

实现多任务之进程与线程
进程与线程
一、多任务概念
1、举个栗子

比如在网盘下载资料的时候,为什么要多个资料同时下载?
答:多个任务同时下载可以大大提高程序执行的效率。
多任务的最大好处就是充分利用好CPU资源,提高程序的执行效率。
2、什么是多任务
多任务是指同一时间内执行多个任务。
例如:现在安装的电脑的操作系统都是多任务操作系统,可以同时运行多个软件。
3、多任务的两种表现形式
① 并发
② 并行
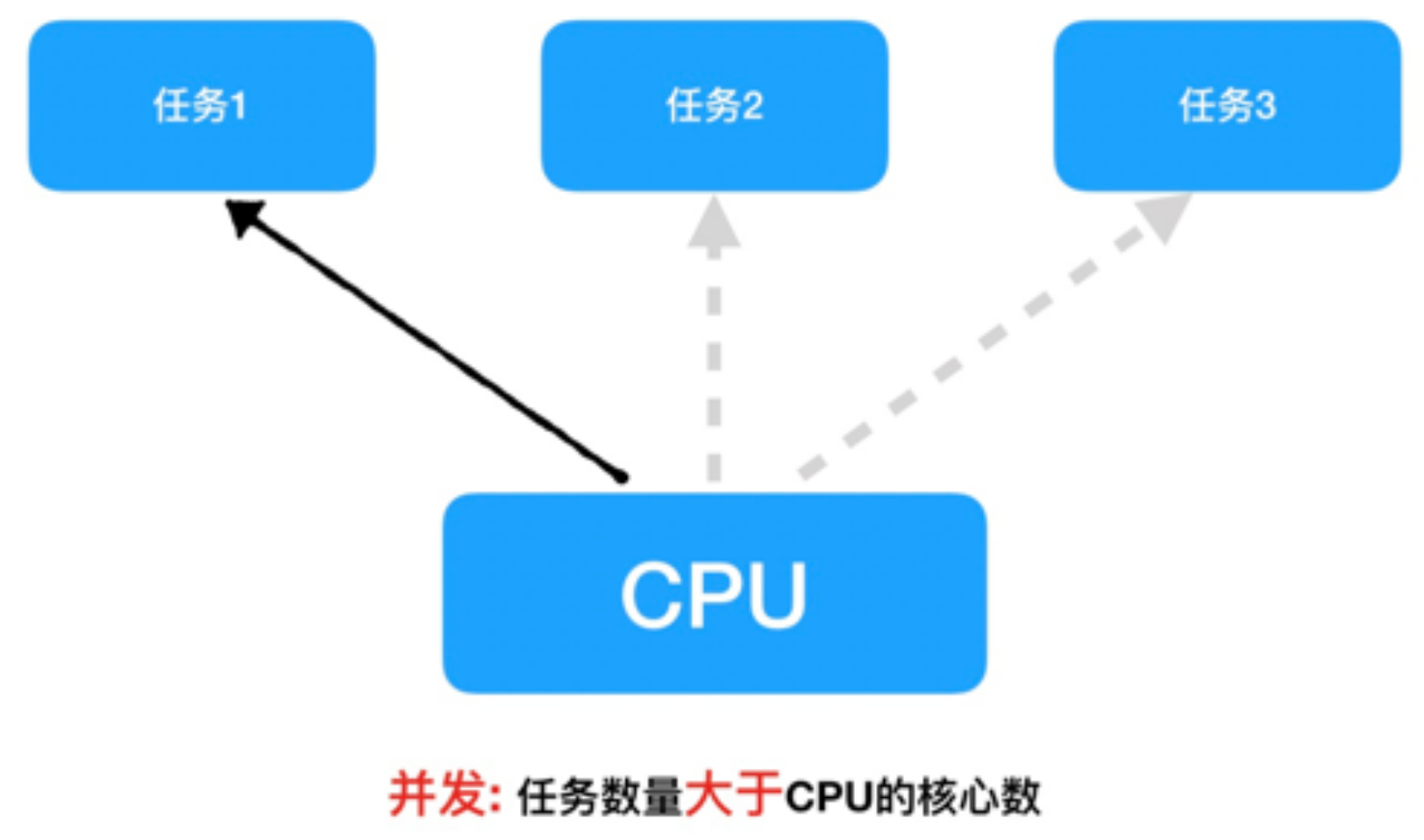
4、并发操作
并发:在一段时间内交替去执行多个任务。
例如:对于单核cpu处理多任务,操作系统轮流让各个任务交替执行。例如:软件1执行了0.01秒,切换到软件2,软件2执行了0.01秒,再切换到软件3,执行了0.01秒....这样反复执行下去。
实际上,每个软件都是交替执行的,但是由于cpu的执行速度实在太快了,表面上我们感觉这些软件都在同时执行一样,这里需要注意单核cpu是并发执行多任务的。
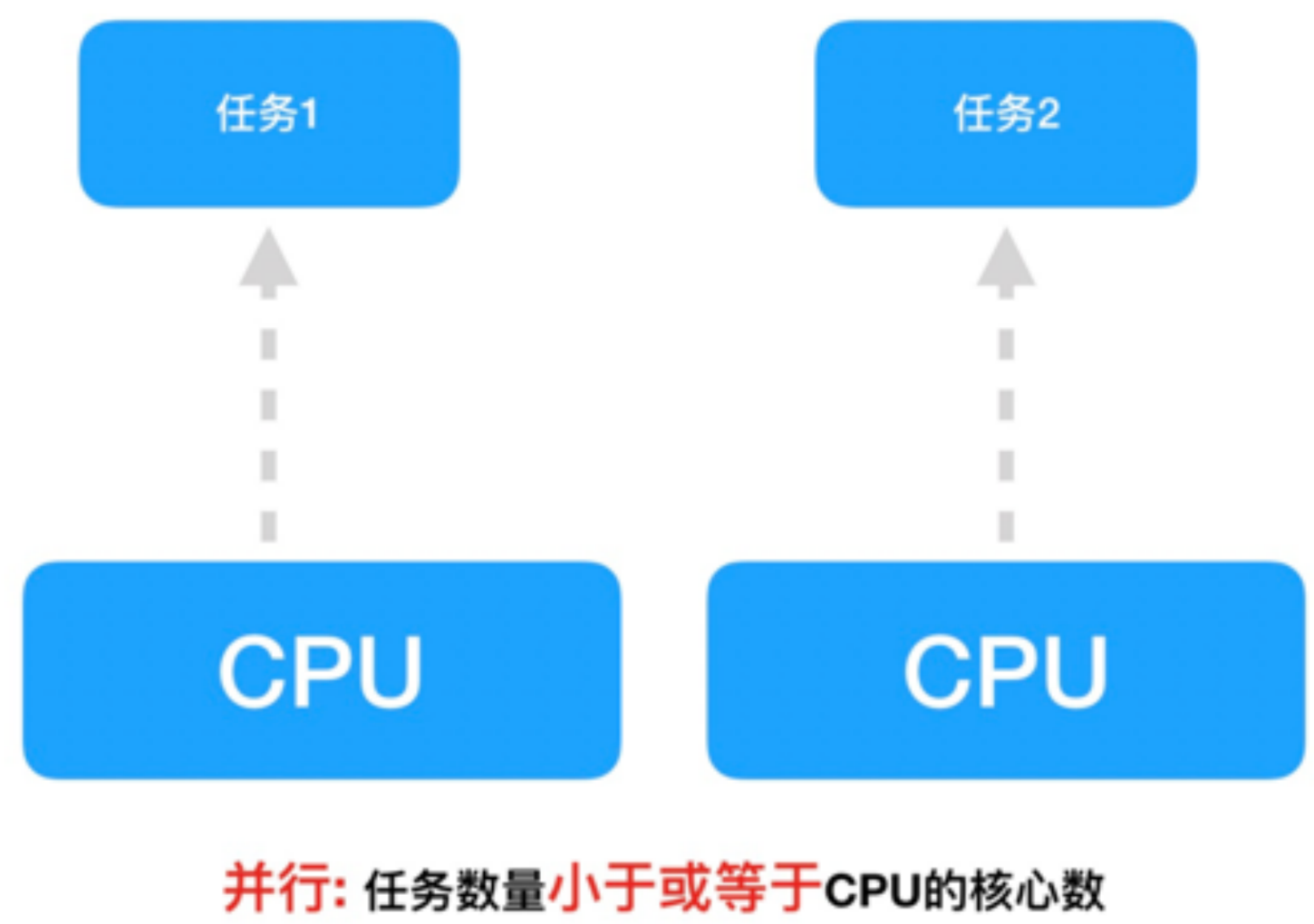
5、并行操作
并行:在一段时间内真正的同时执行多个任务。
对于多核cpu处理多任务,操作系统会给cpu的每个内核安排一个执行的任务,多个内核是真正一起执行多个任务。需要注意多个cpu是并行的执行多任务,始终有多个任务一起执行。
二、进程
1、进程的概念
在python中,想要实现多任务可以使用多进程实现。
进程(process)是资源分配的最小单位,它是操作系统进行资源分配和调度运行的基本单位,通俗理解:一个正在运行的程序就是一个进程。
