用python下载B站的视频
两年前初学爬虫,写了这篇博客——用python爬取B站视频,今天再看当时的代码,很繁杂,有些地方可以简化,所以又补充这篇博客,希望对大家有用。
由于B站对视频资源的保护策略,每一个视频的画面和声音数据是分开存放的,下载之后必须要使用其他工具来合并,我推荐ffmpeg。(下载安装教程)
下面是完整的python代码,复制后保存为python文件运行即可。
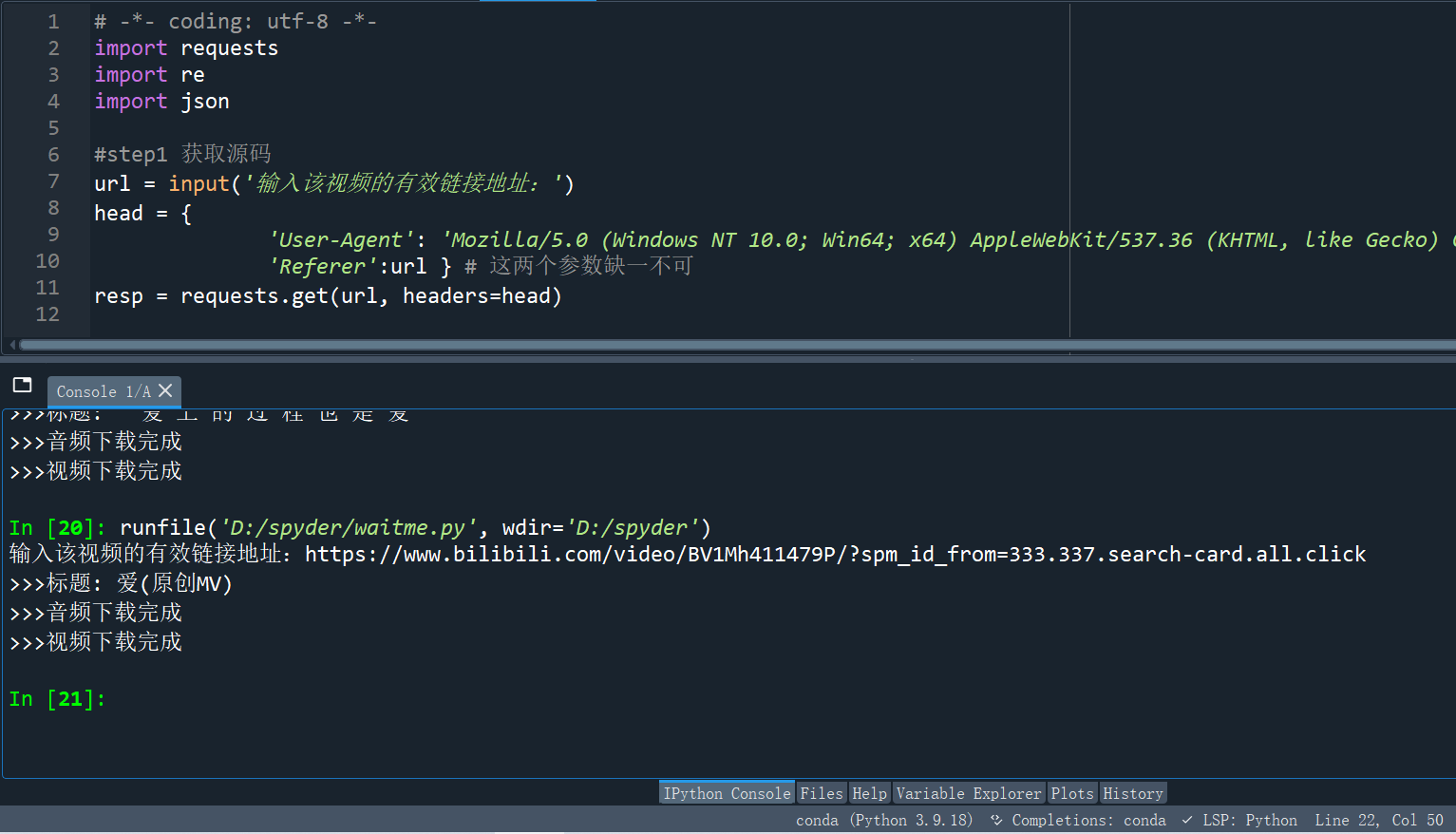
1 # -*- coding: utf-8 -*- 2 import requests 3 import re 4 import json 5 6 #step1 获取源码 7 url = input('输入该视频的有效链接地址:') 8 head = { 9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 Edg/91.0.864.67', 10 'Referer':url } # 这两个参数缺一不可 11 resp = requests.get(url, headers=head) 12 13 #step2 提取标题 14 title = re.findall('<h1.*>(.*?)</h1>',resp.text)[0] 15 print('>>>标题:',title) 16 17 #step3 获取音频和视频 18 json_data = re.findall('<script>window.__playinfo__=(.*?)</script>', resp.text)[0] 19 json_data = json.loads(json_data) 20 21 audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0] 22 audio_data = requests.get(audio_url,headers=head) 23 with