密码
set password for 'tom'@'%' = password('213456789') ;
## mysql8.0之后版本修改密码
ALTER USER 'tom'@'%' IDENTIFIED BY '12345678';
## 删除用户
DROP USER 用户名;
### 例如:
DROP USER tom2;
- 给用户设置权限
*all 除了授权之外的所有权限
*select 查询表内容的权限
*update 修改表内容的权限
*insert 在表中添加内容的权限
*delete 删除表内容的权限
grant 权限列表 on 库.表 to ‘用户名’@‘地址’ ;
#赋予tom 除了授权之外的所有权限 *.* d
grant all privileges on *.* to 'tom'@'%' ;
## 赋予zhangsan插入数据、查询数据、修改数据、删除数据的权限
grant select,update,insert,delete on *.* to 'zhangsan'@'192.168.25.%';
#赋予权限后刷新权限
FLUSH PRIVILEGES;
## 查看用户的权限
select * from mysql.user \G;
## 删除权限
REVOKE 权限列表 ON 库名.表名 FROM 用户名; -- 撤消用户的某个权限
REVOKE ALL PRIVILEGES, GRANT OPTION ON 库名.表名 FROM 用户名; -- 撤销用户的所有权限
11.MySQL备份
- 为了防止数据丢失、方便数据迁移,建议定期备份数据中的数据。
- 方式:
- 逻辑备份:将数据库中库和表转换为SQL语句,生成 .sql文件。还原数据时只需要运行该SQL语句。适合中小型规模的数据,30G以内的数据。数据量过大时,转换效率慢。
- 物理备份:将数据库的data目录,直接复制备份。
- 冷备份:关闭MySQL-Server 后进行的备份。
- 热备份:使用专业的数据备份工具,在服务运行过程中备份。
- 全量备份:每次备份都备份所有的数据。
- 增量部分(差异备份):只备份新增的数据或不一样的数据。
使用mysqldump 工具进行备份
#备份test数据库 在MySQL外执行
#备份完整的test数据库
mysqldump -uroot -p ‘root123’ test【数据库名】 > test.sql【不选路径默认当前目录内】
#还原test数据库数据
#1.在MySQL外执行的
mysql -uroot -p ‘root123’ test < test.sql
#2.在MySQL内执行的
source /root/test.sql ;
使用第三方工具备份
#使用NavicatPremium 软件进行备份
#备份
1.先远程连接上MySQL数据库
2.打开要备份的数据库
3.数据库上鼠标右键选择转储SQL文件,选择要备份去的目录
#还原
1.在数据库上鼠标右键选择执行SQL文件,找到要执行的备份文件即可
物理备份
- 冷备份:
#备份
#1.关闭数据库
systemctl stop mysql
#2.创建备份目录
mkdir -p /bak/2025/8/11
#3.拷贝data目录去备份目录
cp -r /usr/local/mysql/data/ /bak/2025/8/11
#还原
#1.关闭数据库
systemctl stop mysql
#2.删除原有的data目录
rm -rf /usr/local/mysql/data
#3.拷贝备份目录的data目录到MySQL目录
cp -r /bak/2025/8/11/data /usr/local/mysql/
#4.修改data目录的权限为mysql
chown mysql.mysql -R /usr/local/mysql/data
#5.重启服务
systemctl start mysql
-
服务热备份:
- XtraBackup :是一个对InnoDB做数据备份的工具,支持在线热备份(备份时不影响数据读写。percona免费的数据热备份工具。
- Hotbackup:收费的数据热备份工具。
安装xtrabackup软件
# 安装Percona yum存储库
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm
# 启用Percona Server 8.0存储库
percona-release enable-only tools release
percona-release setup ps80
# 安装依赖环境
yum -y install libev perl-DBD-mysql perl-Digest-MD5 epel-release
# 安装
yum -y install percona-xtrabackup-80-8.0.12
# 安装成功后测试版本
xtrabackup --version
#如果成功安装,则会显示Xtrabackup的版本信息。
#安装完成后,我们就可以使用Xtrabackup进行MySQL数据库备份和恢复操作了。
全量备份
#全量备份
#1.在备份服务器上创建一个目录,用于存储备份文件。
mkdir /bak/
#2.运行以下命令来执行完整备份:
# 全量备份,如果远程备份需要添加参数--host=IP,删除--socket参数
xtrabackup --defaults-file=/etc/my.cnf \
--user=root \
--password=root123 \
--port=3306 \
--socket=/tmp/mysql.sock \
--datadir=/usr/local/mysql/data \
--backup \
--target-dir=/bak/full
# 这将备份MySQL数据目录(/usr/local/mysql/data)到指定的目录(/bak/full )中。
--------------------------------------------------------
通用选项:
-u, --user # 数据库用户名 -u root 或 --user=root
-p, --password # 数据库密码 -p root123 或 --password=root123
-P, --port # 数据库端口号 -P 3306 或 --port=3306
-H, --host # 远程连接地址 -H 192.168.8.36 或 --host=192.168.8.36
-S, --socket # 本地数据连接 -S /tmp/mysql.sock 或 --socket=/tmp/mysql.sock
--datadir # 指定MySQL数据库数据存放路径 --datadir=/usr/local/mysql/data
备份选项:
--backup # 创建备份并且放入--target-dir目录中
--target-dir # 指定backup的目的地,如果目录不存在,xtrabakcup会创建。如果目录存在且为空则成功。不会覆盖已存在的文件。
--incremental # 创建增量备份
还原选项:
--prepare # 预处理,合并数据文件和日志文件,确保数据完整性。
--apply-log-only # 在备份还在进行准备工作时,跳过消除(undo)阶段,只执行重做(redo)阶段,从而进行增量备份
--copy-back # 将备份目录下的所有文件复制到数据库数据目录
---------------------------------------------------------
全量还原
#1.首先停止MySQL服务,并确保MySQL数据目录为空。
systemctl stop mysqld
rm -rf /usr/local/mysql/data/*
#2.合并数据文件和日志文件,确保数据完整性。
xtrabackup --prepare \
--datadir=/usr/local/mysql/data \
--target-dir=/bak/full
#3.全备的恢复
xtrabackup --copy-back \
--datadir=/usr/local/mysql/data \
--target-dir=/bak/full
#4.修复所有者和权限
chown -R mysql:mysql /usr/local/mysql/data
#5.启动MySQL
systemctl start mysqld
#6.登录测试
mysql -uroot -proot123
show databases;
增量备份
# 增量备份
mkdir /bak/{inc1,inc2}
# 第一次增量备份
xtrabackup --defaults-file=/etc/my.cnf \
--user=root \
--password=root123 \
--port=3306 \
--socket=/tmp/mysql.sock \
--datadir=/usr/local/mysql/data \
--backup \
--target-dir=/bak/inc1 \
--incremental-basedir=/bak/full
# 第二次增量备份
xtrabackup --defaults-file=/etc/my.cnf \
--user=root \
--password=root123 \
--port=3306 \
--socket=/tmp/mysql.sock \
--datadir=/usr/local/mysql/data \
--backup \
--target-dir=/bak/inc2 \
--incremental-basedir=/bak/inc1
增量还原
#1.首先停止MySQL服务,并确保MySQL数据目录为空。
systemctl stop mysqld
rm -rf /usr/local/mysql/data/*
# 增量备份的恢复,需要恢复增量备份到完全备份
## 1.准备全备
### 预处理,此选项--apply--log-only 阻止回滚未完成的事务
xtrabackup --prepare --apply-log-only --target-dir=/bak/full
## 2.将第一次增备添加到全备中
xtrabackup --prepare --apply-log-only --target-dir=/bak/full --incremental-dir=/bak/inc1
## 3.将第二次增备添加到全备中
xtrabackup --prepare --apply-log-only --target-dir=/bak/full --incremental-dir=/bak/inc2
## 4.将合并后的完备再一次准备复制到数据库目录,注意数据库目录必须为空,MySQL服务不能启动
### A.合并数据文件和日志文件,确保数据完整性。
xtrabackup --prepare \
--datadir=/usr/local/mysql/data \
--target-dir=/bak/full
### B.全备的恢复
xtrabackup --copy-back \
--datadir=/usr/local/mysql/data \
--target-dir=/bak/full
# 这将从备份中复制数据文件到MySQL数据目录,并将权限设置正确。
# 5.修复所有者和权限
chown -R mysql:mysql /usr/local/mysql/data
# 6.启动MySQL
systemctl start mysqld
#或者 /etc/init.d/mysqld start
# 7.登录测试
mysql -uroot -proot123
show databases;
Xtrabackup与mysqldump区别
Xtrabackup属于物理备份,mysqldump属于逻辑备份。
Xtrabackup占用的CPU与内存较少,消耗的IO相对较大,备份后的文件较大。
通过mysql自带的工具mysqldump进行逻辑备份和恢复,虽然可以节省磁盘空间,但是速度很慢。
自动备份和自动删除过期备份
#1.创建用于存储备份文件的目录,并确保权限正确:
mkdir -p /data/mysql_backup
chown -R mysql:mysql /data/mysql_backup # 与 MySQL 运行用户一致
#2.创建一个 Shell 脚本(例如 mysql_xtrabackup.sh),实现自动备份和自动清理过期备份的逻辑。
脚本内容(/usr/local/bin/mysql_xtrabackup.sh):
-------------------------------------------------------
#!/bin/bash
# ======================================
# 配置参数(根据实际环境修改)
# ======================================
BACKUP_DIR="/data/mysql_backup" # 备份存储目录
MYSQL_USER="root" # MySQL 用户名
MYSQL_PASS="your_mysql_password" # MySQL 密码
MYSQL_SOCK="/var/lib/mysql/mysql.sock" # MySQL sock 文件路径
RETENTION_DAYS=7 # 备份保留天数(超过则删除)
# ======================================
# 备份逻辑
# ======================================
# 创建当日备份子目录(格式:YYYYMMDD_HHMMSS)
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
BACKUP_SUB_DIR="${BACKUP_DIR}/${TIMESTAMP}"
mkdir -p "${BACKUP_SUB_DIR}"
# 使用 xtrabackup 执行热备份
echo "开始备份 MySQL 数据库到 ${BACKUP_SUB_DIR} ..."
xtrabackup --user="${MYSQL_USER}" \
--password="${MYSQL_PASS}" \
--socket="${MYSQL_SOCK}" \
--backup \
--target-dir="${BACKUP_SUB_DIR}" \
--compress # 可选:启用压缩(需安装 qpress)
# 检查备份是否成功
if [ $? -eq 0 ]; then
echo "备份成功!"
else
echo "备份失败!删除临时文件并退出。"
rm -rf "${BACKUP_SUB_DIR}"
exit 1
fi
# ======================================
# 清理过期备份
# ======================================
echo "开始清理 ${RETENTION_DAYS} 天前的过期备份..."
find "${BACKUP_DIR}" -maxdepth 1 -type d -mtime +${RETENTION_DAYS} -exec rm -rf {} \;
echo "过期备份清理完成!"
# 在备份脚本末尾添加(确保权限统一)
chown -R mysql:mysql /data/mysql_backup
-------------------------------------------------------
#3.给脚本添加执行权限:
chmod +x /usr/local/bin/mysql_xtrabackup.sh
#4.测试脚本是否能正常运行:
/usr/local/bin/mysql_xtrabackup.sh
#执行后检查 /data/mysql_backup 目录是否生成备份文件,以及过期备份是否被删除。
#5.通过 crontab 设置定时任务,让脚本在指定时间自动执行(例如每天凌晨 2 点执行)。
crontab -e
0 2 * * * /usr/local/bin/mysql_xtrabackup.sh >> /var/log/mysql_backup.log 2>&1
#6.重启 Cron 服务:
systemctl restart crond
#7.验证备份完整性:
# 进入备份目录
cd /bak/back/20250811_194917/
# 解压所有压缩文件(需 qpress 工具)
xtrabackup --decompress --target-dir=.
# 准备备份(使备份文件处于一致性状态)
xtrabackup --prepare --target-dir=.
