
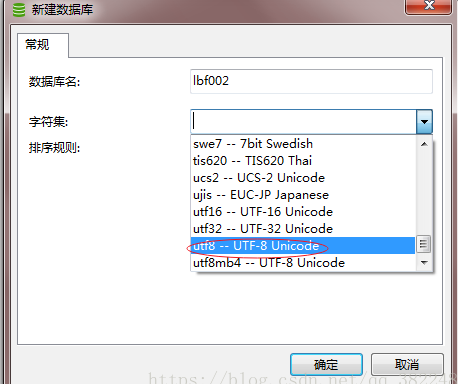
mysql建数据库的字符集与排序规则
详见:https://www.cnblogs.com/LMIx/p/10791742.html
1.字符集说明:
1. 【0020-007F】 Basic Latin 基本拉丁字母
2. 【00A0-00FF】 Latin-1 Supplement 拉丁字母补充-1
3. 【0100-017F】 Latin Extended-A 拉丁字母扩充-A
4. 【0180-023F】 Latin Extended-B 拉丁字母扩充-B
5. 【0250-02AF】 IPA Extensions 国际音标扩充
6. 【02B0-02EF】 Spacing Modifier Letters 进格修饰字符
7. 【0300-036F】 Combining Diacritical Marks 组合音标附加符号
8. 【0370-03FF】 Greek and Coptic 希腊字母
9. 【0400-04FF】 Cyrillic 西里尔字母
10. 【0500-052F】 Cyrillic Supplement 西里尔字母补充
11. 【0530-058F】 Armenian 亚美尼亚文
12. 【0590-05FF】 Hebrew 希伯来文
13. 【0600-06FF】 Arabic 基本阿拉伯文
14. 【0700-074F】 Syriac 叙利亚文
15. 【0750-077F】 Arabic Supplement 阿拉伯文补充
16. 【0780-07BF】 Thaana 塔纳文
17. 【07C0-07FF】 N'Ko
18. 【0900-097F】 Devanagari 天城体梵文字母
19. 【0980-09FF】 Bengali 孟加拉国文
20. 【0A00-0A7F】 Gurmukhi 古尔穆基文
21. 【0A80-0AFF】 Gujarati 古吉拉特文
22. 【0B00-0B7F】 Oriya 奥里亚文
23. 【0B80-0BFF】 Tamil 泰米尔文
24. 【0C00-0C7F】 Telugu 泰卢固文
25. 【0C80-0CFF】 Kannada 卡纳达文
26. 【0D00-0D7F】 Malayalam 马拉亚拉姆文
27. 【0D80-0DFF】 Sinhala 僧伽罗文
28. 【0E00-0E7F】 Thai 泰文
29. 【0E80-0EFF】 Lao 老挝文;寮国文
30. 【0F00-0FFF】 Tibetan 藏文
31. 【1000-109F】 Myanmar 缅甸文
32. 【10A0-10FF】 Georgian 格鲁吉亚文
33. 【1100-11FF】 Hangul Jamo 谚文字母
34. 【1200-137F】 Ethiopic 埃塞俄比亚文
35. 【1380-139F】 Ethiopic Supplement 埃塞俄比亚文补充
36. 【13A0-13FF】 Cherokee 切罗基文
37. 【1400-167F】 Unified Canadian Aboriginal Syllabics 加拿大土著统一音节文字
38. 【1680-169F】 Ogham 欧甘文
39. 【16A0-16FF】 Runic 北欧古文
40. 【1700-171F】 Tagalog 他加禄文
41. 【1720-173F】 Hanunoo 哈努诺文
42. 【1740-175F】 Buhid 布什德文
43. 【1760-177F】 Tagbanwa 塔格巴努亚文
44. 【1780-17FF】 Khmer 高棉文
45. 【1800-18AF】 Mongolian 蒙古文
46. 【1900-194F】 Limbu 林布文
47. 【1950-197F】 Tai Le 傣哪文;德宏傣文
48. 【1980-19DF】 New Tai Lue 新傣仂文
49. 【19E0-19FF】 Khmer Symbols 高棉符号
50. 【1A00-1A1F】 Buginese 布吉文
51. 【1B00-1B7F】 Balinese 巴利文
52. 【1D00-1D7F】 Phonetic Extensions 音标扩充
53. 【1D80-1DBF】 Phonetic Extensions Supplement 音标扩充补充
54. 【1DC0-1DFF】 Combining Diacritical Marks Supplement 组合音标附加符号
55. 【1E00-1EFF】 Latin Extended Additional 拉丁字母扩充附加
56. 【1F00-1FFF】 Greek Extended 希腊文扩充
57. 【2000-206F】 General Punctuation 一般标点符号
58. 【2070-209F】 Superscripts and Subscripts 下标及上标
59. 【20A0-20CF】 Currency Symbols 货币符号
60. 【20D0-20FF】 Combining Diacritical Marks for Symbols 符号用组合附加符号
61. 【2100-214F】 Letterlike Symbols 似字母符号
62. 【2150-218F】 Number Forms 数字形式
63. 【2190-21FF】 Arrows 箭头符号
