
字符集及编码
一 ASCII字符集及本地化扩展
ASCII(American Standard Code for Information Interchange)使用一个字节表示英语世界内的常用符号。其中,0到32状态表示一些控制字符,33到127状态表示标点,数字,字母等。
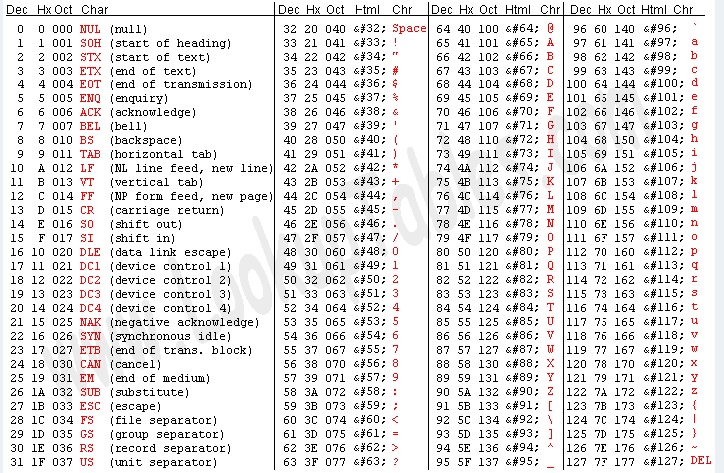 (来自 www.asciitable.com)
(来自 www.asciitable.com)
针对多数西方语言,只需要扩展后8位即可满足某种语言的需求,这就形成了 SBCS(Single-byte character sets),比如针对美式英语使用代码页1252等。
当需要表示象形文字时,一个字节已经无法完成编码,这需要使用DBCS(Double-byte character sets), 针对简体中文,出现了GB2312编码,其代码页为936,编码规则如下:
1)针对ASCII码0到127状态;
2)取消ASCII码扩展部分,使用扩展部分(0XA1-0XF7)与下一个字节高四位(0XA1-0XFE)组合表示汉字,则可表示大约七八千简体汉字。
这部分编码也重复包括了一些数学符号,标点符号等,即全角字符。而ASCII码中符号被称为半角字符。
GB2312后面还进行了一些扩展,但针对简体中文本地化编码中,通常使用GB2312编码。繁体中文使用BIG5编码,代码页为950。到目前为止,针对ASCII即其之上的扩展(如GB2312),编码与字符集可以视为等同的。
在Windows代码页中,编码大于50000的代码页使用多字节表示字符(何时使用未知?),所以在VS开发环境中,多字节字符集也包括:1 单字节字符集;2 双字节字符集。
二 UNICODE字符集
使用ASCII字符集及本地化解决方案(如GB2312,BIG5等),可以在计算机上使用不同语言。但在跨语言交流中,需要一个统一的编码方式,这就是UNICODE字符集(Universal Multiple-Octet Coded Character Set),其基本规则如下:
1)使用两个字节表示字符;
2)对ASCII字符直接一个字节补零扩展到两个字节;
3)使用其他状态表示世界上其他语言字符。
UNICODE字符集可以被多种方式编码,其中,字符集定义就是一种编码方式。在VS开发环境中,将字符集选择为:Use Unicode Character Set,编译器使用 UNICODE _UNICODE选项,这直接导致TCHAR被定义为wchar_t,系统按UNICODE字符规则使用两个字节表示一个字符。当字符集选择为:Use Multi-Byte Character Set,编译器使用 _MBCS 选项,TCHAR被定义为char,系统使用ASCII字符集及本地化解释字符。
UNICODE可以使用不同方式编码,包括UTF8, UTF16等,在网络上一般使用UTF8作为UNICODE编码实现,基本规则如下:
1)对UNICODE前127个字符,使用一个字节编码;
2)对剩下的字符,针对不同区间,使用2,3,4个字节编码,其中每个字节开始插入10,110,1110,11110等;
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
三 字符集间转换
在编程应用中,windows提供了不同字符集间转换函数,如下:
MultiByteToWideChar:将多字节转换为UNICODE字符集定义编码,其中多字节包括:1)ASCII字符集及本地化;2)UTF8(UNICODE变长编码方案)等。
WideCharToMultiByte:将UNICODE字符集定义编码转换为多字节编码。
1 char* str_ascii = "中"; // ASCII扩展,简体中文中为GB2312 2 wchar_t str_ucs[260]; 3 char str_utf8[260]; 4 char str_ascii2[260]; 5 memset(str_ucs, 0, 260* sizeof(wchar_t)); 6 memset(str_utf8, 0, 260); 7 memset(str_ascii2, 0, 260); 8 9 // GB2312编码转换为unicode字符集 10 MultiByteToWideChar(CP_ACP, 0, str_ascii, strlen(str_ascii), str_ucs, sizeof(str_ucs)); 11 12 // unicode字符集转换为GB2312编码 13 WideCharToMultiByte(CP_ACP, 0, str_ucs, wcslen(str_ucs), str_ascii2, sizeof(str_ascii2), NULL, NULL); 14 15 // unicode(utf16)字符集转换为utf8编码 16 WideCharToMultiByte(CP_UTF8, 0, str_ucs, wcslen(str_ucs), str_utf8, sizeof(str_utf8), NULL, NULL); 17 18 // utf8编码转换为unicode(utf16)字符集 19 MultiByteToWideChar(CP_UTF8, 0, str_utf8, strlen(str_utf8), str_ucs, sizeof(str_ucs));