#若输出 completed OK! 则表示备份有效。
12.MySQL进阶
事物
事物:一组数据库的操作(SQL)集合,这个集合中的操作(SQL)要么都执行,要么都不执行。
保证数据库的完整性与一致性。保证数据的安全。
注意:
MySQL的事务默认自动提交的,也就是说,当执行完一条DML语句时,MySQL会立即隐式提交事务。
案例:银行转账:
张三 -> 李四转钱;
在数据库增、删、改时,才需要开启事务,查询不会改变数据的内容。
一组SQL都执行成功了,提交(commit);
任意一条语句执行失败,则回滚(rollback);
#控制事务
#查看或设置事务提交方式
SELECT @@autocommit ;
SET @@autocommit = 0 ;【1是自动提交,0是关闭自动提交】
#事务准备
#创建表
create table account(
id int primary key AUTO_INCREMENT comment 'ID',
name varchar(10) comment '姓名',
money double(10,2) comment '余额'
)comment '账户表';
#添加数据
insert into account(name, money) VALUES ('张三',2000), ('李四',2000);
#开启事务
START TRANSACTION;
或者
BEGIN ;
#执行语句
SELECT * FROM account WHERE name = '张三';
UPDATE account SET money = money - 1000 WHERE name = '张三';
UPDATE account SET money = money + 1000 WHERE name = '李四';
#语句都执行成功后,提交事务
COMMIT;
#若有一条语句执行失败,则事务回滚
ROLLBACK;
事务的四大特性(ACID):
- A 原子性 (Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- C 一致性 (Consistency):事务完成时,必须使所有数据都保持一致状态。
- I 隔离性 (Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- D 持久性 (Durability):事务一旦提交或回滚,他对数据库中的改变就是永远的。一但提交就不能回滚,一旦回滚就不能提交了。
数据库的并发问题:
- 脏读:一个事务读取到另一个事务还未提交的数据。
- 不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同。
- 幻读:一个事务按照查询条件查询数据时,没有对应数据行,但是在插入数据时,又发现这行数据已经存在,好像出现“幻影”。
事务隔离级别:
- READ UNCOMMITTED(读未提交)
- 允许读取未提交的数据,可能会遇到脏读。
- READ COMMITTED (读已提交)
- 只允许读取已经提交的数据,可以避免脏读,但可能出现不可重复读。
- REPEATABLE READ(可重复读)
- 保证一个事务多次读取是一致的,但可能出现幻读。
- SERIALIZABLE (可串行化、序列化)
- 最高的隔离级别,避免脏读、幻读、不可重复读,但会降低数据库性能。
视图
视图(View):是虚拟的表,通常用于简化复杂查询。
视图中的数据来源于基表(基础表)。基表发生变动,视图会受到影响。视图中的数据是动态生成的,它是一条select语句的结果集。
- 视图的功能:
- 简化复杂查询
- 提升安全性
#创建
create view 视图名称 as select ··· from ··· where ··· ;
#使用 和表的使用方法一致
select * from 视图名称 ;
#修改 创建或替换原有视图
CREATE OR REPLACE VIEW 视图名称 AS SELECT 选择的列 FROM 表名 WHERE 条件;
#删除
drop view 视图名称 ;
存储引擎
存储引擎:实现对数据增、删、改、查、事务、索引的数据库核心组件。
MySQL服务端的组成:
-
连接层:通过网络或本地socket和客户端通信,登陆、授权认证等安全方案。
-
服务层:接受SQL语句,进行语句分析,下发指令让引擎层执行。
-
引擎层:存储引擎真正的负责了 MySQL 中数据的存储和提取,不同的需求可以使用不同的引擎。
-
存储层:文件系统,用于存储数据。并完成与存储引擎的交互。
-
常用引擎:
- InnoDB(默认):支持事务(ACID)、支持行级锁、聚簇索引,适合高并发、高安全场景、金融、电商、订单系统。
- MyIsAM:不支持事务、支持表级锁,适合对事务没有要求,读多写少的场景。
- MEMORY:内存型存储引擎,支持哈希(hash)索引,优点:读写速度快;缺点:断电数据会丢失。适合缓存临时数据。
- CSV:文本存储,列与列之间默认用‘逗号’分割。可直接用文本编辑器查看或修改数据,兼容性强(适合与其他系统交换数据)。缺点:性能差,不支持事务,索引,锁 。适合简单的数据存储 例如:日志存储
#查询数据库支持的存储引擎 show engines ; #使用存储引擎 create table 表名( 字段1 数据类型 约束条件 , 字段2 数据类型 约束条件 )engine = csv【引擎】;
索引
index (索引、目录、下标)
定义:加快数据查询的一类数据结构。类似于字典的目录,可以帮助我们快速找到我们需要的数据内容。
注意:索引是和存储引擎关联的,不同的存储引擎提供索引类型不同。
优点:数据量大时,对于查询速度有明显的提升。
缺点:
- 会占用一定的存储空间;
- 会影响写入速度(增、删、改);
索引的分类:
- 数据结构:
- B+tree:InnoDB、MyIsAM
- 所有数据存储在叶子节点,且叶子节点通过双向链表连接,支持范围查询的高效遍历。
- 非叶子节点仅存储索引键,用于快速定位区间,减少单次查询的 IO 次数。
- 高度通常为 3 - 4 层,可存储千万级数据(单节点存储多个键值)。
- hash(哈希):Memory 键值对,哈希函数,使用了哈希算法。
- 哈希算法:将所有数据相加,经过取模(x%y)运算,得到固定长度的结果。这个结果就是键key,对应一个内存地址,将数据存放进去。查找数据时,通过计算找到key对应的地址,直接取值。
- R-tree:MyIsAM
- B+tree:InnoDB、MyIsAM
- 逻辑结构(创建索引):
- 主键索引:主键索引是唯一索引的一种,它不仅确保唯一性,还作为表的主键标识每一行数据。每个表只能有一个主键索引。
- 唯一索引:唯一索引确保索引列中的所有值都唯一。它不仅加速查询,还可以保证数据的唯一性。
- 普通索引(单值索引、单列索引): 普通索引是最基本的索引类型,用于加速数据的检索。
- 复合索引(多列索引):复合索引是在多个列上创建的索引,用于加速基于多个列的查询。
- 核心特性:最左前缀匹配原则
- 全文索引(MyIsAM支持、InnoDB不支持)
数据结构:
- 线性结构:队列、栈、链表、数组
- 树状结构:二叉树、二叉搜索树、红黑树、B树、B+树
- 图状结构:有向图、无向图 ···
二分查找法:先排序,从中间开始找,小的向左找,大的向右找,缩小范围,不断重复;二叉搜索树。
全局查找法:使用穷举法,一个一个找一个一个试;
索引的使用
#创建索引:普通索引、唯一索引、主键索引、复合索引
#普通索引
create index 索引名 on 表名(字段) ;
#例如
create index idx_name on student(name) ;
#唯一索引
create unique index 索引名 on 表名(字段) ;
#例如
create unique index idx_email on student(email) ;
#主键索引:每个表只能有一个主键索引。可在创表时添加主键
alter table 表名 add primary key (字段名);
#例如:
alter table student add primary key (id);
#复合索引
create index 索引名 on 表名(字段名1,字段名2···);
#例如
create index idx_name_age on student(name,age);
#查看索引
show index from 表名 ;
#删除索引
drop index 索引名 on 表名 ;
锁
锁:解决并发事务中的问题,例如:幻读,脏读,不可重复读。
“占位”的操作。
锁的分类:
- 颗粒度(从大到小)
- 全局锁:锁整个库,阻止写操作。
- 表级锁:锁一个表
- 行锁:锁某个记录或某个范围
- 属性分类
- 共享锁(S):读锁,其他用户和事务只能查看,不能修改。
- 排他锁(X):写锁,其他用户和事务不能看也不能写。
- 状态分类
- 意向共享锁(IS):表示某个事务即将加共享锁的意图。
- 意向排他锁(IX):表示某个事务即将加排他锁的意图。
- 模式分类
- 乐观锁:在读多的场景,事务冲突概率低,不加锁,在操作完成后校验。
- 悲观锁:预计冲突的概率高,直接加锁,写操作较多的场景。
- 算法分类
- 间隙锁:防止幻读,锁定一个表的范围。
- 记录锁:锁定一条记录,颗粒度最细的锁。
- 临键锁:临键锁是对数据记录和记录之间的间隙同时加锁的机制。它用于防止在一个事务中读取的数据范围内出现新的记录,从而避免幻读现象。临键锁可以确保在事务执行期间,其他事务不能插入、修改或删除锁定范围内的数据。
死锁问题:
死锁通常发生在以下情况下:
- 事务A持有锁资源1,并请求锁资源2。
- 事务B持有锁资源2,并请求锁资源1。
- 由于相互持有的锁资源,两个事务都无法继续执行,从而产生死锁。
解决:
- InnoDB 自动检测死锁,回滚其中一个事务(通过 innodb_deadlock_detect=ON 控制)。
- 优化:按固定顺序加锁(如按主键排序)、缩短事务时长、减少锁持有时间。
优化
-
插入数据时:
- 批量插入数据
- 手动控制事务
- 主键按顺序添加,建议使用auto_increment,不建议使用UUID作为主键
- 大批量导入数据时,建议客户端添加
–-local-infile选项,直接导入
#-- 客户端连接服务端时,加上参数 -–local-infile mysql –-local-infile -u root -p #-- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关 set global local_infile = 1; #-- 执行load指令将准备好的数据,加载到表结构中 load data local infile '/root/sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n'; -
主键的优化:
- 尽量简短一些
- 按顺序添加,建议使用 auto_increment
- 尽量不要使用 UUID 做主键或者是其他自然主键,如身份证号
- 业务操作时,避免对主键的修改
-
order by 优化:
- Using filesort :全表扫描排序,读取满足条件的数据行,然后在排序缓冲区 sortbuffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
- Using index :使用索引列进行排序,建立索引时,默认会进行排序。给需要排序的列添加单列或联合索引。
- 多列索引的生效依赖于“最左前缀”,必须从第一列开始匹配。
- 在使用索引排序时,不要使用 “select * from ····” ‘
*’会导致索引失效,变为全文扫描。
默认情况下的联合索引都是升序的。也就是 create index index_name on table(age asc,phone asc) #asc可以省略 #正例 (索引有效) select age from table order by age; select age,phone from table order by age,phone; select age from table order by age desc; #反例 select * from table order by ... #不管安排什么字段来排序,只有用*一定索引失效。 select age,name from table order by age # 由于name字段是不包含在idx_age_name索引中所以无法使用索引,此时需要进行文件排序,即Extra: Using filesort select age,name from table order by age,name desc #一升一降,部分失效 select age from table order by phone #需filesort辅助 #总之 大前提,select 中的字段要求在索引中出现。 借联合索引时,要遵循最左匹配原则,当然可以先用 where age 后 order by name,也是遵循的。 借联合索引,order by 的要求字段,要么同时升序要么同时降序。 额外信息中出现 Using index 和 filesort,性能都是不太达标的! 想一升一降的排序,可以这样创建索引 create index index_name on table(age ,name desc) 如此一来,一升一降就不会导致索引 (部分) 失效 -
group by 优化:
- Using temporary:使用临时表来分组,效率低
- Using index:使用索引分组
- select 应该只出现索引有的字段
- 最左匹配,允许先 where 匹配字段,后 group by
-
limit 优化:
select * from table limit 100w,10;
#这样的越往后的分页,效率越低。
MySQL 官方建议:
覆盖索引
select id from table order by id limit 100w,10;
如果没有 order by id 默认下是按照物理磁盘的存储顺序来显示数据的!而不是安排自增 id,其实不存在页合并的话,那么查出来的就是 id 升序
使用连表查询出 id 的行数据
select * from tb_sku t , (select id from table order by id limit 100w,10) a where t.id = a.id;
- count 优化:
count(*)≈count(1)>count(主键)>count(字段)
尽量使用count(*), MySQL专门优化了性能!
- update 优化:
使用 update 会使用到 InnoDB 的锁机制。
锁是针对索引的,如果 where 中没有索引或索引失效,那么将会升级为表锁,性能大大降低
update ... where name='Jack'
#若name没有索引,则是表锁;有索引,则是行锁
另外,如果 name='Jack’有多条记录,这么这多条记录都会施加行锁!
总结:本质还是针对索引优化,因此掌握索引优化,就掌握了 SQL 优化的 80%!!!
- 插入数据:批量插入、手动控制事务、主键顺序插入
- 主键优化:长度短、顺序插入,用 auto_incremrnt 而不是 UUID
- order by:using index 直接索引返回而不是 Using filesort
- group by:多字段分组要满足最左前缀匹配
- limit:覆盖索引 (无需回表)+ 子查询
- count:count(字段)<count(主键 id) < count(数字) ≈ count(*)
- update:尽量根据 (where) 主键 / 索引字段进行数据更新
EXPLAIN
EXPLAIN 是 MySQL 提供的用于分析查询执行计划的核心工具,通过它可以直观看到数据库如何执行一条 SQL 查询(如是否使用索引、扫描了多少行数据、是否需要临时表等),是优化慢查询的关键手段。
#基础用法:在任意 SELECT 语句前添加 EXPLAIN 关键字即可生成执行计划:
explain select * from user where age > 20 ;
#执行后会返回一个结果表,包含多个关键字段,以下是最核心的 10 个字段及其含义:
1. id(查询序号)
2. select_type(查询类型)
3. table(当前操作的表)
4. type(访问类型,最核心字段!)
