

算法与数据结构(四) 图的物理存储结构与深搜、广搜(Swift版)
开门见山,本篇博客就介绍图相关的东西。图其实就是树结构的升级版。上篇博客我们聊了树的一种,在后边的博客中我们还会介绍其他类型的树,比如红黑树,B树等等,以及这些树结构的应用。本篇博客我们就讲图的存储结构以及图的搜索,这两者算是图结构的基础。下篇博客会在此基础上聊一下最小生成树的Prim算法以及克鲁斯卡尔算法,然后在聊聊图的最短路径、拓扑排序、关键路径等等。废话少说开始今天的内容。
一、概述
在博客开头,我们先聊一下什么是图。在此我不想在这儿论述图的定义,当然那些是枯燥无味的。图在我们生活中无处不在呢,各种地图,比如铁路网,公路网等等这都是典型的图形结构。来点直观的,我们就以北京的地铁为例。如果你在北京坐过地铁,那么对下方的这张图并不陌生。下方就是一个典型的图形结构,而且还是连通图呢。也就是说,你从任意一个地铁站进去,就可以在其他相连的地铁站出来。
下方每个地铁站就是图的结点,地铁站与地铁站之间的连线就是图的弧,如果我们给弧添加上距离,那么这个距离就是这个弧所对应的权值。比如我们举个例子,假如大望路站到国贸站的距离是1.5公里。那么我们翻译成我们图中的术语就是大望路结点到国贸结点有一条弧,这条弧的权值是1.5公里。当然,从大望路到国贸有多条路径,那么那条路径最近呢,这就是我们后面要说的最优路径了。我们如果想连通每个站点,并且想连接每个站点的权值的和最小,那么就是我们以后要聊的最小生成树了。
今天我们博客的主题就是如果去存储下方这种类型的图,然后对图中的节点进行遍历。当然存储的时候我们要存储弧度所对应的权值。
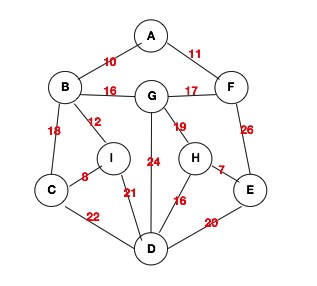
当然,上面这个地铁站的地铁是比较复杂的,我们就简单画一个图,来模拟一下上述图的结构即可。然后将该结构进行存储。然后再基于该存储结构对图进行遍历。图的物理存储结构可以分为邻接矩阵和邻接链表的形式。则图的搜索分为广度优先搜索(BSF -- Breadth First Search)和深度优先搜索(DFS -- Depth First Search)。下面这个图的结构就是我们要存储以及遍历的图。红色的部分就是每条边的权值。
二、邻接矩阵
接下来我们就将上面这个图存储下来,当然是使用我们上面提到过的邻接矩阵或者邻接链表来存储。在构建图之前呢,我们依然要先定义图的协议,因为图的物理存储结构分为邻接矩阵和邻接链表。不同的存储方式也就对应着构建图的方式不同,那么图的BFS与DFS的具体实现也是不同的,但是对外的接口是一致的。还是那句话,面向接口编程。所以我们要先定义完图的相关接口,然后在给出具体实现。
1.图的接口的定义
下方代码片段就是我们图结构的协议,所有定义的图结构都要遵循下方的协议。createGraph()方法会根据传入的参数构建相应存储结构的图,breadthFirstSearch()方法对应的就是图的广度优先搜索,depthFirstSearch()对应的就是图的深度优先搜索,displayGraph()就负责将图的整个存储结构进行输出。
