C#AI系列(6): C#离线实现高效OCR
本文代码已开源,仅需关注 萤火初芒 公众号回复AISharp即可查看仓库地址,获取完整项目及模型数据,供学习交流使用,无套路(部分测试图片为网图,侵删)。
本文项目在笔记本电脑上(Windows, NET10, x64)就可以自己动手尝试OCR, 实现如身份证识别、截图文本识别、扫描图转pdf等功能。
一、OCR的实现基础
实现OCR,我们直接从Tesseract(Apache 2.0,star 71.4K)开始。Tesseract 是目前最活跃、最精确的开源 OCR(光学字符识别)引擎之一,由 Google 维护。它能把图片中的印刷或手写文字转换成可编辑的纯文本、PDF、HTML 等多种格式,支持包括中文等 100 多种语言。Tesseract 4 以后引入基于深度学习的 LSTM 神经网络模型,对整行文字进行识别,准确率大幅提升。
在C#中调用Tesseract (https://github.com/tesseract-ocr/tesseract) 有两个方式:
- 命令行调用:带参数执行 tesseract.exe 文件,读取控制台获取解析结果。适合简单直观,不需要写代码,直接在终端输入命令即可,且跨语言通用。
- Wrapper调用:使用封装好的C#库直接调用相关函数。适合深度集成,提高性能,减少出错。
命令行调用及参数网上已有很好的详细说明(如https://tesseract-ocr.cn/tessdoc/Command-Line-Usage.html),本文不再赘述(已经包含在仓库项目文件中了噢)。
下面我们通过Wrapper调用的方式来使用Tesseract。C# 目前比较好用的Wrapper有同名的Tesseract(https://github.com/charlesw/tesseract, A .NET wrapper for tesseract-ocr 5.2.0.),在Nuget直接拉取可得到包含运行时和Wrapper库的完整程序,直接开箱即用。
二、Tesseract模型准备
执行OCR之前,要准备训练好模型,可以在官方仓库找到(https://github.com/tesseract-ocr/tessdata_best,https://github.com/tesseract-ocr/tessdata_fast),都是免费。
其中语言类模型(language .traineddata)能直接下载的 100 多种,命名规则就是“语言代码[+方向/变体]”。常用举例的有 eng、chi_sim、chi_tra、jpn、kor、rus、ara、deu、fra、spa、lat 等。另外就是垂直排版变体 chi_sim_vert、chi_tra_vert、jpn_vert、kor_vert, 其他特殊格式等:frak(德文花体)、equ(数学公式)、osd。
三、"四行代码"实现OCR
3.1 核心代码
核心代码就四行,非常简单,代码及注释如下:
// 1. 创建引擎实例(参数:语言包、数据路径)
using (var engine = new TesseractEngine(tessDataPath, "chi_sim + eng", EngineMode.LstmOnly))
{
// 2. 加载图像
using (var img = Pix.LoadFromFile(imgPath))
{
// 3. 创建页面对象
using (var page = engine.Process(img, PageSegMode.Auto))
{
// 4. 获取识别结果
Console.WriteLine("识别结果:\n" + page.GetText());
}
}
}
3.2 模型参数
模型加载时可同时加载多个语言,与命令行参数相似,直接用“+”拼接即可,如"eng + chi_sim + osd"。
3.3 引擎模式
EngineMode,对应命令行参数(OEM,--oem N)。4 选 1,决定用哪套“底层引擎”:
- 0: 仅传统引擎(tesseract 3 时代)
- 1: 仅 LSTM 神经网络(tesseract 4+ 主推)
- 2: 二者都跑,再合并结果
- 3: 自动选择(默认,通常等于 1)
3.4 页面分割模式
PageSegMode,对应命令行参数(--psm N)
共 14 个等级(0-13),决定 Tesseract 把图像当成什么版式来处理:
- 0: OSD only
- 1: 自动分栏 + OSD
- 2: 自动分栏,但不做 OSD 也不 OCR(未实现)
- 3: 完全自动分栏,默认模式
- 4: 单列可变尺寸文本
- 5: 单一垂直文本块
- 6: 单一统一文本块
- 7: 单行
- 8: 单个单词
- 9: 圆圈内的单个单词
- 10: 单个字符
- 11: 稀疏文本(无顺序)
- 12: 稀疏文本 + OSD
- 13: 原始行(绕过 Tesseract 特殊调整)
3.5 注意事项
根据实际需求选择合适的模型来OCR,eng对标点符号的处理比较好,一般均可以带上。如果是识别车牌照文本,或无规律的文本,则需要自行考虑改变页面分割模式,非常影响识别效果。
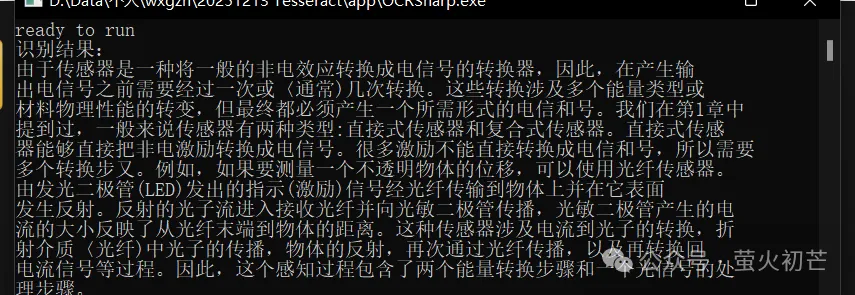
普通文本OCR如下:

结果:
四 扩展应用
4.1 文本块坐标导出及分级处理
遍历page的内部,按block、或word分级获取ocr结果的语言、文本及坐标,这样可以更好辅助实现证件信息读取
using (var iter = page.GetIterator())
{
iter.Begin();
do
{
do
{
do
{
do
{
if (iter.IsAtBeginningOf(PageIteratorLevel.TextLine))
{
iter.GetImage(PageIteratorLevel.TextLine, 0,out var x,out var y);
Console.WriteLine($"<BLOCK> ({x},{y}): {iter.GetWordRecognitionLanguage()}");
}
Console.Write(iter.GetText(PageIteratorLevel.Word));
Console.Write(" ");
if (iter.IsAtFinalOf(PageIteratorLevel.TextLine, PageIteratorLevel.Word))
{
Console.WriteLine();
}
} while (iter.Next(PageIteratorLevel.TextLine, PageIteratorLevel.Word));
if (iter.IsAtFinalOf(PageIteratorLevel.Para, PageIteratorLevel.TextLine))
{
Console.WriteLine();
}
} while (iter.Next(PageIteratorLevel.Para, PageIteratorLevel.TextLine));
} while (iter.Next(PageIteratorLevel.Block, PageIteratorLevel.Para));
} while (iter.Next(PageIteratorLevel.Block));
}
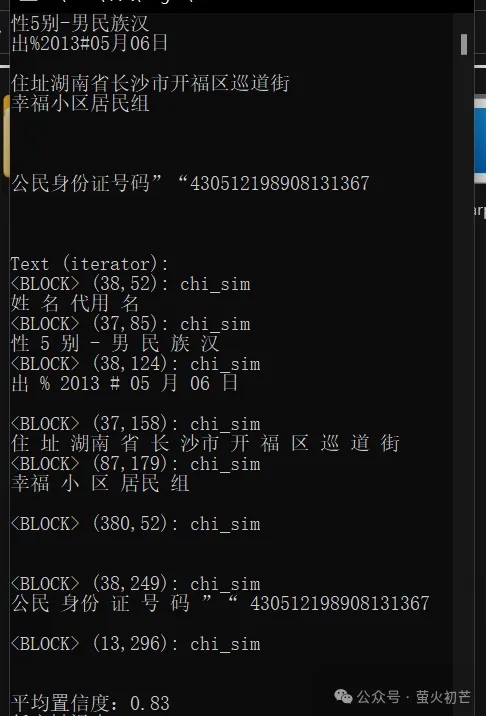
效果如下:

识别后,每个block后面的数字表示当前文本矩形框的左上角xy坐标
4.2 pdf生成
生成导入图像的pdf文件,且pdf中OCR内容区域的文本可被拾取。
using (IResultRenderer renderer = Tesseract.PdfResultRenderer.CreatePdfRenderer(@"test.pdf", tessDataPath, false))
{
// PDF Title
using (renderer.BeginDocument("Serachablepdftest"))
{
using (TesseractEngine engine = new TesseractEngine(tessDataPath, "chi_sim+eng", EngineMode.Default))
{
using (var img = Pix.LoadFromFile(imgPath))
{
using (var page = engine.Process(img, "Serachablepdftest"))
{
renderer.AddPage(page);
}
}
}
}
}
效果如下:
转成pdf文件后的文字拾取效果:

五、单文件打包问题
单文件发布时,可能存在发布成功,但运行程序出现错误的问题。这个与wrapper在加载运行时过程中的文件路径及处理有关。
本项目中对这个wrapper进行了处理,将原来动态加载的非托管库直接写死为win环境下的x64了,这样就可以很好的单文件发布(13.4mb + 模型)及aot发布(3mb + 2.6mb + 4mb + 模型)。
修改后的tesseract(wrapper)可以在仓库里找到。
算上chi_sim和eng模型,所有必须文件加起来独立运行无依赖,一共40mb。
六、 最后
有了tesseract,C#实现ocr也是很方便的事情。简单ocr再也不需要花钱注册会员来整了,随便自己或找个身边的程序员编译下,分分钟就搞定。
感谢您的阅读,本案例及更加完整丰富的机器学习模型案例的代码已全部开源,关注公众号回复AISharp即可查看仓库地址,本期相关代码在仓库下面的OCRSharp文件夹里可以找到。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号