5. possible_keys(可能使用的索引)
6. key(实际使用的索引)
7. key_len(索引的有效长度)
8. ref(索引匹配的列或常量)
9. rows(估算扫描的行数)
10. Extra(额外信息,关键优化点!)
日志
一、MySQL日志体系概述
MySQL的日志体系可分为服务器层日志(适用于所有存储引擎)和存储引擎层日志(如InnoDB特有),不同日志承担不同职责:
| 日志类型 | 所属层级 | 核心作用 | 适用场景 |
|---|---|---|---|
| 错误日志(Error Log) | 服务器层 | 记录服务启动/运行/关闭的异常信息 | 排查服务启动失败、崩溃等问题 |
| 查询日志(General Log) | 服务器层 | 记录所有客户端的连接及SQL操作 | 临时调试(如追踪异常SQL来源) |
| 慢查询日志(Slow Query Log) | 服务器层 | 记录执行时间超过阈值的SQL | 性能优化(定位低效查询) |
| 二进制日志(Binary Log) | 服务器层 | 记录数据变更操作 | 主从复制、数据恢复 |
| 中继日志(Relay Log) | 服务器层(从库) | 存储主库同步的二进制日志,供从库执行 | 主从复制场景 |
| 重做日志(Redo Log) | InnoDB引擎 | 记录数据页修改,保障事务持久性 | 崩溃恢复、事务提交 |
| 回滚日志(Undo Log) | InnoDB引擎 | 记录事务前数据状态,支持回滚和MVCC | 事务回滚、读写不阻塞 |
二、核心日志详解与实战操作
- 错误日志(Error Log)
作用
记录MySQL服务器启动、运行、关闭过程中的关键事件,包括:
- 服务启动/关闭的详细信息
- 严重错误(如权限不足、内存溢出、表损坏)
- 警告信息(如配置参数不推荐使用)
配置方法
错误日志默认强制开启,无需手动启用,仅需配置存储路径。
步骤1:修改配置文件
- Linux系统:配置文件通常为 /etc/my.cnf或 /etc/mysql/my.cnf
- Windows系统:配置文件通常为 D:\MySQL\my.ini
#添加/修改如下参数:
[mysqld]
log-error = /var/log/mysql/mysql-error.log # Linux路径示例
# log-error = "C:/ProgramData/MySQL/MySQL Server 8.0/data/mysql-error.log" # Windows路径示例
步骤2:重启服务生效
# Linux重启命令(根据系统版本选择)
systemctl restart mysqld # CentOS 7+/Ubuntu 16+
#动态查看配置(无需重启): -- 查看错误日志路径
SHOW VARIABLES LIKE 'log_error';
#查看与分析
错误日志为文本格式,可直接用文本工具查看:
# 查看最新10行错误日志
tail -n 10 /var/log/mysql/mysql-error.log
# 搜索关键词(如"error")
grep -i "error" /var/log/mysql/mysql-error.log
#常见错误场景:
启动失败:检查端口占用(Port 3306 is already in use)、权限不足(Permission denied)
崩溃日志:搜索 mysqld got signal 11(段错误),通常与内存或引擎异常相关
#管理策略
日志轮转:通过 logrotate(Linux)定期切割日志,避免单个文件过大:
# 创建logrotate配置(/etc/logrotate.d/mysql-error)
/var/log/mysql/mysql-error.log {
daily # 每天轮转
rotate 7 # 保留7天日志
compress # 压缩旧日志
missingok # 日志不存在时不报错
postrotate # 轮转后重启服务(可选)
systemctl restart mysqld > /dev/null 2>&1
endscript
}
权限设置:确保日志文件属主为 mysql 用户(chown mysql:mysql /var/log/mysql/*),避免写入失败。
- 查询日志(General Log)
作用
记录所有客户端的连接行为(连接/断开)及执行的所有SQL语句(包括SELECT、INSERT等),可用于追踪异常操作(如误删数据)。
注意事项
- 默认关闭(因高并发场景下会产生大量IO,严重影响性能)。
- 仅建议在临时调试时开启(如定位某条SQL的执行来源),调试完成后立即关闭。
#配置方法
方法1:通过配置文件永久开启
[mysqld]
general_log = ON # 开启查询日志(1/ON为开启,0/OFF为关闭)
general_log_file = /var/log/mysql/mysql-general.log # 日志路径
重启服务生效。
方法2:动态开启(无需重启,临时生效)
-- 查看当前状态
SHOW VARIABLES LIKE 'general_log';
SHOW VARIABLES LIKE 'general_log_file';
-- 动态开启
SET GLOBAL general_log = ON;
-- 动态修改日志路径(需确保mysql用户有写入权限)
SET GLOBAL general_log_file = '/var/log/mysql/new-general.log';
#查看与分析
查询日志为文本格式,每行记录包含时间、客户端IP、SQL语句:
tail -f /var/log/mysql/mysql-general.log # 实时查看日志
示例日志内容:
2025-08-14T08:30:00.123456Z 123 Connect root@192.168.1.100 on test using TCP/IP
2025-08-14T08:30:05.678901Z 123 Query SELECT * FROM users WHERE id = 1
2025-08-14T08:30:10.112233Z 123 Quit
#关闭与清理
调试完成后务必关闭,避免性能损耗:
SET GLOBAL general_log = OFF; -- 动态关闭
日志文件可直接删除(需先关闭日志或重启服务),或通过日志轮转工具管理。
- 慢查询日志(Slow Query Log)
作用
记录执行时间超过阈值(默认10秒)的SQL语句,是性能优化的核心工具,可快速定位低效查询(如未加索引、全表扫描的SQL)。
配置方法
核心参数说明:
slow_query_log:是否开启(1/ON开启,0/OFF关闭)slow_query_log_file:日志存储路径long_query_time:慢查询阈值(单位:秒,支持小数如0.5,即500毫秒)log_queries_not_using_indexes:是否记录未使用索引的查询(即使不慢,建议开启)log_slow_admin_statements:是否记录管理员语句(如ALTER TABLE,可选开启)
#方法1:配置文件永久生效
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/log/mysql/mysql-slow.log
long_query_time = 1 # 阈值设为1秒(根据业务调整)
log_queries_not_using_indexes = ON # 记录未用索引的查询
log_slow_admin_statements = ON # 记录慢管理语句
重启服务生效。
#方法2:动态配置(临时生效)
-- 开启慢查询日志
SET GLOBAL slow_query_log = ON;
-- 修改阈值为0.5秒
SET GLOBAL long_query_time = 0.5;
-- 开启未用索引记录
SET GLOBAL log_queries_not_using_indexes = ON;
#日志分析工具
慢查询日志为文本格式,但直接查看效率低,推荐使用专业工具分析:
mysqldumpslow(MySQL自带): 简单统计慢查询TOP N(如最多执行次数、最长时间):
# 查看执行次数最多的10条慢查询
mysqldumpslow -s c -t 10 /var/log/mysql/mysql-slow.log
# 查看平均时间最长的10条慢查询
mysqldumpslow -s t -t 10 /var/log/mysql/mysql-slow.log
pt-query-digest(Percona Toolkit,推荐):
#更强大的分析工具,支持按SQL模板、用户、客户端等维度统计:
# 安装(CentOS示例)
yum install percona-toolkit -y
# 分析慢查询日志并生成报告
pt-query-digest /var/log/mysql/mysql-slow.log > slow_analysis.report
#管理策略
阈值调整:根据业务场景设置合理的long_query_time(如OLTP系统建议0.1-1秒)。
日志轮转:同错误日志,使用logrotate定期切割,避免文件过大。
定期分析:结合业务低峰期(如凌晨)运行pt-query-digest,输出优化清单。
- 二进制日志(Binary Log)
作用
记录所有数据变更操作(如INSERT/UPDATE/DELETE、CREATE/DROP等),不记录纯查询(SELECT)。核心用途:
- 主从复制:主库通过binlog将变更同步到从库,保证数据一致性。
- 数据恢复:通过回放binlog中指定时间段的操作,恢复误删/误改的数据。
配置方法
核心参数:
log_bin:开启binlog并指定路径(如/var/log/mysql/mysql-bin,文件名自动加编号)。binlog_format:日志格式(row/statement/mixed,推荐row)。expire_logs_days:自动过期时间(天,默认0即永不过期)。max_binlog_size:单个binlog文件最大大小(默认1GB,满后自动切换新文件)。
#配置示例:
[mysqld]
log_bin = /var/log/mysql/mysql-bin # 开启binlog
binlog_format = row # 记录行级变更(避免主从数据不一致)
expire_logs_days = 7 # 7天后自动删除旧日志
max_binlog_size = 500M # 单个文件最大500MB
server-id = 1 # 主从架构中必须设置唯一ID(主库1,从库2,3...)
重启服务生效(主从架构中需确保server-id唯一)。
#关键操作
查看binlog列表:
SHOW BINARY LOGS; -- 列出所有binlog文件及大小
查看当前正在写入的binlog:
SHOW MASTER STATUS;
查看binlog内容(需用mysqlbinlog工具):
# 查看指定binlog的文本格式内容(包含时间、SQL操作)
mysqlbinlog --base64-output=decode-rows -v /var/log/mysql/mysql-bin.000001
# 按时间筛选(如2025-08-14 08:00到09:00的操作)
mysqlbinlog --start-datetime="2025-08-14 08:00:00" --stop-datetime="2025-08-14 09:00:00" /var/log/mysql/mysql-bin.000001
#手动删除binlog(谨慎操作):
-- 删除指定文件之前的所有binlog(保留mysql-bin.000005及之后)
PURGE BINARY LOGS TO 'mysql-bin.000005';
-- 删除3天前的binlog
PURGE BINARY LOGS BEFORE DATE_SUB(NOW(), INTERVAL 3 DAY);
#数据恢复实战
假设误删了users表的数据,可通过binlog恢复:
找到误操作时间点(如2025-08-14 10:30)。
确定对应binlog文件(通过SHOW BINARY LOGS和时间匹配)。
提取误操作前的SQL并回放:
# 导出2025-08-14 10:20到10:30(误操作前)的操作
mysqlbinlog --start-datetime="2025-08-14 10:20:00" --stop-datetime="2025-08-14 10:30:00" /var/log/mysql/mysql-bin.000001 > recover.sql
# 执行恢复SQL(注意先备份当前数据)
mysql -u root -p < recover.sql
- 中继日志(Relay Log)
作用
仅存在于从库,是主从复制的"中间载体":
- 从库的IO线程读取主库binlog,写入本地中继日志。
- 从库的SQL线程读取中继日志,执行其中的SQL操作,实现数据同步。
#配置与管理
默认路径:从库数据目录(如/var/lib/mysql/),文件名格式为host-relay-bin.xxxxxx。
核心参数:
[mysqld]
relay_log = /var/lib/mysql/relay-bin # 自定义中继日志路径
relay_log_purge = ON # 自动清理已执行的中继日志(默认开启,避免占用空间)
relay_log_recovery = ON # 从库崩溃后重启时,自动重新同步主库binlog(推荐开启)
#查看中继日志状态:
SHOW SLAVE STATUS\G # 查看中继日志相关信息(如Relay_Log_File、Relay_Log_Pos)
- InnoDB引擎日志(Redo Log & Undo Log)
作用与原理
InnoDB作为MySQL默认存储引擎,通过这两类日志保障事务ACID特性:
| 日志类型 | 核心作用 | 与事务的关系 |
|---|---|---|
| 重做日志(Redo Log) | 记录数据页的修改,确保事务持久性(崩溃后可恢复) | 事务提交时写入,支持"预写日志(WAL)"机制 |
| 回滚日志(Undo Log) | 记录事务前的数据状态,支持回滚和MVCC | 事务执行中动态生成,提交后标记删除 |
MVCC(Multi-Version Concurrency Control,多版本并发控制)是 MySQL InnoDB 存储引擎实现高并发读写的核心机制。它通过为数据记录维护多个版本,让读写操作可以无冲突地并行执行(读不阻塞写,写不阻塞读),同时保证事务隔离性。
简单来说:当多个事务同时操作同一份数据时,MVCC 会为每个事务提供独立的「数据版本」,使得事务之间的操作互不干扰,最终通过一套规则决定事务能看到哪个版本的数据。
#配置与管理
Redo Log配置:
[mysqld]
innodb_log_file_size = 512M # 单个redo log文件大小(默认48M,建议设为512M-2G)
innodb_log_files_in_group = 2 # 日志文件数量(默认2个,如ib_logfile0、ib_logfile1)
innodb_log_group_home_dir = ./ # 日志路径(默认数据目录)
#注意:修改innodb_log_file_size需先停止服务,删除旧日志文件,重启后自动生成新文件。
#Undo Log配置:
[mysqld]
innodb_undo_directory = ./ # undo log存储路径
innodb_undo_logs = 128 # undo日志段数量(默认128)
innodb_undo_tablespaces = 3 # 独立undo表空间数量(避免共享表空间膨胀)
日志管理最佳实践
- 按需开启日志:
- 必须开启:错误日志、二进制日志(主从或需恢复场景)、InnoDB日志(默认开启)。
- 按需开启:慢查询日志(长期开启)、查询日志(仅临时调试)。
- 性能与存储平衡:
- 日志文件存储在独立磁盘(避免与数据盘IO竞争)。
- 高并发场景下,
long_query_time不宜设得过小(如<0.1秒),避免慢查询日志写入频繁。 - 自动化管理:
- 所有日志配置
logrotate轮转(切割、压缩、删除旧日志)。 - 监控日志目录磁盘使用率(如通过Prometheus+Grafana),避免占满磁盘。
- 安全与权限:
- 日志文件权限设为
600(仅mysql用户可读写),避免敏感信息泄露(如binlog包含数据变更)。 - 定期备份二进制日志(用于数据恢复),并加密存储。
常见问题与解决方案
| 问题场景 | 排查步骤 | 解决方案 |
|---|---|---|
| 服务启动失败 | 查看错误日志,搜索"error"关键词 | 检查端口占用、权限、配置文件语法错误 |
| 慢查询日志无记录 | 确认slow_query_log=ON,且SQL执行时间≥阈值 |
调整long_query_time,检查log_queries_not_using_indexes |
| 主从同步延迟 | 从库执行SHOW SLAVE STATUS\G,查看中继日志 |
优化从库SQL线程(如slave_parallel_workers) |
| binlog文件过大 | 检查max_binlog_size和expire_logs_days |
调小单个文件大小,设置自动过期时间 |
MySQL的主从原理
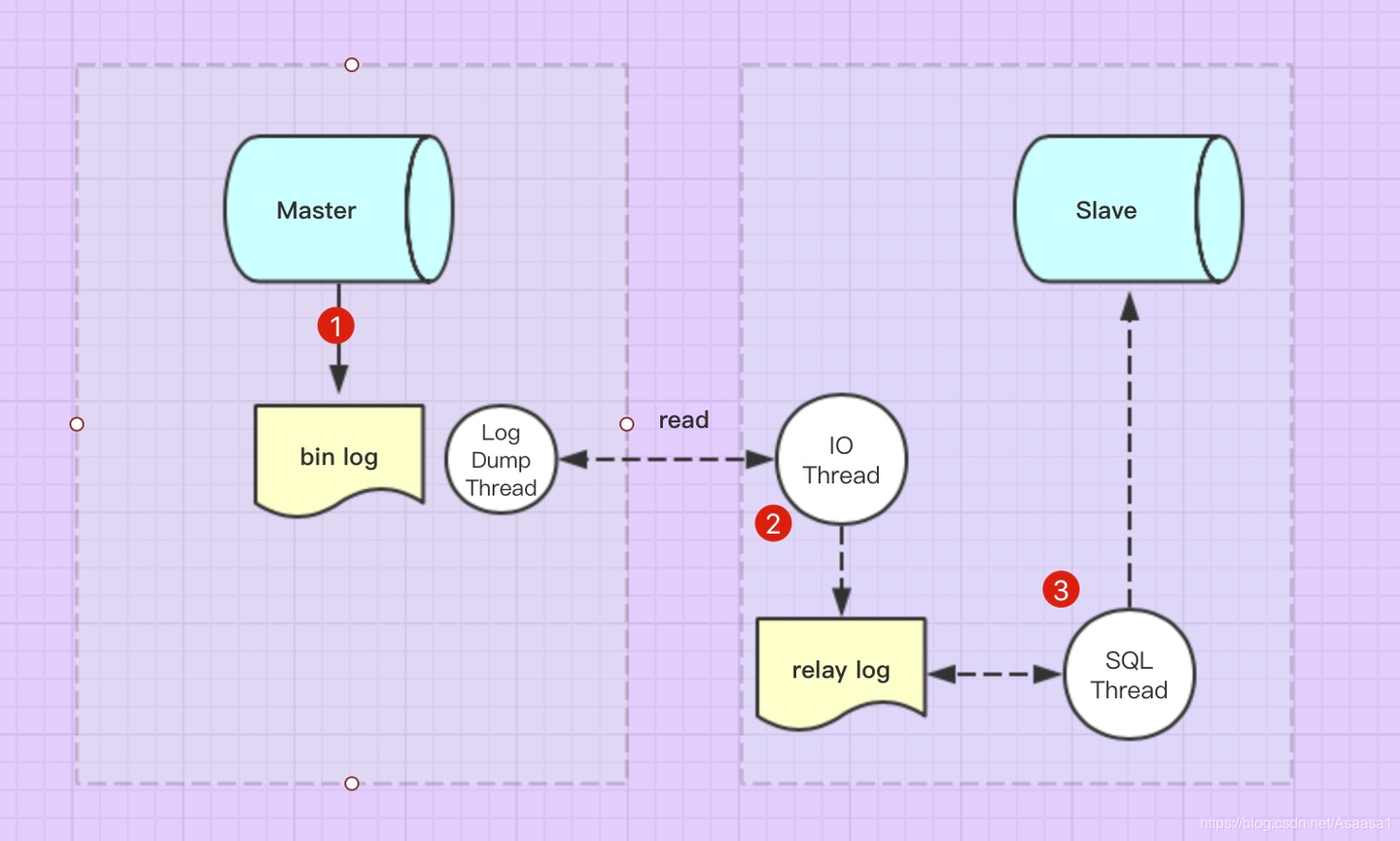
两个日志(master 的 bin-log 和 slave 的 relay log)
- 三个线程(master的dump线程、slave 的 io线程 和spl 线程)
- master(主服务器)执行DDL或DML语句时,会记录bin-log
- bin-log 写入成功后,dump线程会通知slave (从服务器)节点
- slave 使用 io 线程读取master 的bin-log 日志,并写入relay log 中
- slave 使用 sql 线程 将 relay log 中新添加的内容转换为SQL语句,并执行,从而实现从节点(slave)与主节点(master)的数据一致。
线程是进程中任务最小的执行单元,一个进程中可以包含多个线程,执行相同或不同的功能,实现多线程并发执行。
13.MySQL主从集群
原理:
- 主 bin-log 从 relay-log
- 主 dump 从 io 、sql
作用:
- 实时备份:主服务器实时备份数据到从服务器,主服务器中的数据丢失时,可以从从服务器中恢复数据。
