

爬虫1 爬虫介绍, requests模块, 代理(正向代理,反向代理), 爬梨视频, 自动登录网站, HTTP协议复习, 伪静态概念, 301和302状态码区别, http版本0.9 1.1 和2.0的区别
# 1 本质:模拟发送http请求(requests)----》解析返回数据(re,bs4,lxml,json)---》入库(redis,mysql,mongodb) # 2 app爬虫:本质一模一样 # 3 为什么python做爬虫最好:包多,爬虫框架:scrapy:性能很高的爬虫框架,爬虫界的django,大而全(爬虫相关的东西都集成了) # 4 百度,谷歌,就是个大爬虫 在百度搜索,其实是去百度的服务器的库搜的,百度一直开着爬虫,一刻不停的在互联网上爬取,把页面存储到自己库中 # 5 全文检索:全文检索 # 10 你公司里可以做项目,爬虫爬回来的(律师行业),搭一个搜索网站(app,小程序), # 11 医疗行业:造药企业,头孢类的 # 12 爬简历:简历库 #面试很重要:http协议(80%被问到) # 特点 (1)应用层协议(mysql,redis,mongodb:cs架构的软件:Navicat,python代码:pymysql,都是mysql客户端--socket:自己定制的协议----》服务端)(docker,es---》http(resful)---》服务端) (2)基于请求-响应模式: 客户端主动发起请求---》服务端才能响应 (服务端不能主动推送消息:轮询,长轮询,websocket协议:主动推送消息) (3)无状态保存(cookie,session,token:) (4)无连接:发送一次请求,响应完就断开,性能影响(http协议版本:0.9,1.1:多次请求,共用一个socket连接,2.0: 一次请求,可以携带多个http请求) # http请求:请求首行,请求头,请求体 -127.0.0.1/name=lqz&age=18:请求首行 -post请求请求体中放数据:name=lqz&age=18 放在请求体中 -post请求,可以这样发么:127.0.0.1/name=lqz&age=18,django数据requtes.GET,放在请求首行中,通过request.GET获取 # 注意:url发送时候,get是放请求首行(通过request.GET获得),不处理,post是直接放body里 -放在体中的:request.POST -请求体的格式(编码格式): urlencode:name=lqz&age=18 ---》request.POST json:{name:lqz,age:18} ---->request.POST取不出来(为什么?django框架没有做这个事) formdata:传文件,5g大文件, ----》request.POST # http响应: # 响应首行:状态码:1,2,3,4,5 301和302的区别 # 响应头:key:value:背几个响应头 -cookie: -cache-control:缓存控制 # 响应体: html,json # 浏览器调试 -右键--》调试模式 -elements:响应体,html格式 -console:调试窗口(js输出的内容,在这能看到) -network:发送的所有请求,all xhr:ajax请求
# 爬虫协议
- 哪部分允许你爬,哪部分不允许:robots.txt,爬数据的时候,一定要注意速度 可以通过在网址后根目录后添加robots.txt查看,如 https://www.baidu.com/robots.txt
301和302状态码区别
301适合永久重定向
301比较常用的场景是使用域名跳转。
比如,我们访问 http://www.baidu.com 会跳转到 https://www.baidu.com,发送请求之后,就会返回301状态码,然后返回一个location,提示新的地址,浏览器就会拿着这个新的地址去访问。
注意: 301请求是可以缓存的, 即通过看status code,可以发现后面写着from cache。
或者你把你的网页的名称从php修改为了html,这个过程中,也会发生永久重定向。
302用来做临时跳转
