
云原生k8s02 生成yaml网站, node伸缩组件CA, 集群扩缩容, k8s升级, k8s命令补全, etcd进阶, CoreDNS进阶, k8s client项目
公有云Node伸缩组件Cluster Autoscale
Cluster Autoscaler(CA) 是 Kubernetes 官方开源的节点 自动扩缩容组件,核心作用是 根据集群内 Pod 的调度需求,自动增加或删除节点,实现资源的弹性伸缩,既保证业务 Pod 能正常调度,又避免Node资源浪费,
Cluster Autoscaler 是 Kubernetes 实现基础设施弹性伸缩的核心组件,通过与 HPA 协同,可实现从 Pod 到节点的全链路弹性,是云原生环境下资源优化和成本控制的关键工具。
CA和 HPA(Horizontal Pod Autoscaler,Pod 水平扩缩容)是互补关系。
HPA:针对 Pod 副本数的自动扩缩(工作负载层面)。
CA:针对集群节点数的自动扩缩(基础设施层面)。
典型使用场景:
批量任务场景:如大数据计算、AI 训练任务,任务提交时 Pod 激增触发 CA 扩容,任务结束后 Pod 减少触发 CA 缩容,节省资源成本。
弹性业务场景:如电商促销、直播活动,流量高峰时 HPA 扩容 Pod,CA 同步扩容节点;流量低谷时自动缩容,降低运维成本。
混合资源场景:集群内有 CPU / 内存 / GPU 多种节点池,CA 可根据 Pod 的资源需求(如 nvidia.com/gpu: 1)扩容对应 的 GPU 节点池。
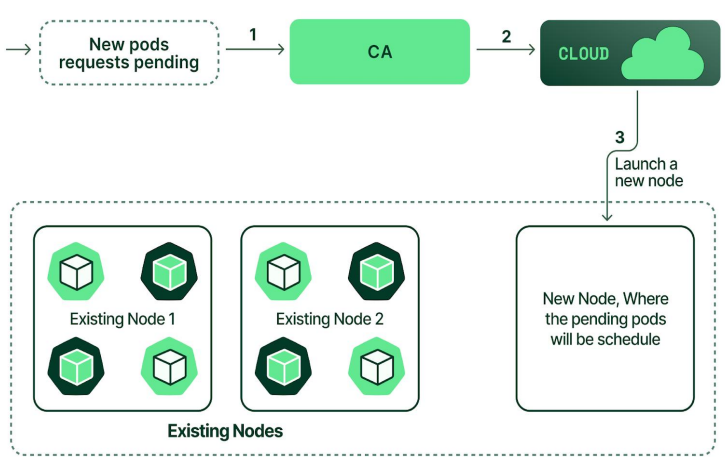
Cluster Autoscaler 会周期性监控集群内的 Pending(待调度)Pod 和节点资源利用率,触发两种核心动作 1. 扩容(Scale Up) 当集群中出现无法调度的 Pending Pod(原因是节点资源不足,如 CPU / 内存 / GPU 不够,或节点亲和性不满足),CA 会向云服务商(如 AWS、阿里云、腾讯云)或本地虚拟化平台(如 VMware)的 节点池 (Node Pool) 发送扩容请求,创建新节点;新节点加入集群后,kube-scheduler 会将 Pending Pod 调度到新节点上。 2. 缩容(Scale Down) 当集群中部分节点资源利用率长期过低(默认阈值是 CPU / 内存使用率低于 50%),且节点上的所有 Pod 都可以被安全迁移到其他节点时,CA 会先将这些 Pod 驱逐(Evict)到其他节点,然后删除闲置节点,释放资源。
#后期如果换个环境搭建,只要把host文件改好(把地址改好),使用里面ansible进行部署 #添加主节点 #查看命令 root@k8s-ha1:~# cd /etc/kubeasz/ root@k8s-ha1:/etc/kubeasz# ./ezctl --help add-master <cluster> <ip> to add a master node to the k8s cluster #查看集群名称 root@k8s-ha1:/etc/kubeasz# ll clusters/k8s-cluster1/ #注意要添加的节点,要提前把公钥拷贝进去 #(如添加失败,先把clusters/k8s-cluster1/hosts中的kube_master或者kube_node中刚刚添加的主机行删掉,再执行添加命令,否则提示节点已存在) #添加主节点,要写集群名,ip地址,和主机名(这里叫10.0.0.103和clusters/k8s-cluster1/hosts保持一致) root@k8s-ha1:/etc/kubeasz# ./ezctl add-master k8s-cluster1 10.0.0.103 k8s_nodename='10.0.0.103' root@k8s-ha1:/etc/kubeasz# kubectl get nodes NAME STATUS ROLES AGE VERSION 10.0.0.101 Ready,SchedulingDisabled master 6d14h v1.34.2 10.0.0.102 Ready,SchedulingDisabled master 6d14h v1.34.2 10.0.0.103 Ready,SchedulingDisabled master 20m v1.34.2 10.0.0.104 Ready node 6d14h v1.34.2 10.0.0.105 Ready node 6d14h v1.34.2 #添加node节点 root@k8s-ha1:/etc/kubeasz# ./ezctl add-node k8s-cluster1 10.0.0.106 k8s_nodename='10.0.0.106' #如果要删node节点,不用写节点名称 #root@k8s-ha1:/etc/kubeasz# ./ezctl del-node k8s-cluster1 10.0.0.106 root@k8s-ha1:/etc/kubeasz# kubectl get nodes NAME STATUS ROLES AGE VERSION 10.0.0.101 Ready,SchedulingDisabled master 6d14h v1.34.2 10.0.0.102 Ready,SchedulingDisabled master 6d14h v1.34.2 10.0.0.103 Ready,SchedulingDisabled master 53m v1.34.2 10.0.0.104 Ready node 6d14h v1.34.2 10.0.0.105 Ready node 6d14h v1.34.2 10.0.0.106 Ready node 13m v1.34.2 #后面加节点,加etcd,删除etcd流程都是这样
k8s升级
