人声伴奏分离—Ultimate Vocal Remover
1. 软件信息
软件名称:Ultimate Vocal Remover
应用平台:Windows / Mac / Linux
软件大小:1.57GB(v5.6)
软件作者:Anjok07、aufr33
软件官网:Ultimate Vocal Remover (Github)
2. 软件功能
- 采用先进的音源分离模型,将音频文件中的人声与伴奏分离,从而获得纯伴奏或纯人声的音频;
3. 注意事项
- 程序安装路径不能有中文和空格,否则可能出现未知错误,作者建议不要更改程序默认安装路径,以避免权限等问题;
- 程序依靠 FFmpeg 来处理非 wav 格式的音频文件,因此在使用之前要保证已安装 FFmpeg;
4. 安装教程
4.1 前置软件
4.1.1 FFmpeg
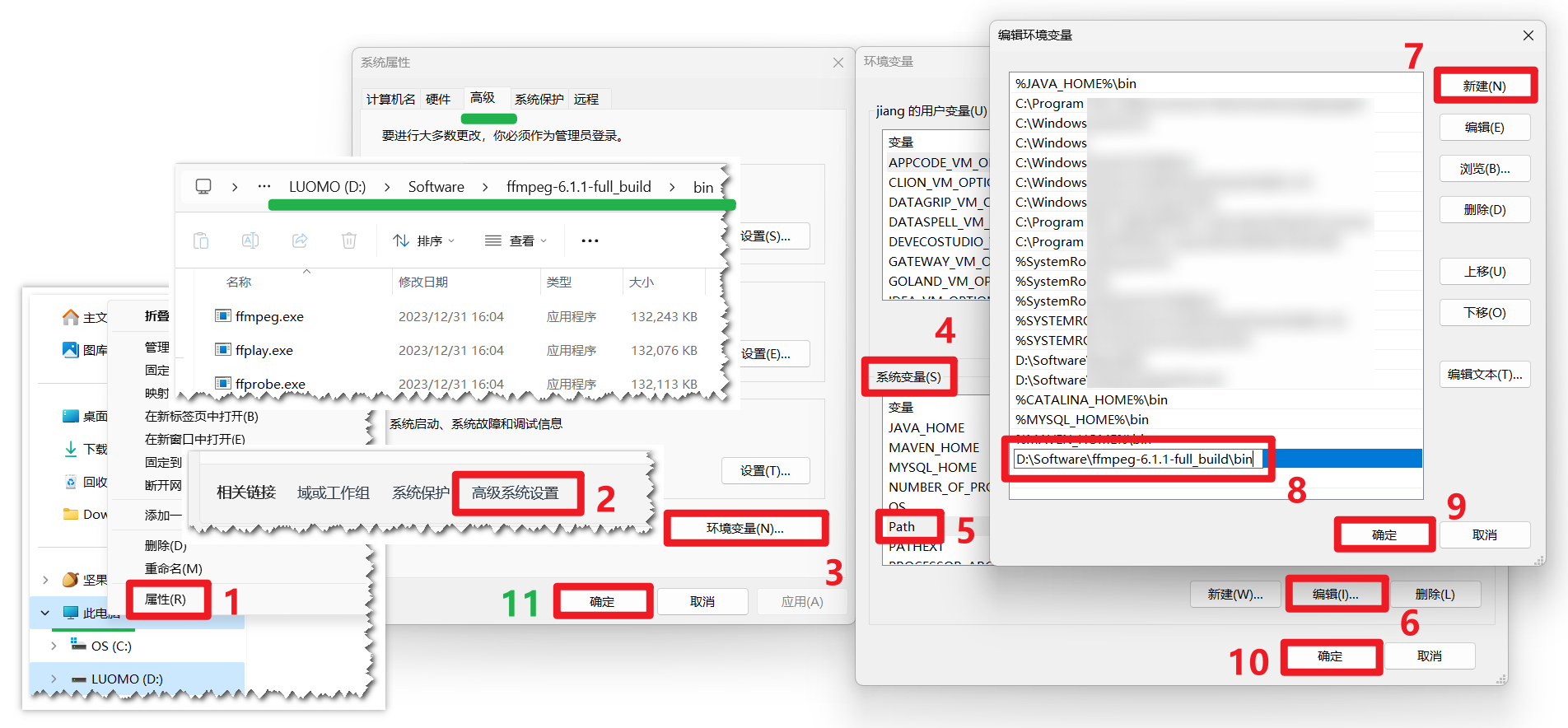
进入 FFmpeg 官网:FFmpeg,在 release builds(发布版本)中选择下载 ffmpeg-release-full.7z 文件,下载后直接解压到合适的位置,并为 FFmpeg 配置环境变量,即可完成安装。
