
clickhouse02 clickhouse监控, clickhouse与kafka集成, clickhouse集群
7.2:clickhouse 系统表
ClickHouse 内置了实例状态检测的功能, 可根据系统表、查询日志等方式、显示 clickhouse 服务器不同资源的度量统计信息、以及查询处理的通用统计信息等。
7.2.1:常见的系统表:
https://clickhouse.com/docs/zh/operations/system-tables
ClickHouse 提供了 system.metrics、system.events 和 system.asynchronous_metrics 表
收集服务器的不同的运行度量,不能被删除或更改,但可以对其进行分离(detach)操作,大
多数系统表将其数据存储在 RAM 中, 一个 ClickHouse 服务在刚启动时便会创建此类系统
表。
system.metrics 表的数据实时更新, 用于查看正在运行的查询或当前副本的延迟信息等。 包含的列有: metric(String) : 度量名称。 value(Int64) :指标值。 description (String) :度量描述。 clickhouse-node1.example.local :) select * from system.metrics limit 5;
用于收集系统中发生的事件数的信息,例如,可以查询自 ClickHouse 服务启动以来已处理的 SELECT 查询数、列信息如下: event (String) : 事件名称。 value (UInt64) : 发生的事件数。 description (String) : 事件描述 clickhouse-node1.example.local :) select * from system.events limit 5;
包含在后台定期计算的指标。例如,正在使用的 RAM 量: 包含的列有: metric( String ) — 指标名称。 value( Float64 ) — 公制值。 description(字符串- 指标描 clickhouse-node1.example.local :) select * from system.asynchronous_metrics limit 5;
https://clickhouse.com/docs/en/operations/system-tables/trace_log
#例如查慢查询对应事件 存储 query profilers 收集的堆栈跟踪日志。 堆栈日志根据计时器类型分为 REAL 和 CPU,分别表示实际时钟计时器和 CPU 时钟计时器。 计时器相关的两个设置: query_profiler_real_time_period_ns:设置 query profilers 的实际计时器的周期,单位为纳 秒,默认为 1000000000(1 秒)。 query_profiler_cpu_time_period_ns:设置 query profilers 的 CPU 计时器的周期,单位为 纳秒,默认为 1000000000(1 秒)。 在 ClickHouse 的主配置文件 config.xml 配置了 trace_log 日志的表、分区、数据刷新间隔等信息 clickhouse-node1.example.local :) select * from system.trace_log limit 1\G
用于统计 MergeTree 引擎表中针对数据片段所有操作(创建、删除、合并、下载等)的信息 clickhouse-node1.example.local :) select * from system.part_log limit 1\G;
text_log 用于记录服务器的常规日志,但是以结构化和高效的方式存储在表中。 text_log 默认是关闭的(因为已经有系统日志了,没必要开),在 ClickHouse 的主配置文件使用如下配置开启日志 # vim /etc/clickhouse-server/config.xml <text_log> <database>system</database> <table>text_log</table> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </text_log> #clickhouse日志 [root@clickhouse-node1 users.d]# ll /var/log/clickhouse-server/ total 578380 -rw-r----- 1 clickhouse clickhouse 94638089 Jan 27 22:29 clickhouse-server.err.log -rw-r----- 1 clickhouse clickhouse 482521456 Jan 27 22:41 clickhouse-server.log
7.2.1.8:system.crash_log:
包含有关致命错误的堆栈跟踪的信息。默认情况下,该表不存在于数据库中,仅在发生致命错误时自动创建
用于存储来自表 system.metrics 和 system.events 指标值的历史记录。 collect_interval_milliseconds(默认 1000)用于设置采集的时间间 #验证指标: clickhouse-node1.example.local :) SELECT * FROM system.metric_log LIMIT 1 \G;
https://github.com/f1yegor/clickhouse_exporter #github https://hub.docker.com/r/f1yegor/clickhouse-exporter #容器镜像 https://github.com/f1yegor/clickhouse_exporter?tab=readme-ov-file #dashboard #clickhouse客户端选8123,9000端口都行(9000是tcp,8123是http) #如果不是很新的clickhouse,可以直接通过容器运行,输入端口(如有密码输入环境变量中),如果是很新版本(如这里使用的23.8.9.54版本),直接起容器监控采集不到,需要通过编译clickhouse-exporter安装(go语言)
root@clickhouse-node1 ~]# yum install epel-release [root@clickhouse-node1 ~]# yum install golang [root@clickhouse-node1 ~]# go version go version go1.20.10 linux/amd64 [root@clickhouse-node1 ~]# git clone https://github.com/ClickHouse/clickhouse_exporter.git [root@clickhouse-node1 ~]# cd clickhouse_exporter #执行初始化,需要从 go的官方仓库下载(可能需要上外网) [root@clickhouse-node1 clickhouse_exporter]# go mod init #配置代理 [root@clickhouse-node1 clickhouse_exporter]# export https_proxy=http://10.0.0.1:7890 http_proxy=http://10.0.0.1:7890 root@clickhouse-node1 clickhouse_exporter]# go mod vendor [root@clickhouse-node1 clickhouse_exporter]# go build #编译完看看生成的二进制能不能执行(暴露metrics端口是9116) [root@clickhouse-node1 clickhouse_exporter]# ./clickhouse_exporter --help #设置环境变量,exporter从中读取用户密码 [root@clickhouse-node1 clickhouse_exporter]# export CLICKHOUSE_USER=default CLICKHOUSE_PASSWORD=123456 [root@clickhouse-node1 clickhouse_exporter]# ./clickhouse_exporter -scrape_uri=http://10.0.0.150:8123 #浏览器输入,测试,获取的指标就是上面clickhouse各种系统表的指标 http://10.0.0.150:9116/metrics
[root@clickhouse-node1 clickhouse_exporter]# pwd /opt/clickhouse_exporter [root@clickhouse-node1 clickhouse_exporter]# cat Dockerfile FROM golang:1.20.10 COPY ./clickhouse_exporter /usr/local/bin/clickhouse_exporter ENTRYPOINT ["/usr/local/bin/clickhouse_exporter"] CMD ["-scrape_uri=http://localhost:8123"] USER nobody EXPOSE 9116 #打镜像,标签自己设定 [root@clickhouse-node1 clickhouse_exporter]# docker build -t registry.cn-hangzhou.aliyuncs.com/zhangshijie/clickhouse_exporter:v20240312-2e28b7c . #运行镜像 root@middleware:~# docker run -d -p 9116:9116 -e CLICKHOUSE_USER=default -e CLICKHOUSE_PASSWORD=123456 registry.cn-hangzhou.aliyuncs.com/zhangshijie/clickhouse_exporter:v20240312-2e28b7c -scrape_uri=http://10.0.0.150:8123/ #浏览器输入,测试,获取的指标就是上面clickhouse各种系统表的指标 http://10.0.0.150:9116/metrics
9.1.3: clickhouse 部分指标简介
ClikckHouse内置 Metrics、events 和 asynchronous_metrics 三张系统表用于存放其监控指标,通过预先安装 clickhouse-exporter 将这三张系统表中的数据序列化为 prometheus 支持的键值数据格式