#kubeadm升级要一个个升级,二进制不用那么麻烦 #master节点下面组件都要升级 kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubectl kubelet #node节点升级下面组件 kube-proxy kubelet #升级流程: (下面2种方法) 1.master节点上把master摘掉,把master的service停掉。把二进制拷过去,如果有配置文件要修改就改,再启动服务,加到apiserver。再把另外一个master摘掉,把对应的master服务停掉,再把二进制替换,把配置文件一拷,再起来,再加进去。再把第三个master注掉... 2.通过kubeasz来升级 #去git仓库下官方的二进制 https://github.com/kubernetes/kubernetes/releases #选择 Kubernetes v1.34.3,点CHANGELOG,点Downloads for v1.34.3 #点击下载 kubernetes.tar.gz #类似文档,脚本 #Client Binaries 下载kubernetes-client-linux-amd64.tar.gz #Server Binaries 下载kubernetes-server-linux-amd64.tar.gz #Node Binaries 下载kubernetes-node-linux-amd64.tar.gz #下载后,传到部署节点上 root@k8s-ha1:~# mkdir -p y99/20260118/kubernetes-1.34.3 root@k8s-ha1:~# cd y99/20260118/kubernetes-1.34.3 #传入kubernetes-client-linux-amd64.tar.gz kubernetes-server-linux-amd64.tar.gz kubernetes-node-linux-amd64.tar.gz kubernetes.tar.gz #逐个解压 root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# tar xf kubernetes-client-linux-amd64.tar.gz root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# tar xf kubernetes-server-linux-amd64.tar.gz root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# tar xf kubernetes-node-linux-amd64.tar.gz root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# tar xf kubernetes.tar.gz #把上面生成的二进制(要升级的)拷贝到工具的部署目录(/etc/kubeasz/bin/) root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# ll /etc/kubeasz/bin/ ... #下面6个都是要升级的 -rwxr-xr-x 1 root root 84041912 Nov 12 03:26 kube-apiserver* -rwxr-xr-x 1 root root 71000248 Nov 12 03:26 kube-controller-manager* -rwxr-xr-x 1 root root 44490936 Nov 12 03:26 kube-proxy* -rwxr-xr-x 1 root root 48844984 Nov 12 03:26 kube-scheduler* -rwxr-xr-x 1 root root 60559544 Nov 12 03:26 kubectl* -rwxr-xr-x 1 root root 59199780 Nov 12 03:26 kubelet* #上面6个要升级的文件在下面 root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# ll kubernetes/server/bin/ #可以验证下版本对不对 root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# ./kubernetes/server/bin/kube-apiserver --version Kubernetes v1.34.3 #把这些文件拷过去(把部署环境的二进制切换成新的) root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# cd kubernetes/server/bin/ root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3/kubernetes/server/bin# cp kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubectl kubelet /etc/kubeasz/bin/ #验证 root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3/kubernetes/server/bin# cd /etc/kubeasz/bin/ root@k8s-ha1:/etc/kubeasz/bin# ./kube-apiserver --version Kubernetes v1.34.3 #使用ezctl进行升级,比自己手动升级简单些 root@k8s-ha1:/etc/kubeasz/bin# cd /etc/kubeasz/ root@k8s-ha1:/etc/kubeasz# ./ezctl upgrade k8s-cluster1 #尽量手动升级,这个证书全升级了,证书也重新签发,这个升完级会用他的calico去部署(前面部署我是用自己的calico yaml部署) #查看pod是否正常启动(有问题的pod删掉,让它自己重新创建下) root@k8s-ha1:/etc/kubeasz# kubectl get pod -A #看到coredns有问题,其实是calico有问题,用了自己的calico,coredns显示pem证书找不到 #先把calico删下,用自己的calico