所谓配置环境变量,即将 FFmpeg 安装后的 bin 目录添加到电脑的系统变量中,以便随地引用 FFmpeg 相关命令。右键此电脑,依次选择 属性 - 高级系统设置 - 环境变量 - 系统变量 - Path,点击 编辑,新建 变量值如下,即可完成添加环境变量:
变量值:即计算机中 FFmpeg 的解压地址,如 D:\Software\ffmpeg-6.1.1-full_build\bin
添加环境变量后,需要连续点击 确定 关闭环境变量窗口以保存环境变量,然后打开 cmd 命令行窗口,键入 ffmpeg 并回车,有相关内容输出,即是安装成功。
4.2 软件下载
软件下载地址:Ultimate Vocal Remover (Github)
其中,各平台适用版本如下:
Windows N卡(CUDA加速):UVR_vx.x.x_setup.exe
Windows A卡/I卡(OpenCL加速):UVR_vx.x.x_setup_opencl.exe
MacOS M芯片(arm64):Ultimate_Vocal_Remover_vx_x_MacOS_arm64.dmg
MacOS Intel芯片(x86_64):Ultimate_Vocal_Remover_vx_x_MacOS_x86_64.dmg
4.3 软件安装
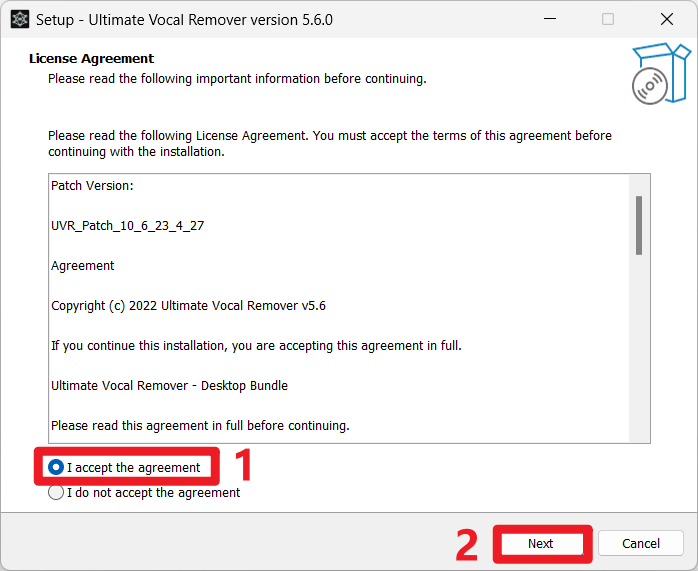
- 双击安装程序,进入以下界面,选择
I accept the agreement(同意软件许可协议),然后点击Next;
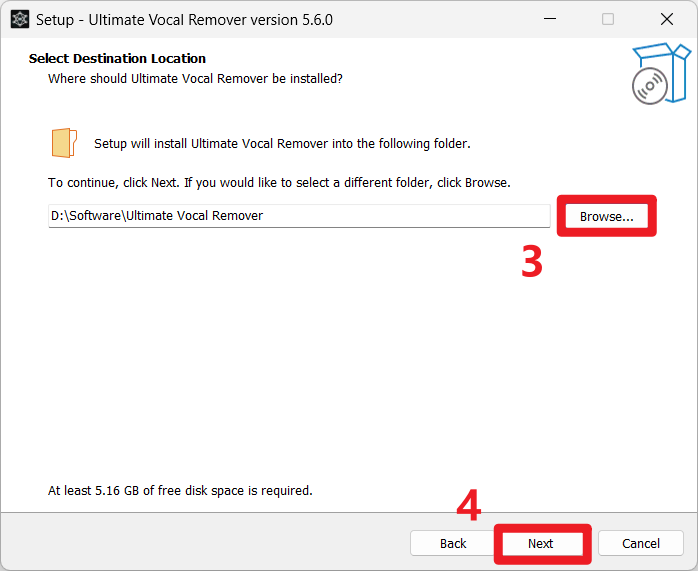
- 点击
Browse,选择软件安装路径(作者建议不要改变默认安装路径,以避免各类权限问题),然后点击Next;
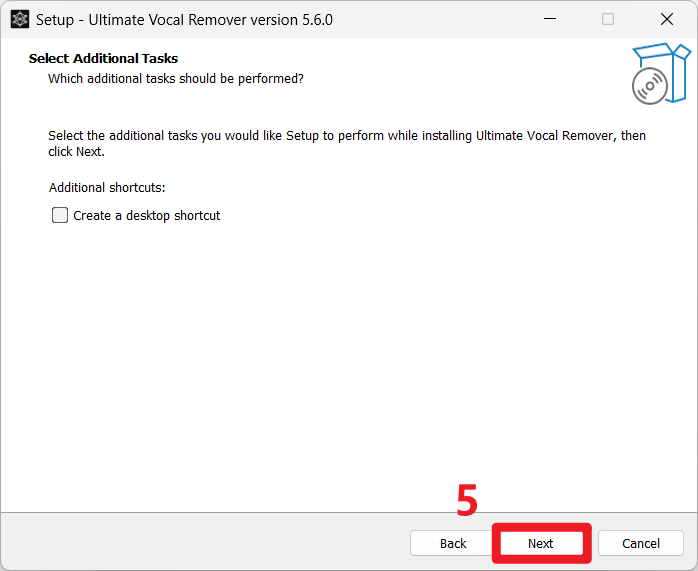
Create a desktop shortcut表示安装后为软件创建桌面快捷方式,根据需要勾选即可,然后点击Next;
- 直接点击
Install;
- 软件安装中,等待几分钟即可;
Launch Ultimate Vocal Remover表示安装完成后直接打开软件,根据需要勾选即可,然后点击Finish结束安装;
4.4 模型下载
UVR 依靠模型(models)进行音源分离工作,因此在安装软件之后还得下载相应的模型文件,才能正常运行,模型的下载与安装有以下两种方式。
4.4.1 自动下载模型