通过命令查询clickhouse指标
#例: 查tcp连接数 [root@clickhouse-node1 ~]# clickhouse-client -h10.0.0.150 --password 123456 --query="SELECT * FROM system.metrics;" | grep "TCPConnection"
#部署prometheus,登录prometheus页面验证 http://10.0.0.151:9090/ #如果yum安装位置在/etc/prometheus/prometheus.yml root@prometheus-server1:~# vim /apps/prometheus/prometheus.yml - job_name: 'clickhouse-node' static_configs: - targets: ['10.0.0.150:9116',] root@prometheus-server1:~# systemctl restart prometheus.service #在prometheus页面上方status下targets查看是否有clickhouse监测了
#部署grafana,登录页面测试 默认用户名/密码 admin http://10.0.0.151:3000/ #添加prometheus数据源 #导入模板 点击左侧菜单栏下的Dashboards,右侧蓝色new键下点击import #参考: https://grafana.com/grafana/dashboards/882-clickhouse/ ID输入882,点击load name输入Clickhouse-882 prometheus选择对应的源
https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings#prometheus
#新版本可以直接暴露部分指标
9.2.1:启用 prometheus 指标:
#里面已经有了,可以直接解开注释,:x!保存 [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/config.xml <tcp_port>9000</tcp_port> <prometheus> <endpoint>/metrics</endpoint> <port>9363</port> <metrics>true</metrics> <events>true</events> <asynchronous_metrics>true</asynchronous_metrics> <errors>true</errors> </prometheus> [root@clickhouse-node1 ~]# systemctl restart clickhouse-server.service
9.2.2: 验证指标:
http://10.0.0.150:9363/metrics
比exporter暴露更多指标, 但是没有库和表的指标(如表有多少行), 如果需要还是需要clickhouse exporter的指标
9.2.2: prometheus 收集指标
root@prometheus-server1:~# vim /apps/prometheus/prometheus.yml - job_name: 'clickhouse-node' static_configs: - targets: ['10.0.0.150:9116','10.0.0.150:9363'] root@prometheus-server1:~# systemctl restart prometheus.service #看下prometheus网页上方栏status下的targets有没有手机9363 http://10.0.0.151:9090/
https://grafana.com/grafana/dashboards/14192-clickhouse/
#导入clickhouse自带的指标模板 点击左侧菜单栏下的Dashboards,右侧蓝色new键下点击import ID输入14192,点击load name输入Clickhouse-14192 prometheus选择对应的源
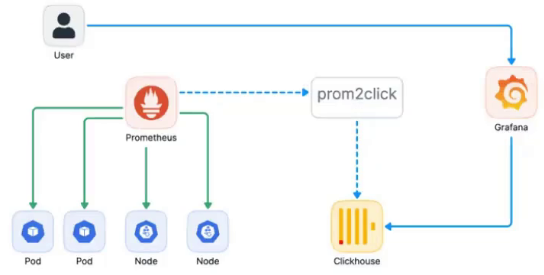
https://github.com/mindis/prom2click?tab=readme-ov-file
prometheus通过prom2click连接clickhouse,实现读写功能
https://github.com/iyacontrol/prom2click/blob/master/config.xml
https://clickhouse.com/docs/zh/engines/table-engines/mergetree-family/graphitemergetree
注: clickhouse版本23.8修改配置也不支持表GraphiteMergeTree引擎创建, 21.8版本可以
#在配置文件/etc/clickhouse-server/config.xml 底部自定义 GraphiteMergeTree 擎设置、实现对 Graphite 数据进行瘦身及汇总、如不修改报错如下: Code: 36. DB::Exception: Received from 172.31.7.211:9000. DB::Exception: This syntax for *MergeTree engine is deprecated. Use extended storage definition syntax with ORDER BY/PRIMARY KEY clause. See also `allow_deprecated_syntax_for_merge_tree` setting.. (BAD_ARGUMENTS) #追加,xml有graphite_rollup_example,但是这个不生效,后面追加下面配置(缩进不重要) [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/config.xml <graphite_rollup> <path_column_name>tags</path_column_name> <time_column_name>ts</time_column_name> <value_column_name>val</value_column_name> <version_column_name>updated</version_column_name> <default> <function>avg</function> <retention> <age>0</age> <precision>10</precision> </retention> <retention> <age>86400</age> <precision>30</precision> </retention> <retention> <age>172800</age> <precision>300</precision> </retention> </default> </graphite_rollup> [root@clickhouse-node1 ~]# systemctl restart clickhouse-server.service
[root@clickhouse-node1 ~]# clickhouse-client --user default --password 123456 -m #库名无所谓,官方叫metrics :) CREATE DATABASE IF NOT EXISTS metrics; #创建表名,名字自己定 :) CREATE TABLE IF NOT EXISTS metrics.samples ( date Date DEFAULT toDate(0), name String, tags Array(String), val Float64, ts DateTime, updated DateTime DEFAULT now() ) ENGINE = GraphiteMergeTree( date, (name, tags, ts), 8192, 'graphite_rollup' );
使用普通账户连接 clickhouse 且密码为空,设置密码提示认证失败
#ch.batch:有多少数据就往里写,写大了会积攒在内存,等满了再写入库中 ch.dsn:clickhouse连接地址 #默认连接库名metrics,表名samples [root@clickhouse-node1 ~]# docker run -it -d -p 9201:9201 fhalim/prom2click -ch.batch 1 -ch.dsn=tcp://10.0.0.150:9000?username=jack
root@prometheus-server1:/apps/prometheus# vim prometheus.yml remote_write: - url: "http://10.0.0.150:9201/write" remote_read: - url: "http://10.0.0.150:9201/read" #prometheus不向本地存数据,存到clickhouse上 root@prometheus-server1:/apps/prometheus# systemctl restart prometheus.service #clickhouse 验证数据: [root@clickhouse-node1 ~]# clickhouse-client -h172.31.7.211 --user jack -m clickhouse-node1.example.local :) select * from metrics.samples;
刚切换到 clickhouse 存储数据、数据比较少
十:与第三方中间件集成:
10.1:ClickHouse 与 Kafka 集成: (了解,很少用)
clickhouse作为查询消费入口, 数据还是在kafka中
Clickhouse 的自带了 Kafka Engine,使得 Clickhouse 和 Kafka 的集成变得非常容易, 基于 clickhouse Kafka 引擎结合 Kafka 使用,可实现将业务数据同步到 clickhouse 的目的, 方便其他业务从 clickhouse 消费数据。
10.1.2:ClickHouse 与 Kafka 集成流程:
通常将 kafka 引擎结合物化视图一起使用,使用方法如下: 1.使用 Kafka 引擎创建一个 Kafka 的消费者,并将其视为一个数据流。 2.创建所需的数据表用于保存后期从 kafka 消费到 clickhouse 的数据。 3.创建对应的物化视图,该视图聚合运算来自 kafka 引擎的数据并将其放入上一步创建的数 CH 据表中。 当物化视图被添加至 kafka 引擎,它将会在后台收集数据,可以持续不断地从 Kafka 收集 数据并通过 SELECT 将数据转换为所需要的格式并写入到 clickhouse 目的数据表。 为了提高性能,接受的消息被分组为 max_insert_block_size(默认 1048576=1k)大小的块, 如果未在 stream_flush_interval_ms(默认 7500 毫秒)内形成块,则不关心块的完整性,都会 将数据刷新到表中。
https://clickhouse.com/docs/zh/engines/table-engines/integrations/kafka
Kafka 引擎支持使用 ClickHouse 配置文件进行扩展配置,可以使用两个配置键:全局 (kafka) 和 主题级别 (kafka_TOPIC),首先应用全局配置,然后应用主题级配置 #例如 配置说明如下: [root@clickhouse-node1 clickhouse-server]# vim /etc/clickhouse-server/config.d/kafka.xml #下一步新建此文档 <!-- Global configuration options for all tables of Kafka engine type --> <kafka> <debug>cgrp</debug> #cgrp #是消费者的核心,主要功能拉取消息和处理消费者组的相关操作,比如 join group, sync group <auto_offset_reset>smallest</auto_offset_reset> #auto.offset.reset #当偏移存储中没有初始偏移位置或所需偏移超出范围时要采取的操作,beginning、latest </kafka> <!-- Configuration specific for topic "logs" --> <kafka_logs> <retry_backoff_ms>250</retry_backoff_ms> #失败请求重试时间 <fetch_min_bytes>100000</fetch_min_bytes> #获取消息的最小字节数 </kafka_logs>
10.1.4: 自定义 kafka 配置并重启 CK:
#创建该文件 [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/config.d/kafka.xml <yandex> <kafka> <debug>cgrp</debug> <auto_offset_reset>smallest</auto_offset_reset> </kafka> <!-- Configuration specific for topic "topic_ch" --> <kafka_topic_ch> #topic名称,叫topic_ch,kafka中也得有这个topic <auto_offset_reset>latest</auto_offset_reset> <retry_backoff_ms>250</retry_backoff_ms> #对给定主题分区的失败请求之前等待的时 <fetch_min_bytes>100000</fetch_min_bytes> #一次获取数据的最小值 </kafka_topic_ch> </yandex> [root@clickhouse-node1 ~]# systemctl restart clickhouse-server.service
基于 docker-compose https://gitee.com/jiege-gitee/kafka 部署 kafka (10.0.0.151):
[root@prometheus-server1 ~]#mkdir /data/kafka -p [root@prometheus-server1 ~]#cd /data/kafka #如果之前做过的话,把卷删了,不然影响实验效果 #root@ubuntu22-04-2:/data/kafka# docker volume rm kafka_zookeeper_vol #root@ubuntu22-04-2:/data/kafka# docker volume rm kafka_kafka_vol [root@prometheus-server1 kafka]#git clone https://gitee.com/jiege-gitee/kafka.git [root@pro metheus-server1 kafka]#cd kafka/ [root@prometheus-server1 kafka]#apt install docker-compose [root@prometheus-server1 kafka]#docker-compose up -d #查看kafka是否是启动的 [root@prometheus-server1 kafka]#docker ps #进入kafka容器中 [root@prometheus-server1 kafka]#docker exec -it kafka-container bash bash-5.1# cd /opt/kafka #创建topic topic_ch,分片为1,连接zookeeper bash-5.1# ./bin/kafka-topics.sh --create --topic topic_ch --replication-factor 1 --partitions 1 --zookeeper 10.0.0.151:2181 #可以列出topic,验证是否创建出来 bash-5.1# ./bin/kafka-topics.sh --list --zookeeper=10.0.0.151:2181 topic_ch #内置了kafka管理工具manager可以连接 http://10.0.0.151:9000/ #这里可以点击添加cluster(集群),名称kafka1 #zookeeper地址输入 10.0.0.151 #kafka版本选2.4.0(这里用的2.8,因为没有就选2.4),点save
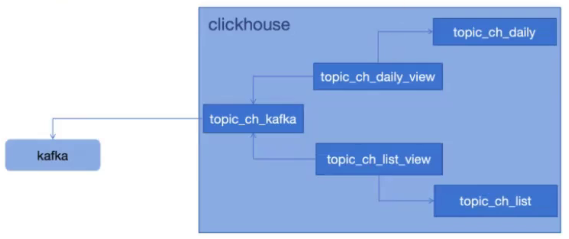
10.1.6:CK 创建 kafka 引擎数据流表:
指定 kafka 服务器、topic 名称,消费组、及数据格式为 JSON 行格式
创建 clickhouse Kafka 引擎表必要的参数:
kafka_broker_list # 以逗号分隔的kafka brokers 列表,如 172.31.1.101:9092,172.31.1.102:9092。 kafka_topic_list #以逗号分隔的 kafka 的 topic 列表,如 my_topic1,my_topic2 kafka_group_name #Kafka 消费组名称,如 group1。 kafka_format #消息的格式,例如 JSONEachRow。 #可选参数: kafka_row_delimiter #每个消息体(记录)之间的分隔符。 kafka_schema #按需定义 schema, kafka_num_consumers #消费者数量,默认 1,最多不超过 Topic 的分区 [root@clickhouse-node1 config.d]# clickhouse-client --password 123456 -m clickhouse-node1 :) use test; clickhouse-node1 :) DROP TABLE test.topic_ch_kafka; #这个表和kafka对接,group_ch为组名 clickhouse-node1 :) CREATE TABLE topic_ch_kafka ( timestamp UInt64, level String, message String ) ENGINE = Kafka('10.0.0.151:9092', 'topic_ch', 'group_ch', 'JSONEachRow');
select * from topic_ch_kafka;#进入kafka容器 [root@prometheus-server1 kafka]# docker exec -it kafka-container bash bash-5.1# cd /opt/kafka #往kafka中写数据(这里实验写不进去数据,group_ch为无效的REPLICATION_FACTOR) bash-5.1# ./bin/kafka-console-producer.sh --topic topic_ch --broker-list 10.0.0.151:9092 {"timestamp":1705663634,"level":"high","message":"test massage"} {"timestamp":1705663632,"level":"info","message":"test massage"} {"timestamp":1705663633,"level":"mid","message":"test massage"} {"timestamp":1705663634,"level":"low","message":"test massage"} #clickhouse查数据验证 clickhouse-node1 :)select * from topic_ch_kafka; #这时已实现从clickhouse查询kafka的目的,如果kafka挂了,clickhouse就查不到数据了 #clickhouse可以再建几个表,将能查到的数据运算或者往别的表里写,这样即使kafka挂了,clickhouse还能查到数据
:) DROP TABLE topic_ch_list; :) CREATE TABLE topic_ch_list ( timestamp UInt64, level String, message String ) ENGINE = MergeTree() order by (timestamp); #物化图的数据从数据流表 topic_ch_kafka 读取并聚合后写入另外一张清单表: :) DROP TABLE topic_ch_list_view; :) CREATE MATERIALIZED VIEW topic_ch_list_view TO topic_ch_list AS SELECT timestamp, level, message FROM topic_ch_kafka;
