

自然语言处理中的迁移学习(下)

本文小结:本文为教程的第二篇,包含教程的 3-6 部分。
相关链接:赛尔笔记 | 自然语言处理中的迁移学习(上)
提纲

-
介绍:本节将介绍本教程的主题:迁移学习当前在自然语言处理中的应用。在不同的迁移学习领域中,我们主要定位于顺序迁移学习 sequential transfer learning 。
-
预训练:我们将讨论无监督、监督和远程监督的预训练方法。
-
表示捕获了什么:在讨论如何在下游任务中使用预训练的表示之前,我们将讨论分析表示的方法,以及观察到它们捕获了哪些内容。
-
调整:在这个部分,我们将介绍几种调整这些表示的方法,包括特征提取和微调。我们将讨论诸如学习率安排、架构修改等的实际考虑。
-
下游应用程序:本节,我们将重点介绍预训练的表示是如何被用在不同的下游任务中的,例如文本分类、自然语言生成、结构化预测等等。
-
开放问题和方向:在最后一节中,我们将提出对未来的展望。我们将突出待解决的问题以及未来的研究方向。
3. 表示捕获了什么
为什么要关心表示捕获了什么?
Swayamdipta, 2019
-
在下游任务进行的外部评估
-
复杂多样,随特定任务而不同
-
Language-aware representations 语言感知表示
-
泛化到其他任务的新的输入
-
作为可能改进预训练工作的中间步骤
-
可解释!
-
我们得到结果的原因是否正确?
-
发现偏见……
分析什么?

-
嵌入
-
单词
-
上下文的
-
网络激活
-
变化
-
结构 (RNN / Transformer)
-
层
-
预训练目标
分析方法 1:可视化
保持嵌入/网络激活静态或冻结
可视化嵌入
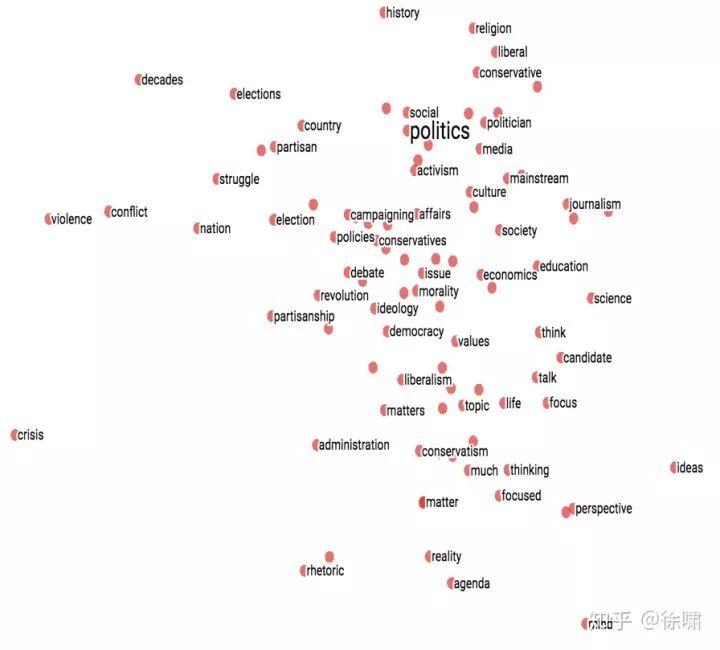
-
在低维(2D/3D)空间内绘制嵌入
-
t-SNE (van der Maaten & Hinton, 2008)
-
PCA projections

-
可视化单词类比 (Mikolov et al. 2013)
-
空间关联
-
![]()
-
词汇语义的高级视图
-
只有有限的例子
-
与其他任务的连接尚不清楚 (Goldberg, 2017)

Radford et al., 2017
-
神经元激活值与特征/标签相关

Karpathy et al., 2016
-
标识学习可识别的功能
-
如何选择某个神经元?难以扩展!
-
可解释 != 重要(Morcos et al., 2018)

-
流行于机器翻译,或其他seq2seq架构:
-
源字与目标字之间的对齐。
-
长距离词与词之间的依赖(句内注意)
-
结构上的亮点
-
拥有复杂的注意力机制可能是一件好事!
-
分层的
-
解释可能很棘手
-
只有几个例子?
-
Robust corpus-wide trends? Next !
Attention is not explanation | Attention is not not explanation
分析方法 2: 行为探测器

-
RNN-based 语言模型
-
主谓关系中的数字一致性 number agreement in subject-verb dependencies
-
自然的、不自然的或不合语法的句子
-
对输出困惑度进行评估
-
RNNs优于其他非神经方法的 Baseline

-
当显式地使用语法训练时,性能会提高(Kuncoro et al. 2018)
Linzen et al., 2016; Gulordava et al. 2018; Marvin et al., 2018
-
这种 probe 可能易受共现偏差的影响
-
“dogs in the neighborhood bark(s)”
-
以前的句子可能和原来的太不一样了…
分析方法 3: Classifier Probes
保持嵌入/网络激活并在顶部训练一个简单的监督模型
探测表层特征
-
给定一个句子,预测属性如
-
长度
-
这个句子里有一个单词吗?
-
给出句子中的单词的预测属性,例如:
-
以前见过的词,与语言模型形成对比
-
词在句子中的位置
-
检查记忆的能力
-
训练有素的、更丰富的体系结构往往运行得更好
-
在语言数据上训练能记忆的更好
Zhang et al. 2018; Liu et al., 2018; Conneau et al., 2018
探测词法,句法,语义