- 读写分离:主服务器负责写操作(insert/update/delete),从服务器主要负责读(select)的操作。
- 高可用集群:当主服务器突然下线,从服务器可以很快的接替主服务器的功能。
- 负载均衡:将原本一台服务器处理的请求分发给多台服务器去处理,适用于高并发场景,防止单台服务器负载过高奔溃。
搭建主从服务器
# 1.服务器的准备
服务器IP 角色 主机名
192.168.25.22 Master1(主) zhu_fwq
192.168.25.23 Slave1(从) con_fwq
--------------------------------------------------------
#2.给两台服务器都安装相同版本的MySQL数据库(mysql8.0.20)
#下载MySQL安装脚本
wget 192.168.56.200/Software/mysql_install.sh
# 执行MySQL安装脚本
bash mysql_install.sh
#安装好后重新加载
source //etc/profile
ba
-------------------------------------------------------
#3.修改主服务器的配置文件 /etc/my.cnf
vim /etc/my.cnf
[mysqld]
... # 省略
# 主从复制-主机配置
# 主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=sys
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
# 设置需要复制的数据库(可设置多个)
# binlog-do-db=test
# 设置logbin格式
binlog_format=ROW
#STATEMENT格式记录执行的SQL语句,而不是记录实际数据行的更改。
#ROW格式记录了对数据行的更改。
#MIXED格式则是根据操作的类型(语句或行)来灵活选择。
--------------------------------------------------------
#4.修改从服务器的配置文件 /etc/my.cnf
vi /etc/my.cnf
[mysqld]
...
# 在之前配置下方编写
# 主从复制-从机配置
# 从服务器唯一ID
server-id=2
# 启用中继日志
relay-log=mysql-relay
--------------------------------------------------------
#5.分别重启两台服务器上的MySQL
/etc/init.d/mysqld restart
--------------------------------------------------------
#6.关闭主从数据库服务器防火墙或开放3306端口
# 查看防火墙状态
systemctl status firewalld
# 关闭防火墙
systemctl stop firewalld
--------------------------------------------------------
#7.主数据库创建用户slave 并授权
# 在主数据库端(192.168.25.22)
# 登录mysql -uroot -p
# 创建用户
create user 'slave'@'%' identified with mysql_native_password by 'root123';
# 授权
grant replication slave on *.* to 'slave'@'%';
# 刷新权限
flush privileges;
--------------------------------------------------------
#8.从数据库端验证主数据库slave用户是否可用
# 在从数据库端(192.168.25.23)
# 验证主数据库slave用户是否可用
mysql -uslave -p -h192.168.8.100 -P3306
#验证成功后退出
--------------------------------------------------------
#9.配置主从节点信息
# 在主数据库端(192.168.25.22)
# 查询服务ID及Master状态
# 登录
mysql -uroot -p
# 查询server_id是否可配置文件中一致
show variables like 'server_id';
# 若不一致,可设置临时ID(重启失效)
set global server_id = 100;
# 查询Master状态,并记录 File(对应下一步中的master_log_file)
# Position (对应下一步中的master_log_pos)的值
show master status\G;
#输出
File: mysql-bin.000001
Position: 828
Binlog_Do_DB:
Binlog_Ignore_DB: sys,mysql,information_schema,performance_schema
Executed_Gtid_Set:
# 注意:执行完此步骤后退出主数据库
# 防止再次操作导致 File 和 Position 的值发生变化
--------------------------------------------------------
#10.在从数据库端设置同步
# 在从数据库端(192.168.25.23)
# 登录
mysql -uroot -p
# 查询server_id是否可配置文件中一致
show variables like 'server_id';
# 若不一致,可设置临时ID(重启失效)
set global server_id = 101;
# 设置主数据库参数(用上一步创建的slave用户及密码)
change master to
master_host='192.168.8.100',
master_port=3306,
master_user='slave',
master_password='root123',
master_log_file='mysql-bin.000001',
master_log_pos=828;
# 开始同步
start slave;
# 查询Slave状态
show slave status\G;
# 查看是否配置成功
# 查看参数 Slave_IO_Running 和 Slave_SQL_Running 是否都为yes,则证明配置成功。若为no,则需要查看对应的 Last_IO_Error 或 Last_SQL_Error 的异常值
# 若出现错误,则停止同步,重置后再次启动
#停止
stop slave;
#重置
reset slave;
#启动
start slave;
--------------------------------------------------------
#11.测试主从复制,主服务上执行
# 在主数据库端(192.168.25.22)
mysql -uroot -p
# 创建test库,t1表,添加测试数据
create database test;
use test;
create table t1(id int,name varchar(30));
insert into t1(id,name) values(1,"aaa");
--------------------------------------------------------
#12.测试主从复制,从服务器上执行
# 在从数据库端(192.168.25.23)
mysql -uroot -p
# 查看是否同步数据
show databases;
use test;
show tables;
select * from t1;
如果主从不同步,怎么解决
从不同的原因分析:
-
问题:主服务器二进制日志异常
解决办法:需要检查主库的二进制日志是否正常。可以通过查看主库的错误日志、binlog文件的状态以及复制进程的状态来判断。如果发现异常,可以尝试重启主库的复制进程或者重新生成二进制日志。
-
问题:主从库的配置不一致也是主从不同步的一个常见原因。比如主库的字符集设置为utf8,而从库的字符集设置为latin1,就会导致数据在复制过程中出现乱码或者丢失的情况。
解决办法:如果主从库的配置不一致,可以通过修改从库的配置文件来保持一致。比如,将从库的字符集设置与主库一致,确保数据在复制过程中不会出现乱码或者丢失。
-
问题:初始数据不一至时,主服务器上修改了从服务器上没有的内容后,导致主从不同步
解决办法:直接忽略报错:在从服务器上修改配置文件,添加 slave_skip_errors=ALL 【跳过所有报错】,然后重启MySQL服务 ,在查看状态
集群
使用多台服务器实现相同的功能,通过网络进行连接。
分类:
- 负载均衡集群
- 高可用集群(主备集群)
- 读写分离集群
分布式
-
单体架构:所有应用、功能、运算、存储等都在一台服务器中。
- 适用于开发、简单测试、个人网站(应用)、小公司。
- 优点:搭建简单、成本低
- 缺点:抗并发能力低,没有备份
-
分布式架构:将服务、应用、运算、存储“拆分”到不同的服务器上实现。
-
适合复杂的服务,应用。
-
横向扩展(增加服务器(节点)数量,来提升整体的性能)
-
分布式存储服务器:网络版的RAID10
-
分布式缓存、分布式运算
-
14.MySQL读写分离
-
中间件:在客户端与服务端之间的服务,用于实现一些特定的功能,安全认证、读写分离、反向代理等功能。
-
ProxySQL:ProxySQL是一款开源的使用C++编写的MySQL集群代理中间件;
1、代理服务:代理后端MySQL服务,进行相关指标的监控
2、负载均衡:后端多节点的访问进行负载均衡
3、高可用:自动识别异常节点,并屏蔽异常节点,保障集群的稳定
4、读写分离:自动动态的识别读写节点,转发SQL至对应节点执行
5、数据分片:通过路由规则,进行SQL分发,达到数据分片的目的
搭建ProxySQL
- 1.搭建MySQL主从
- 2.安装ProxySQL
- 3.配置ProxySQL
- 设置MySQL账户、权限
- 管理监控权限、读写、只读权限
- 设置分发规则
- 设置MySQL账户、权限
- 4.测试
- 使用客户端连接ProxySQL
- 写(create \dorp \install \update \delect) master
- 读(select)负载均衡,多个从服务器 或 一主配一从
- 使用客户端连接ProxySQL
使用ProxySql实现MySQL的读写分离
#实验:使用ProxySql实现MySQL的读写分离
#1.读写分离,简单地说是把对数据库的读和写操作分开,以对应不同的数据库服务器;
#2.主数据库提供写操作,从数据库提供读操作,这样能有效地减轻单台数据库的压力;
#3.基于mysql主从复制
#实现读写分离前需要先配置好主从复制
IP 角色 软件
192.168.25.22 主 MySQL,ProxySQL
192.168.25.23 从 MySQL
#4.大前提 主从服务器上的防火墙都关闭
#1.在主服务器上安装proxysql【主服务器】
## 先配置官方yum源
cat > /etc/yum.repos.d/proxysql.repo << EOF
[proxysql]
name=ProxySQL YUM repository
baseurl=https://repo.proxysql.com/ProxySQL/proxysql-2.5.x/centos/$releasever
gpgcheck=1
gpgkey=https://repo.proxysql.com/ProxySQL/proxysql-2.5.x/repo_pub_key
name=ProxySQL Repository
baseurl=https://repo.proxysql.com/ProxySQL/proxysql-2.5.x/centos/7/
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-proxysql
# 禁用 SSL 证书验证(单独成行的注释)
sslverify=0
EOF
#禁用本地yum源
vim /etc/yum.repos.d/CentOS-Media.repo
#修改这一项
enabled=0 # 必须设为 0 禁用
# 清理所有缓存(包括无效仓库的缓存)
yum clean all
# 重新生成元数据缓存(此时会跳过 c7-media 仓库)
yum makecache
#yum安装proxysql
yum install proxysql
#若是下载时出现密钥获取失败,可以跳过密钥下载
#若暂时无法获取 GPG 密钥,可强制跳过验证(安全性降低)
yum install proxysql --nogpgcheck -y
#2.启动proxysql服务并加入开机自启【主服务器】
systemctl start proxysql #启动
systemctl enable proxysql #设置开机自启
#3.通过管理界面配置ProxySQL
#在主服务器上操作【主服务器】
mysql -uadmin -padmin -h127.0.0.1 -P6032
mysql>show databases;
+-----+---------------+-------------------------------------+
| seq | name | file |
+-----+---------------+-------------------------------------+
| 0 | main | |
| 2 | disk | /var/lib/proxysql/proxysql.db |
| 3 | stats | |
| 4 | monitor | |
| 5 | stats_history | /var/lib/proxysql/proxysql_stats.db |
+-----+---------------+-------------------------------------+
5 rows in set (0.00 sec)
#这些库的含义:
main:内存配置数据库。使用此数据库,可以很容易地以自动化方式查询和更新ProxySQL的配置。使用从内存中加载MYSQL用户和类似命令,可以将存储在此处的配置传播到运行时ProxySQL使用的内存数据结构。
disk:"main"的基于磁盘的镜像。在重新启动过程中,“ main”不会保留,而是根据启动标志以及磁盘上是否存在数据库从“磁盘”数据库或从配置文件加载。
stats:包含从代理的内部功能收集的运行时指标。指标示例包括每个查询规则匹配的次数,当前正在运行的查询等。
monitor:包含与ProxySQL连接的后端服务器相关的监视指标。度量标准示例包括连接到后端服务器或对其进行ping操作的最小和最大时间。
#ProxySQL运行机制
runtime:运行中使用的配置文件
memory:提供用户动态修改配置文件
disk:将修改的配置保存到磁盘SQLit表中(即:proxysql.db)
#添加一个root:root123的用户和密码 远程连接账户【主服务器proxysql】
Admin> select @@admin-admin_credentials;
+---------------------------+
|@@admin-admin_credentials |
+---------------------------+
|admin:admin |
+---------------------------+
1 row in set (0.001 sec)
Admin> set admin-admin_credentials='admin:admin;root:root123';
Query OK, 1 row affected (0.000 sec)
Admin> select @@admin-admin_credentials;
+---------------------------+
|@@admin-admin_credentials |
+---------------------------+
| admin:admin;root:root123 |
+---------------------------+
1 row in set (0.001 sec)
Admin> load admin variables to runtime; # 使修改立即生效
Query OK, 0 rows affected (0.000 sec)
Admin> save admin variables to disk; # 使修改永久保存到磁盘
Query OK, 35 rows affected (0.004 sec)
#4.配置内容
#在主服务器的MySQL中创建监控用户【主服务器mysql】
CREATE USER 'monitor'@'%' IDENTIFIED BY 'monitor';
GRANT USAGE, REPLICATION CLIENT ON *.* TO 'monitor'@'%';
#在proxysql中将监控用户加入【主服务器proxysql】
UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_username';
UPDATE global_variables SET variable_value='monitor' WHERE variable_name='mysql-monitor_password';
#将Master和slave节点添加到mysql_servers表中【主服务器proxysql】
#-- Master主节点
INSERT INTO mysql_servers(hostgroup_id,hostname,port,weight,comment) VALUES (1,'192.168.25.26',3306,1,'Write group');
#-- slave节点
INSERT INTO mysql_servers(hostgroup_id,hostname,port,weight,comment) VALUES (2,'192.168.25.27',3306,1,'Read group');
#-- 保存
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
#查看添加的mysql集群
SELECT * FROM mysql_servers;
#5在MySQL主从节点上创建用户,赋予权限,并将其存储到代理服务器中
#在主服务器上创建账户就行,从服务器上也同步有了
