【项目实战】kaggle产品分类挑战
多分类特征的学习
这里还是b站刘二大人的视频课代码,视频链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=9
相关注释已经标明了(就当是笔记),因此在这里不多赘述,今天的主要目的还是Kaggle的题目
import torch
from torchvision import transforms # 图像处理工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
# 可以把传入的图像变成一个数值在0到1之间的张量,这里的均值和标准差都是算好的
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
text_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(text_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
# 使用交叉熵损失他的作用是尽量保持当前梯度的变化方向。
# 没有动量的网络可以视为一个质量很轻的棉花团,风往哪里吹就往哪里走,一点风吹草动都影响他,四处跳
# 动不容易学习到更好的局部最优。没有动力来源的时候可能又不动了。加了动量就像是棉花变成了铁球,
# 咕噜咕噜的滚在参数空间里,很容易闯过鞍点,直到最低点。可以参照指数滑动平均。优化效果是梯度二阶
# 导数不会过大,优化更稳定,也可以看做效果接近二阶方法,但是计算容易的多。其实本质应该是对参数加了约束
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 这里是一个冲量
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# 前馈反馈和更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累积的loss拿入
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0 # 正确的数量
total = 0 # 总数
with torch.no_grad():
for data in test_loader: # 拿出每一行里面最大值的下标
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item() # 计算猜对的数量
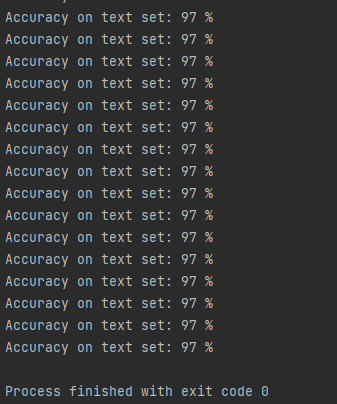
print('Accuracy on text set: %d %%' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
# 到97就跑不上去了,毕竟这就是一个很简单的前馈网络
然后这里是结果
赛题及阅读
本题的kaggle网址在此:https://www.kaggle.com/competitions/otto-group-product-classification-challenge
然后数据集一个train一个text,train,这个挑战主要是给一堆商品数据,这些商品分为9类,每个商品有93个特征,需要你来进行一个模型学习,在测试集中完成分类
原文翻译如下:
在本次比赛中,我们为20多万种产品提供了一个包含93个功能的数据集。我们的目标是建立一个预测模型,能够区分我们的主要产品类别。获奖模型将是开源的。
数据处理
首先我们的数据长成这样


显然我们的target里面的就是我们要学习的标签值,但是他是一个string类型,这个我们可以进行转换
def class2num(brands):
brands_out = []
brand_in = ['class1', 'class2', 'class3', 'class4', 'class5', 'class6', 'class7', 'class8', 'class9']
for brand in brands: //循环的读传入的数据
brands_out.append(brand_in.index(brand)) ##获取当前值在brand_in的索引,巧妙的让他数字化
return brands_out
然后再定义处理数据的函数
class ProductData(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
brand = xy['target']
self.len = xy.shape[0]
self.x_data = torch.tensor(np.array(xy)[:, 1:-1].astype(float)) # 把xy转换成np的array数组然后读取里面的数据,并进行数据转换
self.y_data = class2num(brand)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
再传入数据,定义小批量梯度下降的规模
train_data = ProductData('train.csv')
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0)
模型设计
再开始设计模型,因为我们的最后分类是9,而特征有93个,所以需要把93降到9
这里是我们定义的模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 72)
self.l2 = torch.nn.Linear(72, 36)
self.l3 = torch.nn.Linear(36, 18)
self.l4 = torch.nn.Linear(18, 9)
def forward(self, x):
x = x.view(-1, 93)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
同时在Net的下面我还决定按照昨天的代码编写思路,写上测试的函数
def test(self, x):
with torch.no_grad():
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
_, predict = torch.max(x, dim=1)
# 代码中一个独立的下划线,表示这个变量不重要一个独立的下划线,它也是一个变量名,只不过它比较特殊,当你使用下划线作为变量名时,就代表你告诉大家,这个变量不重要,仅仅占个位置,可以忽略,后面不会再使用它。
y = pd.get_dummies(predict) # 把predict转换成独热向量
return y
实例化模型,并确定损失函数和优化器
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
训练
if __name__ == '__main__':
for epoch in range(200):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0): //用batch_idx, data获取enumerate的值
inputs, target = data
inputs = inputs.float()
optimizer.zero_grad()
outputs = model(inputs) // 放进模型
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累积的loss拿入
if batch_idx % 300 == 299: # 每300轮输出一次
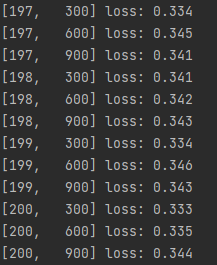
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
这就是小批量梯度下降的训练写法
训练结果如下
测试
按照要求来测试数据集并且输出一个csv
test_data = pd.read_csv('test.csv') # 读取测试集
test_inputs = torch.tensor(np.array(test_data)[:, 1:].astype(float)) # 读取特征
out = model.test(test_inputs.float()) # 传入模型并且用out来接受得到的值
lables=['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
out.columns = lables # 用lables作为标签
out.insert(0, 'id', test_data['id']) # 对应的标签插入值,insert() 函数用于将指定对象插入列表的指定位置
output = pd.DataFrame(out) # 输出成一个dataframe