-
词法学
-
词级别的语法
-
POS tags, CCG supertags
-
Constituent parent, grandparent
-
部分语法
-
依赖关系
-
部分语义
-
实体关系
-
共指
-
角色
Adi et al., 2017; Conneau et al., 2018; Belinkov et al., 2017; Zhang et al., 2018; Blevins et al., 2018; Tenney et al. 2019; Liu et al., 2019
探测分类结果
-
Contextualized > non-contextualized
-
尤其是在句法任务上
-
更紧密的语义任务表现
-
双向上下文很重要
-
BERT (large) 几乎总是获得最佳效果
-
Grain of salt: 不同的上下文表示在不同的数据上训练,使用不同的架构……
探测网络各层
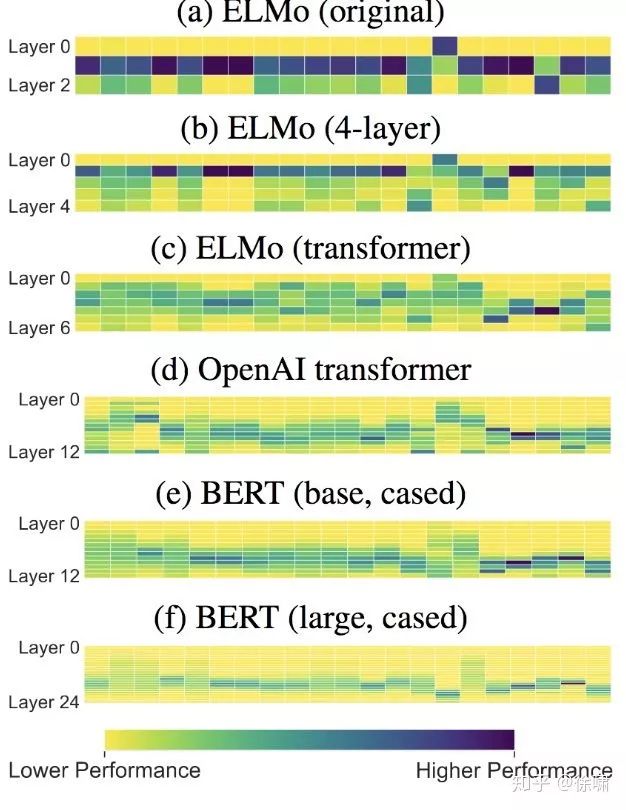
Fig. from Liu et al. (NAACL 2019)
李如 对该篇文章做了简洁的总结
-
CWRs(上下文词表征)编码了语言的哪些特征?
-
在各类任务中,BERT>ELMo>GPT,发现“bidirectional”是这类上下文编码器的必备要素
-
相比于其他任务,编码器们在NER和纠错任务表现较差 => 没有捕获到这方面信息
-
在获得CWRs编码后,再针对任务增加MLP(relu)或者LSTM会提升效果
-
引出了问题:什么时候直接fine-tune编码器?什么时候freeze编码器,增加task-specific layer?
-
编码器中不同层的迁移性是怎样变化的?
-
对于ELMo(LSTM)来说,靠前的层更 transferable,靠后的层更 task-specific
-
对于 Transformer 来说,靠中间的层更 transferable ,但是把各个层加权起来的效果会更好
-
模型需要进行 trade off ,在任务上表现越好,迁移性越差
-
预训练任务会对任务和迁移性有怎样的影响?
-
双向语言模型预训练出来平均效果越好
-
预训练任务越接近特定任务,在特定任务的表现越好
-
预训练数据越多,表现越好
以上引用其总结的三点并稍作修改
-
RNN 的各层:通用语言属性
-
最低层:形态学
-
中间层:语法
-
最高层次:特定于任务的语义
-
Transformer 的各层
-
不同任务的不同趋势;middle-heavy
-
参见Tenney et. al., 2019
探测预训练目标

Zhang et al., 2018; Blevins et al., 2018; Liu et al., 2019;
-
语言建模优于其他非监督和监督目标。
-
机器翻译
-
依存分析
-
Skip-thought 预测上下文的句子
-
低资源时(训练数据的大小)可能导致相反的趋势。
迄今为止我们学到了什么?
-
表征是对某些语言现象的预测:
-
翻译中的对齐,句法层次结构
-
有语法和没有语法的预训练:
-
有语法的预训练具有更好的性能
-
但是如果没有语法,至少还是会学到些语法概念 (Williams et al. 2018)
-
网络架构决定了表示中的内容
-
句法与Bert Transformer (Tenney et al., 2019; Goldberg, 2019)
-
跨架构的不同的逐层趋势
关于探测器的开放问题
-
一个好的探测器应该寻找什么信息?
-
Probing a probe!
-
探测性能告诉我们什么?
-
很难综合各种基线的结果…
-
它本身会带来一些复杂性吗
-
线性或非线性分类
-
行为:输入句子的设计
-
我们应该使用 probe 作为评估指标吗?
-
可能会破坏目的…
分析方法 4:改变模型
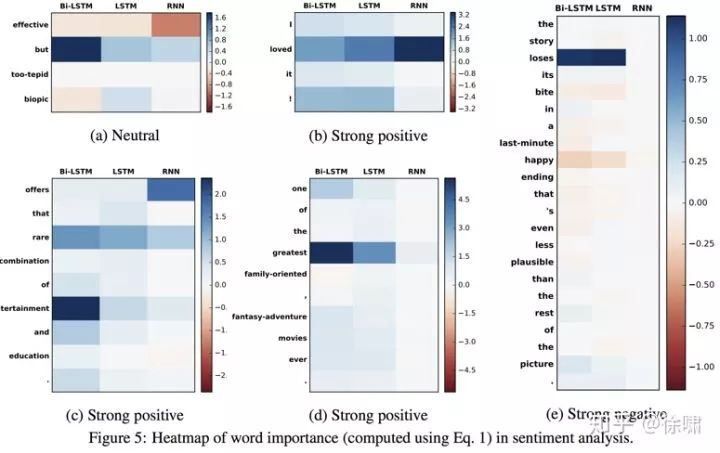
Li et al., 2016
-
逐步删除或屏蔽网络组件
-
词嵌入维度
-
隐藏单位
-
输入——单词/短语
表示捕捉到了什么?
-
这要看你怎么看了!
-
可视化:
-
鸟瞰
-
很少的样本——可能会让人想起 cherry-picking (最佳选择)
-
调查:
-
发现语料层面的特定属性
-
可能会引入自己的偏见…
-
网络修改:
-
对改进建模很有帮助
-
可以是特定于任务的
-
分析方法作为辅助模型开发的工具!
可解释性和可迁移性对下游任务而言是重要的。
4. 调整
如何调整预训练模型
我们可以在几个方向上做决定:
-
结构的修改?
-
为了适应,需要对预训练的模型体系结构进行多大的更改
-
优化方案?
-
在适应过程中需要训练哪些权重以及遵循什么时间表
-
更多信号:弱监督、多任务和集成
-
如何为目标任务获取更多的监督信号
4.1 结构
两个通用选项:
-
保持预训练模型内部不变
-
在顶部添加分类器,在底部添加嵌入,将输出作为特征
-
修改预训练模型的内部架构
-
初始化编码器-解码器、特定于任务的修改、适配器
4.1.1 – 结构:保持模型不变

