零碎知识点 -- 20200409
01.索引是帮助mysql高效获取数据的排序号的数据结构。
02.索引数据结构:(https://www.cs.usfca.edu/~galles/visualization/Algorithms.html)
- 二叉树(数据连续增长时候,树会失去平衡,极端情况可能会退化成链表,不会加速查询了)
- 红黑树(二叉树生长过程遇到的极端情况,红黑树可以通过左旋把非叶子结点调整到叶子节点,一定程度的平衡了二叉树)
- b-tree
* 节点中存放多个索引数据,从左到右递增排列
* 叶子节点都具有相同的深度,叶子节点的指针为空
* 所有索引元素不重复
- b+tree
* 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
* 叶子节点包含所有索引字段
* 叶子节点之间用指针连接,提高区间访问的性能(很方便的从当前叶子节点到下一个叶子节点)
* 一个节点通常为16KB(show global status like 'Innodb_page_size')
@ 节点中的索引和其子节点的地址是成对出现的大于占用空间【bigint(8B)+6B(指针)】,也即一个节点中包含16KB/14B=1170
@ 假设树的高度为3,假设叶子节点可以存储16个【索引+数据】
@ 那么当前数据结构可以容纳1170*1170*16结构为2100万个数据。
- hash表
* 主要用在等值查找,不适用于范围查找
* mysql对hash冲突解决的非常好
03.数据库存储引擎是针对数据库表的
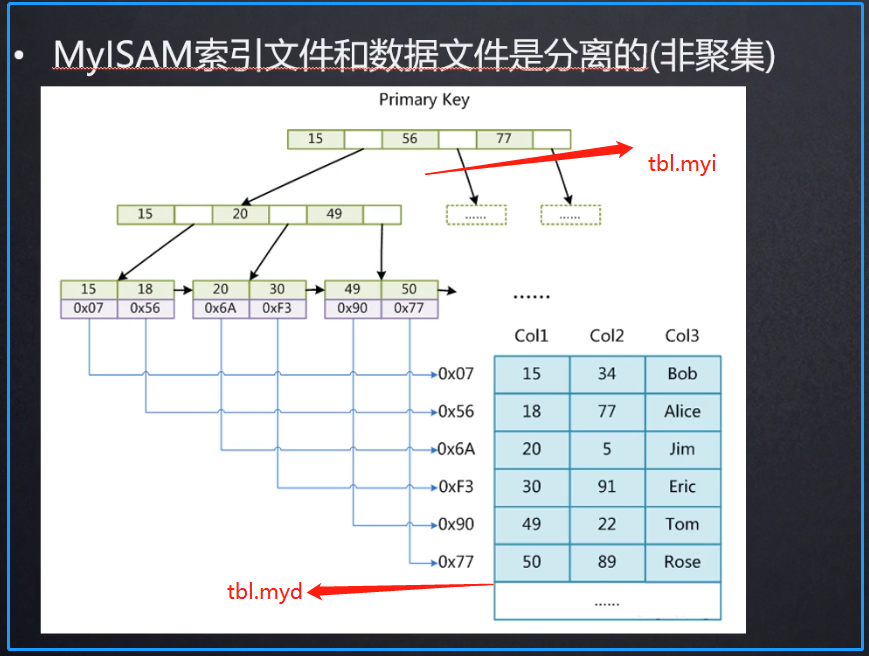
04.myisam存储引擎对应文件结构(索引文件和数据文件是分离的-非聚集)
- table_name.frm 文件描述表的结构
- table_name.MYD 存储数据表中的记录
- table_name.MYI 存储索引信息
- 有索引的情况下查询时候,会查完myi,拿到索引后再次查myd(成为回表)
05.innodb存储引擎对应文件结构(innodb行级锁,使用不当变成表级的锁,多用于高并发环境)
- table_name.frm 文件描述表的结构
- table_name.ibd 存放数据和索引的文件
06.innodb索引实现(聚集)
- 表数据文件本身就是按照b+tree组织的一个索引结构文件
- 聚集索引的叶子节点包含了完整的数据记录
- 为什么InnoDB表必须有主键,并推荐使用整型自增主键?