例如:正在运行的qq或微信都是一个进程。
注:一个正在运行的程序至少有一个进程
2、多进程的作用
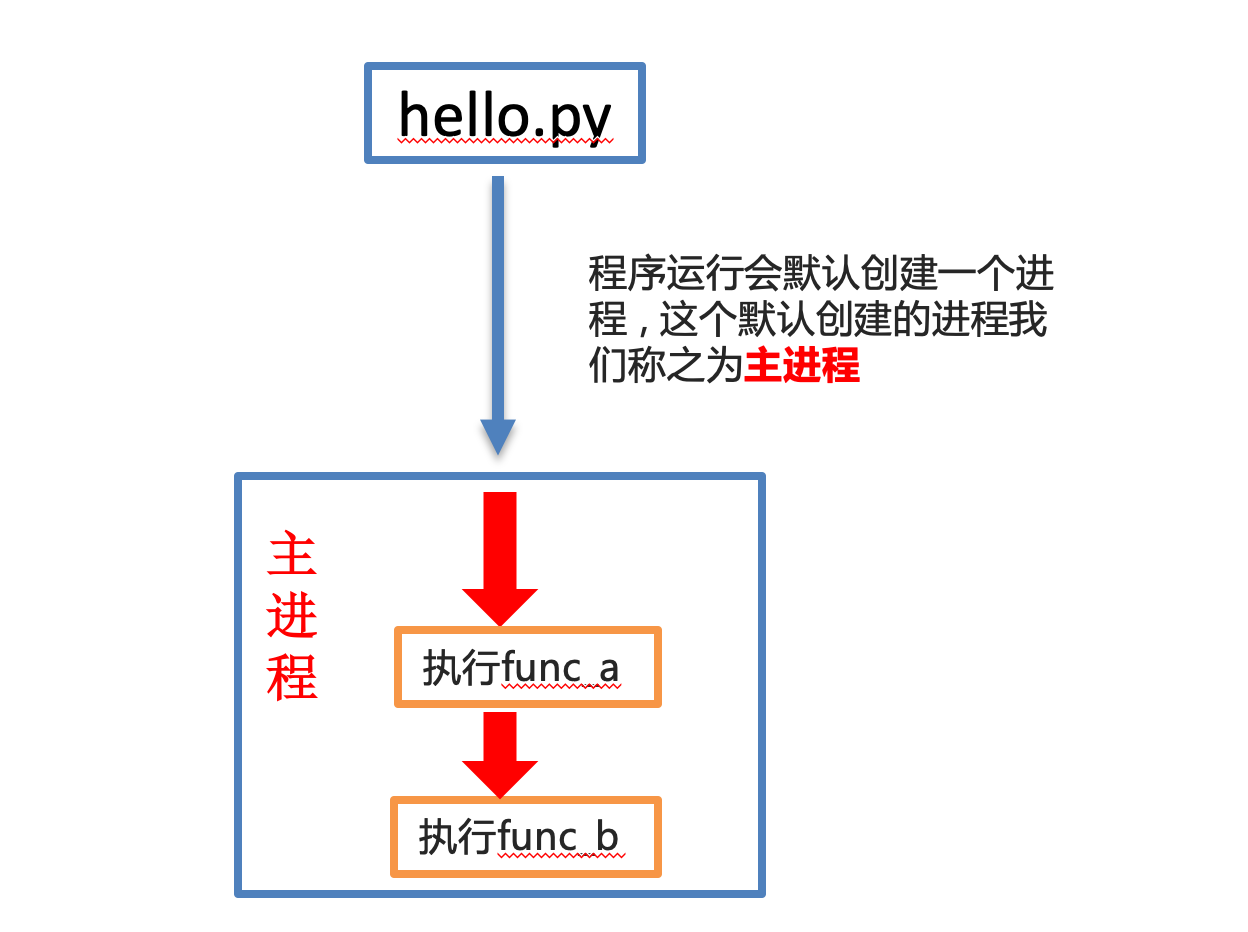
未使用多进程:

思考:
图中是一个非常简单的程序 , 一旦运行hello.py这个程序 , 按照代码的执行顺序 , func_a函数执行完毕后才能执行func_b函数 . 如果可以让func_a和func_b同时运行 , 显然执行hello.py这个程序的效率会大大提升 .
使用了多进程:
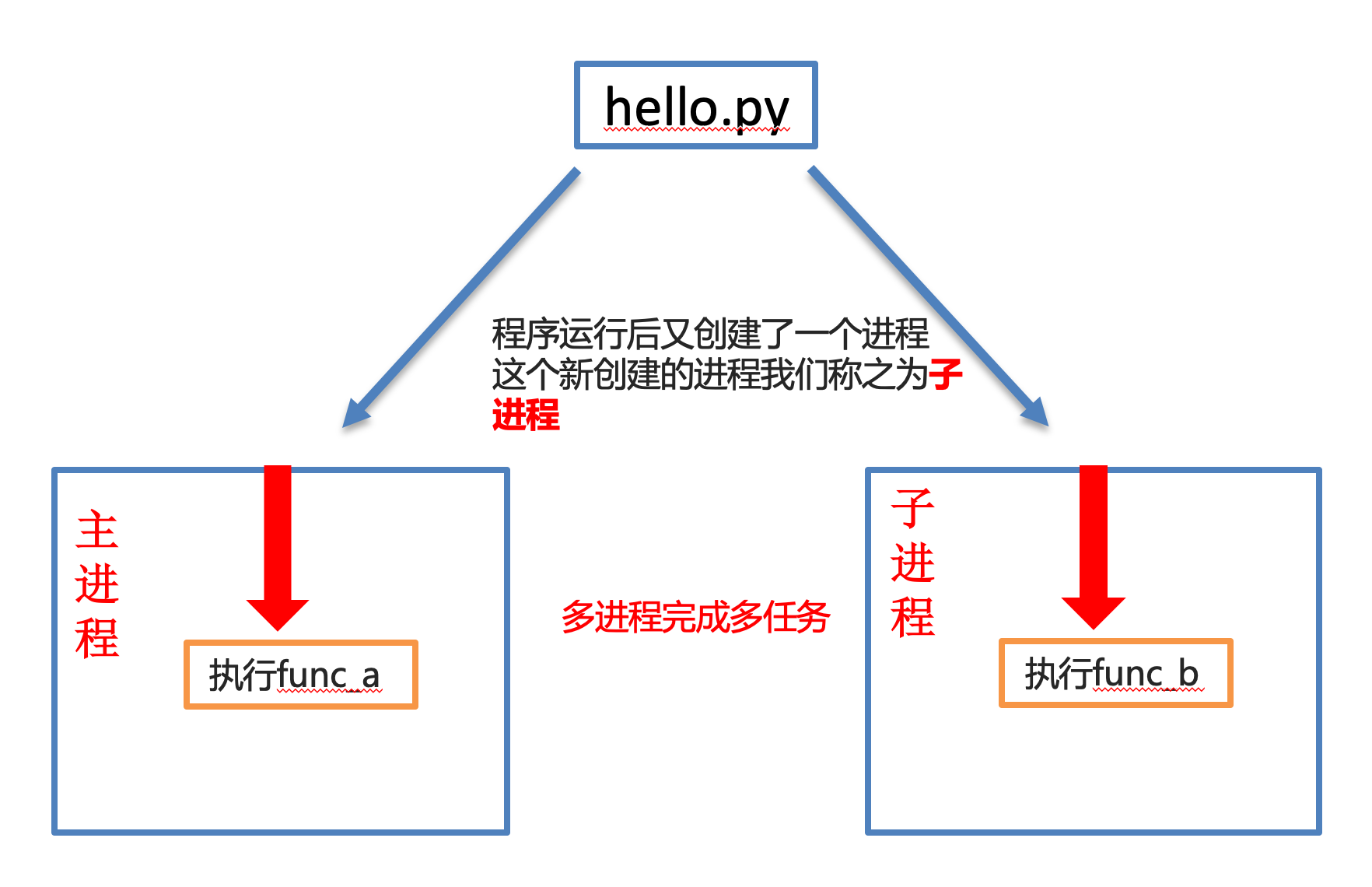
三、多进程完成多任务
1、基本语法
# 导入进程包
import multiprocessing
# 通过进程类创建进程对象
进程对象 = multiprocessing.process()
# 启动进程执行任务
进程对象.start()
进程对象 = multiprocessing.process([group[,target = 任务名[,name]]])
参数说明:
- target :执行的目标任务名,这里指函数名(方法名)
- name :进程名,一般不用设置
- group :进程组,目前只能使用None
2、进程的创建与启动
import multiprocessing
import time
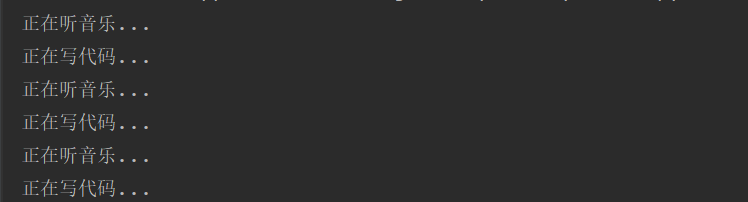
def music():
for i in range(3):
print('正在听音乐...')