常规工作流:
-
如果对目标任务无效,则删除预训练的任务头
-
示例:从预训练语言模型中删除softmax分类器
-
不总是需要:一些调整方案重用了预训练的目标/任务,例如用于多任务学习
-
在预训练模型的顶部/底部添加特定于任务的目标层

-
简单:在预训练的模型上添加线性层

-
更复杂的:将模型输出作为单独模型的输入
-
当目标任务需要预训练嵌入中所没有的交互时,通常是有益的
4.1.2 – 结构:修改模型内部
各种各样的原因:
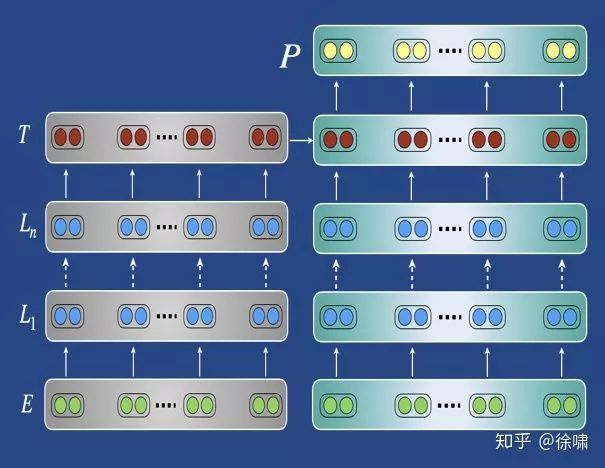
-
适应结构上不同的目标任务
-
例如:使用单个输入序列(例如:语言建模)进行预训练,但是适应多个输入序列的任务(例如:翻译、条件生成……)
-
使用预训练的模型权重尽可能初始化结构不同的目标任务模型
-
例如:使用单语语言模型初始化机器翻译的编码器和解码器参数 (Ramachandran et al., EMNLP 2017; Lample & Conneau, 2019)
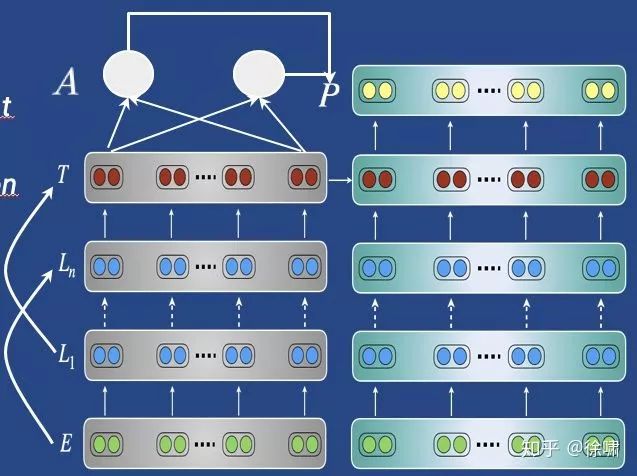
-
特定于任务的修改
-
提供对目标任务有用的预训练模型
-
例如:添加跳过/残差连接,注意力(Ramachandran et al., EMNLP 2017)
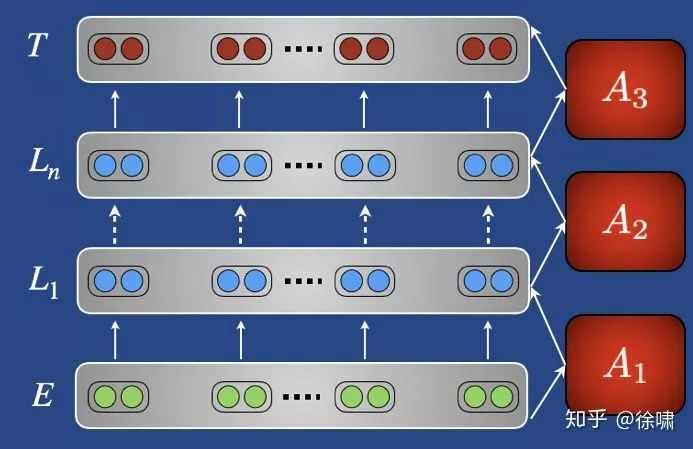
-
使用较少的参数进行调整:
-
更少的参数进行微调
-
在模型参数不断增大的情况下,非常有用
-
例如:在预训练模型的层之间添加瓶颈模块(“适配器”) (Rebuffi et al., NIPS 2017;CVPR 2018)
Adapters
-
通常使用剩余连接与现有层并行的层相连
-
每层之间都放置时效果最佳(底层效果较小)
-
不同的操作(卷积,自我注意)是可能的
-
特别适合 Transformer 等模块化架构 (Houlsby et al., ICML 2019; Stickland and Murray, ICML 2019