64. 【2200-22FF】 Mathematical Operators 数学运算符号
65. 【2300-23FF】 Miscellaneous Technical 混合专门符号
66. 【2400-243F】 Control Pictures 控制图像
67. 【2440-245F】 Optical Character Recognition 光学字符识别
68. 【2460-24FF】 Enclosed Alphanumerics 括号字母数字
69. 【2500-257F】 Box Drawing 制表符
70. 【2580-259F】 Block Elements 区块组件
71. 【25A0-25FF】 Geometric Shapes 几何形状
72. 【2600-26FF】 Miscellaneous Symbols 混合什锦符号
73. 【2700-27BF】 Dingbats 什锦符号
74. 【27C0-27EF】 Miscellaneous Mathematical Symbols-A 混合数学符号-A
75. 【27F0-27FF】 Supplemental Arrows-A 补充性箭头符号-A
76. 【2800-28FF】 Braille Patterns 盲文;盲人点字
77. 【2900-297F】 Supplemental Arrows-B 补充性箭头符号-B
78. 【2980-29FF】 Miscellaneous Mathematical Symbols-B 混合数学符号-B
79. 【2A00-2AFF】 Supplemental Mathematical Operators 补充性数学运算符号
80. 【2B00-2BFF】 Miscellaneous Symbols and Arrows 混合什锦符号和箭头符号
81. 【2C00-2C5F】 Glagolitic 格拉戈尔字母
82. 【2C60-2C7F】 Latin Extended-C 拉丁字母扩充-C
83. 【2C80-2CFF】 Coptic 科普特文
84. 【2D00-2D2F】 Georgian Supplement 格鲁吉亚文补充
85. 【2D30-2D7F】 Tifinagh 提非纳格字母
86. 【2D80-2DDF】 Ethiopic Extended 埃塞俄比亚文扩充
87. 【2E00-2E7F】 Supplemental Punctuation 补充性标点符号
88. 【2E80-2EFF】 CJK Radicals Supplement 中日韩部首补充
89. 【2F00-2FDF】 Kangxi Radicals 康熙部首
90. 【2FF0-2FFF】 Ideographic Description Characters 汉字结构描述字符
91. 【3000-303F】 CJK Symbols and Punctuation 中日韩符号和标点
92. 【3040-309F】 Hiragana 平假名
93. 【30A0-30FF】 Katakana 片假名
94. 【3100-312F】 Bopomofo 注音符号
95. 【3130-318F】 Hangul Compatibility Jamo 谚文兼容字母
96. 【3190-319F】 Kanbun 汉文标注号
97. 【31A0-31BF】 Bopomofo Extended 注音符号扩充
98. 【31C0-31EF】 CJK Strokes 中日韩笔画部件
99. 【31F0-31FF】 Katakana Phonetic Extensions 片假名音标扩充
100.【3200-32FF】 Enclosed CJK Letters and Months 中日韩括号字母及月份
101.【3300-33FF】 CJK Compatibility 中日韩兼容字符
102.【3400-4DBF】 CJK Unified Ideographs Extension A 中日韩统一表意文字扩充A
103.【4DC0-4DFF】 Yijing Hexagram Symbols 易经六十四卦象
104.【4E00-9FFF】 CJK Unified Ideographs 中日韩统一表意文字
105.【A000-A48F】 Yi Syllables 彝文音节
106.【A490-A4CF】 Yi Radicals 彝文字母
107.【A700-A71F】 Modifier Tone Letters 声调符号
108.【A720-A7FF】 Latin Extended-D 拉丁字母扩充-D
109.【A800-A82F】 Syloti Nagri
110.【A840-A87F】 Phags-pa 八思巴字母
111.【AC00-D7AF】 Hangul Syllables 谚文音节
112.【D800-DB7F】 High Surrogates 高半代用区
113.【DB80-DBFF】 High Private Use Surrogates 高半专用代用区
114.【DC00-DFFF】 Low Surrogates 低半代用区
115.【E000-F8FF】 Private Use Area 专用区
116.【F900-FAFF】 CJK Compatibility Ideographs 中日韩兼容表意文字
117.【FB00-FB4F】 Alphabetic Presentation Forms 字母变体显现形式