:) DROP TABLE topic_ch_daily; :) CREATE TABLE topic_ch_daily ( day Date, level String, total UInt64 ) ENGINE = SummingMergeTree(day) ORDER BY (day, level); :) DROP TABLE topic_ch_daily_view; :) CREATE MATERIALIZED VIEW topic_ch_daily_view TO topic_ch_daily AS SELECT toDate(toDateTime(timestamp)) AS day, level, count() as total FROM topic_ch_kafka GROUP BY day, level;
:) select * from topic_ch_list; :) select * from topic_ch_daily;
https://clickhouse.com/docs/zh/engines/database-engines/mysql #映射整个库
https://clickhouse.com/docs/zh/engines/table-engines/integrations/mysql #映射单个表
库引擎,不支持如下操作: RENAME, CREATE TABLE, ALTER, 支持INSERT, SELECT操作(最终存入mysql中)
10.2.1:与 MySQL 集成简介:
1.虽然 clickhouse mysql 引擎支持 insert 语句插入数据,但是不建议使用,生产环境建议在 clickhouse 使用 mysql 只读账号做数据查询使用。 2.ClickHouse 表结构可以不同于原始的 MySQL 表结构。 3.CK 列名应当与原始 MySQL 表中的列名相同,但可以按任意顺序使用其中的一些列。 4.CK 列的数据类型可以与原始的 MySQL 表中的列类型不同,ClickHouse 尝试进行数据类 型转换。
#映射指定单个库的参数: CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] ENGINE = MySQL('host:port', ['database' | database], 'user', 'password') host:port #MySQL 服务地址 database #MySQL 数据库名称 user #MySQL 用户名 password #MySQL 用户密码 #只映射指定单个表的额外参数: MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query,'on_duplicate_clause']); replace_query # 将INSERT INTO查询是否替换为REPLACE INTO的标志,如果replace_query=1则替换查询,replace_query=0 为不替换。 on_duplicate_clause # 将(ON DUPLICATE KEY UPDATE, 允许主键冲突的数据写入)'on_duplicate_clause'表达式添加到 INSERT 查询语句中以允许对重复数据进行写入。
# docker pull mysql:5.7.36 # docker run -it -d -p 3306:3306 --name mysql_server -e MYSQL_ROOT_PASSWORD=12345678 mysql:5.7.36 # docker ps #docker logs -f fcbff87dcf79 CK 服务器测试连接: #安装mysql客户端,用于连接 [root@clickhouse-node1 ~]# yum install mariadb [root@clickhouse-node1 ~]# mysql -uroot -p12345678 -h10.0.0.151 mysql> create database myserver; mysql> create table myserver.app( id INT NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id) ); mysql> insert into myserver.app (id,name,age) VALUES (1,'jack',18); mysql> insert into myserver.app (id,name,age) VALUES (2,'tom',20); mysql> select * from myserver.app;
实际剩余操作略
10.3:MySQL 数据迁移至 CK:
https://github.com/MinervaDB/MinervaDB-ClickHouse-MySQL-Data-Reader #第三方项目(用这个)
https://clickhouse.com/docs/zh/engines/database-engines/materialized-mysql #官方项目,目前为实验特性不建议生产使用
数据同步服务器:10.0.0.156 #安装迁移工具clickhouse-mysql(支持增量同步,增量部分继续同步,但不建议) MySQL 服务器:10.0.0.151 CK 服务器:10.0.0.150
数据同步服务器基础环境准备:
#根据上面文档,安装mysql5.7源,相关依赖 [root@centos7 ~]# sudo yum install -y https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm [root@centos7 ~]# sudo yum install -y epel-release #下面这个找不到源,实验失败 [root@centos7 ~]# curl -s https://packagecloud.io/install/repositories/altinity/clickhouse/script.rpm.sh | sudo bash 修改 repo 不校验 [root@centos7 ~]# vim /etc/yum.repos.d/mysql-community.repo :%s/gpgcheck=1/gpgcheck=0/g [root@centos7 ~]#sudo yum install -y clickhouse-client [root@centos7 ~]# sudo yum install -y mysql-community-devel [root@centos7 ~]# sudo yum install -y mariadb-devel [root@centos7 ~]# sudo yum install -y gcc [root@centos7 ~]# sudo yum install -y python36-devel python36-pip [root@centos7 ~]# pip3.6 install --upgrade pip [root@centos7 ~]# pip3.6 --version pip 21.3.1 from /usr/local/lib/python3.6/site-packages/pip (python 3.6) [root@centos7 ~]# pip3.6 install clickhouse-mysql [root@centos7 ~]# python3.6 get-pip.py #如果环境异常、可重新安装 pip
源 MySQL 服务器必须开启 binlog
root@middleware:~# mkdir /data/etc/mysql/mysql.conf.d/ -p root@middleware:~# docker ps #从容器拷贝到宿主机上 root@middleware:~# docker cp mysql_server:/etc/mysql/mysql.conf.d/mysqld.cnf /data/etc/mysql/mysql.conf.d/ root@middleware:~# vim /data/etc/mysql/mysql.conf.d/mysqld.cnf #必须启用 binlog [mysqld] pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock datadir = /var/lib/mysql server-id = 1 #追加这三行 log_bin = /var/lib/mysql/bin.log binlog-format = row #删了之前的容器重新挂配置,如果是二进制安装就直接建就行 root@middleware:~# docker rm -fv mysql_server root@middleware:~# docker run -it -d -p 3306:3306 --name mysql_server -e MYSQL_ROOT_PASSWORD=12345678 -v /data/etc/mysql/mysql.conf.d/mysqld.cnf:/etc/mysql/mysql.conf.d/mysqld.cnf -v /data/mysql:/var/lib/mysql mysql:5.7.36 root@middleware:~# docker logs -f mysql_server #验证 MySQL 服务启动成功 root@middleware:~# docker exec -it mysql_server bash #写入数据 mysql> create database myserver; mysql> create table myserver.app ( id INT NOT NULL AUTO_INCREMENT, name varchar(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id) ); mysql> insert into myserver.app (id,name,age) VALUES (1,'jack',18); mysql> insert into myserver.app (id,name,age) VALUES (2,'tom',20);
#在数据同步服务器启动数据同步并周期同步增量数据: (通常情况下同步一次就行了)
增量同步时增量部分会有4个,过段时间会合并, 这段时间查数据会有多个, 所以不建议使用增量同步