Adapters (Stickland & Murray, ICML 2019)
-
多头的关注(MH;跨层共享)与BERT的 self-attention (SA)层并行使用
-
两者都被加在一起,并输入到 Layer-norm (LN)中
4.2 优化
涉及到优化本身的几个方向:
-
选择我们应该更新的权重
-
Feature extraction, fine-tuning, adapters
-
选择如何以及何时更新权重
-
From top to bottom, gradual unfreezing, discriminative fine-tuning
-
考虑实事求是的权衡
-
Space and time complexity, performance
4.2.1 – 优化: 什么权重?
主要问题:调整还是不调整(预先训练好的重量)?
-
不改变预先训练的重量
-
Feature extraction
-
(预训练的)权重被冻结

-
线性分类器是在预训练的表示上进行训练的
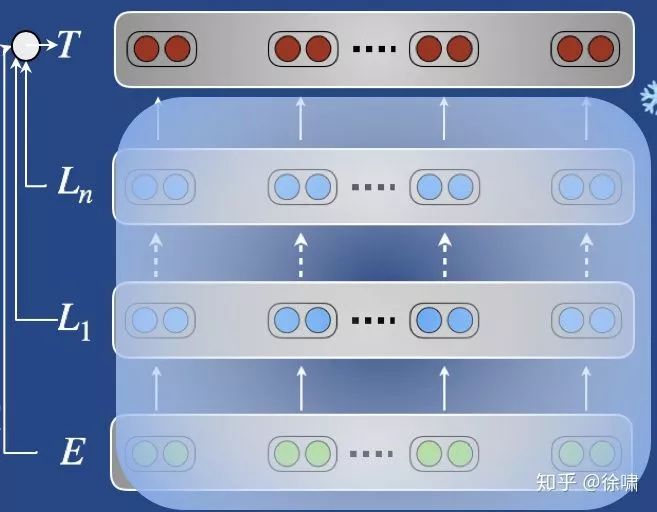
-
不要只使用顶层的特性!
-
学习层的线性组合 (Peters et al., NAACL 2018, Ruder et al., AAAI 2019)

-
或者,在下游模型中使用预先训练的表示作为特性
-
Adapters

-
在现有层之间添加的特定于任务的模块
-
只有 adapters 被训练
-
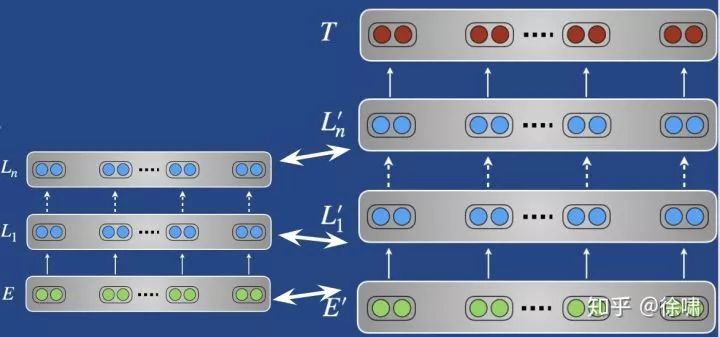
改变预训练权重
-
fine-tuning
-
采用预训练的权重作为下游模型参数的初始化
-
整个预训练的体系结构在适应阶段进行训练
4.2.2 – 优化:什么方式?
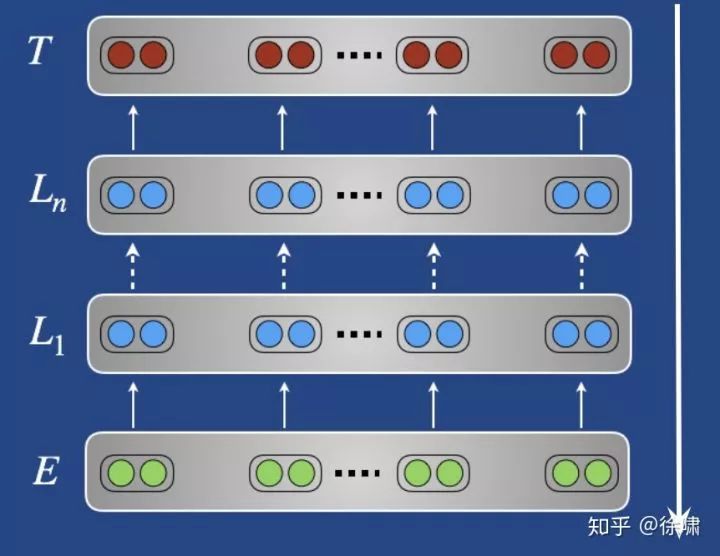
我们已经决定要更新哪些权重,但是以什么顺序以及如何更新它们?
动机:我们希望避免覆盖有用的预训练信息,并最大化积极的知识迁移
相关概念:灾难遗忘 (McCloskey&Cohen, 1989; French, 1999) :一个模型忘记了它最初受过训练的任务
指导原则:从上到下更新
-
时间上逐步更新:冻结
-
强度上逐步更新:改变学习速度
-
Progressively vs. the pretrained model 逐步更新 vs 预训练模型:正则化
优化:冻结
-
主要直觉:在不同分布和任务的数据上同时训练所有层可能导致不稳定的不良解决方案
-
解决方案:单独训练每一层,使他们有时间适应新的任务和数据。
-
回到早期深度神经网络的分层训练(Hinton et al., 2006; Bengio et al., 2007)
相关实例
-
冻结顶层以外的所有层 (Long et al., ICML 2015)
-
Chain-thaw (Felbo et al., EMNLP 2017):每次训练一层
-
先训练新增的层
-
再自底向上,每次训练一层(不再训练新增的那一层,其余层以会在不训练时被同时冻结)
-
训练所有层(包括新增层)
-
Gradually unfreezing (Howard & Ruder, ACL 2018): 逐层解冻(自顶向下)
-
Sequential unfreezing (Chronopoulou et al., NAACL 2019): 超参数控制微调轮数
-
微调 n 轮次新增参数(冻结除了新增层以外的层)
-
微调 k 轮次嵌入层以外的预训练层
-
训练所有层直到收敛
4.2.2 – 优化:学习率
主要想法:使用更低的学习率来避免覆盖掉有用的信息
在哪里以及在什么时候?
-
低层(捕获一般信息)
-
训练初期(模型仍需适应目标分布)
-
训练后期(模型接近收敛)
相关实例 (Howard & Ruder, ACL 2018)
较低层捕获一般信息 → 对较低层使用较低的学习速率
-
Discriminative fine-tuning
-
较低的层捕获一般信息
-
对较低的层次使用较低的学习率
-
![]()
-
Triangular learning rates
-
快速移动到一个合适的区域,然后随着时间慢慢收敛
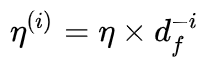
-
也被称为 “learning rate warm-up”
-
用于 Transformer (Vaswani et al., NIPS 2017) 和 Transformer-based methods (BERT, GPT) 等
-
有利于优化;更容易摆脱次优局部极小值
4.2.2 – 优化:正则化
主要思想:通过使用正则化项 ,鼓励目标模型参数接近预先训练的模型参数,将灾难性遗忘最小化。
-
简单的方法:将新参数正则化,不要与预训练的参数偏离太多 (Wiese et al., CoNLL 2017)
-
![]()