time.sleep(0.2)
def coding():
for i in range(3):
print('正在写代码...')
time.sleep(0.2)
if __name__ == '__main__':
# 创建子进程对象
music_process = multiprocessing.Process(target=music)
code_process = multiprocessing.Process(target=coding)
# 启动进程对象
music_process.start()
code_process.start()
3、多进程执行带有参数的任务
process([group[,target [,name [,args [,kwargs ]]]]])
参数说明:
-
args:以元组方式给执行任务传参,args代表调用对象的位置参数元组,args = (1,2,'anen')
-
kwargs: 以字典的方式给执行任务传参,kwargs代表调用对象的字典,kwargs =
1.元组方式传参:元组方式传参一定要和参数的顺序保持一致
2.字典方式传参:字典方式传参中的key一定要和参数名一致
import multiprocessing
import time
# 参数n代表听音乐的次数
def music(n):
for i in range(n):
print('正在听音乐...')
time.sleep(0.2)
# 参数t代表休眠时间
def coding(t):
for i in range(3):
print('正在写代码...')
time.sleep(t)
if __name__ == '__main__':
# 创建子进程对象
music_process = multiprocessing.Process(target=music, args=(3,)) # 以元组方式传参
code_process = multiprocessing.Process(target=coding, kwargs={'t': 0.2}) # 以字典方式传参
# 启动子进程
music_process.start()
code_process.start()
四、获取进程编号
1、进程编号的作用
当程序中进程数量越来越多时,如果没有办法区分主进程和子进程还有不同的子进程,那么就无法进行有效的进程管理,为了方便管理实际上每个进程都是有自己的编号的。
2、获取进程编号
获取当前进程的编号
os.getpid()
**获取当前父进程的编号 ** ppid = parent pid
os.getppid()
根据进程编号杀死指定进程
os.kill(进程编号pid, 传递的信号)
常见的传递信号:
- 9:强制杀掉PID进程
- 15:通知PID进程,正常结束
import os
import multiprocessing
def working():
print(f'当前子进程的编号为{os.getpid()}')
print(f'当前子进程的父进程的编号为{os.getppid()}')
for i in range(3):
print('working...')