root@k8s-ha1:/etc/kubeasz# cd 20260111/ #虽然镜像版本不一致,但是service,deployment等名字一样就会被删 root@k8s-ha1:/etc/kubeasz/20260111# kubectl delete -f calico_v3.28.1-k8s_1.30.1-ubuntu2404.yaml root@k8s-ha1:/etc/kubeasz/20260111# kubectl apply 0f calico_v3.28.1-k8s_1.30.1-ubuntu2404.yaml root@k8s-ha1:/etc/kubeasz/20260111# kubectl get pods -A NAMESPACE NAME READY STATUS RESTARTS AGE kube-system calico-kube-controllers-695bf6cc9d-sfg2m 1/1 Running 0 13m kube-system calico-node-2jd99 1/1 Running 0 13m kube-system calico-node-4cnvv 1/1 Running 0 13m kube-system calico-node-8jr6k 1/1 Running 0 13m kube-system calico-node-mnw25 1/1 Running 0 13m kube-system calico-node-qp885 1/1 Running 0 13m kube-system calico-node-swmzr 1/1 Running 0 13m kube-system coredns-c6576d7df-cfvkf 1/1 Running 0 19m kube-system coredns-c6576d7df-ljt67 1/1 Running 0 19m kuboard kuboard-v3-78f6bc89dc-q68hs 1/1 Running 0 46m root@k8s-ha1:~# kubectl get nodes NAME STATUS ROLES AGE VERSION 10.0.0.101 Ready,SchedulingDisabled master 7d21h v1.34.3 10.0.0.102 Ready,SchedulingDisabled master 7d21h v1.34.3 10.0.0.103 Ready,SchedulingDisabled master 31h v1.34.3 10.0.0.104 Ready node 7d21h v1.34.3 10.0.0.105 Ready node 7d21h v1.34.3 10.0.0.106 Ready node 30h v1.34.3 #结论:要么calico一开始就是kubeasz部署的,要么手动部署calico (hosts写死calico就会升级) --------------------------------------------- #如果自己手动升级步骤: #master节点升级 1.先在负载均衡上把一个master节点摘掉 root@k8s-ha1:~# vim /etc/haproxy/haproxy.cfg root@k8s-ha1:~# systemctl reload haproxy #restart会影响业务 2.把该master节点下面服务停掉 root@ubuntu103:~# systemctl stop kube-apiserver.service kube-controller-manager.service kube-proxy.service kube-scheduler.service kubelet.service 3.把部署节点的二进制文件拷到master节点上二进制文件目录 root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3# cd kubernetes/server/bin/ root@k8s-ha1:~/y99/20260118/kubernetes-1.34.3/kubernetes/server/bin# scp kube-apiserver kube-controller-manager kube-proxy kube-scheduler kubectl kubelet 10.0.0.103:/usr/loca/bin 4.启动master节点下面服务 root@ubuntu103:~# systemctl start kube-apiserver.service kube-controller-manager.service kube-proxy.service kube-scheduler.service kubelet.service 5.在负载均衡上把该master节点加入,再换个master节点摘掉,循环上述操作,直到master节点全部替换 root@k8s-ha1:~# vim /etc/haproxy/haproxy.cfg root@k8s-ha1:~# systemctl reload haproxy #node节点升级 1.强制驱逐从节点 root@k8s-ha1:~# kubectl drain node 10.0.0.105 --ignore-daemonsets --delete-emptydir-data --force=true 2.替换二进制文件... ---------------------------------------------
root@ubuntu101:~# mkdir /data/scripts -p #会生成一个命令补全的脚本 root@ubuntu101:~# kubectl completion bash > /data/k8s-completion.sh #导入脚本,任何人在这个节点上使用客户端都可以生效 root@ubuntu101:~# vim /etc/profile ... #最后追加 source /data/k8s-completion.sh #重新登录或执行下面命令生效都行 root@ubuntu101:~# source /etc/profile #ubuntu或者centos还要安装命令补全的包,就可以补全了 root@ubuntu101:~# apt install bash-completion