#-- 在Master节点和slave节点上创建adm用户,设置为管理员权限。【主服务器mysql】
CREATE USER 'adm'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO 'adm'@'%';
#-- 在Master节点和slave节点上创建用户read,并设置权限为只读。【主服务器mysql】
CREATE USER 'read'@'%' IDENTIFIED BY '123456';
GRANT SELECT ON *.* TO 'read'@'%';
FLUSH PRIVILEGES;
#6在proxysql上添加用户 【主服务器proxysql】
#-- 在proxysql上添加用户
INSERT INTO mysql_users(username,password,default_hostgroup) VALUES ('adm','123456',1);
INSERT INTO mysql_users(username,password,default_hostgroup) VALUES ('read','123456',2);
#-- 保存
LOAD MYSQL USERS TO RUNTIME;
SAVE MYSQL USERS TO DISK;
select hostgroup_id, hostname, port,status from runtime_mysql_servers;
#这是结果
+--------------+---------------+------+--------+
| hostgroup_id | hostname | port | status |
+--------------+---------------+------+--------+
| 1 | 192.168.25.22 | 3306 | ONLINE |
| 2 | 192.168.25.23 | 3306 | ONLINE |
+--------------+---------------+------+--------+
#7在proxysql上配置读写规则 【主服务器proxysql】
#参数介绍:
# rule_id为1,表示规则的唯一标识符。
# active为1,表示规则处于激活状态。
# match_digest为'^SELECT.*FROM UPDATE$',表示匹配查询语句,以SELECT开头,中间可以有任意字符,以FROM UPDATE结尾。
# destination_hostgroup为1,表示匹配成功后,将查询请求发送到hostgroup 1。
# apply为1,表示应用该规则。
INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (1,1,'^SELECT.*FROM UPDATE$',1,1);
INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (2,1,'^SELECT',2,1);
INSERT INTO mysql_query_rules (rule_id,active,match_digest,destination_hostgroup,apply) VALUES (3,1,'^SHOW',2,1);
-- 保存规则
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
-- 查看规则
select rule_id,match_digest,destination_hostgroup,apply from mysql_query_rules order by rule_id;
#这是结果
+---------+-----------------------+-----------------------+-------+
| rule_id | match_digest | destination_hostgroup | apply |
+---------+-----------------------+-----------------------+-------+
| 1 | ^SELECT.*FROM UPDATE$ | 1 | 1 |
| 2 | ^SELECT | 2 | 1 |
| 3 | ^SHOW | 2 | 1 |
+---------+-----------------------+-----------------------+-------+
#8.测试能否正常读取【主服务器】
mysql -uread -p123456 -h 127.0.0.1 -P6033 -e "SELECT @@hostname,@@port"
# 在代理服务器上执行读操作【安装proxysql的服务器】
mysql -uread -p123456 -h 127.0.0.1 -P6033 -e "show databases;"
# 执行创建操作,测试效果【安装proxysql的服务器】
mysql -uadm -p123456 -h 127.0.0.1 -P6033 -e "create database test2;"
# 再次查询【安装proxysql的服务器】
mysql -uread -p123456 -h 127.0.0.1 -P6033 -e "show databases;"
#在代理服务器中查询执行记录【安装proxysql的服务器】
mysql -uadmin -padmin -h127.0.0.1 -P6032 【这是登陆proxysql服务器】
select hostgroup,digest_text from stats_mysql_query_digest\G;
#这是结果
*************************** 1. row ***************************
hostgroup: 1
digest_text: create database test2
*************************** 2. row ***************************
hostgroup: 2
digest_text: show databases
*************************** 3. row ***************************
hostgroup: 1
digest_text: select @@version_comment limit ?
*************************** 4. row ***************************
hostgroup: 2
digest_text: SELECT @@hostname,@@port
*************************** 5. row ***************************
hostgroup: 2
digest_text: select @@version_comment limit ?
5 rows in set (0.00 sec)
ERROR:
No query specified
## ProxySQL保存配置:【主服务器proxysql】
# 修改后重新加载服务并保存配置,防止重启服务器后配置丢失。
#-- 重新加载并保存服务器设置
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
#-- 重新加载并保存查询设置
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
#-- 重新加载并保存用户设置
LOAD MYSQL USERS TO RUNTIME;
SAVE MYSQL USERS TO DISK;
#-- 重新加载并保存变量设置
LOAD MYSQL VARIABLES TO RUNTIME;
SAVE MYSQL VARIABLES TO DISK;
重置配置方法
如果你遇到 ProxySQL 配置错误,需要删除或重置配置,通常可以按照以下步骤操作:
#1. 删除错误配置
#连接到 ProxySQL 数据库:
#使用 mysql 命令行工具或其他 MySQL 客户端连接到 ProxySQL 实例。默认情况下,ProxySQL 的管理界面监听在 3306 端口(也可能是其他端口,取决于你的配置)。
mysql -u admin -p -h 127.0.0.1 -P 6032
#这里 6032 是 ProxySQL 默认的管理端口,admin 是默认的管理用户。
#查看当前配置: 在管理控制台中,你可以使用以下命令查看当前配置:
SELECT * FROM mysql_servers;
SELECT * FROM mysql_users;
#删除或修改错误配置: 假设你要删除某个错误的服务器配置:
DELETE FROM mysql_servers WHERE hostname='错误的主机名';
#对于用户配置,可以用类似的方式删除:
DELETE FROM mysql_users WHERE username='错误的用户名';
#应用更改: 删除或修改配置后,记得应用更改到 ProxySQL 配置:
LOAD MYSQL SERVERS TO RUNTIME;
SAVE MYSQL SERVERS TO DISK;
#对于用户配置:
LOAD MYSQL USERS TO RUNTIME;
SAVE MYSQL USERS TO DISK;
-------------------------------
#2. 重置 ProxySQL 配置
#方法一:可以执行初始化命令:
proxysql --initial
#方法二:也可以删除所有配置并重新加载:
1.删除所有配置:
-- 删除所有的 MySQL 服务器配置
DELETE FROM mysql_servers;
-- 删除所有的 MySQL 用户配置
DELETE FROM mysql_users;
-- 删除所有的 MySQL 规则配置
DELETE FROM mysql_query_rules;
-- 删除所有的 MySQL 监控配置
DELETE FROM stats_mysql_status;
2.重新加载配置:
-- 将删除的配置应用到运行时
LOAD MYSQL SERVERS TO RUNTIME;
LOAD MYSQL USERS TO RUNTIME;
LOAD MYSQL QUERY RULES TO RUNTIME;
-- 将运行时配置保存到磁盘
SAVE MYSQL SERVERS TO DISK;
SAVE MYSQL USERS TO DISK;
SAVE MYSQL QUERY RULES TO DISK;
## 退出重启服务
sudo systemctl restart proxysql
3. 其他检查
确保 ProxySQL 配置文件(通常是 proxysql.cnf)中没有错误,并检查任何可能的日志文件来确认问题的具体细节。
这些步骤应该能帮助你解决 ProxySQL 配置错误。如果问题依然存在,可能需要更详细地检查 ProxySQL 的日志或配置文档。
15.MySQL分库分表与MyCAT
分库分表:
分库:拆分数据库,当单台数据库服务器存储容量不足时,或者并发量过高,单机资源不足。
分表:拆分数据表,当单表数据量过大时,索引(B+树)查询效率会变低,2千万数据左右。
方法:
-
垂直分库:将原本一个库中的表分到不同的库中。
![640]()
-
垂直分表:将原来的表,按字段拆分成多个表。![640]
![640-17555679860852]()
-
水平分库:按照数据内容拆分,例如按年月拆分数据、数据范围拆分、模运算拆分。
- 水平分表:按照内容来拆分表。
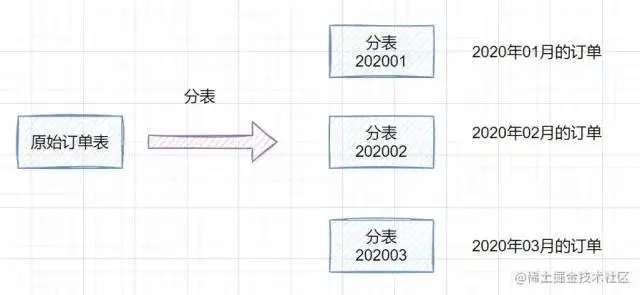
全局ID
是指能够在整个系统范围内唯一标识一条数据记录的标识符。它的核心作用是解决分布式环境下,由于数据分散存储(如分库分表、多服务实例)导致的本地 ID 重复问题,确保所有数据记录的标识在全局范围内不冲突。
MyCAT
使用MyCAT分布式集群中间件,可以实现分库、分表、读写分离、负载均衡、故障(屏蔽)转移。
MyCAT支持MySQL网络协议,可以使用mysql客户端进行操作。
使用java语言开发,安装java运行环境(jdk)。
配置文件常见的格式
- ini : xxx.ini /xxx.conf /xxx.cnf /xxx.repo
- MySQL,yum源
[mysqld]
base_dir=/usrl/local/mysql
date_dir=/usrl/local/mysql/data
·······
- xml : 标签语言,常用于java项目、大数据
- Apache,TomCat
<student>
<id>1001</id>
<name>Alice</name>
<age>20</age>
<courses>
<course>Math</course>
<course>English</course>
</courses>
</student>
- json : JavaScript 对象表示法。API接口数据交换、配置文件、存储简单结构化数据等。
- mycat,Nodejs
{
"student": {
"id": 1001,
"name": "Alice",
"age": 20,
"courses": ["Math", "English"]
}
}
- yaml : 采用缩进表示层级关系,语法简洁,可读性强,支持复杂数据结构,如列表、字典等。
- Docker,K8S
# 嵌套对象(类似JSON的对象)
student:
name: Bob
age: 22
courses: # 嵌套数组
- Math
- English
- Computer Science
MyCAT的安装
#1.准备一台下载好MySQL的服务器
#安装JDK1.8
# CentOS7
yum -y install java-1.8.0-openjdk.x86_64
# 测试安装,显示java版本则为安装成功
java -version
#输出
openjdk version "1.8.0_412"
OpenJDK Runtime Environment (build 1.8.0_412-b08)
OpenJDK 64-Bit Server VM (build 25.412-b08, mixed mode)
#2.安装MyCAT2
#创建/usr/local/src
mkdir -p /usr/local/src
#进入/usr/local/src目录
cd /usr/local/src
#在src目录里下载mycat和依赖环境
# 如果没有wget
# CentOS7安装wget
yum -y install wget
# 第三方下载
wget https://download.topunix.com/MySQL/Software-Cluster/Software-Mycat/Mycat2/mycat2-install-template-1.20.zip
wget https://download.topunix.com/MySQL/Software-Cluster/Software-Mycat/Mycat2/mycat2-1.21-release-jar-with-dependencies.jar
# 局域网下载(192.168.56.200)
wget http://192.168.56.200/Software/mycat2-install-template-1.21.zip
wget http://192.168.56.200/Software/mycat2-1.21-release-jar-with-dependencies.jar
#3.下载完成后检查下载文件是否正确
[root@26_mycat src]# ls
mycat2-1.21-release-jar-with-dependencies.jar mycat2-install-template-1.21.zip
#4.解压并移动到/usr/local目录下
# 没有解压缩工具先下载解压缩工具
yum -y install unzip
# 解压Mycat2
unzip mycat2-install-template-1.21.zip
#把解压完的mycat移动到/usr/local/mycat
mv mycat ../
#5.把bin目录的文件加执行权限
cd /usr/local/mycat/
chmod +x bin/*
#把所需的jar复制到mycat/lib目录
# mycat2-1.21-release-jar-with-dependencies.jar是MyCAT2依赖文件,缺失会导致MyCAT启动失败
cp /usr/local/src/mycat2-1.21-release-jar-with-dependencies.jar /usr/local/mycat/lib/
#移动完查看一下是否正确
#检查mycat结构是否正确
drwxr-xr-x 2 root root 4096 3月 5 2021 bin
drwxr-xr-x 9 root root 275 3月 5 2021 conf
drwxr-xr-x 2 root root 4096 8月 19 11:15 lib
drwxr-xr-x 2 root root 6 3月 5 2021 logs
#bin 执行命令的目录
#conf 配置文件
#lib 依赖包
#logs 日志包
#6.配置系统环境变量,让我们可以在任意位置执行mycat命令
#先查到mycat里bin目录的位置
cd bin/
pwd
/usr/local/mycat/bin
#编辑环境变量
vim /etc/profile
#在末尾添加
#export PATH=$PATH:/usr/local/mycat/bin
export MYCAT_PATH=/usr/local/mycat
export MYSQL_PATH=/usr/local/mysql
export PATH="$MYSQL_PATH/bin:$MYCAT_PATH/bin:$PATH"
#加载环境变量
source /etc/profile
#7.启动一个3306的MySQL
#启动mysql服务
service mysqld start
# 能够连接而上mysql
mysql -uroot -proot123
#8.配置物理库地址
#打开并修改配置文件
vim /usr/local/mycat/conf/datasources/prototypeDs.datasource.json
#修改成
{
"dbType": "mysql",
"idleTimeout": 60000,
"initSqls": [],