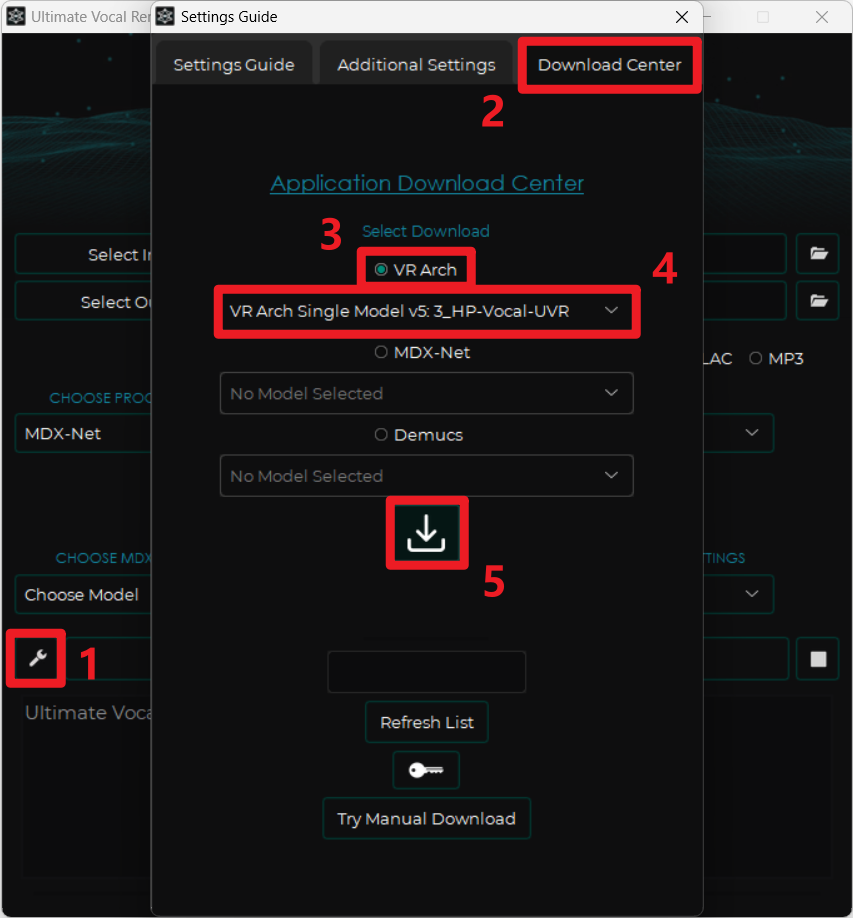
通过软件自动下载模型,可以直接将下载好的模型放到软件安装路径中的相应目录,不需其他额外操作,步骤如下图所示。打开模型下载界面 Download Center,根据需要选择相应的模型算法(VR Arch、MDX-Net 或 Demucs)之后才能选择模型,选择完毕后点击下载按钮即可开始下载。需要注意的是在这里下载模型需要全局富强上网,否则会显示 No Internet Connection(没有互联网连接)。
4.4.2 手动下载模型
除了一键下载并安装模型,还可以从 Github 的模型仓库中手动下载模型,这种方法在下载模型后还需要手动将下载后的模型文件放到软件安装路径中的相应目录。
在 UVR 软件中获得相应模型的 Github 链接的方式如下,也可以直接访问模型仓库的地址 Ultimate Vocal Remover Models 进行下载。
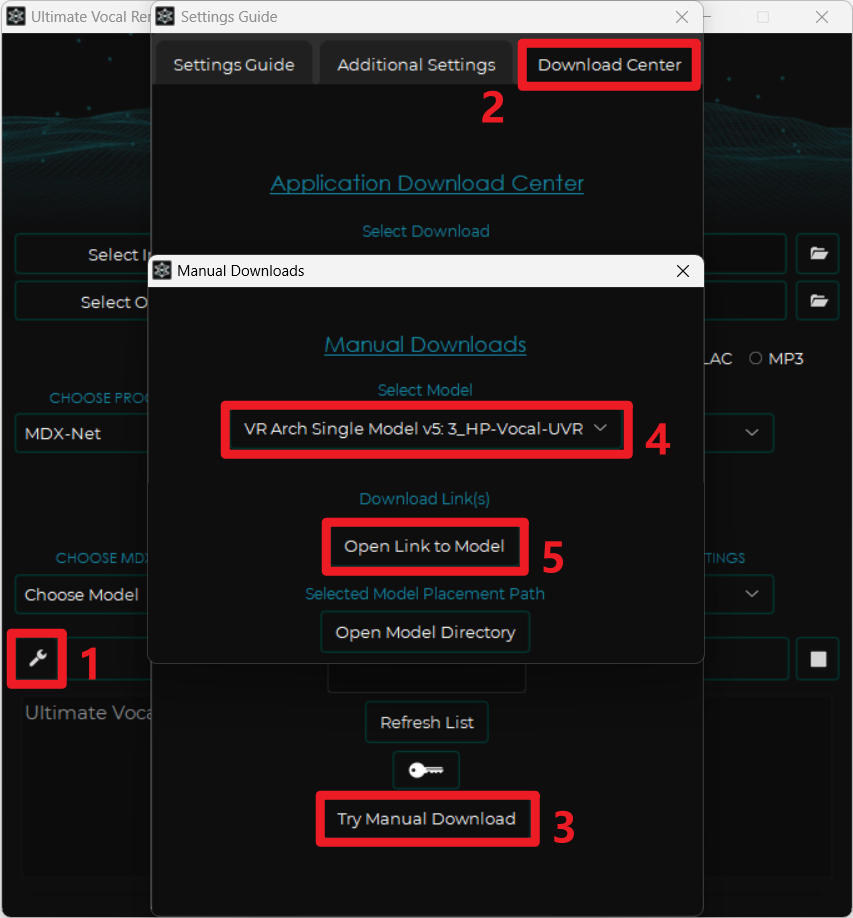
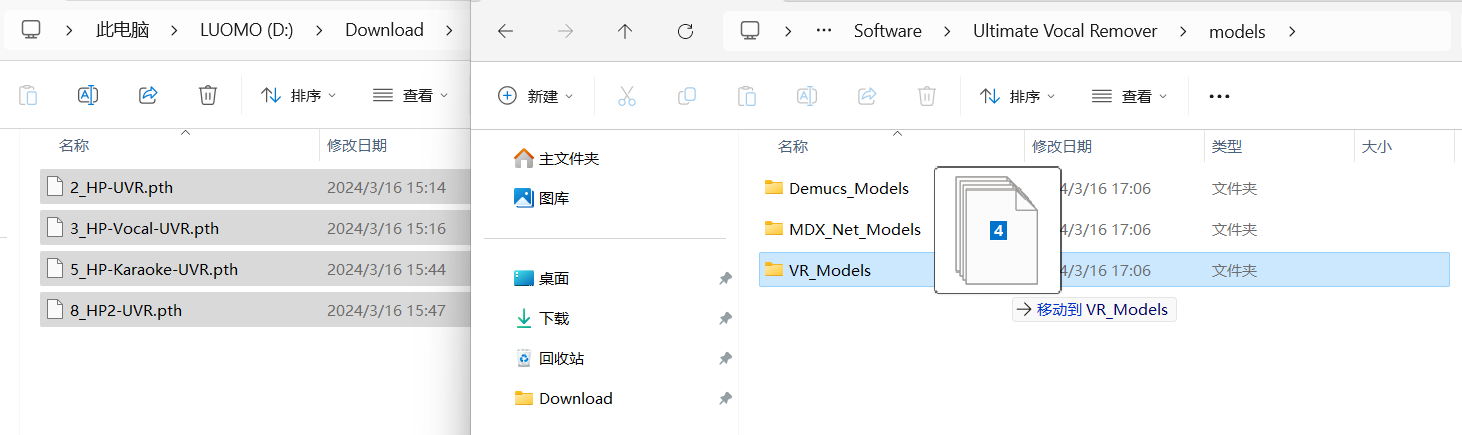
