Spark源码——shuffle
原理回顾
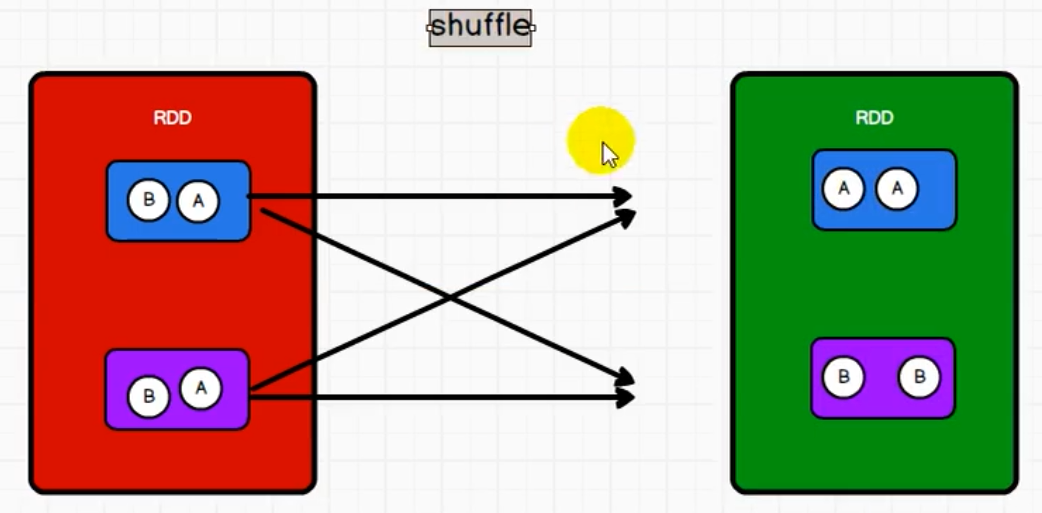
一个RDD的两个分区的数据shuffle到另一个RDD的两个分区中后,如果上一个RDD还存在其他分区没执行完毕的话,不能往下执行,就会造成当前RDD内存数据挤压
所以中间就需要落盘操作,中间需要磁盘文件File
shuffle一定会有落盘,但是效率慢,如何提高效率?落盘数据量越少速度就会变快。算子如果存在预聚合功能,就会提升shuffle性能
原理回顾
一个RDD的两个分区的数据shuffle到另一个RDD的两个分区中后,如果上一个RDD还存在其他分区没执行完毕的话,不能往下执行,就会造成当前RDD内存数据挤压
所以中间就需要落盘操作,中间需要磁盘文件File
shuffle一定会有落盘,但是效率慢,如何提高效率?落盘数据量越少速度就会变快。算子如果存在预聚合功能,就会提升shuffle性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号