if __name__ == '__main__':
# 获取当前进程的编号
print(f'当前进程的编号:{os.getpid()}')1
# 创建子进程并或子进程和其父进程的编号
working_process = multiprocessing.Process(target=working)
working_process.start()

- 主进程默认等待所有子进程执行结束再结束
五、进程的注意点
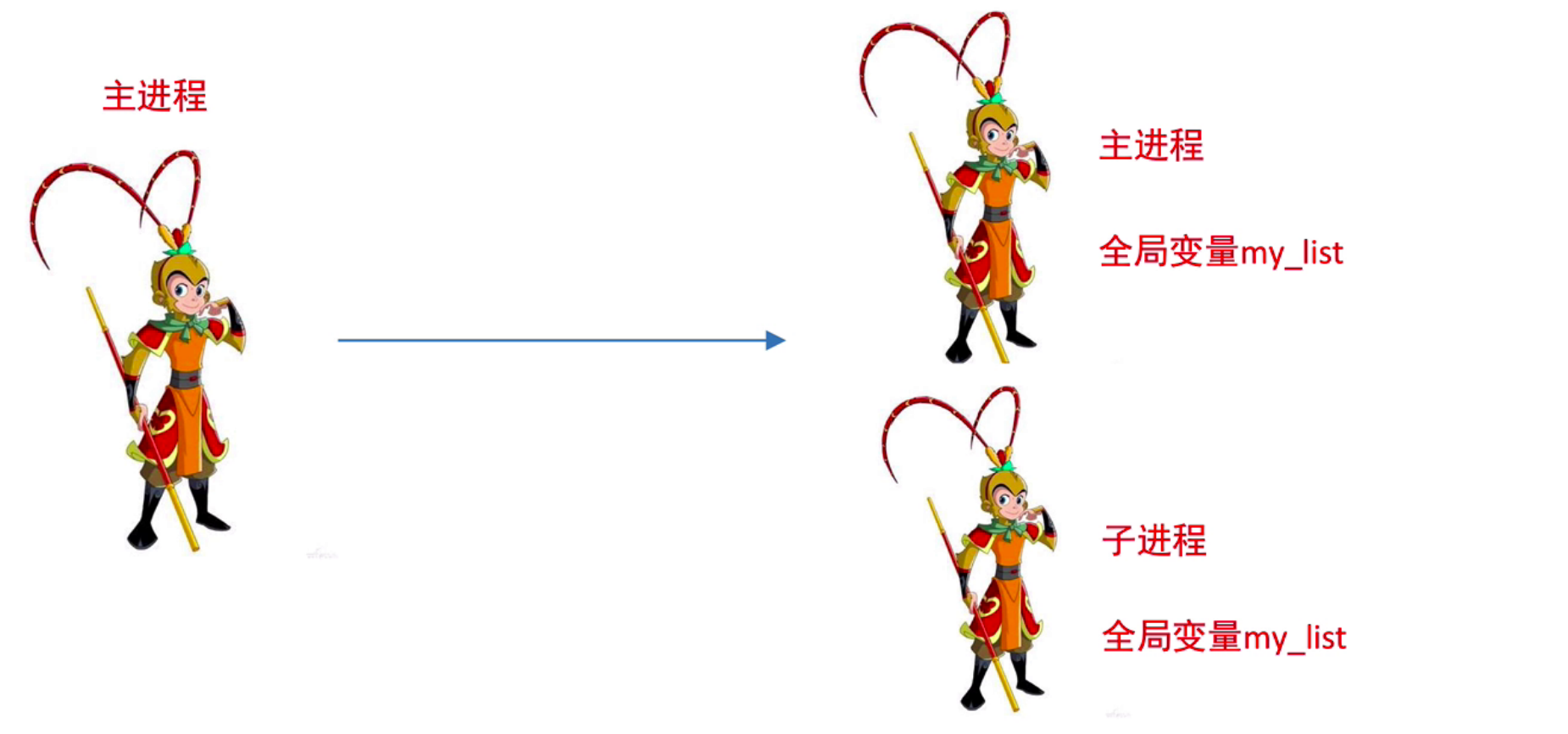
1、进程之间不共享全局变量
实际上创建一个子进程就是把主进程的资源进行拷贝产生了一个新的进程,这里的主进程和子进程是相互独立的
import time
import multiprocessing
# 定义一个全局变量
my_list = []
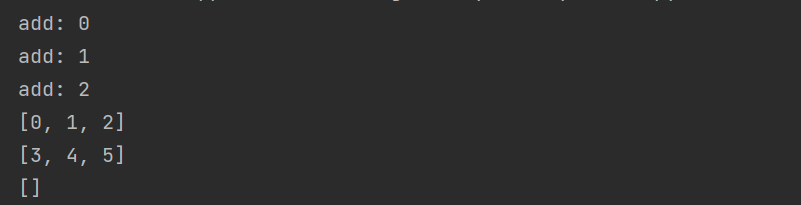
def write_data():
for i in range(3):
my_list.append(i)
print('add:', i)
print(my_list)
def read_data():
print(my_list)
if __name__ == '__main__':
# 创建一个写数据的子进程
write_process = multiprocessing.Process(target=write_data)
# 创建一个读数据的子进程
read_process = multiprocessing.Process(target=read_data)
# 启动子进程
write_process.start()
time.sleep(1) # 休眠1秒
read_process.start()
for i in range(3, 6):
my_list.append(i)
print(my_list)
- 主进程与子进程的全局变量也是不共享的
原理分析:
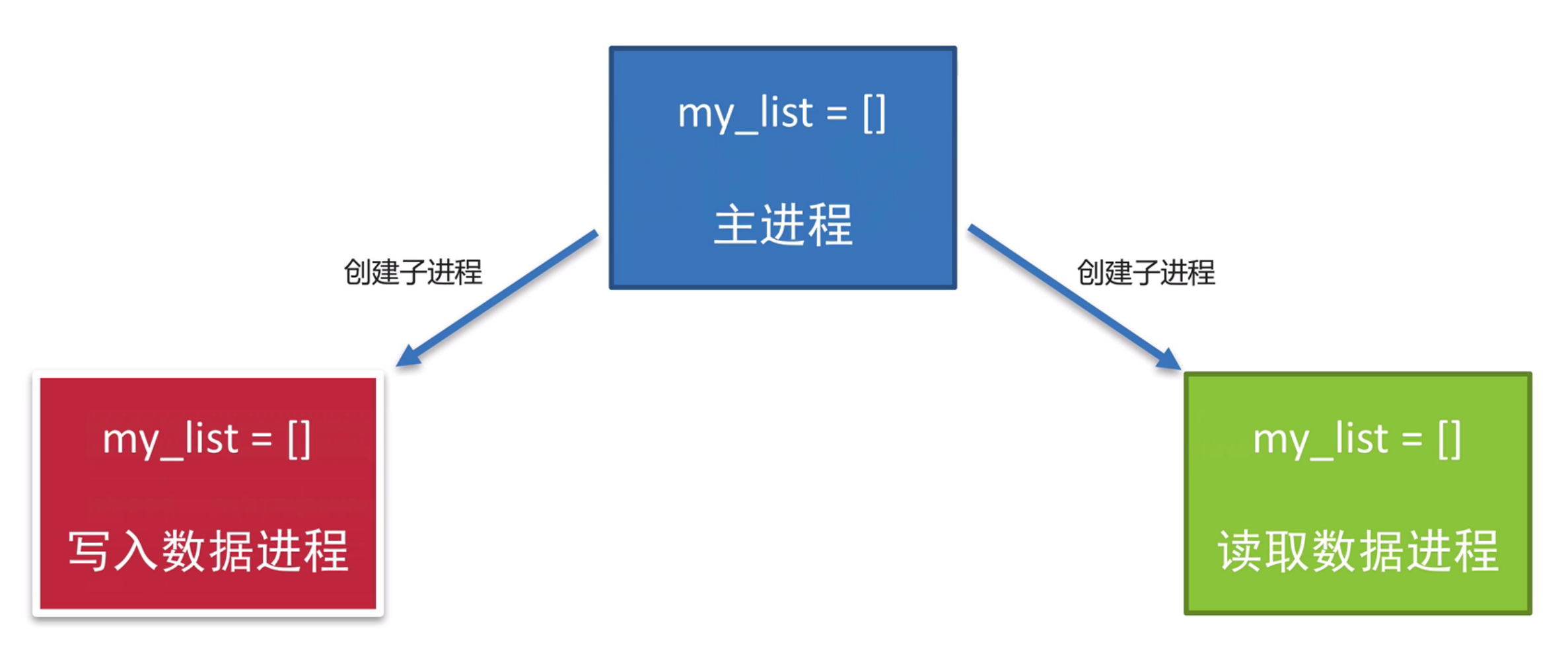