UVR 的模型路径为 Ultimate Vocal Remover\models,将下载好的模型文件直接移动到该文件夹下的相应模型算法文件夹(VR_Models、MDX_Net_Models 或 Demucs_Models,具体该放到哪个文件夹可以参考上一步自动下载模型一节,选择相应的模型算法后能看到该模型算法下含有哪些模型)内模型即可生效,其详细步骤如下:
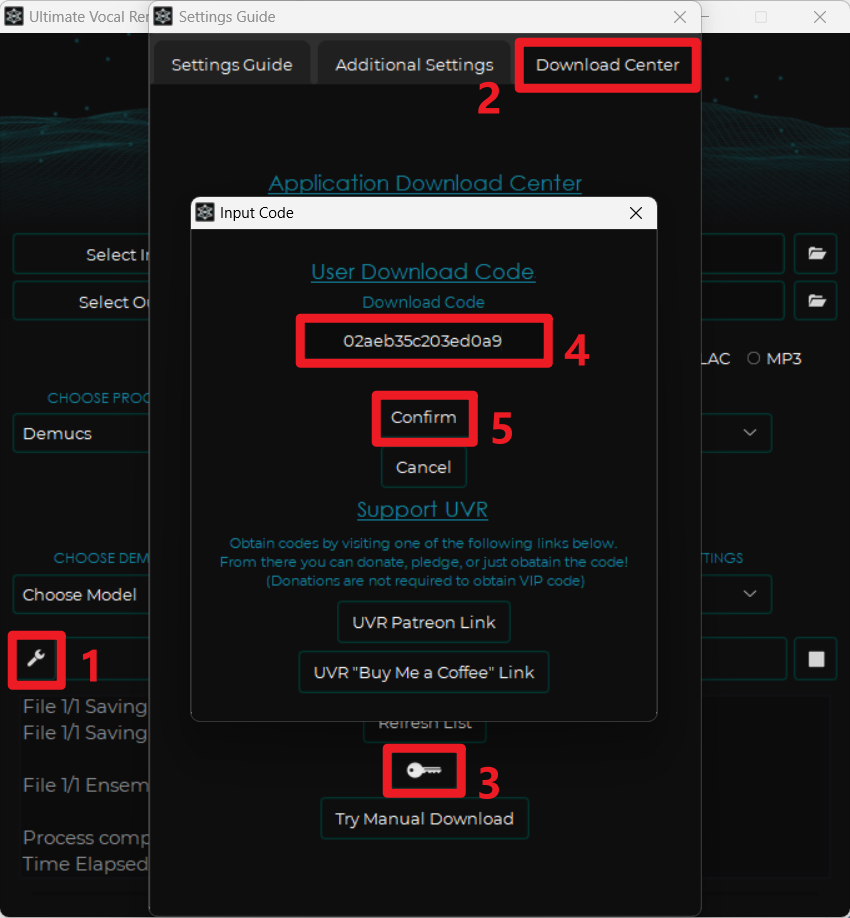
4.4.3 模型解锁
通过以下步骤输入 Download Code:02aeb35c203ed0a9,之后点击 Confirm,即可解锁软件内的 VIP 模型。
5. 软件界面
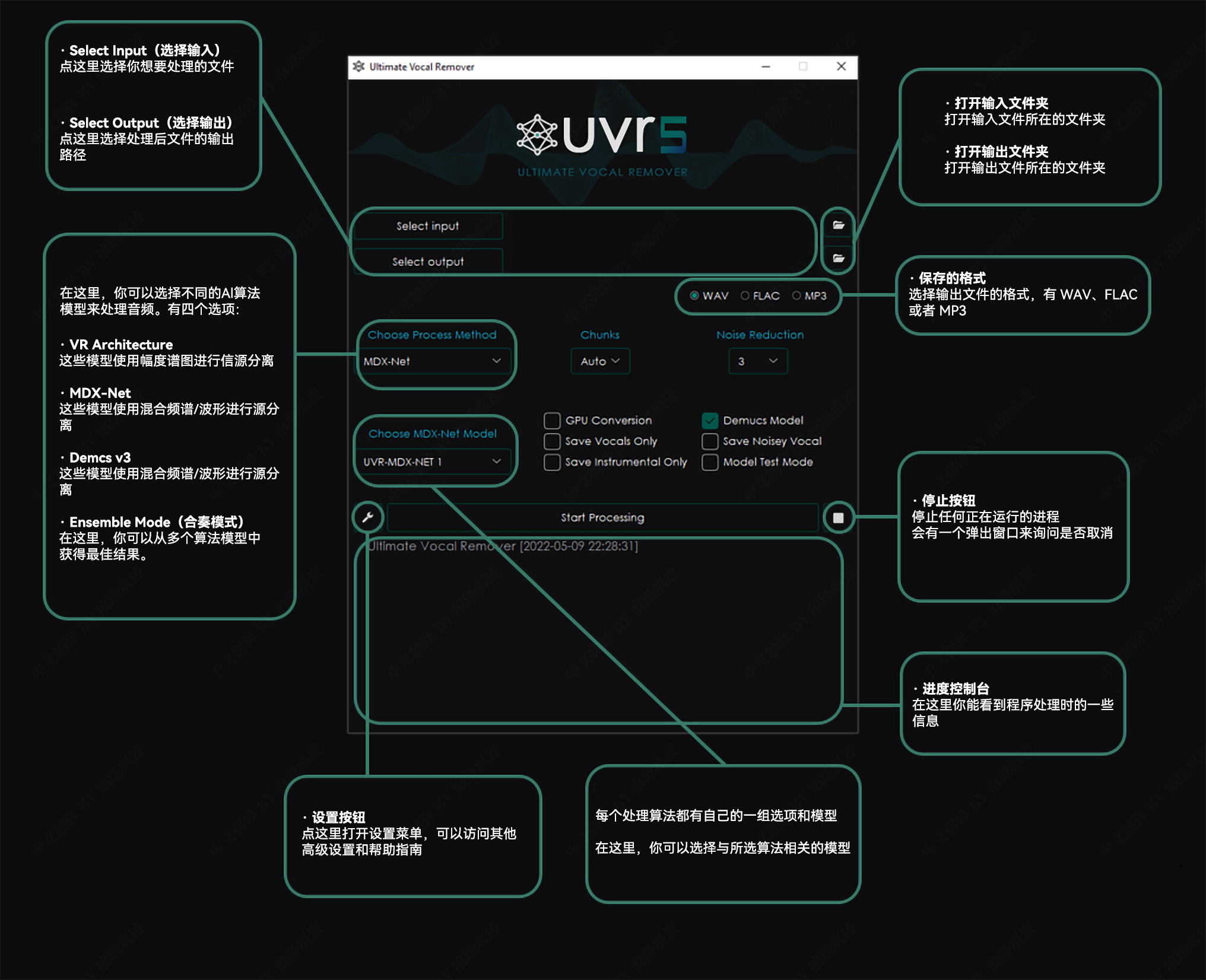
- 上图出自哔哩哔哩UP主 @痕继痕迹
6. 使用教程
要想获得最好的分离效果,分离模型的选择是最主要的,一般会选择一个专项功能的模型,搭配 MDX-Net 算法下的 UVR-MDX-NET Main 模型,通过 Ensemble Mode 算法融合进行音频分离,能获得较好的结果。
如下图,为提取较纯净的伴奏,把 VR Arc 算法下提取伴奏的专项模型 2_HP-UVR 和 MDX-Net 算法下的 UVR-MDX-NET Main 模型通过 Ensemble Mode 算法融合,即可获得不错的伴奏音频,对于非专业的使用场景,这样的音频质量已经完全足够了。