-
更高级(elastic weight consolidation; EWC)(Kirkpatrick et al., PNAS 2017)
-
基于 Fisher 信息矩阵 F ,关注对预训练任务重要的参数
-
![]()
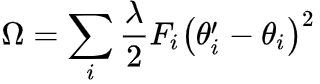
-
EWC在持续学习方面有缺点:
-
可能过度约束参数
-
计算成本与任务数量成线性关系(Schwarz et al., ICML 2018)
-
如果任务相似,我们也可以鼓励基于交叉熵的源和目标预测接近,类似于蒸馏:
-
![]()
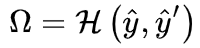
4.2.3 – 优化:权衡
在选择更新哪些权重时,需要权衡以下几个方面:
A. 空间复杂度
-
特定于任务的修改、附加参数、参数重用

B. 时间复杂度
-
训练时间

C. 性能
-
经验法则:如果任务源和目标任务不相似*,使用特征提取 (Peters et al., 2019)
-
否则,特征提取和微调常常效果类似(此时用微调更好)
-
在文本相似性任务上对 BERT 进行微调,效果明显更好
-
适配器实现了与微调相比具有竞争力的性能
-
有趣的是,Transformer 比 LSTMs 更容易微调(对超参数不那么敏感)
*不相似:某些能力(例如句子间关系建模)对目标任务是有益的,但预训练的模型缺乏这些能力能(参见后面的更多内容)
4.3 – 获得更多信号
目标任务通常是低资源任务。我们经常可以通过组合不同的信号,提高迁移学习的效果:
-
在单个适应任务上微调单个模型
-
基本原理:用一个简单的分类目标对模型进行微调
-
其他数据集和相关任务中收集信号
-
微调与弱监督,多任务和顺序调整
-
集成模型
-
结合几个微调模型的预测
4.3.1 – 获得更多信号:基本的 fine-tuning
微调文本分类任务的简单例子:
-
从模型中提取单个定长向量
-
第一个/最后一个令牌的隐藏状态,或者是隐藏状态的平均值/最大值
-
使用附加的分类器投影到分类空间
-
用分类目标函数训练
4.3.2 – 获得更多信号:相关数据集/任务
-
顺序调整 Sequential adaptation
-
对相关数据集和任务进行中间微调
-
与相关任务进行多任务微调
-
如 GLUE 中的 NLI 任务
-
数据集分割
-
当模型在特定的数据片上始终表现不佳时
-
半监督学习
-
使用未标记的数据来提高模型的一致性
4.3.2 – 获得更多信号:顺序调整
在相关高资源数据集进行微调
-
在拥有更多的数据的相关任务对模型进行微调
-
在目标任务上微调数据集
-
对于数据有限并且有类似任务的任务尤其有用(Phang et al., 2018)
-
提高目标任务的样本复杂度(Yogatama et al., 2019)
4.3.2 – 获得更多信号:多任务 fine-tuning
在相关任务上共同微调模型

