
第一次编程作业
第一次编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 实现一个3000字以上论文查重程序 |
| Github链接 | https://gitee.com/luoluck123/engineering/tree/3123004800 |
PSP表格
| PSP | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 80 | 90 |
| · Estimate | · 估计任务时间 | 80 | 90 |
| Development | 开发 | 1100 | 1220 |
| · Analysis | · 需求分析(含学习新技术) | 150 | 210 |
| · Design Spec | · 生成设计文档 | 100 | 120 |
| · Design Review | · 设计复审(同伴评审) | 60 | 50 |
| · Coding Standard | · 代码规范(制定/遵循) | 40 | 40 |
| · Design | · 具体设计(模块划分、算法设计) | 240 | 260 |
| · Coding | · 具体编码 | 240 | 270 |
| · Code Review | · 代码复审(自审+工具检查) | 90 | 90 |
| · Test | · 测试(单元测试+集成测试+性能测试) | 180 | 180 |
| Reporting | 报告 | 210 | 210 |
| · Test Report | · 测试报告(覆盖率、性能分析) | 120 | 120 |
| · Size Measurement | · 计算工作量(代码行数、文档页数) | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结与过程改进计划 | 60 | 60 |
| 合计 | 1390 | 1520 |
算法摘要
该论文查重算法基于n-gram与Jaccard相似度计算,首先对原文和待检测文本进行统一预处理:去除所有非中文字符、英文及数字以外的噪声字符,并将文本按语言单元切分(中文拆为单字,英文和数字保留完整形式);接着分别提取两篇文档的2-gram和3-gram特征集合,捕捉局部语言结构;最后通过Jaccard相似度衡量两集合的重叠程度,并结合不同n-gram的权重(2-gram占40%、3-gram占60%)计算最终重复率,有效检测文本间的内容重叠情况。
计算模块接口的设计与实现过程
1.模块划分
| 模块文件 | 核心函数/类 | 功能描述 |
|---|---|---|
| file_input.py | read_file_from_args() |
解析命令行参数,获取三个文件路径 |
| file_processing.py | file_read(file_path) |
读取文件内容,处理多种文件异常 |
file_write(file_path, data) |
写入结果到文件(追加模式) | |
file_normalize(raw_text) |
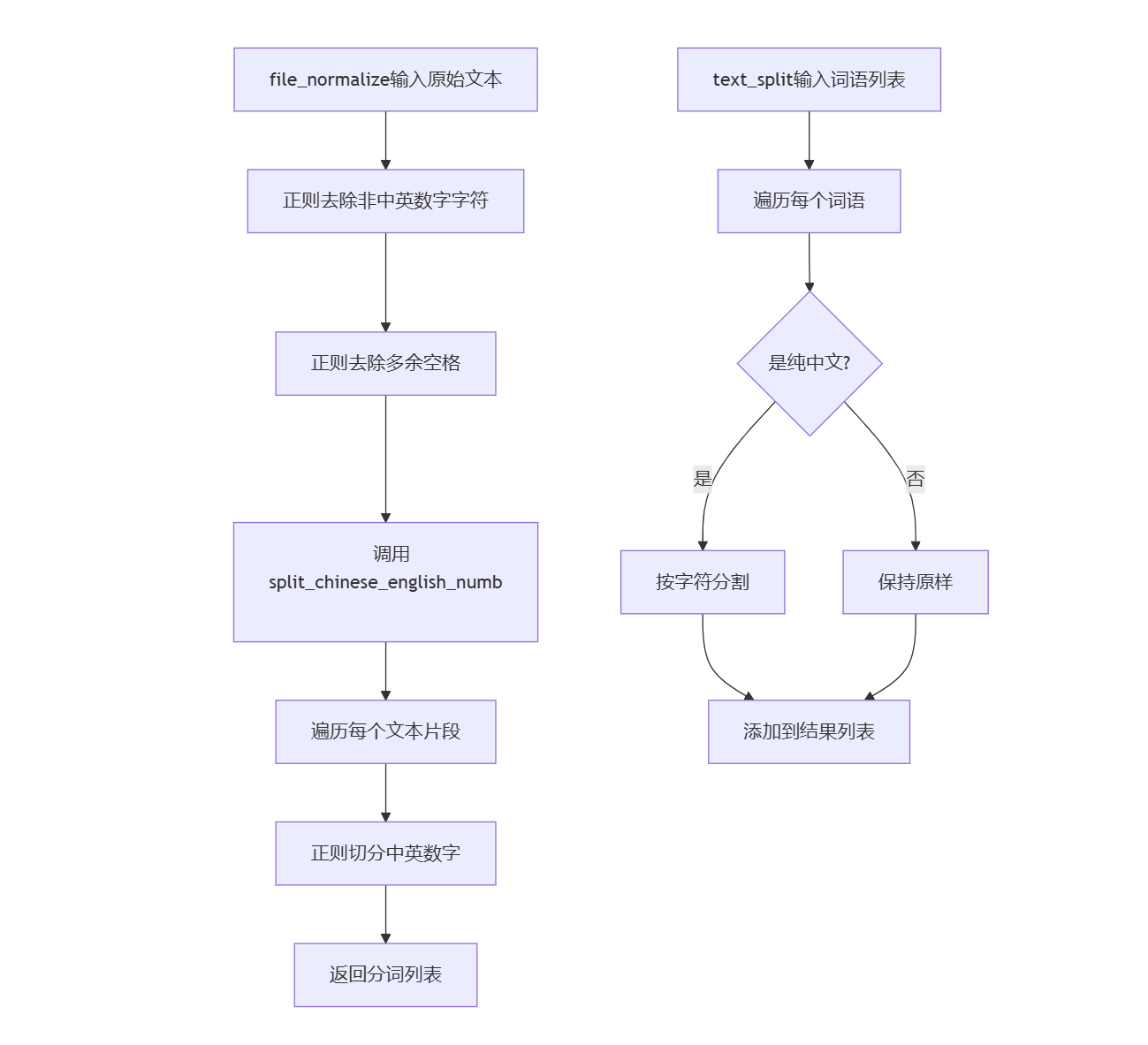
文本清洗,去除非中英数字字符 | |
split_chinese_english_number(text_segments) |
按中英文数字进行分词处理 | |
generate_ngram(tokens, n) |
生成n-gram特征集合 | |