四 windows处理UNICODE与本地化规则
windows NT 内部使用UNICODE处理字符集,同时也鼓励应用软件使用UNICODE方案,这样的应用软件可以很容易本地化。由于历史原因,很多软件仍然使用多字节字符集方案,在注册表目录 HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Nls\CodePage下可以查看当前字符集设置,如下:
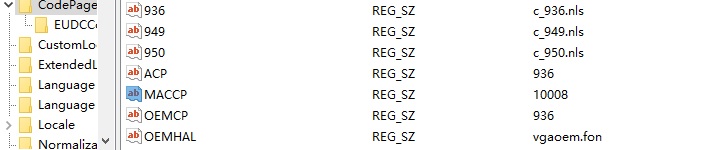
其中,ACP表示 Ansi code page,OEMCP表示 OEM code page,MACCP表示 Mactonish code page,当前设置为简体中文,具体信息可查下表(通过系统函数获得):


37 (IBM EBCDIC - 美国/加拿大) 437 (OEM - 美国) 500 (IBM EBCDIC - 国际) 708 (阿拉伯语 - ASMO) 720 (阿拉伯语 - 透明 ASMO) 737 (OEM - 希腊语 437G) 775 (OEM - 波罗的语) 850 (OEM - 多语言拉丁语 I) 852 (OEM - 拉丁语 II) 855 (OEM - 西里尔文) 857 (OEM - 土耳其语) 858 (OEM - 多语言拉丁语 I + Euro) 860 (OEM - 葡萄牙语) 861 (OEM - 冰岛语) 862 (OEM - 希伯来语) 863 (OEM - 加拿大法语) 864 (OEM - 阿拉伯语) 865 (OEM - 挪威语) 866 (OEM - 俄语) 869 (OEM - 现代希腊语) 870 (IBM EBCDIC - 多语言/ROECE (拉丁语-2)) 874 (ANSI/OEM - 泰语) 875 (IBM EBCDIC - 现代希腊语) 932 (ANSI/OEM - 日语 Shift-JIS) 936 (ANSI/OEM - 简体中文 GBK) 949 (ANSI/OEM - 朝鲜语) 950 (ANSI/OEM - 繁体中文 Big5) 1026 (IBM EBCDIC - 土耳其语(拉丁语-5)) 1047 (IBM EBCDIC - 拉丁语-1/开放系统) 1140 (IBM EBCDIC - 美国/加拿大(37 + Euro)) 1141 (IBM EBCDIC - 德国(20273 + Euro)) 1142 (IBM EBCDIC - 丹麦/挪威(20277 + Euro)) 1143 (IBM EBCDIC - 芬兰/瑞典(20278 + Euro)) 1144 (IBM EBCDIC - 意大利(20280 + Euro)) 1145 (IBM EBCDIC - 拉丁美洲/西班牙(20284 + Euro)) 1146 (IBM EBCDIC - 英国 (20285 + Euro)) 1148 (IBM EBCDIC - 国际(500 + Euro)) 1149 (IBM EBCDIC - 冰岛语(20871 + Euro)) 1250 (ANSI - 中欧) 1251 (ANSI - 西里尔文) 1252 (ANSI - 拉丁语 I) 1253 (ANSI - 希腊语) 1254 (ANSI - 土耳其语) 1255 (ANSI - 希伯来语) 1256 (ANSI - 阿拉伯语) 1257 (ANSI - 波罗的海) 1258 (ANSI/OEM - 越南) 1361 (朝鲜语 - Johab) 10000 (MAC - 罗马) 10001 (MAC - 日语) 10002 (MAC - 繁体中文 Big5) 10003 (MAC - 朝鲜语) 10004 (MAC - 阿拉伯语) 10005 (MAC - 希伯来语) 10006 (MAC - 希腊语 I) 10007 (MAC - 西里尔文) 10008 (MAC - 简体中文 GB 2312) 10010 (MAC - 罗马尼亚) 10017 (MAC - 乌克兰) 10021 (MAC - 泰语) 10029 (MAC - 拉丁语 II) 10079 (MAC - 冰岛文) 10081 (MAC - 土耳其语) 10082 (MAC - 