-
对于每个优化步骤,取样一个任务和一批数据进行训练
-
通过多任务学习训练多轮
-
只在最后几个阶段对目标任务进行微调
使用无监督的辅助任务微调模型

-
语言建模是一个相关的任务!
-
微调语言模型有助于将预训练的参数调整到目标数据集
-
即使没有预训练,也会起到帮助 (Rei et al., ACL 2017)
-
可选退火比
![]() (Chronopoulou et al., NAACL 2019)
(Chronopoulou et al., NAACL 2019) -
作为 ULMFiT 中的一个单独步骤使用
 (Chronopoulou et al., NAACL 2019)
(Chronopoulou et al., NAACL 2019)4.3.2 – 获得更多信号:数据集切分
使用仅在数据的特定子集上训练的辅助头
-
分析模型误差
-
使用启发式方法自动识别训练数据的挑战性子集
-
与主头一起联合训练辅助头
See also Massive Multi-task Learning with Snorkel MeTaL
4.3.2 – 获得更多信号:半监督学习
使用未标记的数据可以使模型预测更加一致
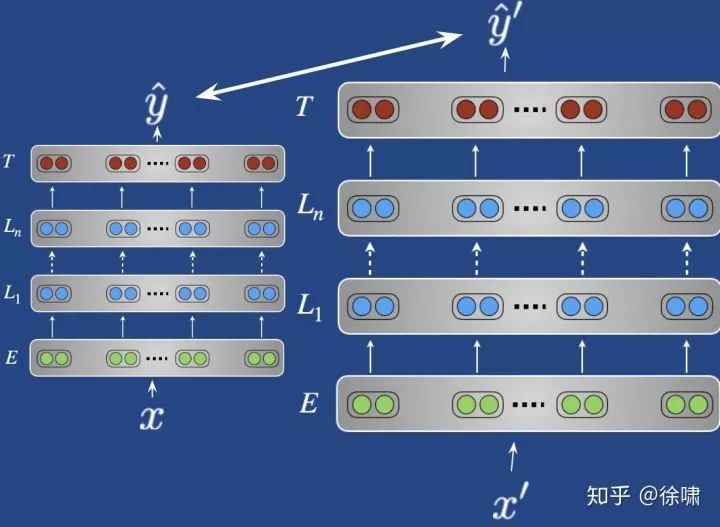
-
主要思想:使对原始输入 x 和扰动输入 x' 的预测之间的距离最小化
-
扰动可以是噪声、掩蔽(Clark et al., EMNLP 2018)、数据增强,例如 back-translation (Xie et al., 2019)
4.3.3 – 获得更多信号:集成
通过集成独立的微调模型达到最先进水平
-
集成模型:使用各种超参数微调模型预测的组合
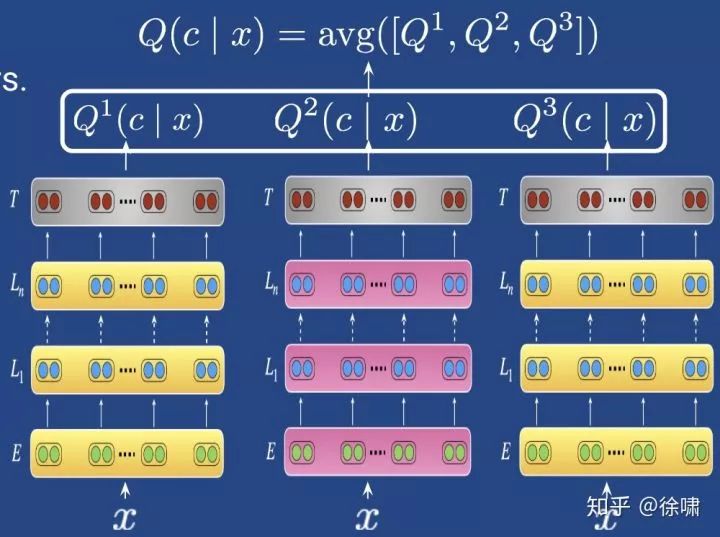
-
在不同的任务
-
在不同的数据集分块
-
使用不同的参数(dropout, initializations…)
-
来自预训练模型的变体(例如 cased/uncased )
-
知识蒸馏:在一个更小的模型中提取一组调优模型

5. 下游应用程序
在本节中,我们将沿两个方向探索下游的应用和实际考虑:
-
迁移学习在自然语言处理中的各种应用是什么
-
文档/句子分类、令牌级分类、结构化预测和语言生成
-
如何利用多个框架和库来实现实际应用
-
Tensorflow、PyTorch、Keras和第三方库,例如 fast.ai, HuggingFace……

-
句子和文档级分类
-
动手实践:文档级分类(fast.ai)
-
令牌分类
-
实践:问答(谷歌BERT & Tensorflow/TF Hub)
-
语言生成
-
实践:对话生成(OpenAI GPT & HuggingFace/PyTorch Hub)
本部分内容偏向编程实践,将在本教程的第三篇中进行补充
5.1 – 句子和文档级别分类
使用 fast.ai 库完成文档分类的迁移学习
-
目标任务
-
IMDB:一个二元情绪分类数据集,包含用于训练的25k个高度极性的电影评论,用于测试的25k个,以及其他未标记的数据。https://ai.stanford.edu/~amaas/data/sentiment/
-
Fast.ai 特别提供了:
-
一个预先训练的英文模型可供下载
-
一个标准化的数据块API
-
易于访问标准数据集,如IMDB
-
fast.ai 基于 PyTorch
fast.ai 为视觉、文本、表格数据和协同过滤提供了许多开箱即用的高级API
库的设计是为了加快实验的速度,例如在互动计算环境中一次导入所有必需的模块,例如:

Fast.ai 包含快速设置迁移学习实验所需的所有高级模块。
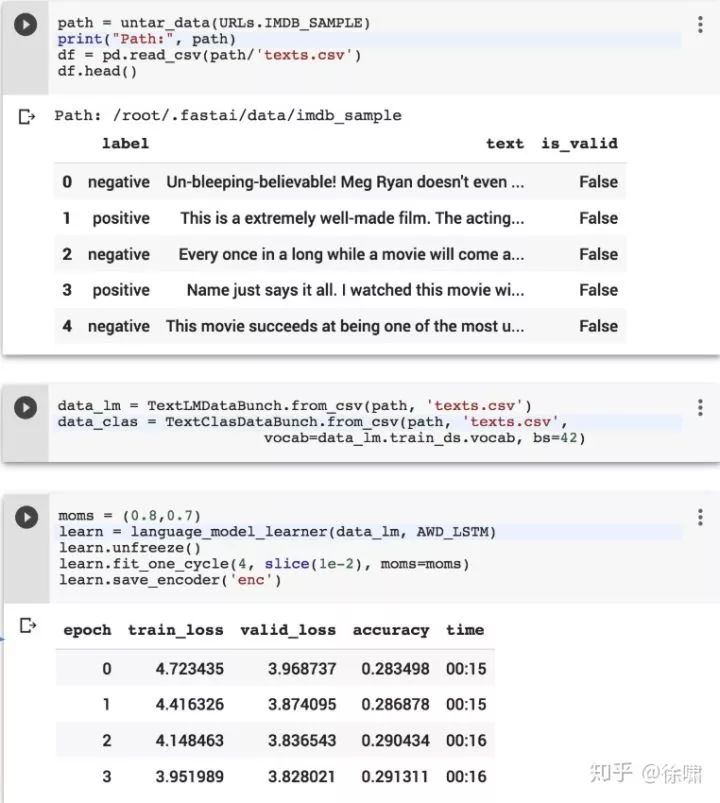
-
加载数据集
-
使用语言模型和分类器的 DataBunch
-
使用语言模型损失函数,在 WikiText-103 上预训练的 AWD-LSTM 并在 IMDB 数据集上微调
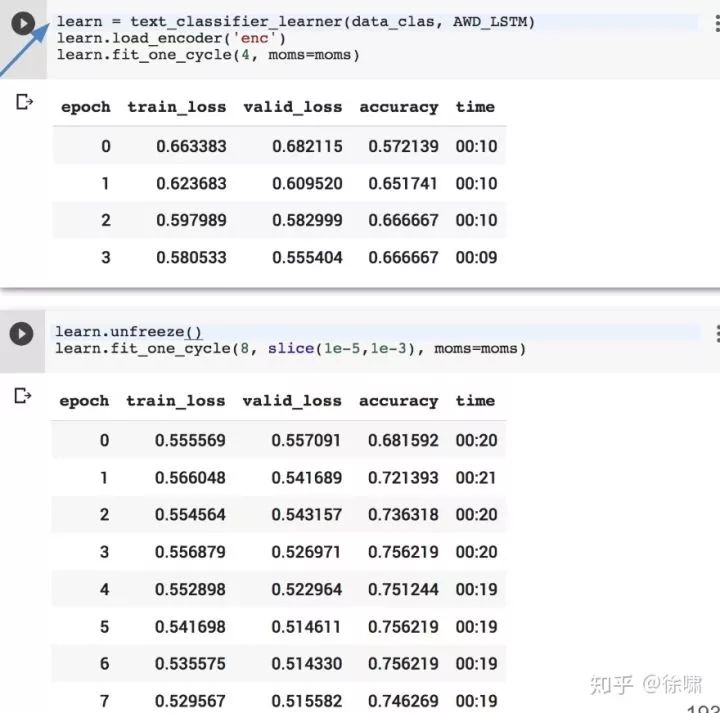
一旦我们有了微调的语言模型(AWD-LSTM),我们可以创建一个文本分类器,添加一个分类头:
-
将RNN的最终输出的最大值与所有中间输出(沿着序列长度)的平均值连接起来的层
-
Two blocks of nn.BatchNorm1d ⇨ nn.Dropout ⇨ nn.Linear ⇨ nn.ReLU 的隐藏维度为50
-
分两步微调
-
只训练分类头,同时保持语言模型不变
-
微调整个结构
-
Colab: tiny.cc/NAACLTransferFastAiColab
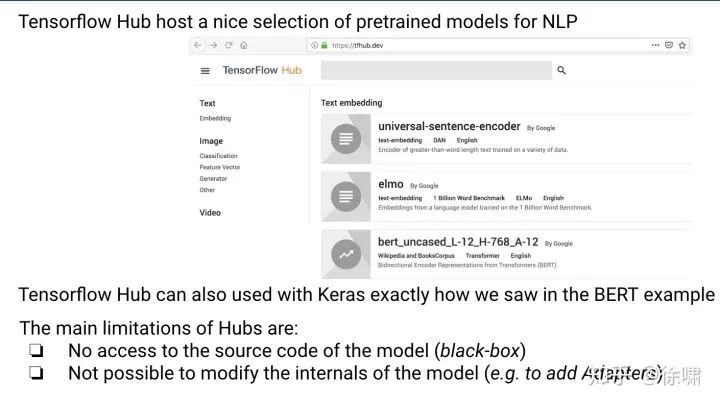
5.2 – Token 级别分类: BERT & Tensorflow
用于令牌级分类的迁移学习:谷歌的 BERT in TensorFlow
-
目标任务:
-
SQuAD: 回答问题的数据集 https://rajpurkar.github.io/SQuAD-explorer/
-
在本例中,我们将直接使用 Tensorflow checkpoint
-
例如:https://github.com/google-research/bert/
-
我们使用通常的Tensorflow工作流:创建包含核心模型和添加/修改元素的模型图
-
加载检查点时要注意变量分配



语言生成迁移学习:OpenAI GPT 和 HuggingFace 库
-
目标任务
-
ConvAI2 -第二届会话智能挑战,用于训练和评估非目标导向对话系统的模型,例如闲聊
-
http://convai.io
-
预训练模型的 HuggingFace 仓库
-
大型预先训练模型 BERT, GPT, GPT-2, Transformer-XL 的仓库
-
提供一个简单的方法来下载、实例化和训练PyTorch中预先训练好的模型
-
HuggingFace的模型现在也可以通过PyTorch Hub访问

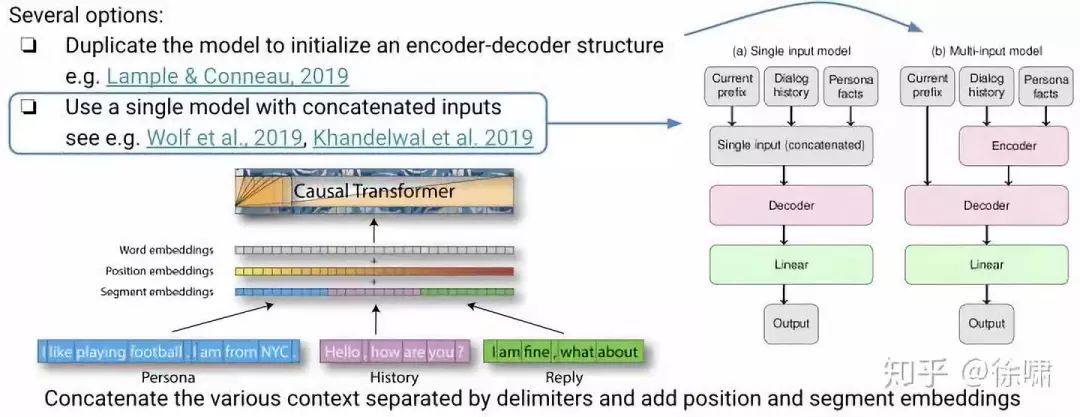
语言生成任务接近语言建模训练前的目标,但是:
-
语言建模前的训练只需要一个输入:一系列单词
-
在对话框设置中:提供了几种类型的上下文来生成输出序列
-
知识库:角色句
-
对话的历史:至少是用户的最后一句话
-
已生成的输出序列的标记
我们应该如何适应这种模式?