三个进程分别操作的都是自己进程里面的全局变量my_list,不会对其他变量里面的全局变量产生影响,所以进程之间不共享全局变量,只不过进程之间的全局变量的名称相同而已,但是操作的不是一个进程里面的全局变量
知识小结
创建子进程会对主进程的资源进行拷贝,也就是说子进程是主进程的一个副本,好比是一对双胞胎,之所以进程之间不共享全局变量,是因为操作的不是同一个进程里面的全局变量,只不过不同进程里面的全局变量名字相同而已。
2、主进程与子进程的结束顺序
主进程会默认等待所有子进程执行结束再结束
import multiprocessing
import time
def work():
for i in range(5):
print('working...')
time.sleep(0.2)
if __name__ == '__main__':
work_process = multiprocessing.Process(target=work)
# 子进程执行1秒
work_process.start()
# 延迟0.5秒
time.sleep(0.5)
print(f'主进程执行结束')
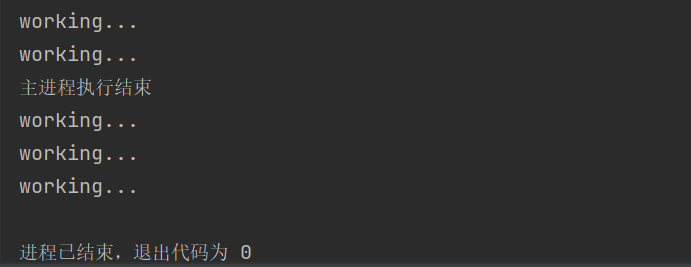
- 按道理说,主进程执行结束之后,子进程也要结束了
解决方案一:设置守护线程
设置守护主线程,主进程结束之后子进程直接销毁,不再执行子进程中的代码
子进程名称.daemon = True
- 在启动子进程之前,设置守护线程
import multiprocessing
import time
def work():
for i in range(5):
print('working...')
time.sleep(0.2)
if __name__ == '__main__':
work_process = multiprocessing.Process(target=work)
# 设置守护主进程,在主进程退出后子进程直接销毁,不再执行子进程中的代码
work_process.daemon = True
work_process.start()
# 让主进程等待0.5秒
time.sleep(0.5)
print('主进程执行结束!')