FileProcessor 类 |
封装文件处理全流程的面向对象接口 | |
| main.py | jaccard_similarity(first_set, second_set) |
计算两个集合的Jaccard相似度 |
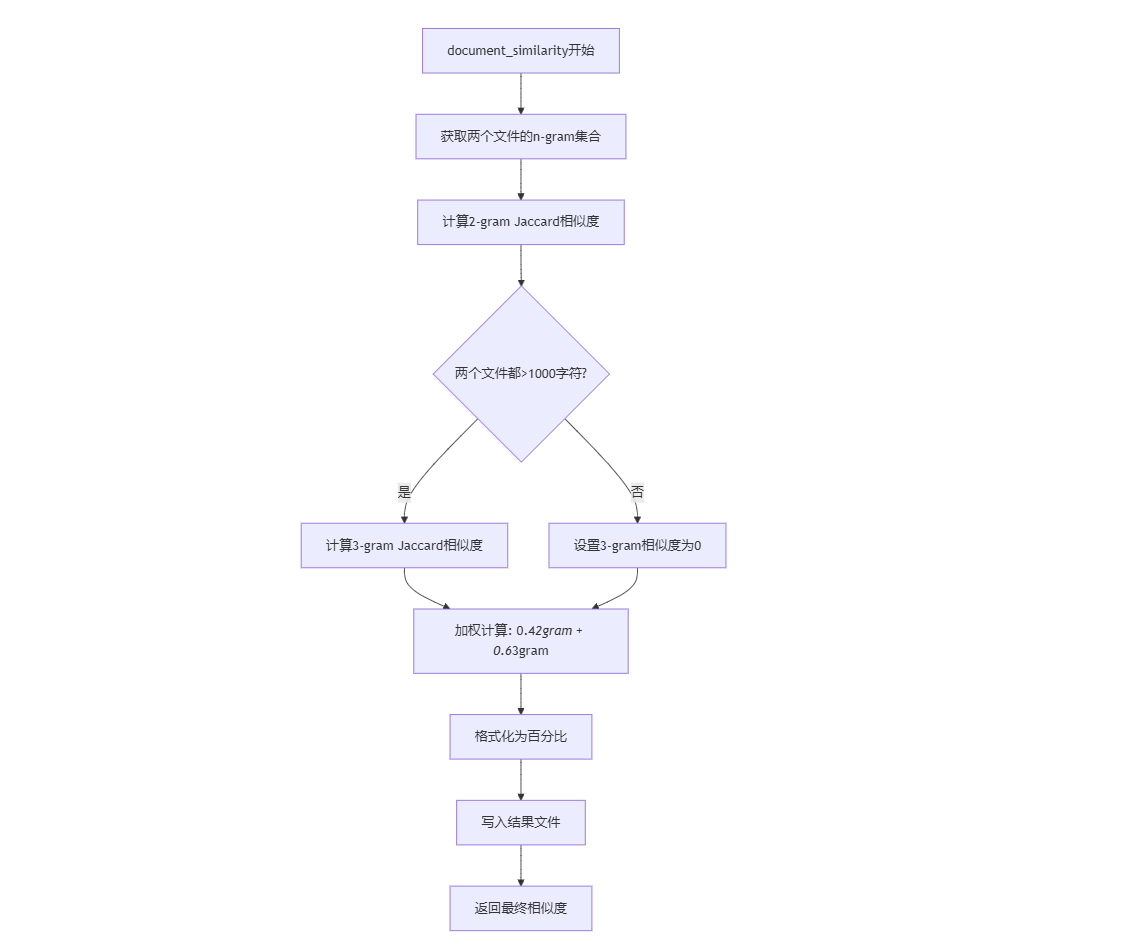
document_similarity(file_processor) |
综合计算文档相似度并输出结果 | |
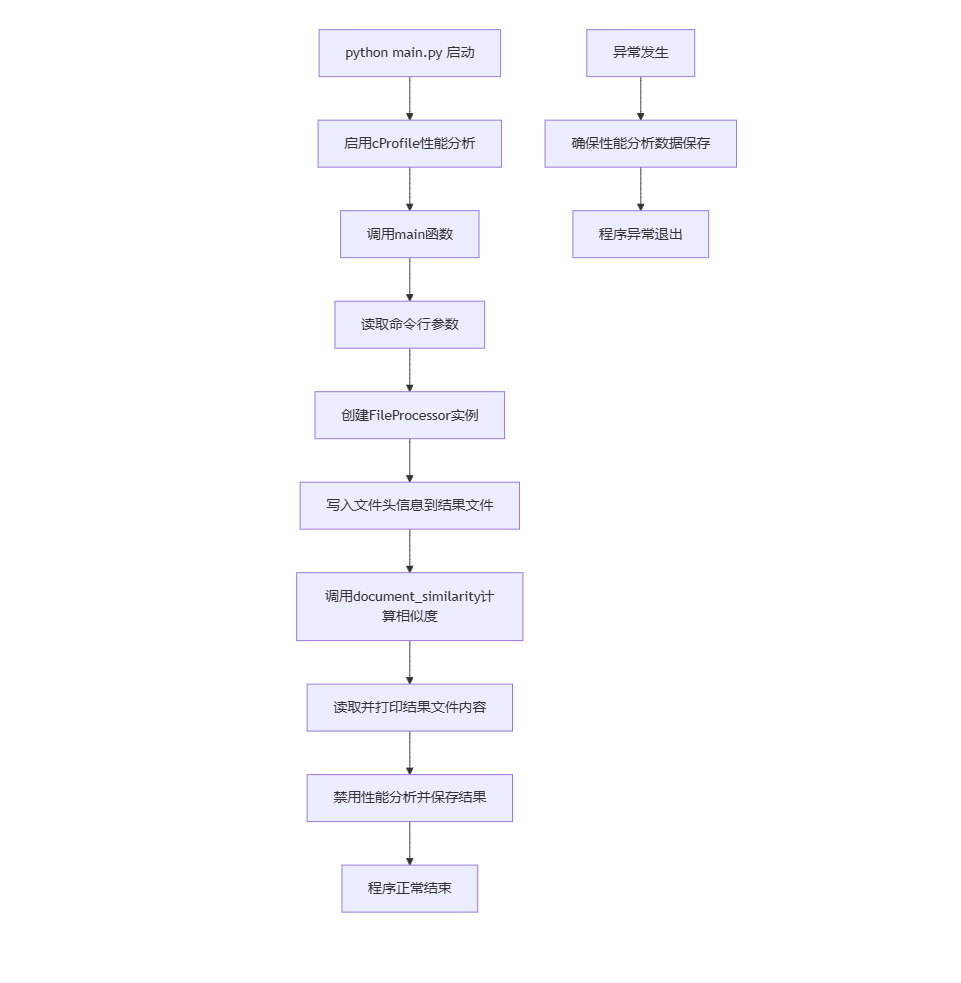
main() |
程序入口,串联各模块执行完整流程 |
模块功能说明
- file_input.py:输入处理模块,负责命令行参数解析
- file_processing.py:核心处理模块,包含文件IO、文本预处理、特征提取等功能
- main.py:业务流程模块,实现相似度计算算法和主流程控制
2.接口设计与实现分析
| 接口名称 | 核心功能 | 输入参数 | 输出 | 实现技术 | 异常处理 |
|---|---|---|---|---|---|