6. 开放问题和方向
预训练的语言模型的缺点
-
概述:语言模型可视为一般的预训练任务;有了足够的数据、计算和容量,LM可以学到很多东西
-
在实践中,许多在文本中表示较少的东西更难学习
-
预先训练好的语言模型并不擅长
-
细粒度语言任务 (Liu et al., NAACL 2019)
-
常识(当你真的让它变得困难 Zellers et al., ACL 2019);自然语言生成(维护长期依赖、关系、一致性等)
-
当微调时,倾向于过度适应表面形成的信息;‘rapid surface learners’
大型的、预训练的语言模型很难优化。
-
微调通常是不稳定的,并且有很高的方差,特别是在目标数据集非常小的情况下
-
Devlin et al. (NAACL 2019) 指出,BERT的大版本(24层)特别容易导致性能退化;多次随机重启有时是必要的,这在(Phang et al., 2018)中也有详细的研究
当前的预训练语言模型非常大
-
我们真的需要所有这些参数吗?
-
最近的研究表明,BERT中只需要几个注意力头(Voita et al., ACL 2019)
-
需要做更多的工作来理解模型参数
-
修剪和蒸馏是两种处理方法
-
预训练任务
语言建模目标的不足
-
并不适用于所有模型
-
如果我们需要更多的输入,就需要对这些部件进行预培训
-
例如序列到序列学习中的解码器(Song et al., ICML 2019)
-
从左到右的偏见并不总是最好的
-
考虑更多上下文(如屏蔽)的目标似乎有用(采样效率较低)
-
可能组合不同LM变种(Dong et al., 2019)
-
语义和长期上下文的弱信号与语法和短期单词共存的强信号
-
需要激励机制来促进我们所关心的编码,例如语义
更加多样化的自我监督目标
-
从计算机视觉中获得灵感
-
语言中的自我监督主要基于词的共现(Ando and Zhang, 2005)
-
不同层次意义上的监督
-
论述、文件、句子等
-
使用其他信号,例如元数据
-
强调语言的不同性质

抽样一个补丁和一个邻居,并预测它们的空间配置(Doersch et al., ICCV 2015)

图片着色 (Zhang et al., ECCV 2016)
专门的预训练任务来教我们的模型缺少的东西
-
制定专门的预训练任务,明确学习这些关系
-
获取背景知识的单词对关系 (Joshi et al., NAACL 2019)
-
范围级表示(Swayamdipta et al., EMNLP 2018)
-
不同的预训练词嵌入是有用的(Kiela et al., EMNLP 2018)
-
其他预训练的任务可以明确地学习推理或理解
-
算术、时间、因果等;话语、叙述、谈话等。
-
预训练的表示可以以稀疏和模块化的方式连接
-
基于语言子结构(Andreas et al., NAACL 2016) 或专家 (Shazeer et al., ICLR 2017)
需要更加合理的表示
-
分布式假设的局限性——很难从原始文本中学习特定类型的信息
-
人类报告偏见:不陈述显而易见的(Gordon and Van Durme, AKBC 2013)
-
常识不是写下来的
-
关于命名实体的事实
-
没有其他模式的基础
-
可能的解决方式:
-
吸收其他结构化知识(e.g. knowledge bases like ERNIE, Zhang et al 2019)
-
多模态学习(e.g. with visual representations like VideoBERT, Sun et al. 2019)
-
交互式/human-in-the-loop 的方法(e.g. dialog, Hancock et al. 2018)
任务和任务的相似性
许多任务可以表示为语言建模的变体
-
语言本身可以直接用于指定任务、输入和输出,例如,通过构建QA (McCann et al., 2018)
-
基于对话的学习,不受正向预测的监督 (Weston, NIPS 2016)
-
将NLP任务制定为完形填空预测目标 (Children Book Test, LAMBADA, Winograd, ...)
-
通过提示触发任务行为,例如翻译提示 (Radford, Wu et al. 2019); 使zero-shot适应
-
质疑NLP中的“任务”概念
-
预训练和目标任务(NLI,分类)的直觉相似性与较好的下游性能相关
-
不清楚两个任务在什么时候以及如何相似和相关
-
获得更多理解的方法之一:大规模的迁移实证研究,如 Taskonomy (Zamir et al., CVPR 2018)
-
是否有助于设计更好和更专业的预训练任务
持续和元学习
-
当前迁移学习只进行一次适应。
-
最终,我们希望拥有能够在许多任务中持续保留和积累知识的模型(Yogatama et al., 2019)
-
预训练和适应之间没有区别;只有一个任务流
-
主要的挑战是:灾难性的遗忘
-
不同的研究方法:
-
记忆、正则化、任务特定权重等
-
迁移学习的目的:学习一种对许多任务都通用且有用的表示方法
-
客观因素不会刺激适应的易用性(通常不稳定);没有学会如何适应它
-
元学习与迁移学习相结合可以使这一方法更加可行
-
然而,大多数现有的方法都局限于few-shot场景,并且只学习了几个适应步骤
偏见
-
偏见已经被证明普遍存在于单词嵌入和一般的神经模型中
-
大型预训练的模型必然有自己的一套偏见
-
常识和偏见之间的界限很模糊
-
我们需要在适应过程中消除这种偏见
-
一个小的微调模型应该更不易被误用
结论
-
主题:语境中的词汇,语言模型预培训,深度模型
-
预训练具有较好的 sample-efficiency ,可按比例放大
-
对某些特性的预测——取决于您如何看待它
-
性能权衡,自顶向下
-
迁移学习易于实现,实用性强
-
仍然存在许多不足和尚未解决的问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号