Kubernetes进阶实战读书笔记:资源需求及限制
一、资源需求及资源限制
1、详解官方手册
相比较来说,CPU属于可压缩性资源,即资源额度可按需收缩、而内存则是不可压缩型资源,对其执行收缩操作可能会导致某种程度的问题
[root@master chapter4]# kubectl explain pod.spec.containers.resources
KIND: Pod
VERSION: v1
RESOURCE: resources <Object>
DESCRIPTION:
Compute Resources required by this container. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
ResourceRequirements describes the compute resource requirements.
FIELDS:
limits <map[string]string>
#限制资源可用的最大值,即硬限制
Limits describes the maximum amount of compute resources allowed. More
info:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
requests <map[string]string> #属性定义其请求的确保可用值,即容器运行可能用不到这些额度的资源,使用到时必须确保有如此多的资源可用
Requests describes the minimum amount of compute resources required. If
Requests is omitted for a container, it defaults to Limits if that is
explicitly specified, otherwise to an implementation-defined value. More
info:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
它是指pod内所有容器上某种类型资源的请求和限制的总和
stree容器确保128Mi的内存及五分之一个CPU核心资源(200m)可用、它运行stress-ng镜像启动一个进程(-m 1)进行内存性能压力测试
满载则是时它也会尽可能多地占用CPU资源,另外再启动一个专用的CPU压力测试进程(-c 1)
2、资源清单
[root@master chapter4]# cat stress-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: stress-pod
spec:
containers:
- name: stress
image: ikubernetes/stress-ng
command: ["/usr/bin/stress-ng", "-c 1", "-m 1", "--metrics-brief"]
resources:
requests:
memory: "128Mi"
cpu: "200m"
limits:
memory: "512Mi"
cpu: "400m"
上面的配置清单中,其请求使用的cpu资源大小为200m、这意味着一个CPU核心足以确保其期望的最快方式运行。
另外、配置清单中期望使用的内存大小为128Mi,不过其运行时未必真的会用到这么多。考虑到内存为非压缩型资源,其超出指定的大小在运行时存在被OOMKilled杀死的可能性,于是请求值也应该就是其理想中使用的内存空间上线
3、创建运行
接下来创建并运行此POD 需要特别说明的是,当前使用的系统环境中,每个节点的可用CPU核心均为4,物理内存空间为16GB
[root@master chapter4]# kubectl create -f stress-pod.yaml pod/stress-pod created
4、效果验证
而后在pod资源容器内运行top命令观察其CPU及内存资源的占用状态
[root@master chapter4]# kubectl exec stress-pod -- top
Load average: 0.11 0.22 0.30 4/501 14
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
6 1 root R 6892 0% 3 5% {stress-ng-cpu} /usr/bin/stress-ng
8 7 root R 262m 1% 0 5% {stress-ng-vm} /usr/bin/stress-ng
1 0 root S 6244 0% 1 0% /usr/bin/stress-ng -c 1 -m 1 --met
7 1 root S 6244 0% 2 0% {stress-ng-vm} /usr/bin/stress-ng
9 0 root R 1504 0% 2 0% top
期中{stress-ng-vm}是执行内存压力测试的子进程,它默认使用256m的内存空间{stress-ng-cpu}是执行cpu压测的专用子进程
top命令的输出结果显示,每个测试进程的CPU占用率为5%(实际为12.5%){stress-ng-vm}的内存占用为:262m(VSZ),此两项资源占用量都远超其请求的用量
原因是stress-ng会在可用的范围内尽量多地占用相关的资源两个测试线程分布于两个CPU核心以满载的方式运行,系统共有4个核心因此使用率为50%
另外,节点上的内存资源充裕,虽然容器的内存用量远超128M,但他依然可运行。一旦资源紧张时,节点仅保证容器有五分之一个CPU核心可用,对于有着4个核心的节点来说,它的占用率为5%,
于是每个进程为2.5%,多占用的资源会被压缩,内存为非可压缩型资源,所以此POD在内存在资源紧张时可能会因OOM被杀死、
5、压缩性资源和非压缩性资源
对于CPU来说,未定义其请求用量以确保其最小的可用资源时,它可能会被其他的pod资源压缩至极低的水平甚至会达到pod不能被调度运行的境地。
而对于非压缩型资源来说,内存资源在任何原因导致的紧缺倾向下都有可能导致相关的集成被杀死、因此,在系统上运行关键型业务相关的pod时必须使用requests属性为容器定义资源的确保可用量
调度pod时,仅那些被请求资源的余量可容纳当前被调度的pod的请求量的节点才可作为目标节点、根据容器的requests属性中定义的资源需求量来判定那些节点可接收运行相关的pod资源,
而对于一个节点的资源来说,每运行一个pod对象,其requests中定义的请求量都要被预留,直到被所有的pod对象瓜分完完毕为止
二、资源限制
1、如何解决程序bug导致系统资源被长时间占用的问题?