output.to_csv('my_predict.csv', index=False) # 输出为csv文件
放进kaggle看看
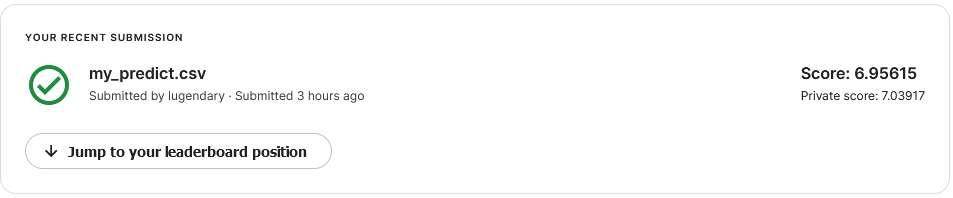
分数不太行嗷
改变一下动量看看(改成0.1)

稍微好一点
以下是完整代码
import numpy as np
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn.functional as F
import torch.optim as optim
def class2num(brands):
brands_out = []
brand_in = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
for brand in brands:
brands_out.append(brand_in.index(brand))
return brands_out
class ProductData(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
brand = xy['target']
self.len = xy.shape[0]
self.x_data = torch.tensor(np.array(xy)[:, 1:-1].astype(float)) # 把xy转换成np的array数组然后读取里面的数据,并进行数据转换
self.y_data = class2num(brand)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
train_data = ProductData('train.csv')
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 72)
self.l2 = torch.nn.Linear(72, 36)
self.l3 = torch.nn.Linear(36, 18)
self.l4 = torch.nn.Linear(18, 9)
def forward(self, x):
x = x.view(-1, 93)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
def test(self, x):
with torch.no_grad():
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
_, predict = torch.max(x, dim=1)
# 代码中一个独立的下划线,表示这个变量不重要一个独立的下划线,它也是一个变量名,只不过它比较特殊,当你使用下划线作为变量名时,就代表你告诉大家,这个变量不重要,仅仅占个位置,可以忽略,后面不会再使用它。
y = pd.get_dummies(predict) # 把predict转换成独热向量
return y
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.1)
if __name__ == '__main__':
for epoch in range(200):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs = inputs.float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累积的loss拿入
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
# 测试
test_data = pd.read_csv('test.csv')
test_inputs = torch.tensor(np.array(test_data)[:, 1:].astype(float))
out = model.test(test_inputs.float())
lables=['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
out.columns = lables
out.insert(0, 'id', test_data['id'])
output = pd.DataFrame(out)
output.to_csv('my_predict.csv', index=False)
全梯度
故技重施,搞一下直接梯度下降看看,训练5w遍
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
import torch.optim as optim
def class2num(brands):
brands_out = []
brand_in = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
for brand in brands:
brands_out.append(brand_in.index(brand))
return brands_out
xy = pd.read_csv('train.csv')
brand = xy['target']
len = xy.shape[0]
x_data = torch.tensor(np.array(xy)[:, 1:-1].astype(float)) # 把xy转换成np的array数组然后读取里面的数据,并进行数据转换
y_data = torch.tensor(class2num(brand))
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 72)
self.l2 = torch.nn.Linear(72, 36)
self.l3 = torch.nn.Linear(36, 18)
self.l4 = torch.nn.Linear(18, 9)
def forward(self, x):
x = x.view(-1, 93)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
def test(self, x):
with torch.no_grad():
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
_, predict = torch.max(x, dim=1)
# 代码中一个独立的下划线,表示这个变量不重要一个独立的下划线,它也是一个变量名,只不过它比较特殊,当你使用下划线作为变量名时,就代表你告诉大家,这个变量不重要,仅仅占个位置,可以忽略,后面不会再使用它。
y = pd.get_dummies(predict) # 把predict转换成独热向量
return y
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.1)
if __name__ == '__main__':
for epoch in range(50000):
x_data = x_data.float()
optimizer.zero_grad()
outputs = model(x_data)
loss = criterion(outputs, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 测试
test_data = pd.read_csv('test.csv')
test_inputs = torch.tensor(np.array(test_data)[:, 1:].astype(float))
out = model.test(test_inputs.float())
lables=['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
out.columns = lables
out.insert(0, 'id', test_data['id'])
output = pd.DataFrame(out)
output.to_csv('my_predict.csv', index=False)
这次训练速度肉眼可见的慢,慢的一批
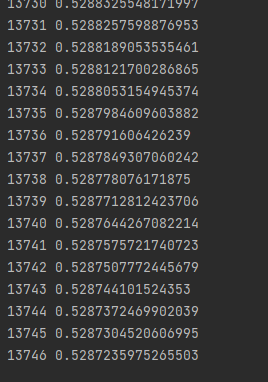
下降的也非常缓慢,基本可以判断是碰到局部最优了,毕竟刚刚那个200次就loss就0.3了
最后我们再用随机梯度下降试试,只需要把batchsize改成1即可
慢的就离谱。。。。
半天就跑这么点
那没事了
结束今天的学习!
本文来自博客园,作者:Lugendary,转载请注明原文链接:https://www.cnblogs.com/lugendary/p/16151086.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号