华为信息通信技术-HCIP
华为信息通信技术-HCIP
一、策略路由与路由策略的区别
| 路由策略 | |
|---|---|
| 基于控制平面,会影响路由表表项。 | 基于转发平面,不会影响路由表表项,且设备收到报文后,会先查找策略路由进行匹配转发,若匹配失败,则在查找路由表进行转发。 |
| 只能基于目的地址进行策略制定。 | 可以基于源地址、目的地址、协议类型、报文大小等进行策略制定。 |
| 与路由协议结合使用。 | 需要手工逐跳配置,以保证报文按策略进行转发。 |
| 常用工具:Route-Policy、Filter-Policy等 | 常用工具:Traffic-Filter、Traffic-Policy、Policy-Based-Route等 |
top
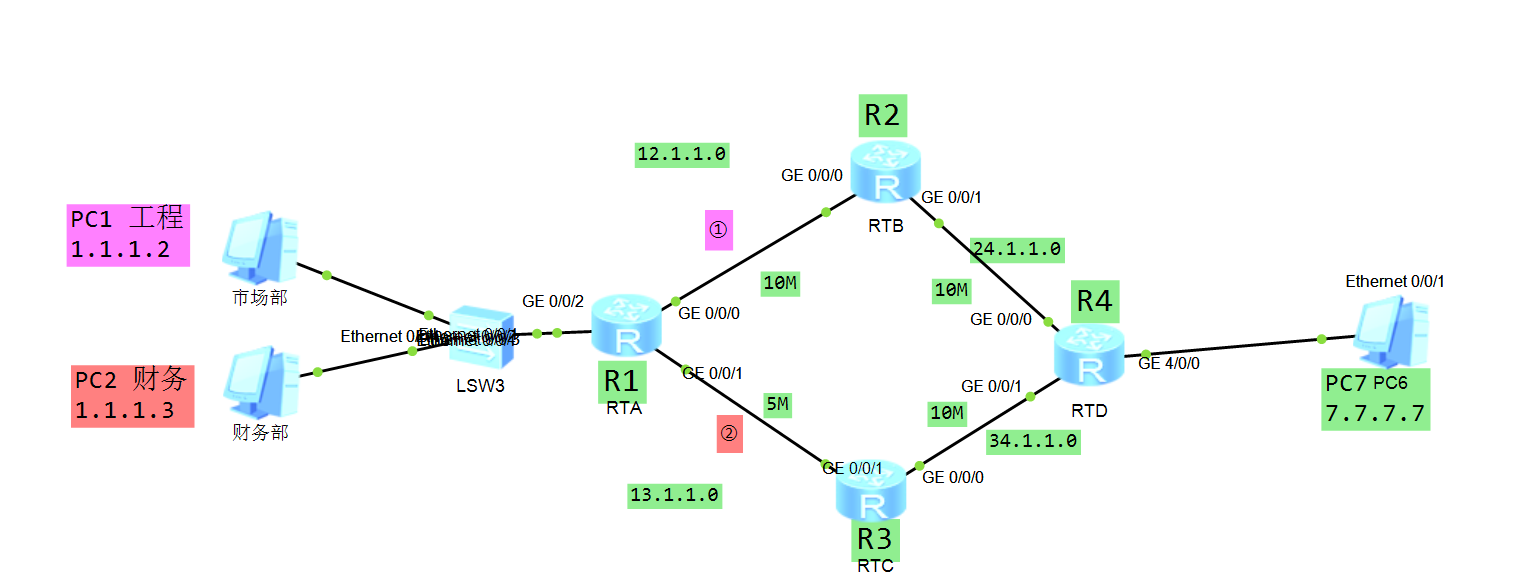
配置路由全网互通:
R1:
system-view
undo info-center enable
sysname R1
interface g0/0/2
ip address 1.1.1.1 24
interface g0/0/0
ip address 12.1.1.1 24
interface g0/0/1
ip address 13.1.1.1 24
q
ospf 1 router-id 1.1.1.1
area 0
network 1.1.1.1 0.0.0.0
network 12.1.1.1 0.0.0.0
network 13.1.1.1 0.0.0.0
R2:
system-view
undo info-center enable
sysname R2
interface g0/0/0
ip address 12.1.1.2 24
interface g0/0/1
ip address 24.1.1.2 24
q
ospf 1 router-id 2.2.2.2
area 0
network 12.1.1.2 0.0.0.0
network 24.1.1.2 0.0.0.0
R3:
system-view
undo info-center enable
sysname R3
interface g0/0/0
ip address 34.1.1.3 24
interface g0/0/1
ip address 13.1.1.3 24
q
ospf 1 router-id 3.3.3.3
area 0
network 34.1.1.3 0.0.0.0
network 13.1.1.3 0.0.0.0
R3:
system-view
undo info-center enable
sysname R4
interface g0/0/0
ip address 24.1.1.4 24
interface g0/0/1
ip address 34.1.1.4 24
interface g4/0/0
ip address 7.7.7.1 24
q
ospf 1 router-id 4.4.4.4
area 0
network 24.1.1.4 0.0.0.0
network 34.1.1.4 0.0.0.0
network 7.7.7.1 0.0.0.0
1.1 路由策略
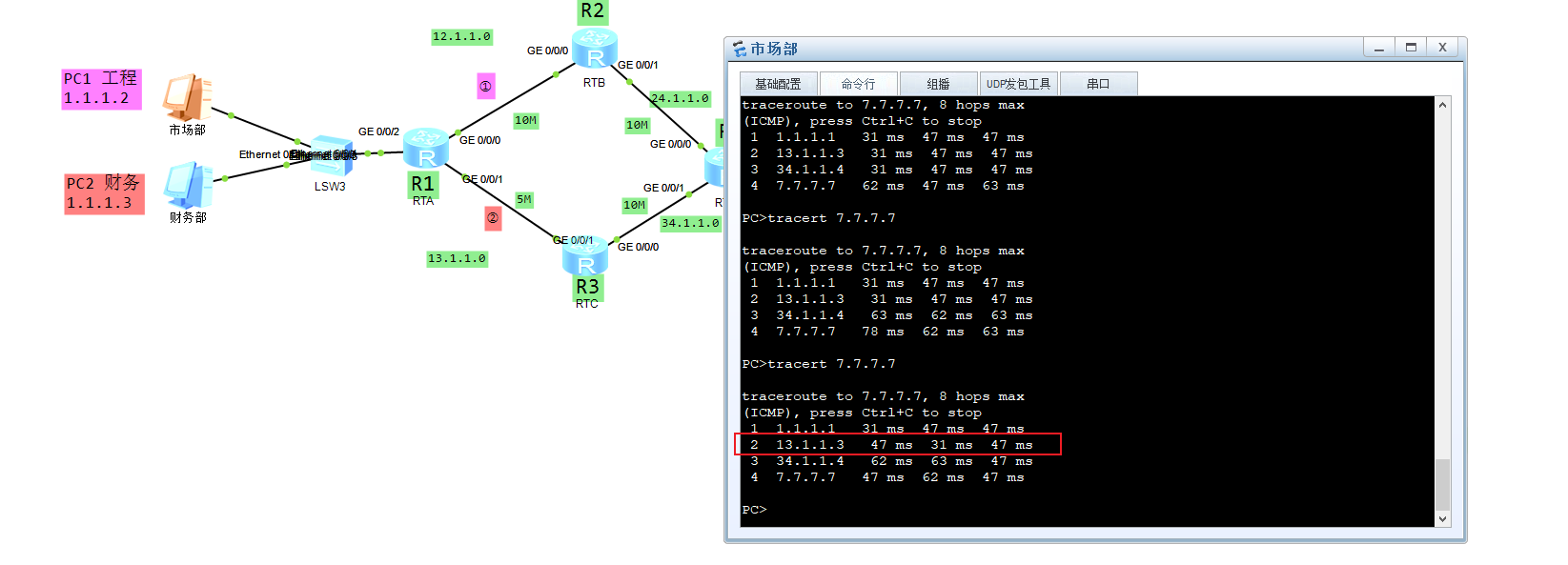
此时查看左边的1.1.1.0网段的主机去到7.7.7.0网段的路由有两条,一种是走R2,另一种是走R3,这里现在它默认走R3:
1.1.1 修改路由开销控制流量
现在如果想要控制它走R2的话,可以把走R1GE0/0/1的开销改大,当然也可以改R3的GE0/0/0,为了保证回来走的同一路线,建议把回来的出接口也该一下:
R1:
interface g0/0/1
ospf cost 2
R3:
interface g0/0/1
ospf cost 2
此时再看他就会从R2过去:

1.1.2 使用Filter-Policy
假设现在有需求说控制R1左侧的所有设备不允许访问R4右侧的所有设备,那怎么实现呢?这时候就可以使用Filter-Policy,配置Filter-Policy之后让R1上去7.7.7.0网段的路由消失,现在看R1上还有去往7.7.7.0网段的路由:
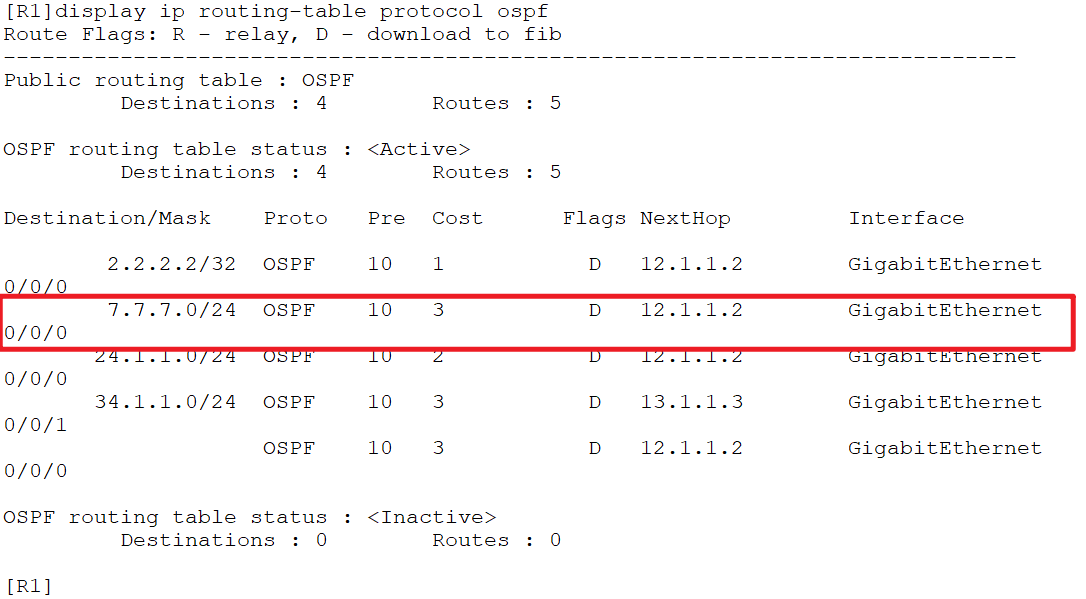
在R1上配置Filter-Policy,原理就是先创建一个ACL之后进入ospf进程里导入它,可以实现路由过滤的功能,这里过滤掉7.7.7.0网段:
acl 2000
rule deny source 7.7.7.0 0.0.0.255
rule permit
q
ospf 1
filter-policy 2000 import
之后再查看对应路由就会消失,对应设备也无法访问:
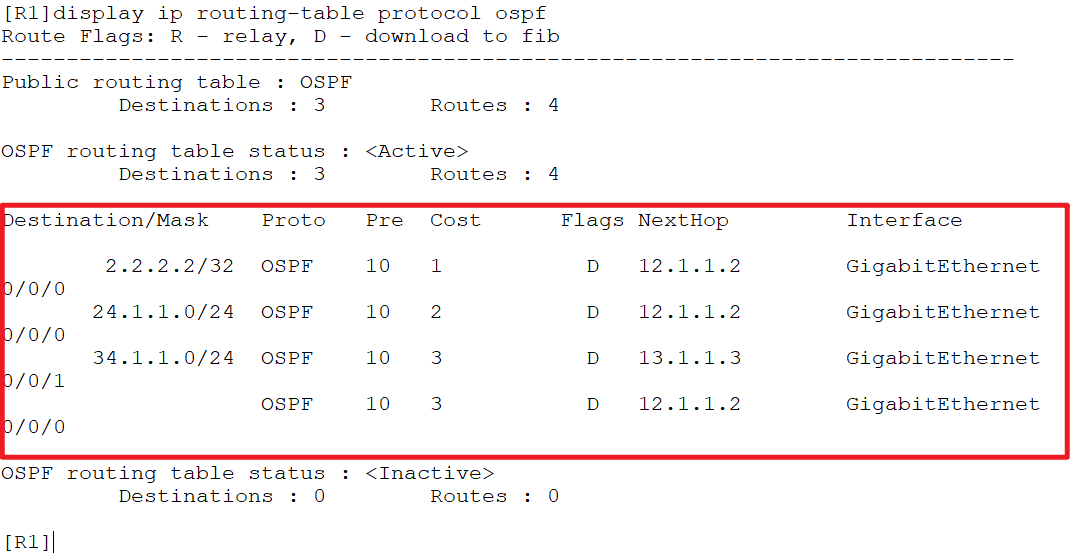
1.2 策略路由
1.2.1 本地方式
只能对由本机主动触发的流量生效。对流经本机的(转发流量)无效,一般很少用。
当前可以看到R1去往7.7.7.7主机的链路是走R2,可以配置本地策略路由让他走下面的R3:
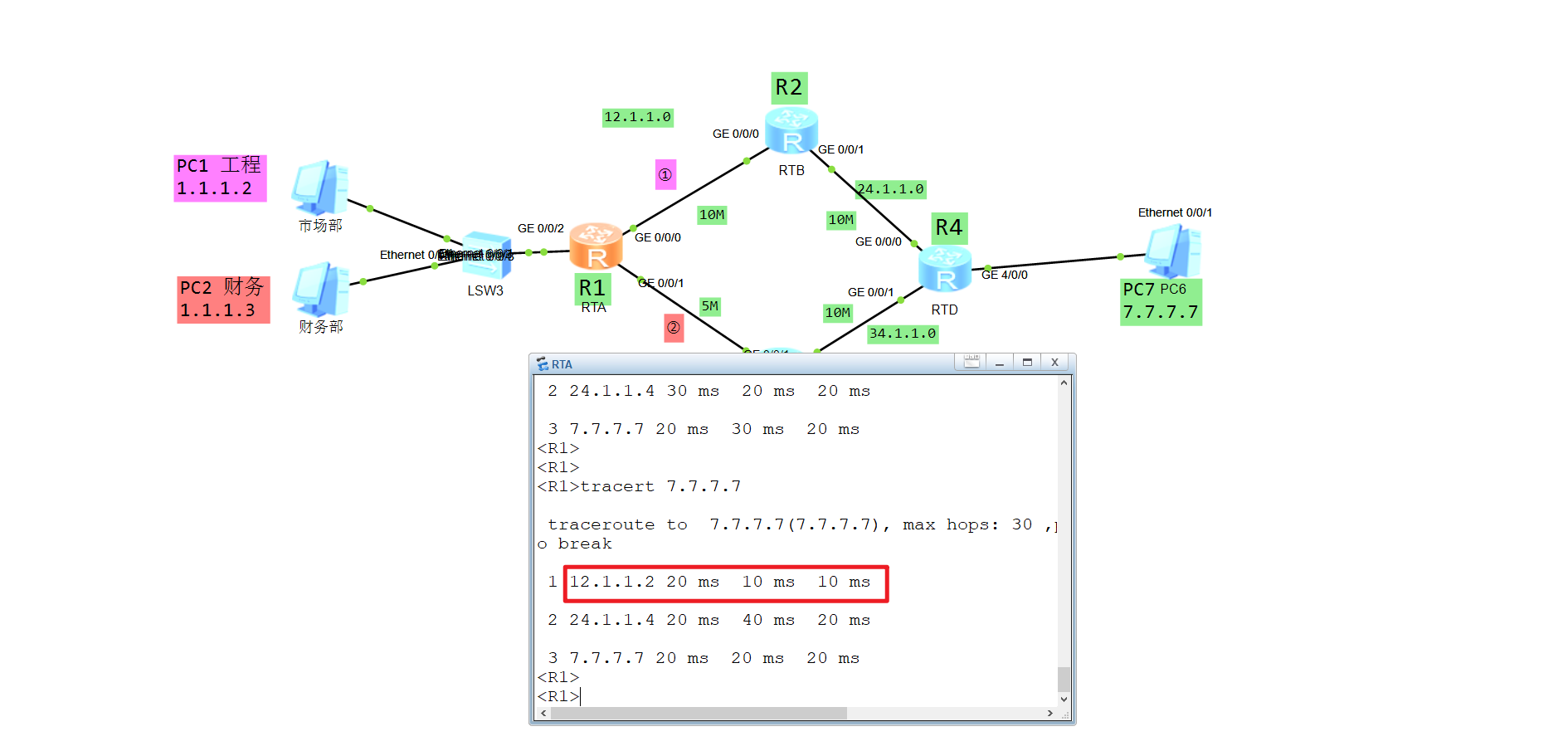
R1:
# 制定报文匹配的ACL
[R1] acl 3000
[R1-acl-adv-3000] rule permit ip destination 7.7.7.7 0
# 创建policy-based-route,策略名为aa, 10和acl中的规则序号差不多,如果报文匹配了ACL3000,将强制它的下一跳为13.1.1.3
[R1] policy-based-route aa permit node 10
[R1-policy-based-route-aa-10] if-match acl 3000
[R1-policy-based-route-aa-10] apply ip-address next-hop 13.1.1.3
#本地调用
[R1] ip local policy-based-route aa
此时R1访问7.7.7.7的流量就路径就会改变
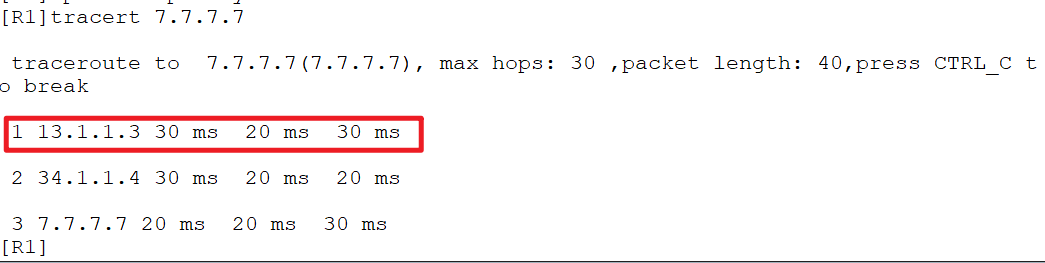
需要注意的是它不会影响其它的流量,他只是改变了自身的流量,比如1.1.1.2现在访问7.7.7.7和之前走的链路并没有什么改变。
1.2.2 基于接口
把之前的配置拿掉:
[R1] undo ip local policy-based-route aa
[R1] undo acl 3000
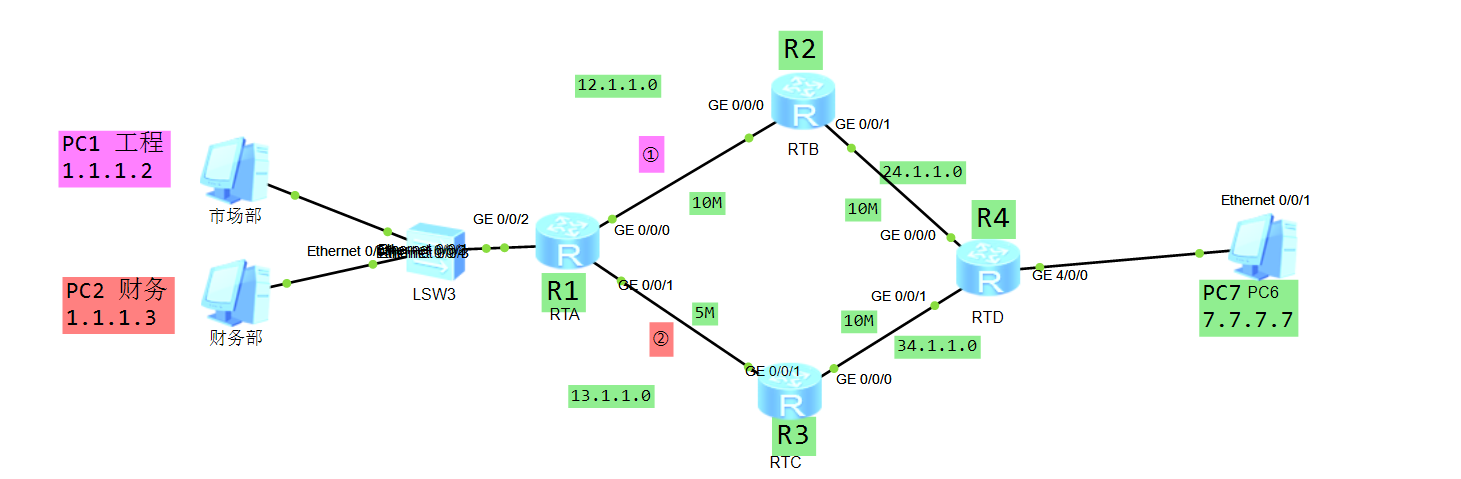
假设现在有需求说PC1工程部访问7.7.7.7要从R2过,而PC2财务部访问7.7.7.7需要从R3过,可以做如下配置:
R1:
- 流量分类(通过ACL实现)
# 创建一个名为gongcheng的流量分类并调用ALC 2006来分类
[R1] traffic classifier gongcheng
[R1-classifier-gongcheng] if-match acl 2006
# 再创建一个名为caiwu的流量分类并调用ALC 2006来分类
[R1] traffic classifier caiwu
[R1-classifier-caiwu] if-match acl 2007
- 创建对应acl来匹配流量
这里犹豫没有多余网段使用精确匹配
# 工程部流量匹配
[R1] acl 2006
[R1-acl-basic-2006] rule permit source 1.1.1.2 0.0.0.0
# 财务部流量匹配
[R1] acl 2007
[R1-acl-basic-2007] rule permit source 1.1.1.3 0.0.0.0
- 指定动作
即流量匹配之后做什么动作,名字可以和上面流量分类的名字不一样
# 指定工程部的流量下一跳
[R1] traffic behavior gongcheng
[R1-behavior-gongcheng] redirect ip-nexthop 12.1.1.2
# 指定财务部的流量的下一跳
[R1] traffic behavior caiwu
[R1-behavior-caiwu] redirect ip-nexthop 13.1.1.3
- 关联(策略)
把分类和动作关联起来,这里的aa是策略名称
[R1] traffic policy aa
[R1-trafficpolicy-aa] classifier gongcheng behavior gongcheng
[R1-trafficpolicy-aa] classifier caiwu behavior caiwu
- 在接口上调用
注意:接口一定要在流量进入的入口,不能是出口
[R1] interface g0/0/2
[R1-GigabitEthernet0/0/2] traffic-policy aa inbound
此时就可以看到PC1工程部访问7.7.7.7R2过,而PC2财务部访问7.7.7.7从R3过的效果:
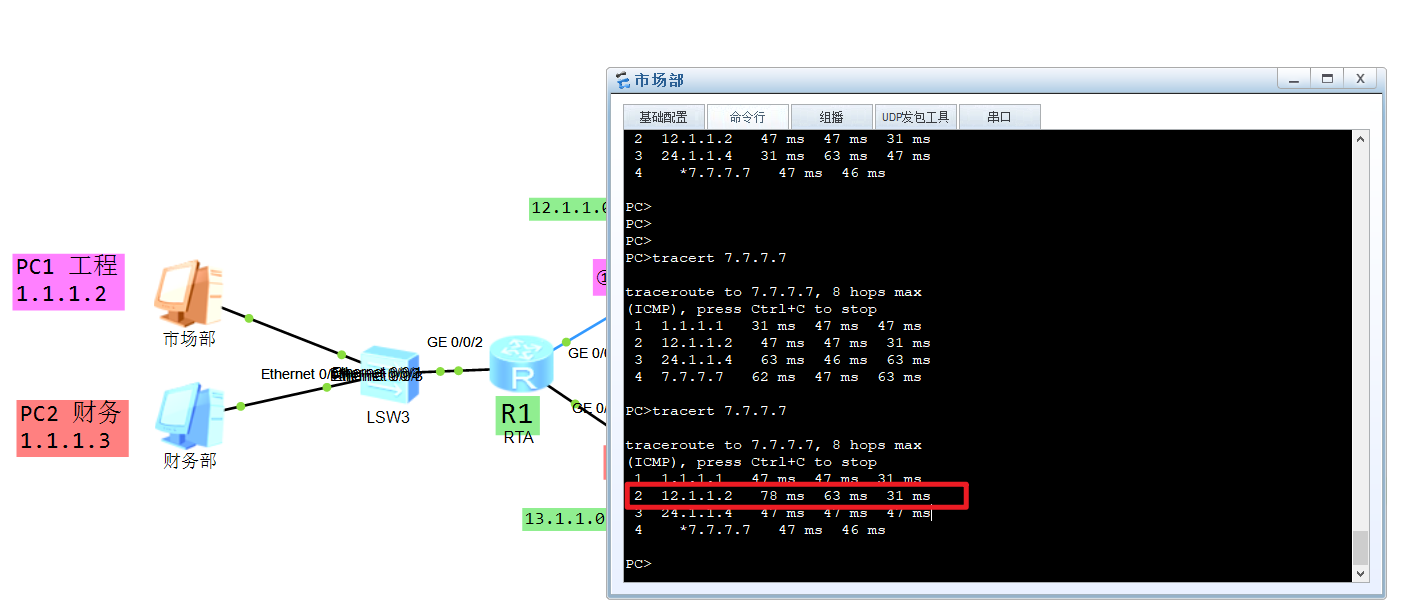
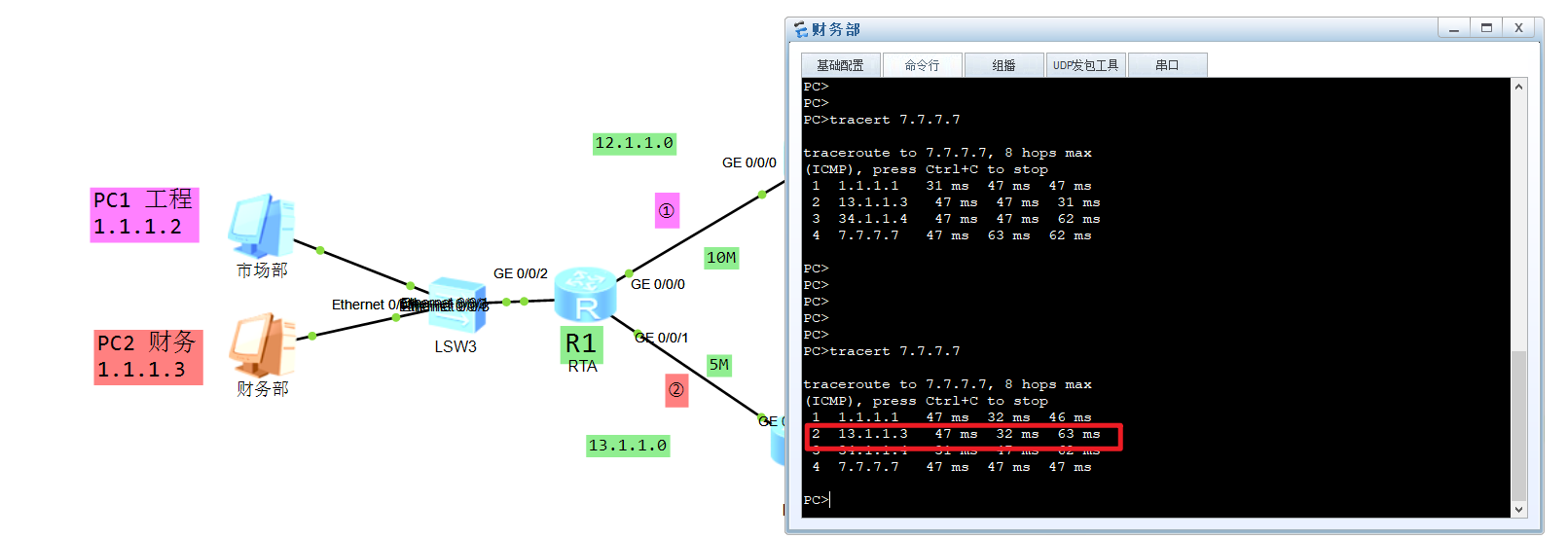
可以使用:display acl all 查看报文匹配数量
1.3 总结
区别和联系:两者都是为了改变网络流量的转发路径,目的一样,但实现的方式不一样。
路由策略:通过更改某些路由参数影响路由表的路由条目来影响报文的转发(例如:filter-policy、route-policy、cost值修改、优先级修改等)
策略路由:通过管理员在路由器上配置策略强制数据包按照策略转发,策略路由优先于路由表。(比如策略路由可以基于源地址定制数据的转发路径)
二、BFD
BDF简介:
Bidirectional Forwarding Detection,双向转发检查 概述:毫秒级链路故障检查,通常结合三层协议(如静态路由、vrrp、 ospf、 BGP等)实现链路故障快速切换。
作用:
① 检测二层非直连故障
② 加快三层协议收敛
R1:
system-view
undo info-center enable
sysname R1
interface loopback 0
ip address 1.1.1.1 24
interface e0/0/1
ip address 21.1.1.1 24
interface e0/0/0
ip address 12.1.1.1 24
q
ip route-static 2.2.2.0 255.255.255.0 21.1.1.2
ip route-static 2.2.2.0 255.255.255.0 12.1.1.2 preference 50
R2:
system-view
undo info-center enable
sysname R2
interface loopback 0
ip address 2.2.2.2 24
interface e0/0/1
ip address 21.1.1.2 24
interface e0/0/0
ip address 12.1.1.2 24
q
ip route-static 1.1.1.0 255.255.255.0 21.1.1.1
ip route-static 1.1.1.0 255.255.255.0 12.1.1.1 preference 50
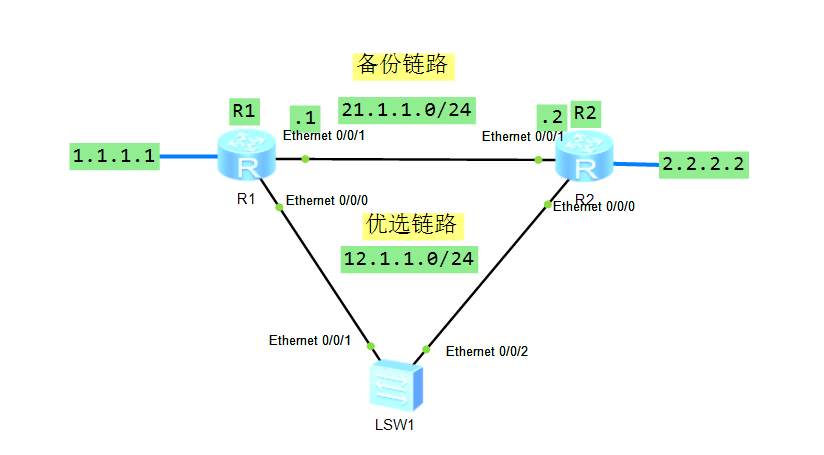
如上图,配置静态路由使得两个路由器上的设备都能互联,但是通常可能会存在以下问题,动态路由还会交互报文确认链路可用,但是配置了静态路由,路由切换的触发条件是当前路由器接口有接口处于down的状态,当出现以下情况它并不会切换,如下:
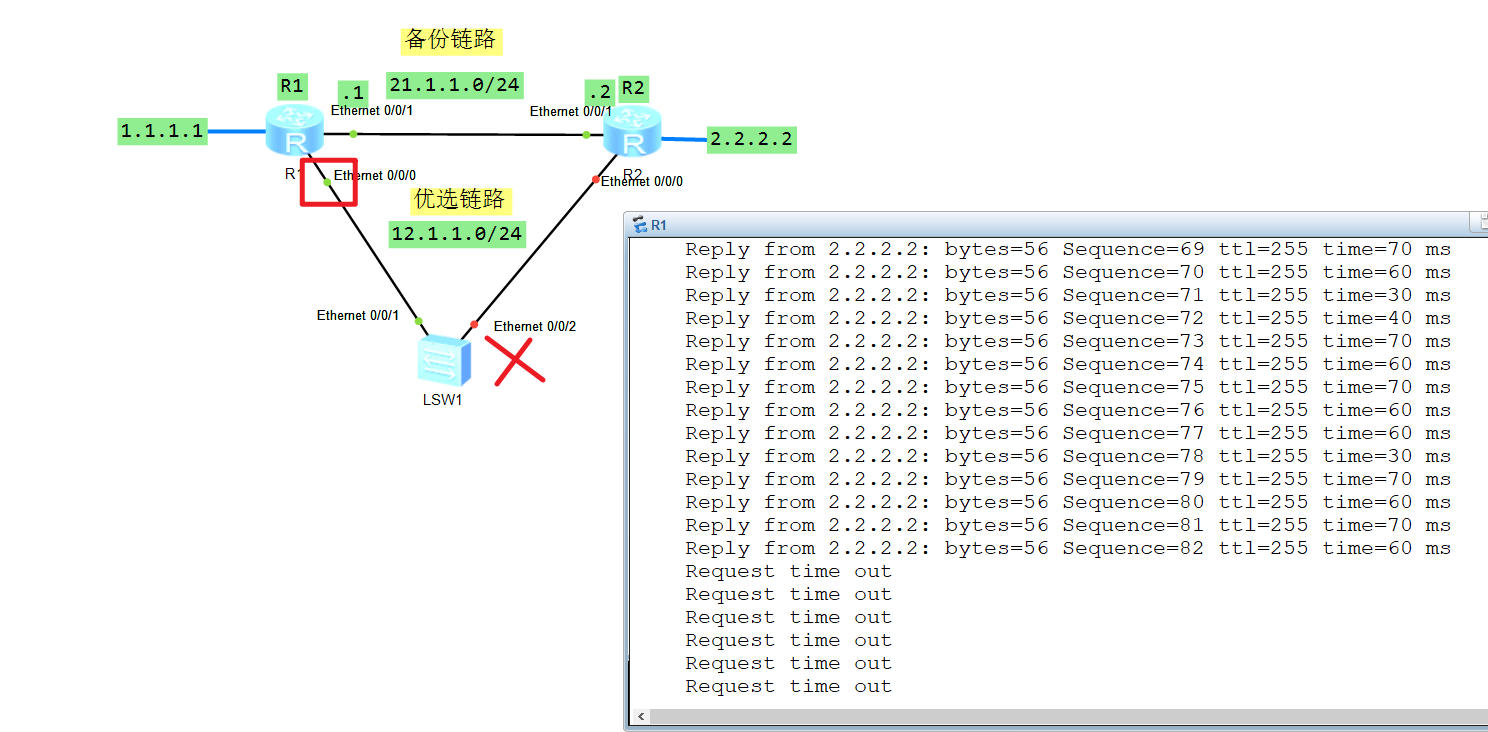
此时优选路由链路其实已经异常,但是路由器还是根据优先级往下面的链路发送流量包。
2.1 静态路由调用静态BFD
为解决以上问题就需要使用BFD技术,配置规则如下:
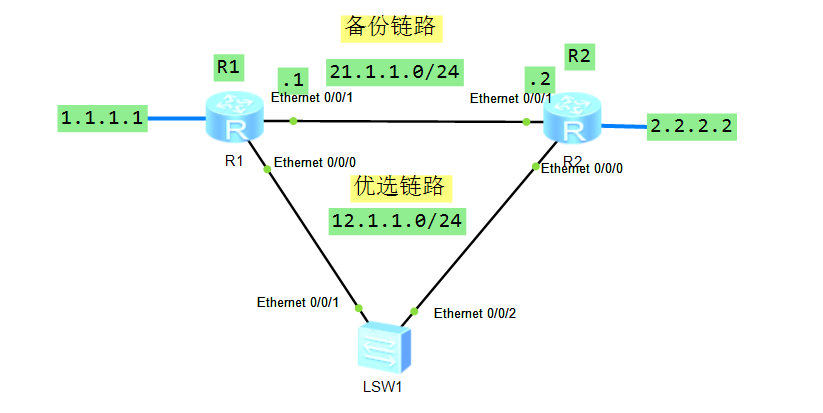
R1:
# 全局使能bfd
[R1] bfd
# 配置指定链路的邻居ip和自己出口的ip,aa是bfd的名称,用于与其他协议绑定使用,等会与静态路由配合使用
[R1] bfd aa bind peer-ip 12.1.1.2 source-ip 12.1.1.1
# 本地标识 两台路由器的标识需要互为对称
[R1-bfd-session-aa] discriminator local 1
[R1-bfd-session-aa] discriminator remote 2
# 使用display this查看没问题的话就可以提交了
[R1-bfd-session-aa] commit
本地表示对称的意思是:
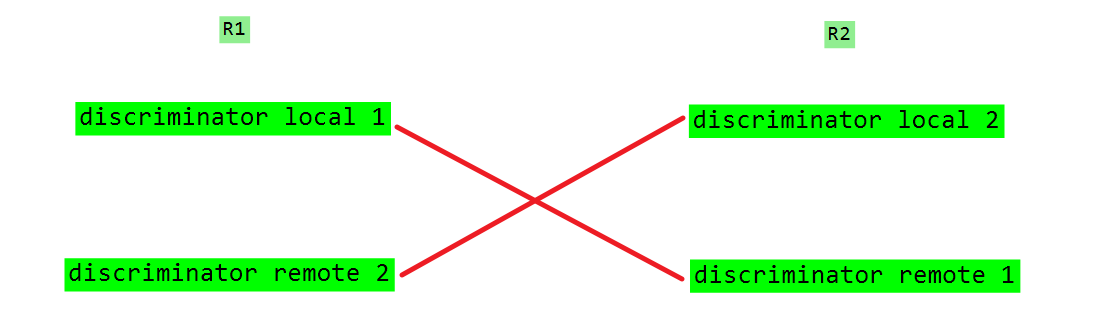
R2:
bfd
q
bfd aa bind peer-ip 12.1.1.1 source-ip 12.1.1.2
discriminator local 2
discriminator remote 1
commit
之后抓包可以看见交互的BFD流量包:
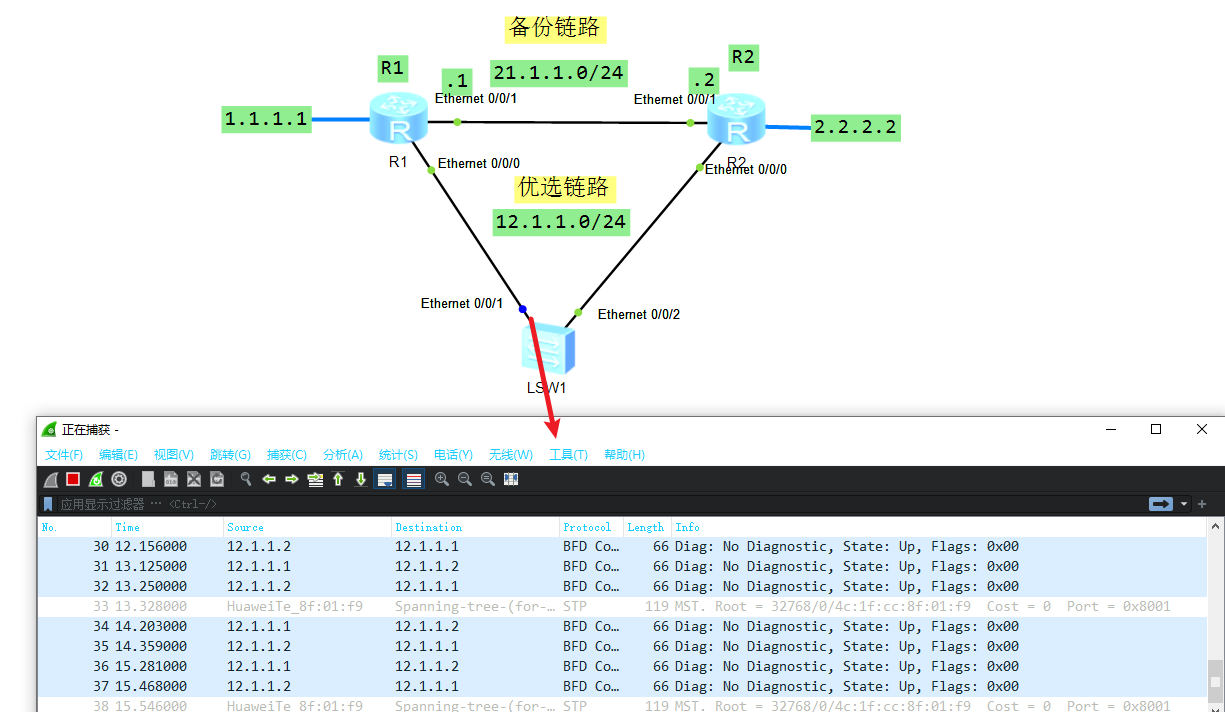
此时再两个路由器上配置静态路由调用BFD即可:
R1:
ip route-static 2.2.2.0 255.255.255.0 12.1.1.2 preference 50 track bfd-session aa
R2:
ip route-static 1.1.1.0 255.255.255.0 12.1.1.1 preference 50 track bfd-session aa
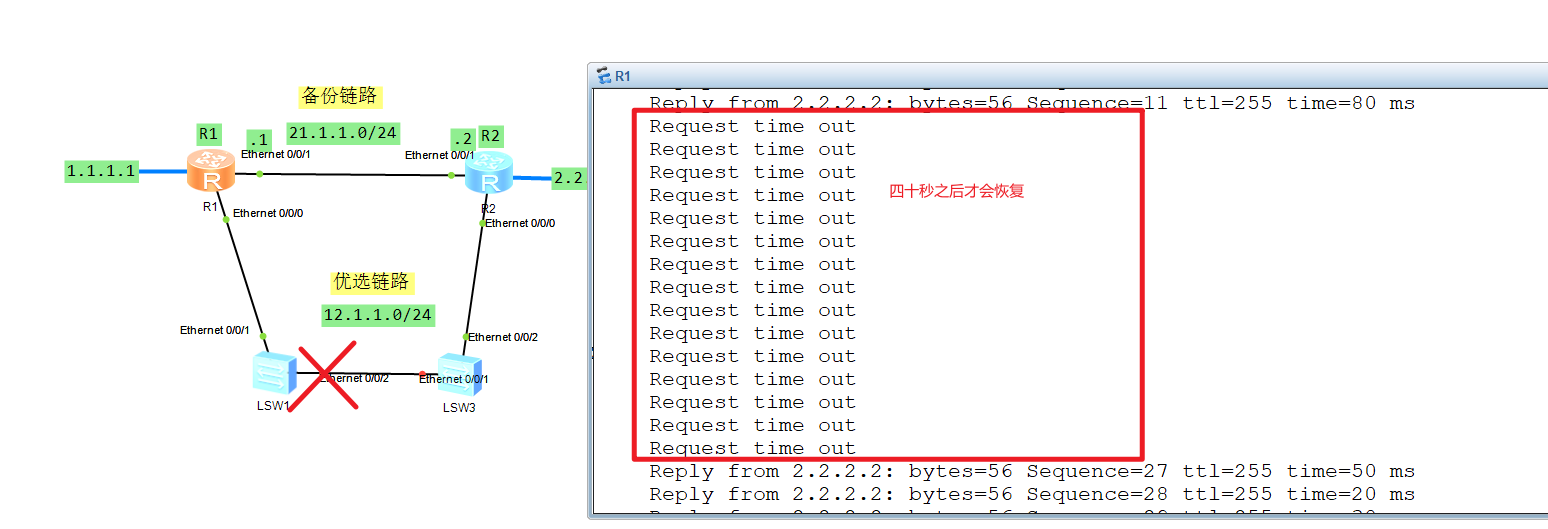
此时再模拟优选链路异常它会快速切换:
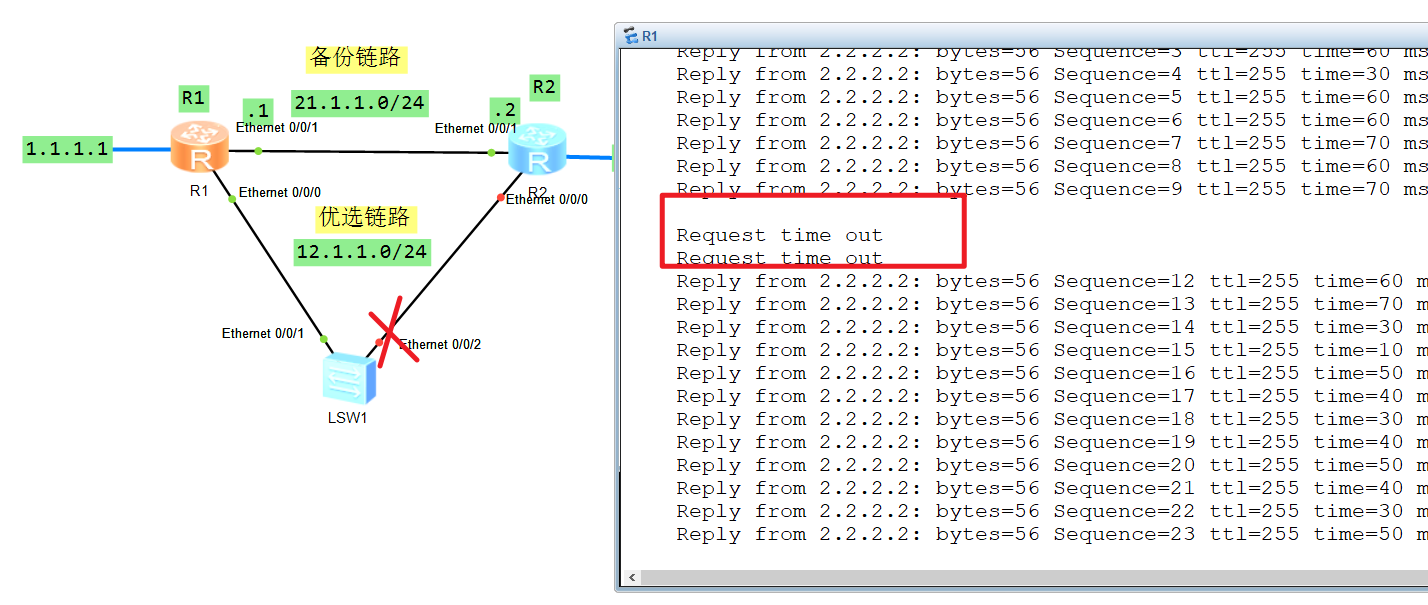
链路大概三秒就就切换了。
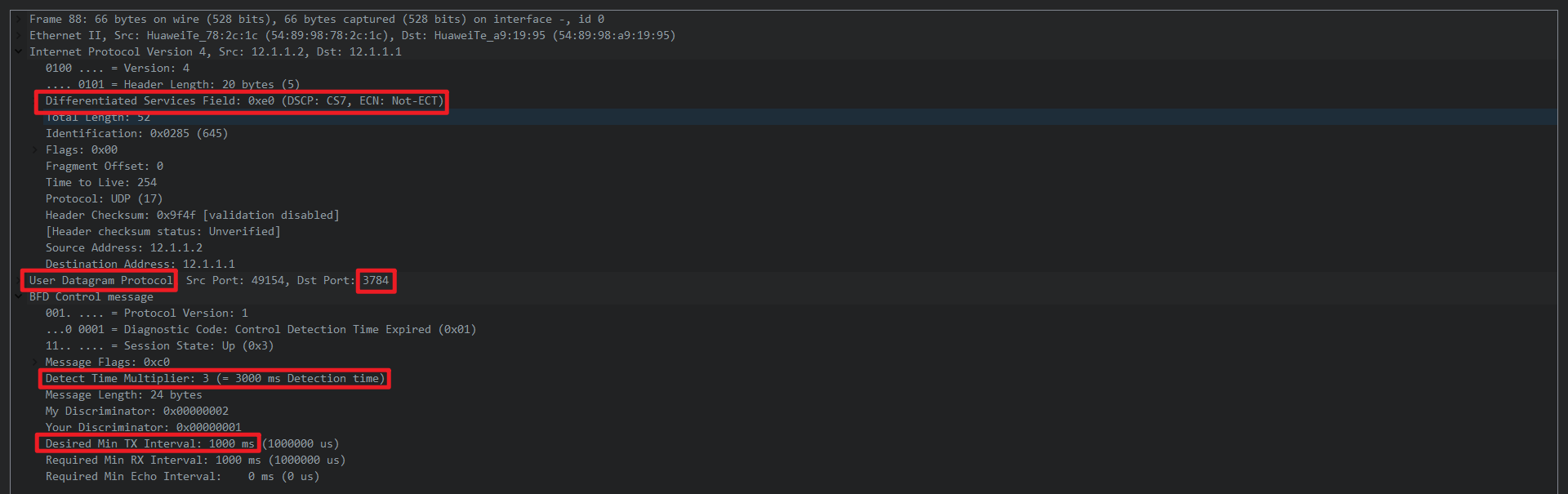
可以看到BFD使用的是UDP的3784端口交互,每隔1000ms交互一次,超过3000就算异常,该数据包有较高的优先级。
调试命令:
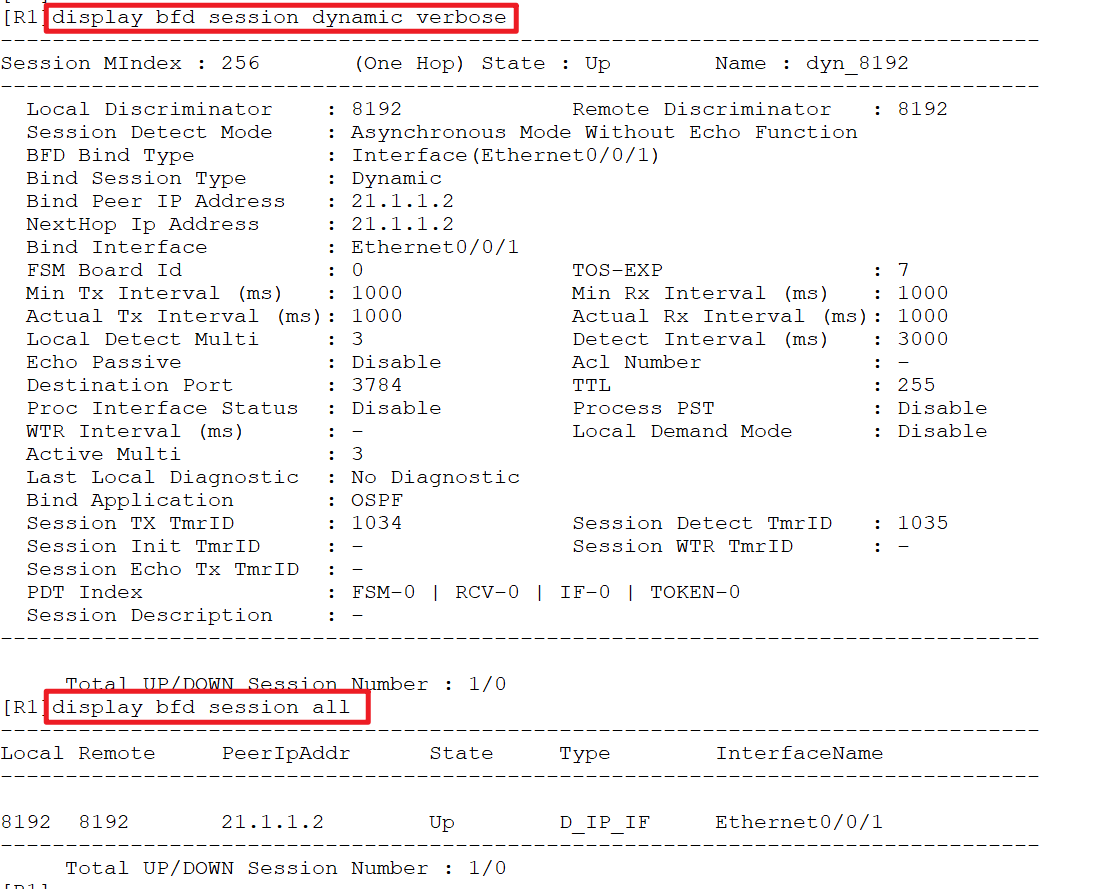
[R1]display bfd session static
--------------------------------------------------------------------------------
Local Remote PeerIpAddr State Type InterfaceName
--------------------------------------------------------------------------------
1 2 12.1.1.2 Up S_IP_PEER -
--------------------------------------------------------------------------------
Total UP/DOWN Session Number : 1/0
2.2 静态路由调用动态BFD
(static-auto)动态协商标识
# 拿掉之前的BFD aa,如果不加名称就是拿掉所有的bfd
[R1] undo bfd aa
配置动态BFD,其实是半自动的,等到使用动态路由的时候才是真全动态。
R1:
# 一点要先敲bfd启用之后退出创建,否则不生效
[R1] bfd
[R1-bfd] q
# 创建动态bfd,多了一个参数auto
[R1] bfd tt bind peer-ip 12.1.1.2 source-ip 12.1.1.1 auto
# 没问题的话提交
[R1-bfd-session-tt] commit
[R1-bfd-session-tt] q
# 静态路由调用
[R1] ip route-static 2.2.2.0 255.255.255.0 12.1.1.2 preference 50 track bfd-session tt
R2:
[R2] bfd
[R2-bfd] quit
[R2] bfd tt bind peer-ip 12.1.1.1 source-ip 12.1.1.2 auto
[R2-bfd-session-tt] commit
[R2-bfd-session-tt] quit
[R2] ip route-static 1.1.1.0 255.255.255.0 12.1.1.1 preference 50 track bfd-session tt
2.3 ospf调用BFD加快收敛
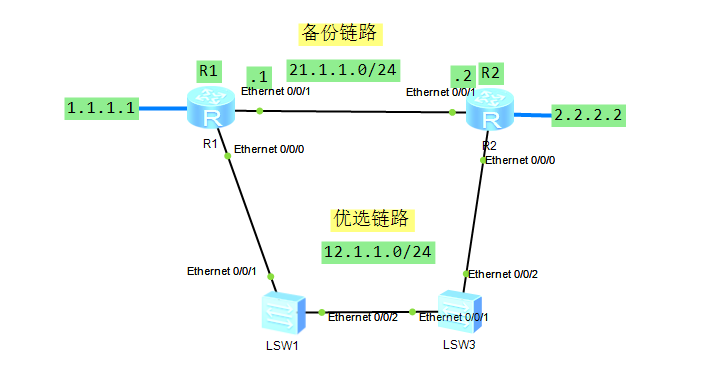
把之前的静态路由以及BFD拿掉:
R1:
[R1] undo bfd
Warning: All BFD capability on the device will be deleted. Continue? [Y/N]Y
[R1] undo ip route-static 2.2.2.0 255.255.255.0 21.1.1.2
[R1] undo ip route-static 2.2.2.0 255.255.255.0 12.1.1.2 preference 50
R2:
[R2]undo bfd
Warning: All BFD capability on the device will be deleted. Continue? [Y/N]y
[R2]undo ip route-static 1.1.1.0 255.255.255.0 21.1.1.1
[R2]undo ip route-static 1.1.1.0 255.255.255.0 12.1.1.1 preference 50
配置ospf来让全网互通:
R1:
ospf 1 router-id 1.1.1.1
area 0
network 12.1.1.1 0.0.0.0
network 1.1.1.1 0.0.0.0
network 21.1.1.1 0.0.0.0
q
q
# 把开销改大让它走优选路径
interface e0/0/1
ospf cost 2
R2:
ospf 1 router-id 2.2.2.2
area 0
network 12.1.1.2 0.0.0.0
network 2.2.2.2 0.0.0.0
network 21.1.1.2 0.0.0.0
q
q
# 把开销改大让它走优选路径
interface e0/0/1
ospf cost 2
问题描述:如果未配置BFD,ospf也会在链路交互hello包,每间隔10秒交互一次,如果交互了4次都是异常,路由才会切换,当然如果是两个路由器能感应到自己有端口down的话它会马上就切换:
配置ospf启用BFD:
R1:
# 全局使能bfd
[R1] bfd
[R1-bfd] quit
# 进入之前配置的ospf进程并所有接口启用,当然也可以启用当个接口
[R1] ospf 1
[R1-ospf-1] bfd all-interfaces enable
以上是所有接口启用,但接口如下,要先进入接口
[R1-Ethernet0/0/1] ospf bfd enable
R2:
bfd
quit
ospf 1
bfd all-interfaces enable
此时再模拟优选链路故障发现三秒就切换了:
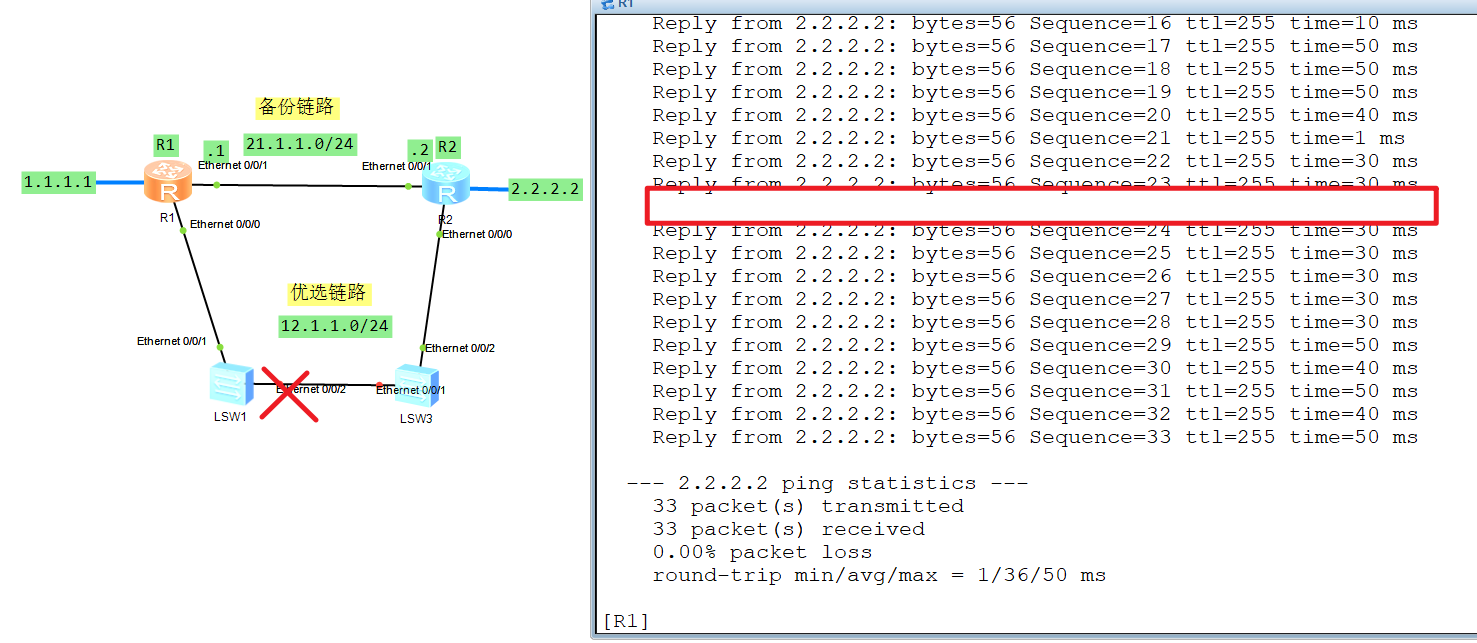
2.4 bfd 单臂回声(one arm echo)
配置BFD一般要在本地以及对端配置,假设如果我们的出口路由器出去之后接的是运营商的设备,运营商的设备我们又无法操作(有钱的话他们也可以帮忙配置),此时就需要配置bfd单臂回声。
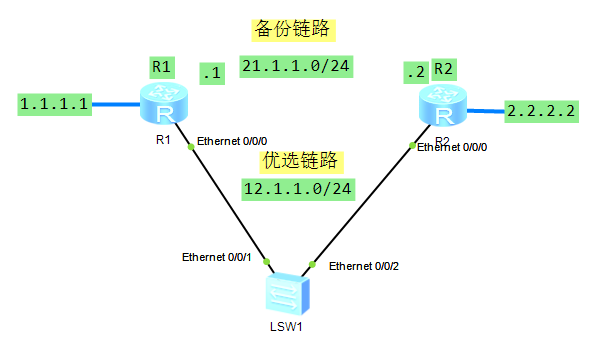
假设还是这个图,把上面的配置都去掉,把21链路的线去掉,只留下配置好的IP,重新配置,左边模拟内网,右边模拟运营商:
给R1配置出去的默认路由:
[R1] ip route-static 0.0.0.0 0.0.0.0 12.1.1.2
R2也配置一下回包路由:
[R2] ip route-static 1.1.1.0 255.255.255.0 12.1.1.1
R1配置单臂BFD:
[R1]bfd
[R1-bfd] quit
[R1] bfd aa bind peer-ip 12.1.1.2 interface e0/0/0 source-ip 21.1.1.1 one-arm-echo
[R1-bfd-session-aa] discriminator local 100
[R1-bfd-session-aa] commit
注意:
source-ip 21.1.1.1 :不建议写本端的IP,写该设备其他端口或者环回口的地址,有些安全设备不允许目标IP和源IP一致,它会以为是攻击包
interface e/0/0: bfd单臂回声报文的目的地址即12.1.1.1(如下图抓包)通常为出接口。
peer-ip 12.1.1.2 : 对端地址 bfd需要依靠该地址探测对方的mac地址 同时作为建立bfd 会话使用见下图(并不用作bfd报文目标地址)
在R1上路由调用:
[R1] ip route-static 0.0.0.0 0.0.0.0 12.1.1.2 track bfd-session aa
如下,它其实就是发了一个以自己出接口为目的地的包,发出去后对端发现是这边的又给它自己发回来,如果发不回来就说明异常:
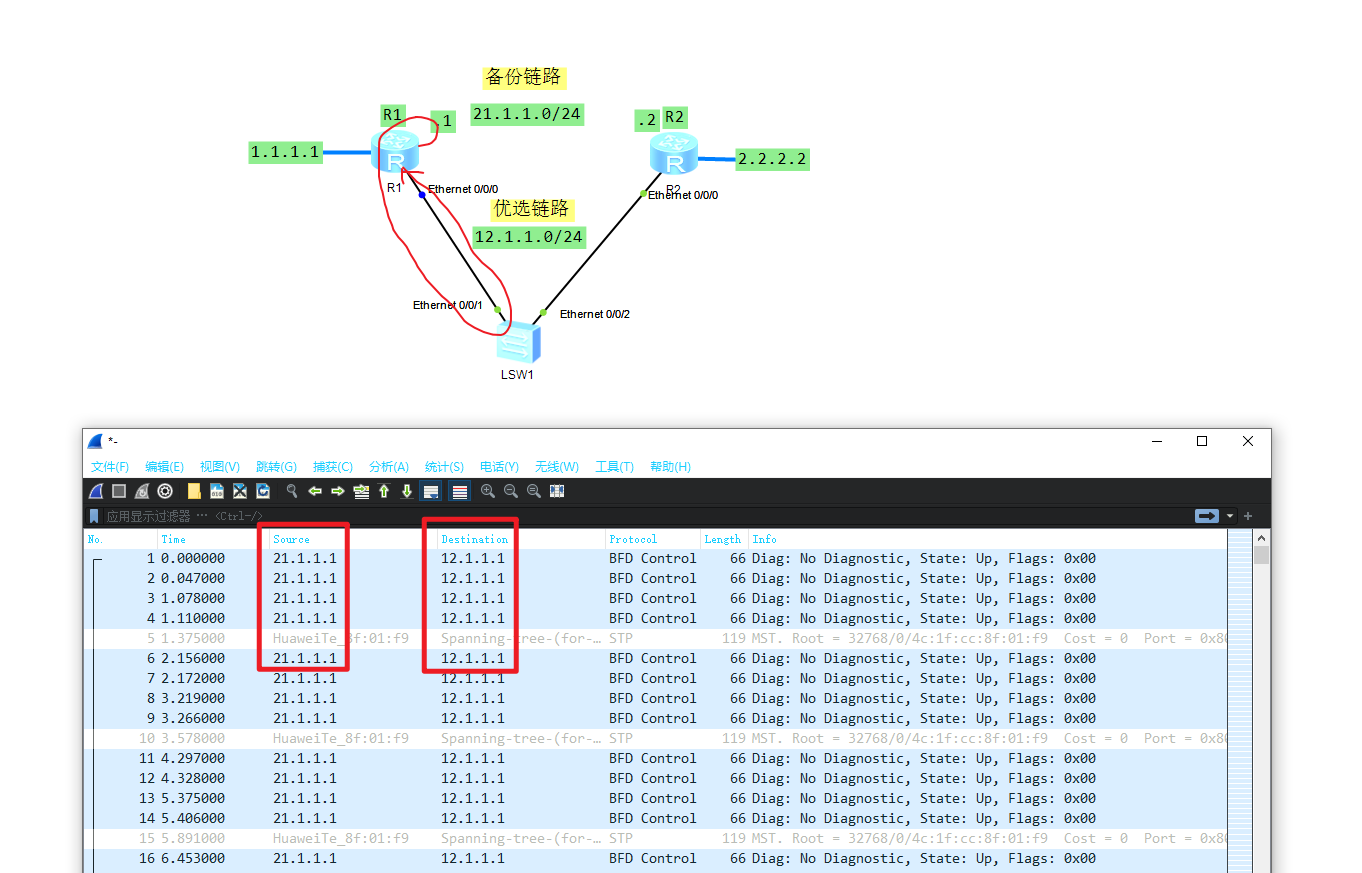
[R1] display bfd session all
--------------------------------------------------------------------------------
Local Remote PeerIpAddr State Type InterfaceName
--------------------------------------------------------------------------------
100 - 12.1.1.2 Up S_IP_IF Ethernet0/0/0
--------------------------------------------------------------------------------
Total UP/DOWN Session Number : 1/0
三、DHCP
概述:在终端规模较大的网络中手工配置IP地址时,为避免IP地址重复,需要事先规划每个终端的IP地址,导致工作量大且容易出错!
dhcp工作流程:
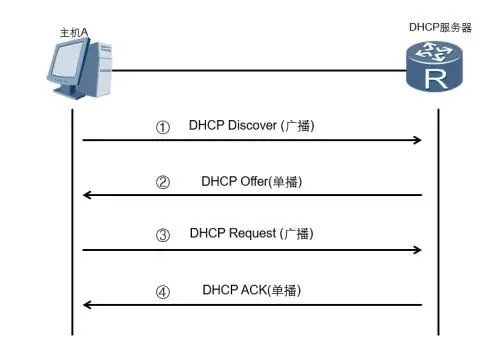
DHCP报文共有一下几种:
- DHCP DISCOVER:客户端开始DHCP过程发送的包,是DHCP协议的开始
- DHCP OFFER :服务器接收到DHCP DISCOVER之后做出的响应,它包括了给予客户端的IP(yiaddr)、客户端的MAC地址、租约过期时间、服务器的识别符以及其他信息
- DHCP REQUEST :客户端对于服务器发出的DHCP OFFER所做出的响应。在续约租期的时候同样会使用。
- DHCP ACK :服务器在接收到客户端发来的DHCP REQUEST之后发出的成功确认的报文。在建立连接的时候,客户端在接收到这个报文之后才会确认分配给它的IP和其他信息可以被允许使用。
- DHCP NAK :DHCP ACK的相反的报文,表示服务器拒绝了客户端的请求。
- DHCP RELEASE :一般出现在客户端关机、下线等状况。这个报文将会使DHCP服务器释放发出此报文的客户端的IP地址
- DHCP INFORM :客户端发出的向服务器请求一些信息的报文
- DHCP DECLINE :当客户端发现服务器分配的IP地址无法使用(如IP地址冲突时),将发出此报文,通知服务器禁止使用该IP地址。
3.1 基于接口的DHCP
R2:
system-view
undo info-center enable
dhcp enable
interface e0/0/0
ip address 192.168.1.1 24
dhcp select interface
dhcp server dns-list 114.114.114.114 8.8.8.8
其他常用调试命令:
客户端:
# 释放当前地址
ipconfig /release
# 重新请求IP地址
ipconfig /renew
服务端:
# 查看所有地址池使用情况
[Huawei]display ip pool
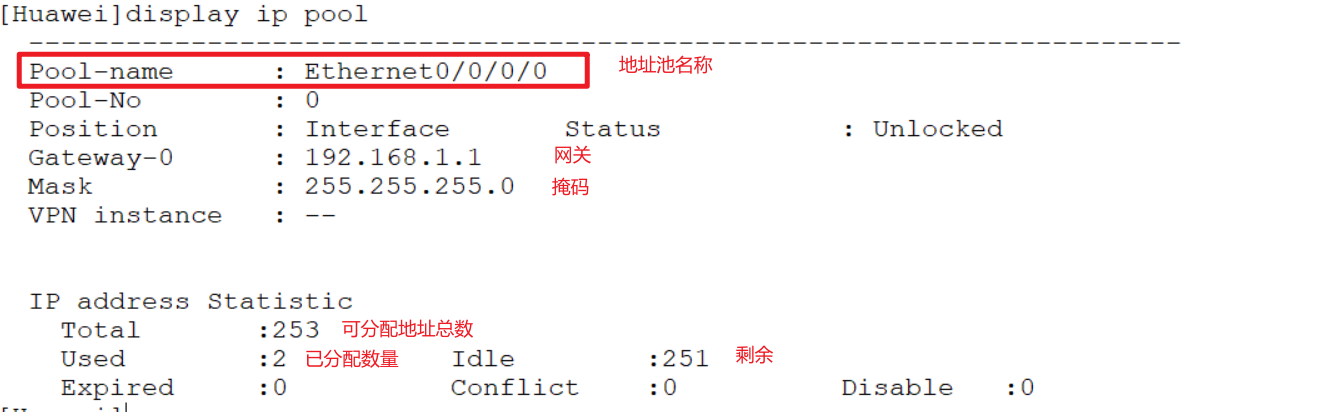
# 查看指定地址池详细信息, Ethernet0/0/0/0是地址池名称
[Huawei]display ip pool interface Ethernet0/0/0/0 used
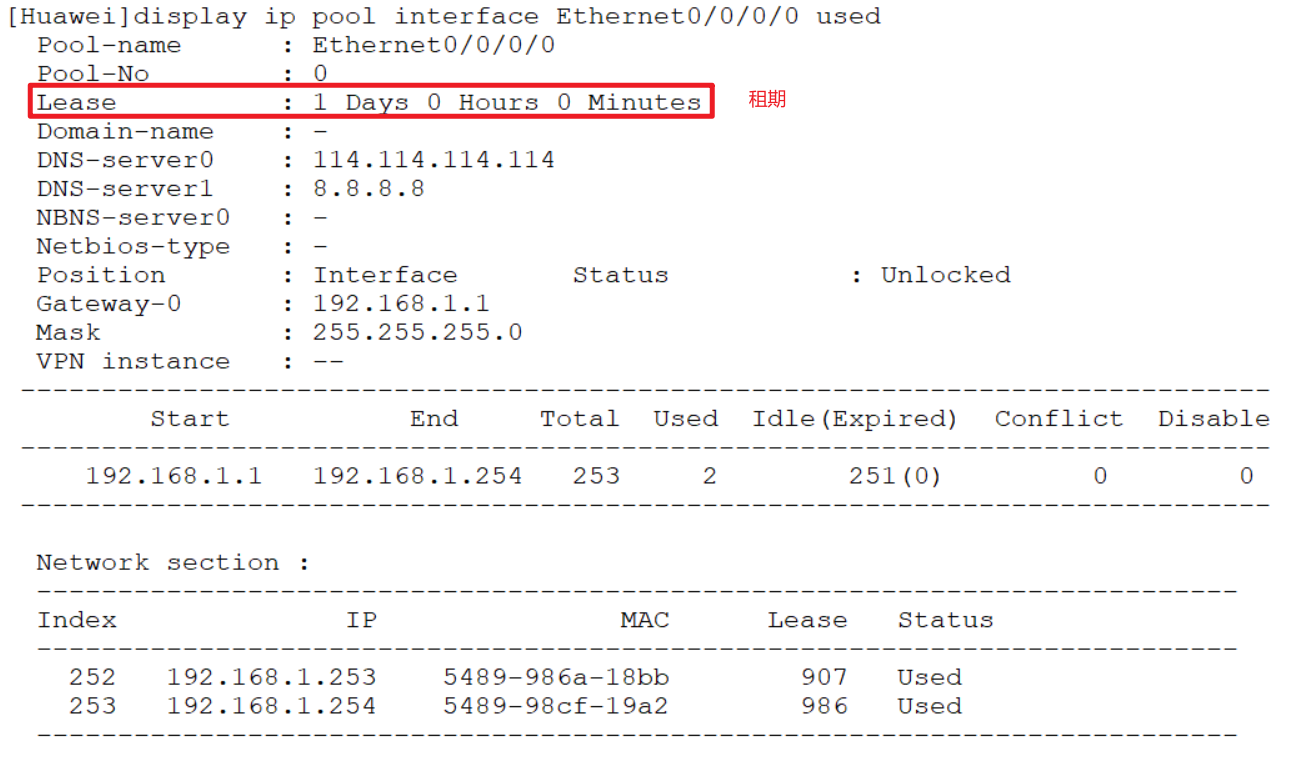