clickhouse-node1:) drop database myserver; #删除已有数据库、或clickhouse #开始同步数据 [root@centos7 ~]# clickhouse-mysql \ --src-server-id=1 \ #指定server-id --src-wait \ #等待同步 --nice-pause=300 \ #周期,每隔300s同步一次(如果是增量,每5分钟同步一次) --src-host=10.0.0.151 \ #源数据库地址 --src-user=root \ --src-password=12345678 \ --src-tables=myserver.app \ #同步表,可以写多个,中间用逗号隔开(不同库的表也行) --dst-host=10.0.0.150 \ #目的服务器地址 clickhouse --dst-password=123456 \ --dst-create-table \ #如果不存在就创建 --migrate-table \ #合并表 --pump-data \ --csvpo #CK 验证数据: clickhouse-node1:) select * from myserver.app;
了解, 优势支持更多数据库, 不推荐, java本身也有性能瓶颈
集群部署简介:https://clickhouse.com/docs/en/architecture/cluster-deployment 集群实现方式:https://clickhouse.com/docs/zh/operations/clickhouse-keeper ClickHouse Keeper #目前处于不稳定阶段 zookeeper #稳定,推荐使用
6台机器做clickhouse节点(centos7),3台做zookeeper集群(ubuntu)
#zookeeper用与集群状态通告,集群库分片副本管理
#假如2分片3副本,同一个分片3个副本都是主(往哪个副本些都一样,会向两外两个副本进行复制,没有主备观念)
数据复制通过part, mysql是通过binlog。这两者是不同的(如果改一个地方,也是part块复制,不太合适,mysql如果改一点就binlog的sql语句复制到从库修改即可)
11.3:部署 zookeeper 集群
各节点安装 JDK 环境: ~# apt install openjdk-11-jdk 各节点部署 zookeeper: ~# mkdir /apps ~# cd /apps/ /apps# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.2/apache-zookeeper-3.7.2-bin.tar.gz /apps# tar xvf apache-zookeeper-3.7.2-bin.tar.gz /apps# ln -sv /apps/apache-zookeeper-3.7.2-bin /apps/zookeeper apps# cd /apps/zookeeper/conf/ #一台机器改完配置拷贝到另外两台 root@clickhouse-zookeeper1:/apps/zookeeper/conf# cp zoo_sample.cfg zoo.cfg root@clickhouse-zookeeper1:/apps/zookeeper/conf# vim zoo.cfg dataDir=/data/zookeeper #指定数据目录 server.151=10.0.0.151:2888:3888 #追加集群配置 server.主机id(这里写ip最后一位即可) server.152=10.0.0.152:2888:3888 server.153=10.0.0.153:2888:3888 root@clickhouse-zookeeper1:/apps/zookeeper/conf# scp zoo.cfg 10.0.0.152:/apps/zookeeper/conf root@clickhouse-zookeeper1:/apps/zookeeper/conf# scp zoo.cfg 10.0.0.153:/apps/zookeeper/conf 各节点操作 #各个节点创建数据目录 /apps/zookeeper/conf# mkdir /data/zookeeper -p #各个节点id写入myid文件中(必须叫myid文件) root@clickhouse-zookeeper1:/apps/zookeeper/conf# echo 151 > /data/zookeeper/myid root@clickhouse-zookeeper2:/apps/zookeeper/conf# echo 152 > /data/zookeeper/myid root@clickhouse-zookeeper3:/apps/zookeeper/conf# echo 153 > /data/zookeeper/myid #各个节点启动zookeeper :/apps/zookeeper/conf# /apps/zookeeper/bin/zkServer.sh start #查看状态,谁是主(选举中id大的会被选为主) /apps/zookeeper/conf# /apps/zookeeper/bin/zkServer.sh status
#在各个clickhouse节点配上主机名解析(如果配置用ip地址解析可以不配,但我测试下来要配) [root@ck01 ~]# vim /etc/hosts 10.0.0.157 ck01 10.0.0.158 ck02 10.0.0.159 ck03 10.0.0.160 ck04 10.0.0.161 ck05 10.0.0.162 ck06 #这次使用官方yum源安装 ~]# sudo yum install -y yum-utils ~]# sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo #启用 LTS(长期支持版) 镜像源(默认没有启用) ~]# vim /etc/yum.repos.d/clickhouse.repo [clickhouse-stable] name=ClickHouse - Stable Repository baseurl=https://packages.clickhouse.com/rpm/stable/ gpgkey=https://packages.clickhouse.com/rpm/stable/repodata/repomd.xml.key gpgcheck=0 repo_gpgcheck=0 enabled=1 [clickhouse-lts] name=ClickHouse - LTS Repository baseurl=https://packages.clickhouse.com/rpm/lts/ gpgkey=https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key gpgcheck=0 repo_gpgcheck=0 enabled=1 #国外的key很慢,建议关闭 :%s/enabled=0/enabled=1/g :%s/repo_gpgcheck=1/repo_gpgcheck=0/g #查看仓库的 clickhouse 版本: ~]# yum list clickhouse-server.x86_64 --showduplicates | sort -r 各节点安装指定版本 CK: ~]# sudo yum install clickhouse-server-23.8.9.54-1 clickhouse-client-23.8.9.54-1
https://clickhouse.com/docs/en/operations/server-configuration-parameters/settings#timezone #配置参数
https://clickhouse.com/docs/en/operations/configuration-files#substitution #/etc/metrika.xml 等配置文件路径
11.5.2: 各节点指定监听地址:
#clickhouse集群配置 #对每个clickhouse进行配置 [root@ck01 ~]#vim /etc/clickhouse-server/config.xml <listen_host>0.0.0.0</listen_host> <!-- 追加内容 --> <timezone>Asia/Shanghai</timezone> <path>/data/clickhouse/data/</path> <!-- 修改数据目录 --> <tmp_path>/data/clickhouse/tmp/</tmp_path> <!-- 修改临时数据目录 --> <include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from> <!-- 导入自定义配置文件 --> <zookeeper incl="zookeeper-servers" optional="false" /> <!-- ZK 配置 --> :x! 强制保存 #对每个clickhouse配置default账号密码 [root@ck01 ~]#vim /etc/clickhouse-server/users.xml <password>123456</password> #对每个clickhouse配置集群metrika配置 [root@ck01 ~]#vim /etc/clickhouse-server/config.d/metrika.xml <yandex> <remote_servers> <myserver_clickhouse_cluster> <!--集群名称--> <shard> <!--其中一个分片的设置--> <internal_replication>true</internal_replication> <!--内部复制,一定要是true--> <replica> <!--其中一个分片下的副本--> <host>10.0.0.157</host> <port>9000</port> <user>default</user> <!--连接账号--> <password>123456</password> </replica> <replica> <host>10.0.0.158</host> <port>9000</port> <user>default</user> <password>123456</password> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>10.0.0.159</host> <port>9000</port> <user>default</user> <password>123456</password> </replica> <replica> <host>10.0.0.160</host> <port>9000</port> <user>default</user> <password>123456</password> </replica> </shard> <shard> <replica> <internal_replication>true</internal_replication> <host>10.0.0.161</host> <port>9000</port> <user>default</user> <password>123456</password> </replica> <internal_replication>true</internal_replication> <replica> <host>10.0.0.162</host> <port>9000</port> <user>default</user> <password>123456</password> </replica> </shard> </myserver_clickhouse_cluster> </remote_servers> <zookeeper-servers> <!