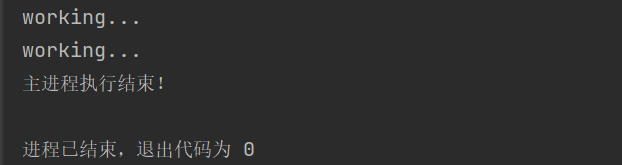
解决方案二:销毁子进程
子进程名称.terminate()
- 在主程序退出之前销毁所有的子进程
import multiprocessing
import time
def work():
for i in range(5):
print('working...')
time.sleep(0.2)
if __name__ == '__main__':
work_process = multiprocessing.Process(target=work)
work_process.start()
# 让主进程等待0.5秒
time.sleep(0.5)
# 让子进程直接销毁,表示终止执行,主程序退出之前,把所有子进程销毁就可以了
work_process.terminate()
print('主进程执行结束!')

六、线程
1、线程的作用
线程是多任务执行的另外一种方式
进程是资源分配的最小单位,一旦创建一个线程就会分配一定的资源,就像在QQ与两个人同时聊天需要打开两个QQ软件比较浪费资源。
线程是程序执行的最小单位,实际上进程只负责分配资源,真正利用资源执行程序的是线程,也就是说一个进程是线程的容器,一个进程里至少拥有一个线程来负责执行程序,同时线程不拥有系统资源,只需要一点在运行中必不可少的资源,但它可与同属一个进程的其他线程共享进程所拥有的全部资源。这就像通过一个QQ软件(一个进程)打开两个窗口(两个线程)与两个好友同时聊天一样,实现多任务的同时也节省了资源。
那么什么时候使用多线程,什么时候使用多进程呢?
- 偏cpu计算任务 => 推荐使用多线程 => 推荐使用多进程 (需要使用到较多的系统资源)
- 偏IO型任务 => 文件操作/网络连接 => 推荐使用多线程(系统资源需要少,且需要频繁操作)
注意:多进程在cpu允许的情况下是并行执行的,而同属一个进程内的多线程多任务只能使用一个cpu,是并发执行的
多线程的实现:
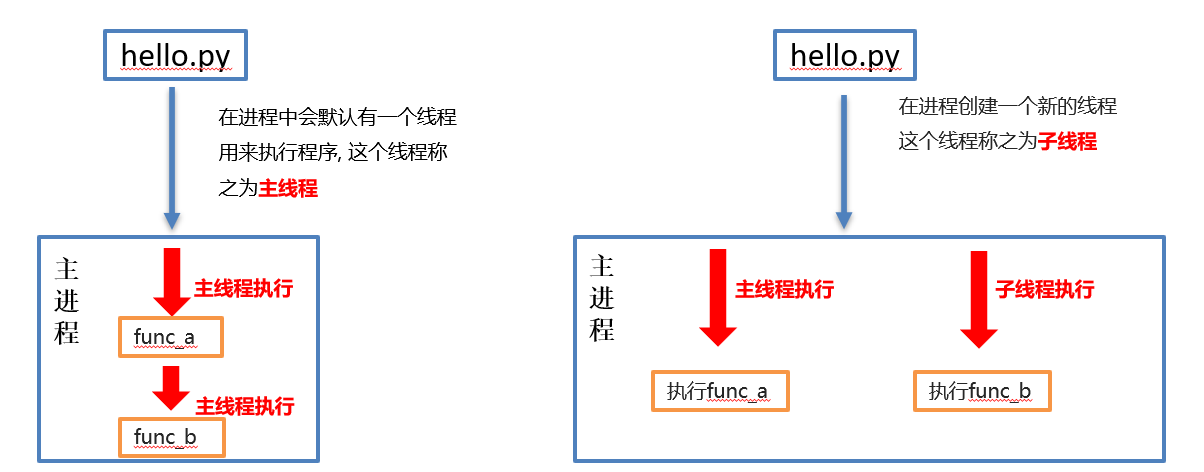
- 线程包含在进程的内部,一个进程理论上至少含有一个线程
- 进程是资源分配的最小单位(申请资源),线程是程序执行的最小单位(专门用于执行程序的)
- 同属一个进程的多个线程共享进程内的所有资源
2、多线程完成多任务
基本语法:
# 导入线程模块
import threading
# 通过线程类创建线程对象
线程对象 = threading.Thread(target = 任务名)
# 启动线程执行任务
线程对象.start()
线程对象 = threading.Thread([group[,target [,name [,args [,kwargs ]]]]])
参数说明:
- target :执行的目标任务名,这里指函数名(方法名)
- name :线程名,一般不用设置
- group :线程组,目前只能使用None
- args:在创建线程的时候通过元组的方式传入参数
- kwargs:在创建线程的时候通过字典的方式传入参数
import threading
import time
def music(n):
for i in range(n):
print('正在听音乐...')