118.【FB50-FDFF】 Arabic Presentation Forms-A 阿拉伯文变体显现形式-A
119.【FE00-FE0F】 Variation Selectors 字型变换选取器
120.【FE10-FE1F】 Vertical Forms 竖式标点
121.【FE20-FE2F】 Combining HalF】 Marks 组合半角标示
122.【FE30-FE4F】 CJK Compatibility Forms 中日韩相容形式
123.【FE50-FE6F】 Small Form Variants 小写变体
124.【FE70-FEFF】 Arabic Presentation Forms-B 阿拉伯文变体显现形式-B
125.【FF00-FFEF】 Halfwidth and Fullwidth Forms 半角及全角字符
126.【FFF0-FFFF】 Specials 特殊区域
127.【10000-1007F】 Linear B Syllabary 线形文字B音节文字
128.【10080-100FF】 Linear B Ideograms 线形文字B表意文字
129.【10100-1013F】 Aegean Numbers 爱琴数字
130.【10140-1018F】 Ancient Greek Numbers 古希腊数字
131.【10300-1032F】 Old Italic 古意大利文
132.【10330-1034F】 Gothic 哥特文
133.【10380-1039F】 Ugaritic 乌加里特楔形文字
134.【103A0-103DF】 Old Persian 古波斯文
135.【10400-1044F】 Deseret 犹他大学音标
136.【10450-1047F】 Shavian 肃伯纳字母
137.【10480-104AF】 Osmanya
138.【10800-1083F】 Cypriot Syllabary 塞浦路斯音节文字
139.【10900-1091F】 Phoenician 腓尼基字母
140.【10A00-10A5F】 Kharoshthi 佉卢字母
141.【12000-123FF】 Cuneiform 楔形文字
142.【12400-1247F】 Cuneiform Numbers and Punctuation 楔形文字数字及标点
143.【1D000-1D0FF】 Byzantine Musical Symbols 东正教音乐符号
144.【1D100-1D1FF】 Musical Symbols 音乐符号
145.【1D200-1D24F】 Ancient Greek Musical Notation 古希腊音乐谱记号
146.【1D300-1D35F】 Tai Xuan Jing Symbols 太玄经符号
147.【1D360-1D37F】 Counting Rod Numerals 算筹记数式
148.【1D400-1D7FF】 Mathematical Alphanumeric Symbols 数学用字母数字符号
149.【20000-2A6DF】 CJK Unified Ideographs Extension B 中日韩统一表意文字扩充B
150.【2F800-2FA1F】 CJK Compatibility Ideographs Supplement 中日韩兼容表意文字补充
151.【E0000-E007F】 Tags 语言编码卷标
152.【E0100-E01EF】 Variation Selectors Supplement 字型变换选取器补充
153.【FFF80-FFFFF】 Supplementary Private Use Area-A 补充专用区-A
154.【10FF80-10FFFF】 Supplementary Private Use Area-B 补充专用区-B
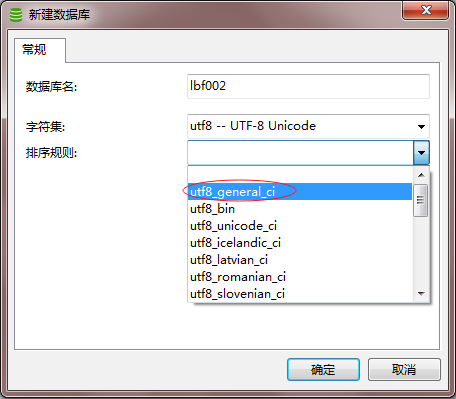
2.排序说明
一、官方文档说明
下面摘录一下Mysql
5.1中文手册中关于utf8_unicode_ci与utf8_general_ci的说明:
当前,utf8_unicode_ci校对规则仅部分支持Unicode校对规则算法。一些字符还是不能支持。并且,不能完全支持组合的记号。这主要影响越南和俄罗斯的一些少数民族语言,如:Udmurt 、Tatar、Bashkir和Mari。
utf8_unicode_ci的最主要的特色是支持扩展,即当把一个字母看作与其它字母组合相等时。例如,在德语和一些其它语言中‘ß'等于‘ss'。
utf8_general_ci是一个遗留的 校对规则,不支持扩展。它仅能够在字符之间进行逐个比较。这意味着utf8_general_ci校对规则进行的比较速度很快,但是与使用utf8_unicode_ci的 校对规则相比,比较正确性较差)。
例如,使用utf8_general_ci和utf8_unicode_ci两种 校对规则下面的比较相等:
Ä = A
Ö = O
Ü = U
两种校对规则之间的区别是,对于utf8_general_ci下面的等式成立:
ß = s
但是,对于utf8_unicode_ci下面等式成立:
ß = ss
对于一种语言仅当使用utf8_unicode_ci排序做的不好时,才执行与具体语言相关的utf8字符集 校对规则。例如,对于德语和法语,utf8_unicode_ci工作的很好,因此不再需要为这两种语言创建特殊的utf8校对规则。