--zk配置--> <node index="151"> <!--主机id--> <host>10.0.0.151</host> <port>2181</port> </node> <node index="152"> <host>10.0.0.152</host> <port>2181</port> </node> <node index="153"> <host>10.0.0.153</host> <port>2181</port> </node> </zookeeper-servers> <macros> <!--分片的宏配置,仅对本机生效,每台主机都要改下--> <layer>01</layer> <!--类似分层(非必须)--> <shard>01</shard> <!--分片的宏配置、shard表示分片的编号、01表示第一个分片,用于对当前分片实现唯一的标识,后续建表的时候需要要到(对应上面第一个<shard>)--> <replica>10.0.0.157</replica> <!--replica为配置副本的标识符,可以是其他方便区分分片的值,比如主机名简称--> </macros> <networks> <!--监听地址--> <ip>::/0</ip> <!--允许任意地址访问 --> </networks> <clickhouse_compression> <!--压缩配置--> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <!--最小压缩比--> <method>lz4</method> </case> </clickhouse_compression> </yandex> #第二台机器修改部分示例 ... #前面内容保持一致 <macros> <!--分片的宏配置,仅对本机生效,每台主机都要改下--> <layer>01</layer> <!--类似分层(非必须)--> <shard>01</shard> <!--属于同一个分片下另一个副本,所以也是01--> <replica>10.0.0.158</replica> </macros> ... #第三台机器修改部分示例 ... #前面内容保持一致 <macros> <!--分片的宏配置,仅对本机生效,每台主机都要改下--> <layer>01</layer> <!--类似分层(非必须)--> <shard>02</shard> <!--属于同一个分片下另一个副本,所以也是01--> <replica>10.0.0.159</replica> </macros> ... #每台clickhouse执行操作 #创建数据目录 [root@ck01 ~]#mkdir /data/clickhouse/data /data/clickhouse/tmp -p #clickhouse是以普通用户运行的,所以数据目录也要改权限 [root@ck01 ~]#chown -R clickhouse:clickhouse /data/clickhouse/ #重启 [root@ck01 ~]#systemctl restart clickhouse-server.service #测试 [root@ck01 ~]#ss -lnt #看9000和8123端口是否开启 [root@ck01 ~]#vim /var/log/clickhouse-server/clickhouse-server.err.log #看有没有报错 #连接clickhouse [root@ck01 ~]#clickhouse-client -h10.0.0.157 --password 123456 -m #验证集群配置 ubuntu :)select * from system.clusters; #default是本机
本地(复制)表: 实际存储数据的表,可以基于多分片提高并发读写性能、并且基于副本实现高可用。 分布式表: 一个逻辑上的表, 可以理解为数据库中的视图, 一般查询都查询分布式表,分布式表引擎会 将客户端的查询请求路由给本地表进行查询, 然后进行汇总最终返回给用户. #加上ON CLUSTER参数表示在集群创建(每个主机都会创建同一个库或表),而不是在本地创建 CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]]) [SETTINGS name=value, ...]#引擎Distributed表示分布式表 创建本地复制参数: cluster_name: 集群名称。 db_name: 数据库名称,可使用常量表达式:currentDatabase()。 table_name: 各分片上的表名称。 sharding_key:(可选)分片的 key,可设置为 rand()。 policy_name:(可选)策略名称,用于存储异步发送的临时文件。
例: #先连接到主机clickhouse [root@ck01 ~]#clickhouse-client -h10.0.0.157 --password 123456 -m #在集群删除数据库(集群中每个主机都会删除,没有这个库就报错) :) drop database cluster_db_test ON CLUSTER myserver_clickhouse_cluster; #在集群创建数据库(每个主机都会创建这个库) (0就是成功,error没信息就是成功) :) CREATE DATABASE cluster_db_test ON CLUSTER myserver_clickhouse_cluster; ┌─host───────┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐ 1. │ 10.0.0.154 │ 9000 │ 0 │ │ 5 │ 0 │ 2. │ 10.0.0.151 │ 9000 │ 0 │ │ 4 │ 0 │ 3. │ 10.0.0.156 │ 9000 │ 0 │ │ 3 │ 0 │ 4. │ 10.0.0.153 │ 9000 │ 0 │ │ 2 │ 0 │ 5. │ 10.0.0.152 │ 9000 │ 0 │ │ 1 │ 0 │ 6. │ 10.0.0.155 │ 9000 │ 0 │ │ 0 │ 0 │ └────────────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘ #在另一台主机上进行验证 [root@ck06 ~]#clickhouse-client -h10.0.0.162 --password 123456 -m ubuntu :) show databases; #有cluster_db_test说明集群创建库成功 ┌─name───────────────┐ 1. │ INFORMATION_SCHEMA │ 2. │ cluster_db_test │ 3. │ default │ 4. │ information_schema │ 5. │ system │ └────────────────────┘ #在任何一个主机上切入这个库 :) use cluster_db_test; #创建本地测试表,会在每台CK服务器同时创建的本地表(只能查询到当前分片的数据,无法查询到其他主机分片内的数据) (引擎ReplicatedMergeTree表示复制表) :) CREATE TABLE cluster_db_test.local_table ON CLUSTER myserver_clickhouse_cluster ( `id` Int64, `name` String, `age` Int32 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/local_table', '{replica}') #变量从主机配置文件中调用,路径在zookeeper中进行维护 ORDER BY id; # 创建测试分布式表、需要对应上一步创建的集群的复制表(通过分布式表可以查询表中的所有数据) (引擎Distributed为分布式表) :) CREATE TABLE cluster_db_test.cluster_table ON CLUSTER myserver_clickhouse_cluster ( `id` Int64, `name` String, `age` Int32 ) ENGINE = Distributed('myserver_clickhouse_cluster', 'cluster_db_test', 'local_table', rand()); #在myserver_clickhouse_cluster集群cluster_db_test库,local_table表,rand表示读写随机