3.2 dhcp 静态绑定、租约
假设场景有时候公司有领导PC或者公共的打印机之类的设备有时候需要固定IP,这时候希望每次DHCP分配地址的时候都希望拿到同一个地址,这时候就需要静态绑定IP,它会更具设备的MAC地址分配同一个地址。
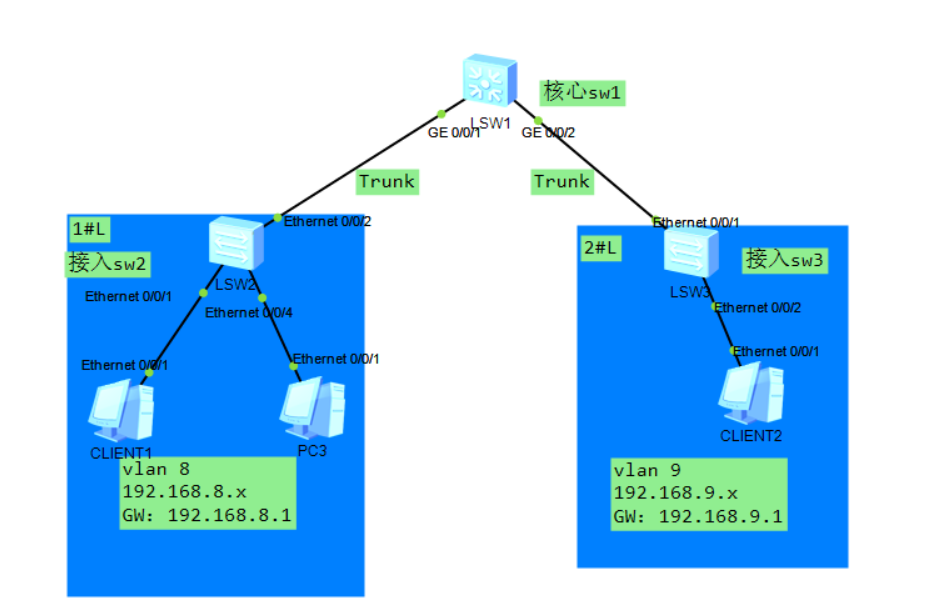
如上使用LSW1交换机作为DHCP服务器,配置全局模式使得下面的PC能够自动获取IP:
LSW1:
system-view
sysname HX_LSW1
undo info-center enable
dhcp enable
vlan batch 8 9
ip pool vlan8
network 192.168.8.0 mask 255.255.255.0
gateway-list 192.168.8.1
dns-list 114.114.114.114 8.8.8.8
q
ip pool vlan9
network 192.168.9.0 mask 255.255.255.0
gateway-list 192.168.9.1
dns-list 114.114.114.114 8.8.8.8
q
interface vlanif 8
ip address 192.168.8.1 24
dhcp select global
interface vlanif 9
ip address 192.168.9.1 24
dhcp select global
interface g0/0/1
port link-type trunk
port trunk allow-pass vlan 8 9
interface g0/0/2
port link-type trunk
port trunk allow-pass vlan 8 9
LSW2:
system-view
undo info-center enable
sysname JR_LSW2
vlan batch 8 9
interface e0/0/2
port link-type trunk
port trunk allow-pass vlan 8 9
q
port-group group-member Ethernet 0/0/1 Ethernet 0/0/4
port link-type access
port default vlan 8
LSW3:
system-view
undo info-center enable
sysname JR_LSW3
vlan batch 8 9
interface e0/0/1
port link-type trunk
port trunk allow-pass vlan 8 9
q
interface e0/0/2
port link-type access
port default vlan 9
3.2.1 dhcp静态绑定配置
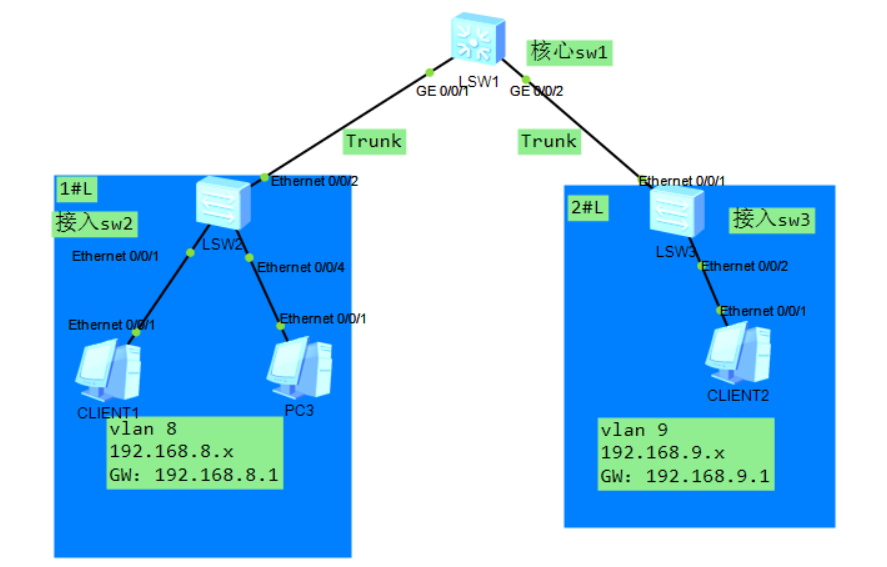
假设现在让CLIENT1拿到静态地址192.168.8.8:
LSW1:
[HX_LSW1] ip pool vlan8
[HX_LSW1-ip-pool-vlan8]static-bind ip-address 192.168.8.8 mac-address 5489-98ce-157a
使用以上命令配置如果此时那个客户端已经分配到地址,在地址池中有记录的话它就会报错,此时需要先清空地址池中的分配记录,该操作需要退出系统视图:
<HX_LSW1> reset ip pool name vlan8 used
# 以上命令是清除所有,下面的命令是清楚指定IP,之后再配置静态IP与mac地址捆绑即可
<HX_LSW1> reset ip pool name vlan8 192.168.8.254
然后再在对应主机上释放并重新获取IP即可:
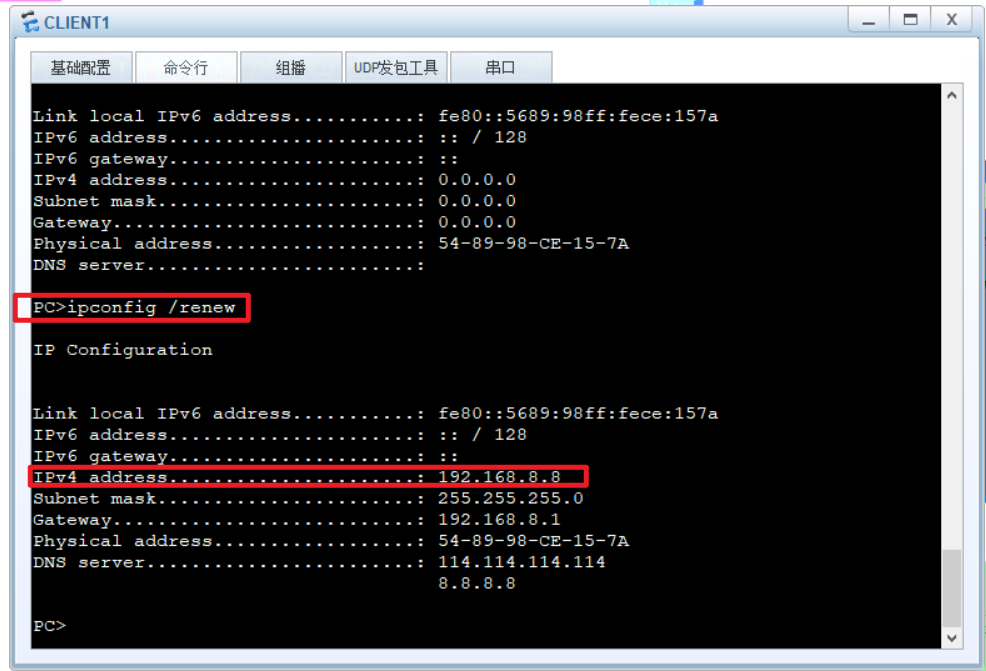
也可以在服务端查看捆绑情况:
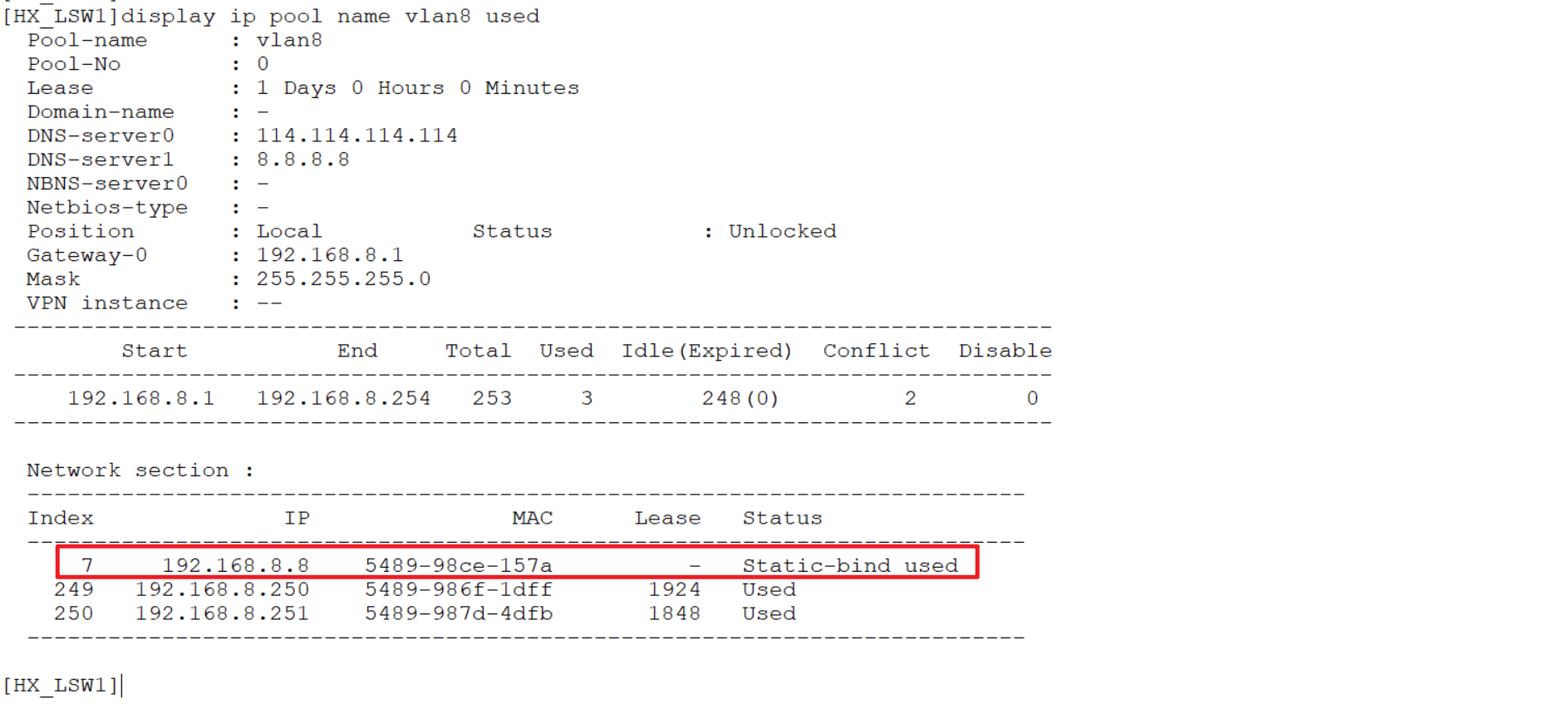
3.2.2 租约
[HX_LSW1] ip pool vlan8
# 租期改为2天2小时30分钟
[HX_LSW1-ip-pool-vlan8] lease day 2 hour 2 minute 30
建议使用默认就可以,不然不利于地址的利用。
3.3 排除地址、domain-name
在规划地址池的时候命令是:network 192.168.8.0 mask 24,它会分配一整个网段的地址在里面,这时候如果你希望部分地址排除在地址池外,希望用于其他用途,这时候就可以配置排除地址:
[HX_LSW1] ip pool vlan8
[HX_LSW1-ip-pool-vlan8] excluded-ip-address 192.168.8.2 192.168.8.10
这里可能会提示要排除的地址处于非空闲状态,但是排除的配置已经写进去了,可以使用display this查看到。
domain-name:这个其实没有什么用,指定一下就可以,这个是DNS后缀。
配置:
[HX_LSW1] ip pool vlan8
[HX_LSW1-ip-pool-vlan8] domain-name guojie.com
配了客户端这里会显示:
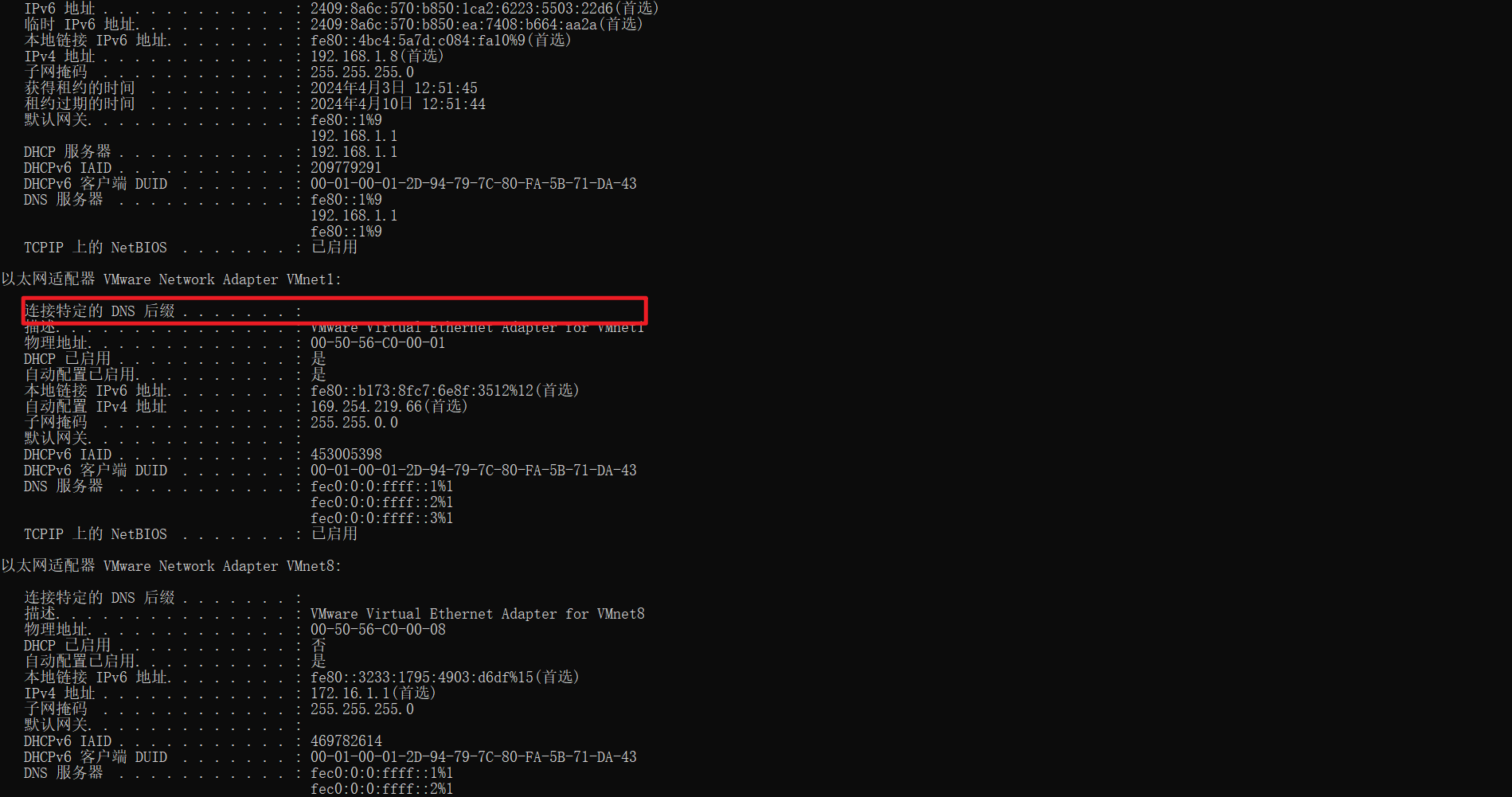
3.4 DHCP server IP 冲突检测
这个功能指的是DHCP server端的功能,意思是DHCP server在收到DHCP请求的时候会对预分配的IP进行测试查看是否广播域内有设备使用该地址,它会直接通过ICMP的ping检测,如果ping了有回复他将测试下一个地址,直到测试得到的地址在广播域中没有人回应他才会把这个IP分配给请求的客户端,但是现在windows7以后的电脑好多都是禁ping的,导致DHCP server无法正确判断该地址是否可用,好多时候DHCP server给客户端分配IP之后,客户端通过ARP检测到广播域内有其它设备正在使用该地址,然后避免冲突它会丢弃该地址,导致很多时候实际PC并不能正确的分配到IP地址。
3.5 DHCP中继-dhcp relay
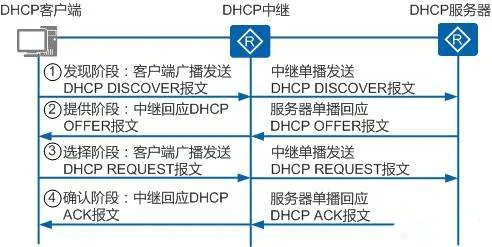
在有些场景中需要创建许多地址池,这时候往往消耗交换机或者路由器的资源,这时候很多情况下就需要使用专门的服务器来当作DHCP服务器,可以使用windows,也可以是linux,而在网关上配置dhcp中继帮忙转发dhcp数据包。
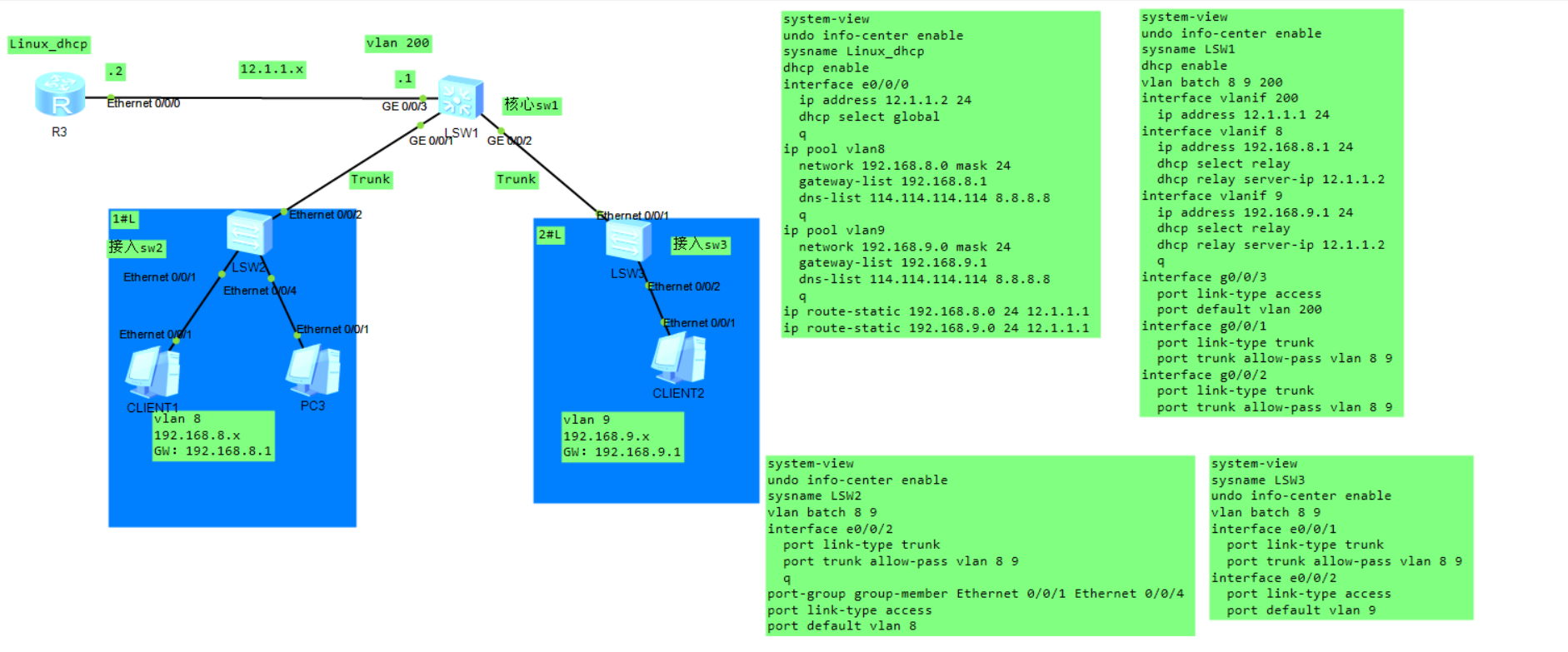
这里使用R3路由器模拟linux服务器做DHCP server:
R3:
dhcp enable
interface e0/0/0
ip address 12.1.1.2 24
dhcp select global
q
ip pool vlan8
network 192.168.8.0 mask 24
gateway-list 192.168.8.1
dns-list 114.114.114.114 8.8.8.8
q
ip pool vlan9
network 192.168.9.0 mask 24
gateway-list 192.168.9.1
dns-list 114.114.114.114 8.8.8.8
q
ip route-static 192.168.8.0 24 12.1.1.1
ip route-static 192.168.9.0 24 12.1.1.1
配置地址池并启用全局模式,有几个vlan就创建几个地址池,客户端请求发送到中继之后它会以网关作为源地址发送单播到dhcp服务器,注意还要配置路由保证互通。
LSW1:
interface vlanif 8
ip address 192.168.8.1 24
dhcp select relay
dhcp relay server-ip 12.1.1.2
interface vlanif 9
ip address 192.168.9.1 24
dhcp select relay
dhcp relay server-ip 12.1.1.2
主要的就是配置中继模式以及指定dhcp服务器的地址。
dhcp中继原理:由于dhcp服务器和用户不在同一个vlan(即不在一个广播 域),因此dhcp 广播报文无法发送到dhcp 服务器,此时在核心交换机上 面配置dhcp中继 将dhcp 广播请求变为单播发送到dhcp 服务器。源地址由0.0.0.0 变成相应vlanif 接口的ip地址,目标地址由255.255.255.255 变成 dhcp 服务器的单播地址。广播包变成单播包被中继到dhcp 服务器,完成 37 地址分配。
3.6 DHCP snooping
DHCP 面临的安全威胁:
- 网络攻击行为无处不在,针对DHCP的攻击行为也不例外。例如某公司突然出现大面积用户无法上网的情况,经检查用户端均未获得IP地址,且DHCP server地址池中的地址已经全部被分配出去,这种情况就是很有可能DHCP受到了饿死攻击导致的。
- DHCP在设计上未充分考虑到安全因素,从而留下了许多安全漏洞,使得DHCP很容易受到攻击,实际网络中,针对DHCP的攻击行为主要有一下三种:
- DHCP饿死攻击
- 仿冒DHCP server攻击
- DHCP中间人攻击
3.6.1 仿冒DHCP Server攻击
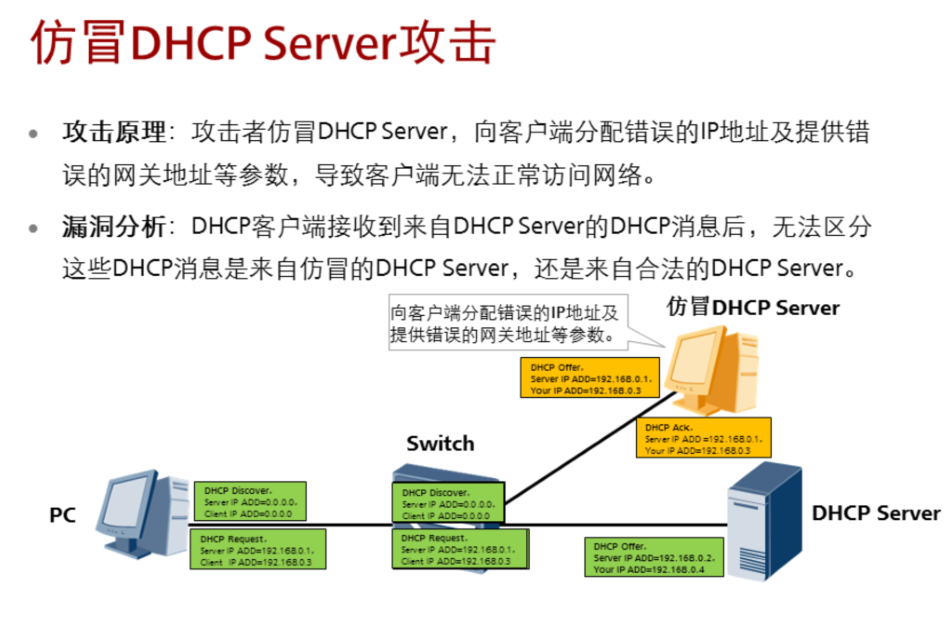
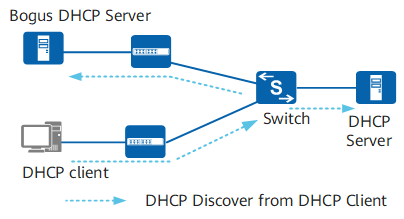
为了杜绝这种情况,我们可以引用dhcp snooping,他的原理是设置一个可信的接口,然后只相信该接口分配过来的IP,可以有效防止非法的dhcp服务器。配置一般要配置在接入层交换机上面。
还是拿上面的图说:
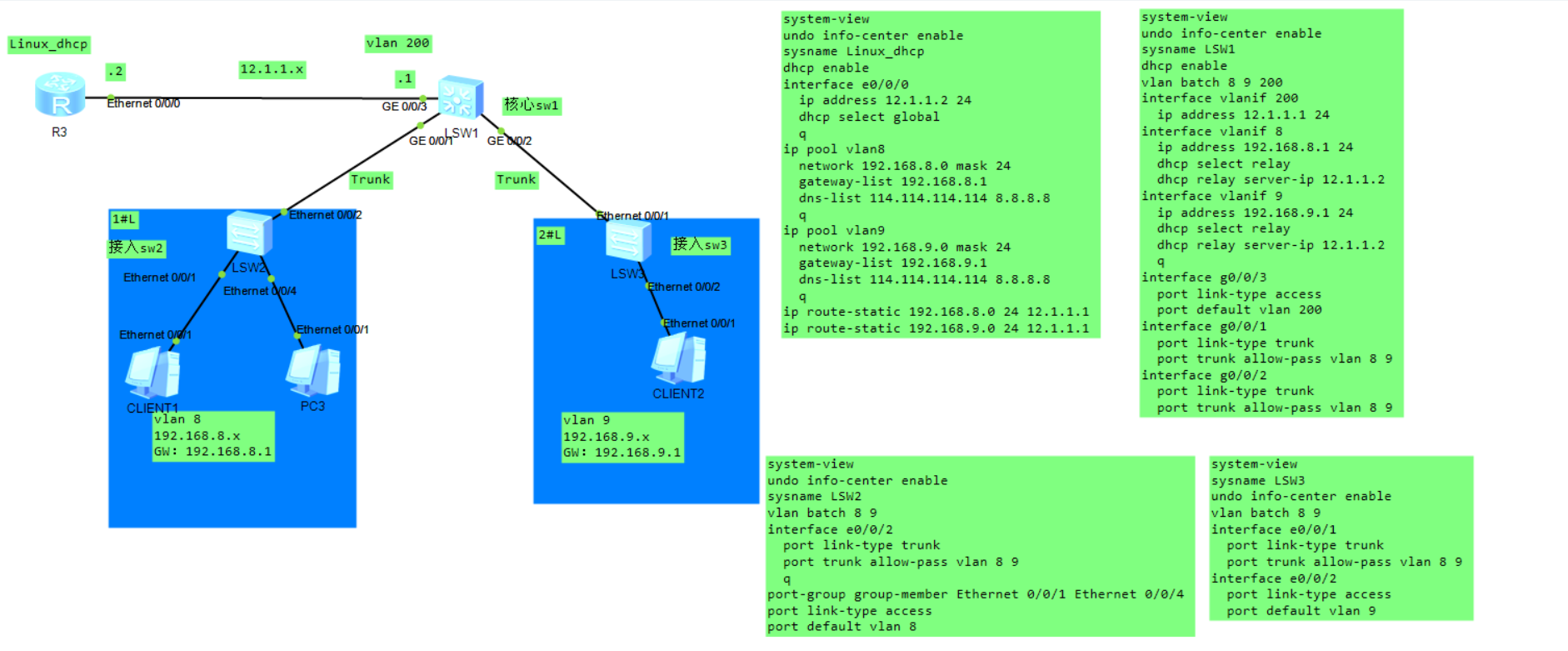
需要在LSW2和LSW3上做如下配置:
LSW2:
# 启用 dhcp snooping
[LSW2] dhcp enable
[LSW2] dhcp snooping enable
# 还要针对对应vlan开启
[LSW2] vlan 8
[LSW2-vlan8] dhcp snooping enable
#最后把上游接口设备为可信接口,否则所有的接口都是非信任接口
[LSW2] interface e0/0/2
[LSW2-Ethernet0/0/2] dhcp snooping trusted
LSW3也是同样的配置:
dhcp enable
dhcp snooping enable
vlan 9
dhcp snooping enable
q
interface e0/0/1
dhcp snooping trusted
交换机从Trusted端口接收到DHCP响应报文(例如DHCP Offer报文、DHCP Ack报文等等)后,会转发这些报文,从而保证合法的DHCP Server可以正常地分配IP地址及提供其他网络参数;交换机从Untrusted端口接收到DHCP响应报文(例如DHCP Offer报文、DHCP Ack报文等等)后,会丢弃这些报文。
3.6.2 DHCP饿死攻击
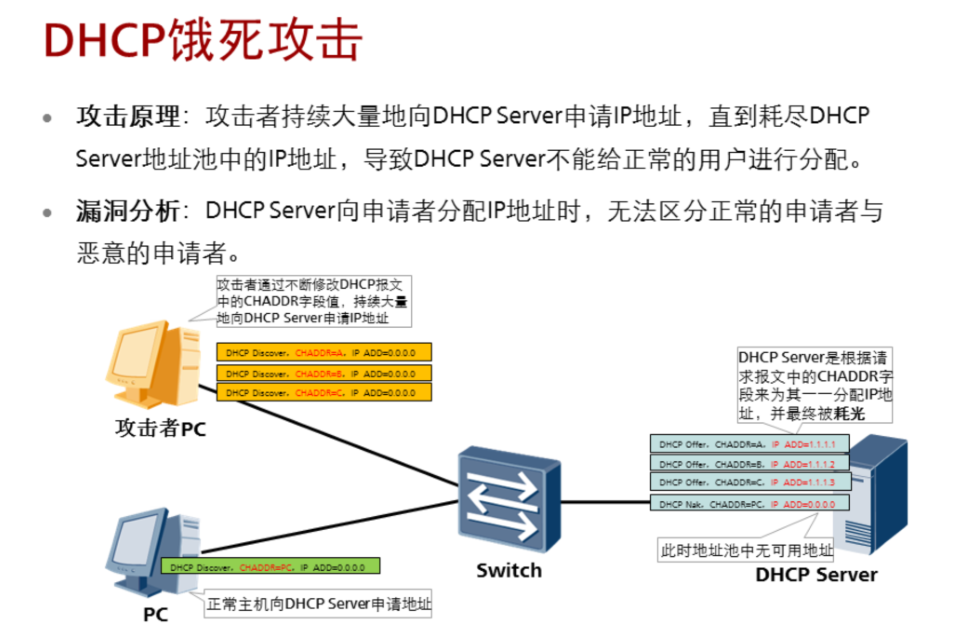
防御该类攻击的方法就是对DHCP request报文的源MAC地址与CHADDR进行一致性检查,发现不一致的话将其丢弃。如果一致则进行转发,配置的方法就是进入所有接入交换的pc接入接口视图下执行如下命令:
还是之前的图,以LSW2为例:
[LSW2] dhcp enable
[LSW2] dhcp snooping enable
[LSW2] port-group group-member e0/0/1 e0/0/4
[[LSW2-port-group] dhcp snooping check dhcp-chaddr enable
chaddr: 该字段表示客户端的MAC地址,此字段与前面的“Hardware Type”和“Hardware Length”保持一致。当客户端发出DHCP请求时,将自己的硬件地址填入此字段。对于以太网,当“Hardware Type”和“Hardware Length”分别为“1”和“6”时,此字段必须填入6字节的以太网MAC地址。
3.6.3 DHCP中间人攻击
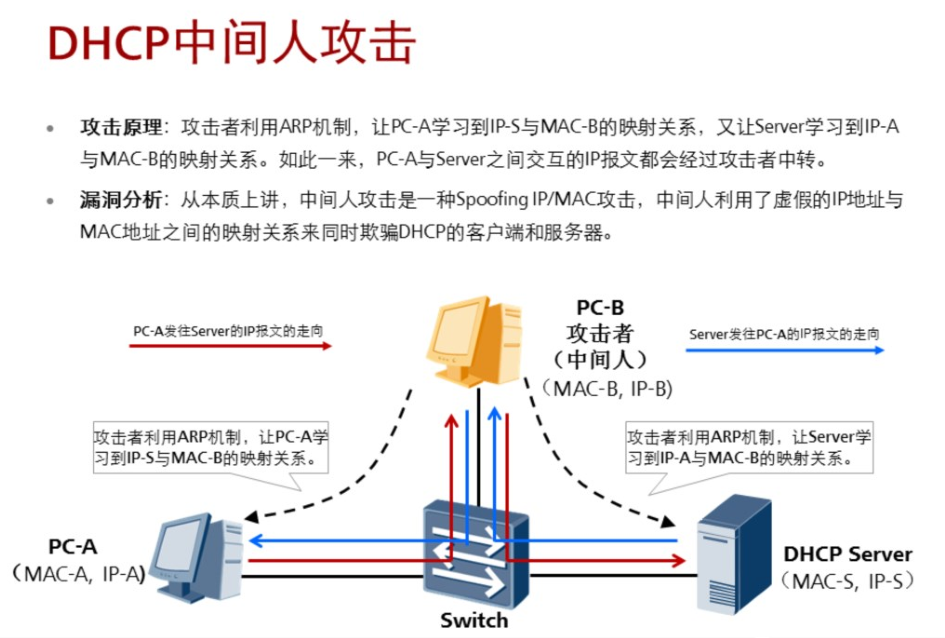
如果需要使用上面所描述的防止Spoofing IP/MAC攻击(进而防止中间人)的方法,需要在交换机的系统视图下执行配置命令
arp dhcp-snooping-detect enable
3.6.4 DHCP Snooping与IPSG技术的联动
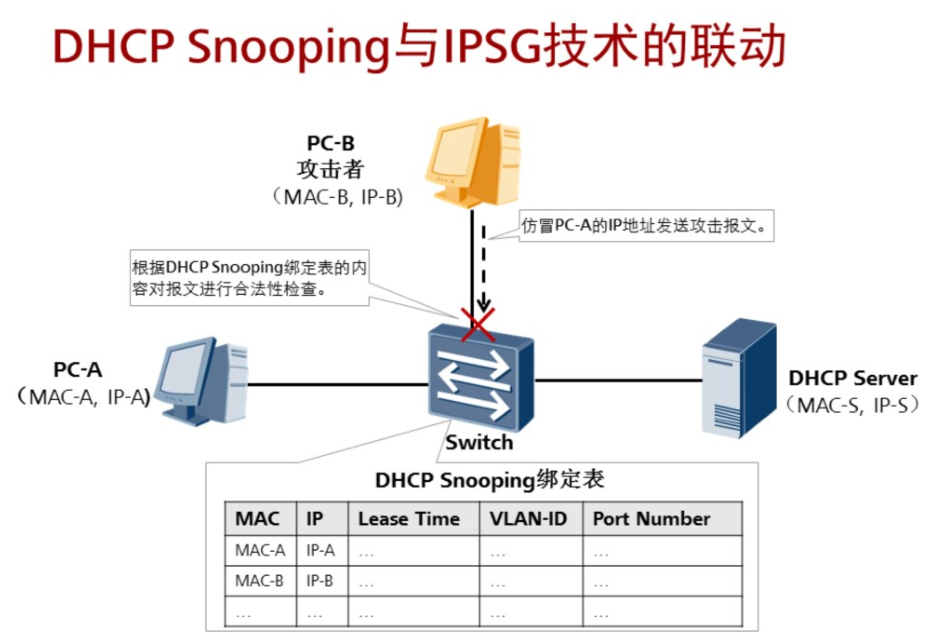
网络中经常会存在针对源IP地址进行欺骗的攻击行为,例如,攻击者仿冒合法用户的IP地址来向服务器发送IP报文。针对这类攻击,相应的防范技术称为IPSG(IPSource Guard)技术。交换机使能IPSG功能后,会对进入交换机端口的报文进行合法性检查,并对报文进行过滤(如果合法,则转发;如果非法,则丢弃)。
报文的检查项可以是源IP地址、源MAC地址、VLAN和物理端口号的若干种组合。例如,在交换机的端口视图下可支IP+MAC、IP+VLAN、IP+MAC+VLAN等组合检查,在交换机的VLAN视图下可支持:IP+MAC、IP+物理端口号、IP+MAC+物理端口号等组合检查。
关键配置命令:在交换机的端口视图下或VLAN视图下执行配置命令
[LSW2-Ethernet0/0/1] ip source check user-bind enable
# 或者
[LSW2] vlan 8
[LSW2-vlan8] ip source check user-bind enable
查看绑定表:

绑定表好像要配置完dhcp信任接口之后才会出现,也就是完成如下步骤:
dhcp enable #开启dhcp
dhcp snooping enable #开启dhcp snooping
vlan 9
dhcp snooping enable #vlan视图开启dhcp snooping
q
interface e0/0/1
dhcp snooping trusted #设置信任接口
完成该操作之后它会按照这个绑定表检查所有的IP,MAC地址等,如果你自己配置IP即使在分配的网段内也无法正常上网。
四、可靠型企业网
常见的可靠型企业网方案有以下两种:
- vrrp+mstp(传统,公有技术,造价小,技术复杂,管理难度大,适用于旧网改造,老旧设备)
- 堆叠技术(推荐,现代,造价高,技术简单,管理简单,私有技术(不同品牌技术不兼容),新建网络)
是否搭建可靠型网络取决与企业性质,如中小学校等可能没必要,但是像政府、银行、三甲医院等等就很有必要。
4.1 MSTP 概述
多生成树协议即MSTP(Multiple Spanning Tree Protocol)

可能会有如下弊端:
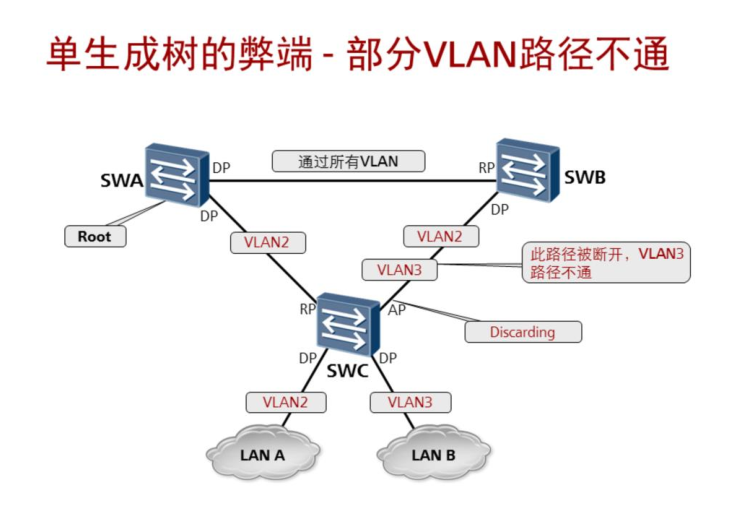
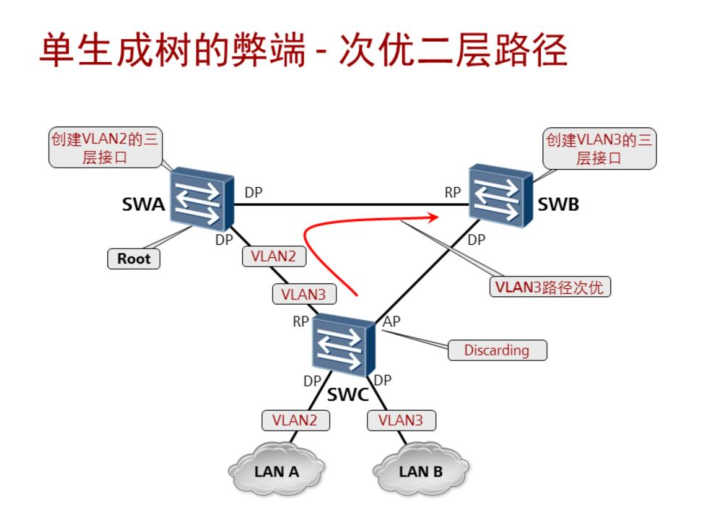
为了解决上面的弊端,之后就出现了MSTP:
MST域是多生成树域(Multiple Spanning Tree Region),由交换网络中的多台交换设备以及它们之间的网段所构成。同一个MST域的设备具有下列特点:
-
都启动了MSTP。
-
具有相同的域名。
-
具有相同的VLAN到生成树实例映射配置。
-
具有相同的MSTP修订级别配置。
注意1:VLAN映射表是MST域的属性,它描述了VLAN和MSTI之间的映射关系,MSTI可以与一个或多个VLAN对应,但一个VLAN只能与一个MSTI对应。
注意2:MSTP兼容STP和RSTP,既可以快速收敛,又提供了数据转发的各个冗余路径,在数据转发过程中实现VLAN数据的负载均衡。
注意3:每个MSTI(MST Instance)都有一个标识(MSTID),MSTID是一个两字节的整数。VRP平台支持16个MST Instance,MSTID取值范围是0~15(软件升级之后取值范围0-48),默认所有VLAN映射到MST Instance 0。
简单的说就是运行多个实例的stp,他们互不干扰,每一个实例都会有自己的算法阻塞不同端口。
4.2 MSTP 配置
华为交换机:出厂默认运行mstp协议,默认情况下所有的vlan 都属于组0 (instance 0 )。默认的mstp域名是交换机的桥 mac地址。 instance 0 :默认实例 默认出厂配置

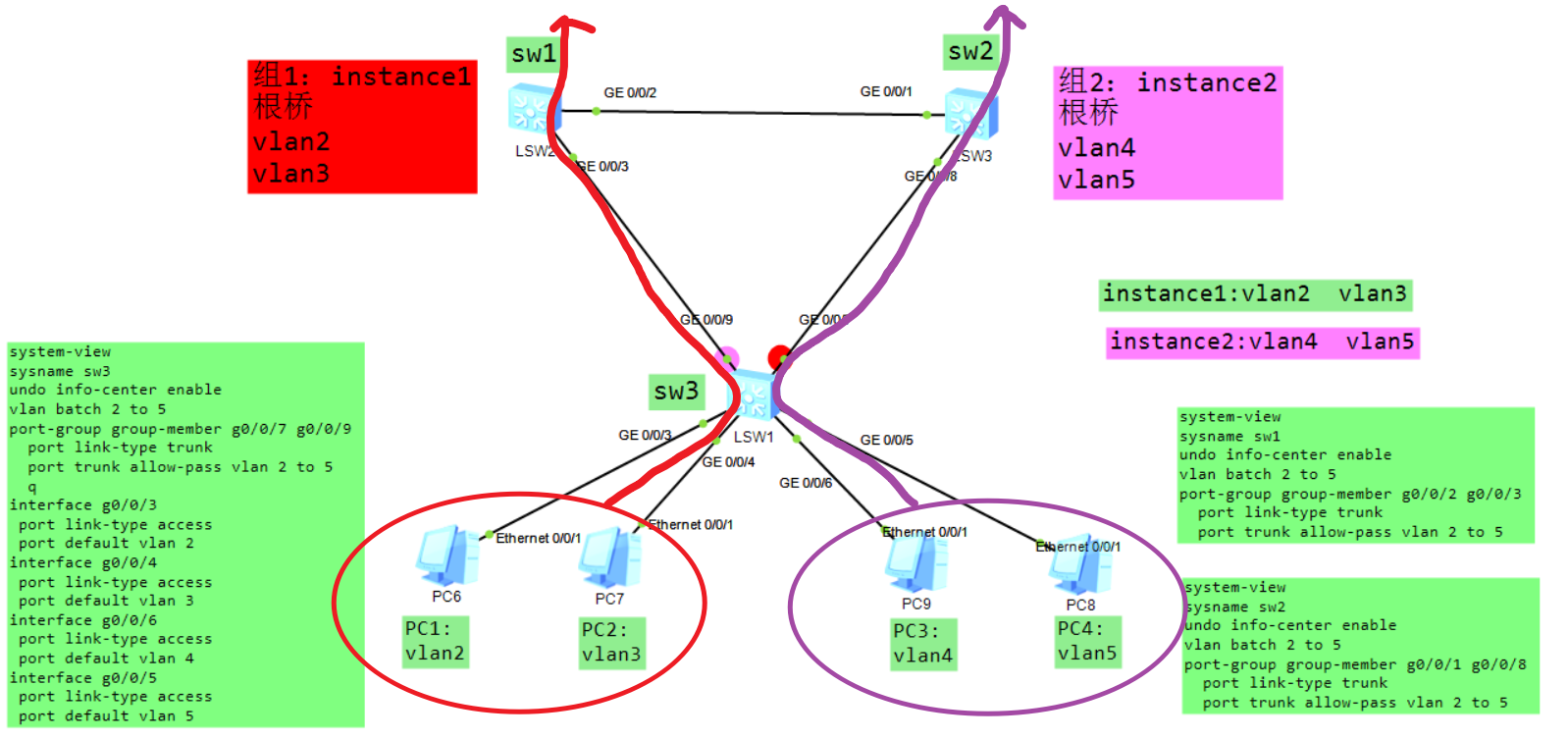
如上图,所有交换机vlan、trunk提前配置,所有交换机vlan保持一致,现在希望PC1、PC2在正常情况下让它走左边的链路,有异常再自动切换到右边,而右边的PC3、PC4则相反,优先走右边的链路,异常之后再切换过来。要达到这种目的就需要两套互不干扰的stp,左边的PC需要让stp阻塞右边的端口,右边的PC需要让stp阻塞左边的端口,就需要做如下配置:
sw1:
# 进入mstp配置界面
[sw1] stp region-configuration
# 配置mstp域名
[sw1-mst-region] region-name aa
# 配置修订号
[sw1-mst-region] revision-level 1
# 将vlan 2、3映射到实例1,vlan4、5映射到实例2
[sw1-mst-region] instance 1 vlan 2 3
[sw1-mst-region] instance 2 vlan 4 5
# 激活mstp配置
[sw1-mst-region] active region-configuration
其他两个交换机(sw2、sw3)也要做相同操作:
stp region-configuration
region-name aa
revision-level 1
instance 1 vlan 2 3
instance 2 vlan 4 5
active region-configuration
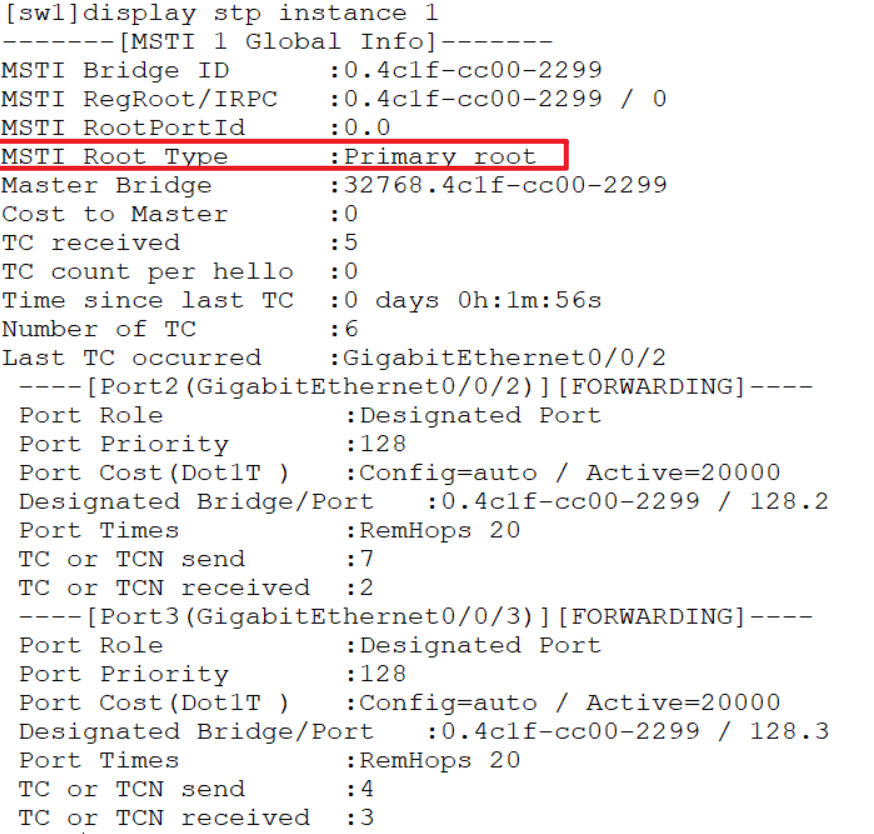
sw1设置桥优先级,保证组1里被选举为根桥,让它的接口在组1中不会被阻塞,这里可以修改优先级,方便的就是可以直接在组1中直接把它设置为根桥,把sw2设置为备份根桥:
sw1:
[sw1] stp instance 1 root primary
sw2:
[sw2] stp instance 1 root secondary
之后就可以查看sw1在instace 1中被选为根桥:
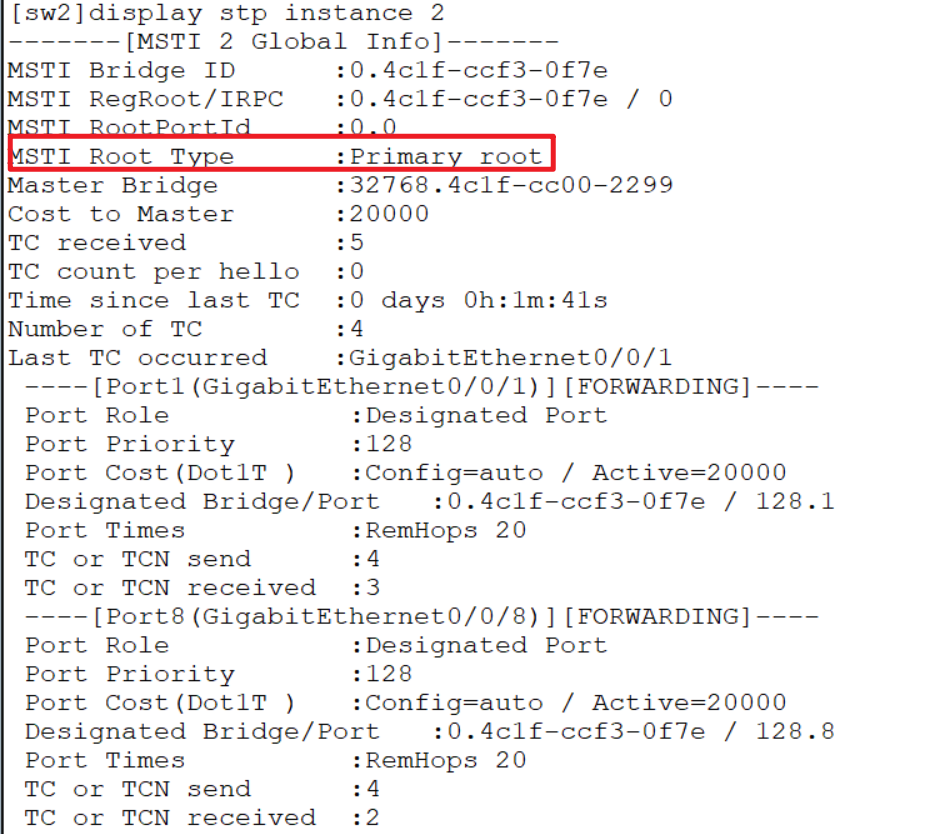
组二配置:
之后再配置组2,组2映射了vlan 4、5,所以要保证sw2被选举为根桥,同理:
sw2:
[sw2] stp instance 2 root primary
sw1:
[sw1] stp instance 2 root secondary
在sw3上查看阻塞情况:
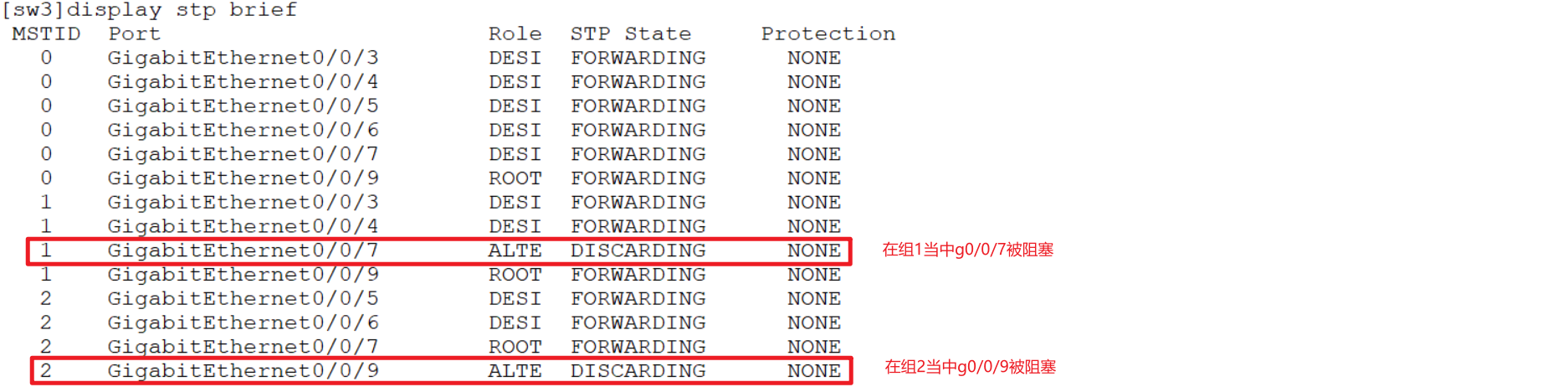
4.3 MSTP调试命令:
display stp region-configuration
display stp instance 1
display stp brief
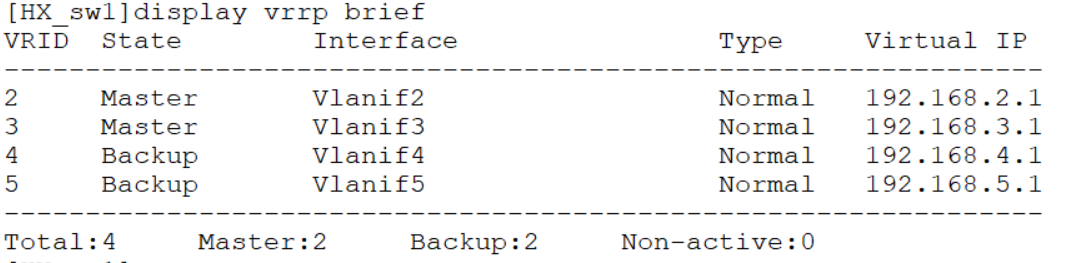
4.4 VRRP 概述
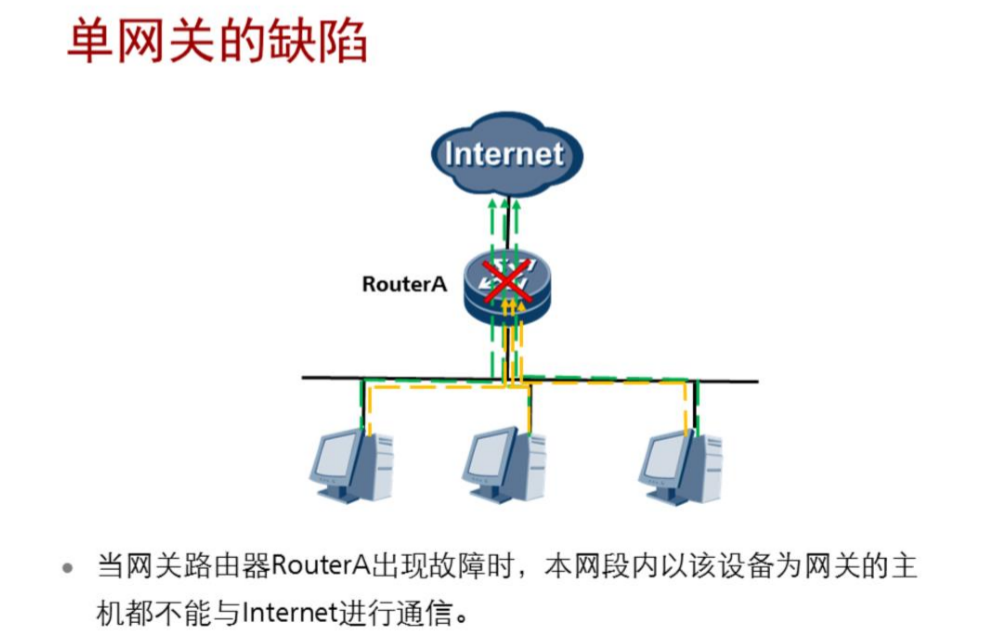
VRRP:虚拟网关冗余协议 Virtual Router Redundancy Protocol 三层路由冗余技术,大多叫虚拟网关冗余协议,对用用户的网关做冗余,提升网络的稳定性。
先说一下出现的原因:
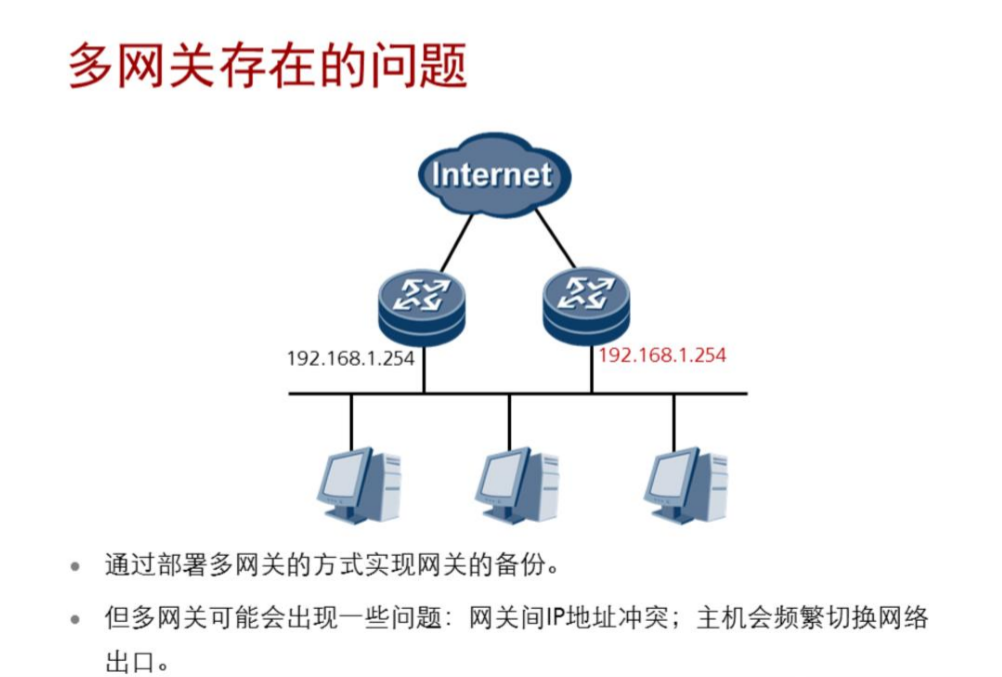
解决方案:

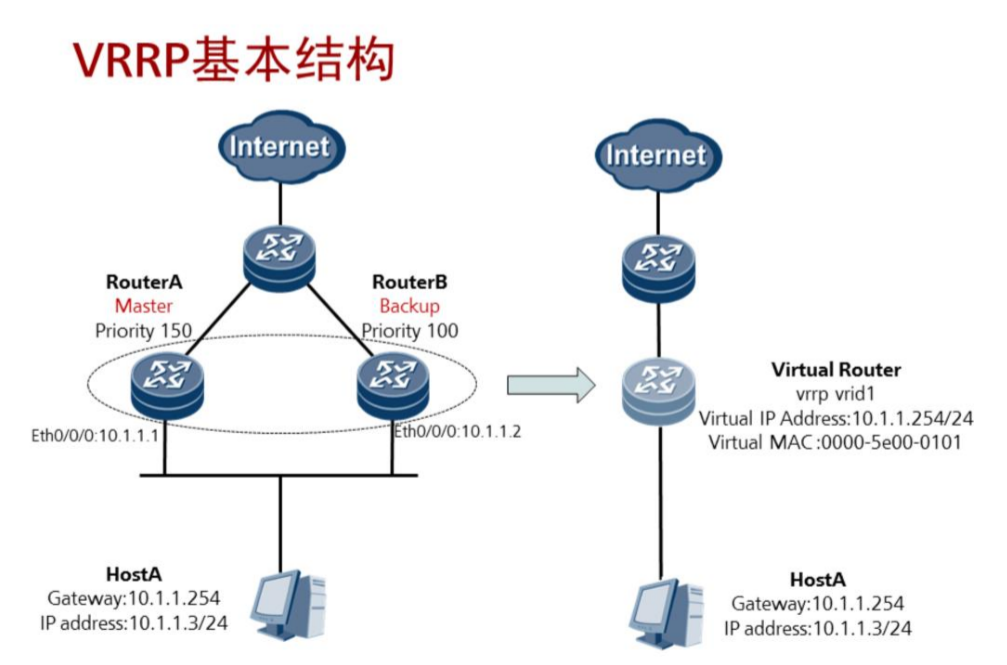
即可以理解为多个网关虚拟出一个网关,当网络故障时它会自己切换。
注意1:Priority:设备在备份组中的优先级,取值范围是0~255。0表示设备停止参与VRRP备份组,用来使备份设备尽快成为Master设备,而不必等到计时器超时;255则保留给IP地址拥有者,无法手工配置;设备缺省优先级值是100。
注意2:IP地址拥有者(IP Address Owner):如果一个VRRP设备将真实的接口IP地址配置为虚拟路由器IP地址,则该设备被称为IP地址拥有者。如果IP地址拥有者是可用的,则它将一直成为Master。
注意3:虚拟MAC地址(Virtual MAC Address):虚拟路由器根据vrid生成的MAC地址。一个虚拟路由器拥有一个虚拟MAC地址,格式为:00-00-5E-00-01-{vrid} 。
4.5 VRRP 主备备份
4.5.1 主备配置
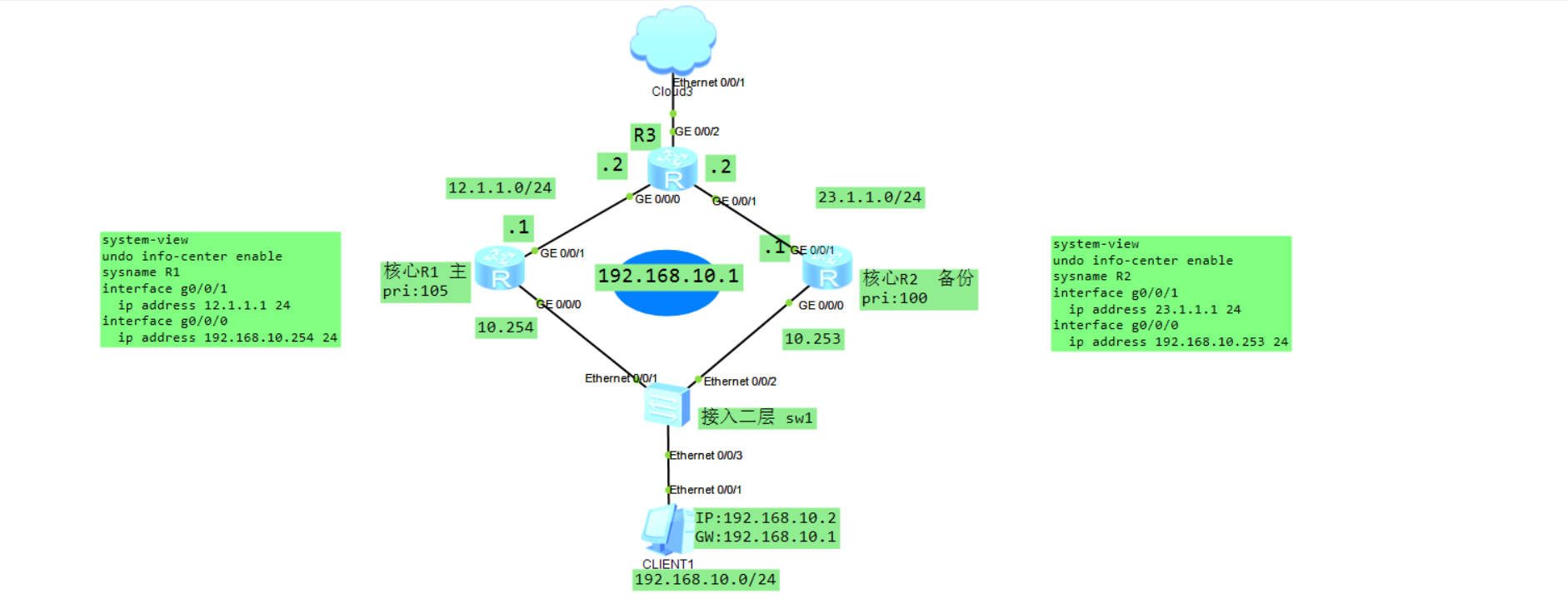
R1:
# 进入下游(链接用户的接口)
[R1] interface g0/0/0
# 配置虚拟IP,vrid和其它真实网关的要一致
[R1-GigabitEthernet0/0/0] vrrp vrid 1 virtual-ip 192.168.10.1
# 配置优先级,默认是100,越大优先越高
[R1-GigabitEthernet0/0/0] vrrp vrid 1 priority 105
R2:
interface g0/0/0
vrrp vrid 1 virtual-ip 192.168.10.1
注意:vrrp手动设置的优先级为1-254,如果设置为0,它不参与选举主备,而255是用来表述虚拟地址的拥有者,该拥有者只要正常工作就一直是255。
4.5.2 跟踪上联接口:
以上配置存在一个问题,就是假设上端口GE0/0/1连接的上游设备如果出问题了,此时该路由器已经异常了,不能为用户提供正确的转发需求,但是VRRP还是不会迁移到备份网关R2,因为它的心跳报文还是可以从GE0/0/0正常发给备用网关。此时就需要配置跟踪上联接口的配置。
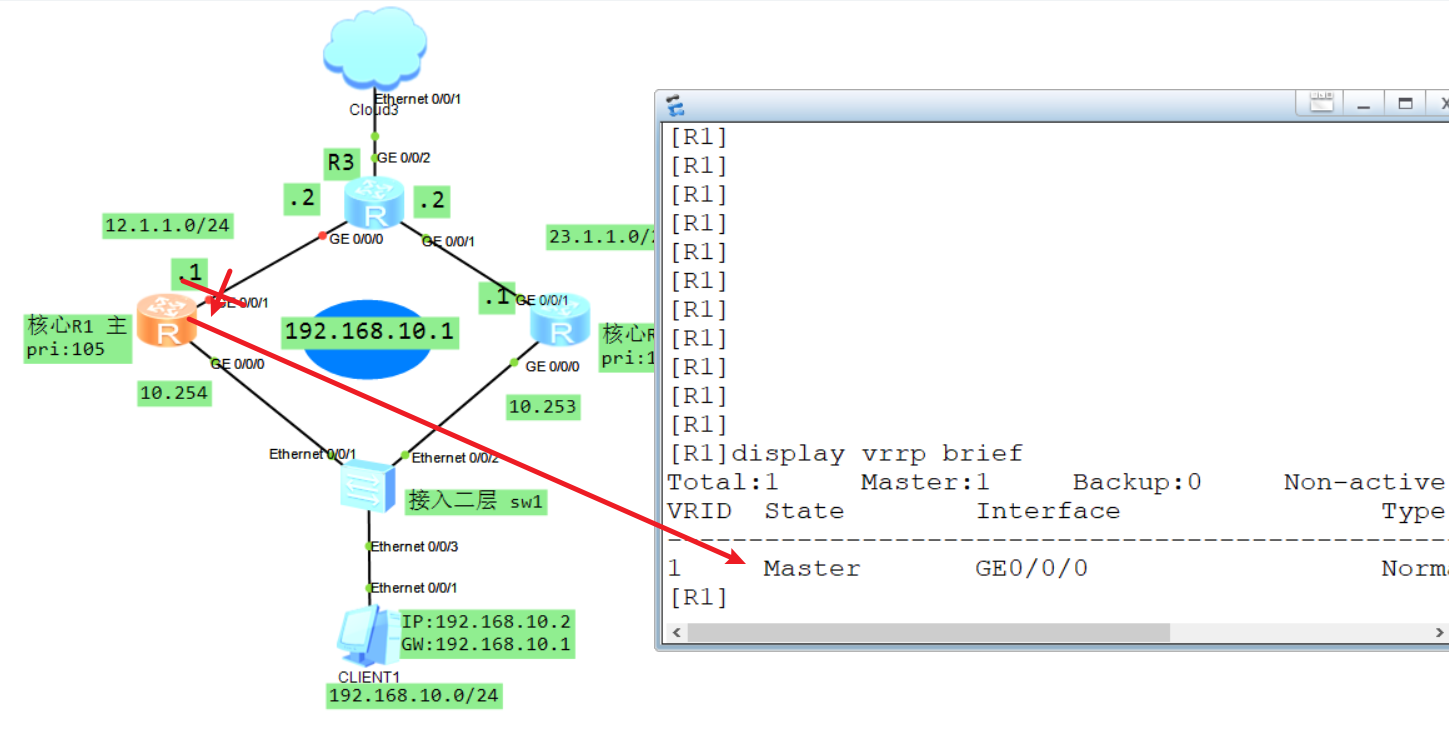
配置:
R1:
[R1-GigabitEthernet0/0/0] vrrp vrid 1 track interface GigabitEthernet 0/0/1 reduced 10
主要接口和vrid要配置正确,该命令的含义是它会最终g0/0/1接口的状态,如果它down了该vrid的优先级就会减去10,默认就是减10,这里本端优先级是105,对端使用的是默认的100,如果该接口异常,优先级减10将会比对备份的网关R2低,到时候主节点身份就会被对端抢占。
4.5.3 联动BFD
还有另外的情况就是上游如果还接了一个二成设备,导致接口发现不了异常,如下:
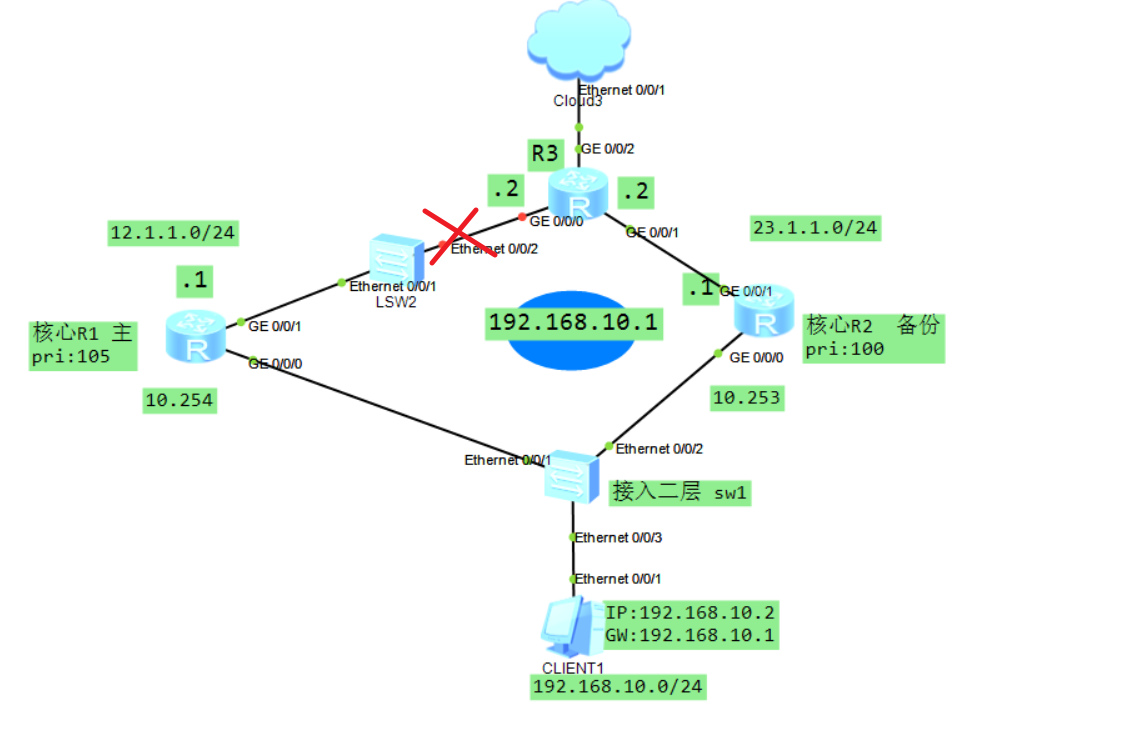
这时候就需要联动BFD,用BFD探测对端是否存活:
R1:
[R1] bfd
[R1-bfd] quit
[R1] bfd aa bind peer-ip 12.1.1.2 source-ip 12.1.1.1 auto
[R1-bfd-session-aa] commit
R3:
bfd
quit
bfd aa bind peer-ip 12.1.1.1 source-ip 12.1.1.2 auto
commit

配置之后调用它,当然也可以配置单臂回声路由,这里就配置动态BFD:
R1:
# 先把之前的 跟踪上联接口配置拿掉
[R1-GigabitEthernet0/0/0] undo vrrp vrid 1 track interface GigabitEthernet0/0/1
[R1-GigabitEthernet0/0/0]vrrp vrid 1 track bfd-session session-name aa reduced 10
测试看看,切换成功:
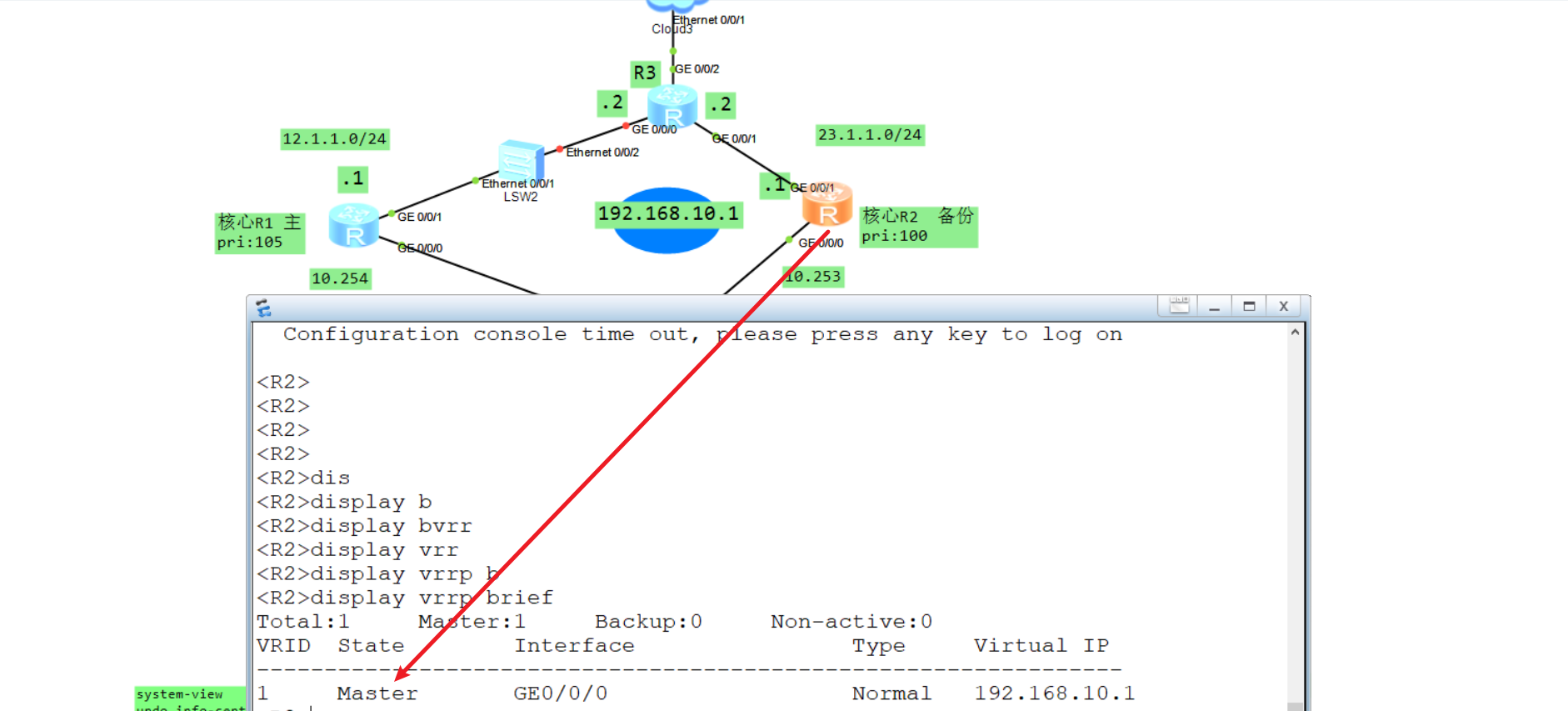
4.6 VRRP 负载分担
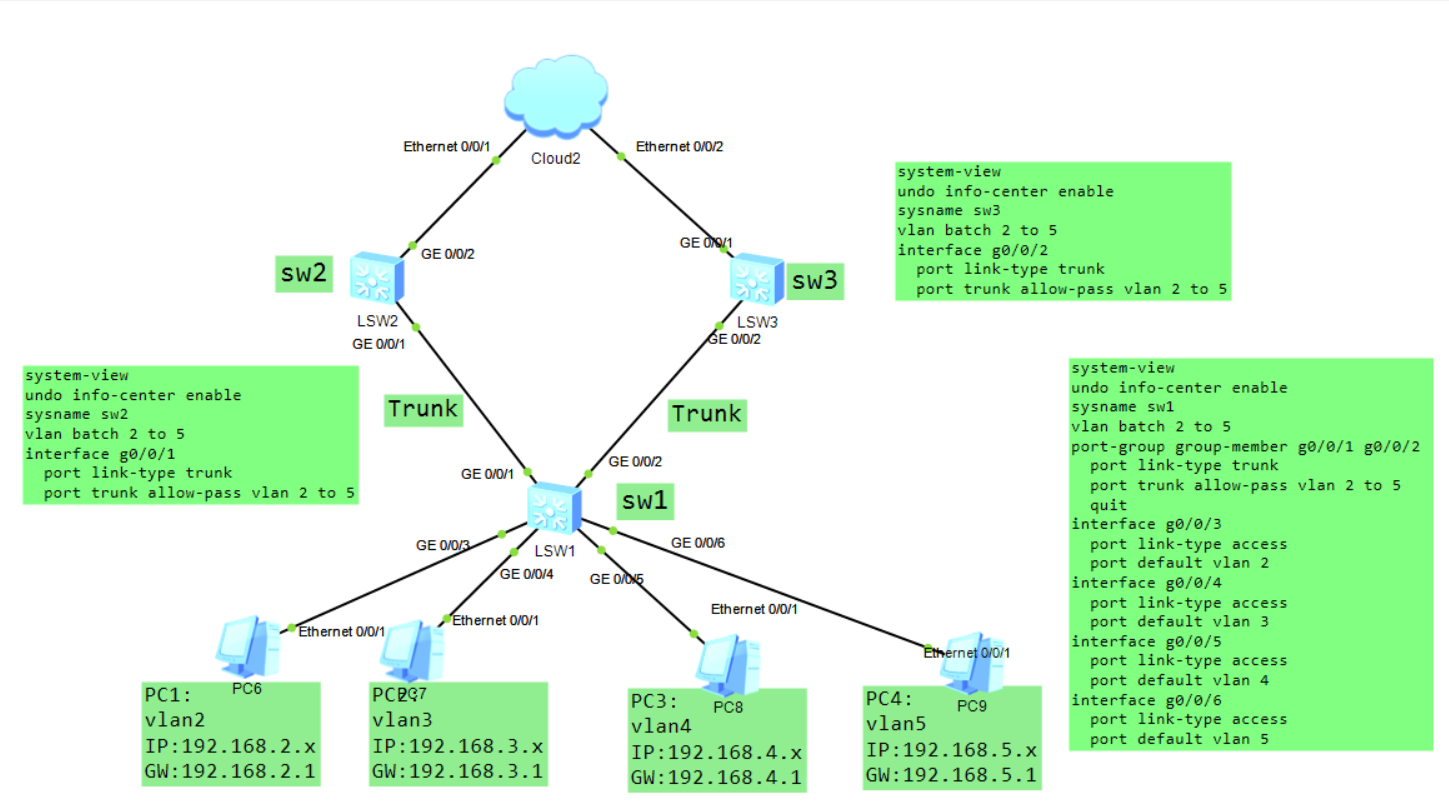
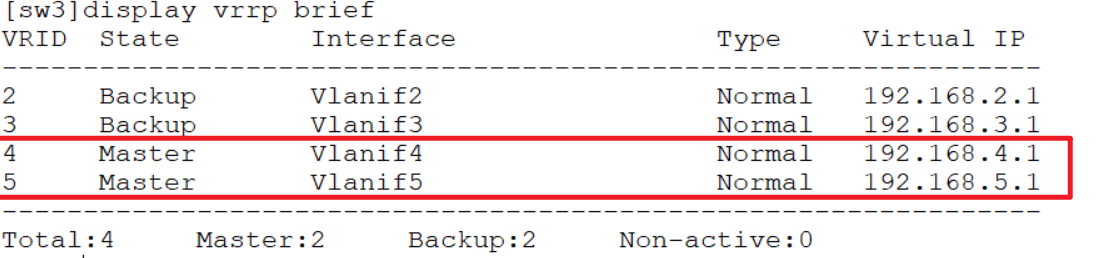
如图,先配置好vlan、trunk之后做如下配置:
sw2:
interface Vlanif 2
ip address 192.168.2.254 255.255.255.0
vrrp vrid 2 virtual-ip 192.168.2.1
vrrp vrid 2 priority 105
interface Vlanif 3
ip address 192.168.3.254 255.255.255.0
vrrp vrid 3 virtual-ip 192.168.3.1
vrrp vrid 3 priority 105
interface Vlanif 4
ip address 192.168.4.254 255.255.255.0
vrrp vrid 4 virtual-ip 192.168.4.1
interface Vlanif 5
ip address 192.168.5.254 255.255.255.0
vrrp vrid 5 virtual-ip 192.168.5.1
sw3:
interface Vlanif 2
ip address 192.168.2.253 255.255.255.0
vrrp vrid 2 virtual-ip 192.168.2.1
interface Vlanif 3
ip address 192.168.3.253 255.255.255.0
vrrp vrid 3 virtual-ip 192.168.3.1
interface Vlanif 4
ip address 192.168.4.253 255.255.255.0
vrrp vrid 4 virtual-ip 192.168.4.1
vrrp vrid 4 priority 105
interface Vlanif 5
ip address 192.168.5.253 255.255.255.0
vrrp vrid 5 virtual-ip 192.168.5.1
vrrp vrid 5 priority 105
通过这样配置就可以负载分担不同的vlan,同时如果网关异常还能快速切换。
查看: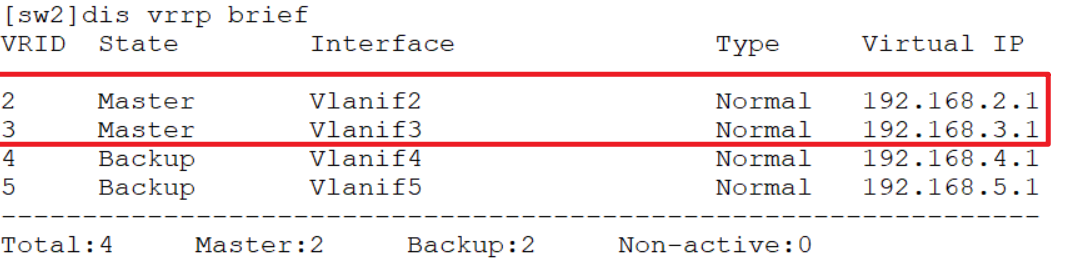
4.7 VRRP+MSTP
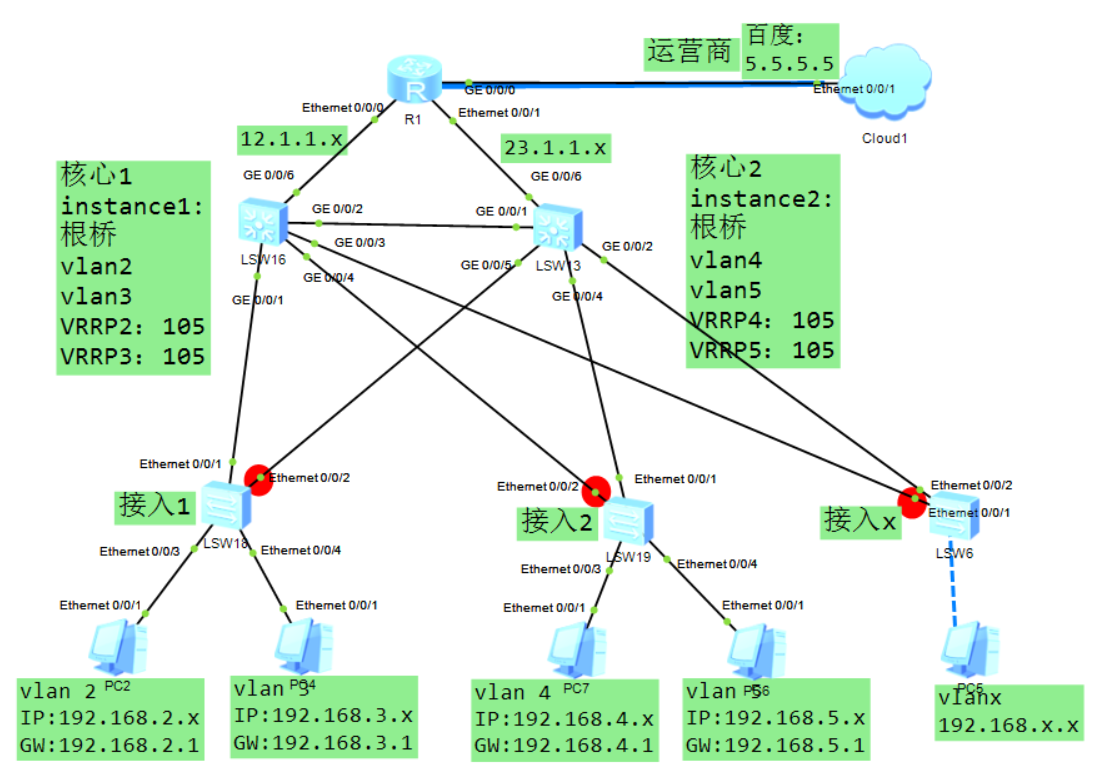
如上做好vlan、trunk,以及配置好IP(vlanif的没配):
4.7.1 MSTP配置
所有交换机(系统视图):
stp region-configuration
region-name aa
revision-level 1
instance 1 vlan 2 to 3
instance 2 vlan 4 to 5
active region-configuration
核心1交换机(系统视图):
stp instance 1 root primary
stp instance 2 root secondary
核心2交换机(系统视图):
stp instance 2 root primary
stp instance 1 root secondary
配置验证: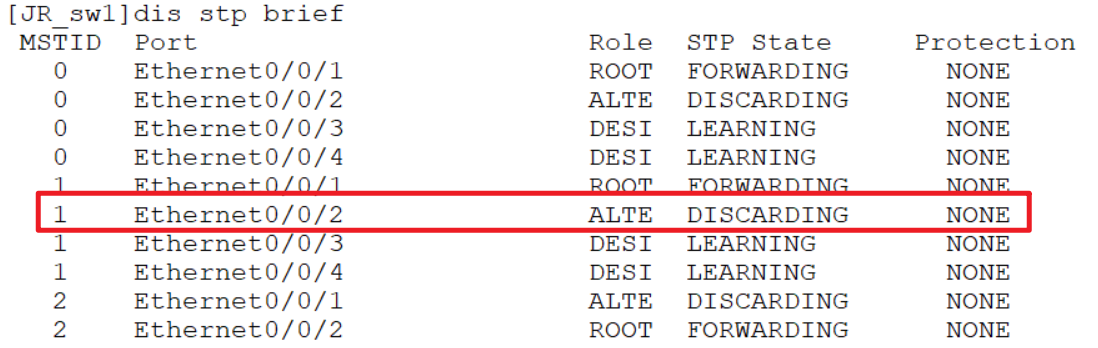
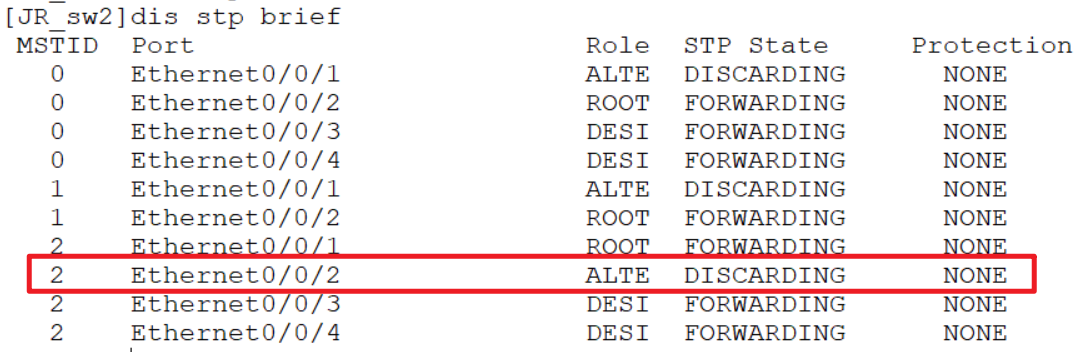
4.7.2 VRRP配置
核心sw1:
interface vlanif 2
ip address 192.168.2.254 255.255.255.0
vrrp vrid 2 virtual-ip 192.168.2.1
vrrp vrid 2 priority 105
vrrp vrid 2 track interface GigabitEthernet0/0/6
vrrp vrid 2 track interface GigabitEthernet0/0/1
interface vlanif 3
ip address 192.168.3.254 255.255.255.0
vrrp vrid 3 virtual-ip 192.168.3.1
vrrp vrid 3 priority 105
vrrp vrid 3 track interface GigabitEthernet0/0/6
vrrp vrid 3 track interface GigabitEthernet0/0/1
interface Vlanif 4
ip address 192.168.4.254 255.255.255.0
vrrp vrid 4 virtual-ip 192.168.4.1
interface Vlanif 5
ip address 192.168.5.254 255.255.255.0
vrrp vrid 5 virtual-ip 192.168.5.1
核心sw2:
interface vlanif 2
ip address 192.168.2.253 255.255.255.0
vrrp vrid 2 virtual-ip 192.168.2.1
interface vlanif 3
ip address 192.168.3.253 255.255.255.0
vrrp vrid 3 virtual-ip 192.168.3.1
interface Vlanif 4
ip address 192.168.4.253 255.255.255.0
vrrp vrid 4 virtual-ip 192.168.4.1
vrrp vrid 4 priority 105
vrrp vrid 4 track interface GigabitEthernet0/0/6
vrrp vrid 4 track interface GigabitEthernet0/0/4
interface Vlanif 5
ip address 192.168.5.253 255.255.255.0
vrrp vrid 5 virtual-ip 192.168.5.1
vrrp vrid 5 priority 105
vrrp vrid 5 track interface GigabitEthernet0/0/6
vrrp vrid 5 track interface GigabitEthernet0/0/4
配置验证:

4.7.3 配置ospf全网互通
核心sw1:
ospf 1
area 0.0.0.0
network 192.168.2.0 0.0.0.255
network 192.168.3.0 0.0.0.255
network 192.168.4.0 0.0.0.255
network 192.168.5.0 0.0.0.255
network 12.1.1.0 0.0.0.255
核心sw2:
ospf 1
area 0.0.0.0
network 192.168.2.0 0.0.0.255
network 192.168.3.0 0.0.0.255
network 192.168.4.0 0.0.0.255
network 192.168.5.0 0.0.0.255
network 23.1.1.0 0.0.0.255
路由器R1:
ospf 1
area 0.0.0.0
network 12.1.1.0 0.0.0.255
network 23.1.1.0 0.0.0.255
核心交换机再增加缺省路由:
核心sw1:
ip route-static 0.0.0.0 0.0.0.0 12.1.1.1
ip route-static 0.0.0.0 0.0.0.0 23.1.1.1 preference 65
和心sw2:
ip route-static 0.0.0.0 0.0.0.0 23.1.1.1
ip route-static 0.0.0.0 0.0.0.0 12.1.1.1 preference 65
修改开销,保证回来的路径一致,有时候网络中有安全设备的话他就会限制限制:
核心sw1(把vlanif 4、5接口的开销改大让它走核心sw2):
interface vlanif 4
ospf cost 4
interface vlanif 5
ospf cost 4
核心sw2(把vlanif 2、3接口的开销改大让它走核心sw1):
interface vlanif 2
ospf cost 4
interface vlanif 3
ospf cost 4
测试:
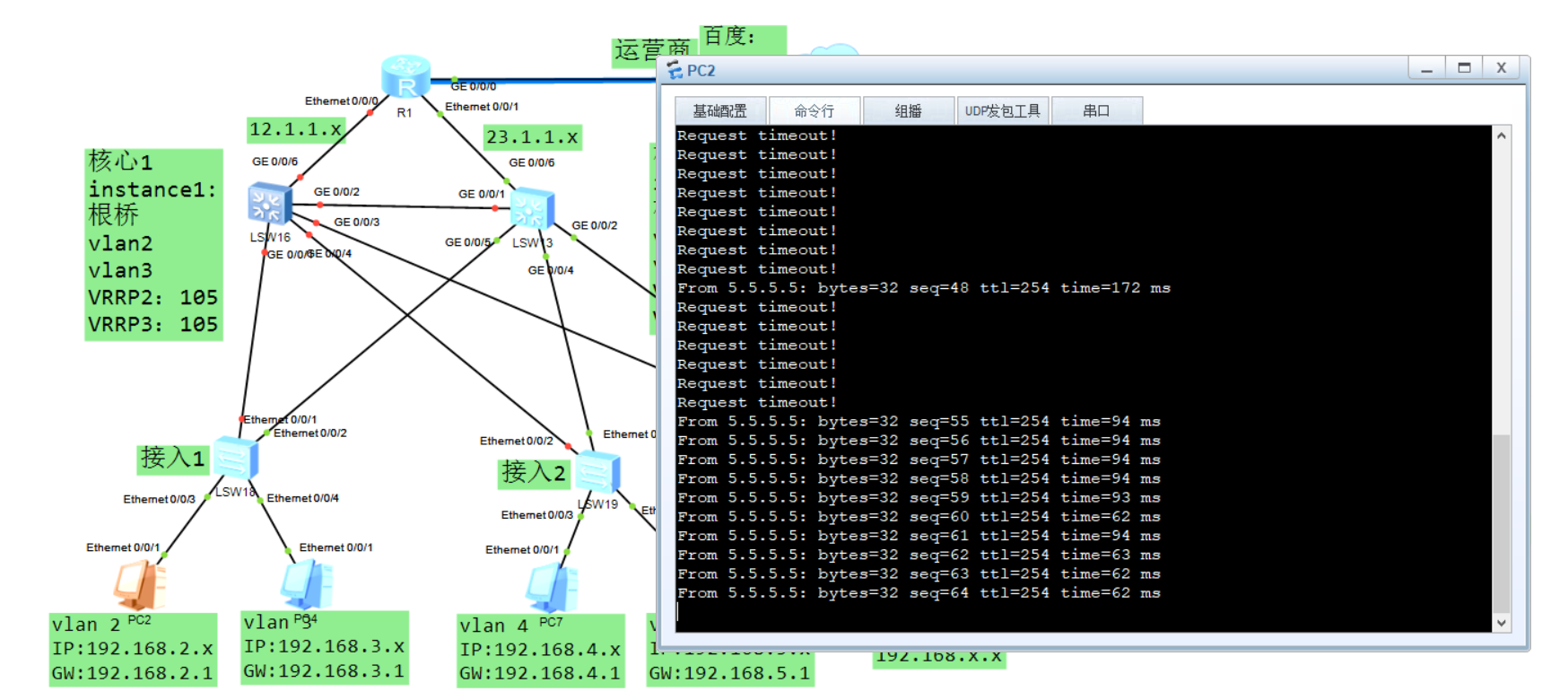
有一台交换机故障后过一会儿它会切换过去。
五、ospf
5.1 基础回顾