open(title+'.mp3', mode='wb') as f: 24 f.write(audio_data.content) 25 print('>>>音频下载完成') 26 27 video_url = json_data['data']['dash']['video'][0]['backupUrl'][0] 28 video_data = requests.get(video_url,headers=head) 29 with open(title+'.mp4', mode='wb') as f: 30 f.write(video_data.content) 31 print('>>>视频下载完成')
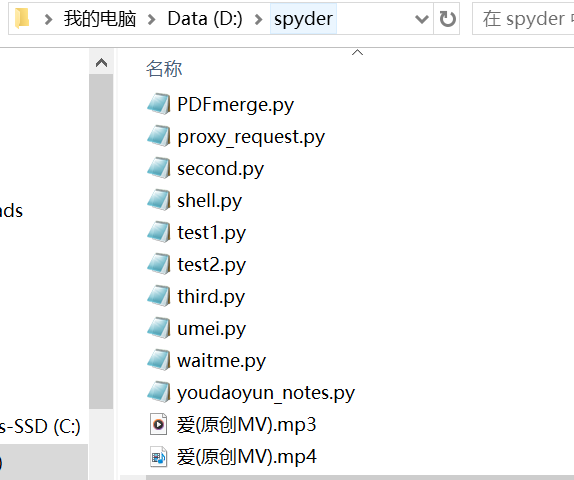
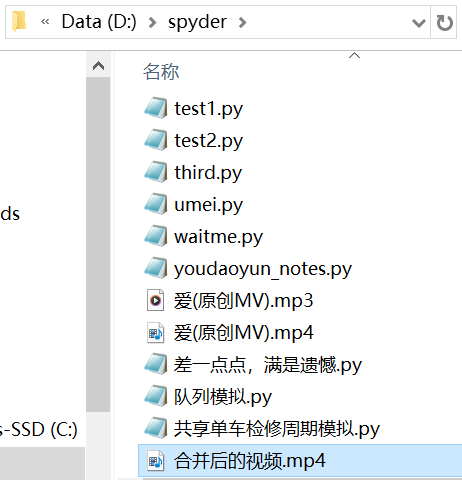
下面是一个使用示例,下载好的音频和视频保存在你存放该程序的文件夹里。
注意:
1.requests库如果没有安装,那就先安装。(打开cmd,输入pip install requests)
2.下载的包括一个音频和一个视频,要自己用ffmpeg合并。
使用举例:
1)在包含文件“爱(原创MV).mp3”和“爱(原创MV).mp4”的文件夹上方输入cmd再确认
ps: 建议先把文件名改的简单一点,有些视频标题太长,不便于输入
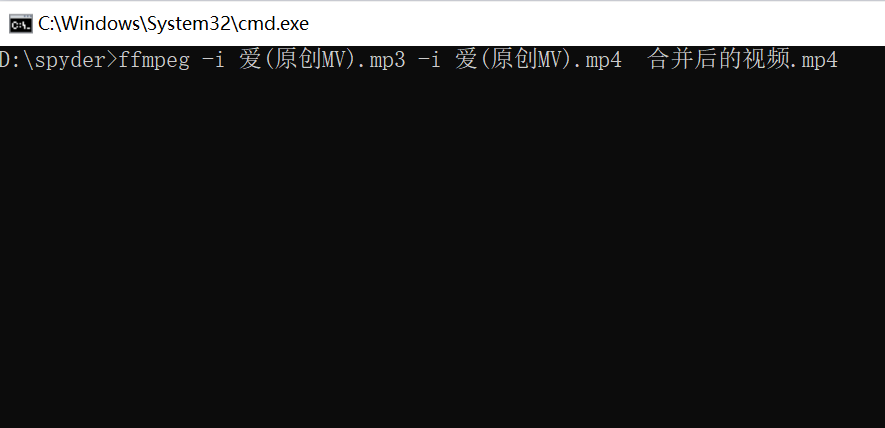
2)在cmd里按照这个格式输入: ffmpeg -i 音频文件名 -i 视频文件名 合并后的文件名
ps: ffmpeg安装好后记得加入环境变量。如果运行时仍然提示“ffmpeg不是系统内部或外部的命令”,重启一下电脑即可。
3)回到文件夹,你就可以看到合并完成的文件,这就是你要下载的B站视频。
最后,希望这篇博客能帮到你,欢迎和我交流。(邮箱2929837385@qq.com,博客不常看)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号