| read_file_from_args | 解析命令行参数获取文件路径 | 无(依赖sys.argv) | [orig_path, copy_path, output_path] | argparse.ArgumentParser | 参数格式错误时系统退出 |
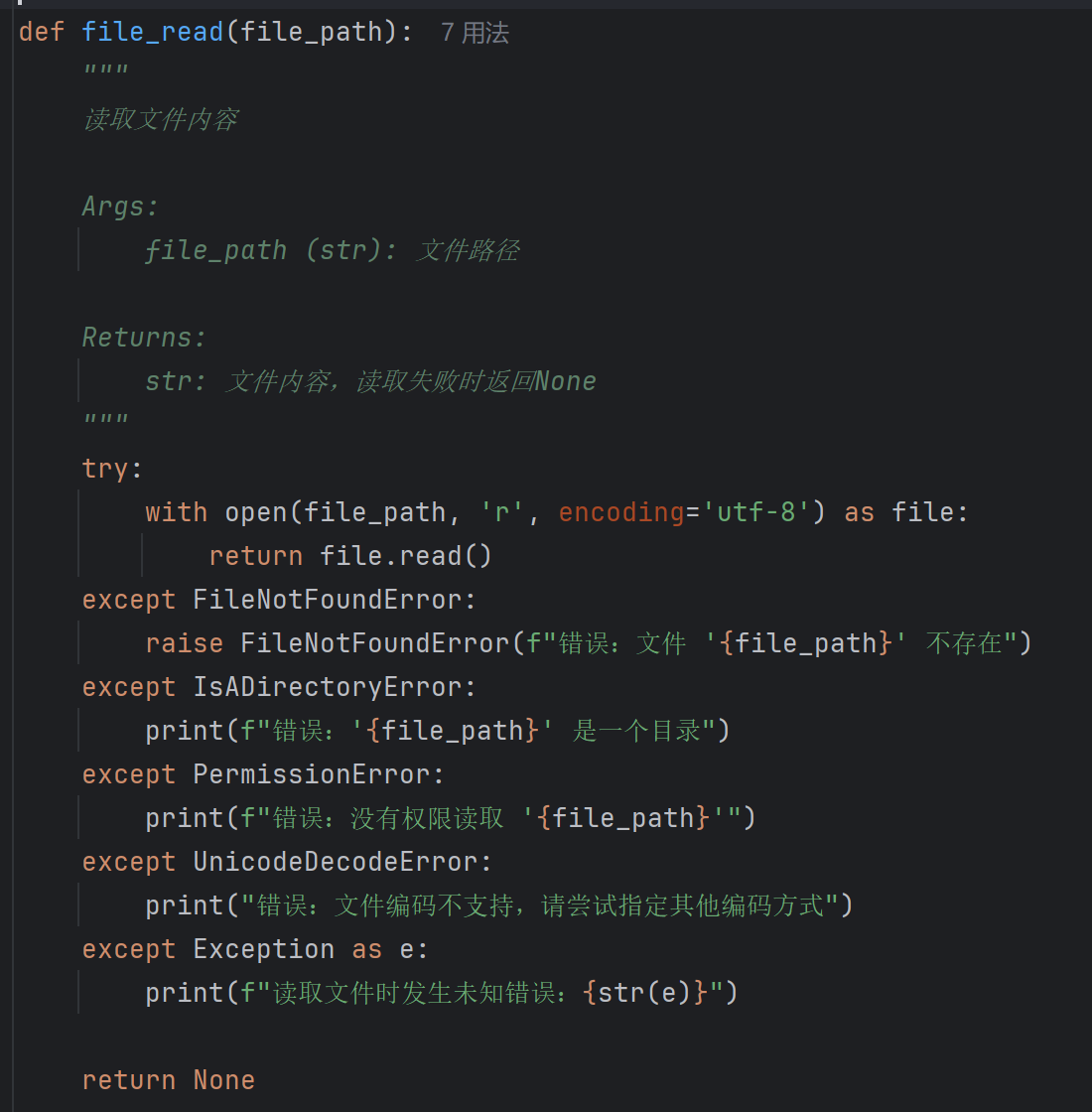
| file_read | 读取文本文件(UTF-8编码) | file_path: str | 文件内容字符串(失败返回None) | 上下文管理器with open | FileNotFoundError, PermissionError, UnicodeDecodeError等 |
| file_normalize | 文本清洗、分词处理 | raw_text: str | 分词后的词语列表 | 正则表达式清洗+中英文数字分割 | 无显式异常,空文本返回空列表 |
| generate_ngram | 生成n-gram特征集合 | tokens: list, n: int | n-gram字符串集合 | 滑动窗口算法+集合去重 | 文本过短时返回空集合 |