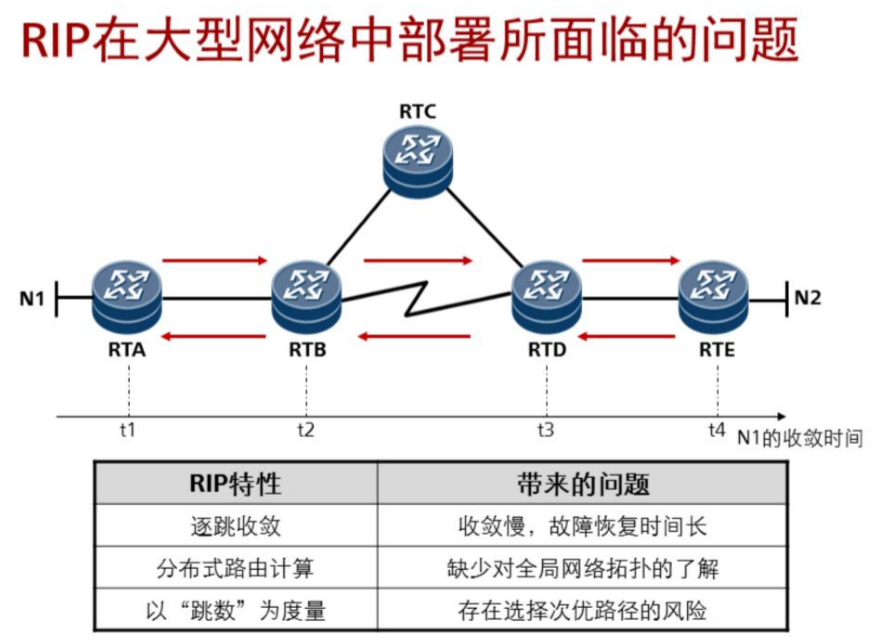
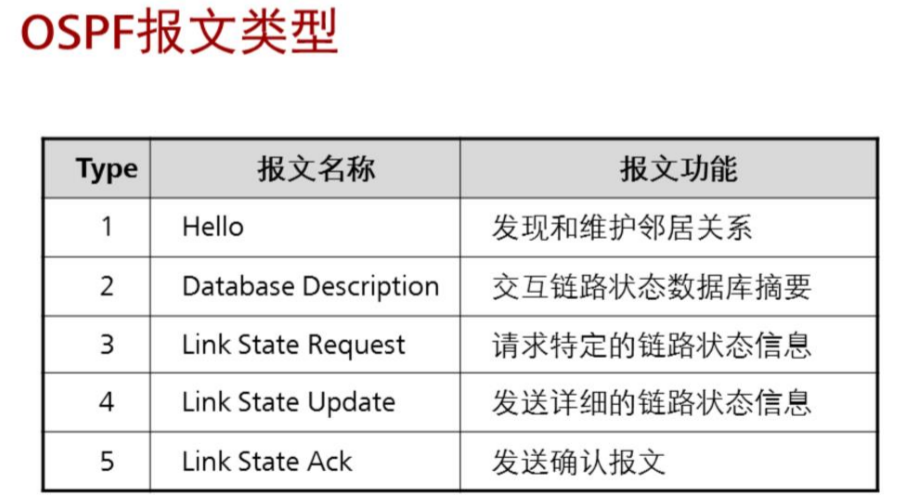
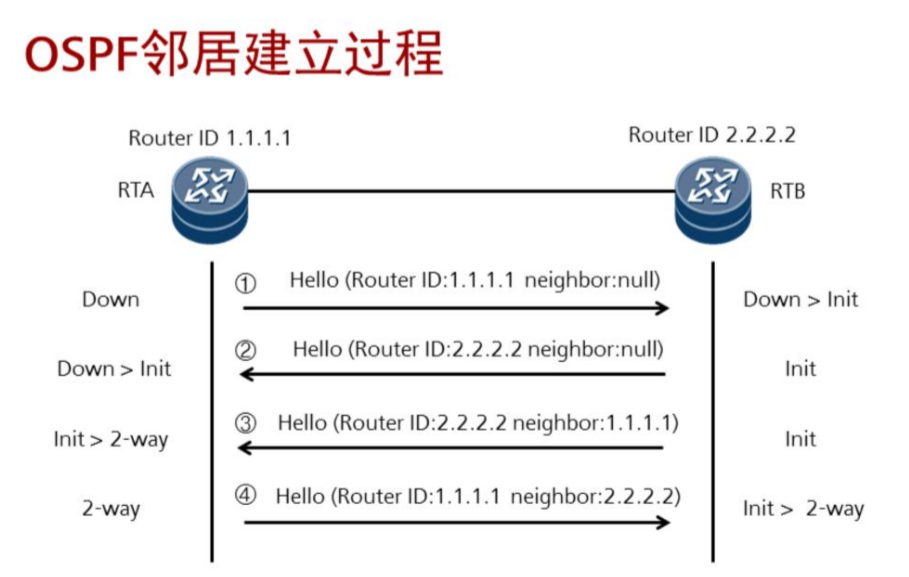
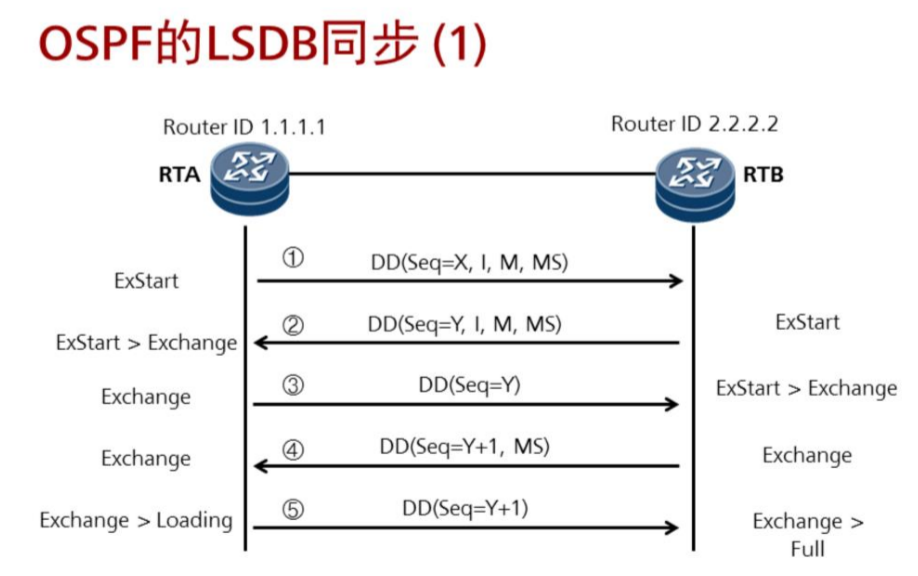
状态含义:
Down:这是邻居的初始状态,表示没有从邻居收到任何信息。
Init:在此状态下,路由器已经从邻居收到了Hello报文,但是自己的Router ID不在所收到的Hello报文的邻居列表中,表示尚未与邻居建立双向通信关系。
2-Way:在此状态下,路由器发现自己的Router ID存在于收到的Hello报文的邻居列表中,已确认可以双向通信。
ExStart:邻居状态变成此状态以后,路由器开始向邻居发送DD报文。Master/Slave关系是在此状态下形成的,初始DD序列号也是在此状态下确定的。在此状态下发送的DD报文不包含链路状态描述。
Exchange:在此状态下,路由器与邻居之间相互发送包含链路状态信息摘要的DD报文。
Loading:在此状态下,路由器与邻居之间相互发送LSR报文、LSU报文、LSAck报文。
Full:LSDB同步过程完成,路由器与邻居之间形成了完全的邻接关系。
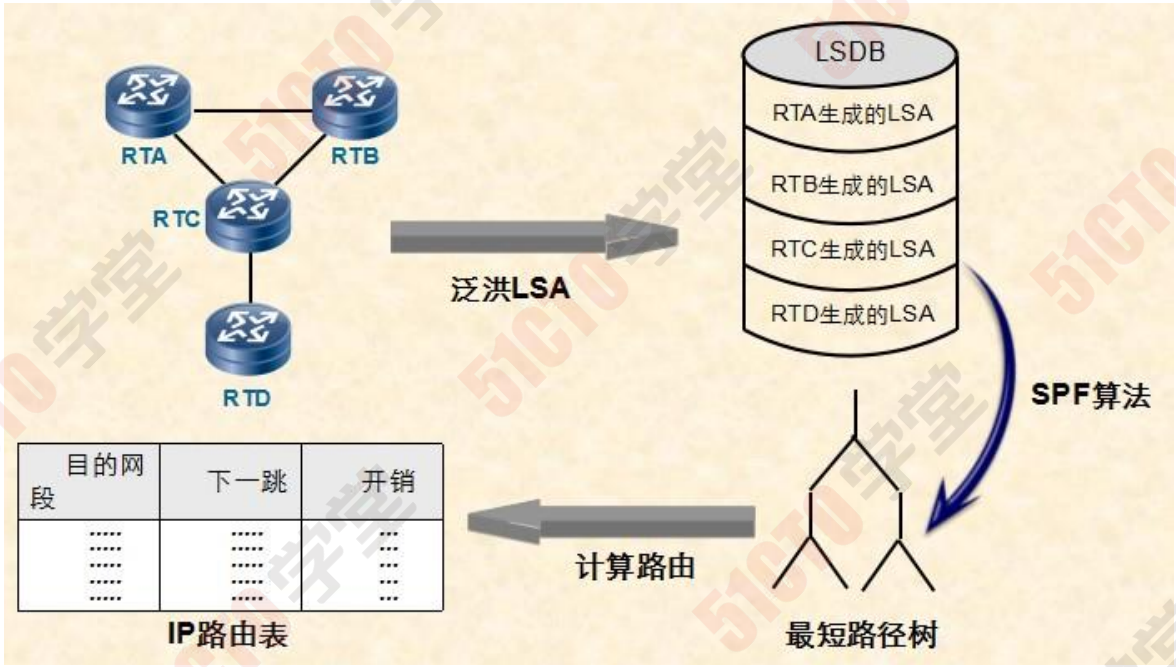
互相发送 hello报文--->邻居--->泛洪LSA(互相传递链路信息) ---->LSDB--->运行SPF算法---->生成最优路由 >路由表
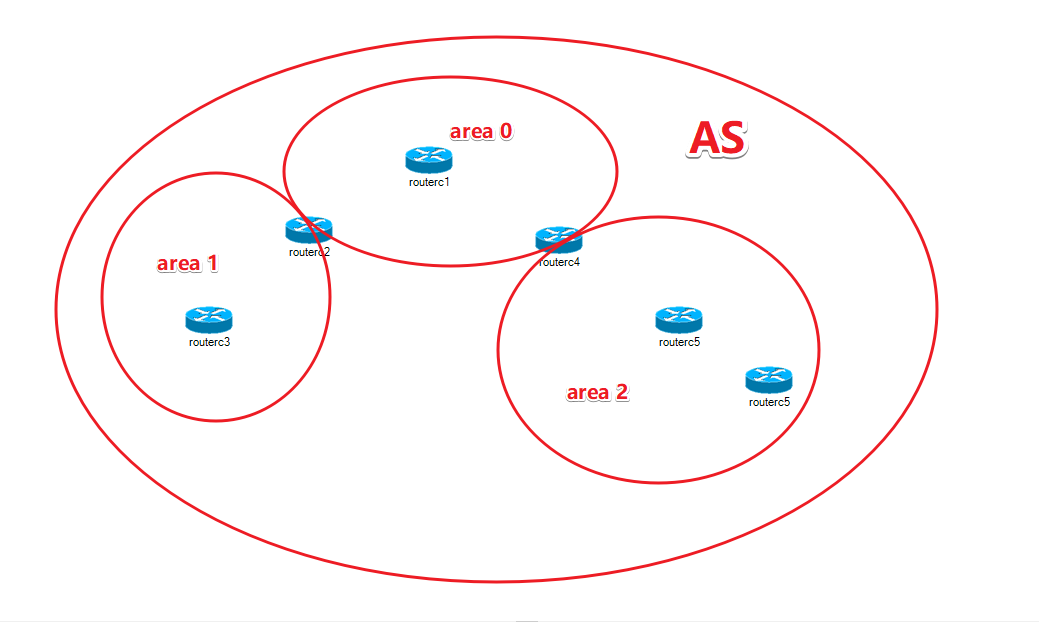
5.2 多区域OSPF
ospf 设计多区域原因:
① 每个区域的路由器只需同步自己所在区域的链路状态数据库,分区域设 计可以使得每个区域的链路状态数据库得以减少。以降低路由器cpu、内存 的消耗。
② 避免某区域内的网络故障(例如:接口频繁up down)而引发整个网络 所有路由器的路由计算,进而提升网络的稳定性。即降低area x 网络故障对 其他区域的影响。 注意:常规区域必须和骨干区域直接相连。如果常规区域没有何骨干区域直 接相连,此时需采用虚链路来将常规区域连接到骨干区域。
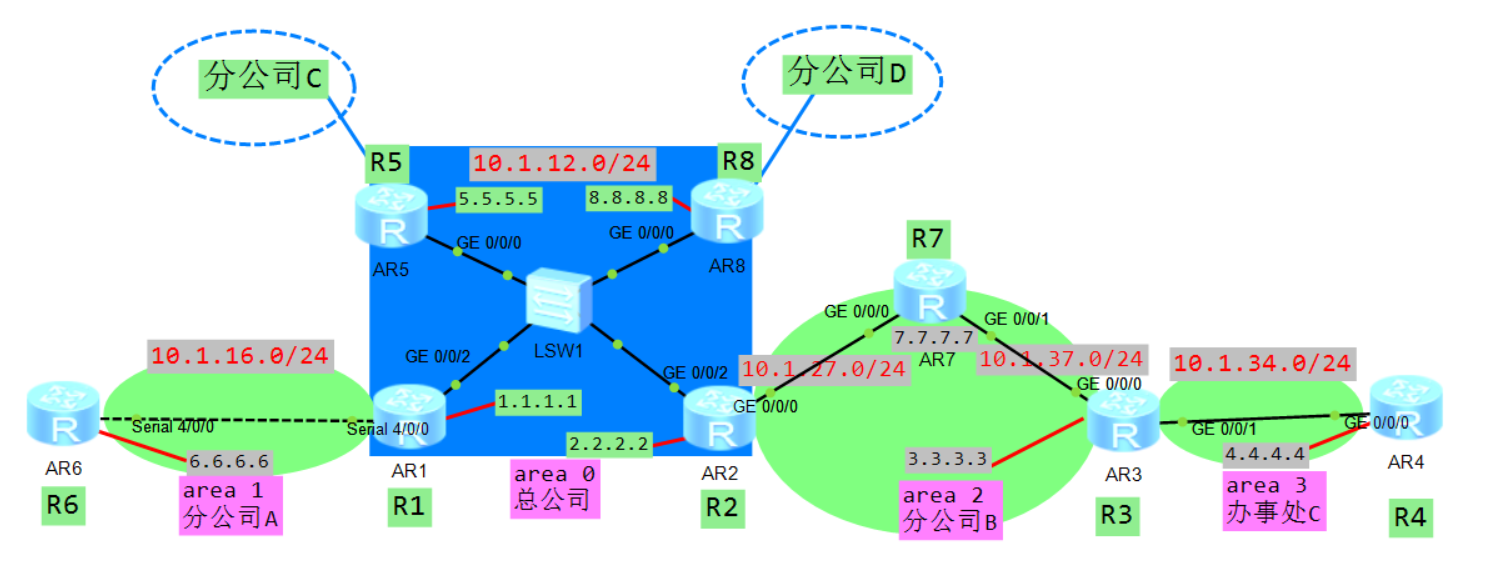
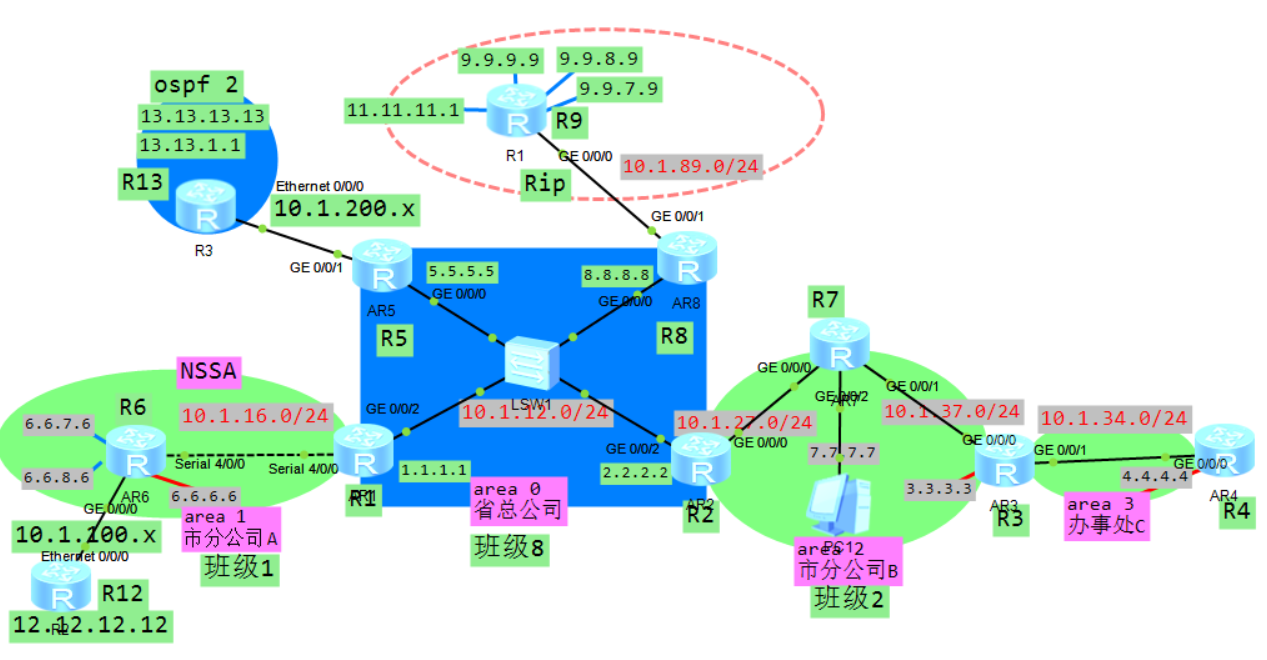
配置好IP,环回接口也要配上,然后配置ospf宣告自己的接口网段,注意区域:
R1:
ospf 1 router-id 1.1.1.1
area 0.0.0.0
network 1.1.1.1 0.0.0.0
network 10.1.12.1 0.0.0.0
area 0.0.0.1
network 10.1.16.1 0.0.0.0
R2:
ospf 1 router-id 2.2.2.2
area 0.0.0.0
network 2.2.2.2 0.0.0.0
network 10.1.12.2 0.0.0.0
area 0.0.0.2
network 10.1.27.2 0.0.0.0
R3:
ospf 1 router-id 3.3.3.3
area 0.0.0.2
network 3.3.3.3 0.0.0.0
network 10.1.37.3 0.0.0.0
area 0.0.0.3
network 10.1.34.3 0.0.0.0
R4:
ospf 1 router-id 4.4.4.4
area 0.0.0.3
network 4.4.4.4 0.0.0.0
network 10.1.34.4 0.0.0.0
R5:
ospf 1 router-id 5.5.5.5
area 0.0.0.0
network 5.5.5.5 0.0.0.0
network 10.1.12.5 0.0.0.0
R6:
ospf 1 router-id 6.6.6.6
area 0.0.0.1
network 6.6.6.6 0.0.0.0
network 10.1.16.6 0.0.0.0
R7:
ospf 1 router-id 7.7.7.7
area 0.0.0.2
network 7.7.7.7 0.0.0.0
network 10.1.27.7 0.0.0.0
network 10.1.37.7 0.0.0.0
R8:
ospf 1 router-id 8.8.8.8
area 0.0.0.0
network 8.8.8.8 0.0.0.0
network 10.1.12.8 0.0.0.0
5.3 开销计算
注意:ospf 开销计算既看“距离”也看带宽,综合评定!
cost= 沿途累加(100M/链路带宽) 100M属于默认参考带宽,串行链路的带宽:2.048Mbps 开销=48 ospf 1
bandwidth-reference 10000 将参考带宽改成10G建议所有路由器都修 改!!!
[R1-ospf-1] bandwidth-reference 10000
int gi 0/0/x (接口必须是路由进入的方向) ospf cost 55 手动修改链路的开销影响选路
[R1-GigabitEthernet0/0/2] ospf cost 55
5.4 ospf 虚链路
ABR:area boundary router 区域边界路由器
ASBR: autonomous system boundary router 自治系统边界路由器
router id :代表运行ospf 路由器的身份ID “路由器的身份证号”。仅 在ospf 进程刚启动的时候选举出来,选出后则不再改变,除非重启ospf 进 程。
<R2> reset ospf process
注意:虚链路属于骨干区域的延伸。属于骨干区域的一部分。
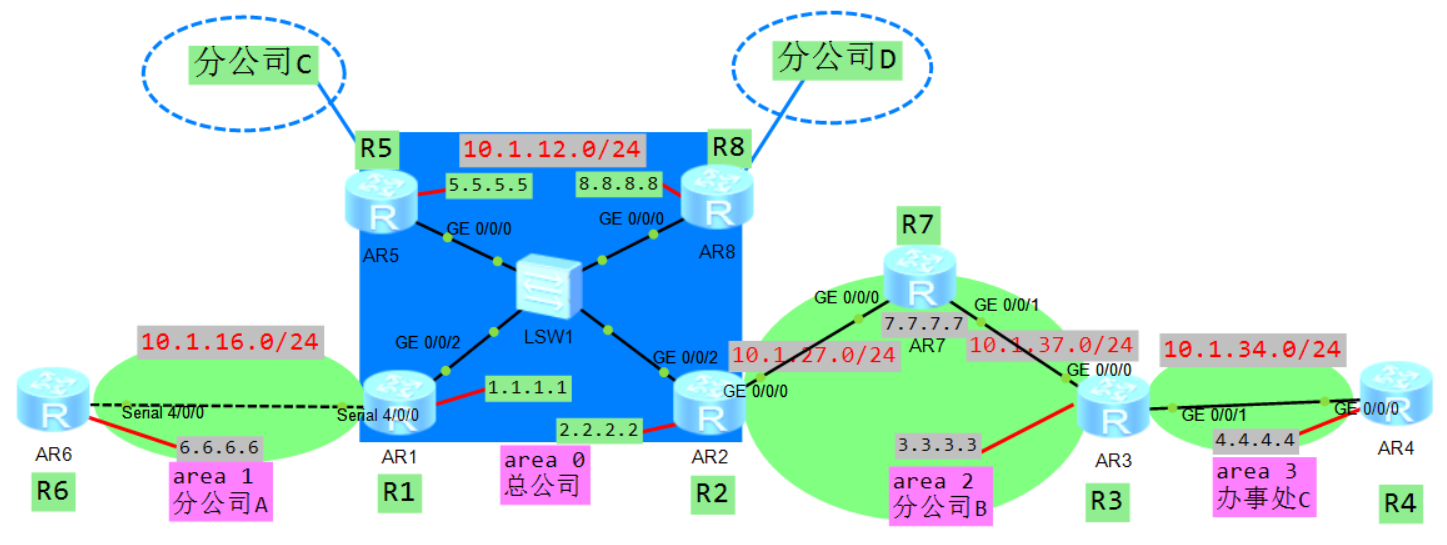
这里配置虚链路area0链接到area3:
R2:
[R2] ospf 1
[R2-ospf-1] area 2
[R2-ospf-1-area-0.0.0.2] vlink-peer 3.3.3.3
3.3.3.3是对方路由器的router id
R3:
[R3] ospf 1
[R3-ospf-1] area 2
[R3-ospf-1-area-0.0.0.2] vlink-peer 2.2.2.2
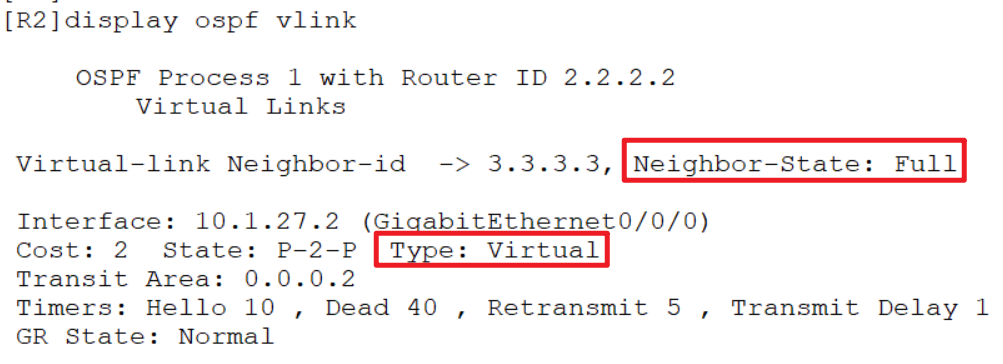
查看:
display ospf vlink
5.5 ospf 邻居建立过程
互相发送hello报文--->邻居--->泛洪LSA(互相传递链路信息) ---->LSDB--->运行SPF算法---->生成最优路由 >路由表
ospf的五种数据包:

info-center enable 打开信息中心 显示日志报文 reset ospf process:
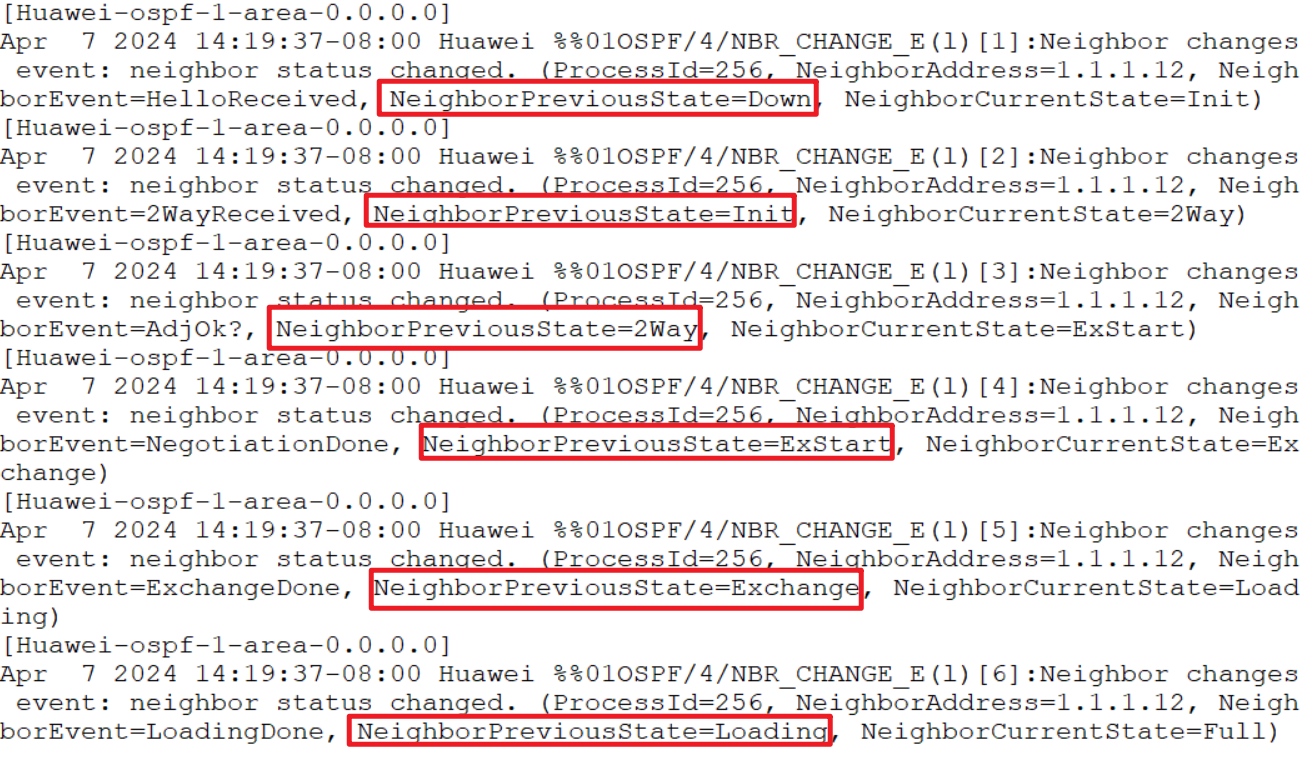
邻接:链路状态数据同步 Full邻居:进展到 2-way
邻居关系建立状态:
Init :初始化状态 准备建立邻居
two-way:互相得知对方的router id 等信息(互相认识)
exstart:准备开始交互链路信息(ospf 隐式确认机制,确定主 从关系)
exchange:正式交互链路信息
loading:确认链路信息交互 full :完全同步
loading:确认链路信息交互 full :完全同步
邻居建立条件:
① 直连通信
② network 宣告网段
③ 认证通过
④ area id 一致
⑤ hello dead 时间一致
⑥ Option Ebit位 Nbit位 一致(stub、 nssa 区域)
⑦ 掩码一致(针对多路访问网络)
⑧ 静默端口
⑨ MTU(思科检查,华为不检查)
⑩ 版本一致
11 router id 不能冲突
注意:MTU 包含在DD报文里面的。
OSPF的特殊区域有STUB和NSSA,分别对应如下的情况:
STUB区域:E 比特位= 0 Nbit=0
NSSA区域:E 比特位= 0 N比特位=1

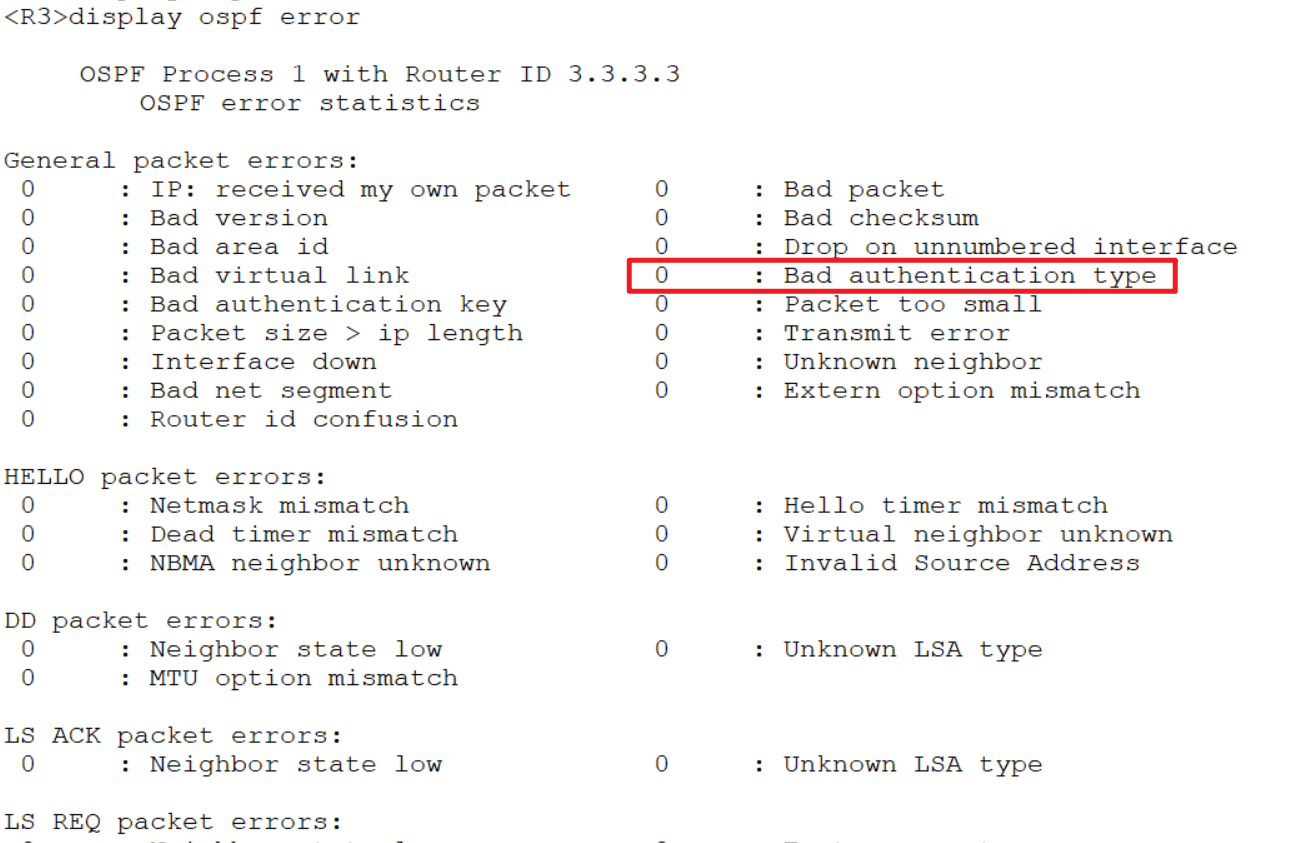
查看ospf是否有错误:
display ospf error
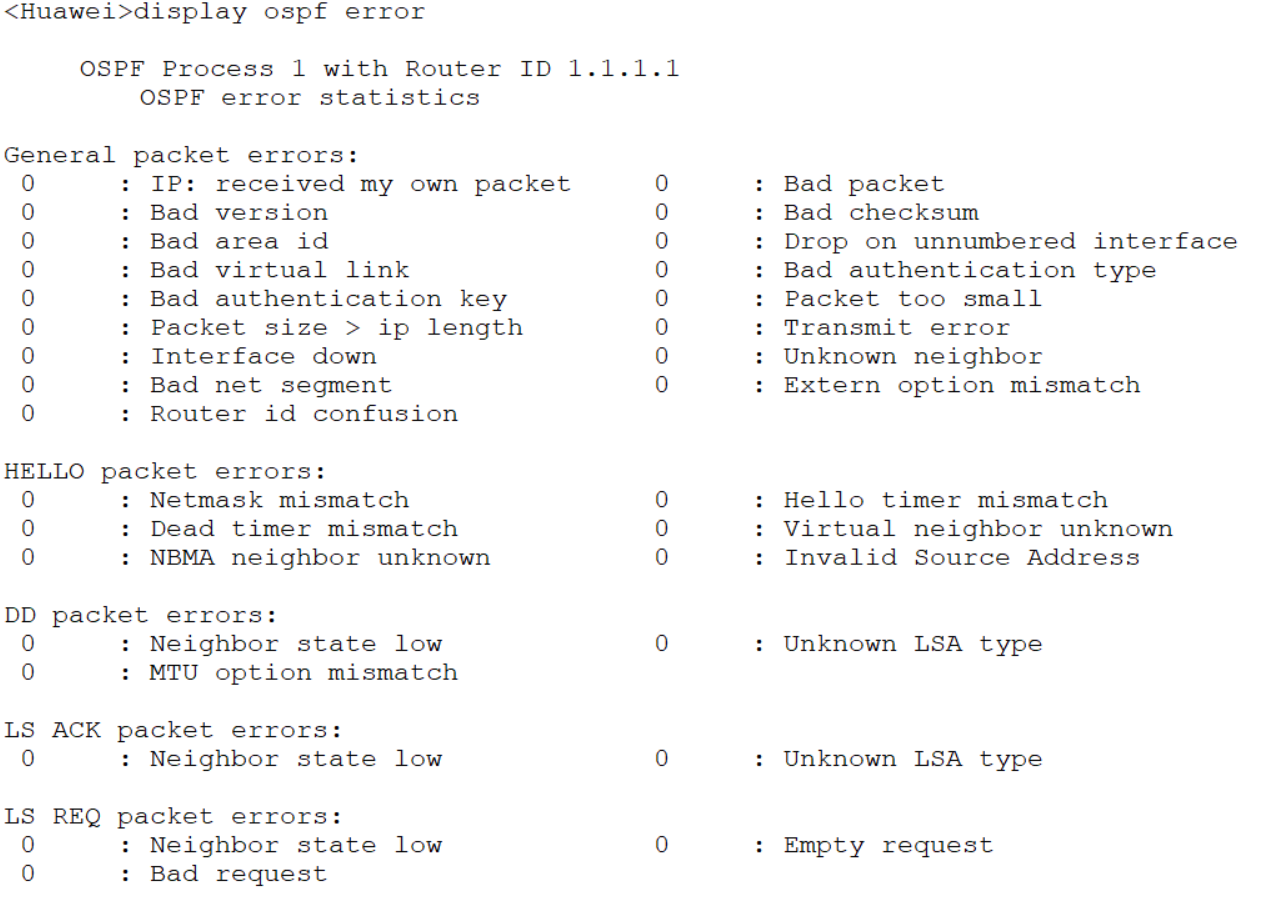
重置ospf error 计数
reset ospf counters
5.6 DR和BDR
DR:designate router 指定路由器 (班长)
BDR:backup DR 备份指定路由器 (副班长)
目的:减少重复LSA报文的发送,减少邻接关系的建立,提升 ospf协议报文的传输效率,降低网络资源的消耗。
注意:DR和BDR的选举仅在多路访问环境才会选举。在点到点的环境不选举DR和BDR。
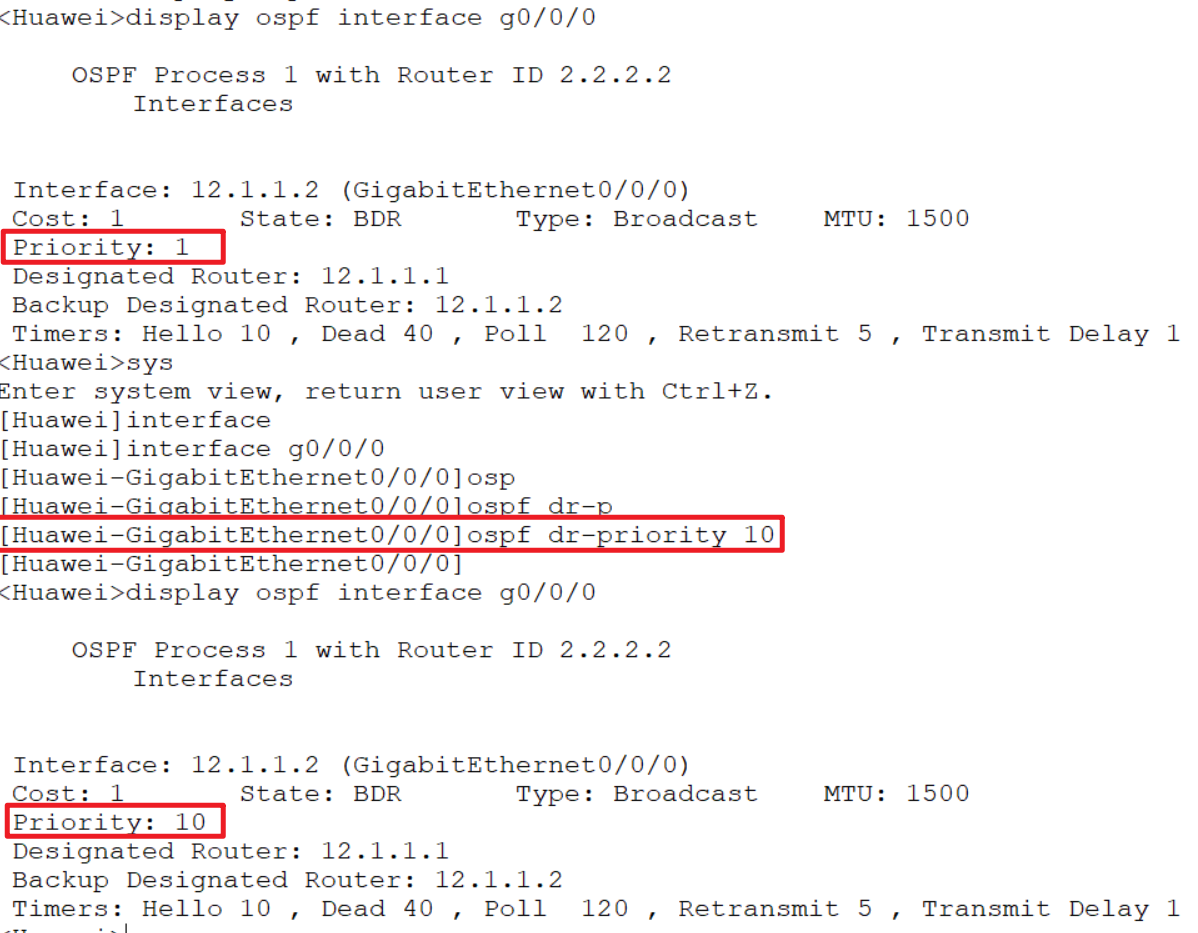
手动配置接口的网络类
型选举规则:
① 接口优先级 + rouer-id,越大越优先。默认ospf接口优 先级都是1。
② 优先级为0 表示不参与DR和BDR的选举
③ 遵循不抢占原则。
修改优先级:
int gi 0/0/x
ospf dr-priority 10
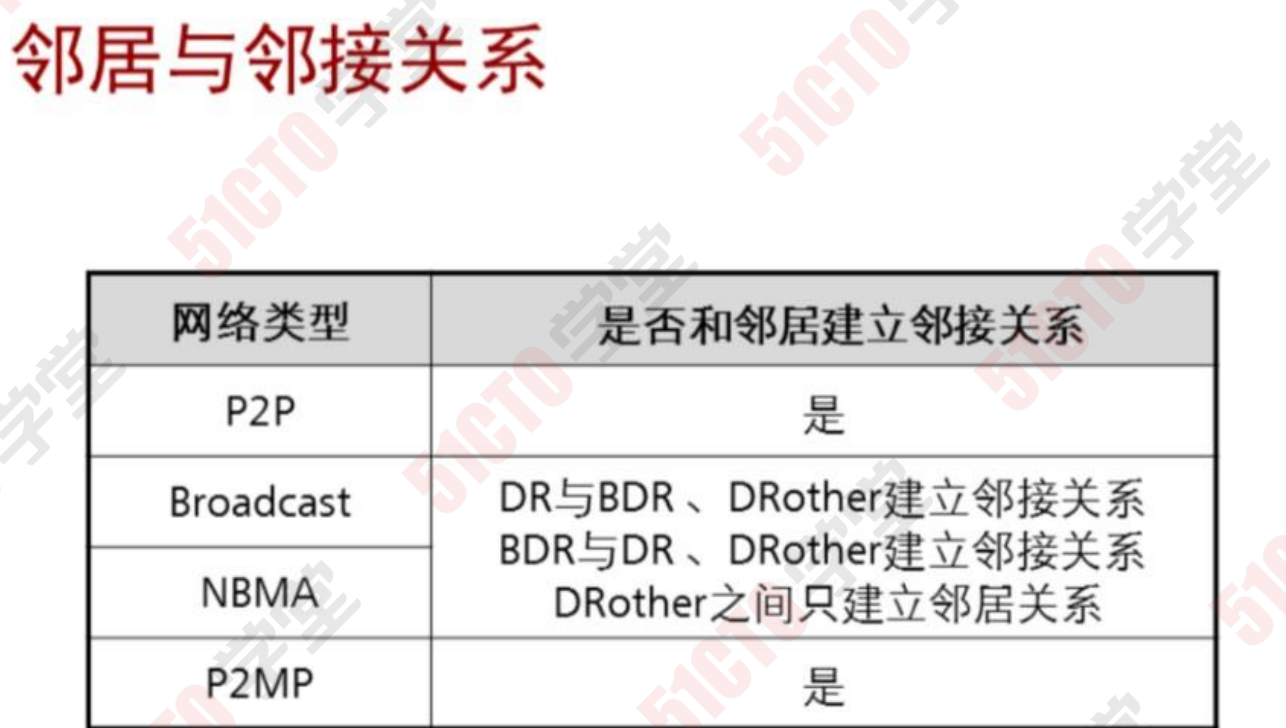
邻居(Neighbor)关系与邻接(Adjacency)关系是两个不同的概念。
OSPF路由器之间建立邻居关系后,进行LSDB同步,最终形成邻接关系。
在广播型网络及NBMA网络上,DRother之间只能建立邻居关系,不能建 立邻接关系,DRother 与DR/BDR路由器之间会建立邻接关系,DR与BDR 之间也会建立邻接关系。
注意1:在broadcast型网络里面默认所有路由器发送hello报文的目标地址 93 都是:224.0.0.5。
注意2:DR other 发送(LSU LsACK)目标地址是224.0.0.6 DR BDR 发送(LSU LsACK)目标地址是224.0.0.5
5.7 路由引入
R8:
ip route-static 11.11.11.0 255.255.255.0 10.1.89.9
rip 1
version 2
network 10.0.0.0
R9:
rip 1
version 2
network 10.0.0.0
network 9.0.0.0
ospf 路由种类:
ospf :ospf 普通的路由
o_ASE :ospf 自制系统外部路由
o_NSSA:ospf 特殊区域的路由
O_ASE:外部路由的种类:autonomous system external
a : type 2 (默认种类),cost值始终1 不累加
b :type 1 ,cost 沿途累加
使用ospf 引入缺省路由:
ospf 1
default-route-advertise always 动态下发缺省路由
在 ASBR :
R8:
ospf 1
import-route rip 1 #将rip 1 的路由引入ospf 区域
rip 1
import-route ospf 1 #将ospf 区域的路由全部引入rip 区
5.8 OSPF LSA
lsa:link state advertise 链路状态宣告 ,封装在LSU里面
三元组:LS type,Link State ID和Advertising Router的组合 共同标识一条LSA。
三张表:
邻居表:dis ospf peer brief 95
拓扑表(链路状态数据库):dis ospf lsdb
路由表:dis ip routing-table
Type1型LSA:
router lsa 每个路由器都可以发出仅在自己area 区域 发送 通告自身链路状态信息(自报家门)
调试: dis ospf lsdb dis ospf lsdb router
注意1:Advrouter (advertised router )总是代表宣告该 lsa的路由器的router id
LinkState ID :不同类型的lsa代表的意义不一样。
注意2:一型 LSA linkstate ID 代表 路由器的router id。

Type2型LSA:
Network lsa只有DR可以发出
仅在自己area区域发送
通告DR的位置和身份以及本广播域的所有成员及链路信息
注意:二型 LSA linkstate ID 代表 DR的接口IP地址
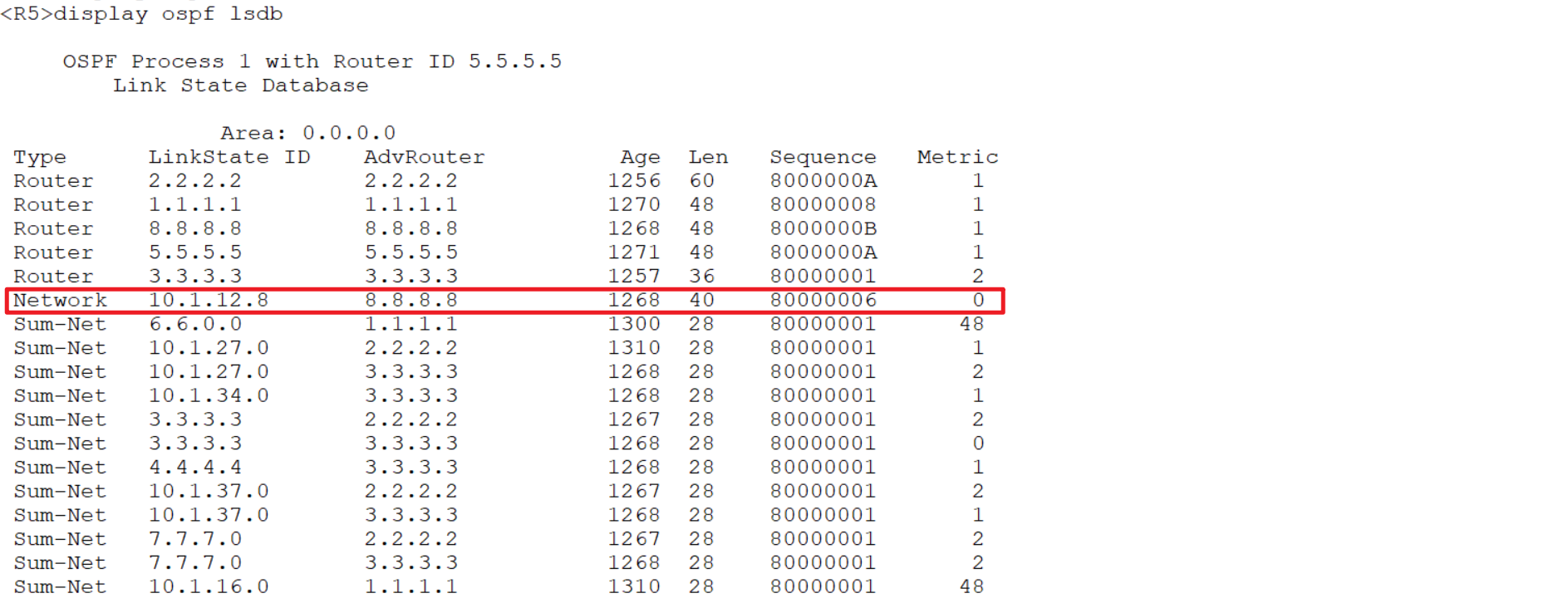
Type3型LSA:
network-summary lsa
只能由ABR发送(类似班级的辅导员)
可以穿越整个ospf自制系统(中间需要各个ABR中转)将不同区 域的ospf 路由信息互相传递
注意:三型 LSA linkstate ID 代表网段路由信息。
Type4型LSA:asbr lsa
只能由各ABR发送
发送范围整个ospf自制系统通告ASBR的身份和位置信息
注意:四型 LSA linkstate ID 代表ASBR的router id。
Type5型LSA:
External lsa ASBR发出
发送范围整个ospf自制系统引入其他自制系统的路由信息
注意:五型 LSA linkstate ID 代表其他自制系统的路由信息。
Type7LSA:
nssa lsa 由位于nssa区域的ASBR产生
发送范围仅仅是nssa区域(传至abr时会转换成5型继续传递)作用是将nssa区域后的自制系统外部路由引入ospf自制系统
ospf 路由种类:
ospf :1、2 3型lsa
O_ASE: 靠5型和 4型 产生 该路由 (O_ASE:ospf_AS_External)
O_NSSA :7型LSA External :外部的
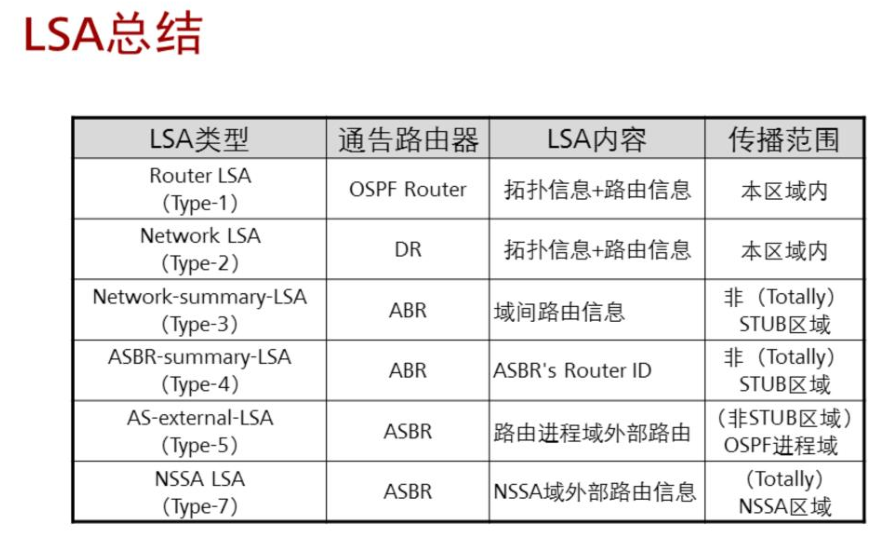