比如未登陆的用户访问用户中心重定向到登录页面。
访问404页面会重新定向到首页。
301重定向和302重定向的区别
302重定向只是暂时的重定向,搜索引擎会抓取新的内容而保留旧的地址,因为服务器返回302,所以,搜索搜索引擎认为新的网址是暂时的。
而301重定向是永久的重定向,搜索引擎在抓取新的内容的同时也将旧的网址替换为了重定向之后的网址。
# 1 模块:可以模拟发送http请求,urlib2:内置库,不太好用,繁琐,封装出requests模块,应用非常广泛(公司,人) # 2 pip3 install requests # 3 小插曲:requests作者,众筹换电脑(性能跟不上了),捐钱(谷歌公司捐了),2 万 8 千美元,买了游戏设备,爆料出来,骗捐,辟谣
# 1 request模块基本使用 import requests # # 发送http请求 # # get,delete,post。。本质都是调用request函数 # ret=requests.get('https://www.cnblogs.com') # print(ret.status_code) # 响应状态码 # print(ret.text) # 响应体,转成了字符串 # print(ret.content) # 响应体,二进制 # ret=requests.post()\ # ret=requests.request("get",) # ret=requests.delete() # 2 get 请求带参数 # 方式一 # ret = requests.get('http://127.0.0.1:8000/?name=lqz', # headers={ # # 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36', # 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36' # }) # print(ret.text) # 方式2(建议用方式二)中文会自动转码 # ret=requests.get('http://0.0.0.0:8001/',params={'name':"美女",'age':18}) # print(ret.text) #服务器端 def index(request): print(request.GET) # 获取关键字参数 return HttpResponse('ok') # 3 带headers # ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3', # headers={ # # 标志,什么东西发出的请求,浏览器信息,django框架,从哪取?(meta) # 'User-Agent': 'request', # # 上一个页面的地址,图片防盗链 # 'Referer': 'xxx' # 网页不刷新的情况下,可以看出 # }) # print(ret) # 图片防盗链:如果图片的referer不是我自己的网站,就直接禁止掉 # <img src="https://www.lgstatic.com/lg-community-fed/community/modules/common/img/avatar_default_7225407.png"> #服务器端 def index(request): print(request.GET) print(request.META) # 包含了所有本次HTTP请求的Header信息 return HttpResponse('ok') # 4 带cookie,随机字符串(用户信息:也代表session),不管后台用的token认证,还是session认证 # 一旦登陆了,带着cookie发送请求,表示登陆了(下单,12306买票,评论) # 第一种方式 # ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3', # headers={ # 'cookie': 'key3=value;key2=value', # }) # 第二种方式 # ret = requests.get('http://0.0.0.0:8001/?name=%E7%BE%8E%E5%A5%B3', # cookies={"islogin":"xxx"}) # django优化 # print(ret) #服务器端 def index(request): print(request.COOKIES) # 获取cookie return HttpResponse('ok') # 5 发送post请求(注册,登陆),携带数据(body) #data=None, json=None # data:urlencoded编码 # ret=requests.post('http://0.0.0.0:8001/',data={'name':"lqz",'age':18}) # json:json编码 # import json # data=json.dumps({'name':"lqz",'age':18}) # ret=requests.post('http://0.0.0.0:8001/',json=data) # print(ret) # 注意:编码格式是请求头中带的,所有我可以手动修改,在headers中改 #服务器端 def index(request): print(request.POST) # 获取post请求提交的数据 print(request.body) # 获得body数据 return HttpResponse('ok') # 6 session对象(了解) # session=requests.session() # # 跟requests.get/post用起来完全一样,但是它处理了cookie # # 假设是一个登陆,并且成功 # session.post() # # 再向该网站发请求,就是登陆状态,不需要手动携带cookie # session.get("地址") # 7 响应对象 # print(respone.text) # 响应体转成str # print(respone.content) # 响应体二进制(图片,视频) # # print(respone.status_code) # 响应状态码 # print(respone.headers) # 响应头 # print(respone.cookies) # 服务端返回的cookie # print(respone.cookies.get_dict()) # 转成字典 # print(respone.cookies.items()) # # print(respone.url) # 当次请求的地址(了解) # print(respone.history) # 如果有重定向,放到一个列表中(了解) # ret=requests.post('http://0.0.0.0:8001/') # ret=requests.get('http://0.0.0.0:8001/admin') # #不要误解,只针对当前ret一个对象 # ret=requests.get('http://0.0.0.0:8001/user') # print(ret.history) # print(respone.encoding) # 编码方式 #response.iter_content() # 视频,图片迭代取值 # with open("a.mp4",'wb') as f: # for line in response.iter_content(): # f.write(line) # 8 乱码问题 # 加载回来的页面,打印出来,乱码(我们用的是utf8编码),如果网站用gbk, # ret.encoding='gbk' # ret=requests.get('http://0.0.0.0:8001/user') # # ret.apparent_encoding当前页面的编码 # ret.encoding=ret.apparent_encoding # 9 解析json # 返回数据,有可能是json格式,有可能是html格式 # ret=requests.get('http://0.0.0.0:8001/') # print(type(ret.text)) # print(ret.text) # # a=ret.json() # 