etcd
主节点,从节点挂掉一个影响都比较小。像比较重要的无状态服务可以通过反亲和,让每个pod在不同的节点上运行。etcd一定要高可用,etcd如果挂掉一个,可能会出现一些读写异常,但会很快选举选出新的leader。
如果etcd只有单节点,挂了,那k8s全挂了,pod,deployment,容器元数据像pv,pvc这些就全丢了,只能重新部署。 如果etcd有备份,找个服务器重新部署起来就行,地址不改,主机名称不变,apiserver会去找新的etcd,再把pod重新部署出来(里面有controller manager会检查当前k8s集群可用的pod副本数,
如果pod有问题会把执行重建请求发给apiserver,修复pod的状态,再由kube-scheduler进行调度,调度完再发给apiserver,apiserver再写到etcd。node上kubelet拿到事件了,进行重建,新的pod运行了就把老的pod删掉。
如果pod还没被删,对应节点直接断电了(kubelet没有返回删除成功的结果),etcd会记下一条,pod在这个节点上但是删不掉terminating,这时node不在了,pod还在这个节点上就得手动强制删除)
etcd具有下面这些属性: 完全复制:集群中的每个节点都可以使用完整的存档 高可用性:Etcd可用于避免硬件的单点故障或网络问题 一致性:每次读取都会返回跨多主机的最新写入 简单:包括一个定义良好、面向用户的API(gRPC) 安全:实现了带有可选的客户端证书身份验证的自动化TLS 快速:每秒10000次写入的基准速度 可靠:使用Raft算法实现了存储的合理分布Etcd的工作原理 #service示例: root@k8s-etcd1:~# cat /etc/systemd/system/etcd.service [Unit] Description=Etcd Server After=network.target After=network-online.target Wants=network-online.target Documentation=https://github.com/coreos [Service] Type=notify WorkingDirectory=/var/lib/etcd/ #数据保存目录 ExecStart=/usr/bin/etcd \ #二进制文件路径 --name=etcd-172.31.7.105 \ #当前node 名称 --cert-file=/etc/etcd/ssl/etcd.pem \ --key-file=/etc/etcd/ssl/etcd-key.pem \ --peer-cert-file=/etc/etcd/ssl/etcd.pem \ #对端证书和key --peer-key-file=/etc/etcd/ssl/etcd-key.pem \ --trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ #同一个集群共用一套证书 --peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \ --initial-advertise-peer-urls=https://172.31.7.105:2380 \ #通告自己的集群端口 --listen-peer-urls=https://172.31.7.105:2380 \ #集群之间通讯端口 --listen-client-urls=https://172.31.7.105:2379,http://127.0.0.1:2379 \ #客户端访问地址,本机访问为http --advertise-client-urls=https://172.31.7.105:2379 \ #通告自己的客户端端口 --initial-cluster-token=etcd-cluster-0 \ #创建集群使用的token,一个集群内的节点保持一致 --initial-cluster=etcd-172.31.7.105=https://172.31.7.105:2380,etcd-172.31.7.106=https://172.31.7.106:2380,etcd-172.31.7.107=https://172.31.7.107:2380 \ #集群所有的节点信息,各节点名称要正确 --initial-cluster-state=new \ #首次初始化 etcd 集群 时使用,只在第一次启动集群时生效,如果是把一个节点加入到已经存在的集群为existing。 --data-dir=/var/lib/etcd #数据目录路径 --wal-dir= \ #wal日志目录,空则默认使用data-dir路径(预写式日志,可用于后期恢复日志) --snapshot-count=50000 \ #写入5万次就触发一次执行完整快照 --auto-compaction-retention=10 \ #首先会等待 10 小时进行第一次压缩,然后每隔一小时(10 小时的 1/10)进行一次压缩 --auto-compaction-mode=periodic \ #自动压缩模式:periodic(按时间)/revision(按版本)#一般按时间,按版本会根据写入量压缩 --max-request-bytes=10485760 \ # 客户端最大请求字节数,默认10MB --log-outputs=/var/log/etcd.log \ #指定日志输出路径#默认没有,用systemctl status etcd看日志,这里配上systemctl daemon-reload后systemctl restart etcd会自动创建日志(如果磁盘慢就别记日志了) --quota-backend-bytes=8589934592 # etcd最大存储配额,默认8GB Restart=on-failure RestartSec=5 LimitNOFILE=65536 [Install] WantedBy=multi-user.target
