
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
实例描述 通常情况下,倒排索引由一个单词(或词组)以及相关的文档列表组成,文档列表中的文档或者是标识文档的ID号,或者是指文档所在位置的URL 在实际应用中,还需要给每个文档添加一个权值,用来指出每个文档与搜索内容的相关度:
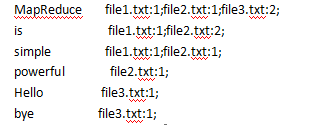
样例输入:1)file1: MapReduce is simple
2)file2: MapReduce is powerful is simple
3)file3: Hello MapReduce bye MapReduce
样例输出:
思路:
Map过程: key:word+url value:字频(设置为1)
Combine阶段:key:word value:url+字频(所有map阶段相同的key对应的value(1)相加)
Reduce阶段:key:word value:将combine阶段的url+字频合并起来。
代码:
package mapreduce01;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class daopai {
static String INPUT_PATH = "hdfs://master:9000/qp";
static String OUTPUT_PATH="hdfs://master:9000/output";
static class MyMapper extends Mapper<Object,Object,Text,Text> {
Text output_key=new Text();
Text output_value=new Text();
FileSplit split;
protected void map(Object key,Object value,Context context)throws IOException, InterruptedException{
//获得<key,value>对所属的FileSplit对象。
split = (FileSplit)context.getInputSplit();
System.out.println(split);
//StringTokenizer是用来把字符串截取成一个个标记或单词的,默认是空格或多个空格(\t\n\r等等)截取
StringTokenizer itr = new StringTokenizer( value.toString());
while(itr.hasMoreTokens()){
// key值由单词和URI组成。
output_key.set(itr.nextToken()+":"+split.getPath().toString());
output_value.set("1");
context.write(output_key, output_value);
}
}
}
public static class MyCombiner extends Reducer<Text,Text,Text,Text> {
Text output_value= new Text();
Text output_key = new Text();
protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context) throws java.io.IOException, InterruptedException {
//统计词频
int sum=0;
for(Text value:values){
sum += Integer.parseInt(value.toString() ); //parseInt解析字符串
}
System.out.println(sum);
int splitIndex = key.toString().indexOf(":");//找:的位置
//重新设置value值由URI和词频组成
output_value.set( key.toString().substring( splitIndex + 1) +":"+sum );
//重新设置key值为单词
output_key.set( key.toString().substring(0,splitIndex));
context.write(output_key,output_value);
}
}
public static class MyReduce extends Reducer<Text,Text,Text,Text>{
Text output_value = new Text();
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context)
throws IOException, InterruptedException {
//生成文档列表
String fileList = new String();
for (Text value : values) {
fileList += value.toString()+";";
}
output_value.set(fileList);
context.write(key, output_value);
}
}
public static void main(String[] args) throws Exception{
Path outputpath=new Path(OUTPUT_PATH);
Configuration conf=new Configuration();
FileSystem fs = outputpath.getFileSystem(conf);
if(fs.exists(outputpath)){
fs.delete(outputpath,true);
}
//wordCount
Job job = Job.getInstance(conf);
FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outputpath);
job.setMapperClass(MyMapper.class); //map
job.setCombinerClass( MyCombiner.class);
job.setReducerClass(MyReduce.class); //reduce
// job.setMapOutputKeyClass(LongWritable.class);
// job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.waitForCompletion(true);
}
}
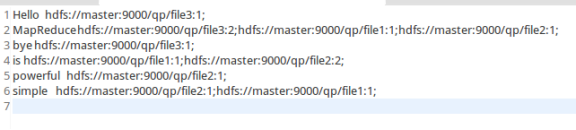
输出结果:
Never Give up;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号