克罗地亚) 20000 (CNS - 台湾) 20001 (TCA - 台湾) 20002 (Eten - 台湾) 20003 (IBM5550 - 台湾) 20004 (TeleText - 台湾) 20005 (Wang - 台湾) 20105 (IA5 IRV 国际字母表 5) 20106 (IA5 德语) 20107 (IA5 瑞典语) 20108 (IA5 挪威语) 20127 (US-ASCII) 20261 (T.61) 20269 (ISO 6937 无空格重音符) 20273 (IBM EBCDIC - 德国) 20277 (IBM EBCDIC - 丹麦/挪威) 20278 (IBM EBCDIC - 芬兰/瑞典) 20280 (IBM EBCDIC - 意大利) 20284 (IBM EBCDIC - 拉丁美洲/西班牙) 20285 (IBM EBCDIC - 英国) 20290 (IBM EBCDIC - 扩展式日语片假名) 20297 (IBM EBCDIC - 法国) 20420 (IBM EBCDIC - 阿拉伯语) 20423 (IBM EBCDIC - 希腊语) 20424 (IBM EBCDIC - 希伯来语) 20833 (IBM EBCDIC - 扩展式朝鲜语) 20838 (IBM EBCDIC - 泰语) 20866 (俄语 - KOI8) 20871 (IBM EBCDIC - 冰岛语) 20880 (IBM EBCDIC - 西里尔文(俄语)) 20905 (IBM EBCDIC - 土耳其语) 20924 (IBM EBCDIC - 拉丁语-1/开放系统(1047 + Euro)) 20932 (JIS X 0208-1990 0212-1990) 20936 (简体中文 GB2312) 21025 (IBM EBCDIC - 西里尔文(塞尔维亚语、保加利亚语)) 21027 (Ext Alpha 小写) 21866 (乌克兰语 - KOI8-U) 28591 (ISO 8859-1 拉丁语 I) 28592 (ISO 8859-2 中欧) 28593 (ISO 8859-3 拉丁语 3) 28594 (ISO 8859-4 波罗的语) 28595 (ISO 8859-5 西里尔文) 28596 (ISO 8859-6 阿拉伯语) 28597 (ISO 8859-7 希腊语) 28598 (ISO 8859-8 希伯来语: 视觉排序) 28599 (ISO 8859-9 拉丁语 5) 28603 (ISO 8859-13 拉丁语 7) 28605 (ISO 8859-15 拉丁语 9) 38598 (ISO 8859-8 希伯来语: 逻辑排序) 50220 (ISO-2022 不带半形片假名的日语) 50221 (ISO-2022 带半形片假名的日语) 50222 (ISO-2022 日语 JIS X 0201-1989) 50225 (ISO-2022 朝鲜语) 50227 (ISO-2022 简体中文) 50229 (ISO-2022 繁体中文) 51949 (EUC-朝鲜语) 52936 (HZ-GB2312 简体中文) 54936 (GB18030 简体中文) 55000 (SMS GSM 7bit) 55001 (SMS GSM 7bit 西班牙语) 55002 (SMS GSM 7bit 葡萄牙语) 55003 (SMS GSM 7bit 土耳其语) 55004 (SMS GSM 7bit 希腊语) 57002 (ISCII - 梵文) 57003 (ISCII - 孟加拉语) 57004 (ISCII - 泰米尔语) 57005 (ISCII - 泰卢固语) 57006 (ISCII - 阿萨姆语) 57007 (ISCII - 奥里亚语) 57008 (ISCII - 埃纳德语) 57009 (ISCII - 马拉雅拉姆语) 57010 (ISCII - 古吉拉特语) 57011 (ISCII - 旁遮普语(果鲁穆奇语)) 65000 (UTF-7) 65001 (UTF-8)
操作系统接收用户输入时使用UNICODE编码,在传递给应用软件前,通过查找当前代码页并根据当前设定代码页进行翻译,应用程序存储翻译后多字节编码信息。
当应用程序需要显示信息时,操作系统根据应用程序传出信息并结合当前代码页翻译为UNICODE编码,操作系统将UNICODE信息输出显示。
通过修改注册表下代码页同时添加对应语言,如修改代码页949并添加朝鲜语言包,即可在多字节应用程序上进行朝鲜语输入输出,而固定界面文字使用英文显示,这在一定程度上可以满足部分本地化需求。如医疗软件中,病人信息以及诊断信息使用本地语言,其他信息使用英文呈现。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号