"initSqlsGetConnection": true,
"instanceType": "READ_WRITE",
"maxCon": 1000,
"maxConnectTimeout": 3000,
"maxRetryCount": 5,
"minCon": 1,
"name": "prototypeDs",
"password": "root123",
"type": "JDBC",
"url": "jdbc:mysql://localhost:3306?useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8",
"user": "root",
"weight": 0
}
#9.启动MyCAT
#设置了环境变量,可在任意位置执行mycat命令
cd /usr/local/mycat/bin
./mycat start 启动
./mycat stop 停止
./mycat console 前台运行
./mycat install 添加到系统自动启动
./mycat remove 取消随系统自动启动
./mycat restart 重启
./mycat pause 暂停
./mycat status 查看启动状态
#启动mycat
mycat start
#10.查看logs/wrapper.log文档看有无错误
cat /usr/local/mycat/logs/wrapper.log
#正确结果
STATUS | wrapper | 2025/08/19 11:50:25 | --> Wrapper Started as Daemon
STATUS | wrapper | 2025/08/19 11:50:25 | Launching a JVM...
INFO | jvm 1 | 2025/08/19 11:50:25 | Wrapper (Version 3.2.3) http://wrapper.tanukisoftware.org
INFO | jvm 1 | 2025/08/19 11:50:25 | Copyright 1999-2006 Tanuki Software, Inc. All Rights Reserved.
INFO | jvm 1 | 2025/08/19 11:50:25 |
INFO | jvm 1 | 2025/08/19 11:50:26 | path:/usr/local/mycat/./conf
INFO | jvm 1 | 2025/08/19 11:50:26 | 2025-08-19 11:50:26,214[INFO]io.mycat.MycatCore.newMycatServer:213start VertxMycatServer
INFO | jvm 1 | 2025/08/19 11:50:26 | 2025-08-19 11:50:26,571[INFO]com.alibaba.druid.pool.DruidDataSource.init:990{dataSource-1} inited
INFO | jvm 1 | 2025/08/19 11:50:26 | 2025-08-19 11:50:26,828[INFO]io.mycat.replica.heartbeat.HeartbeatFlow.sendDataSourceStatus:71prototypeDs heartStatus DatasourceStatus(status=OK_STATUS, isSlaveBehindMaster=false, dbSynStatus=DB_SYN_NORMAL, master=true)
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,760[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server 5ace8c13-1dad-4e02-acac-6615ae3140a3 started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,761[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server d93fb9b5-91b0-42c6-866a-62047715eed6 started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,770[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server 59488811-db7f-4dbb-a8da-bcb6da18a9e4 started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,771[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server 5e34af6f-0c85-403d-9f6e-746ce1faa525 started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,771[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server dbf9feeb-3767-4c6f-b351-f5b48a3a8f81 started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,772[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server f89e3d87-c1eb-4f00-980e-11f11f3d6524 started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,773[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server a60a85f5-dc07-49b3-9822-a56e68bf91af started up.
INFO | jvm 1 | 2025/08/19 11:50:27 | 2025-08-19 11:50:27,790[INFO]io.mycat.vertx.VertxMycatServer.lambda$start$1:120Mycat Vertx server 2213c4b3-a110-4328-8ba2-252170fa2c1a started up.
#11.连接MyCAT
MyCAT的默认用户是:root
初始密码是:123456
端口号是:8066
#使用MySQL默认客户端或者mycli命令行登陆MyCAT
mysql -uroot -p123456 -P8066 -h127.0.0.1
# 或者
mycli -uroot -P8066 -h"127.0.0.1"
#看看是否能进入mycat 界面 ,也支持第三方软件登陆mycat
# Navicat for MySQL 对MyCAT支持查询
概念
数据源:datasource MyCAT用于连接后端的MySQL数据库,连接信息
- 用户名、密码、IP
- 配置文位置 :/usr/local/mycat/conf/datasources/{数据源名字}.datasource.json
MyCAT集群设置:对后端MySQL进行组合设置,例如主、从、只读、读写、分库、分表
- clusters:设置集群
MyCAT用户设置:users 里修改用户信息密码
- 配置文件位置 /usr/local/mycat/conf/users/{用户名}.user.json
MyCAT逻辑库设置:schemas
- 配置文件位置: /usr/local/mycat/conf/schemas/{库名}.schema.json
mycat注释指令:
#登陆mycat
mysql -uroot -proot123 -P8066 -h127.0.0.1
#清空所有配置
/*+ mycat:resetConfig{} */;
mycat restart 重启
#创建用户
/*+ mycat:createUser{
"username":"user"【用户名】,
"password":""【密码】,
"ip":"127.0.0.1"【也可写null,允许所有登陆】,
"transactionType":"xa"}
*/;
mycat restart 重启
#查看用户
/*+ mycat:showUsers */;
#删除用户
/*+ mycat:dropUser{ "username":"user"【要删除的用户名】} */;
mycat restart 重启
数据源指令:
#登陆mycat
mysql -uroot -proot123 -P8066 -h127.0.0.1
#创建数据源
/*+ mycat:createDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"dc1",
"password":"root123",
"type":"JDBC",
"url":"jdbc:mysql://127.0.0.1:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",
"weight":0}
*/;
#删除数据源
/*+ mycat:dropDataSource{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":3000,
"maxRetryCount":5,
"minCon":1,
"name":"dc1",
"type":"JDBC",
"weight":0}
*/;
#查看数据源
/*+ mycat:showDataSources{} */;
集群相关指令:
#登陆mycat
mysql -uroot -p123456 -P8066 -h127.0.0.1
#创建集群
/*! mycat:createCluster{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[ "dc1" //主节点 ],
"maxCon":2000,
"name":"c0",
"readBalanceType":"BALANCE_ALL",
"replicas":[ "dc2" //从节点 ],
"switchType":"SWITCH"}
*/;
#删除集群
/*! mycat:dropCluster{ "name":"c0"} */;
#查看集群
/*+ mycat:showClusters{} */;
MyCAT一主一从读写分离
#准备三台安装好MySQL的服务器
#两台服务器搭建主从连接 两台服务器都需要创建远程连接账号
#一台安装MyCAT mysql -uroot -proot123 -P8066 -h127.0.0.1 -A db1【新建的库名】
#在mycat服务器上操作
#创建数据源
#-- 重置配置
/*+ mycat:resetConfig{} */ 【可选】
#1.添加读写的数据源 【添加主服务器】
/*+ mycat:createDataSource
{
"dbType": "mysql",
"idleTimeout": 60000,
"initSqls": [],
"initSqlsGetConnection": true,
"instanceType": "READ_WRITE",
"maxCon": 1000,
"maxConnectTimeout": 3000,
"maxRetryCount": 5,
"minCon": 1,
"name": "m1",
"password": "root123",
"type": "JDBC",
"url": "jdbc:mysql://192.168.25.27:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user": "root",
"weight": 0
}
*/;
#2.添加读的数据源 【添加从服务器】
/*+ mycat:createDataSource
{
"dbType": "mysql",
"idleTimeout": 60000,
"initSqls": [],
"initSqlsGetConnection": true,
"instanceType": "READ",
"maxCon": 1000,
"maxConnectTimeout": 3000,
"maxRetryCount": 5,
"minCon": 1,
"name": "m1s1",
"password": "root123",
"type": "JDBC",
"url": "jdbc:mysql://192.168.25.28:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user": "root",
"weight": 0
}
*/;
# 查询数据源 是否添加成功
/*+ mycat:showDataSources{} */;
#3.创建集群
/*! mycat:createCluster{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetry":3,
"minSwitchTimeInterval":300,
"slaveThreshold":0
},
"masters":[
"m1"
],
"maxCon":2000,
"name":"ji_qun1",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"m1s1"
],
"switchType":"SWITCH"
} */;
#查询集群是否创建正确
/*! mycat:showClusters{} */;
#4. 创建逻辑库
#在mycat上创建逻辑库 ,主从数据库上都应该存在
CREATE DATABASE db1 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
#修改逻辑库的数据源
vim /usr/local/mycat/conf/schemas/db1.schema.json
## 在里面添加集群的名称,作用是让该集群生成并管理这个库的物理库
"targetName":"ji_qun1"
#重启MyCAT:
mycat restart
#5.测试读写分离是否成功(在MyCAT里面测试)
#在MyCAT里面的db1库里创建一个sys_user表:
CREATE TABLE sys_user( ID BIGINT PRIMARY KEY, USERNAME VARCHAR(200) NOT NULL, ADDRESS VARCHAR(500));
#检查主从数据库内是否存在我们创建的表
#通过注释生成物理库和物理表:
#如果物理表不存在,在 MyCAT2 能正常启动的情况下,根据当前配置自动创建分片表,全局表和物理表:
/*+ mycat:repairPhysicalTable{} */;
#查看后端物理库:发现物理库和物理表都生成了。
#在MyCAT里面向sys_user表添加一条数据:
INSERT INTO sys_user(ID,USERNAME,ADDRESS) VALUES(1,"XIAOMING","WUHAN");
#查看主从库里的先对应的表中内容有没有添加上
#6.测试负载均衡
#把从库中表的内容修改之后, 在mycat上查看表中的内容 ,会发现每次查询的结果不一样:
mysql> select * from sys_user;
+----+----------+---------+
| ID | USERNAME | ADDRESS |
+----+----------+---------+
| 1 | XIAOMING | WUHAN |
+----+----------+---------+
1 row in set (0.00 sec)
om.alibaba.druid.sql.parser.ParserException: syntax error, expect STATUS, actual EOF, pos 10, line 1, column 11, token EOF
mysql> select * from sys_user;
+----+----------+---------+
| ID | USERNAME | ADDRESS |
+----+----------+---------+
| 1 | zhangsan | sanxi |
+----+----------+---------+
1 row in set (0.01 sec)
om.alibaba.druid.sql.parser.ParserException: syntax error, expect STATUS, actual EOF, pos 10, line 1, column 11, token EOF
#到此,我们使用MyCAT2主从搭建就完成了。
#在mycat上创建逻辑库,主库不同步
#写个脚本一件操作
/usr/local/mycat/bin/create_db.sh
vim create_db.sh
#!/bin/bash
# /usr/local/mycat/bin/create_db.sh
# 一键:1) 主库建物理库 2) MyCat建逻辑库 3) 生成db.schema.json并绑定集群
set -e
DB_NAME=$1
[ -z "$DB_NAME" ] && { echo "Usage: $0 <db_name>"; exit 1; }
############## 可改成你自己的环境变量 ################
MASTER_HOST=192.168.25.22
MASTER_PORT=3306
MASTER_USER=root
MASTER_PWD=root123
MYCAT_HOST=127.0.0.1
MYCAT_PORT=8066
MYCAT_USER=root
MYCAT_PWD=root123
# MyCat2 的 schemas 目录
SCHEMA_DIR=/usr/local/mycat/conf/schemas
CLUSTER_NAME=ji_qun1 # 你的一主一从集群名
######################################################
echo "=> Creating physical database '$DB_NAME' on master..."