转为json格式 # print(a['name']) # print(type(a)) # 10 使用代理 # 正向代理 # django如何拿到客户端ip地址 META.get("REMOTE_ADDR") request.META.get('REMOTE_ADDR') # 如何去获取代理,如何使用(用自己项目验收) # 使用代理有什么用 # ret=requests.get('http://0.0.0.0:8001/',proxies={'http':'地址'}) # print(type(ret.text)) # print(ret.text) # 11 异常处理 # 用try except捕获一下 就用它就型了:Exception # 12 上传文件(爬虫用的比较少,后台写服务,) # file={'myfile':open("1.txt",'rb')} # ret=requests.post('http://0.0.0.0:8001/',files=file) # print(ret.content) #服务器端 def index(request): with open('x.txt','wb') as f: for line in request.FILES.get('myfile'): f.write(line) return JsonResponse({'name':'lqz','age':18})
# 13 request设置请求超时时间
request.get('https:www.baidu.com',timeout=3) # 如果超过3秒未得到响应就报错
# 认证,处理ssl(不讲了)
## 代理 # 网上会有免费代理,不稳定 # 使用代理有什么用? # drf:1分钟只能访问6次,限制ip # 每次发请求都使用不同代理,random一下 # 代理池:列表,其实就是代理池的一种 import requests # ret=requests.get('https://www.cnblogs.com/',proxies={'http':'222.85.28.130:40505'}) #高匿:服务端,根本不知道我是谁 #普通:服务端是能够知道我的ip的 # http请求头中:X-Forwarded-For:代理的过程 # ret=requests.get('http://101.133.225.166:8080',proxies={'http':'222.85.28.130:40505'}) # ret=requests.get('http://101.133.225.166:8080',proxies={'http':'114.99.54.65:8118'}) # print(ret.text)
# 代理 import requests ret = requests.get('https://www.cnblogs.com/',proxies={'http':'115.159.154.79:1080'}) # ret = requests.get('https://www.cnblogs.com/') print(ret.text)
正向代理
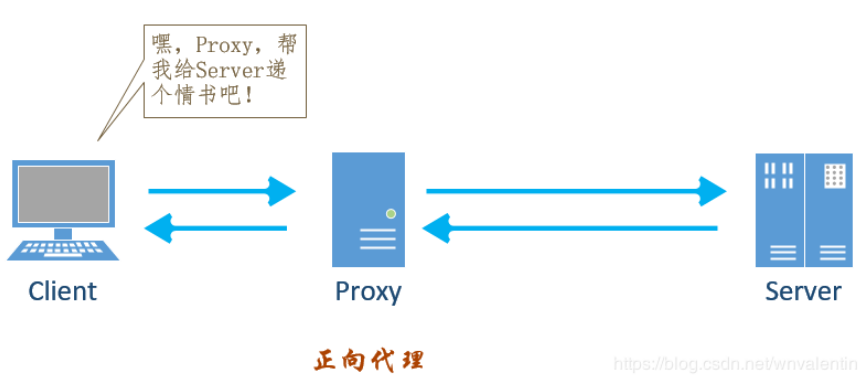
反向代理

正向代理,反向代理

可以参考:https://www.cnblogs.com/liuqingzheng/p/10521675.html
例如淘宝试用微服务架构内部各个框架试用不同接口,通信数据交换。反向代理

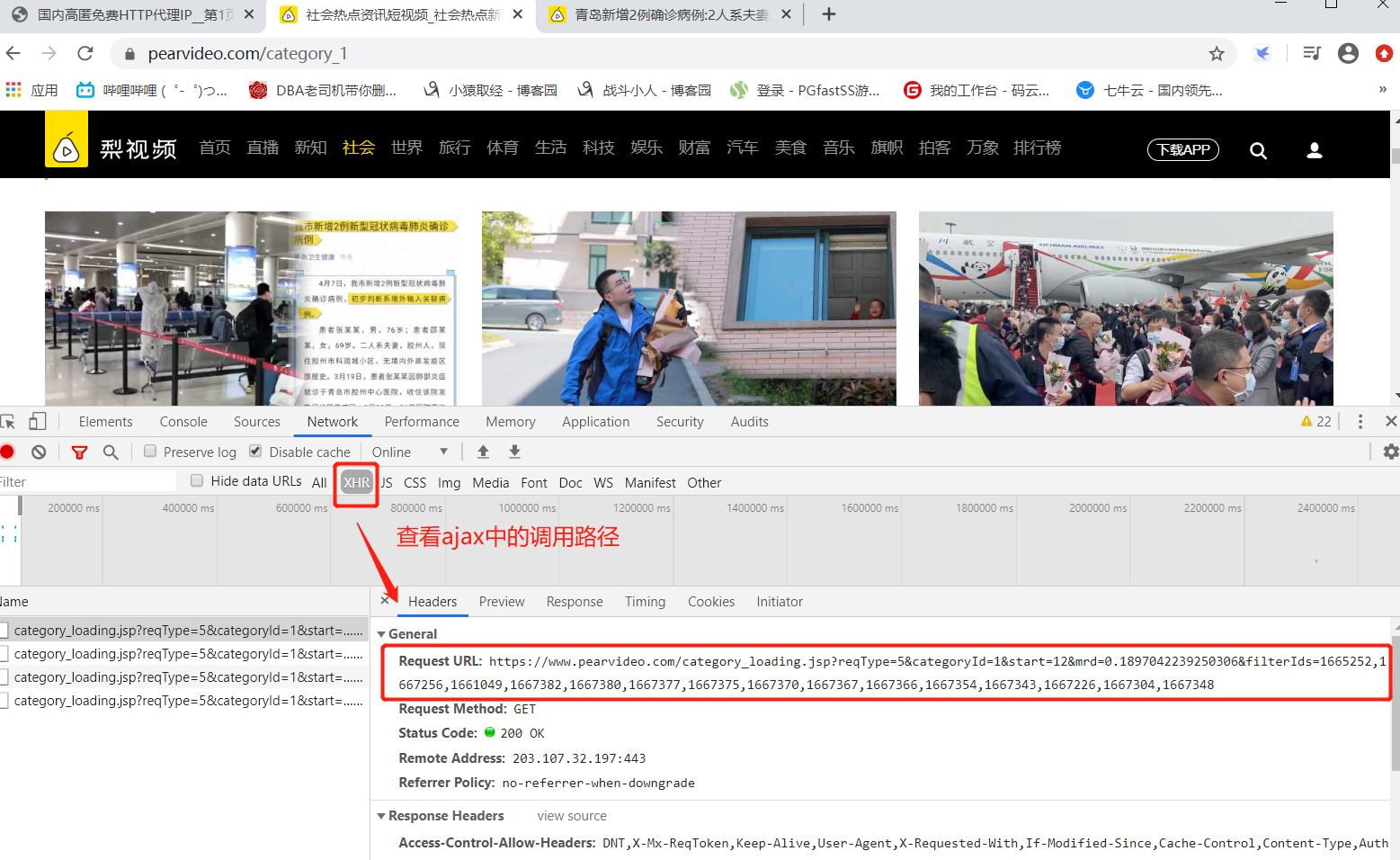
