
从零开始:如何用 C# 开发一款媲美 “AnyTxt” 的文件内容搜索工具
说起文件内容搜索工具,那么不得不提到“AnyTxt”,号称本地知识库检索的终极答案。唯一的不足可能就是索引更新机制,不能实时监视文件更改从而更新索引,最小定期更新间隔为半小时,容易导致cpu占用率高,毕竟是全盘全文件类型索引。
很多时候,其实我们对文件内容的搜索,是一个简单文档管理需求,我们期望能的是快速定位文件,而不仅仅是信息。这时候对文件夹以及文件类型的限制就很重要了。还有就是有可能我们会对比如CAD图纸(.dwg、.dxf)的图签或者文件数据库(.db)的表名等特殊文件格式的自定义内容感兴趣。这时候就需要自己来实现扩展了。再加上很多时候,磁盘的信息都是敏感数据,一定要保证软件程序的安全。
因此,我们决定用C#开发一款开源的Windows平台全文搜索工具-TDSContent,并将整个开发过程中的思路与遇到的“坑”记录下来。最终代码与实现已完全开源。https://github.com/LdotJdot/TDSContent
我们接下来将对标AnyTxt的核心功能来TDSContent的技术实现。
二、从对标AnyTxt特性来设计TDSContent技术实现
在网上搜集了AnyTxt的特性与技术优势后,对应地对TDSContent在各个环节的实现进行了分析。具体如下:
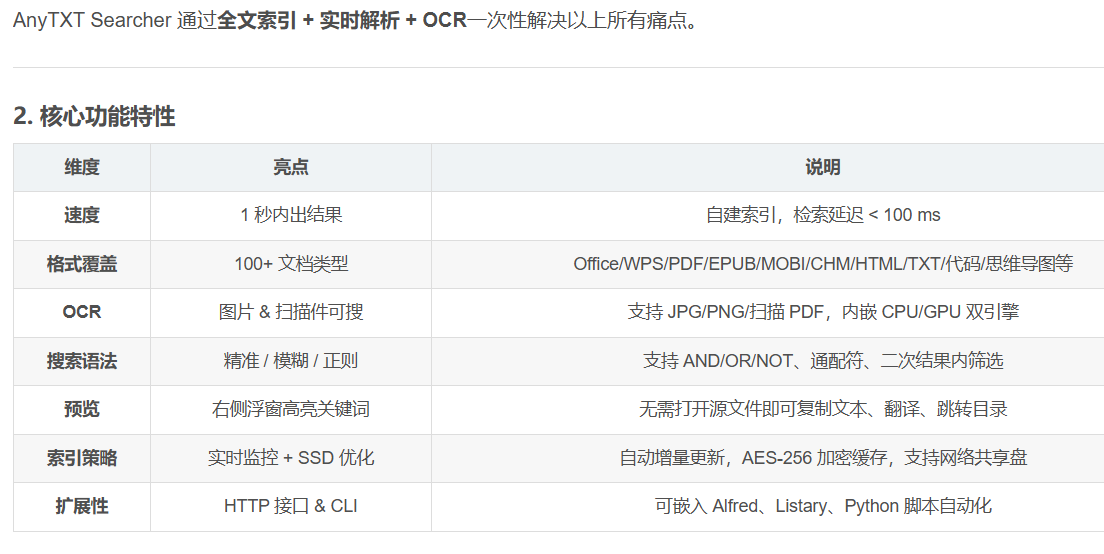
2.1 对标AnyTxt(速度): 1 秒内出结果,自建索引,检索延迟 < 100 ms
文件全文关键词检索的方式大致分两种:
- 直接检索,先枚举出候选文件,在文件中查询出结果,返回对应文件信息。
- 索引检索,在索引中匹配关键词,生成索引匹配结果,返回索引匹配结果对应的文件信息。
直接检索适合于纯文本类的高效搜索,此时信息的读取成本低,即从文件中读取文本与转化速度都快。比较有代表性的就是ripgrep这类工具,直接开多个线程快速扫描所有;
索引检索适合信息量较大、信息的读取成本较高的场景,例如文件读取速度较慢或读取后存在较耗时文本解析过程。此时就需要提取解析文件,将文本索引存储好,提高后续搜索速度。比较有代表性的就是ElasticSearch这类工具。
为了更好支持更多类型文件内容搜索,TDSContent选择的是索引检索这种模式,采用了与ElasticSearch同样的Lucene的.net移植版本Lucene.net作为索引架构。该架构提供了完整的查询引擎和索引引擎,内部通过倒排索引查询,速度响应非常快。对于每个目标文件夹,我们都将单独进行索引创建维护,这样在近实时的更新写入与读取时都有非常好的性能。
现使用是Lucene.Net.Analysis.SmartCn(4.8.0-beta00017,要勾选预览版本才能在Nuget中搜得到),自带了支持中文分词的Analyzer。
2.2 对标AnyTxt(格式):100+ 文档类型,包括 Office/WPS/PDF/EPUB/MOBI/CHM/HTML/TXT/代码/思维导图等
文件内容的检索主要对象就是文本。对文档格式的支持无非就是将文件转换为我们感兴趣的文本信息部分。对于纯文本文件可以直接读取即可,如果是其他类型则需要进行解析转换。
TDSContent默认内置的转换器用开源库实现了几种常用格式的解析:
- PDF: 选择PDFiumCore(Apache-2.0 license),它是对PDFium(BSD-3-Clause license)的封装,可从Nuget直接拉取,提供了.NET的接口,可以直接提取出可读的string文本无需额外转换。其他试过的还有貌似效果更好的iTextSharp,但他的协议AGPL v3,怕有风险。