对因应用程序自身存在的BUG等多种原因而导致的系统资源被长时间占用的情况则无计可施,这就需要通过limits属性为容器定义资源的最大可用量
资源分配时可压缩资源cpu的控制阀可自由调节,如果进程申请分配超过其limits属性定义的内存资源时,它将被OOM Killed杀死、不过、随后可能会被其控制进程所重启
2、资源清单
[root@master chapter4]# cat memleak-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: memleak-pod
spec:
containers:
- name: simmemleak
image: saadali/simmemleak
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "64Mi"
cpu: "1"
3、创建运行
创建资源清单:memleak-pod
[root@master chapter4]# kubectl apply -f memleak-pod.yaml pod/memleak-pod created
4、效果验证
pod资源的默认重启策略为always,于是在memleak因为内存资源达到硬限制而被终止后会立即重启、因此用户很难观察到其因OMM而被杀死的相关信息
不过,多次重复地因为内存资源耗尽而重启会触发Kubernetes系统的重启延迟机制,即每次重启的时间间隔会不断拉长。于是用户看到pod资源的相关状态通常为"CrashLoopBackOff"
[root@master chapter4]# kubectl get pods -l app=memleak NAME READY STATUS RESTARTS AGE memleak-pod 0/1 CrashLoopBackOff 5 5m35s
POD资源首次的重启将在crash后立即完成若随后再次crash,那么其重启操作会延迟10秒进行,随后的延迟时长会逐渐增加,依次为20秒、40秒、80秒、160秒和300秒,随后的延迟将固定在5分钟的时长之上而不再增加,直到其不再crash活着delete位置describe命令可以嫌弃其状态相关的信息、其部分内容如下所示:
[root@master chapter4]# kubectl describe pods memleak-pod
Name: memleak-pod
......
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Tue, 09 Jun 2020 17:20:31 +0800
Finished: Tue, 09 Jun 2020 17:20:31 +0800
Ready: False
Restart Count: 5
......
5、过载使用
如上述命令结果所显示的OOMKilled表示容器因内存耗尽而被终止、因此为limits属性中的memory设置一个合理值至关重要,与requests不同的是
limits并不会影响pod的调度结果,也可以说、一个节点上的所有pod的对象limits数量之和可以大于节点所有用的资源量、即支持过载使用
不过、这么一来一旦资源耗尽,尤其是内存资源耗尽,则必然会有容器因OOMKilled而终止
pod能够获得请求的cpu时间个度、它们能否获得额外的cpu时间、则取决于其他正在运行的作业对cpu资源占用的情情况
总数1000m的cpu资源:容器A请求使用200m、容器B请求使用500m 在不超出他们各自的最大限额的前提下,余下的300M在双方都需要时会以2:5(200M:500m)的方式进行配置
三、容器可见资源
容器中可见的资源量依然是节点几倍的可用总量,例如为前面定义的stress-pod添加如下limits属性定义
limits:
memory: "512Mi"
cpu: "400m"
1、资源清单
[root@master chapter4]# cat stress-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: stress-pod
spec:
containers:
- name: stress
image: ikubernetes/stress-ng
command: ["/usr/bin/stress-ng", "-c 1", "-m 1", "--metrics-brief"]
resources:
requests:
memory: "128Mi"
cpu: "200m"
limits:
memory: "512Mi"
cpu: "400m"
2、创建运行
重新创建stress-pod对象,并于其容器内分贝列出容器可见的内存和CPU资源总量、命令及结果如下所示
[root@master chapter4]# kubectl apply -f stress-pod.yaml pod/stress-pod configured
3、效果验证
[root@master chapter4]# kubectl exec stress-pod -- cat /proc/meminfo |grep ^MemTotal MemTotal: 18330380 kB [root@master chapter4]# kubectl exec stress-pod -- cat /proc/cpuinfo |grep ^processor processor : 0 processor : 1 processor : 2 processor : 3 [root@master chapter4]# kubectl exec stress-pod -- cat /proc/cpuinfo |grep -c ^processor 4