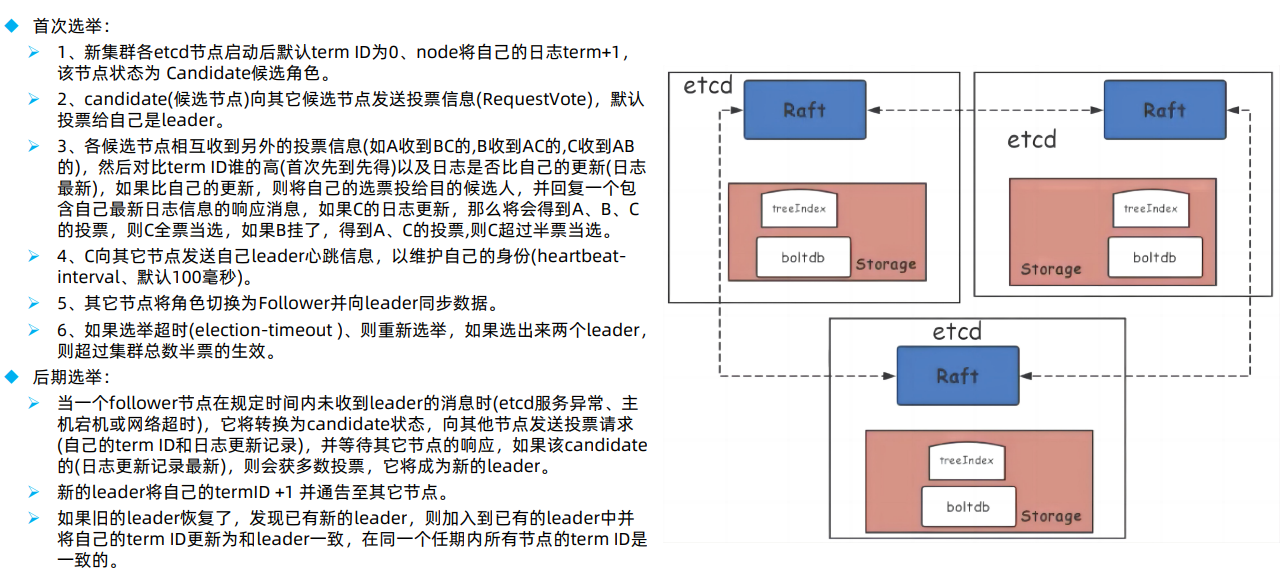
节点角色:集群中每个节点只能处于 Leader、Follower 和 Candidate 三种状态的一种 follower:追随者(Redis Cluster的Slave节点) candidate:候选节点,选举过程中。#会短暂出现,然后编程主或从 leader:主节点(Redis Cluster的Master节点) 节点启动后基于termID(任期ID)进行相互投票并选举出唯一leader,termID是一个整数默认值为0,在Raft算法中,一个term代表leader的一段任期周期,每当一个节点成为leader时,就会进入一个新的term,
然后每个节点都会在自己的term ID上加1,以便与上一轮选举区分开来。 Leader负责处理客户端写请求、同步日志到 Follower 节点,Follower 仅处理读请求。#往follower写会路由到主节点 Leader 周期性发送心跳包(默认每 100ms 毫秒一次),维持 Leader 身份,选举超时时间默认为1000ms毫秒。 --heartbeat-interval=100 --election-timeout=500 #所有节点保持一致,https://etcd.io/docs/v3.4/tuning/#time-parameters#如果跨机房,时间设置的长些
配置 优化: --max-request-bytes=10485760 #request size limit(请求的最大字节数,默认一个key最大1.5Mib,官方推荐最大不要超出10Mib) --quota-backend-bytes=8589934592 #storage size limit(磁盘存储空间大小限制,默认为2G,此值超过8G启动会有警告信息) 集群碎片整理:#数据在磁盘放的很不连续(尤其是机械盘),可执行该命令把数据整理下,机械盘上可以连续读写,比较快 #现在都是固态盘了,也用不上了 #指定其中一个端点就行 root@k8s-etcd1:~# ETCDCTL_API=3 /usr/local/bin/etcdctl defrag --cluster --endpoints=https://172.31.7.106:2379 -- cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem Finished defragmenting etcd member[https://172.31.7.106:2379] Finished defragmenting etcd member[https://172.31.7.107:2379] Finished defragmenting etcd member[https://172.31.7.108:2379]
#查看etcd方法 root@ubuntu101:~# etcdctl --help #查看etcd有哪些成员(可以用于监控,如果节点少于3个就触发告警,后面有更高级的监控方式) root@ubuntu101:~# etcdctl member list 13e17ead073290e4, started, etcd-10.0.0.103, https://10.0.0.103:2380, https://10.0.0.103:2379, false 40f6efe0cdfe82d0, started, etcd-10.0.0.101, https://10.0.0.101:2380, https://10.0.0.101:2379, false 4f717e13d25fde12, started, etcd-10.0.0.102, https://10.0.0.102:2380, https://10.0.0.102:2379, false #查看集群状态 #1.先环境配置3个etcd服务器地址 root@ubuntu101:~# export NODE_IPS="10.0.0.101 10.0.0.102 10.0.0.103" #2.write-out输入格式表格,执行member list,endpoints连上一个节点(IS LEARNER是否同步数据) root@ubuntu101:~# /usr/local/bin/etcdctl --write-out=table member list --endpoints=https://10.0.0.101:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem +------------------+---------+-----------------+-------------------------+-------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+-----------------+-------------------------+-------------------------+------------+ | 13e17ead073290e4 | started | etcd-10.0.0.103 | https://10.0.0.103:2380 | https://10.0.0.103:2379 | false | | 40f6efe0cdfe82d0 | started | etcd-10.0.0.101 | https://10.0.0.101:2380 | https://10.0.0.101:2379 | false | | 4f717e13d25fde12 | started | etcd-10.0.0.102 | https://10.0.0.102:2380 | https://10.0.0.102:2379 | false | +------------------+---------+-----------------+-------------------------+-------------------------+------------+ #验证节点心跳状态: root@ubuntu101:~# export NODE_IPS="10.0.0.101 10.0.0.102 10.0.0.103" root@ubuntu101:~# for ip in ${NODE_IPS}; do ETCDCTL_API=3 /usr/local/bin/etcdctl --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health; done {"level":"warn","ts":"2026-01-31T19:30:25.639837+0800","caller":"flags/flag.go:94","msg":"unrecognized environment variable","environment-variable":"ETCDCTL_API=3"} https://10.0.0.101:2379 is healthy: successfully committed proposal: took = 13.917943ms {"level":"warn","ts":"2026-01-31T19:30:25.671038+0800","caller":"flags/flag.go:94","msg":"unrecognized environment variable","environment-variable":"ETCDCTL_API=3"} https://10.0.0.102:2379 is healthy: successfully committed proposal: took = 12.232795ms {"level":"warn","ts":"2026-01-31T19:30:25.701006+0800","caller":"flags/flag.go:94","msg":"unrecognized environment variable","environment-variable":"ETCDCTL_API=3"} https://10.0.0.103:2379 is healthy: successfully committed proposal: took = 15.200798ms #查看谁是leader(核心) root@ubuntu101:~# export NODE_IPS="10.0.0.101 10.0.0.102 10.0.0.103" root@ubuntu101:~# for ip in ${NODE_IPS}; do /usr/local/bin/etcdctl --write-out=table endpoint status --endpoints=https://${ip}:2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem; done +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ | ENDPOINT | ID | VERSION | STORAGE VERSION | DB SIZE | IN USE | PERCENTAGE NOT IN USE | QUOTA | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | DOWNGRADE TARGET VERSION | DOWNGRADE ENABLED | +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ | https://10.0.0.101:2379 | 40f6efe0cdfe82d0 | 3.6.4 | 3.6.0 | 8.0 MB | 2.0 MB | 75% | 8.6 GB | false | false | 17 | 152124 | 152124 | | | false | +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ | ENDPOINT | ID | VERSION | STORAGE VERSION | DB SIZE | IN USE | PERCENTAGE NOT IN USE | QUOTA | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | DOWNGRADE TARGET VERSION | DOWNGRADE ENABLED | +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ | https://10.0.0.102:2379 | 4f717e13d25fde12 | 3.6.4 | 3.6.0 | 7.9 MB | 2.0 MB | 75% | 8.6 GB | false | false | 17 | 152124 | 152124 | | | false | +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ | ENDPOINT | ID | VERSION | STORAGE VERSION | DB SIZE | IN USE | PERCENTAGE NOT IN USE | QUOTA | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | DOWNGRADE TARGET VERSION | DOWNGRADE ENABLED | +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+ | https://10.0.0.103:2379 | 13e17ead073290e4 | 3.6.4 | 3.6.0 | 7.9 MB | 2.0 MB | 75% | 8.6 GB | true | false | 17 | 152124 | 152124 | | | false | +-------------------------+------------------+---------+-----------------+---------+--------+-----------------------+--------+-----------+------------+-----------+------------+--------------------+--------+--------------------------+-------------------+