Adv rtr:产生此LSA 的ABR路由器的Router ID。
Metric:ABR到达目的网段的开销值。
注意1:一条三型LSA只能描述一条路由信息。
注意2:三型LSA只传递路由信息,并未传递原始的拓扑信息。
ospf 区域内的防环:SPF算法
ospf 区域间的防环:① 骨干区域和非骨干区域的拓扑设计 (只有一个骨干区域,非骨干区域必须直接和骨干区域相连) ② 三类LSA的传递规则(从骨干区域传递到非骨干区域的三类 LSA,不能回传到骨干区域。
5.9 路由汇总
4-12 OSPF 路由汇总路由汇总作用:
① 减小路由表的大小,提高路由的查找速度,降低路由器资 源的开销。
② 避免明细路由频繁down up 影响范围过大,进而避免路由 震荡。提升网络的稳定性。
注意:ospf 的路由汇总只能汇总路由信息,无法汇总链路拓扑 信息。
ospf 区域间的汇总:只能在ABR上面进行配置
ospf 1 area 0.0.0.1 abr-summary 6.6.0.0 255.255.240.0
自制系统间的汇总:只能在ASBR上面配置
ospf 1 asbr-summary 9.9.0.0 255.255.240.0
5.10 OSPF特殊区域(优化技术)
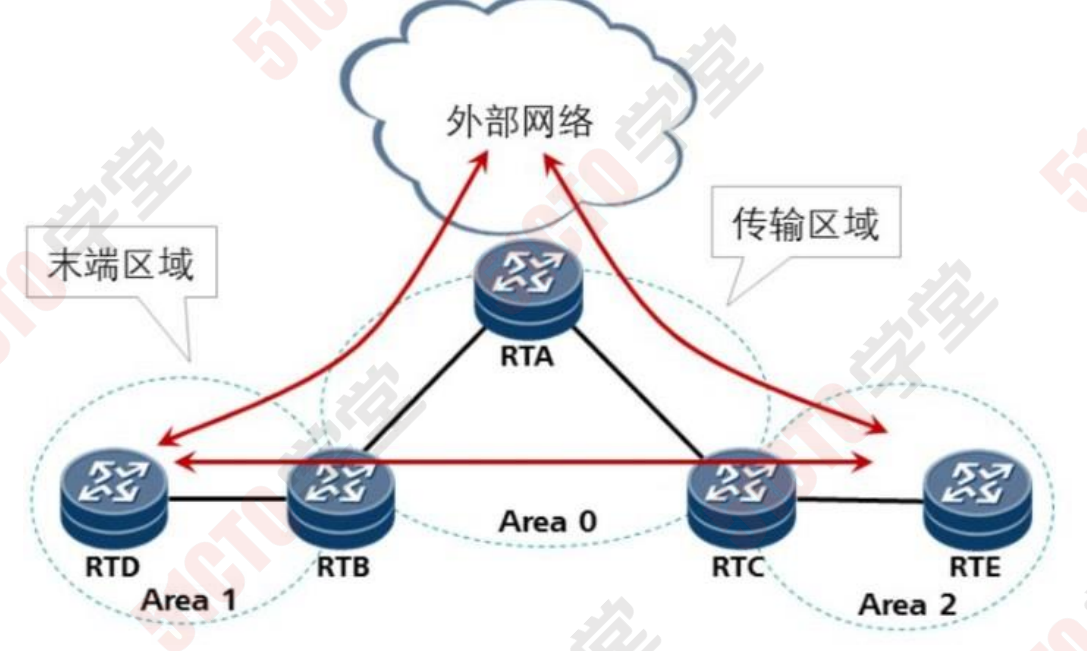
作用:
① 减小末节区域LSDB规模以及路由表大小,降低边缘路由器 资源开销(内存 cpu等)
② 减少其他自制系统或区域网络变化对末节区域的影响,减 少路由震荡提升网络的稳定性。
特殊区域:
5.10.1 stub区域
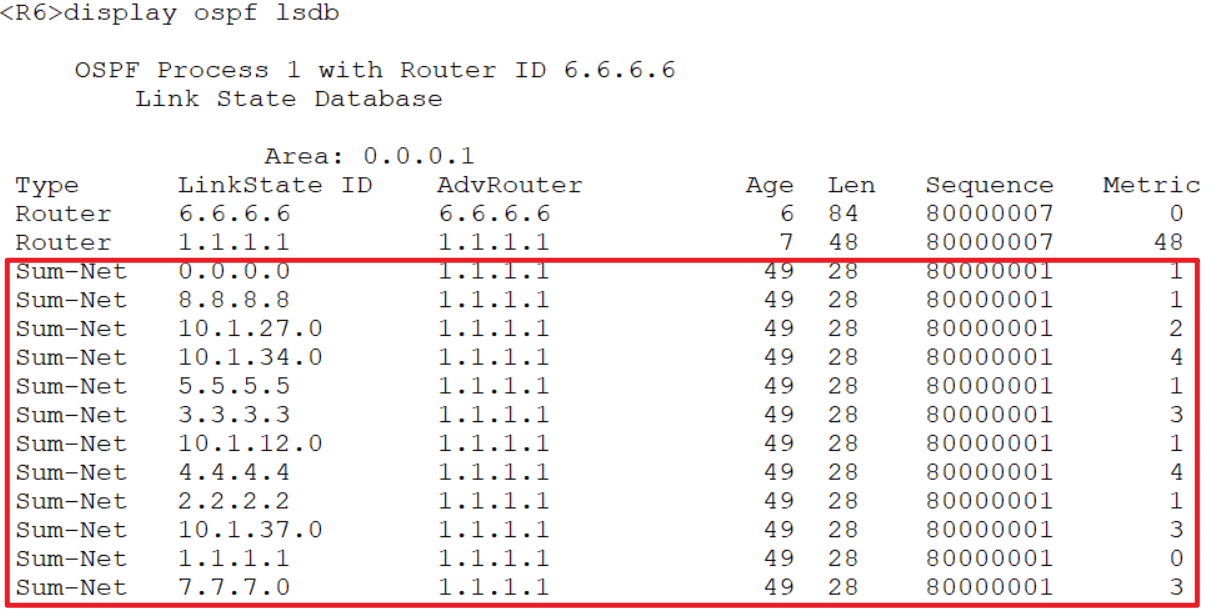
stub :末节区域 不接收四、五型的lsa
工作原理:不接收4、5型LSA,同时自动形成指向中间路由 器 ABR的缺省路由。
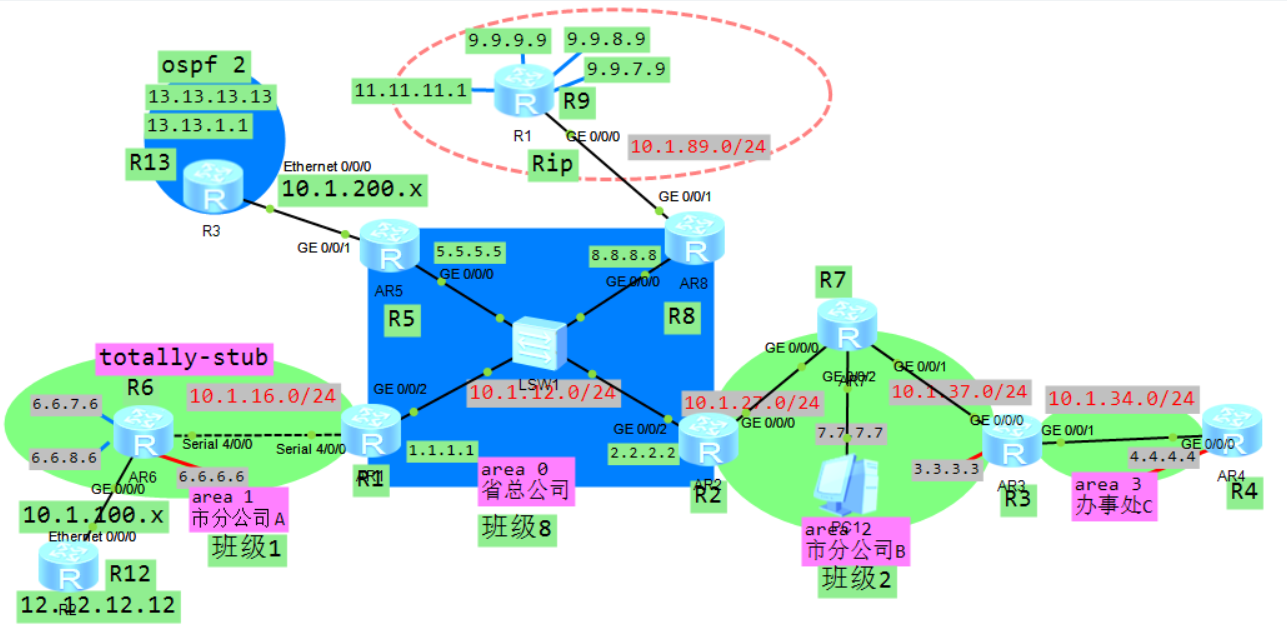
R1 R6: 将区域1 配置为stub区域 stub
ospf 1
area 1
stub
注意1:area 0 不能配置为stub区域。
注意2:虚链路属于骨干区域的延伸,虚链路所在的区域不能 配置为stub区域。
注意3:stub区域内不存在ASBR
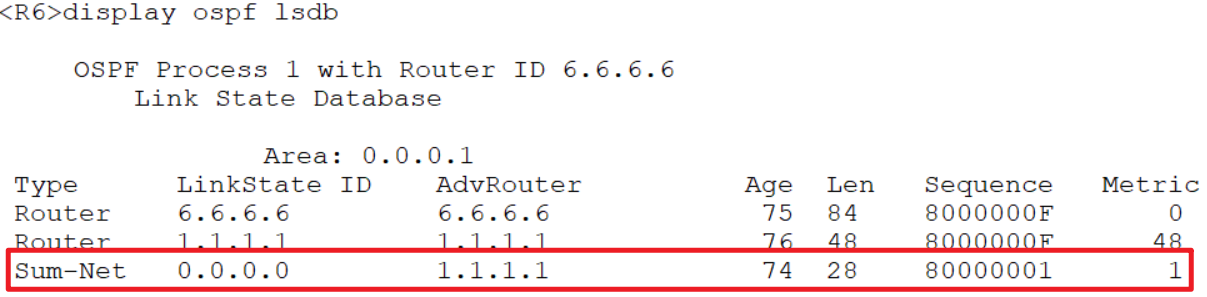
5.10.2 totally-stub 区域
totally-stub 完全末节区域:追加关键字no-summary ,不接 收三、四、五 型的LSA
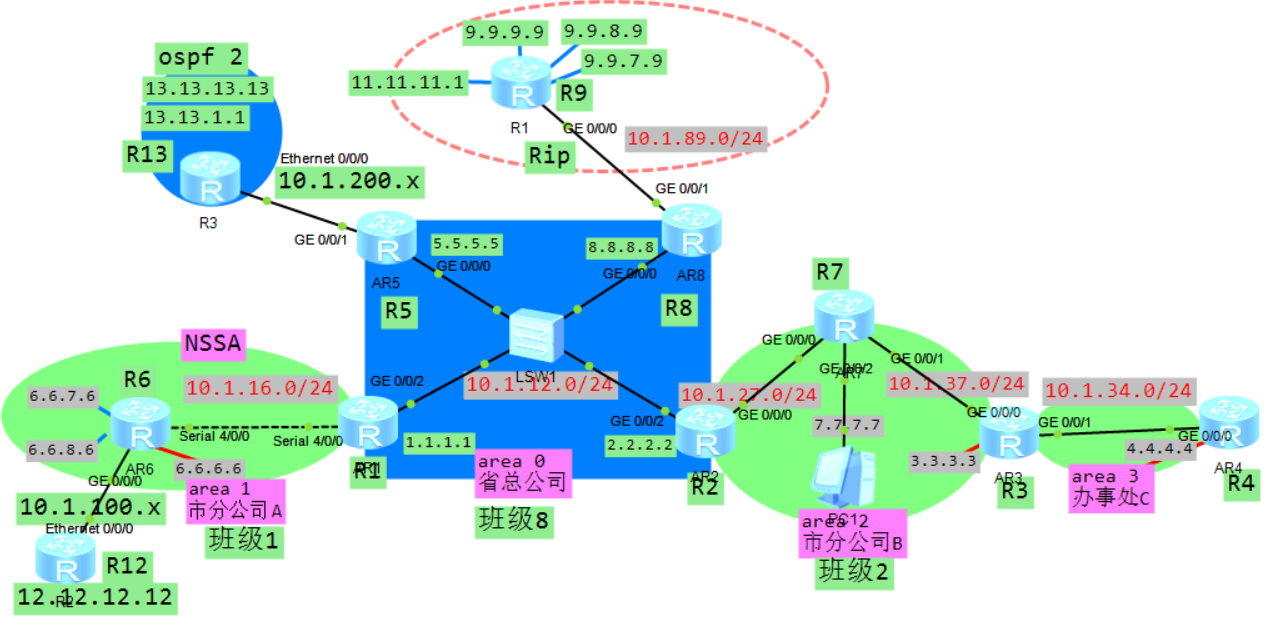
R1 R6:
ospf 1
area 1
stub no-summary
5.11 NSSA 区域 (not so stub area):
不完全末端区域
R1 R6:
ospf 1
area 1
nssa
特点:不接收4、5型lsa,但是同时可以产生7型的lsa。
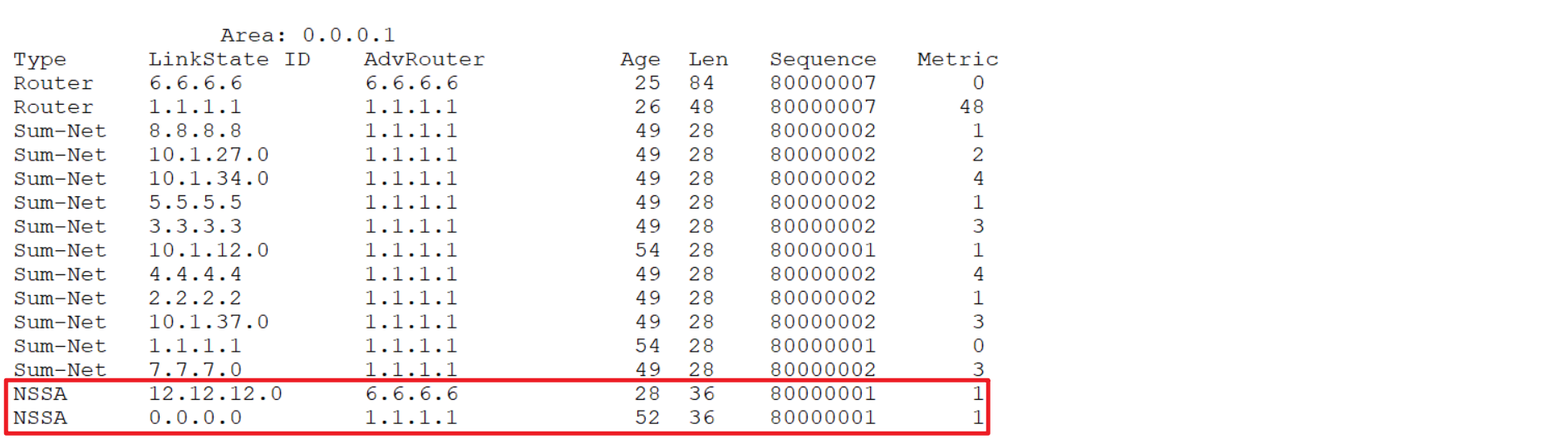
5.12 totally-nssa
totally-nssa:加关键字no-summary 可以过滤掉3 4 5 的LSA
ospf 1
area 1
nssa no-summary
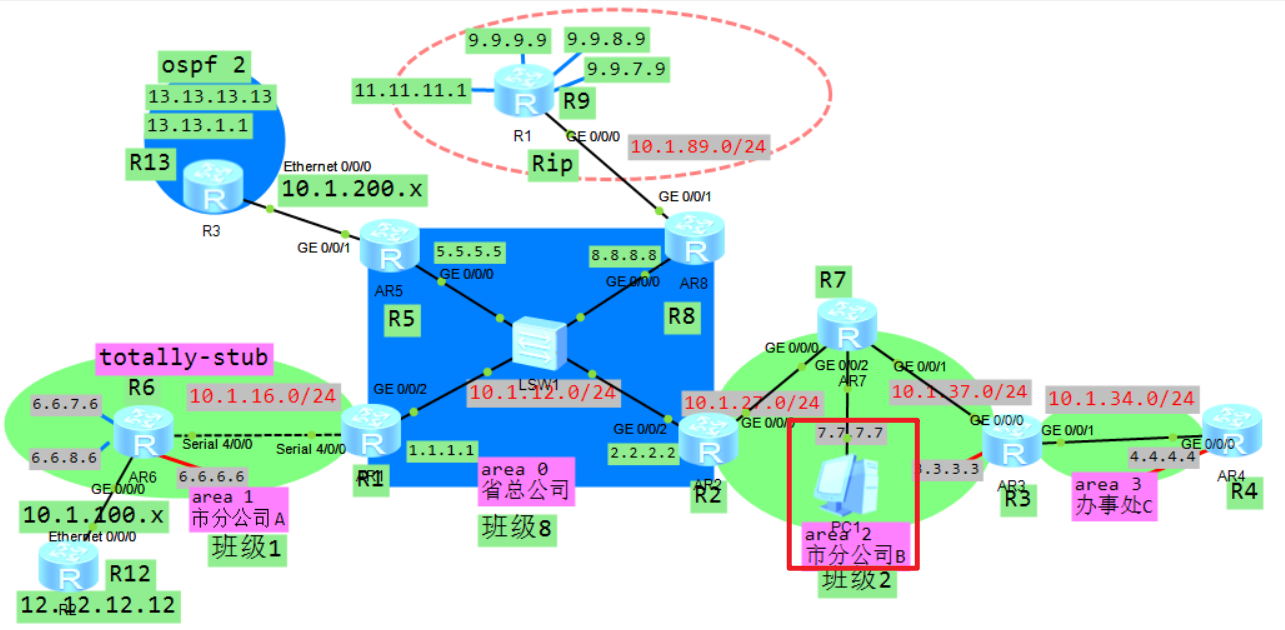
5.11 OSPF静默接口
ospf 1
silent-interface GigabitEthernet0/0/0
将gi0/0/0 配置为静 默接口 注意:路由器不会从静默接口向外发送任何ospf 相关报文。如下,有可能路由器上接了二层设备或者PC的时候它不需要接受OSPF报文的时候就可以设置。
5.12 OSPF
R3:
interface GigabitEthernet0/0/1
ospf authentication-mode md5 1 cipher Abc123456
R4:
interface GigabitEthernet0/0/0
ospf authentication-mode md5 1 cipher Abc123456
如果认证不成功可以通过查看错误信息知道:
如果设备多个接口同属于一个area可以通过以下方法同时配置多个接口:
ospf 1
area 0.0.0.2
authentication-mode md5 1 cipher abc123 #将位于area 2 里面的所有接口全部开启认证
5.13 OSPF路由过滤
ospf 1
filter-policy 2000 import
acl number 2000
rule 5 deny source 2.2.2.2 0
rule 10 permit 105
注意:由于ospf 传递的是链路信息,因此filter-policy import指令只能阻止链路信息进入路由表。 LSA会继续传递给其邻居!!
ospf 1
import-route rip 1 route-policy aa
route-policy aa permit node 10
if-match acl 2005
acl number 2005
rule 5 deny source 9.9.8.0 0.0.0.255
rule 10 permit
5.14 前缀列表
acl 既能用于ip报文的过滤(包过滤),也能用于路由信息的 匹配,但用于匹配路由时仅能匹配路由前缀无法匹配掩码。 前缀列表能同时匹配前缀和掩码长度但仅能用于路由信息的 过滤,不能用于ip报文的过滤(包过滤)。
5.13 ospf 多进程
ospf 多进程:
a 进程号本台路由器有效
b 两台路由器,进程号不同可以建立邻居并传递路由
c 同一台路由器,不同的ospf 进程默认不能互串路由,多个进程独立运行,互不干扰
d 默认的ospf 进程是1
六、VRF
6.1 概念
VRF(Virtual Routing Forwarding)VPN路由转发表也称VPN-instance(VPN实例),是PE为直接相连的site建立并维护的一个专门实体,每个site在PE上都有自己的VPN-instance,每个VPN-instance包含到一个或多个与该PE直接相连的CE的路由和转发表,另外如果要实现同一VPN各个Site间的互通,该VPN-instance还就应该包含连接在其他PE上的发出该VPN的Site的路由信息。(简单的理解就是一个网络中运行多张网)。
6.2 基础配置
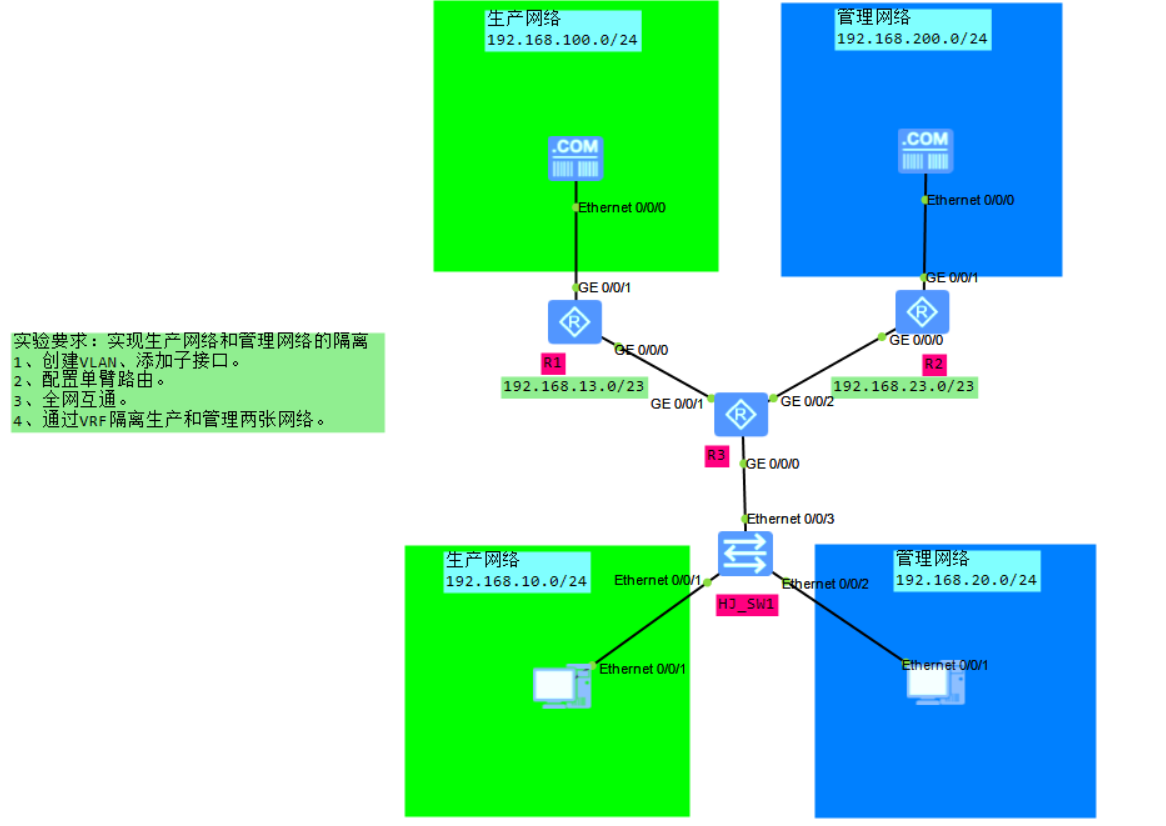
基础配置:
HJ_SW1:
system-view
sysname HJ_SW1
undo info-center enable
vlan batch 10 20
interface Ethernet 0/0/3
port link-type trunk
port trunk allow-pass vlan 10 20
interface Ethernet 0/0/1
port link-type access
port default vlan 10
interface Ethernet 0/0/2
port link-type access
port default vlan 20
R3:
system-view
sysname R3
undo info-center enable
interface GigabitEthernet 0/0/0.10
dot1q termination vid 10
ip address 192.168.10.1 24
arp broadcast enable
interface GigabitEthernet 0/0/0.20
dot1q termination vid 20
ip address 192.168.20.1 24
arp broadcast enable
interface GigabitEthernet 0/0/1
ip address 192.168.13.3 24
interface GigabitEthernet 0/0/2
ip address 192.168.23.3 24
R1:
system-view
sysname R1
undo info-center enable
interface GigabitEthernet 0/0/0
ip address 192.168.13.1 24
interface GigabitEthernet 0/0/1
ip address 192.168.100.1 24
R2:
system-view
sysname R3
undo info-center enable
interface GigabitEthernet 0/0/0.10
dot1q termination vid 10
ip address 192.168.10.1 24
arp broadcast enable
interface GigabitEthernet 0/0/0.20
dot1q termination vid 20
ip address 192.168.20.1 24
arp broadcast enable
interface GigabitEthernet 0/0/1
ip address 192.168.13.3 24
interface GigabitEthernet 0/0/2
ip address 192.168.23.3 24
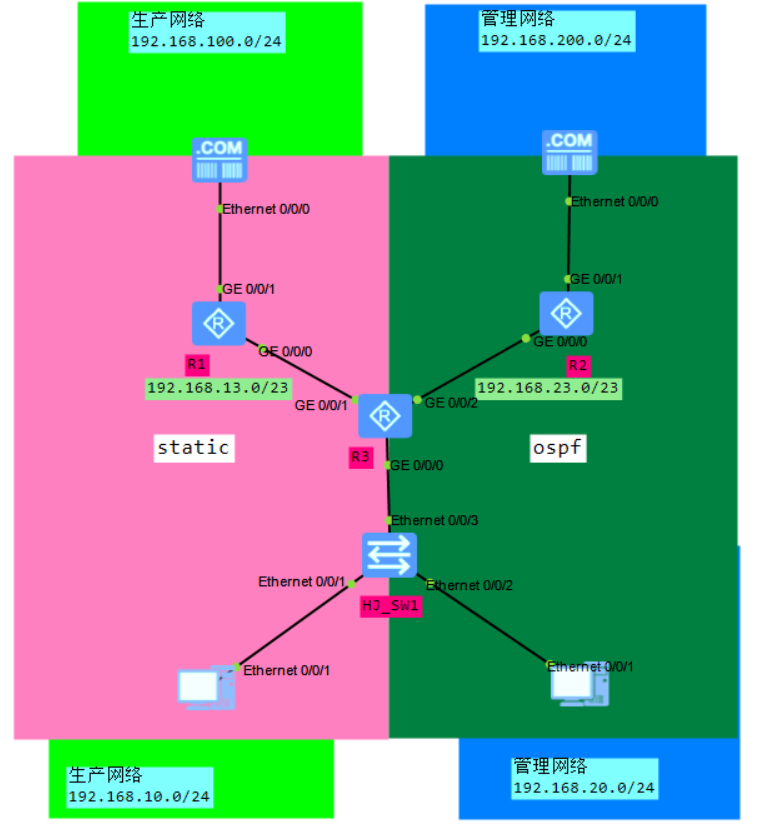
6.3 VRF配置
R3:
创建VRF(vpn实例):
ip vpn-instance shengchan
ipv4-family
q
q
ip vpn-instance guanli
ipv4-family
q
q
将接口加入到vpn实例(配置之前先查看接口ip,该配置会删除ip):
interface GigabitEthernet0/0/0.10
ip binding vpn-instance shengchan
ip address 192.168.10.1 24
interface GigabitEthernet0/0/1
ip binding vpn-instance shengchan
ip address 192.168.13.3 24
interface GigabitEthernet0/0/0.20
ip binding vpn-instance guanli
ip address 192.168.20.1 24
interface GigabitEthernet0/0/2
ip binding vpn-instance guanli
ip address 192.168.23.3 24
ip binding vpn-instance shengchan #这条命令会把该接口加入到上面创建的shengchan这个vpn实例,它会把ip地址的配置删掉,需要重新配置回来
6.4 配置路由
这里路由使用什么路由协议都不影响,我们选择左边用static,右边用ospf。
做完以上配置在公共路由表中是看不到直连路由的,要在小路由表中才能看见。
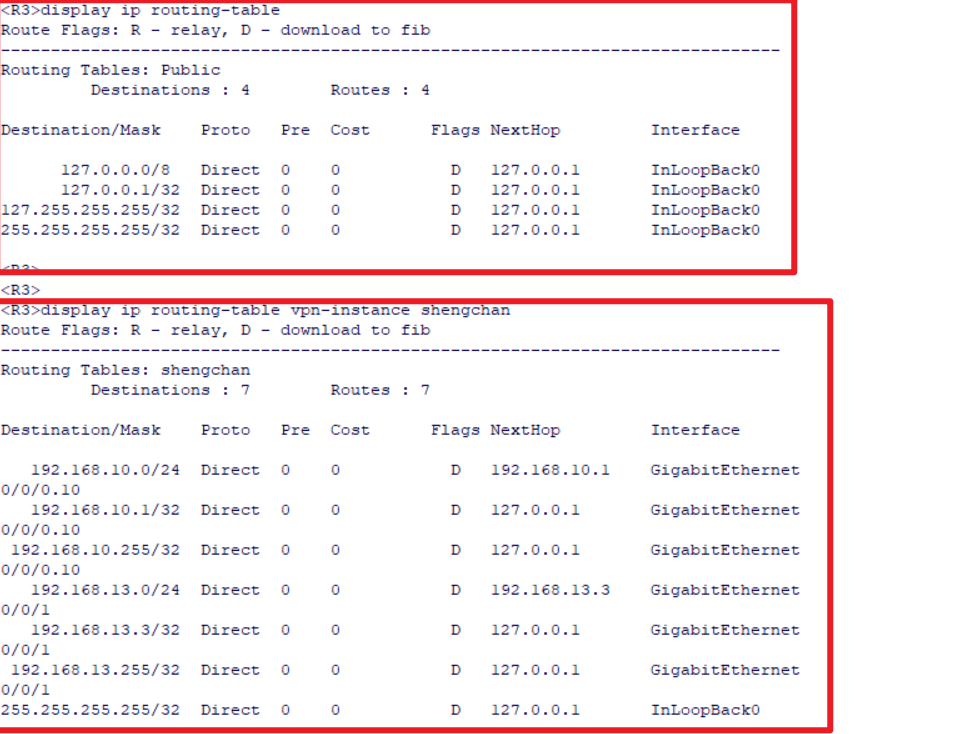
而且因为没有路由,连直连都ping不通,要制定实例ping, 如:
ping -vpn-instance shengchan 192.168.13.1
生产网配置:
R3:
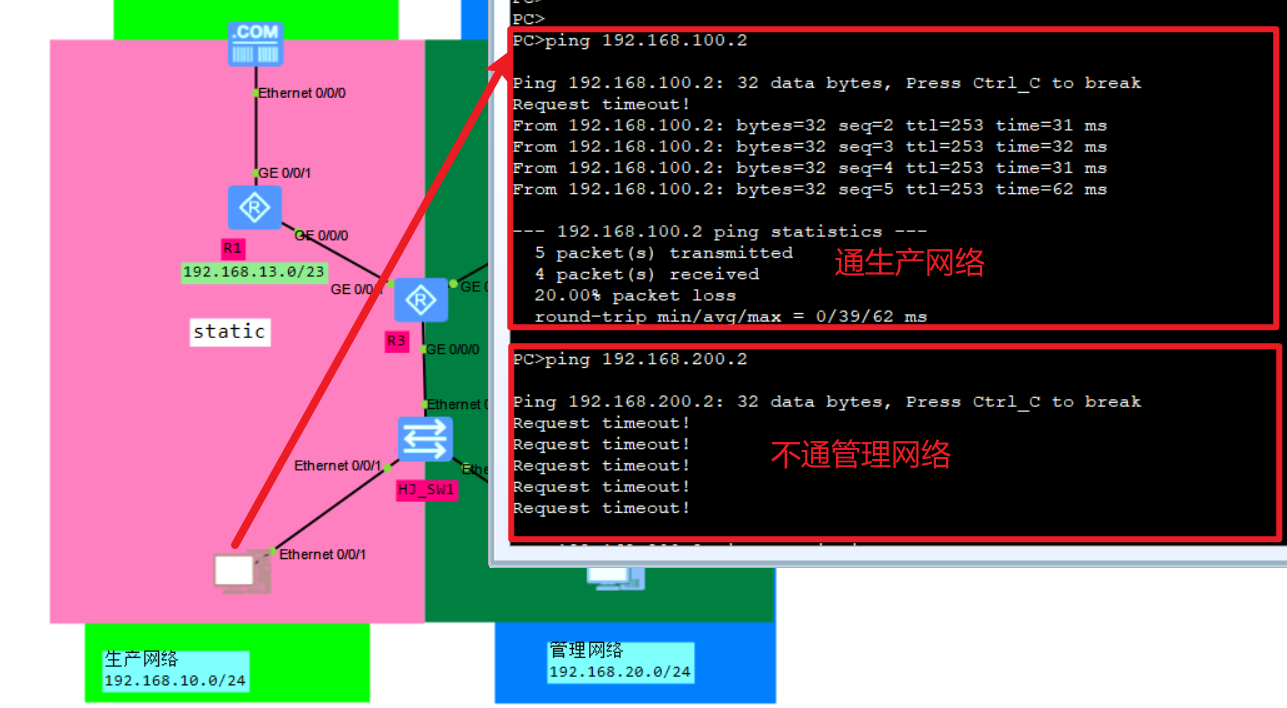
ip route-static vpn-instance shengchan 192.168.100.0 24 192.168.13.1
在R1上配置回程路由(这个就直接配就行):
ip route-static 192.168.10.0 24 192.168.13.3
测试:
管理网配置:
R3:
ospf 1 router-id 3.3.3.3 vpn-instance guanli
area 0.0.0.0
network 192.168.20.0 0.0.0.255
network 192.168.23.0 0.0.0.255
R2:
ospf 1 router-id 2.2.2.2
area 0.0.0.0
network 192.168.200.0 0.0.0.255
network 192.168.23.0 0.0.0.255
测试:
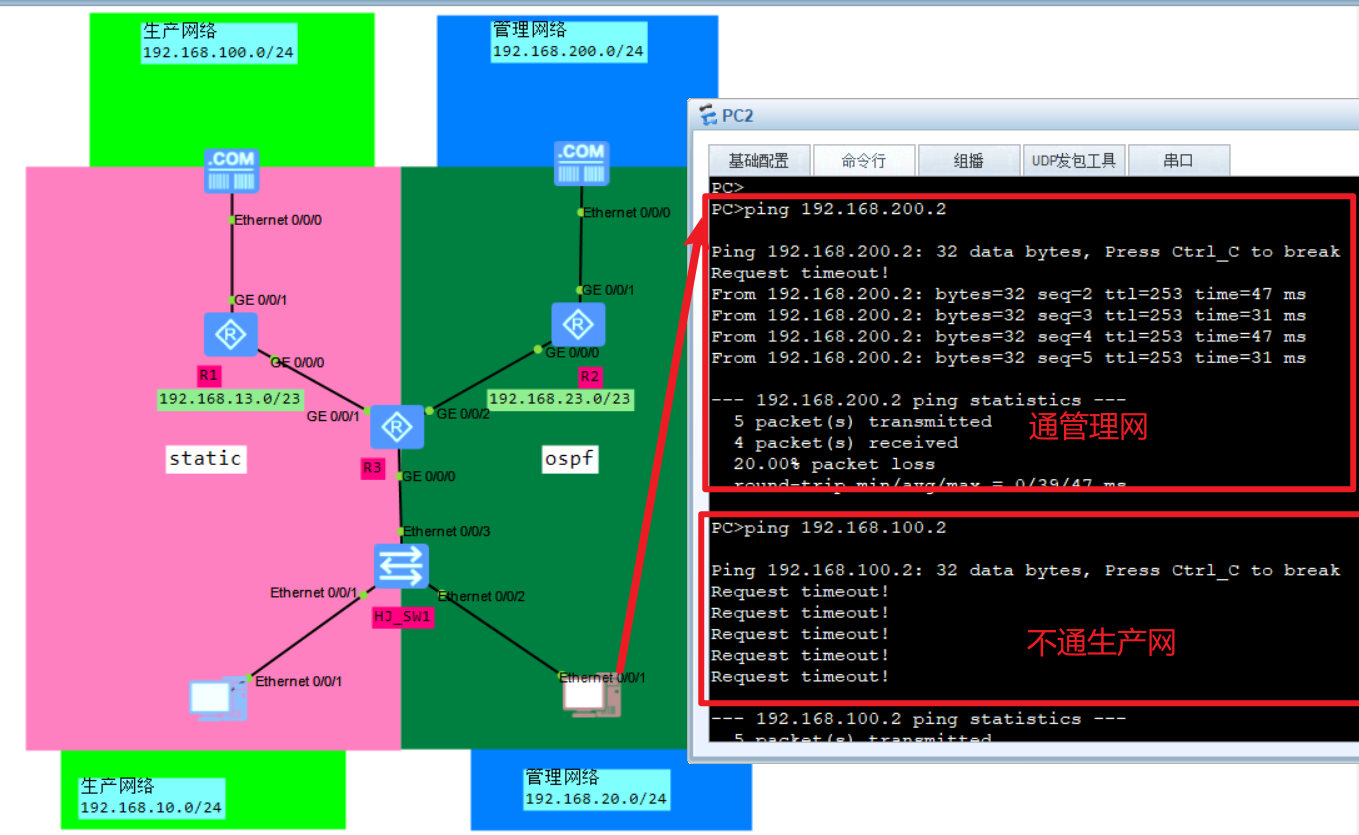
七、ISIS