4、对容器应用的配置带来不小的负面影响
1、java应用程序
pod中运行java应用程序时,若为使用"-Xmx"选项指定JVM的堆内存可用总量、默认会设置为主机内存总量的一个空间比例(30%)、这会导致容器中的应用程序申请内存资源时将会达到上限而转为 OOMKilled;
另外即便使用"-Xmx"选项指定JVM的堆内存上限、但它对非堆内存的可用空间不会产生任何限制作用,结果仍然存在达到容器内存资源上限的可能性
2、nginx应用
pod中运行的nginx应用,在配置参数worker_processes的值为:"auto"时,主进程会创建于pod中能够访问到的CPU核心相同数量的worker进程
若pod的实际可用cpu核心远低于主机级别的数量时,那么这种该设置在较大的并发访问负荷下会导致严重的资源竞争,并将带来更多的内存消耗
一个较为妥当的解决方案是使用Downward API将limits定义的资源量暴露给容器、这一点在后面的章节中介绍
四、Pod的服务质量类别
1、如何解决过载问题
前面曾提到过、kubernetes允许节点资源对limits的过载使用,这意味着节点无法同时满足其上的所有pod对象以资源满载的方式运行
于是、在内存资源紧缺时、应该以何中次序先后终止那些Pod对象?kubernetes无法自行对此作出决策、它需要借助于pod对象的优先级完成判定根据POD对象的requests和limits属性
kubernetes将pod对象归类到BestFffort、Burstable和Guaranteed三个服务质量来别下具体说明如下
2、kubernetes服务质量的三个级别
Guaranteed:每个容器都为cpu资源设置了具有相同的requests和limits属性、以及每个人容器都为内存资源设置了具有相同值的requests和limits属性的pod资源会自动归属此类别、这类pod资源具有最高优先级
Burstable:至少有以个容器设置了cpu或内存资源的requests属性、但不满足Guaranteed类别要求的pod资源自动归属于此类别、他们具有中等优先级
BestFffort:未为任何一个容器设置requests和limits属性的pod资源将自动归属于此类别、他们的优先级别为最低级别
3、资源紧缺时pod终止优先级
1、内存资源紧缺时、BestFffort类别的容器将首当其冲地被终止、因为系统不为其提供任何级别的资源保证、但换来的好处是、他们能够在可用时做到尽可能多地占用资源。
2、若依然不存在任何类别的容器、则接下来是有着中等优先级的Burstable类别的pod被终止
3、Guaranteed类别的容器用油最高优先级、它们不会被杀死、除非其内存资源需要超限、或者OMM时没有其他更低优先级的pod资源存在
4、pod资源的OOM调节分值
每个运行状态容器都有其OOM得分、得分越高越会被优先杀死、OOM得分主要根据两个维度进行计算:由Qos类别继承而来的默认分值和容器的可用内存比例同等类别的pod资源的默认分值相同
下面的代码片段取自pkg/kubelt/qos/policy.go源码文件、他们定义的各种类别的pod资源的OOM调节分值
即默认分值、其中Guaranteed类别的pod资源的分值为-998、而BestFffort类别的pod资源的分值为-1000、Burstable类别的pod资源的分值则经由相应的计算得出:
const ( // KubeletOOMScoreAdj is the OOM score adjustment for Kubelet KubeletOOMScoreAdj int = -999 // KubeProxyOOMScoreAdj is the OOM score adjustment for kube-proxy KubeProxyOOMScoreAdj int = -999 guaranteedOOMScoreAdj int = -998 besteffortOOMScoreAdj int = 1000 )
5、 完整源码如下
/*
Copyright 2015 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package qos
import (
v1 "k8s.io/api/core/v1"
v1qos "k8s.io/kubernetes/pkg/apis/core/v1/helper/qos"
"k8s.io/kubernetes/pkg/kubelet/types"
)
const (
// KubeletOOMScoreAdj is the OOM score adjustment for Kubelet
KubeletOOMScoreAdj int = -999
// KubeProxyOOMScoreAdj is the OOM score adjustment for kube-proxy
KubeProxyOOMScoreAdj int = -999
guaranteedOOMScoreAdj int = -998
besteffortOOMScoreAdj int = 1000
)
// GetContainerOOMScoreAdjust returns the amount by which the OOM score of all processes in the
// container should be adjusted.