# 在分片 1 服务器 157,连接 clickhouse,向本地表插入以下测试数据: [root@ck01 ~]#clickhouse-client -h10.0.0.157 --password 123456 -m :) use cluster_db_test; :) insert into local_table values(1,'zhang',1),(2,'li',2),(3,'zhao',3),(4,'qian',4),(5,'sun',5),(6,'wang',6),(7,'tian',7),(8,'he',8),(9,'zheng',9),(10,'dong',10); # 在分片 1 服务器 158,连接 clickhouse,向本地表插入以下测试数据: [root@ck02 ~]#clickhouse-client -h10.0.0.158 --password 123456 -m :) use cluster_db_test; :) insert into local_table values (11,'aa',11),(12,'bb',12),(13,'cc',13);
# 验证数据分片以及副本状态(157 和 158): :) use cluster_db_test; :) select * from local_table; # 本地复制表在不同服务器中只能看到在本服务器(单机环境)或同分片所有副本主机(多分片环境)插入的数据 #这里157,158会看到互相合并的数据,因为他们是同一分片,其他主机没有数据 :) select * from cluster_table; # 分布式表无论在哪台服务器执行,都可看到插入的所有数据 #所有主机都会看到数据
1.分布式表基于 Distributed 引擎创建,在多个分片上实现分布式读写。 2.数据读是自动并行化的,可使用远程服务器上的索引(如果有)。 3.数据在请求的本地服务器上尽可能地被部分处理。例如对于 GROUP BY 查询,数据将在 远程服务器上聚合,聚合函数的中间状态将发送到请求服务器,然后数据将进一步聚合。 4.生产业务很少逐个 node 读取本地复制表,推荐基于分布式表读数据、基于本地复制表写 数据。 #写的话,可以让开发用轮询的方式,在一个一个主机本地表上写数据 #如果写入分布式表,rand,那就随机落入某个主机 # 基于分布式表插入数据,任意节点执行 :) use cluster_db_test; :) insert into cluster_table values (14,'hh',14),(15,'ii',15),(16,'jj',16),(17,'kk',17),(18,'ll',18),(19,'mm',19); #从每个节点查看数据 [root@ck03 ~]#clickhouse-client -h10.0.0.159 --password 123456 -m :) select * from local_table; #每个节点都可能会有上面14-19中的部分数据(副本内容相同) ┌─id─┬─name─┬─age─┐ │ 14 │ hh │ 14 │ │ 15 │ ii │ 15 │ │ 16 │ jj │ 16 │ └────┴──────┴─────┘ :) select * from cluster_table; #会有全部数据 ┌─id─┬─name──┬─age─┐ │ 1 │ zhang │ 1 │ │ 2 │ li │ 2 │ │ 3 │ zhao │ 3 │ │ 4 │ qian │ 4 │ │ 5 │ sun │ 5 │ │ 6 │ wang │ 6 │ │ 7 │ tian │ 7 │ │ 8 │ he │ 8 │ │ 9 │ zheng │ 9 │ │ 10 │ dong │ 10 │ └────┴───────┴─────┘ ┌─id─┬─name─┬─age─┐ │ 11 │ aa │ 11 │ │ 12 │ bb │ 12 │ │ 13 │ cc │ 13 │ └────┴──────┴─────┘ ┌─id─┬─name─┬─age─┐ │ 17 │ kk │ 17 │ │ 18 │ ll │ 18 │ │ 19 │ mm │ 19 │ └────┴──────┴─────┘ ┌─id─┬─name─┬─age─┐ │ 14 │ hh │ 14 │ │ 15 │ ii │ 15 │ │ 16 │ jj │ 16 │ └────┴──────┴─────┘
执行分布式查询时, 首先计算分片的每个副本的错误数,然后将查询发送至最少错误的副 本,通常副本是没有错误的,如果没有错误或者错误数相同,则按如下的策略查询数据: https://clickhouse.com/docs/en/operations/settings/settings#load_balancing 1. Random (默认):将查询发送至任意一个副本 2. nearest_hostname:将查询发送至主机名最相似的副本。 3. in_order:将查询按配置文件中的配置顺序发送至副本。 4. first_or_random:优先选择第一个副本,如果第一个副本不可用,再随机选择一个可用 的副本 5. round_robin:该算法在具有相同错误数量的副本之间使用循环策略 6. hostname_levenshtein_distance:具有相同错误数量的副本将按照配置中指定的顺序进 行访问
关闭分配的一个副本,验证数据是否可以正常读写 #关闭分片 1 的副本 [root@ck02 ~]# systemctl stop clickhouse-server.service #不影响clickhouse1的读写(分片只要有一个副本就能正常读写) ck01 :) select * from local_table; ck01 :) select * from cluster_table; #如果把分片1的两个副本都关了,其他节点还能查到数据,但是分片1的数据查不到了 #再启动分片1 其中一个副本,又能查到全部数据了 #注意如果挂了的节点起来,会立即同步副本的数据
1.只有 MergeTree 系列引擎支持数据副本,支持副本的引擎是在 MergeTree 引擎名称的前 面加上前缀 Replicated。 2.副本是表级别的而不是整个服务器级别的,因此,服务器可以同时存储复制表和非复制表 3.副本不依赖于分片,每个分片都有自己独立的副本,如下: ReplicatedMergeTree ReplicatedSummingMergeTree ReplicatedReplacingMergeTree ReplicatedAggregatingMergeTree ReplicatedCollapsingMergeTree ReplicatedVersionedCollapsingMergeTree ReplicatedGraphiteMergeTree 复制是多主异步的(Replication is asynchronous and multi-master),集群中的每个节点角色 对等,客户端访问任意一个节点都能得到相同的效果,这种多主的架构有许多优势,例如对 等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的 所有节点功能相同,所以它天然规避了单点故障的问题。 INSERT 语句(以及 ALTER)可在任意可用的服务器上执行,数据首先插入到本地的服务器 (即运行查询的服务器),然后数据被复制到其他服务器。 由于复制是异步的,所以最近插入的数据出现在其他副本上查询会有一定的延迟。 如果部分副本不可用,则会在该副本恢复后会自动从其他副本同步数据并可写入数据。 副本可用时读写等待的时间是通过网络传输压缩数据块所耗费的时间。 默认情况下,INSERT 操作只需等待一个副本写入成功后返回,如果要启动来自多个副本的 写入确认机制,可以设置 insert_quorum 选项,默认是写入一个副本就返回写入完成。 :) select * from system.settings where name = 'insert_quorum';
https://github.com/Altinity/clickhouse-backup
十 二 : 基 于 helm 在 Kubernetes 部 署 ClickHouse 集群
12.1:存储类准备:
注意: 存储类会决定clickhouse的性能
[root@master01 ~]#kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE nfs-csi nfs.csi.k8s.io Delete Immediate false 27m
https://bitnami.com/stack/clickhouse/helm
注意: 下面方法bitnami删除了dockerhub上的clickhouse镜像, 此方法已不可用
#本地helm配置 添加 Bitnami 的 Helm 仓库地址 #这里需要先开vpn代理,helm才能添加bitnami仓库地址 [root@master01 ~]#export HTTPS_PROXY=http://10.0.0.1:7890 [root@master01 ~]#helm repo add bitnami https://charts.bitnami.com/bitnami #在 已登记到本地的仓库索引 里做关键字搜索 [root@master01 ~]#helm search repo clickhouse -l NAME CHART VERSION APP VERSION DESCRIPTION bitnami/clickhouse 9.4.4 25.7.5 ClickHouse is an open-source column-oriented OL... bitnami/clickhouse 9.4.3 25.7.4 ClickHouse is an open-source column-oriented OL... ... bitnami/clickhouse 4.0.4 23.8.3 ClickHouse is an open-source column-oriented OL... [root@master01 ~]#mkdir -p /data/helm/charts [root@master01 ~]#cd /data/helm/charts #指定chart版本,相当于指定了helm的版本 #下载chart包到当前目录,改下参数再装 (直接装也行,但有些参数不太好改) [root@master01 charts]#helm pull bitnami/clickhouse --version=4.0.4 #稳定版 #解压 [root@master01 charts]#tar xvf clickhouse-4.0.4.tgz [root@master01 charts]#cd clickhouse/ #修改变量 [root@master01 clickhouse]#vim values.yaml ... shards: 2 #默认2个分片 replicaCount: 3 #默认3个副本 ... auth: username: default password: "123456" #默认不提供密码要改下 existingSecret: "" existingSecretKey: "" #service类型默认是clusterIP,可后期创建后单独改service,如果这里直接改nodeport所有端口都暴露了 #ingress没必要,通过service访问就可以了,再绕ingress会慢些(本身就是nginx) ... persistence: enabled: true existingClaim: "" storageClass: "nfs-csi" #修改存储类,会为clickhouse动态创建pv,pvc ... #metrics指标可以暴露出来,让promethues进行抓取 metrics: enabled: true #这里改成true podAnnotations: prometheus.io/scrape: "true" #允许promethues服务发现,直接发现pod进行指标采集 