还是那句话,因为图对外的调用接口是一致的,所以我们对于不同的物理存储结构的图,我们可以使用同一个测试用例。定义好了下方的协议后,我们就可以根据图的物理存储结构,给出具体实现了。
2、图中关系的输入
要想构建上面的图的结构,我们得根据图所提供的信息来构建相应物理结构的图。下方就是我们在构建图结构时,所输入的信息。allGraphNote数组中存储的是图中的所有结点,就类似于某个地铁站的名字。而relation数组中存储的就是结点之间的信息。其中一个元组就是一个结点间的关系。(A, B, 10)就说明A到B有条弧,该弧的权值是10,类似于大望路到国贸有条地铁,距离是1.5一样。我们就可以根据下方的这个信息来构建我们想构建的图了。
当然下方信息在邻接矩阵和邻接链表中的存储方式是不同的,下方会详细介绍。 而上面我们提到的createGraph()方法中的两个参数,就是下方这两个数组。

3.邻接矩阵的构建
邻接矩阵是存储图结构的一种物理存储方式,其实说白了邻接矩阵就是一个二维数组,这个二维数组中存储的是图中节点的关系。下方这个截图就是上述图结构的邻接矩阵的存储方式。节点与节点中间如果没有弧的话,那么权值就是0。如果两个节点间有关系的话,那么其中存储的就是该弧上的权值,具体如下所示。
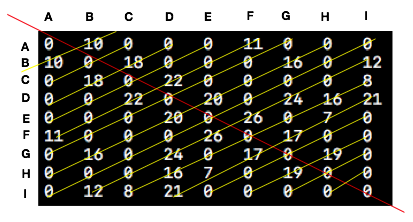
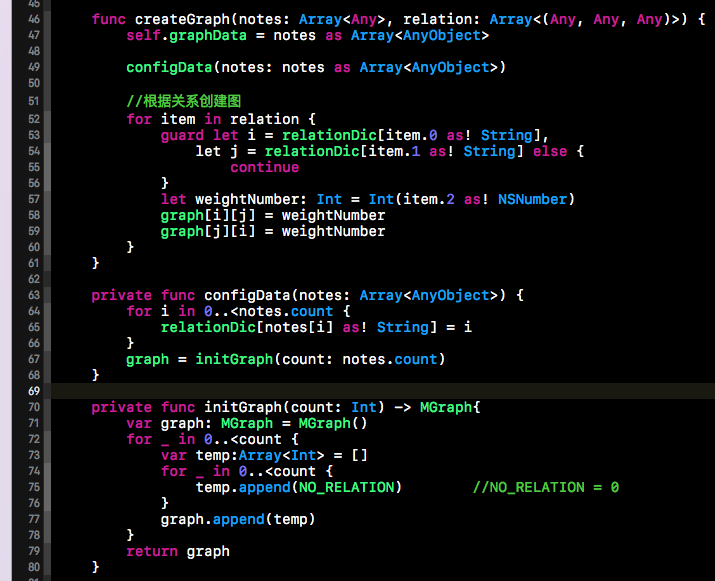
根据上面这个结构,我们就开始我们的代码实现了,下方就是我们创建邻接矩阵相应的代码。createGraph()方法的第一个参数是我们上面提到过的allGraphNote,也就是图中所有的结点集合。第二个参数则是上面我们提到过的relation,其中存储的就是图中结点间的关系。下方的initGraph()方法负责存储图的邻接矩阵的初始化,而relationDic中存储的就是图的结点与邻接矩阵下标的对应关系。通过下方这三个函数,我们就可以构建出上面图结构所对应的邻接矩阵了。
上面这个矩阵其实就是下方这段代码构建的图结构的输出结果。通过输出结果可以看出,上面的邻接矩阵以红线为中心轴对称。因为A到B的的权值为10,那么B到A的权值也是10,所以会形成上述对称结构。这个在我们对图的遍历时需要注意一下该对称结构。
4.邻接矩阵的广度优先搜索(BFS)
上面创建完邻接矩阵后,我们就开始对此邻接矩阵进行操作了。接下来要干的事情就是对上面的邻接矩阵进行广度优先搜索(Breadth Frist Search)。在之前二叉树的层次遍历中我们提到过,二叉树的层次遍历与图的广度优先搜索就是一个东西。接下来我们仔细的聊聊。图的广度优先搜索要借助我们之前聊的队列。该队列中记录的就是上次遍历那一层节点,下次遍历结点的顺序就按照队列中记录的节点的顺序来。下方就是广度搜索的示意图。
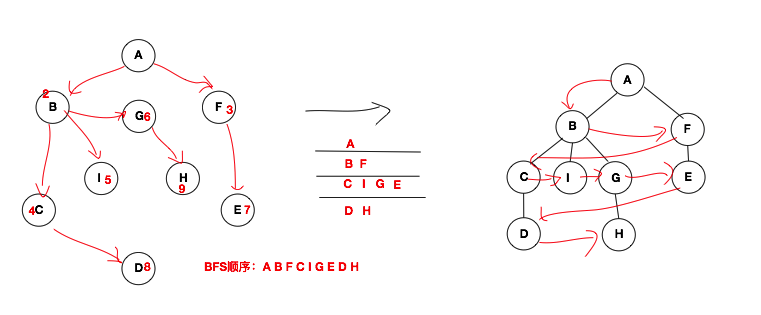