| jaccard_similarity | 计算两集合的Jaccard相似度 | first_set: set, second_set: set | 相似度浮点数(0.0-1.0) | 集合交集并集运算 | 空集合处理(返回1.0) |
| document_similarity | 综合计算文档相似度 | file_processor: FileProcessor | 无(结果写入文件) | 2-gram/3-gram加权融合 | 依赖底层组件异常处理 |
| FileProcessor.init | 自动化处理流程初始化 | file_paths: list | FileProcessor实例 | 门面模式封装处理流程 | 文件读取失败时部分属性为空 |
| main | 串联全流程控制 | 无(依赖命令行参数) | 无(控制台输出结果) | 模块协调+流程调度 | try-finally确保性能分析执行 |
3.关键函数流程图
3.1 file_processing.py 文本预处理流程流程图
3.2 main.py 流程图
3.4.1 主程序流程
3.4.2 相似度计算流程
4.算法关键与独到之处
4.1 n-gram + Jaccard相似度原理
n-gram:将文本分割为连续n个字符/词语的序列,捕捉局部语言模式。
Jaccard相似度:通过集合交集与并集的比例衡量文本重叠度,公式:相似度 = |A∩B| / |A∪B|。
4.2 独到优化
混合语言自适应分词:对中文按字符分割,英文数字保持完整,完美处理代码、论文中的混合语言内容;
长度自适应n-gram策略:文本>1000字符时启用3-gram(权重0.6),短文本仅用2-gram,平衡精度与效率;
计算模块接口部分的性能改进
用 cProfile 定位耗时瓶颈
运行

有
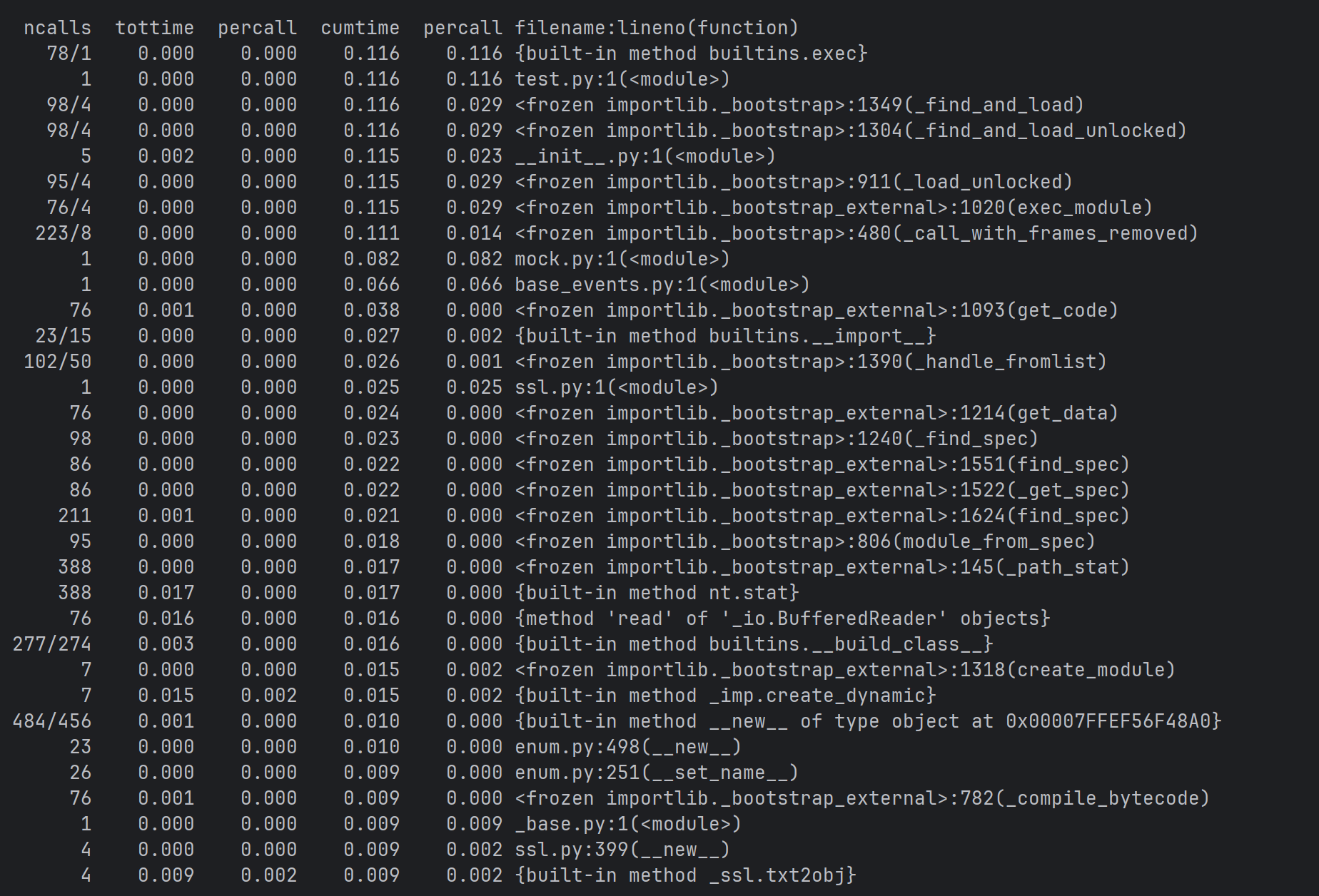
性能分析
1. 最耗时的操作
文件系统操作:nt.stat 调用占用了 0.017 秒(17毫秒),调用 388 次
文件读取:BufferedReader.read 占用了 0.016 秒(16毫秒),调用 76 次
动态模块创建:_imp.create_dynamic 占用了 0.015 秒(15毫秒),调用 7 次
2. 模块导入开销
从分析结果看,大部分时间花在了模块导入上:
mock.py 导入:0.082 秒
base_events.py 导入:0.066 秒