mysql -h$MASTER_HOST -P$MASTER_PORT -u$MASTER_USER -p$MASTER_PWD \
-e "CREATE DATABASE IF NOT EXISTS \`$DB_NAME\` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;"
echo "=> Creating logical database '$DB_NAME' in MyCat..."
mysql -h$MYCAT_HOST -P$MYCAT_PORT -u$MYCAT_USER -p$MYCAT_PWD \
-e "CREATE DATABASE \`$DB_NAME\`;"
echo "=> Writing $SCHEMA_DIR/${DB_NAME}.schema.json ..."
cat > "$SCHEMA_DIR/${DB_NAME}.schema.json" <<EOF
{
"customTables": {},
"globalTables": {},
"normalProcedures": {},
"normalTables": {},
"schemaName": "${DB_NAME}",
"shardingTables": {},
"targetName": "${CLUSTER_NAME}",
"views": {}
}
EOF
echo "=> Reload MyCat config..."
mysql -h$MYCAT_HOST -P$MYCAT_PORT -u$MYCAT_USER -p$MYCAT_PWD \
-e "/*+ mycat:reloadConfig{} */;" 2>/dev/null || true
echo "✅ 物理库 + 逻辑库 + schema.json 全部就绪!"
#使用这个脚本一件创建库
./reate_db.sh ku1【库名】
--------------------------------------------------------
#创建好后新建表后,在检查一下库相关的配置文件 集群源是否正确
/usr/local/mycat/conf/schemas
库名.schema.json
MyCAT分库分表实验
#准备五个数据库 服务器 每个都创建好远程登陆账号
#一个mycat服务器
192.168.25.26 8066 127.0.0.1
#两对主从服务器 dw0-dr0 ,dw1-dr1
dw0 192.168.25.27 3306
dr0 192.168.25.28 3306
dw1 192.168.25.29 3306
dr1 192.168.25.30 3306
- 配置MyCAT数据源
通过上面的配置,我们准备了两组主从,分别为:
主服务器dw0 从服务器dr0
主服务器dw1 从服务器dr1
接下来,我们要在MyCAT里面配置这四个数据源。
#-- 添加dw0数据源
/*+ mycat:createDataSource
{ "name":"dw0",
"password":"root123",
"url":"jdbc:mysql://192.168.25.27:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",}
*/;
#-- 添加dr0数据源
/*+ mycat:createDataSource
{ "name":"dr0",
"password":"root123",
"url":"jdbc:mysql://192.168.25.28:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",}
*/;
#-- 添加dw1数据源
/*+ mycat:createDataSource
{ "name":"dw1",
"password":"root123",
"url":"jdbc:mysql://192.168.25.29:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",}
*/;
#-- 添加dr1数据源
/*+ mycat:createDataSource
{ "name":"dr1",
"password":"root123",
"url":"jdbc:mysql://192.168.25.30:3306?useUnicode=true&serverTimezone=UTC&characterEncoding=UTF-8",
"user":"root",}
*/;
#-- 查看数据源
/*+ mycat:showDataSources{} */;
执行之后我们在MyCAT里面看到如下数据源的配置文件。
- 配置MyCAT集群配置
注意:自动分片默认要求集群名字以c为前缀,数字为后缀:
c0就是分片表第一个节点;
c1就是第二个节点。
一般情况下我们使用默认的就可以了。
/*! mycat:createCluster{ "name":"c0", "masters":[ "dw0" ], "replicas":[ "dr0" ]} */;
/*! mycat:createCluster{ "name":"c1", "masters":[ "dw1" ], "replicas":[ "dr1" ]} */;
#-- 查看集群
/*+ mycat:showClusters{} */;
创建完成之后查看MyCAT配置文件里面内容如下:
#集群的文件的内容是
{
"clusterType": "MASTER_SLAVE",
"heartbeat": {
"heartbeatTimeout": 1000,
"maxRetryCount": 3,
"minSwitchTimeInterval": 300,
"showLog": false,
"slaveThreshold": 0.0
},
"masters": [
"dw0"
],
"maxCon": 2000,
"name": "c0",
"readBalanceType": "BALANCE_ALL",
"replicas": [
"dr0"
],
"switchType": "SWITCH"
}
- 全局表配置
全局表:所有分片库中都有全量数据的表。分库分表的环境准备好之后,接下来我们在MyCAT里面执行相关的命令,就可以帮我们创建全局表。
#1.创建库
# 确保五个数据库都创建了这个库
CREATE DATABASE db1 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
#2.在mycat上创建好库后在库里创建全局表
use db1;
CREATE TABLE `sys_dict` ( `id` bigint NOT NULL AUTO_INCREMENT,
`dict_type` int ,
`dict_name` varchar(100) DEFAULT NULL,
`dict_value` int , PRIMARY KEY (`id`)
) ENGINE=InnoDB
DEFAULT CHARSET=utf8mb4
BROADCAST;
# 上面的SQL中有一个BROADCAST 这个就是全局表的标识。
#创建好表后检查四个数据库是否都有这个表
其mycat配置文件是这个的 /usr/local/mycat/conf/schemas/db1.schema.json
后端数据库中发现所有的表全部出现了。
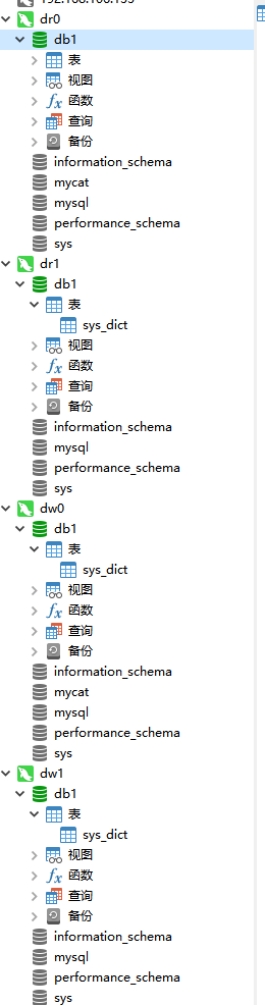
#2.添加数据查看结果
INSERT INTO sys_dict(dict_type,dict_name,dict_value) VALUES(1,"男",1);
INSERT INTO sys_dict(dict_type,dict_name,dict_value) VALUES(1,"女",0);
# 所有的库中都有的数据
#3.查询数据查看结果
select * from sys_dict;
发现数据并没有重复。每个数据库都查询一下数据 看看是否都存在
- 分片表配置
分片表是指按照预设规则将单表数据分散存储到多个物理表(分片) 的表。这些物理表分布在不同的数据库(分片库)中,但对应用层(如 MySQL 客户端)暴露为一个 “逻辑表”,应用无需感知底层分片细节。
关键字:dbpartition、tbpartitition、tbpartitions、dbpartitions。以上的运行成功必须是c0、c1的数据源配置没有问题才行。
#1.创建表
CREATE TABLE orders( ID BIGINT NOT NULL AUTO_INCREMENT,
ORDER_TYPE INT, CUSTOMER_ID INT,
AMOUNT DECIMAL(10,2), PRIMARY KEY(ID)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
dbpartition BY mod_hash(CUSTOMER_ID)
dbpartitions 2
tbpartition By mod_hash(CUSTOMER_ID)
tbpartitions 1;
# dbpartition BY mod_hash(CUSTOMER_ID): 指定数据库的分片算法及使用哪一条数据进行分片
# tbpartition BY mod_hash(CUSTOMER_ID) :指定表的分片算法及使用哪一条数据进行分片
# dbpartitions 2 数据库的分片数量
# tbpartitions 1 表的分片数量
查看mycat生成的配置文件 /usr/local/mycat/conf/schemas/db1.schema.json

#添加数据
INSERT INTO orders(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(1,101,100,100101);
INSERT INTO orders(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(2,101,100,100101);
INSERT INTO orders(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(3,101,100,100101);
INSERT INTO orders(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(4,102,101,101102);
INSERT INTO orders(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(5,102,101,101102);
INSERT INTO orders(ID,ORDER_TYPE,CUSTOMER_ID,AMOUNT) VALUES(6,102,101,101102);
添加完成后,查询后台物理库
从图中我们可以看到数据库生成了。打开数据库后,里面的表也生成了,里面的数据也分开了,并不在一个表里。
MyCAT中查询
从上图中,我们发现查询的结果也帮我们合并了。
- ER表配置
ER 表是与主分片表存在强关联关系(如父子关系)的表,通常跟随主表的分片规则存储(即 “主表和 ER 表在同一个分片”),用于解决分库分表后的跨分片关联查询问题。
说明:在1.6的版本中,我们ER表的配置有关系的数据必须存放在相同的库中,但是在2.0中不用了,MyCAT2自动帮我们优化了。上面我们创建了一张订单表,接下来我们创建一张订单详情表。
#创建表
CREATE TABLE orders_detail( id BIGINT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id BIGINT, PRIMARY KEY(ID)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4
dbpartition BY mod_hash(order_id)
tbpartition By mod_hash(order_id)
tbpartitions 1
dbpartitions 2;
# dbpartition BY mod_hash(order_id) :指定数据库的分片算法及使用哪一条数据进行分片
# BY mod_hash(order_id) :指定表的分片算法及使用哪一条数据进行分片
# tbpartitions 1 表的分片数量
# dbpartitions 2 数据库的分片数量
查看MyCAT生成的配置
从上图中我们可以出已经放到分片表里面了。
#添加数据
INSERT INTO orders_detail VALUES(1,"详情1",1);
INSERT INTO orders_detail VALUES(2,"详情2",2);
INSERT INTO orders_detail VALUES(3,"详情3",3);
INSERT INTO orders_detail VALUES(4,"详情4",4);
INSERT INTO orders_detail VALUES(5,"详情5",5);
INSERT INTO orders_detail VALUES(6,"详情6",6);
查询后台物理库
从上图可知,dw0里面只存了三条

发现dw1里面也存放了三条。
MyCAT中关联查询

- 分片算法
- 取模哈希分片 MOD_HASH
- 如果分片值是字符串则先对字符串进行Hash转换为数值类型
- 分库键和分表键是同键
- 分表下标=分片值%(分库数量*分表数量)
- 分库下标=分表下标/分表数量
- 分库键和分表键是不同键
- 分表下标= 分片值%分表数量
- 分库下标 = 分片值%分库数量
create table travelrecord ( ....) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by MOD_HASH (id)
dbpartitions 6
tbpartition by MOD_HASH (id)
tbpartitions 6;
- 范围哈希分片 RANGE_HASH
- RANGE_HASH(字段1, 字段2, 截取开始下标)
- 仅支持数值类型,字符串类型
- 当时字符串类型时候,第三个参数生效
- 计算时候优先选择第一个字段,找不到选择第二个字段
- 如果是字符串则根据下标截取其后部分字符串,然后该字符串hash成数值
- 根据数值按分片数取余
- 要求截取下标不能少于实际值的长度
- 两个字段的数值类型要求一致
create table travelrecord(...)ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by RANGE_HASH(id,user_id,3)
dbpartitions 3
tbpartition by RANGE_HASH(id,user_id,3)
tbpartitions 3;
- 字符串哈希分片 UNI_HASH
- 如果分片值是字符串则先对字符串进行hash转换为数值类型
- 分库键和分表键是同键
- 分库下标=分片值%分库数量
- 分表下标=(分片值%分库数量)*分表数量+(分片值/分库数量)%分表数量
- 分库键和分表键是不同键
- 分表下标= 分片值%分表数量
- 分库下标=分片值%分库数量
create table travelrecord ( ....) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by UNI_HASH (id)
dbpartitions 6
tbpartition by UNI_HASH (id)
tbpartitions 6;
-
日期哈希分片 YYYYDD
-
仅用于分库
-
DD是一年之中的天数
-
(YYYY*366+DD)%分库数
-
create table travelrecord ( ....) ENGINE=InnoDB DEFAULT CHARSET=utf8
dbpartition by YYYYDD(xxx)
dbpartitions 8
tbpartition by xxx(xxx)
tbpartitions 12;
MHA高可用实验
VIP 指的是虚拟 IP 地址:VIP 的核心价值是 “地址不变,服务迁移”:
一、环境准备
- 服务器规划(至少3节点)
| 角色 | 主机名 | IP地址 | 说明 |
|---|---|---|---|
| Master | mha-node1 | 192.168.25.27 | 主库 |
| Slave1 | mha-node2 | 192.168.25.28 | 从库(候选主库) |
| Slave2 | mha-node3 | 192.168.25.29 | 从库 |
| Manager | mha-manager | 192.168.25.26 | MHA管理节点(独立服务器)可无MySQL |
- 基础配置(所有节点)所有服务器
# 关闭防火墙 所有节点执行
systemctl stop firewalld && systemctl disable firewalld
# 关闭SELinux 所有节点执行
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 配置hosts(所有节点一致)
cat >> /etc/hosts << EOF
192.168.25.27 mha-node1
192.168.25.28 mha-node2
192.168.25.29 mha-node3
192.168.25.26 mha-manager
EOF
# 配置SSH免密登录(manager节点需免密登录所有数据库节点,数据库节点间也需互信)所有节点执行
ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa
for host in mha-node1 mha-node2 mha-node3; do
ssh-copy-id -i ~/.ssh/id_rsa.pub $host
done
二、部署MySQL 8.0主从复制
- 安装MySQL 8.0(所有数据库节点:mha-node1、mha-node2、mha-node1)
# 这里使用MySQL安装脚本
cd /usr/local/src
wget http://192.168.56.200/Software/mysql_install.sh
bash mysql_install.sh
- 配置MySQL(主从差异化配置)确保主从配置文件里的bin_log 的条件都一致
Master(mha-node1)配置 主1
vim /etc/my.cnf
[mysqld]