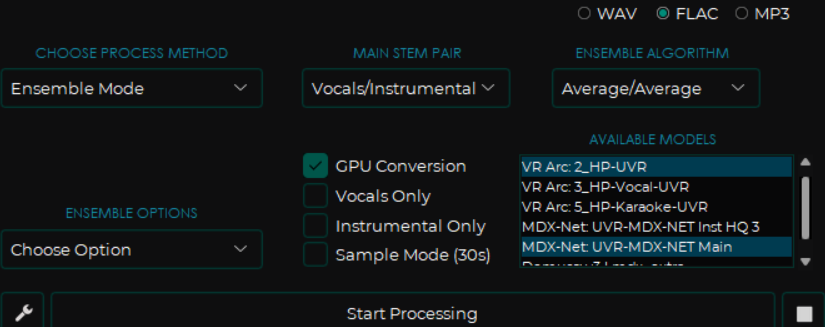
下面就针对不同的使用场景,推荐一些适合的专项模型。
6.1 提取伴奏(无和声)
以下模型中,通过 7_HP2-UVR 模型提取的伴奏质量是最好的,但提取速度很慢,可与 2_HP-UVR.pth 模型交替使用。
VR Arch 算法:
1_HP-UVR.pth:非常强的伴奏提取模型
2_HP-UVR.pth:基于1_HP-UVR.pth的微调模型(推荐)
7_HP2-UVR.pth:使用了更多的数据和新参数训练的超强伴奏提取模型(推荐)
8_HP2-UVR.pth:超强伴奏提取模型
9_HP-UVR.pth:基于8_HP2-UVR.pth微调的模型
6.2 提取伴奏(带和声)
以下模型中,通过 6_HP-Karaoke-UVR 模型和 UVR Model 模型提取的伴奏质量都比较好,可根据实际情况选择使用。
VR Arch 算法:
5_HP-Karokee-UVR.pth:保留和声模型