上面BFS示意图中,是以A为首结点来进行的广度优先搜索。广度优先搜索的思想是借助队列“一层一层的输出”。在遍历一个点后,那么就将与该结点相连并未遍历的点加入队列,下次输出的点从队列中获取,然后再输出,不断的重复这个过程。从描述中我们可以看出,此过程可以使用递归来解决。下方代码段就是邻接矩阵的广度优先搜索的代码,如下所示:
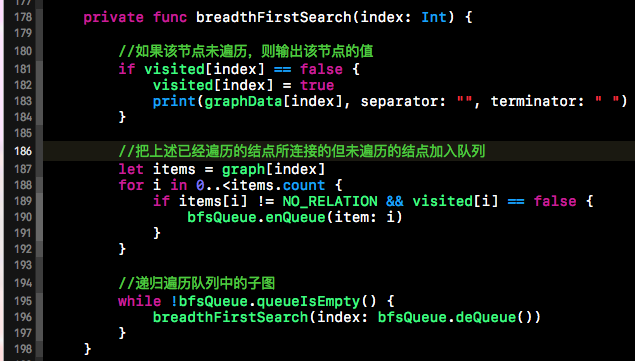
上面的代码并不复杂,上面用到的visited数组用来标记当前遍历的结点是否已经被遍历过,因为上述的矩阵是对称的。代码比较简单,在此就不做过多赘述了。主要还是借助队列来保证层级关系。
5.邻接矩阵的深度优先搜索(Depth First Search)
接下来我们来聊深度优先搜索--DFS。一句话总结DFS,其实就是“一条道走到黑,走不通,退一步再找道”。其实深度优先搜索与之前我们聊的二叉树的先序遍历非常类似。在实现DFS时,如果不使用递归来实现的话,我们可以借助栈的操作来实现。因为递归本来就是一个栈结构,所以直接可以使用递归来完成DFS。下方就是DFS的示意图,下方的示意图看明白了,用代码去实现也就不是什么难事了。
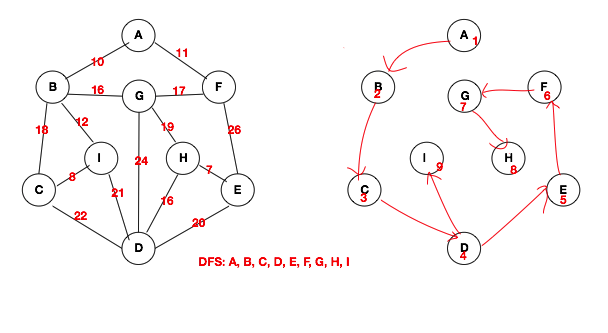
下方这个递归函数就是邻接矩阵的DFS的实现,同样会用到visited来标记结点是否被遍历过。

6.测试用例
下方这段代码就是我们的测试用例,该测试用例函数的参数的类型是GraphType, 也就是我们之前定义的协议。只要是遵循该协议的类的对象都可以作为该函数的参数,所以我们下方这个测试用例是通用的。这也是面向接口编程的好处之一。
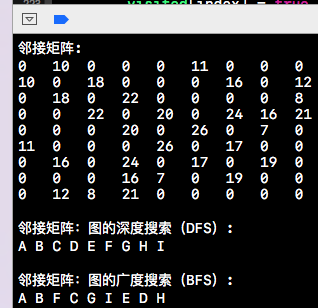
下方是上述代码的测试用例所输出的结果,如下所示。当然该测试用例也同样适用于邻接链表实现的图,前提是要遵循我们之前定义的协议。
三、邻接链表
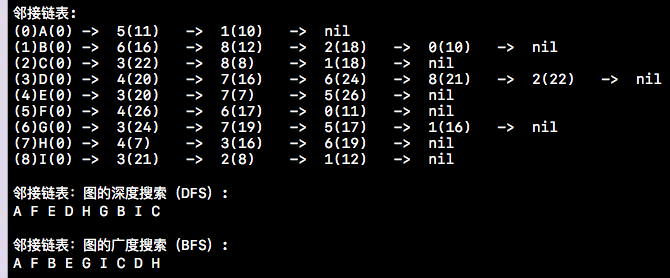
上面介绍完邻接矩阵及其相关内容后,我们还要聊一下另一种图的存储结构----邻接链表。邻接链表就是数组与链表的结合体,也就是将链表挂在一维数组中。开门见山,下方就是邻接链表测试用例所输出的结果。前面的下标其实就是一个一维数组,每个下标后方所跟的链就是挂在该下标后方的链。链中每个节点所存储的内容是与该数组下标所连接的结点的下标以及权值。下方这个邻接链表存储的就是上面我们那个图。
虽然下方的DFS和BFS与上述邻接矩阵中的DFS和BFS不同,但是规则是按照我们之前聊的规则来的。
1.邻接链表的创建
上面也说了,邻接链表就是将一个个的链表挂在一维数组中。在创建邻接链表之前,我们得先创建邻接链表中链表所需的结点。下方这个就是我们邻接链表中所需要的结点。data存储的是所连结点在一维数组中的index,weightNumber存储的就是权值,preNoteIndex存储的就是当前结点所在链表连接的一维数组的index。next则指向链表中的下一个结点。