prometheus.io/port: "{{ .Values.containerPorts.metrics }}" #端口 #安装 clickhouse: [root@master01 charts]#pwd /data/helm/charts #指定名称空间,这里就用default #这里需先取消下上面的代理,否则k8s的连接也走代理导致无法连接apiserver无法使用kubectl [root@master01 charts]#unset HTTPS_PROXY #bitnami删除了dockerhub上的clickhouse镜像,这一步无法下载镜像安装了 [root@master01 charts]#helm install myserver-clickhouse /data/helm/charts/clickhouse [root@master01 charts]#kubectl get pod NAME READY STATUS RESTARTS AGE myserver-clickhouse-shard0-0 1/1 Running 0 34m #第1个副本 myserver-clickhouse-shard0-1 1/1 Running 0 34m #第2个副本 myserver-clickhouse-shard0-2 1/1 Running 0 34m #第3个副本 myserver-clickhouse-shard1-0 1/1 Running 0 34m myserver-clickhouse-shard1-1 1/1 Running 0 34m myserver-clickhouse-shard1-2 1/1 Running 0 34m myserver-clickhouse-zookeeper-0 1/1 Running 0 34m myserver-clickhouse-zookeeper-1 1/1 Running 0 34m myserver-clickhouse-zookeeper-2 1/1 Running 0 3
root@k8s-master1:/data/helm# kubectl exec -it myserver-clickhouse-shard0-0 bash myserver-clickhouse-shard0-0.myserver-clickhouse-headless.default.svc.cluster.local :) show databases; ┌─name───────────────┐ │ INFORMATION_SCHEMA │ │ default │ │ information_schema │ │ system │ └────────────────────┘ myserver-clickhouse-shard0-0.myserver-clickhouse-headless.default.svc.cluster.local :) #查询在zookeeper的注册信息 SELECT * FROM system.zookeeper WHERE path = '/clickhouse'; myserver-clickhouse-shard0-0.myserver-clickhouse-headless.default.svc.cluster.local :) #查看集群状态 select * from system.clusters;
root@k8s-master1:/data/helm# kubectl edit svc myserver-clickhouse ... type: NodePort #改成nodeport
[root@clickhouse-node1 ~]# clickhouse-client -h 10.0.0.153 --port 57412 --password 123456 -m myserver-clickhouse-shard1-2.myserver-clickhouse-headless.default.svc.cluster.local :) show databases; #在集群创建数据库: default.svc.cluster.local :) CREATE DATABASE cluster_db_test ON CLUSTER default; #在集群创建本地复制表: default.svc.cluster.local :) CREATE TABLE cluster_db_test.local_table ON CLUSTER default ( `id` Int64, `name` String, `age` Int32 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{layer}-{shard}/local_table', '{replica}') ORDER BY id; #在集群创建分布式表: default.svc.cluster.local :) CREATE TABLE cluster_db_test.cluster_table ON CLUSTER default ( `id` Int64, `name` String, `age` Int32 ) ENGINE = Distributed('default', 'cluster_db_test', 'local_table', rand()); #向本地复制表插入数据: #当前表有 default.svc.cluster.local :) use cluster_db_test; default.svc.cluster.local :) insert into local_table values(1,'zhang',1),(2,'li',2),(3,'zhao',3),(4,'qian',4),(5,'sun',5),(6,'wang',6),(7,'tian',7),(8,'he',8)(9,'zheng',9),(10,'dong',10); #集群表插入数据: #随机转发到不同分片上 default.svc.cluster.local :) insert into cluster_table values (14,'hh',14),(15,'ii',15),(16,'jj',16),(17,'kk',17),(18,'ll',18),(19,'mm',19); #验证本地复制表数据读: default.svc.cluster.local :) select * from cluster_db_test.local_table; #验证分布式表数据读取: default.svc.cluster.local :) select * from cluster_db_test.cluster_table;
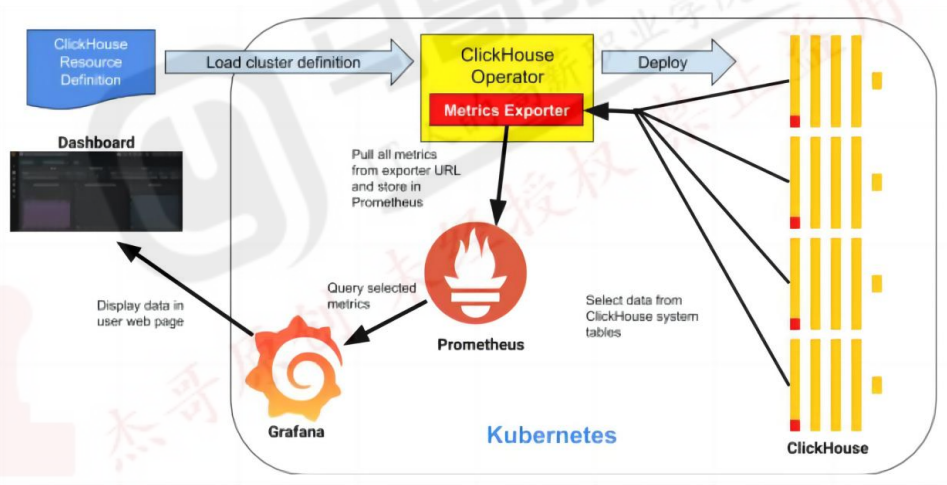
#上面的clickhouse的pod配置了promethues自动发现 [root@master01 charts]#cd clickhouse/ [root@master01 clickhouse]#vim values.yaml #metrics指标可以暴露出来,让promethues进行抓取 metrics: enabled: true #这里改成true,打开功能 podAnnotations: prometheus.io/scrape: "true" #允许promethues服务发现,直接发现pod进行指标采集 prometheus.io/port: "{{ .Values.containerPorts.metrics }}" #通过describe查看clickhouse的pod可以注解如下: Annotations: promethues.io/port: 8001 promethues.io/scrapt: true #允许抓取 可以测试下,如下: [root@master01 charts]# kubectl get pod -o wide NAME READY STATUS IP NODE myserver-clickhouse-shard0-0 1/1 Running 10.200.213.104 ... myserver-clickhouse-shard0-1 1/1 Running 10.200.241.100 ... myserver-clickhouse-shard0-2 1/1 Running 10.200.207.100 ... ... #返回要有指标才行 [root@master01 charts]#curl 10.200.213.104:8001/metrics #promethues发现这些pod指标并把他们收集起来
#部署好promethues root@k8s-master1:~/1.prometheus-case-files# vim case3-1-prometheus-cfg.yaml #专门用来发现pod的 - job_name: 'pods' kubernetes_sd_configs: - role: pod #不加namespace就发现所有namespace的pod #namespaces: #可选指定 namepace,如果不指定就是发现所有的 namespace中的 pod # names: # - myserver # - magedu # - defafult #需要符合下面的条件 relabel_configs: #需要pod里加上注解 - source_labels:[__meta_kubernetes_pod_annotation_prometheus_io_scrape] action: keep regex: true #协议要是https - source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) #得有端口,才能对指标抓取 - source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 #会对端口地址重新组合 - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_pod_name] action: replace target_label: kubernetes_pod_name root@k8s-master1:~/1.prometheus-case-files# kubectl apply -f case3-1-prometheus-cfg.yaml
在promethues网页能看到clickhouse的pod的状态
可以在 prometheus dashboard 验证指标
12.6.5:grafana 导入模板
导入模板 14192 名称写 ClickHouse-14192

 浙公网安备 33010602011771号
浙公网安备 33010602011771号