6_HP-Karaoke-UVR.pth:作用同5_HP-Karokee-UVR.pth一样(推荐)
MDX-Net 算法:
UVR-MDX-NET Karaoke:保留和声模型
Demuvs 算法:
UVR Model:保留和声模型(推荐)
6.3 提取人声
以下模型中提取的人声质量都比较好,可根据实际情况选择使用。
VR Arch 算法:
3_HP-Vocal-UVR.pth:用于人声提取,人声部分会很清晰,但伴奏部分可能会变得浑浊(推荐)
4_HP-Vocal-UVR.pth:用于人声提取,但是比3_HP-Vocal-UVR.pth更加强势(Aggressive)(推荐)
6.4 提取吉他
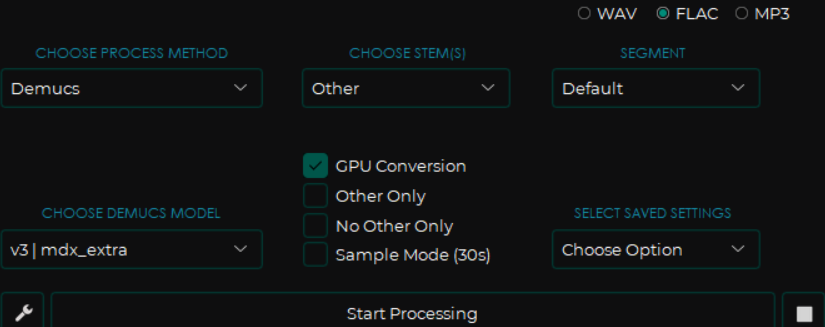
使用 Demucs 算法下的 mdx_extra 模型,设置 CHOOSE STEM(S) 为 Other,其余设置保持默认,即可完成对音频文件内吉他音轨的提取(或清除,提取剩下的文件就没有吉他音轨了)。提取后的文件中,带 Other 标签的文件就是吉他音轨,带 No Other 标签的文件就是去吉他音轨。具体设置如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号