utf8_general_ci也适用与德语和法语,除了‘ß'等于‘s',而不是‘ss'之外。如果你的应用能够接受这些,那么应该使用utf8_general_ci,因为它速度快。否则,使用utf8_unicode_ci,因为它比较准确。
如果你想使用gb2312编码,那么建议你使用latin1作为数据表的默认字符集,这样就能直接用中文在命令行工具中插入数据,并且可以直接显示出来.而不要使用gb2312或者gbk等字符集,如果担心查询排序等问题,可以使用binary属性约束,例如:
create table my_table ( name varchar(20) binary not null default '')type=myisam default charset latin1;
二、简短总结
utf8_unicode_ci和utf8_general_ci对中、英文来说没有实质的差别。
utf8_general_ci校对速度快,但准确度稍差。
utf8_unicode_ci准确度高,但校对速度稍慢。
如果你的应用有德语、法语或者俄语,请一定使用utf8_unicode_ci。一般用utf8_general_ci就够了,到现在也没发现问题。。。
三、详细总结
1、对于一种语言仅当使用utf8_unicode_ci排序做的不好时,才执行与具体语言相关的utf8字符集校对规则。例如,对于德语和法语,utf8_unicode_ci工作的很好,因此不再需要为这两种语言创建特殊的utf8校对规则。
2、utf8_general_ci也适用与德语和法语,除了‘?'等于‘s',而不是‘ss'之外。如果你的应用能够接受这些,那么应该使用
utf8_general_ci,因为它速度快。否则,使用utf8_unicode_ci,因为它比较准确。
用一句话概况上面这段话:utf8_unicode_ci比较准确,utf8_general_ci速度比较快。通常情况下 utf8_general_ci的准确性就够我们用的了,在我看过很多程序源码后,发现它们大多数也用的是utf8_general_ci,所以新建数据 库时一般选用utf8_general_ci就可以了
四、如何在MySQL5.0中使用UTF8
在 my.cnf中增加下列参数
[mysqld]
init_connect='SET NAMES utf8′
default-character-set=utf8
default-collation = utf8_general_ci
执行查询 mysql>show variables where Variable_name like '%set%'; 相关如下:
character_set_client | utf8
character_set_connection | utf8
character_set_database | utf8
character_set_results | utf8
character_set_server | utf8
character_set_system | utf8
collation_connection | utf8_general_ci
collation_database | utf8_general_ci
collation_server | utf8_general_ci
个人见解,对于数据库的使用,utf8 - general 已经足够的准确,并且相较与 utf8 - unicode速度上有优势,固可放心采用之
附1:旧数据升级办法
以原来的字符集为latin1为例,升级成为utf8的字符集。原来的表: old_table (default
charset=latin1),新表:new_table(default charset=utf8)。
第一步:导出旧数据
mysqldump --default-character-set=latin1 -hlocalhost -uroot -B my_db --tables old_table > old.sql
第二步:转换编码(类似unix/linux环境下)
iconv -t utf-8 -f gb2312 -c old.sql > new.sql
或者可以去掉 -f 参数,让iconv自动判断原来的字符集
iconv -t utf-8 -c old.sql > new.sql
在这里,假定原来的数据默认是gb2312编码。
第三步:导入
修改old.sql,在插入/更新语句开始之前,增加一条sql语句: "SET
NAMES utf8;",保存
mysql -hlocalhost -uroot my_db < new.sql
大功告成!!
附2:支持查看utf8字符集的MySQL客户端有
1.) MySQL-Front,据说这个项目已经被MySQL
AB勒令停止了,不知为何,如果国内还有不少破解版可以下载(不代表我推荐使用破解版 :-P)。
2.)
Navicat,另一款非常不错的MySQL客户端,汉化版刚出来,还邀请我试用过,总的来说还是不错的,不过也需要付费。
3.)
PhpMyAdmin,开源的php项目,非常好。
4.) Linux下的终端工具(Linux
terminal),把终端的字符集设置为utf8,连接到MySQL之后,执行 SET NAMES UTF8; 也能读写utf8数据了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号