- docx,pptx: 用Open-XML-SDK(MIT),Nuget直接拉取简单易用。
- dwg: 用ACadSharp(MIT)。现在dwg的解析库已经相对成熟了(遥想几年前dwg的解析还是个难题,还得用Teigha转dxf后再处理)。
- dxf: 用netDxf(MIT),可从Nuget直接拉取。ACadSharp也能解析dxf,但实测下来部分dxf会报错,而netDxf兼容性更好。
- doc,ppt: 20251018新增,用mit开源库实现二进制文件的文本读取(https://github.com/mayswind/SimpleOfficeReader)
- 纯文本: 直接用C#代码读取,包括txt,md,json,log,ini等。
大家可以通过实现项目中的IFileToStringConverter接口,实现自己的格式解析器。
public interface IFileToStringConverter : IDisposable
{
string Extension { get; }
string Convert(string filepath);
}
2.3 对标AnyTxt(OCR):图片 & 扫描件可搜,支持 JPG/PNG/扫描 PDF,内嵌 CPU/GPU 双引擎
TDSContent中对于图片OCR解析转换暂无相关计划,有需要的话可以自己实现。可以考虑使用Tesseract实现本地图片的解析。
2.4 对标AnyTxt(搜索语法):支持精准 / 模糊 / 正则,AND/OR/NOT、通配符、二次结果内筛选
由于基于的是Lucene索引框架,因此TDSContent能支持Lucene的所有查询方式,主要包括:
| 查询方式 | 意义 |
|---|---|
| TermQuery | 精确查询 |
| TermRangeQuery | 查询一个范围 |
| PrefixQuery | 前缀匹配查询 |
| WildcardQuery | 通配符查询 |
| BooleanQuery | 多条件查询 |
| PhraseQuery | 短语查询 |
| FuzzyQuery | 模糊查询 |
| TDSContent默认的是采用”短语查询“,其他查询方式未UI中还未开放,但内部基本已实现。 |
2.5 对标AnyTxt(预览):右侧浮窗高亮关键词,无需打开源文件即可复制文本、翻译、跳转目录
尽管我们在Lucene引擎中,对每个文件的文本内容是通过索引的方式执行了全文存入的。但是我们没有做预览窗口。为了简洁,仅在目标结果文件下方做了最多5行的高亮匹配文本展示。

其他如翻译功能也没实现。
2.6 对标AnyTxt(索引策略):实时监控 + SSD 优化,自动增量更新,AES-256 加密缓存,支持网络共享盘
TDSContent没有实时监控线程。因此文件的更新是通过索引项目的USN日志实现。基于USN的好处是,哪怕用户在程序关闭状态下执行内容修改、重命名、文件夹修改、路径移动等操作,当下一次程序启动时,会依照记录自动实现对应索引结构更新。这样会非常经济且高效,不会有严重的卡顿以及频繁扫盘等问题,尤其不影响笔记本续航,缺点就是必须依赖USN。
2.7 对标AnyTxt(扩展性)
本项目为开源免费软件,可任意扩展。
三、其他
关于UI的优化及界面的实现可以参考这一篇。其他的关于数据组织及存储更新机制,感兴趣的可关注微信公众号萤火初芒,我们会在后面和大家详细分享。
如果你对这款工具有任何建议或想法,欢迎随时交流!项目已在 GitHub 完全开源 https://github.com/LdotJdot/TDSContent

 浙公网安备 33010602011771号
浙公网安备 33010602011771号