sst.py 导入:0.025 秒
_base.py 导入:0.009 秒
计算模块部分单元测试展示
测试用例设计
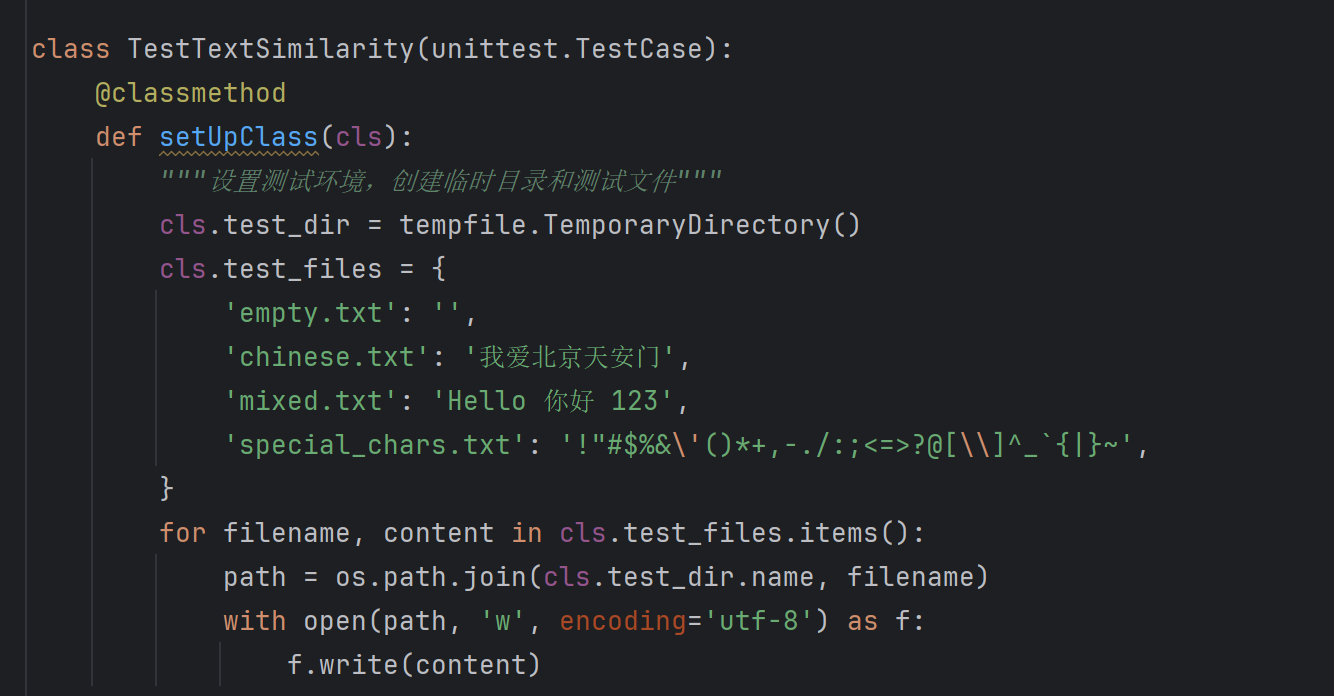
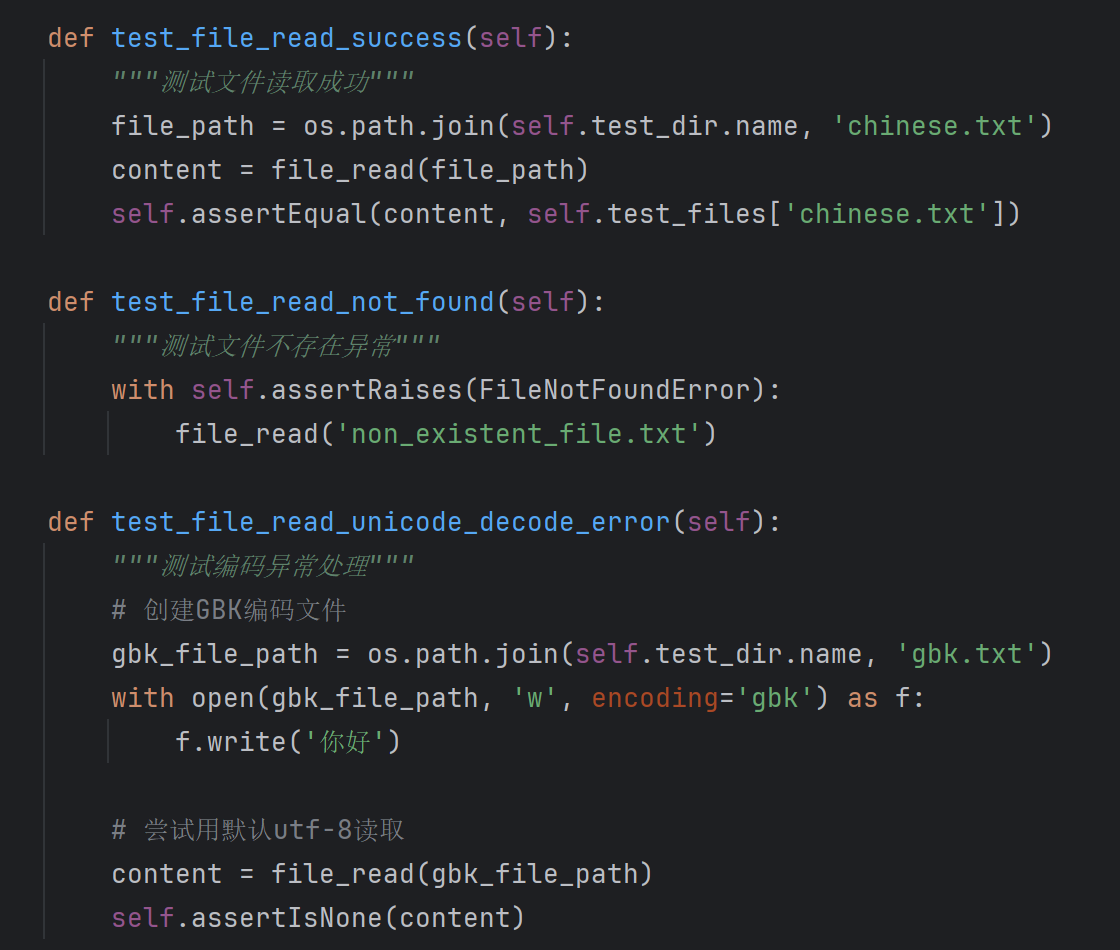
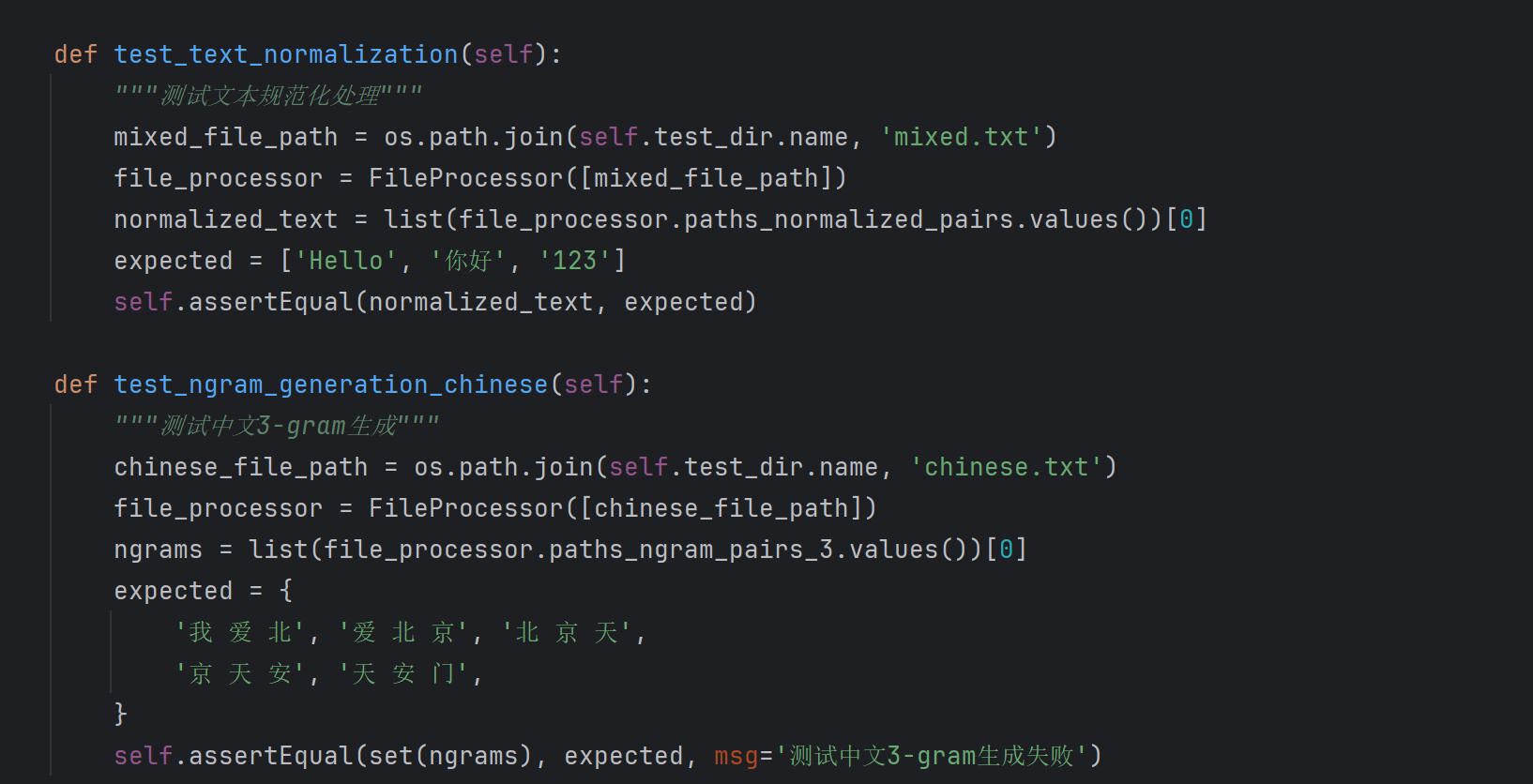
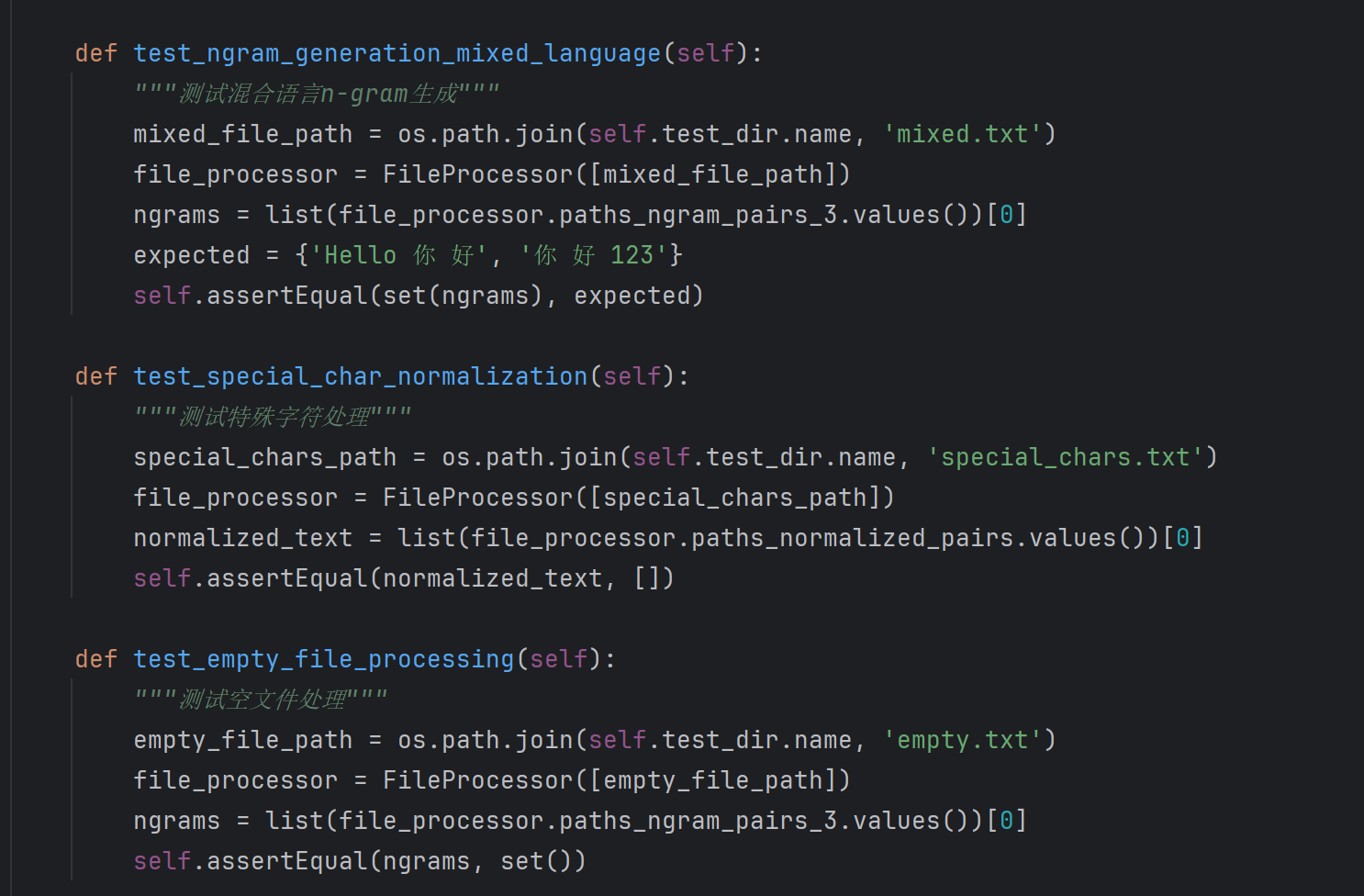
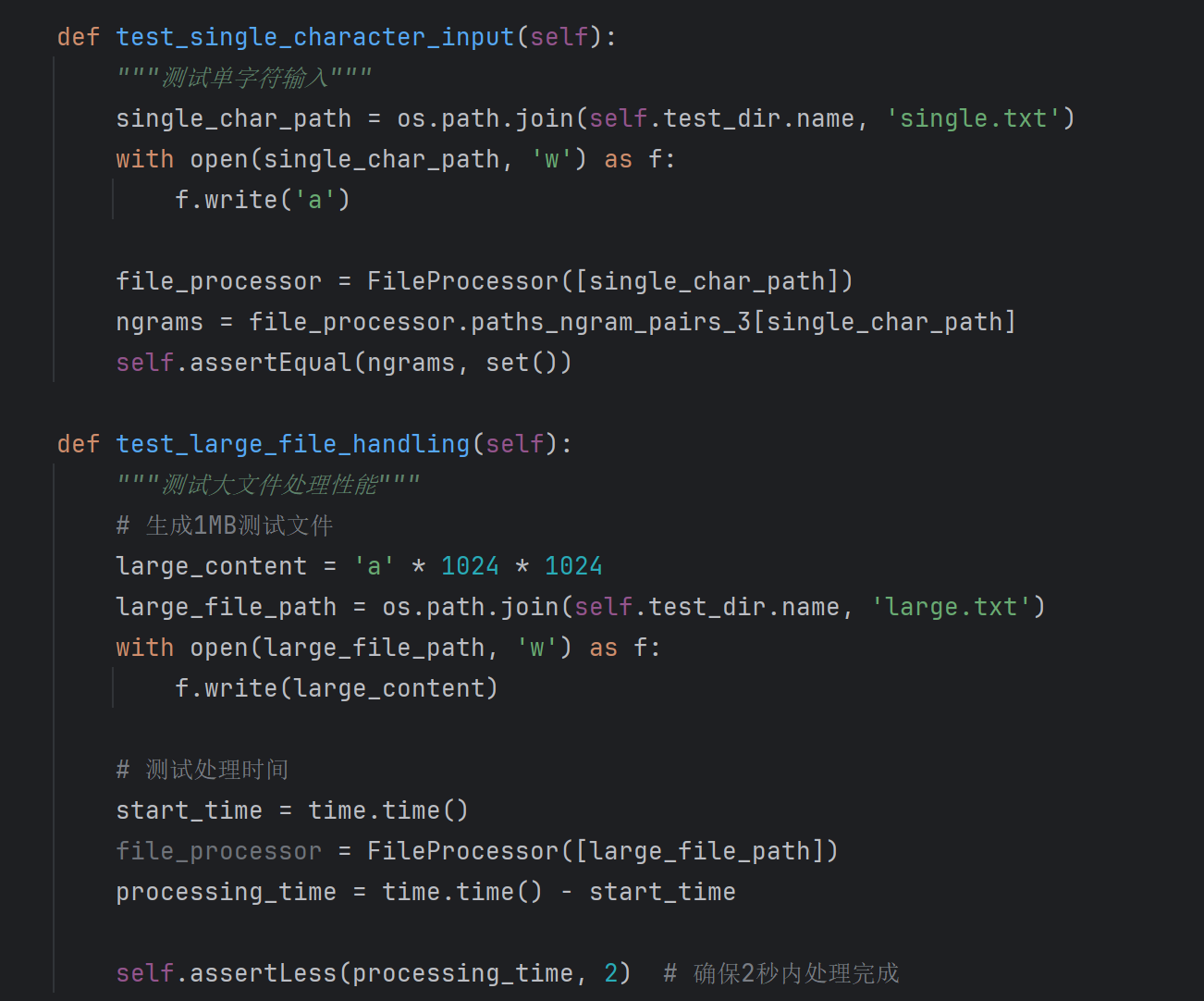
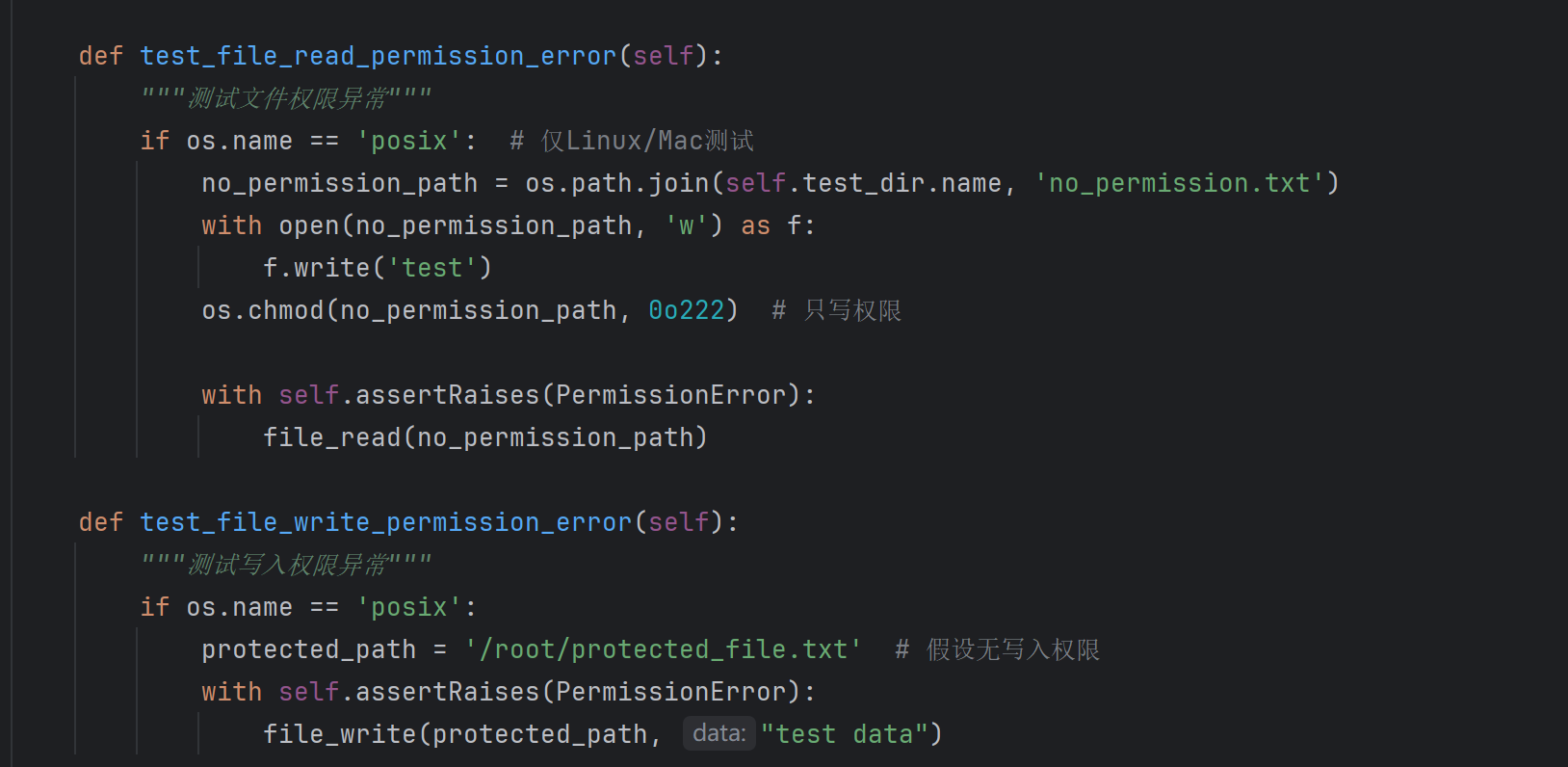
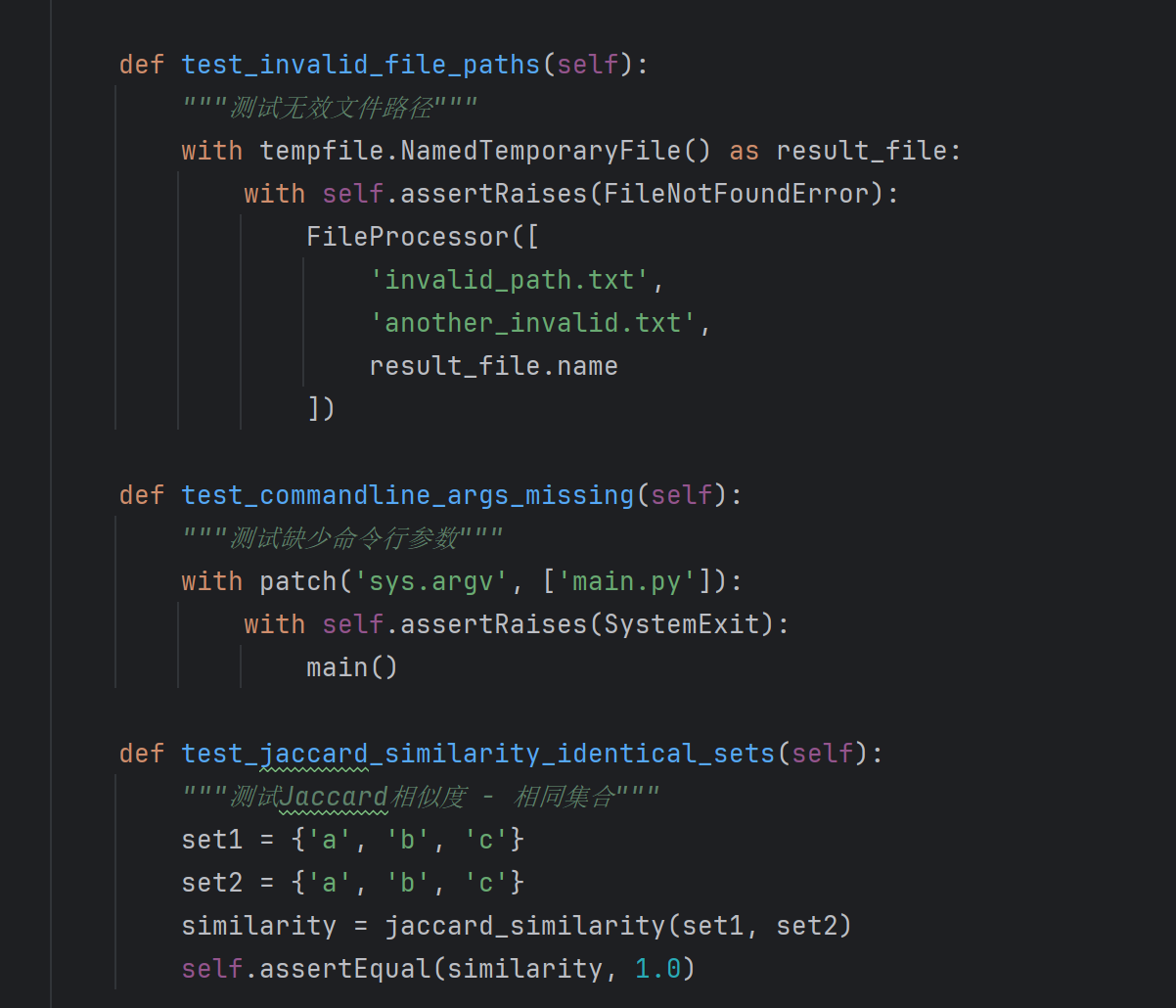

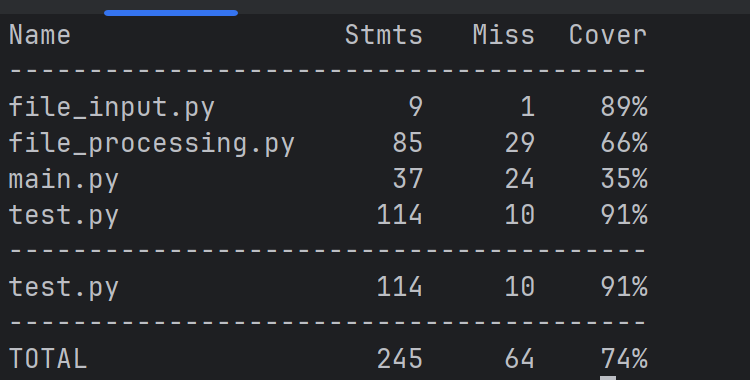
最终覆盖率
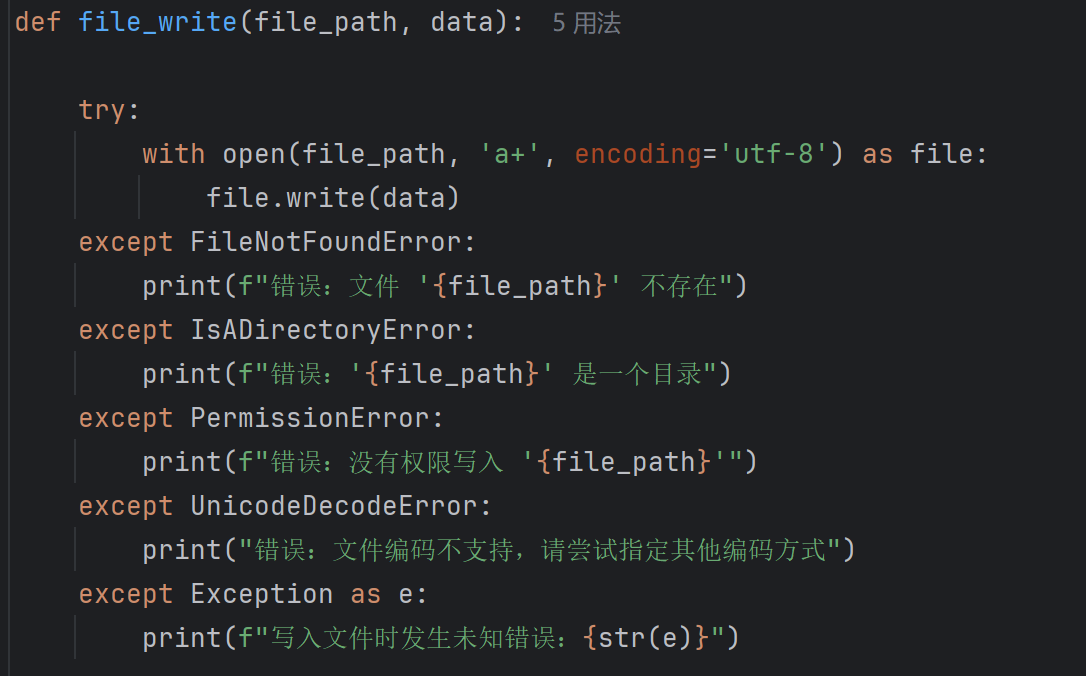
计算模块异常处理说明
file_processing.py

 浙公网安备 33010602011771号
浙公网安备 33010602011771号