#node节点一直watch etcd自己有没有被绑定pod,一旦有,etcd会通知node节点的kubelet这个事件 基于不断监看数据,发生变化就主动触发通知客户端,Etcd v3 的watch机制支持watch某个固定的key,也支持watch一个范围。 #在etcd node1上watch一个key,没有此key也可以执行watch,后期可以再创建: root@k8s-etcd1:~# /usr/local/bin/etcdctl watch /data #在etcd node2修改数据,验证etcd node1是否能够发现数据变化 root@k8s-etcd2:~# /usr/local/bin/etcdctl put /data "data v1" OK root@k8s-etcd2:~# /usr/local/bin/etcdctl put /data "data v2" OK
当etcd集群宕机数量超过集群总节点数一半以上的时候(如总数为三台宕机两台),就会导致整合集群宕机,后期需要重新恢复数据,则恢复流程如下: 1、恢复服务器系统 2、重新部署ETCD集群 3、停止kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy 4、停止ETCD集群 5、各ETCD节点恢复同一份备份数据 #单机用单机命令,集群用集群命令 6、启动各节点并验证ETCD集群 7、启动kube-apiserver/controller-manager/scheduler/kubelet/kube-proxy 8、验证k8s master状态及pod数据
WAL是write ahead log(预写日志)的缩写,顾名思义,也就是在执行真正的写操作之前先写一个日志,预写日志。 wal: 存放预写式日志,最大的作用是记录了整个数据变化的全部历程。在etcd中,所有数据的修改在提交前,都要先写入到WAL中。 #虽然有预写式日志,但是该备份还得备份,这样可以很快做恢复/集群数据同步等操作 V3版本备份数据: #创建备份目录 root@ubuntu101:~# mkdir -p /data/etcd #这个db文件就是当前所有的集群数据 root@ubuntu101:~# etcdctl snapshot save /data/etcd/snapshot.db V3版本恢复数据:#etcdutl是v3版本的命令,该工具需要拷贝进去(根据etcd --version去github下etcd二进制包,内有) #这里下载etcd-v3.6.4-linux-amd64.tar.gz,windows上解压,里面有etcdutl命令(这个命令用来管理备份文件的) root@ubuntu101:~# cd /data/etcd #传入etcdutl root@ubuntu101:/data/etcd# ls etcdutl snapshot.db root@ubuntu101:/data/etcd# chmod a+x etcdutl root@ubuntu101:/data/etcd# mv etcdutl /usr/local/bin/ #查看快照备份文件的状态 root@ubuntu101:/data/etcd# etcdutl snapshot status snapshot.db fcbda86f, 159381, 425, 8.0 MB, 3.6.0 #恢复,不能恢复已存在的路径里,只能恢复到新的目录(可以先恢复到另外一个目录,再修改etcd的service文件) #确保要恢复的文件夹/var/lib/etcd-data不存在(将数据恢复到一个空的目录中) root@ubuntu101:/data/etcd# etcdutl snapshot restore ./snapshot.db --data-dir=/var/lib/etcd-data #废弃的恢复命令 #root@k8s-etcd1:~# etcdctl snapshot restore snapshot.db --data-dir=/opt/etcd-testdir #针对单机etcd恢复的2种方式: #1.把etcd service服务停掉,把原来的数据目录移走,把新的数据目录移过去,启动service文件 #2.直接修改service文件(/etc/systemd/system/etcd.service),修改WorkingDirectory指向新数据地址,重启数据恢复 #单机自动备份数据 root@ubuntu101:/data# mkdir /data/etcd-backup-dir/ -p root@ubuntu101:/data# vim etcd-backup.sh #!/bin/bash source /etc/profile DATE=`date +%Y-%m-%d_%H-%M-%S` ETCDCTL_API=3 /usr/local/bin/etcdctl snapshot save /data/etcd-backup-dir/etcd-snapshot-${DATE}.db