time.sleep(0.1)
def coding(t):
for i in range(3):
print('正在写代码....')
time.sleep(t)
if __name__ == '__main__':
# 创建多线程,并以元组或字典的方式传入参数
music_thread = threading.Thread(target=music, args=(3,))
code_thread = threading.Thread(target=coding, kwargs={'t': 0.2})
# 启动线程
music_thread.start()
code_thread.start()

3、线程之间共享全局变量
多进程实现多任务:无法共享全局变量
多线程实现多任务:因为所有线程都位于一个进程中,不仅资源是共享的,全局变量也是共享的
import threading
import time
my_list = []
def write_data():
for i in range(3):
my_list.append(i)
print(my_list)
def read_data():
print(my_list)
if __name__ == '__main__':
write_thread = threading.Thread(target=write_data)
read_thread = threading.Thread(target=read_data)
write_thread.start()
time.sleep(1)
read_thread.start()
for i in range(3, 6):
my_list.append(i)
print(my_list)

4、主线程与子线程的结束顺序
对比进程
主线程也是会默认等待所有的子进程执行结束后主线程再结束
import threading
import time
def work():
for i in range(3):
print('working...')
time.sleep(0.5)
if __name__ == '__main__':
work_thread = threading.Thread(target=work)
work_thread.start()
time.sleep(1)
print('主线程执行结束')

设置守护线程的两种方式
方式一:
# 创建子线程的同时设置守护线程
work_thread = threading.Thread(target=work,daemon = True)
方式二:
# 通过设置方法设置守护线程
work_thread = threading.Thread(target=work)
work_thread.setDaemon(True)
案例:
import threading
import time
def work():
for i in range(3):
print('working...')
time.sleep(0.5)
if __name__ == '__main__':
# 创建的线程的同时设置守护主线程
# work_thread = threading.Thread(target=work, daemon=True)
work_thread = threading.Thread(target=work)
work_thread.setDaemon(True)
work_thread.start()
time.sleep(1)
print('主线程执行结束')

5、线程的执行顺序
思考:当我们在进程中创建了多个线程,其线程之间是如何执行的呢,按顺序执行?一起执行?还是其他的执行方式呢?
答:线程之间的执行顺序是无序的(由cpu的调度算法决定的)
验证:获取当前线程的线程(current_thread)
# 通过current_thread()方法获取当前线程对象
current_thread = threading.current_thread()
# 通过threading.current_thread对象可以知道线程的相关信息,比如创建的顺序
print(current_thread)
线程的执行顺序:
import threading
import time
def get_info():
# 防止执行速度过快,在另外一个线程启动的时候,该线程已经执行结束
time.sleep(0.3)
current_thread = threading.currentThread()
print(current_thread)
if __name__ == '__main__':
# 按顺序创建线程
for i in range(5):
sub_thread = threading.Thread(target=get_info)
sub_thread.start()
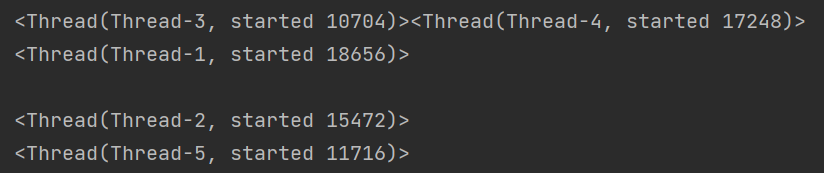
- 线程之间的执行是无序的,是由cpu调度决定哪个线程先执行的。
6、案例之多线程实现TCP服务器端开发
import socket
import threading
class WebServer(object):
def __init__(self):
self.tcp_server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_server_socket.bind(('', 8080))
self.tcp_server_socket.listen(128)
def handle_message(self, new_socket, ip_port):
content = new_socket.recv(1024).decode('gbk')
print(f'接收到客户端{ip_port}发送的数据:{content}')
# reply = input('请输入服务器回复的信息内容:')
new_socket.send('你好!'.encode('gbk'))
new_socket.close()
def start(self):
while True:
new_socket, ip_port = self.tcp_server_socket.accept()
# 每接收到一个客户端的请求连接就创建一个线程
handle_thread = threading.Thread(target=self.handle_message, args=(new_socket, ip_port))
handle_thread.start()
if __name__ == '__main__':
ws = WebServer()
ws.start()
七、进程与线程对比
关系对比
- 线程是依附在进程里面的,没有进程就没有线程
- 一个进程默认提供一条线程,进程可以创建多个线程
区别对比
- 进程之间是不共享全局变量的,线程是共享全局变量的
- 创建进程的资源开销要比创建线程的资源开销要大
- 进程是操作系统资源分配的基本单位,线程是cpu调度的基本单位
- 线程不能独立执行,必须依存在进程中
优缺点对比
1、进程优缺点:
优点:适合做cpu密集型应用,因为可以使用多核
缺点:资源开销大
2、线程优缺点:
优点:适合做IO密集型应用(文件、网络),资源开销小,因为只需要进程中的一点点资源就可以运行
缺点:不能使用多核
点击查看代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号