# ...
# 在默认配置下方添加:
server-id=11 # 唯一ID
log_bin=mysql-bin # 开启binlog
binlog_format=ROW # ROW模式(MHA推荐)
gtid_mode=ON # 开启GTID
enforce_gtid_consistency=ON # 强制GTID一致性
log_slave_updates=ON # 从库同步时记录binlog(用于级联复制)
skip_name_resolve=ON # 跳过域名解析
systemctl restart mysqld
Slave(mha-node2/mha-node3)配置 从1从2
# mha-node2(server-id=12)
vim /etc/my.cnf
[mysqld]
# ...
server-id=12 # 唯一ID(mha-node3设为13)
log_bin=mysql-bin
binlog_format=ROW
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
skip_name_resolve=ON
relay_log=relay-bin # 开启中继日志
read_only=ON # 从库只读(可选)
systemctl restart mysqld
- 搭建主从复制(基于GTID)
在Master(mha-node1)创建复制用户
#-- MySQL 8.0默认认证插件为caching_sha2_password,MHA需用mysql_native_password
CREATE USER 'repl'@'192.168.25.%' IDENTIFIED WITH mysql_native_password BY 'Repl@123';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.25.%';
FLUSH PRIVILEGES;
在Slave(mha-node2/mha-node3)配置复制
#-- 登录Slave的MySQL
CHANGE MASTER TO
MASTER_HOST='mha-node1',
MASTER_USER='repl',
MASTER_PASSWORD='Repl@123',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1; # 基于GTID自动定位
#-- 启动复制
START SLAVE;
#-- 检查复制状态(确保Slave_IO_Running和Slave_SQL_Running均为Yes)
SHOW SLAVE STATUS\G;
三、部署MHA
- 安装依赖(所有节点) 所有服务器
CentOS7安装依赖
# 配置本地Yum源
vim /etc/yum.repos.d/CentOS-Media.repo
[c7-media]
name=CentOS-$releasever - Media
baseurl=file:///media/CentOS/
file:///media/cdrom/
file:///media/cdrecorder/
gpgcheck=1
enabled=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
# 挂载光盘
mount -r /dev/sr0 /media/cdrom
# 安装wget
yum install -y wget
# 配置网络Yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
# 配置Yum扩展源
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
# 安装Perl依赖(MHA基于Perl开发)
yum install -y perl-DBD-MySQL perl-CPAN perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker
yum install -y perl-Email-Sender perl-Email-Valid perl-Mail-Sender
Ubuntu22.04安装依赖包
sudo apt install -y perl libdbi-perl libdbd-mysql-perl libperl-dev libconfig-tiny-perl liblog-dispatch-perl libparallel-forkmanager-perl
- 安装MHA包
下载MHA源码包
# 在教室可以使用局域网下载
# 管理节点下载 mha的服务器
wget http://192.168.56.200/Software/mha4mysql-manager-0.58.tar.gz
# 所有节点下载 所有服务器
wget http://192.168.56.200/Software/mha4mysql-node-0.58.tar.gz
# github下载
# 管理节点下载
# wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58.tar.gz
# 所有节点下载
# wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58.tar.gz
安装MHA Node(所有节点)所有服务器
tar -zxvf mha4mysql-node-0.58.tar.gz
cd mha4mysql-node-0.58
perl Makefile.PL
make && make install
安装MHA Manager(仅manager节点)mha服务器
tar -zxvf mha4mysql-manager-0.58.tar.gz
cd mha4mysql-manager-0.58
perl Makefile.PL
make && make install
# 创建MHA工作目录
mkdir -p /etc/mha/mha_cluster /var/log/mha/mha_cluster
manager组件安装后在/usr/local/bin下面会生成几个工具,主要包括以下几个:
- masterha_check_ssh 检查 MHA 的 SSH 配置状况
- masterha_check_repl 检查 MySQL 复制状况cd
- masterha_manger 启动 manager的脚本
- masterha_check_status 检测当前 MHA 运行状态
- masterha_master_monitor 检测 master 是否宕机
- masterha_master_switch 控制故障转移(自动或者手动)
- masterha_conf_host 添加或删除配置的 server 信息
- masterha_stop 关闭manager
node组件安装后也会在/usr/local/bin 下面会生成几个脚本(这些工具通常由 MHAManager 的脚本触发,无需人为操作)主要如下:
- save_binary_logs 保存和复制 master 的二进制日志
- apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的 slave
- filter_mysqlbinlog 去除不必要的 ROLLBACK 事件
- purge_relay_logs 清除中继日志(Relay-log)
- 配置MHA
创建MHA配置文件(manager节点)mha服务器
cat > /etc/mha/mha_cluster.cnf << EOF
[server default]
# MHA管理用户(需在所有MySQL节点创建)
user=mha_user
password=Mha@123
# SSH登录用户
ssh_user=root
# MySQL复制用户
repl_user=repl
repl_password=Repl@123
# 健康检查间隔(秒)
ping_interval=1
# master的binlog目录
master_binlog_dir=/usr/local/mysql/data
# 远程节点临时目录
remote_workdir=/tmp
# 二次检查节点
secondary_check_script=masterha_secondary_check -s mha-node2 -s mha-node3
# manager工作目录
manager_workdir=/var/log/mha/mha_cluster
# manager日志
manager_log=/var/log/mha/mha_cluster/manager.log
[server1]
hostname=mha-node1
port=3306
# 不优先作为候选主库
candidate_master=0
[server2]
hostname=mha-node2
port=3306
# 优先作为候选主库(数据最新时)
candidate_master=1
# 忽略复制延迟,强制作为候选
check_repl_delay=0
[server3]
hostname=mha-node3
port=3306
candidate_master=0
EOF
创建MHA管理用户(所有MySQL节点)在主服务器上创建用户,从服务器上也会有同步生成
CREATE USER 'mha_user'@'192.168.25.%' IDENTIFIED WITH mysql_native_password BY 'Mha@123';
GRANT ALL PRIVILEGES ON *.* TO 'mha_user'@'192.168.25.%';
FLUSH PRIVILEGES;
四、验证MHA配置
- 检查SSH连接(manager节点) mha服务器
masterha_check_ssh --conf=/etc/mha/mha_cluster.cnf
# 输出"All SSH connection tests passed successfully."即为正常
- 检查主从复制(manager节点)mha服务器
masterha_check_repl --conf=/etc/mha/mha_cluster.cnf
# 输出"MySQL Replication Health is OK."即为正常
五、启动MHA Manager mha服务器
# 前台启动(测试用,日志实时输出)
masterha_manager --conf=/etc/mha/mha_cluster.cnf
# 后台启动(生产用)
nohup masterha_manager --conf=/etc/mha/mha_cluster.cnf > /var/log/mha/mha_cluster/nohup.log 2>&1 &
# 检查MHA状态
masterha_check_status --conf=/etc/mha/mha_cluster.cnf
# 输出"mha_cluster (pid: xxxx) is running(0:PING_OK)"即为正常运行
六、测试故障切换
- 模拟Master故障(在mha-node1执行)主数据库
systemctl stop mysqld # 停止主库服务
- 观察故障切换(manager节点日志)mha服务器
tail -f /var/log/mha/mha_cluster/manager.log
# 正常情况下,日志会显示:
# - 检测到master故障
# - 提升mha-node2为新master
# - 其他slave(mha-node3)指向新master
- 验证切换结果
# 在新master(mha-node2)查看状态
mysql -uroot -p -e "SELECT @@server_id, @@read_only;"
# 应显示server_id=12,read_only=OFF
# 在mha-node3查看复制状态
mysql -uroot -p -e "SHOW SLAVE STATUS\G"
# 应显示Master_Host为mha-node2,且复制正常
七、故障恢复后处理
- 修复原master(mha-node1),重新安装MySQL并配置为新master(mha-node2)的从库。
- 重新启动MHA Manager(故障切换后Manager会自动退出):
nohup masterha_manager --conf=/etc/mha/mha_cluster.cnf > /var/log/mha/mha_cluster/no
hup.log 2>&1 &
注意事项
- MySQL 8.0兼容性:需使用MHA 0.58版本,且用户认证插件必须为
mysql_native_password。 - GTID依赖:建议开启GTID,减少MHA切换时的binlog定位复杂度。
- 候选主库选择:
candidate_master=1的节点应尽量与原master数据一致(复制延迟小)。 - 日志监控:定期检查MHA日志,及时发现潜在问题(如SSH连接失败、复制延迟等)。
通过以上步骤,即可完成MySQL 8.0环境下的MHA高可用部署,实现主库故障时的自动切换,提升数据库服务可用性。
MySQL编程开发
变量
- 系统变量:MySQL内置的变量;
#查看所有系统变量
show variables ;
#模糊查询
SHOW VARIABLES LIKE '参数名%'(支持通配符 % 或 _);
#修改系统变量
#临时修改(重启后失效):使用 SET 命令(会话变量默认当前连接生效,全局变量需 GLOBAL 关键字)。
#永久修改:需修改 MySQL 配置文件(如 my.cnf 或 my.ini),重启服务器生效。
#-- 临时修改全局变量(需权限)
SET GLOBAL max_connections = 200; -- 调整最大连接数为200
#-- 临时修改会话变量(当前连接生效)
SET SESSION wait_timeout = 3600; -- 调整超时时间为1小时
#-- 查看全局变量(如最大连接数)
SHOW GLOBAL VARIABLES LIKE 'max_connections';
#-- 或直接查询
SELECT @@global.max_connections;
#-- 查看会话变量(如字符集)
SHOW VARIABLES LIKE 'character_set_client';
#-- 或直接查询
SELECT @@session.character_set_client;
- 全局变量:在所有终端中生效;
- 会话变量:仅在当前会话(本次登陆)生效;
- 用户变量:用于临时存储用户自己的数据,例如:select 的查询结果。
#-- 用户变量操作示例
#-- 赋值(方式1:直接赋值)
SET @num1 = 10;
SET @num2 := 20; -- 支持 := 避免与 SQL 关键字冲突
#-- 赋值(方式2:查询结果赋值)
SELECT COUNT(*) INTO @user_count FROM users; -- 将 users 表行数存入 @user_count
#-- 使用用户变量
SELECT @num1 + @num2 AS sum_result; -- 输出 30
SELECT @user_count AS total_users; -- 输出 users 表行数
- 局部变量:在存储过程内部定义的变量,只在该存储过程中有效。
触发器
触发器(Triggers)可以在数据表上的数据更改时自动执行特定的操作。
例如:在对a表插入一条新的数据,b表会同步记录操作日志。
#创建触发器
#语法结构 :
create trigger trigger_name
before/after insert/update/delete
on tbl_name
[ for each row ] -- 行级触发器
begin
trigger_stmt ;
end;
#删除触发器
#语法结构 :
drop trigger [schema_name.]trigger_name
如果没有指定 schema_name,默认为当前数据库 。
#查看触发器
#可以通过执行 SHOW TRIGGERS 命令查看触发器的状态、语法等信息。
#语法结构 :
show triggers ;
存储过程
将复杂的 sql 语句,包含在存储过程中,存放在服务端,可被重复调用。
客户端使用 call 存储过程名; 执行该存储过程;
优点:简化客户端的 sql 编写,减少网络发送的数据量,加速执行,提高效率。
缺点:但在可移植性、调试、资源占用等方面存在不足。
存储过程适合用于处理数据库端的复杂、高频复用的业务逻辑,能提升性能和安全性;但在可移植性、调试、资源占用等方面存在不足。实际使用中需根据具体场景权衡,避免过度依赖或完全摒弃。
函数
对数据进行简单的处理,例如:求和、平均值、最大值、最小值、文本处理,获取时间等····· ,函数有返回值。
使用 select 函数名(参数)···;
MySQL内置
MySQL自定义函数
| 特性 | 存储过程 | 函数 |
|---|---|---|
| 返回值 | 无或多个输出参数 | 必须返回一个单一值 |
| 调用方式 | CALL procedure_name() |
SELECT function_name() |
| SQL 上下文 | 可包含数据修改(如 INSERT) |
通常禁止修改数据(仅查询) |
| 适用场景 | 复杂业务逻辑(如批量数据处理) | 简单计算或单一结果查询 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号