// The OOM score of a process is the percentage of memory it consumes
// multiplied by 10 (barring exceptional cases) + a configurable quantity which is between -1000
// and 1000. Containers with higher OOM scores are killed if the system runs out of memory.
// See https://lwn.net/Articles/391222/ for more information.
func GetContainerOOMScoreAdjust(pod *v1.Pod, container *v1.Container, memoryCapacity int64) int {
if types.IsCriticalPod(pod) {
// Critical pods should be the last to get killed.
return guaranteedOOMScoreAdj
}
switch v1qos.GetPodQOS(pod) {
case v1.PodQOSGuaranteed:
// Guaranteed containers should be the last to get killed.
return guaranteedOOMScoreAdj
case v1.PodQOSBestEffort:
return besteffortOOMScoreAdj
}
// Burstable containers are a middle tier, between Guaranteed and Best-Effort. Ideally,
// we want to protect Burstable containers that consume less memory than requested.
// The formula below is a heuristic. A container requesting for 10% of a system's
// memory will have an OOM score adjust of 900. If a process in container Y
// uses over 10% of memory, its OOM score will be 1000. The idea is that containers
// which use more than their request will have an OOM score of 1000 and will be prime
// targets for OOM kills.
// Note that this is a heuristic, it won't work if a container has many small processes.
memoryRequest := container.Resources.Requests.Memory().Value()
oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity
// A guaranteed pod using 100% of memory can have an OOM score of 10. Ensure
// that burstable pods have a higher OOM score adjustment.
if int(oomScoreAdjust) < (1000 + guaranteedOOMScoreAdj) {
return (1000 + guaranteedOOMScoreAdj)
}
// Give burstable pods a higher chance of survival over besteffort pods.
if int(oomScoreAdjust) == besteffortOOMScoreAdj {
return int(oomScoreAdjust - 1)
}
return int(oomScoreAdjust)
}
因此、同等级别优先级的Pod资源在OMM时、与自身的requests属性相比、其内存占用比例最大的Pod对象被首先杀死、例如图
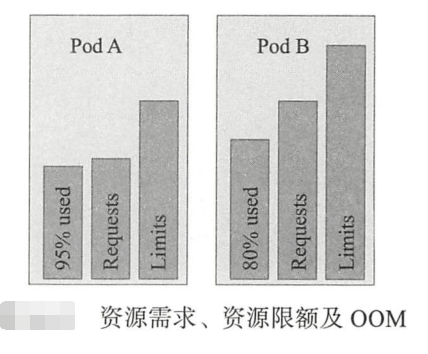
中的同属于类别的pod A 将优先于pod B被杀死、虽然其内存量小、但与自身的requests值相比、它的占用比例95%要大于Pod B的80%
需要特别说明的是:OMM是内存耗尽时的处理机制、它们与可压缩型资源CPU无关、因此CPU资源的需求无法得到保证时、Pod仅仅是暂时获取不到相应的资源而已
五、小结
- Pod就是联系紧密的一组容器,它们共享network、UTS和IPC名称空间及存储卷资源
- 分布式系统设计主要有sidecar、Ambassahor和adapter三种主要模式
- Kubernetes资源对象的管理操作基本上是由增、删、改和查等操作组成的,并且支持陈述式命令、陈述式对象配置和声明式对象配置三种管理方式
- Pod的核心目标在于运行容器,容器的定制配置常见的包括暴露端口及传递环境变量等
- 标签是附加在Kubernetes系统上的键值类型的元数据,而标签选择器是基本等值或集合关系的标签过滤机制;注解类似于标签,但不能被用于标签选择器
- Pod的生命周期中可能存在多种类型的操作,但运行主容器是其核心任务
- 存活性探测及就绪性探测是辅助判断容器状态的重要工具
- 资源需求及资源限制是管理POD对象系统资源分配的有效方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号