* 数据是B+tree组织的,肯定要包含主键索引
* 使用整型存储空间少
* 使用整型检索排序快,uuid要转换为ascii码逐一比对
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省空间)
07.mysql一个select只会使用一个索引,虽然可能建立了多个索引,且索引的类型只有hash/btree两种。
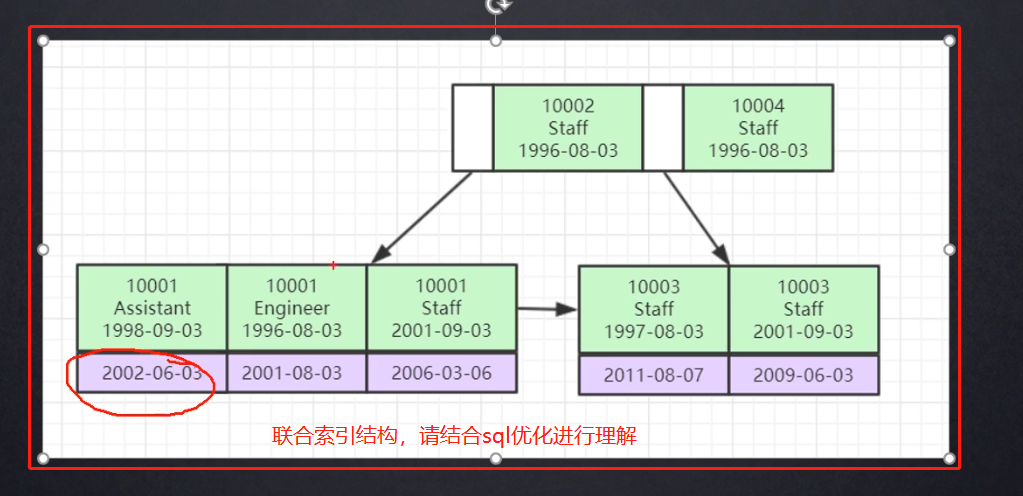
08.联合索引(比单值索引要更常用)的底层存储结构:
- 单值索引里面都是单个列的值,联合索引里面有多个列的值,检索的时候,就会按照where条件一次使用每个节点里面的多列值进行定位。
09.explain工具的复习(https://www.bilibili.com/video/BV1Vs411M7Qi?p=19)
- explain 表的读取顺序,读取操作类型,可能会使用的索引,实际被使用的索引,表之间的引用,多少记录被优化器查询。
- 执行结果包含字段 id | select_type | table | type | possible_keys | key | key_len | ref | rows | extra
- id如果相同:执行顺序从上到下(常见join查询);id不同:id大的优先查询(常见子查询);id相同不同时存在:结合前两个规则。
- select_type:有6个取值。
* derived:在from列表中包含的子查询被标记为derived(衍生)
* primary:sql中包含子查询时候,最外层查询被标记为primary
- type:取值范围:system > const > eq_ref > ref > range > index > all
* system: 表只有一行记录(等于系统表),是const类型的特例
* const: 表示通过索引一次就找到了,常见primary key 或unique出现在where列表中
* eq_ref: 表示唯一索引扫描,每个索引键,对应只有一条记录。常见主键或者唯一索引扫描。
* ref: 非唯一性扫描,返回匹配某个单独值的所有行,本质上是索引访问,可能返回多个结果,所以属于查找和扫描的混合体。
* range: 只检索给定范围的行,使用一个索引来选择行,explain的key列显示了使用的索引,一般sql中where用到了范围会有range,这个至少比全表扫描好。
* index: full index scan,区别与all的是只遍历索引树。
* all: 全表查询(上百万数据all肯定要优化了)
- key_len:越短越好,表示可能的最大长度,并非实际使用长度。根据表定义计算而得,不是通过检索而得。
- row: 表示多少行记录可能被加载到内存,这个值肯定是越少越好。
- extra(危险取值):
* using filesort: 是危险信号。表示排序没有按照索引建立的顺序进行排序。
* using temporary:使用了临时表保存了中间结果,对查询结果排序或分组的时候会使用临时表,常见order by 或group by
* using index: 表示select操作使用了覆盖索引(covering index),效率会不错,
若同时出现了using where表示覆盖索引用来执行索引键值的查找,
若没有出现using where表示通过索引来加载数据,而非执行查找动作。
10.sql优化
- 建立索引
- 避免索引失效
- explain sql,检查索引的使用情况,删除不好的索引,建立可靠的索引。
11.索引失效:
- 尽量使用全值匹配
- 最佳左前缀:查询按照索引的顺序,从最左方用,不要跳过,否则会导致索引失效(结合下面补的图来理解理解)。
- 不在索引列上做任何操作(计算、函数、类型转换(字符串不加引号也会失效索引)),否则失效导致全表扫描
- 尽量使用覆盖索引,尽量不要select *
- != <> 无法使用索引
- is null, is not null 无法使用索引
- like('%abc...'),索引失效,like('abc..%')不会导致失效。
- 用or连接会导致索引失效
12.索引建立原则:
- 排序字段
- where条件字段
- 使用覆盖索引(covering index):
* select列中的数据从索引中就可以获取到,不必读取数据行,查询的列被建立的索引覆盖了。
13.如果锁定数据库中的某一行:
- begin;
- select * from table where a=9 for update; --重点是for update
- 做一些操作
- commit;
14.行锁变成表锁:
- innodb索引失效后行锁会变成表锁,varchar没有添加引号,事务没有进行提交,别的事务会被阻塞。
15.间隙锁危害:
- where锁住了不存在的记录,会影响别的事务对范围内不存在的记录的添加。
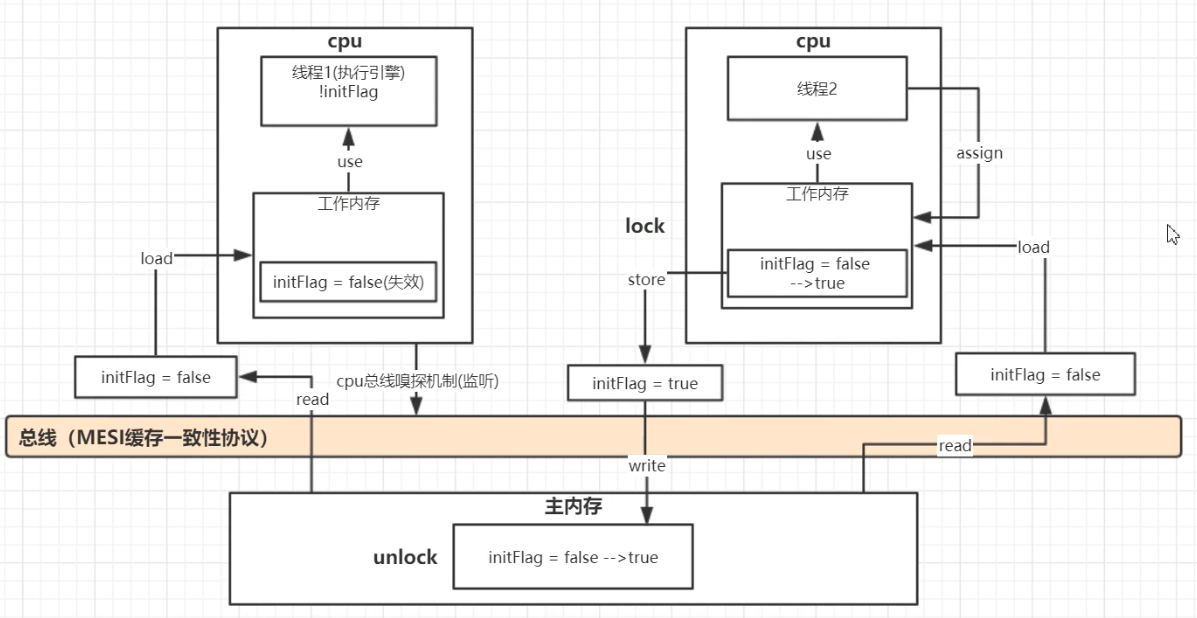
16.volatile
- volatile修饰的变量对应的汇编指令前都有一个lock指令
- lock指令的功能
* 将当前处理器缓存行的数据立即写回到系统内存
* 这个写回内存操作会引起在其他cpu里缓存了该内存地址的数据无效(MESI协议,缓存一致性协议)
* 当前处理器处理被修饰的变量的时候会加一把锁,处理完之后会释放锁
- 内存屏障,有序性
17.mysql集群搭建
- io thread 读取主节点的binlog,保存中继binlog
- sql thread 读取中继过来的binlog,并执行
- binlog里面只记录增删改,不记录查询日志
- 常用命令:
* show binary logs;--查看所有的日志文件;
* show master status; --查看当前使用的日志文件,及日志position
* show binlog events in 'mysql-bin.000003'; --查看binlog日志
* start slave
* stop slave
* show slave status


 浙公网安备 33010602011771号
浙公网安备 33010602011771号