#在k8s部署节点上 root@k8s-ha1:~# cd /etc/kubeasz/ #备份,后面跟集群的名称(本质连到etcd上(找一个节点),打个快照,拷到当前集群的备份目录) root@k8s-ha1:/etc/kubeasz# ./ezctl backup k8s-cluster1 #备份位置(每次备份完的最后一个文件会作为snapshot.db,默认恢复该文件,要恢复其他文件就改名为snapshot.db) root@k8s-ha1:/etc/kubeasz# ll clusters/k8s-cluster1/backup/ total 23548 drwxr-xr-x 2 root root 89 Feb 1 20:42 ./ drwxr-xr-x 5 root root 4096 Jan 25 21:35 ../ -rw------- 1 root root 8032288 Feb 1 20:42 snapshot.db -rw------- 1 root root 8032288 Feb 1 20:27 snapshot_202602012027.db -rw------- 1 root root 8032288 Feb 1 20:42 snapshot_202602012042.db #恢复(恢复期间会停掉api server) root@k8s-ha1:/etc/kubeasz# ./ezctl restore k8s-cluster1 #会报错,显示使用etcdctl,修改下面ansible文件,把etcdctl改成etcdutl root@k8s-ha1:/etc/kubeasz# vim roles/cluster-restore/tasks/main.yml - name: etcd 数据恢复 shell: "cd /etcd_backup && \ #会从当前节点把这个目录拷过去 ETCDCTL_API=3 {{ bin_dir }}/etcdutl snapshot restore snapshot.db \ 改成etcdutl --name etcd-{{ inventory_hostname }} \ #当前节点名称,是etcd.service中的--name --initial-cluster {{ ETCD_NODES }} \ #etcd集群信息,来源于配置(告诉当前节点node是哪些) --initial-cluster-token etcd-cluster-0 \ --initial-advertise-peer-urls https://{{ inventory_hostname }}:2380" - name: 恢复数据至etcd 数据目录 #ETCD_DATA_DIR就是/var/lib/etcd shell: "cp -rf /etcd_backup/etcd-{{ inventory_hostname }}.etcd/member {{ ETCD_DATA_DIR }}/" #拷贝完后面步骤会把etcd跑起来 #改完,先上传etcdutl,把etcdutl命令分发到各个etcd节点的/usr/local/bin root@k8s-ha1:/etc/kubeasz# cd /usr/local/bin #上传etcdutl root@k8s-ha1:/usr/local/bin# chmod a+x etcdutl root@k8s-ha1:/usr/local/bin# scp /usr/local/bin/etcdutl 10.0.0.101:/usr/local/bin/etcdutl root@k8s-ha1:/usr/local/bin# scp /usr/local/bin/etcdutl 10.0.0.102:/usr/local/bin/etcdutl root@k8s-ha1:/usr/local/bin# scp /usr/local/bin/etcdutl 10.0.0.103:/usr/local/bin/etcdutl #再执行恢复(要每个节点执行成功才行) root@k8s-ha1:/etc/kubeasz# ./ezctl restore k8s-cluster1 #可以检测下pod,deployment等是否恢复了
ETCD集群节点添加与删除:
add-etcd del-etcd #会动态修改etcd.service文件
errors:错误信息标准输出。 health:在CoreDNS的 http://localhost:8080/health 端口提供 CoreDNS 服务的健康报告。 ready:监听8181端口,当coredns的插件都已就绪时,访问该接口会返回 200 OK。 kubernetes:CoreDNS 将基于 kubernetes service name进行 DNS 查询并返回查询记录给客户端. #这个service的域名存在etcd中,coredns通过kubernetes的service读取etcd的域名解析地址 prometheus:CoreDNS 的度量指标数据以 Prometheus 的key-value的格式在http://localhost:9153/metrics URI上提供。 forward: 不是Kubernetes 集群内的其它任何域名查询都将转发到 预定义的目的server,如 (/etc/resolv.conf或IP(如8.8.8.8)). cache:启用 service解析缓存,单位为秒。 loop:检测域名解析是否有死循环,如coredns转发给内网DNS服务器,而内网DNS服务器又转发给coredns,如果发现解析是死循环,则强制中止 CoreDNS 进程(kubernetes会重建)。 reload:检测corefile是否更改,在重新编辑configmap 配置后,默认2分钟后会优雅的自动加载。 loadbalance:轮训DNS域名解析,如果一个域名存在多个记录则轮训解析 #示例 data: Corefile: | .:53 { errors health { lameduck 5s } ready kubernetes example.local in-addr.arpa ip6.arpa { pods insecure fallthrough in-addr.arpa ip6.arpa ttl 30 } prometheus :9153 #可获取coredns pod对应指标curl 10.200.131.4:9153/metrics forward . 8.8.8.8 { max_concurrent 10000 } cache 30 #设置缓存时间,请求同一域名直接转发(别太长,service地址变了,还是返回以前的地址) loop reload loadbalance } myserver.online { forward . 172.16.16.16:53 }
在jenkins里非常适用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号