CLNP:ConnectionLess Network Protocol 无连接网络协议


OSI模型中的数据链路层:
LLC子层(logical link control):逻辑链路控制为上层协议提供SAP(Service Accessing point)服务访问点,并为数据加上控制信息,其协议为802.2,为以太网和令牌环网提供了通用功能
MAC子层(media access control):介质访问控制负责MAC寻址和定义介质访问控制方法
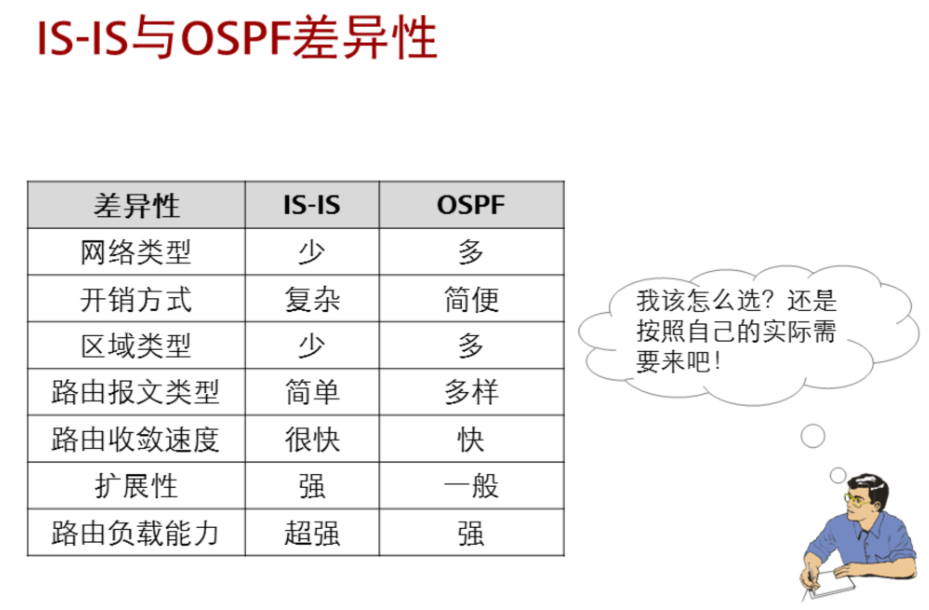
注意:IS-IS属于内部网关协议,用于自治系统内部。IS-IS是一种链路状态协议,使用最短路径优先算法进行路由计算。
7.1 ISIS概述
ISIS: Intermediate System to Intermediate System(中间系统到中间系统)的简称
中间系统:路由器
isis 是一个主要应用于运营商的路由协议,其应用规模和算法和OSPF类似。
isis 路由优先级:15
直连 0
静态路由 60
rip 100
ospf 10
isis 15
内部网关路由协议 IGP:rip ospf isis
外部网关路由协议EGP:BGP
ISIS扩展性极强:TLV
type:类型
length:长度
value:数值
ISIS协议特点:
特点:
① IS 指路由器
② isis 属于大型内部网关路由协议类似ospf,多用于运营商, 普通企业网很少使用。
③ 使用SPF算法,链路状态类路由协议。
④ ISIS 最早是基于OSI 模型设计,而ospf、rip、以及常见的 以太网数据包封装都是基于TCP/IP模型。
⑤ ISIS 划分区域是基于路由器的。即一个路由器只能属于一 个区域
⑥ ISIS 基于链路层 OSPF基于网络层
骨干区域:
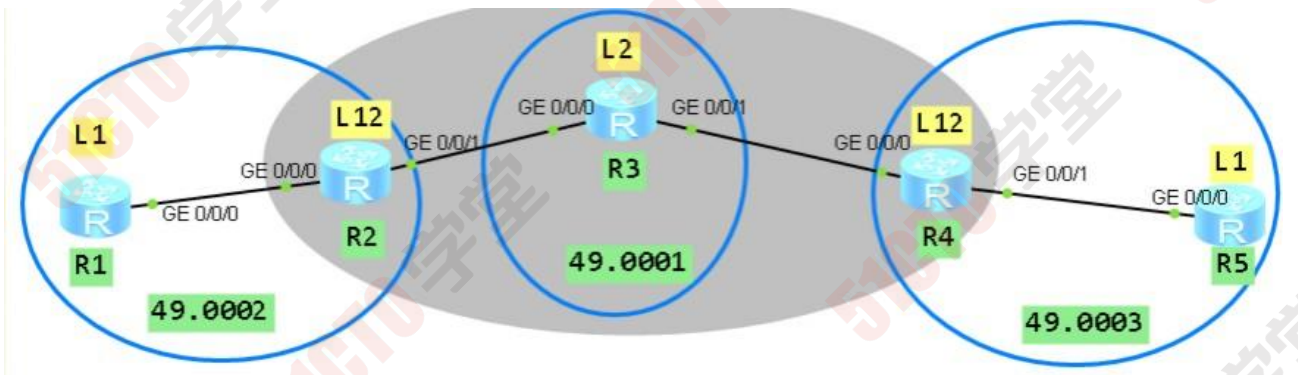
骨干区域:连续的一片Level 2 路由器(包含L 1 2)的集合。 即底色为灰色区域.
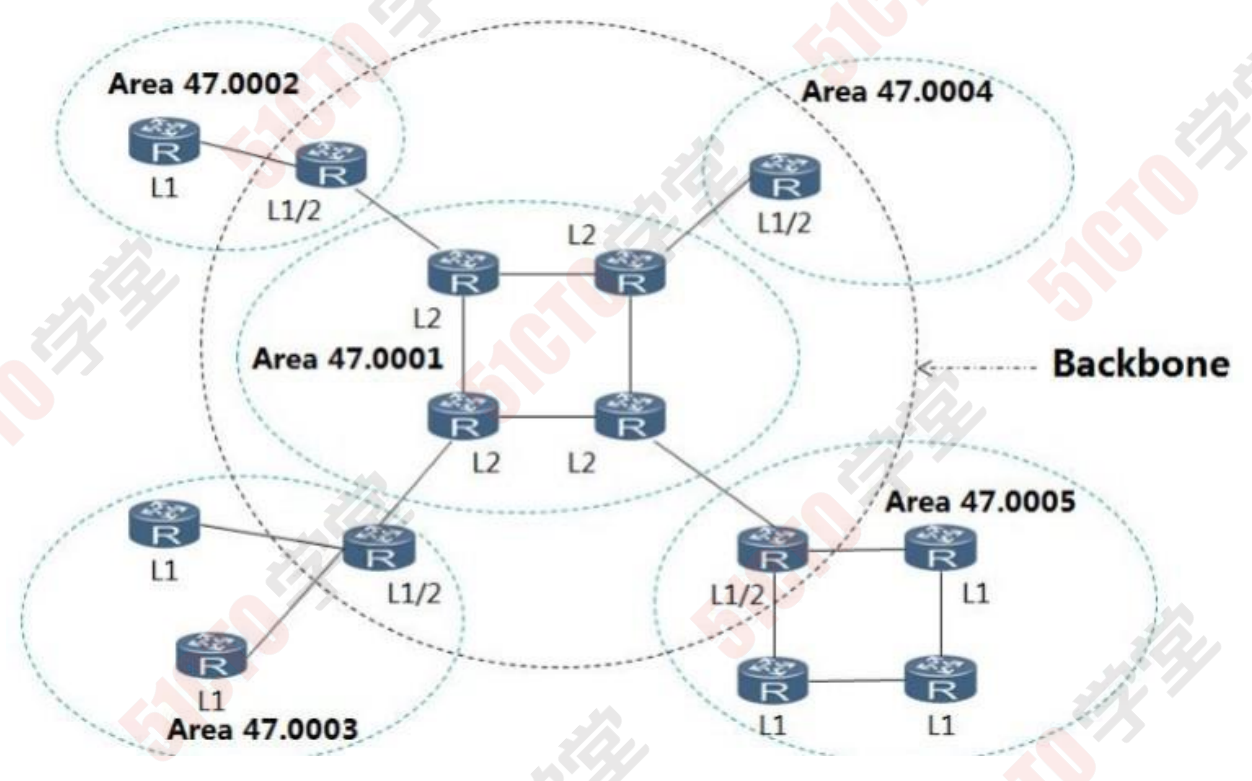
isis 路由器的种类
① Level 1路由器:仅收发L1 isis报文
② Level 2路由器:仅收发L2 isis报文
③ Level 1 2路由器:可以收发L1 和L2的isis报文
ISIS 报文种类:L1 L2
注意事项:Level 1 路由器不能跨区域建立邻居关系。Level 1 邻居关系不能跨区域建立。
是否能建立邻居关系:
| 区域 | 路由器种类 | 是否可以建立邻居关系 |
|---|---|---|
| 相同区域(如R1:49.0001 R2:49.0001) | Level 1 + Level 2 | no |
| 相同区域(如R1:49.0001 R2:49.0001) | Level 1 + Level 1 | yes (Level 1) |
| 相同区域(如R1:49.0001 R2:49.0001) | Level 2 + Level 2 | yes (Level 2) |
| 相同区域(如R1:49.0001 R2:49.0001) | Level 1 + Level 1 2 | yes (Level 1) |
| 相同区域(如R1:49.0001 R2:49.0001) | Level 2 + Level 1 2 | yes (Level 2) |
| 相同区域(如R1:49.0001 R2:49.0001) | Level 1 2 + Level 1 2 | yes(Level 1 Level 2) |
| 不同区域(如R1:49.0001 R2:49.0002) | Level 1 + Level 2 | no |
| 不同区域(如R1:49.0001 R2:49.0002) | Level 1 + Level 1 | no |
| 不同区域(如R1:49.0001 R2:49.0002) | Level 2 + Level 2 | yes (Level 2) |
| 不同区域(如R1:49.0001 R2:49.0002) | Level 1 + Level 1 2 | no |
| 不同区域(如R1:49.0001 R2:49.0002) | Level 2 + Level 1 2 | yes (Level 2) |
| 不同区域(如R1:49.0001 R2:49.0002) | Level 1 2 + Level 1 2 | yes (Level 2) |
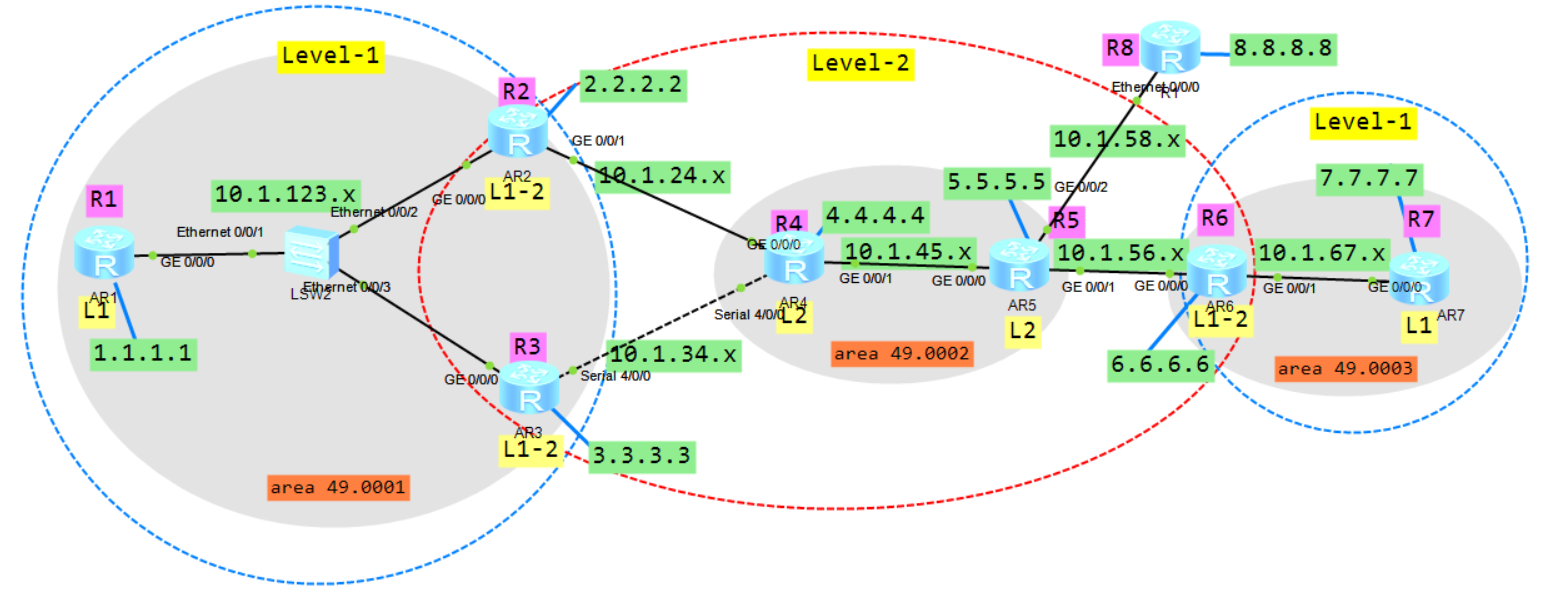
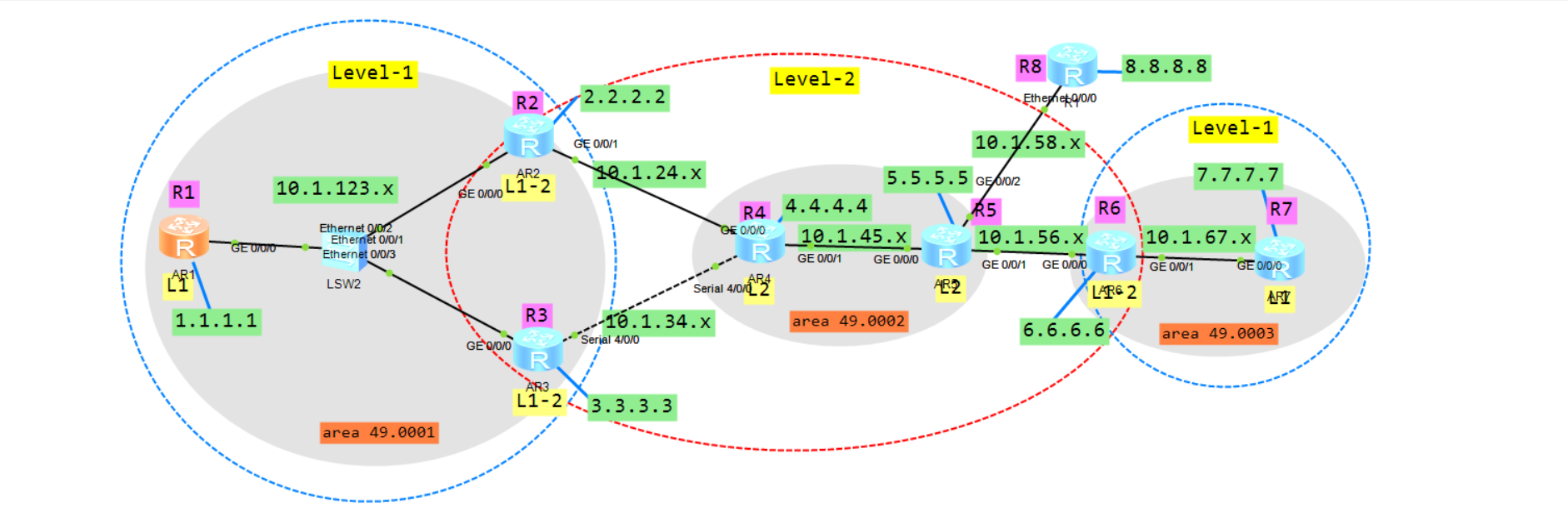
7.2 ISIS 配置
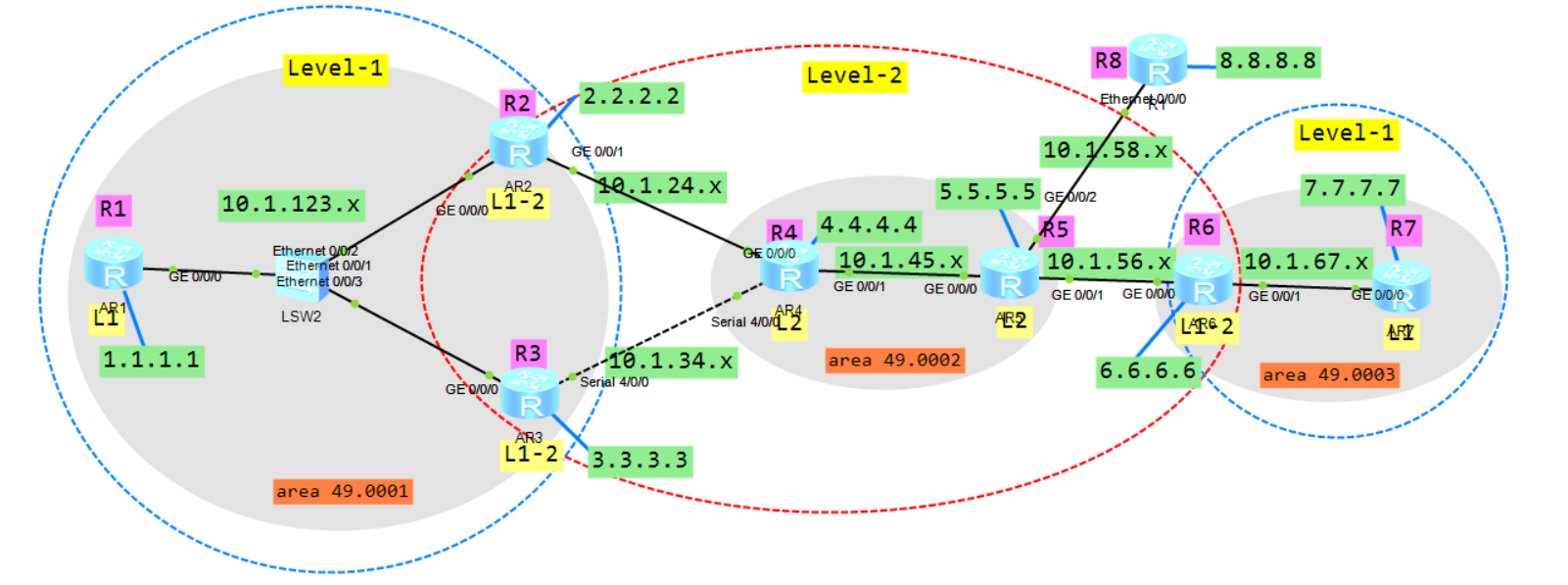
按照规划配置好路由器名称和各个接口的地址。
ISIS配置:
R1:
[AR1] router id 1.1.1.1
[AR1] isis 1
[AR1-isis-1] network-entity 49.0001.0000.0000.0001.00
[AR1-isis-1] is-level level-1
[AR1-isis-1] interface g0/0/0
[AR1-GigabitEthernet0/0/0] isis enable 1
[AR1-GigabitEthernet0/0/0] interface loopback 0
[AR1-LoopBack0] isis enable 1
R2:
router id 2.2.2.2
isis 1
network-entity 49.0001.0000.0000.0002.00
is-level level-1-2
interface g0/0/0
isis enable 1
interface g0/0/1
isis enable 1
interface loopback 0
isis enable 1
R3:
router id 3.3.3.3
isis 1
network-entity 49.0001.0000.0000.0003.00
is-level level-1-2
interface s4/0/0
isis enable 1
interface g0/0/0
isis enable 1
interface loopback 0
isis enable 1
R4:
router id 4.4.4.4
isis 1
network-entity 49.0002.0000.0000.0004.00
is-level level-2
interface s4/0/0
isis enable 1
interface g0/0/0
isis enable 1
interface g0/0/1
isis enable 1
interface loopback 0
isis enable 1
R5:
router id 5.5.5.5
isis 1
network-entity 49.0002.0000.0000.0005.00
is-level level-2
interface g0/0/0
isis enable 1
interface g0/0/1
isis enable 1
interface loopback 0
isis enable 1
R6:
router id 6.6.6.6
isis 1
network-entity 49.0003.0000.0000.0006.00
is-level level-1-2
interface g0/0/0
isis enable 1
interface g0/0/1
isis enable 1
interface loopback 0
isis enable 1
R7:
router id 7.7.7.7
isis 1
network-entity 49.0003.0000.0000.0007.00
is-level level-1
interface g0/0/0
isis enable 1
interface loopback 0
isis enable 1
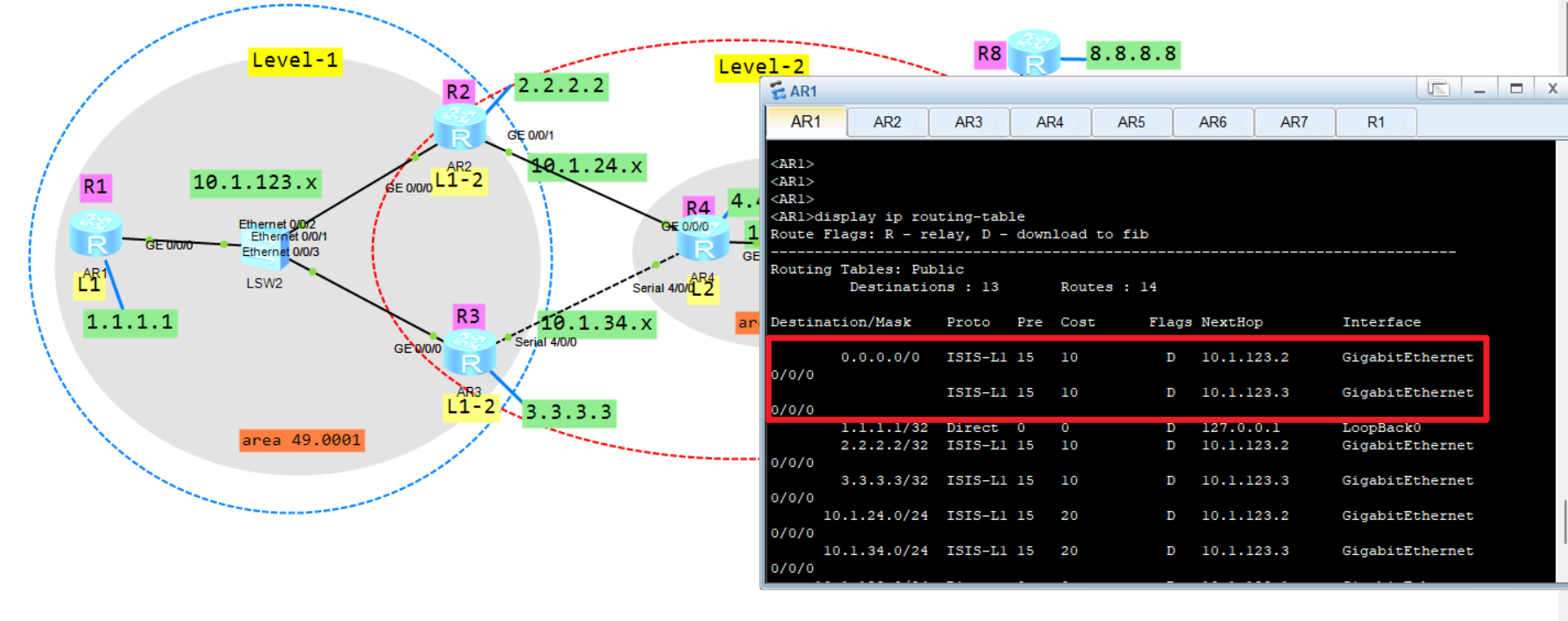
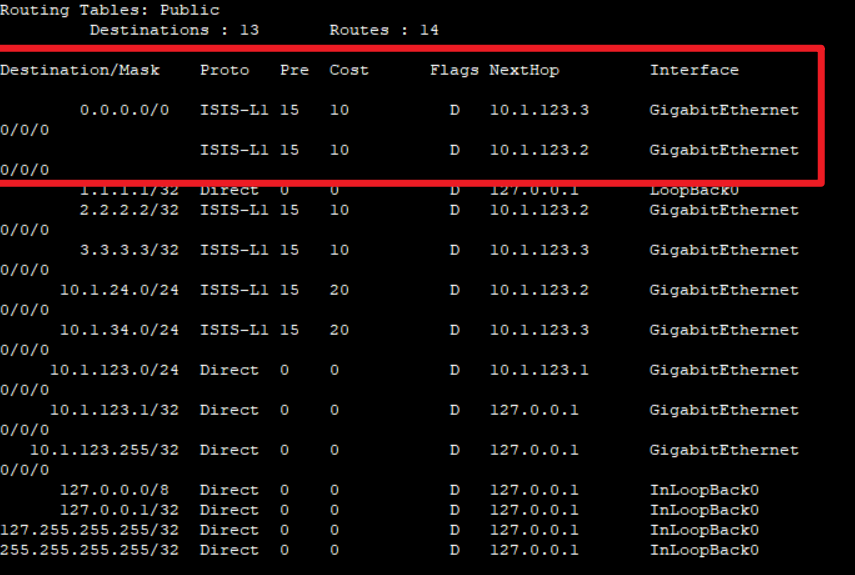
配置完成之后除开R8以外应该是全网互通的。可以形成邻居的会有路由,其它的它会自动生成一条缺省路由。
7.3 ISIS邻居建立
三种hello报文:
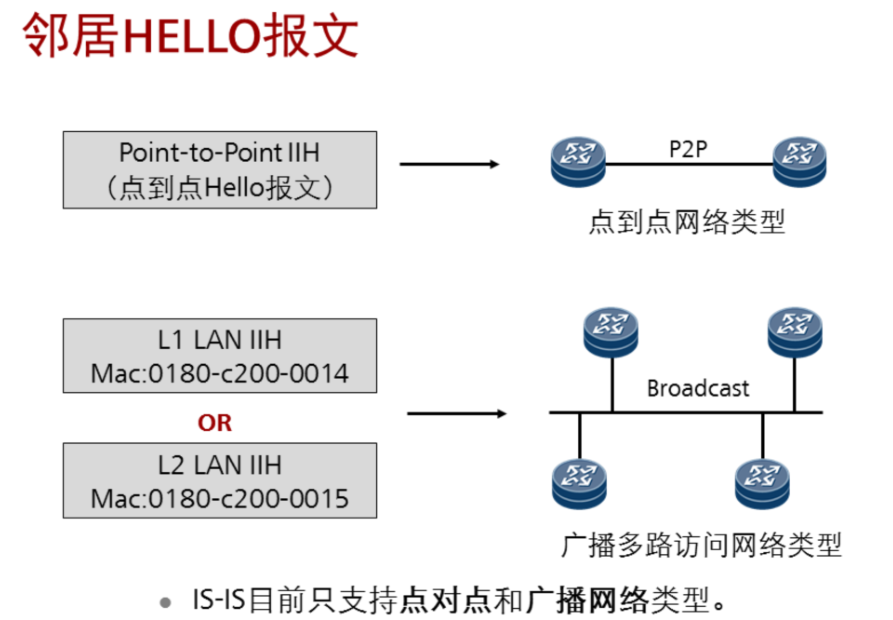
DIS的选举:
a 接口优先级(默认64)越大越优先
b 接口mac地址越大越优先
修改接口优先级:
[AR1-GigabitEthernet0/0/0] isis dis-priority 65
查看是否是DIS:


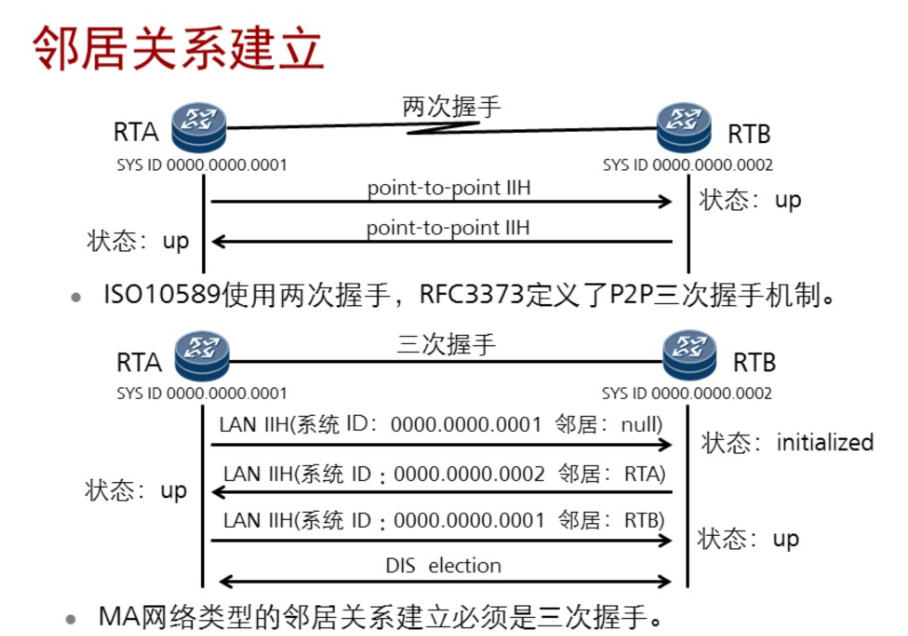
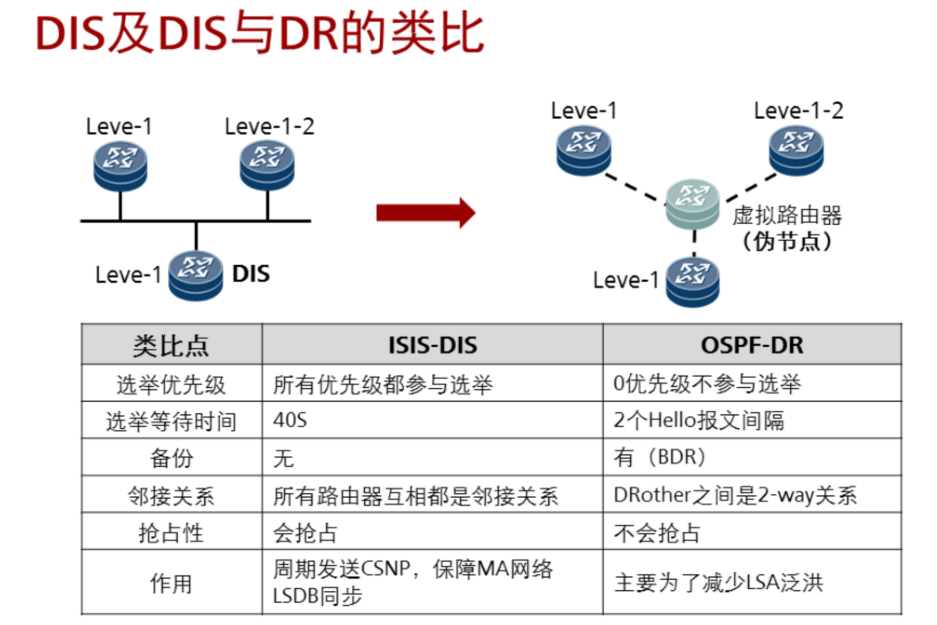
DIS:hello时间 1/3 hello 即3.3s。
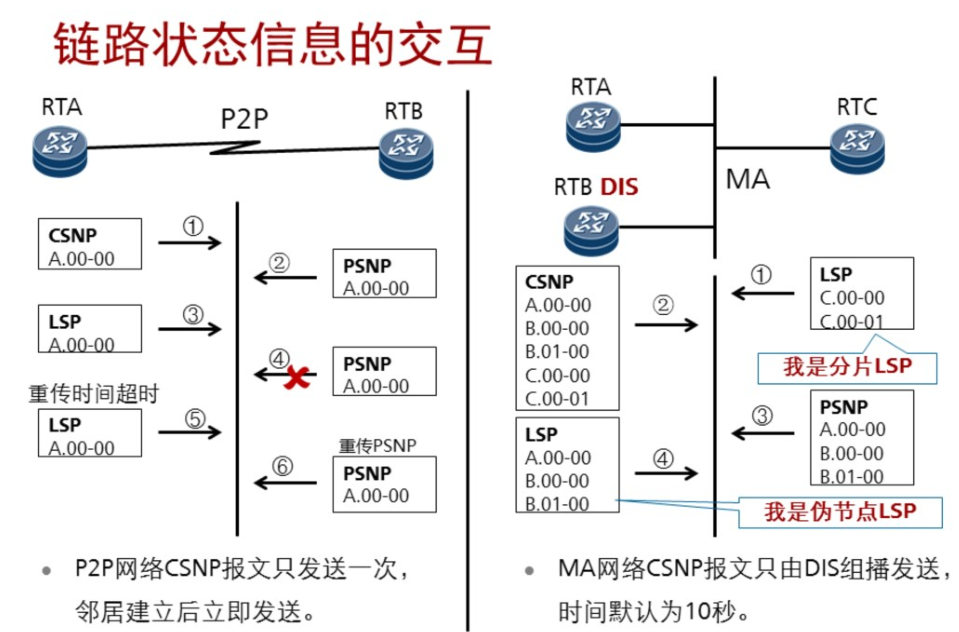


7.4 路由引入
R5增加一条通往8.8.8.8的静态路由:
R5:
[AR5] ip route-static 8.8.8.8 32 10.1.58.8
R8再配置一条回来的缺省路由:
R8:
[AR8] ip route-static 0.0.0.0 0 10.1.58.5
在在ISIS进程中导入该静态路由:
[AR5] isis 1
[AR5-isis-1] import-route static
[AR5-isis-1] import-route direct
默认是以Level 2 的形式引入。可以在后面加参数指定以什么形式导入。如:
[AR5-isis-1] import-route direct level-1
上面的引入如果不引入直连路由(direct),则R8 ping的时候要指定源地址为8.8.8.8 ping
[AR8] ping -a 8.8.8.8 1.1.1.1
7.5 路由渗透
如图,R1到达右侧有两条路径,一条是走R2,一条是走R3,但是明显走R2要更好,但是由于区域隔离它不知道走R2更合理,两条路径的优先级是一致的。
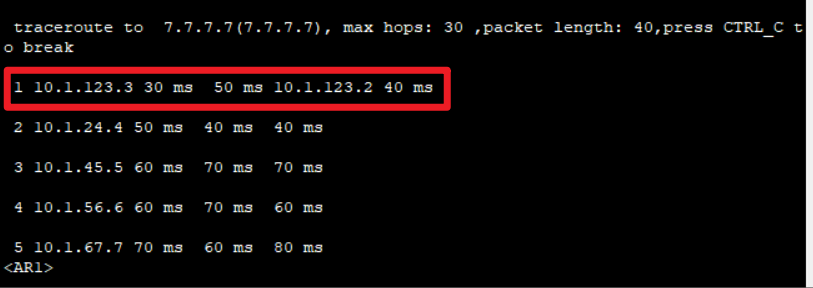
此时可以通过路由渗透的方式让Level-1区域学习部分Level-2的路由让他走合理的路径:
R2:
[AR2] isis 1
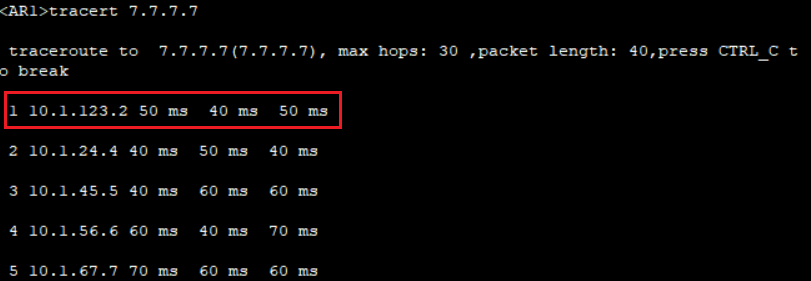
[AR2-isis-1] import-route isis level-2 into level-1
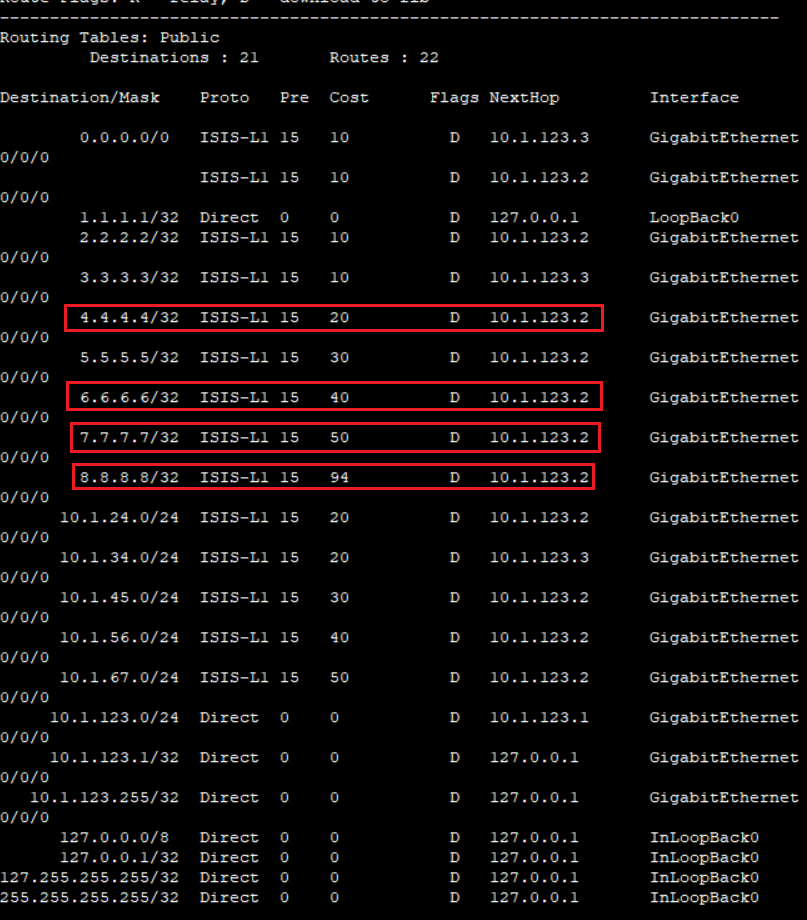
他会学习到Level-2中的路由,然后选择合理的路径:
以上配置由于没有过滤,它会导入所有路由,对于性能较差的边界路由器来说可能很不友好,我们可以通过filter-policy来过滤只学习到需要的路由:
AR2:
[AR2-isis-1] undo import-route isis level-2 into level-1
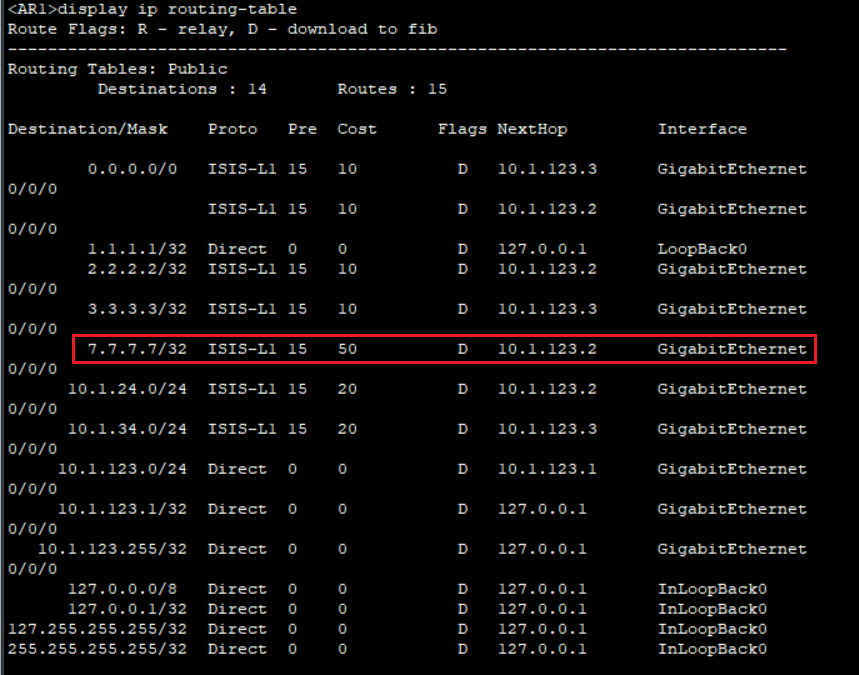
[AR2-isis-1] import-route isis level-2 into level-1 filter-policy 2005
[AR2-isis-1] acl 2005
[AR2-acl-basic-2005] rule 5 permit source 7.7.7.7 0.0.0.0
[AR2-acl-basic-2005] rule 10 deny
之后他就会只引入匹配的路由,其它路由不再学习。
八、BGP
8.1 BGP概述
BGP(边界网关路由协议):boder gateway protocol
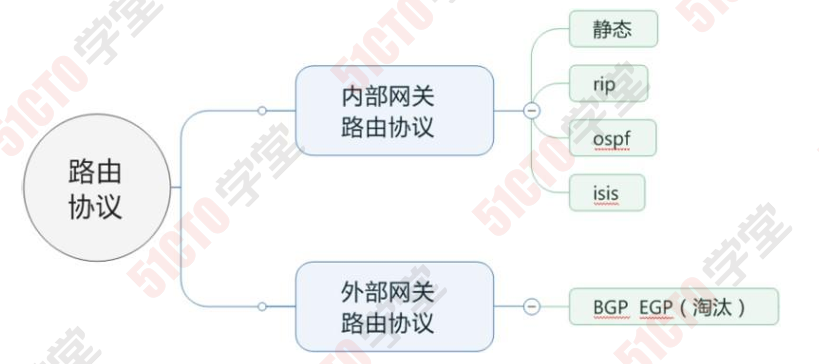
IGP: Interior Gateway Protocol内部网关协议
EGP:Exterior Gateway Protocol外部网关协议
IGP:路由发现和计算
BGP:路由的控制、优选和传递
特点:
① 属于外部网关路由协议
② 主要用于大型网络、大型集团、运营商、银行、国家电网、 国与国之间的路由
③ BGP 运行在IGP(内部网关)之上,其底层是IGP(内部网关 路由协议)
④ AS 自制系统,一个AS 可以是一个国家,也可以是一个运 营商,也可以是一个跨国集团 118
⑤ BGP的邻居关系: IBGP:相同的AS EBGP:不同AS
⑥ BGP可以跨路由器建立邻居(因为bgp发送的报文都是单播)
⑦ bgp 四层使用tcp 179号端口
⑧ 一台路由器只能启用一个bgp 进程 6-2 BGP报文
BGP五种报文:
open:建立邻居
keepalive:维持邻居
update:路由更新
route-refresh:刷新路由策略
Notification :差错检测
8.2 BGP基础配置
8.2.1 IBGP配置
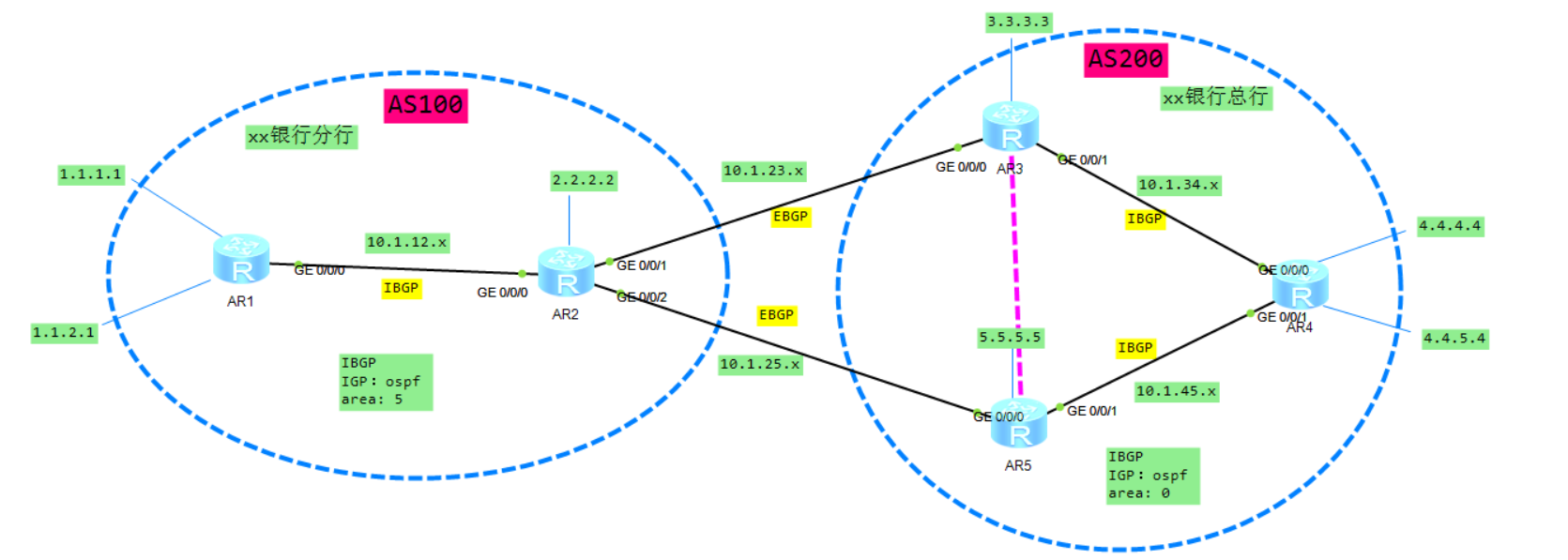
配置AS区域内部跑ospf(基础网络配置跳过):
AS100:
AR1:
router id 1.1.1.1
ospf 1 router-id 1.1.1.1
area 0.0.0.5
network 1.1.1.0 0.0.0.255
network 1.1.2.0 0.0.0.255
network 10.1.12.0 0.0.0.255
AR2:
router id 2.2.2.2
ospf 1 router-id 2.2.2.2
silent-interface GigabitEthernet0/0/1 (把AS区域出去的接口配置成静默接口)
silent-interface GigabitEthernet0/0/2 (把AS区域出去的接口配置成静默接口)
area 0.0.0.0
network 10.1.23.0 0.0.0.255
network 10.1.25.0 0.0.0.255
area 0.0.0.5
network 2.2.2.0 0.0.0.255
network 10.1.12.0 0.0.0.255
AS200:
AR3:
ospf 1 router-id 3.3.3.3
silent-interface GigabitEthernet0/0/0 (把AS区域出去的接口配置成静默接口)
area 0.0.0.0
network 3.3.3.0 0.0.0.255
network 10.1.23.0 0.0.0.255
network 10.1.34.0 0.0.0.255
AR4:
router id 4.4.4.4
ospf 1 router-id 4.4.4.4
area 0.0.0.0
network 4.4.4.0 0.0.0.255
network 4.4.5.0 0.0.0.255
network 10.1.34.0 0.0.0.255
network 10.1.45.0 0.0.0.255
AR5:
router id 5.5.5.5
ospf 1 router-id 5.5.5.5
silent-interface GigabitEthernet0/0/0 (把AS区域出去的接口配置成静默接口)
area 0.0.0.0
network 5.5.5.0 0.0.0.255
network 10.1.25.0 0.0.0.255
network 10.1.45.0 0.0.0.255
IBGP: 相同的AS(建议使用环回口地址建立)
EBGP:不同的AS
8.2.2 BGP 配置
AS100:
AR1:
bgp 100 (BGP的区域号,属于哪个区域就填哪个)
router-id 1.1.1.1 (router-id,和ospf中的一样)
peer 2.2.2.2 as-number 100 (相当于告诉AR1:你有一个邻居为2.2.2.2,以后发送单播的bgp报文地址就发送到这 个地址,地址也可以写物理地址,但是建议写环回地址,比较稳定,后面的100表示邻 居属于哪个as区域)
peer 2.2.2.2 connect-interface LoopBack0 (指定更新源接口地址,这里要填自身的接口,使用的是loopback0,使用环回接口比 较稳定)
以上步骤指定了BGP报文的源地址为自己的loopback0接口,也就是地址1.1.1.1,以及目标地址2.2.2.2。
AR2:
bgp 100
router-id 2.2.2.2
peer 1.1.1.1 as-number 100
peer 1.1.1.1 connect-interface LoopBack0
peer 10.1.23.3 as-number 200
peer 10.1.25.5 as-number 200
异AS区域的邻居不用指定源接口,默认就是使用出接口作为源地址。
配置完成之后AR1和AR2就可以成功建立邻居了:

此时抓包也可以看见keepalive报文:

之后再配置AS200区域:
AS200:
注:AS200 中AR3和AR5是可以跳过AR4建立邻居关系的,他们是基于TCP连接的,可以通过AR4通过ospf路由转发,比如这里AR2通往AS200区域它有两条路径可选,其实和AR4没有多大关系,因此AR4其实不用运行BGP也是可以的。
AR3:
bgp 200
router-id 3.3.3.3
peer 5.5.5.5 as-number 200
peer 5.5.5.5 connect-interface LoopBack0
peer 10.1.23.2 as-number 100
AR5:
bgp 200
router-id 5.5.5.5
peer 3.3.3.3 as-number 200
peer 3.3.3.3 connect-interface LoopBack0
peer 10.1.25.2 as-number 100
这里AR4不配置是因为它可以跨三层建立连接,只要TCP网络连接正常即可。
可以看见邻居关系建立成功:

8.3 BGP邻居状态
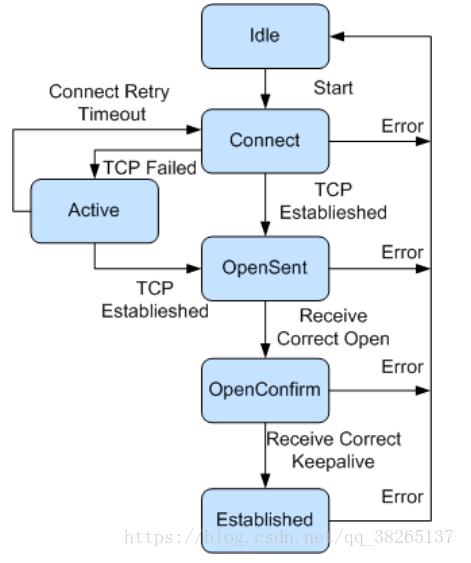
Active状态:TCP连接失败,启动BGP重传定时器,BGP路由器再次尝试 与对方建立TCP连接 :
例如:对方路由器配置了BGP但是没有指定邻居。
Connect状态:对方没有配置bgp进程。
总结:
Active :被动等待TCP连接
Connect :开始主动建立TCP连接
8.4 BGP 路由生成方式
① network
② import
BGP 是将路由表中的路由引入BGP转发表(BGP路由表)
③ bgp路由汇总(聚合)
注意1:network 将路由表中的路由引入bgp转发表, network引入路由时,路由需在路由表中存在,且引入时掩码 需要和路由表中保持一致。
8.4.1 network
如图,在AR5中存在如下路由,我们可以把它加入到BGP路由表(或者叫BGP转发表)当中:
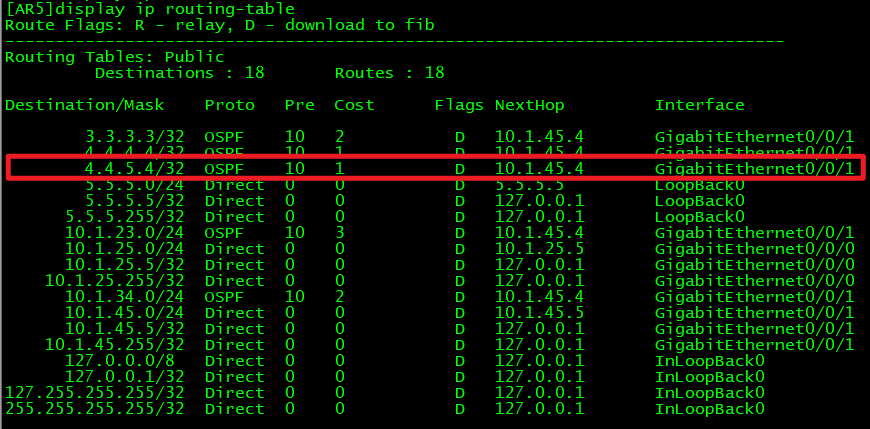
我们可以把它加入到BGP路由表当中:
AR5:
[AR5]bgp 200
[AR5-bgp]network 4.4.5.4 32
如果想多加几条路由到BGP妆发表里就多network几条路由而已。
查看BGP路由表:
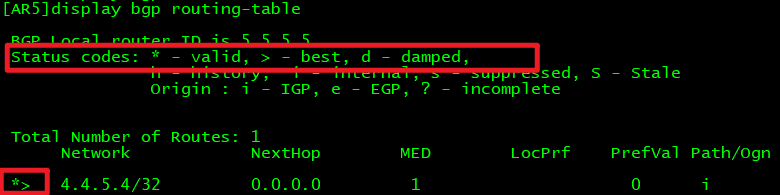
命令:display bgp routing-table
valid(*):表示有效
best(>):优化\最好
*> 就是表示可用
此时在AS100当中的路由器上就可以看见该BGP转发表:
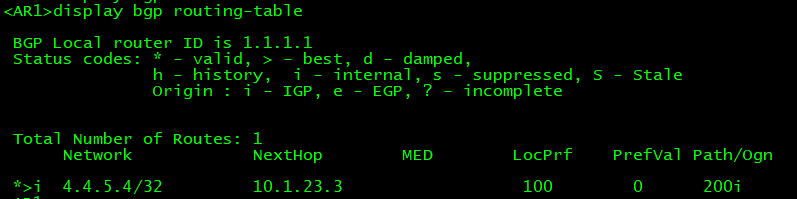
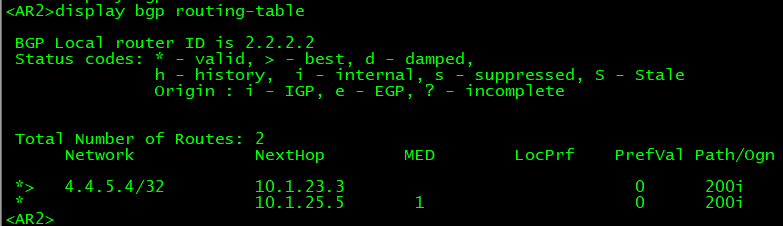
在转发表当中有之后路由表中也会有,如果路由表中没有的话要先检查BGP装发表当中是否有并且处于可用状态:
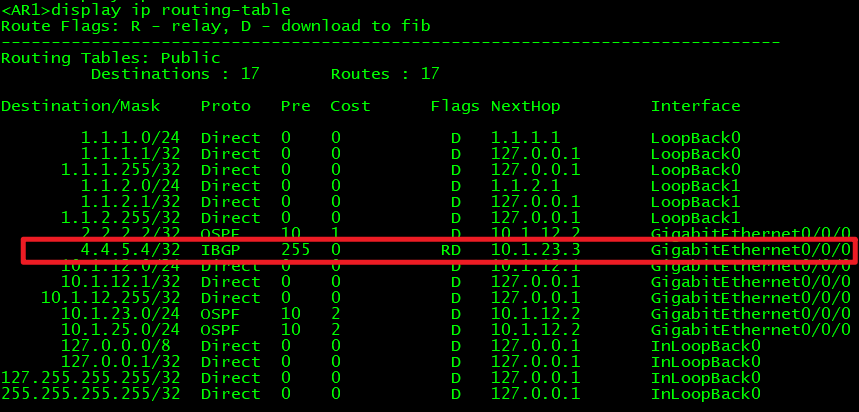
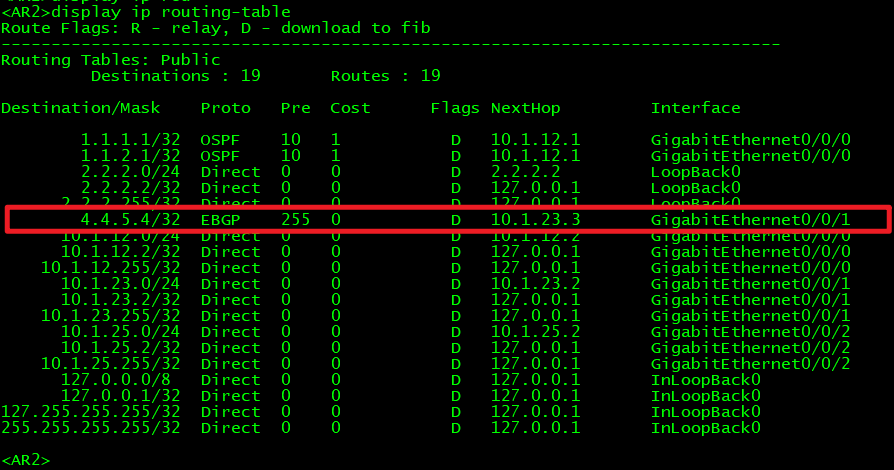
有BGP路由也也不一定ping的通。
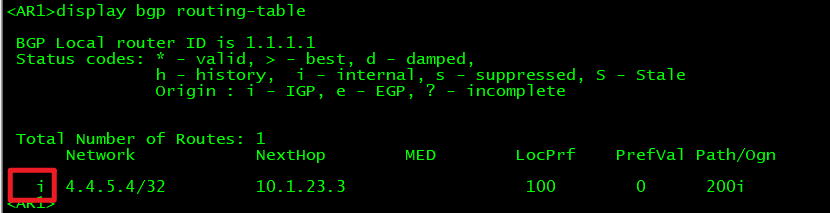
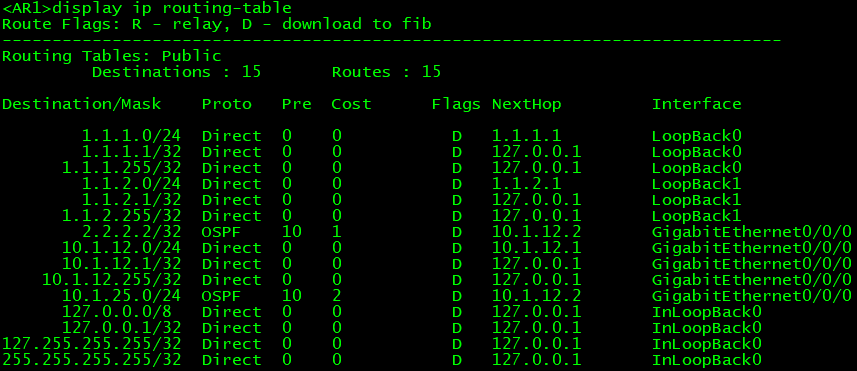
现在如果我们在AR2上把宣告10.1.23.0的配置删除,导致AR1上BGP路由表的下一跳不可达,那么它就会变成不可用状态,路由表也将消失IBGP路由:
8.4.1 import
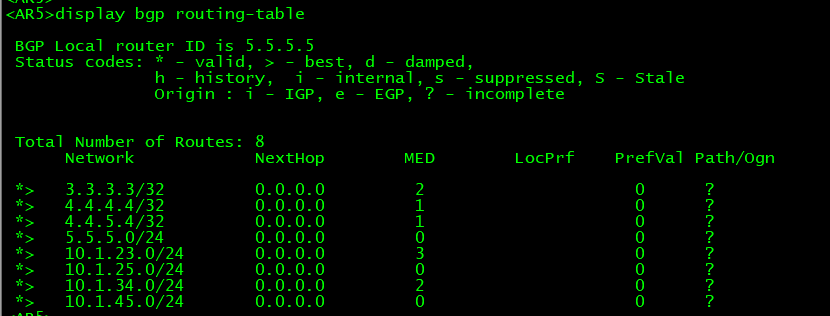
在AR5上删除原来通过network引入的路由:
[AR5] bgp 200
[AR5-bgp] undo network 4.4.5.4 255.255.255.255
在AR5上引入ospf学到的路由:
[AR5] bgp 200
[AR5-bgp] import-route ospf 1
为了稳定建议在AR3上也导入一下,路由是可以通过route-policy过滤的。
再次查看你BGP转发表:
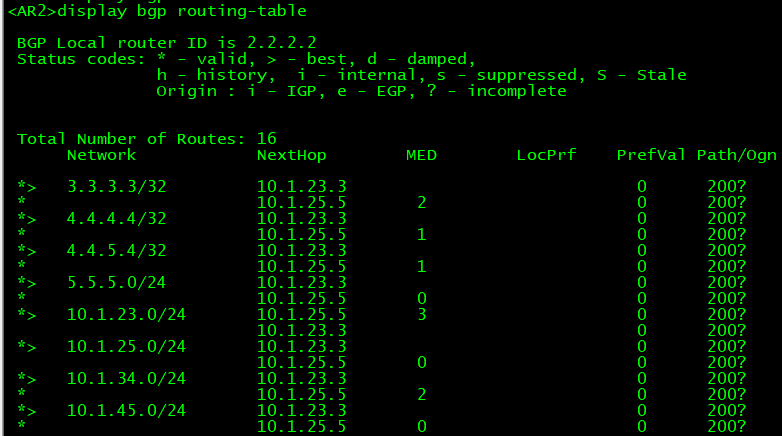
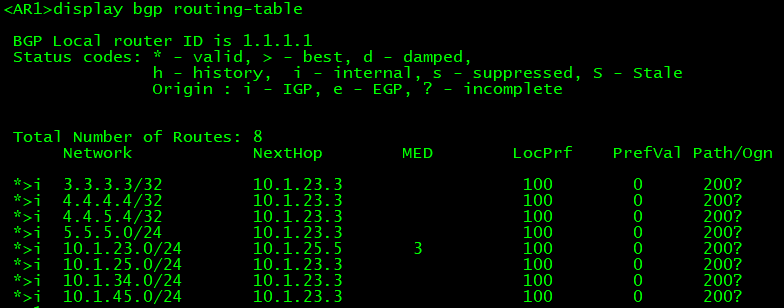
把区域边界的路由器都引入一下,AR2和AR3:
AR3:
[AR3] bgp 200
[AR3-bgp] import-route ospf 1
AR2:
[AR2] bgp 100
[AR2-bgp] import-route ospf 1
此时我们在AR1上虽然看见了到达4.4.4.4的路由,但是确无法访问,这个是著名的BGP路由黑洞:
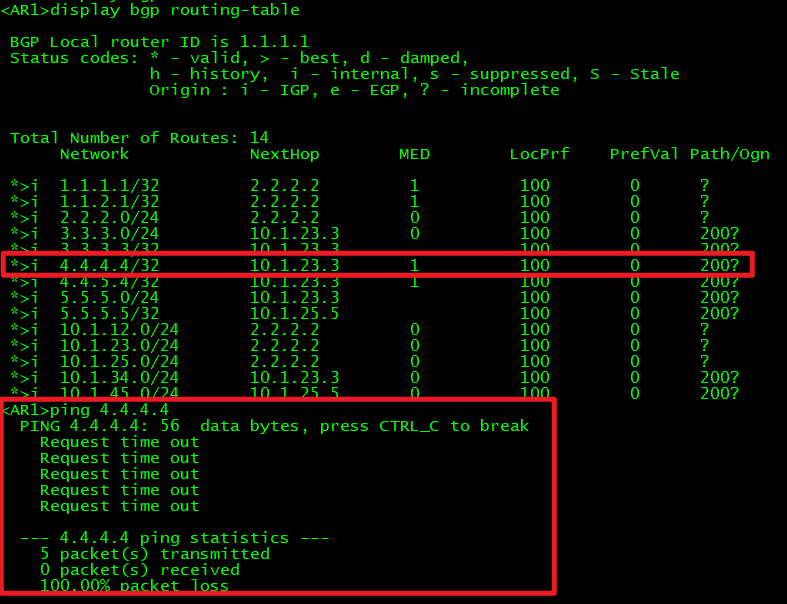
BGP路由黑洞:能学习到路由,但是访问(控制层面可达,数据层面不可达)。
可以发现AR1是可以访问运行了BGP路由的其它路由器,但是不通没有运行BGP的AR4,原因就是它上面由于没有运行BGP路由,它并没有学习到到达AR1的路由,即回不来:
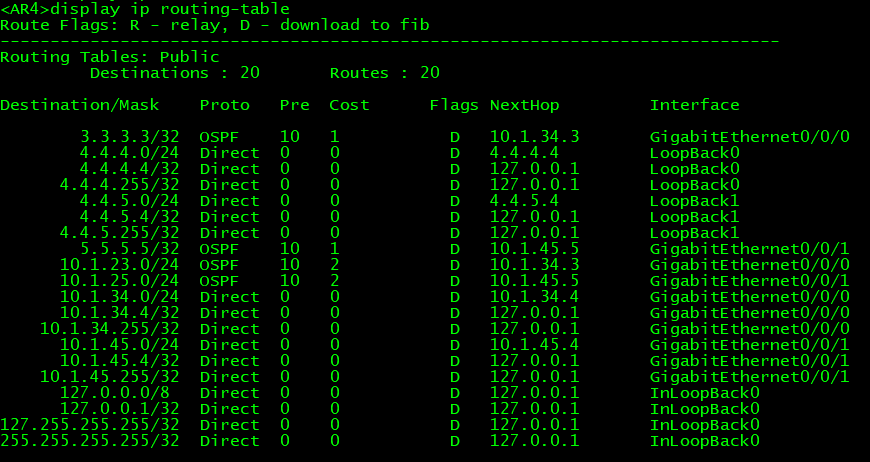
像这种情况有两个解决方案:
- 在ospf中引入BGP路由(这是类似银行内部使用,因为BGP路由条目比较少):
[AR5] ospf 1
[AR5-ospf-1] import-route bgp
这里也可以在AR3上引,但是会存在路由环路的问题,因此在其中一台上引入即可。
此时AR4就可以学习到1.1.1.1的路由,AR1就可以正常访问AR4:
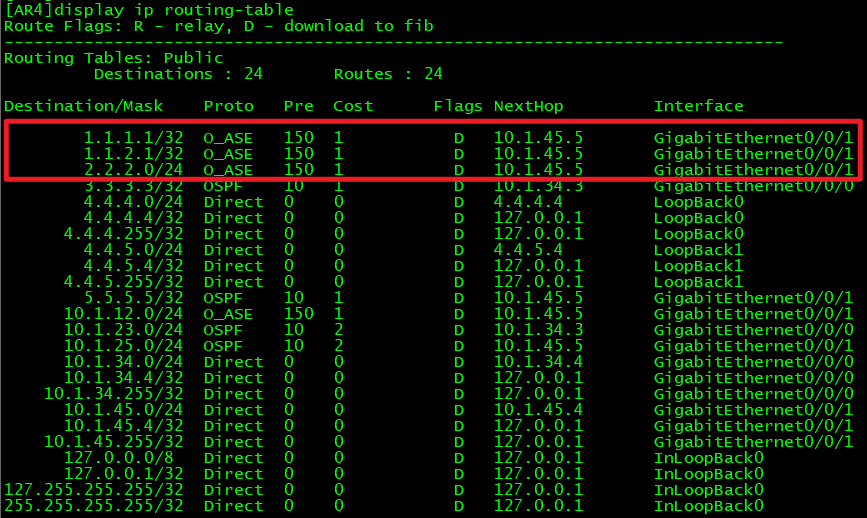
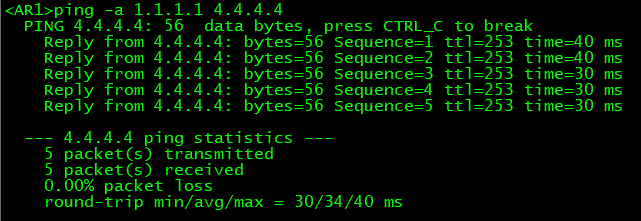
-
在AR4上也运行BGP路由(这种为运营商当中常用的方案)。
-
也可以使用MPLS解决方案。
九、路由策略和流量控制
控制流量可达性的方法:
① 路由策略
a route-policy
b filter-policy

9.1 filter-policy
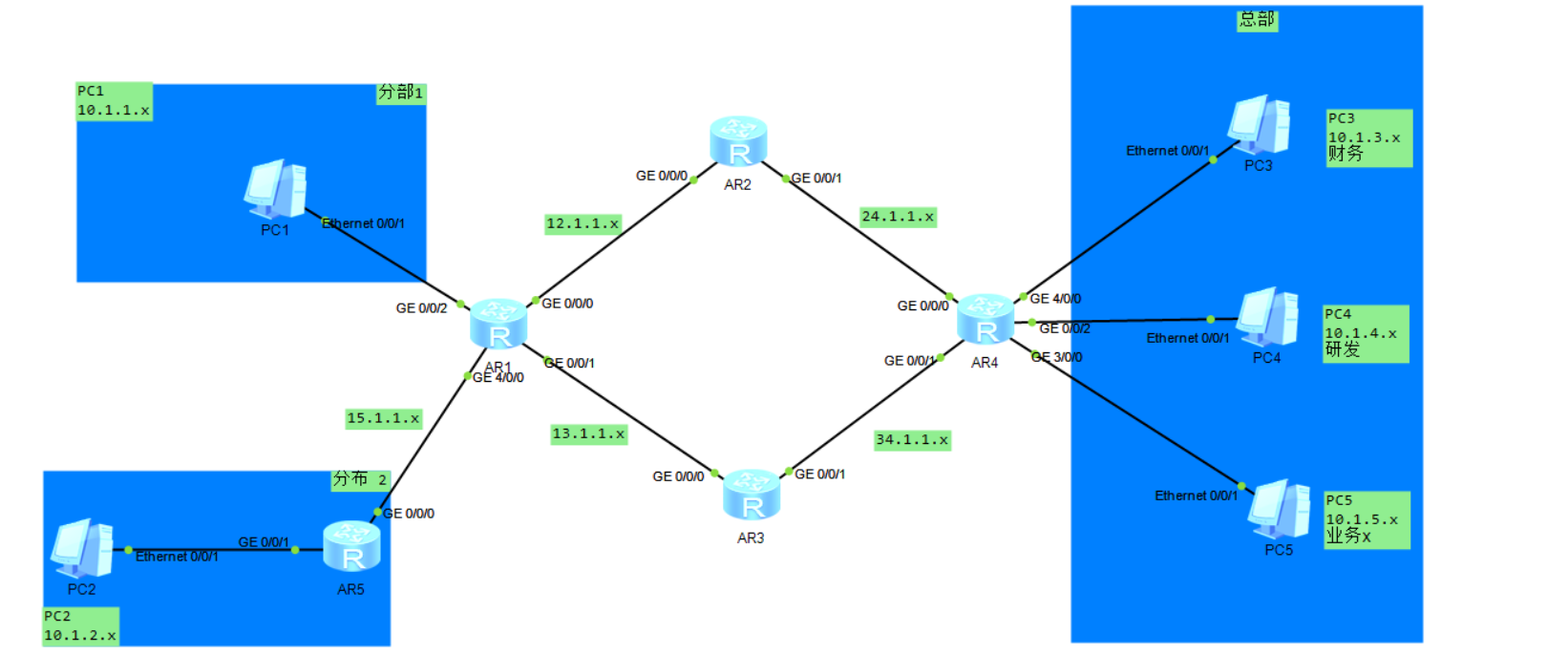
如上都运行了ospf并通告与自身网段。
需求:让PC2无法访问PC4
方法1:使用filter-policy,过滤到达10.1.4.0网段的路由,让AR5无法学习到这条路由。
AR5:
# 定义ACL用于匹配10.1.4.0网段
acl 2000
rule 5 deny source 10.1.4.0 0.0.0.255
rule 10 permit
# 通过filter-policy 过滤路由学习
ospf 1
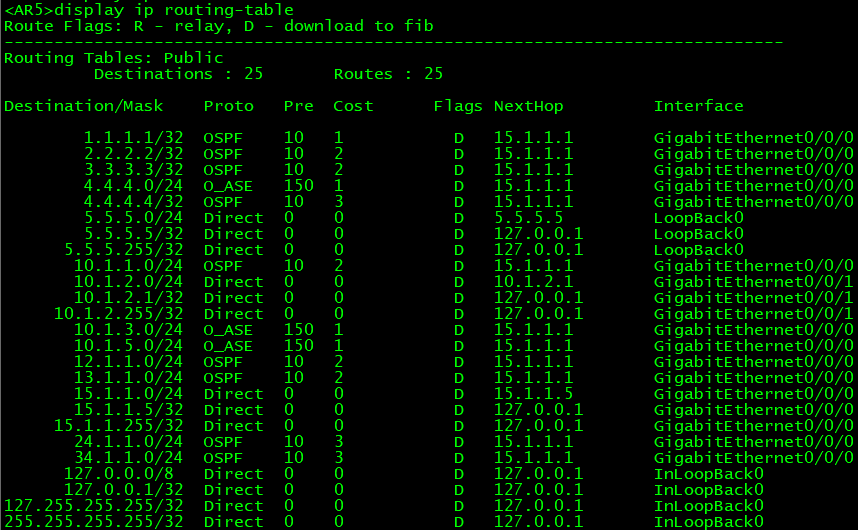
filter-policy 2000 import
此时AR5无法学习到对应路由,PC也无法访问。
9.2 route-policy
还可以有下面的方法:
方法2:使用 route-policy,引入路由时拒绝10.1.5.0网段的路由。
AR5上拿掉之前的配置:
[AR5] ospf 1
[AR5-ospf-1] undo filter-policy 2000 import
AR4上配置route-policy:
#用于匹配路由的前缀列表
[AR4] ip ip-prefix aa index 10 deny 10.1.5.0 24 greater-equal 24 less-equal 24
[AR4] ip ip-prefix aa index 20 permit 0.0.0.0 0 less-equal 32
# 再写route-policy调用ip-prefix
[AR4] route-policy aa permit node 10
[AR4-route-policy] if-match ip-prefix aa
# 在ospf引入路由时调用route-policy
[AR4] ospf 1
[AR4-ospf-1] import-route direct route-policy aa
node之间是”或“的关系,node下的if-mach之间是”与“的关系。
此时该路由就不会被引入到ospf当中,更不会被其它设备学习:
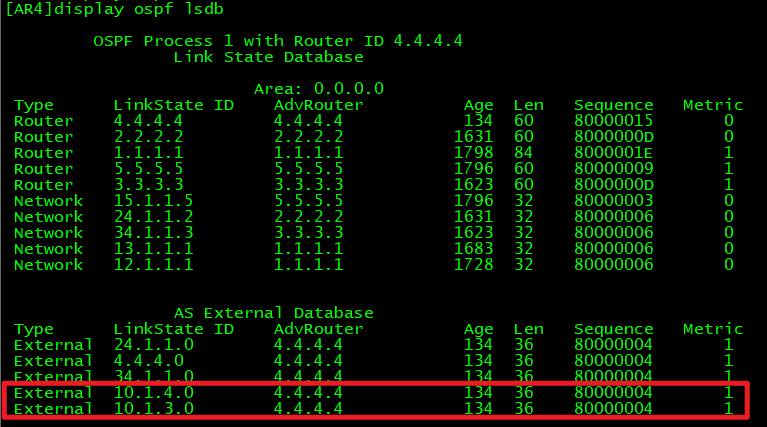
注意:filter-policy export针对链路状态协议, 只对起源于本地的引入的路由信息生效。
9.3 流量控制
流量控制,其实就是访问控制列表ACL,在第一章中有介绍,这里不再叙述。
十、交换机堆叠与集群
概念:堆叠是指将多台交换机设备通过线缆连接后组合在一起, 虚拟化成一台设备,是一种横向虚拟化技术。
可靠组网:
① VRRP+MSTP (传统)
② 堆叠+链路捆绑 (推荐) 堆叠:CSS(框式) 、iStack(盒式)
思科:VSS
华三:IRF
锐捷:VSU
注:堆叠技术是厂商的私有技术,用于堆叠的设备一般是同一个 系列,最好是同一个型号。
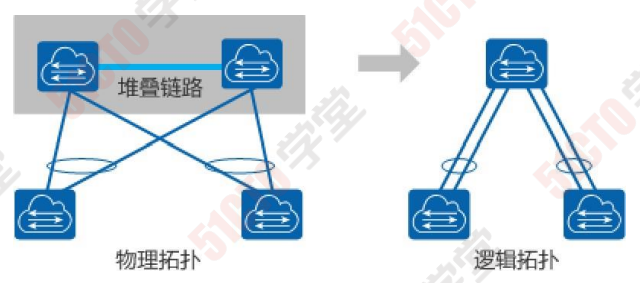
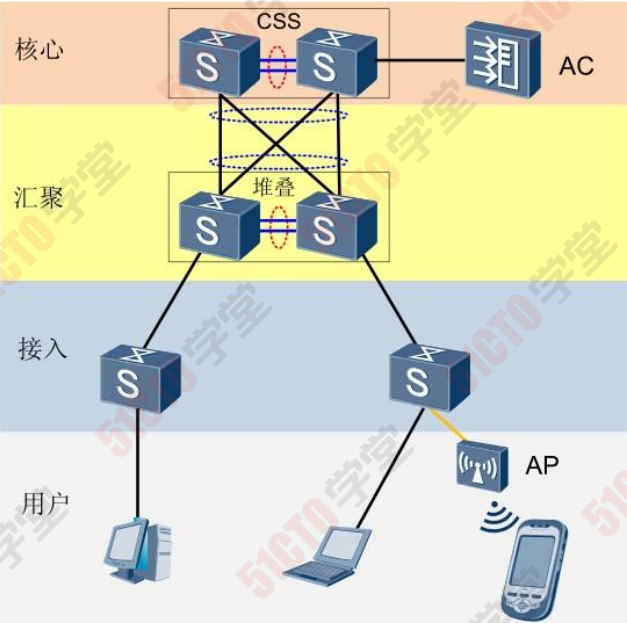
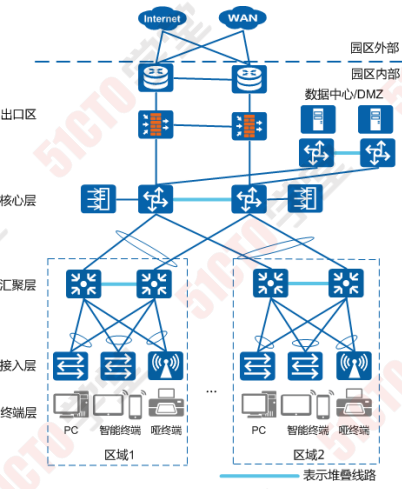
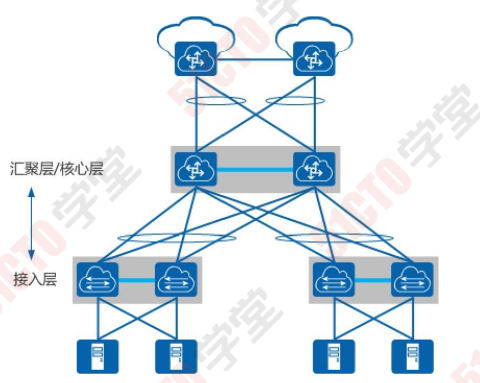
堆叠作为一种横向虚拟化技术,将多台设备在逻辑上虚拟成一 台设备,可以简化网络的配置和管理。同时,结合跨设备链路 聚合技术,不仅可以实现设备及链路的高可靠性备份,而且可 以避免二层环路。相对传统的STP破环保护,逻辑拓扑更加清 晰、链路利用更加高效。
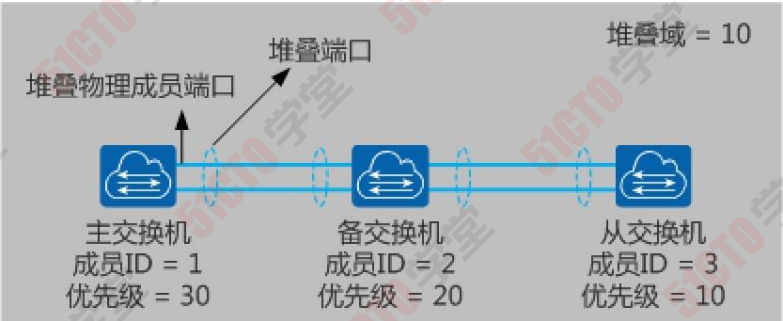
10.1 华为堆叠原理

10.2 华三交换机堆叠
sw1:
[sw1] irf member 1 priority 5 #将sw1优先级配置为5使其成为master,不配置的话是1
[sw1] interface Ten-GigabitEthernet1/0/49 #先关闭堆叠口
[sw1-Ten-GigabitEthernet1/0/49] shutdown
[sw1] irf-port 1/1 #创建irf接口1/1
[sw1-irf-port1/1] port group interface Ten-GigabitEthernet1/0/49 #物理接口加入irf接口
注意:
irf-port 1/1: 前一个1表示member ID ,后一个1 表示 irf 接口ID
注意2:
第二数字最多是2,即一台交换机上的IRF port 接口最多 有两个,而且irf port接口连接时必须交叉连接。
例如:1/1--2/2 2/1---3/2
sw2:
[sw2] irf member 1 renumber 2 #把sw2重新编号2
Renumbering the member ID may result in configuration change or loss. Continue?[Y/N]:Y
Please reboot the device for the new member ID to take effect.
# 保存重启生效
<sw2>save
The current configuration will be written to the device. Are you sure? [Y/N]:Y
Please input the file name(*.cfg)[flash:/startup.cfg]
(To leave the existing filename unchanged, press the enter key):
Validating file. Please wait...
Saved the current configuration to mainboard device successfully.
<sw2>reboot
Start to check configuration with next startup configuration file, please wait.........DONE!
This command will reboot the device. Continue? [Y/N]:Y
Now rebooting, please wait......
#和sw1一样配置堆叠口
[sw2] interface Ten-GigabitEthernet 2/0/49 #先关闭物理接口
[sw2-Ten-GigabitEthernet2/0/49] shutdown
[sw2] irf-port 2/2
[sw2-irf-port2/2] port group interface Ten-GigabitEthernet 2/0/49
以上配置完成之后分别启动堆叠物理接口并保存配置:
sw1:
[sw1] interface Ten-GigabitEthernet 1/0/49
[sw1-Ten-GigabitEthernet1/0/49] undo shutdown
<sw1> save
[sw1] irf-port-configuration active
sw2:
[sw2] interface Ten-GigabitEthernet 2/0/49
[sw2-Ten-GigabitEthernet2/0/49] undo shutdown
<sw2> save
[sw2] irf-port-configuration active
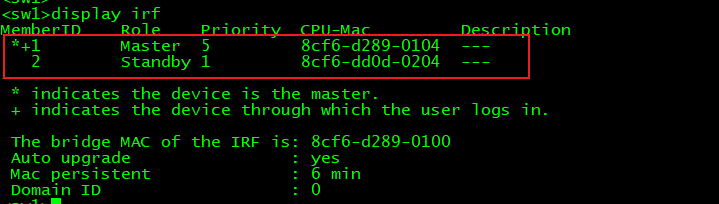
10.3 华为交换机配置堆叠
10.3.1 单线路堆叠
步骤1: 如果有堆叠卡是可以不用配置的,没有的话就需要把业务口配置成堆叠口,首先要按需求把两台交换机的堆叠口连接起来。
步骤2:分配设备编号(堆叠ID)(可选)
[Huawei] stack slot 0 renumber 1
<Huawei> save
<Huawei> reboot
接口编号就从0变为了1,这个命令可以在从(备)交换机上配置,配置后重启生效。
也可以实用如下命令查看编号:
<Huawei> display stack
步骤3:配置优先级,当然这个步骤你不需要指定哪台成为主交换机也是可选的。默认是100,数字越大优先级越高。
可以修改主交换机的优先级,把它改大。
[Huawei] stack slot 0 priority 200
步骤4:指定堆叠接口,两台交换机上指定堆叠接口
SwitchA:
[HUAWEI] interface stack-port 0/1
[HUAWEI-stack-port0/1] port interface Gigabitethernet 0/0/28 enable //将物理接口加入逻辑堆叠口1
PS:0代表设备编号(堆叠ID),1代表堆叠接口编号,每个设备可以创建两个堆叠口,堆叠接口编号需要“交叉”(言外之意就是不能一样)。
SwitchB:
[HUAWEI] interface stack-port 1/2
[HUAWEI-stack-port1/2] port interface Gigabitethernet 0/0/28 enable //将物理接口加入逻辑堆叠口1
10.3.2 双线路堆叠(推荐)
双机堆叠
sw1和sw2进行堆叠
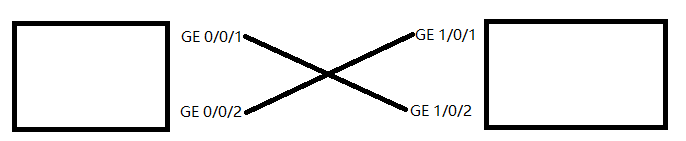
配置sw1的业务口GigabitEthernet0/0/1、GigabitEthernet0/0/2为物理成员端口,并加入到相应的逻辑堆叠端口。
sw1:
[HUAWEI] stack slot 0 priority 200 #修改优先级,默认为100,值越大优先级越高
[HUAWEI] interface stack-pork 0/1
[HUAWEI-stack-port0/1] port interface Gigabitethernet 0/0/1 enable
[HUAWEI-stack-port0/2] interface stack-port 0/2
[HUAWEI-stack-port0/2] port interface Gigabitethernet 0/0/2 enable
不配置堆叠成员号和优先级,使用默认的成员号0和默认的优先级100
sw2:
[Huawei] stack slot 0 renumber 1 #修改堆叠成员号,默认为0,这里修改为1
[Huawei] quit
<Huawei> save
<Huawei> reboot
[HUAWEI] interface stack-pork 0/1
[HUAWEI-stack-port0/1] port interface Gigabitethernet 0/0/1 enable
[HUAWEI-stack-port0/2] interface stack-port 0/2
[HUAWEI-stack-port0/2] port interface Gigabitethernet 0/0/2 enable
如上图配置完成后线缆要交叉插入交换机。
10.4 华为交换机配置集群(集群卡)
注意:只有7700往上的设备采用集群的模式,往下是用堆叠
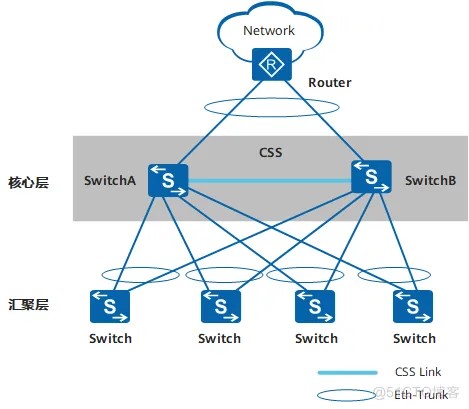
1.组网需求
核心层SwitchA和SwitchB两台交换机采取集群卡集群方式进行组网,其中SwitchA为主交换机,SwitchB为备交换机。汇聚层Switch通过Eth-Trunk连接到集群系统,同时集群系统通过Eth-Trunk接入上行网络。
2.配置思路
-
为SwitchA和SwitchB分别安装集群卡并连接集群线缆。
-
在SwitchA和SwitchB上分别配置集群连接方式,配置集群ID分别为1和2,配置集群优先级分别为200和100,以提高SwitchA成为主交换机的可能。
-
先使能SwitchA的集群功能,然后再使能SwitchB的集群功能,以保证SwitchA成为主交换机。
-
检查集群组建是否成功。
-
配置集群系统的下行Eth-Trunk,增加转发带宽,提高可靠性
3.操作步骤
3.1 配置集群连接方式、集群ID及集群优先级
配置SwitchA的集群连接方式为集群卡集群,集群ID为1,集群优先级为200。
1. <HUAWEI> system-view
2. [HUAWEI] sysname SwitchA
3. [SwitchA] set css mode css-card
4. [SwitchA] set css id 1
5. [SwitchA] set css priority 200
配置SwitchB的集群连接方式为集群卡集群,集群ID为2,集群优先级为100。
1. <HUAWEI> system-view
2. [HUAWEI] sysname SwitchB
3. [SwitchB] set css mode css-card
4. [SwitchB] set css id 2
5. [SwitchB] set css priority 100
3.2 查看集群配置信息
查看SwitchA上的集群配置信息。
1. [SwitchA] display css status saved
2. Current Id Saved Id CSS Enable CSS Mode Priority Master force
3. -----------------------------------------------------------------------------
4. 1 1 Off CSS card 200 Off
查看SwitchB上的集群配置信息。
1. [SwitchB] display css status saved
2. Current Id Saved Id CSS Enable CSS Mode Priority Master force
3. ------------------------------------------------------------------------------
4. 1 2 Off CSS card 100 Off
3.3使能集群功能
使能SwitchA的集群功能并重新启动SwitchA。
1. [SwitchA] css enable
2. Warning: The CSS configuration will take effect only after the system is rebooted. T
3. he next CSS mode is CSS card. Reboot now? [Y/N]:y
使能SwitchB的集群功能并重新启动SwitchB。
1. [SwitchB] css enable
2. Warning: The CSS configuration will take effect only after the system is rebooted. T
3. he next CSS mode is CSS card. Reboot now? [Y/N]:y
3.4检查集群组建是否成功
查看指示灯状态。
SwitchA集群卡上MASTER灯常亮,表示该集群卡所在的主控板为集群系统主用主控板,SwitchA为主交换机。
SwitchB集群卡上MASTER灯常亮,表示SwitchB为备交换机。
# 通过任意主控板上的Console口本地登录集群,使用命令行查看集群组建是否成功。
<SwitchA> display device
Chassis 1 (Master Switch)
S7712's Device status:
Slot Sub Type Online Power Register Status Role
-------------------------------------------------------------------------------
1 - ES0D0X12SA00 Present PowerOn Registered Normal NA
9 - ES1D2S08SX1E Present PowerOn Registered Normal NA
12 - ES0D0X12SA00 Present PowerOn Registered Normal NA
13 - ES1D2SRUE000 Present PowerOn Registered Normal Master
1 ES1D2VS04000 Present PowerOn Registered Normal NA
14 - ES1D2SRUE000 Present PowerOn Registered Normal Slave
1 ES1D2VS04000 Present PowerOn Registered Normal NA
PWR1 - - Present PowerOn Registered Normal NA
PWR2 - - Present PowerOn Registered Normal NA
CMU1 - EH1D200CMU00 Present PowerOn Registered Normal Master
FAN1 - - Present PowerOn Registered Normal NA
FAN2 - - Present PowerOn Registered Normal NA
FAN3 - - Present PowerOn Registered Normal NA
FAN4 - - Present PowerOn Registered Normal NA
Chassis 2 (Standby Switch)
S7712's Device status:
Slot Sub Type Online Power Register Status Role
-------------------------------------------------------------------------------
1 - ES0D0X12SA00 Present PowerOn Registered Normal NA
9 - ES1D2S08SX1E Present PowerOn Registered Normal NA
12 - ES0D0X12SA00 Present PowerOn Registered Normal NA
13 - ES1D2SRUE000 Present PowerOn Registered Normal Master
1 ES1D2VS04000 Present PowerOn Registered Normal NA
14 - ES1D2SRUE000 Present PowerOn Registered Normal Slave
1 ES1D2VS04000 Present PowerOn Registered Normal NA
PWR1 - - Present PowerOn Registered Normal NA
PWR2 - - Present PowerOn Registered Normal NA
CMU1 - EH1D200CMU00 Present PowerOn Registered Normal Master
FAN1 - - Present PowerOn Registered Normal NA
FAN2 - - Present PowerOn Registered Normal NA
FAN3 - - Present PowerOn Registered Normal NA
FAN4 - - Present PowerOn Registered Normal NA
以上显示信息中,能够查看到两台成员交换机的单板状态,表示集群建立完成。
查看集群链路状态是否正常。
<SwitchA> display css channel
CSS link-down-delay: 0ms
Chassis 1 || Chassis 2
================================================================================
Num Slot HG Port (Status) || Port (Status) Slot HG
1 1/13 0/13 -- 1/13/0/1(UP 10G) ---||--- 2/13/0/1(UP 10G) -- 2/13 0/12
2 1/13 0/14 -- 1/13/0/4(UP 10G) ---||--- 2/13/0/4(UP 10G) -- 2/13 1/13
3 1/14 0/13 -- 1/14/0/1(UP 10G) ---||--- 2/14/0/1(UP 10G) -- 2/14 0/12
4 1/14 0/14 -- 1/14/0/4(UP 10G) ---||--- 2/14/0/4(UP 10G) -- 2/14 1/13
以上显示信息中,集群链路均为UP,表示集群链路正常,至此可以说明集群组建完全成功。
10.5 华为交换机配置集群(业务口)
1.开机(两台交换机),做堆叠配置
配置LSW1的集群优先级为200(值大的优先),集群连接方式为业务口连接方式。
[lsw1] set css mode lpu
[lsw1] set css id 1
[lsw1] set css priority 200
配置LSW2的集群ID、优先级100,集群连接方式
[lsw2] set css mode lpu
[lsw2] set css id 2
[lsw2] set css priority 100
配置lsw1的业务口XGE0/0/46~XGE0/0/47为集群物理成员端口并加入集群端口。
[lsw1] interface css-port 1
[lsw1-css-port1] port interface xgigabitethernet 0/0/46 to xgigabitethernet 0/0/47 enable
配置lsw2的业务口XGE0/0/46~XGE0/0/47为集群物理成员端口并加入集群端口。
[lsw1] interface css-port 1
[lsw1-css-port1] port interface xgigabitethernet 0/0/46 to xgigabitethernet 0/0/47 enable
2.保存配置 save
- 执行css enable
[lsw1] save
[lsw1] css enable
Warning: The CSS configuration takes effect only after the system is rebooted. The next CSS mode is lpu. Reboot now? [Y/N]:y
[lsw2] save
[lsw2] css enable
Warning: The CSS configuration takes effect only after the system is rebooted. The next CSS mode is lpu. Reboot now? [Y/N]:y
4.重启下点的时候,接上光纤。
5.验证接口已经是集群并且是up的
display interface brief
display css channel
可以看到所有端口都变成四维的了
Chassis 1 || Chassis 2
================================================================================
Num [Css-port] [Lpu Port] || [Lpu Port] [Css-port]
1 1/1 XGigabitEthernet1/0/0/1 XGigabitEthernet2/0/0/1 2/1
2 1/1 XGigabitEthernet1/0/0/2 XGigabitEthernet2/0/0/2 2/1
3 1/1 XGigabitEthernet1/0/0/3 XGigabitEthernet2/0/0/3 2/1
4 1/1 XGigabitEthernet1/0/0/4 XGigabitEthernet2/0/0/4 2/1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号