############ # 2 爬取视频 ############# # 先查看ajax的调用路径 https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0 #categoryId=9 分类id #start=0 从哪个位置开始,每次加载12个 # https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0 import requests import re ret=requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=9&start=0') # print(ret.text) # 正则取解析 reg='<a href="(.*?)" class="vervideo-lilink actplay">' video_urls=re.findall(reg,ret.text) print(video_urls) for url in video_urls: ret_detail=requests.get('https://www.pearvideo.com/'+url) # 相当于文件句柄,建立连接,流的方式,不是一次性取出 reg='srcUrl="(.*?)",vdoUrl=srcUrl' mp4_url=re.findall(reg,ret_detail.text)[0] #type:str # 下载视频 video_content=requests.get(mp4_url) video_name=mp4_url.rsplit('/',1)[-1] with open(video_name,'wb') as f: for line in video_content.iter_content(): f.write(line)
改进(用线程池爬取)
from concurrent.futures import ThreadPoolExecutor,wait,ALL_COMPLETED import requests import re import time start = time.time() pool = ThreadPoolExecutor(10) ret = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start=0') # print(ret.text) # 正则解析 reg = '<a href="(.*?)" class="vervideo-lilink actplay">' video_urls=re.findall(reg,ret.text) # print(video_urls) def download(url): ret_detail = requests.get('https://www.pearvideo.com/' + url) # 相当于文件句柄,建立连接,流的方式,不是一次性取出 # print(ret_detail.text) # 正则去解析 reg = 'srcUrl="(.*?)",vdoUrl=sr' # 正则表达式匹配式 mp4_url = re.findall(reg, ret_detail.text)[0] # type:str # 下载视频 video_content = requests.get(mp4_url) video_name = mp4_url.rsplit('/', 1)[-1] with open(video_name, 'wb')as f: for line in video_content.iter_content(): f.write(line) threads=[] for url in video_urls: t = pool.submit(download(url),url) threads.append(t) wait(threads, return_when=ALL_COMPLETED) # 等待线程池全部完成 end = time.time() print('time:',end-start) # 计算时间
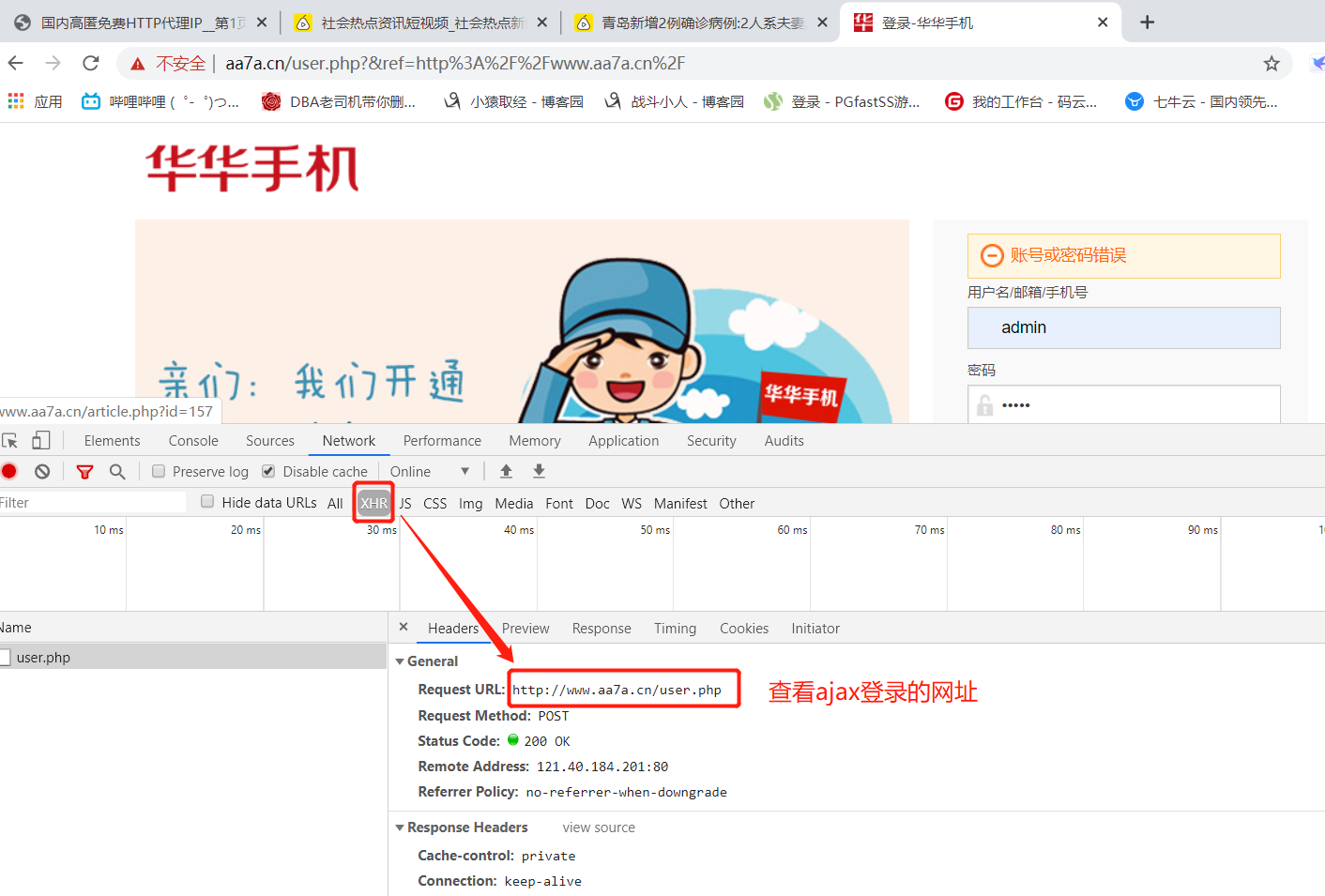