创建好我们需要的头结点后,我们就该创建我们的邻接链表了。下方代码段的createGraph()方法所需的参数与邻接矩阵对应的方法所需的参数一致。下方函数中第一个循环是初始化一维数组,将每个结点的信息添加到一维数组中,等待着与这些结点相连的结点挂在相应的链上。relationDic中记录着结点与一维数组索引的对应信息。第二个循环是遍历relation数组,取出每个结点间的关系信息,根据这些信息将相应的结点挂在相应的一维数组每个元素对应的链上。

2、邻接链表的广度优先搜索(BFS)
邻接链表的广度优先搜索与邻接矩阵的广度优先搜索虽然算法一致,但是由于其存储数据的方式不同,具体实现起来还是有所不同的。因为是BFS, 所以,邻接链表的BFS依然会借助队列来实现。下方我们采用了队列加递归的方式来实现的BFS。
方法中最外层的if语句块用来判断当前方法传入的索引所对应的结点是否已经被遍历了,如果未被遍历则输出,输出后将标志位置为true。遍历完当前结点后,将与该结点相连接的并且未被遍历的结点进入队列。然后再递归遍历队列中未被遍历的结点。具体代码如下所示:

3、邻接链表的深度优先搜索(DFS)
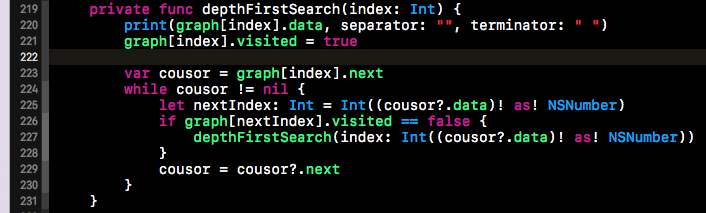
下方这段代码就是邻接链表的深度优先搜索,下方代码段没有借用队列,但是使用了递归。因为在递归调用函数的过程中,存在递归调用栈。栈有着先入后出的特点,上面我们在聊DFS时聊到,深度优先搜索就是一直往下走,走不动了就回退一步继续寻找可以往下走的路。这个一直往下走其实就是不断push入栈的过程,而回退一步其实就是pop出栈的步骤。鉴于递归过程本身就是一个栈的结构,所以就不需要我们再创建一个栈来实现这个push和pop操作了。下方就是邻接链表的DFS的相关代码。代码并不复杂,在此不做过多赘述了。
至此,图的邻接矩阵和邻接链表的DFS、BFS就聊完了。当然本篇博客往上贴的代码只是部分核心代码,完整的Demo已在github上进行分享。下方就是分享链接,下篇博客会聊一下图的最小生成树的两个算法。今天博客就先到这儿。
Github分享地址:https://github.com/lizelu/DataStruct-Swift/tree/master/Graph
作者:青玉伏案
出处:http://www.cnblogs.com/ludashi/
本文版权归作者和共博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果文中有什么错误,欢迎指出。以免更多的人被误导。
收简历:坐标美团(北京总部),长期招聘FE/iOS/Android靠谱工程师,入职后,可内部联系楼主,有小礼品赠送,有意者可邮箱投递简历:zeluli@foxmail.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号