############ # 3 模拟登陆某网站 ############# import requests ret = requests.post('http://www.aa7a.cn/user.php', # 通过浏览器查看ajax记录确定登录地址 data={ # 登录信息 'username': '616564099@qq.com', 'password': 'lqz123', 'captcha': 'f5jn', 'remember': '1', 'ref': 'http://www.aa7a.cn/', 'act': 'act_login', }) cookie=ret.cookies.get_dict() print(cookie) # 如果不出意外,咱么就登陆上了,再向首页发请求,首页返回的数据中就有616564099@qq.com ret1=requests.get('http://www.aa7a.cn/',cookies=cookie) # ret1=requests.get('http://www.aa7a.cn/') print('616564099@qq.com' in ret1.text) # 如果登录成功,用户名就会在页面中 # 秒杀小米手机,一堆小号 # 定时任务:一到时间,就可以发送post请求,秒杀手机 # 以后碰到特别难登陆的网站,代码登陆不进去怎么办? # 之所以要登陆,就是为了拿到cookie,下次发请求(如果程序拿不到cookie,自动登陆不进去) # 就手动登陆进去,然后用程序发请求
总结:
# 1 爬虫基本原理:发送http请求(requests)----》拿到数据(html,json)(re,bs4)---》入库(文件,excel,mysql,redis,mongodb) # 2 爬虫协议:哪部分允许你爬,哪部分不允许:robots.txt,爬数据的时候,一定要注意速度 可以通过在网址后根目录后添加robots.txt查看,如 https://www.baidu.com/robots.txt # 3 http回顾,应用层协议,请求协议和响应协议 # 4 requests模块:基于urlib封装的 # 5 基本使用 requests.get/post----》本质都是调用requests.request 函数 # 6 get请求携带参数(两种方式) # 7 发送请求携带header(ua,referer,。。。。) # 8 携带cookie 两种方式(放到头中,cookies={}) # 9 发送post请求,携带数据(data,json) # 10 响应对象属性和方法 response对象 # 11 返回数据是json格式,json()--》直接转成字典 # 12 代理 ,普通,高匿,使用代理的方式,自己搭一个简单的代理池(列表) # 13 超时,异常 # 14 上传文件
伪静态
静态网页就是,比如知乎网站上放了一个abc.html文件,你想访问它就直接输入zhihu. com/abc.html。Web服务器看到这样的地址就直接找到这个文件输出给客户端。
动态网页就是,假如你想做一个显示当前时间的页面,那么就可以写个PHP文件,然后访问zhihu. com/abc.php。Web服务器看到这样的地址,找到abc.php这个文件,会交给PHP执行后返回给客户端。而动态网页往往要输入参数,所以地址就变成zhihu. com/abc.php?a=1&b=2。
搜索引擎比较烦这种带问号的动态网页,因为参数可以随便加,而返回内容却不变,所以会对这种网页降权。
于是有了mod_rewrite,它可以重新映射地址。比如当前这个页面的地址htt p://www.zhihu. com/question/20153311,Web服务器收到请求后会重新映射为www.zhihu. com/question.php?n=20153311,然后再执行那个PHP程序。(以上网址均为假设)这样,在内部不改变的情况下,对外呈现出来的网址变成了没有问号的象静态网页的网址一样。
于是有人给起了个名字叫“伪静态”。其实也没什么伪的,就是没有问号的静态网址,让搜索引擎舒服点而已。
http 0.9 1.1 和2.0的区别
参考: https://www.cnblogs.com/wupeixuan/p/8642100.html
0.9 一个http请求就是一个socket链接
2.0 多路复用,同一个数据包可以有多个请求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号