使用Presto加速Hive分区表查询:释放$partitions的强大能力
问题:
presto查询的Hive表,发现 :增量表的查询时间区间取的是数仓表的分区dt,取最大和最小dt的时候,Trino会全表扫描hive表,无效计算而且特别慢。
- 全量表的话,每天的分区里都是分区当天及以前的数据;查询默认限定在最新的分区。
- 增量表的话每天的分区只有分区当天的数据;查询要根据时间范围限定分区。
从Presto监控可以明显看出 当前SQL所占用分区数:290个,大小2.32MB。

遇到流量等大增量表,就会特别耗时,建议修改生成SQL的逻辑,测试对比SQL如下
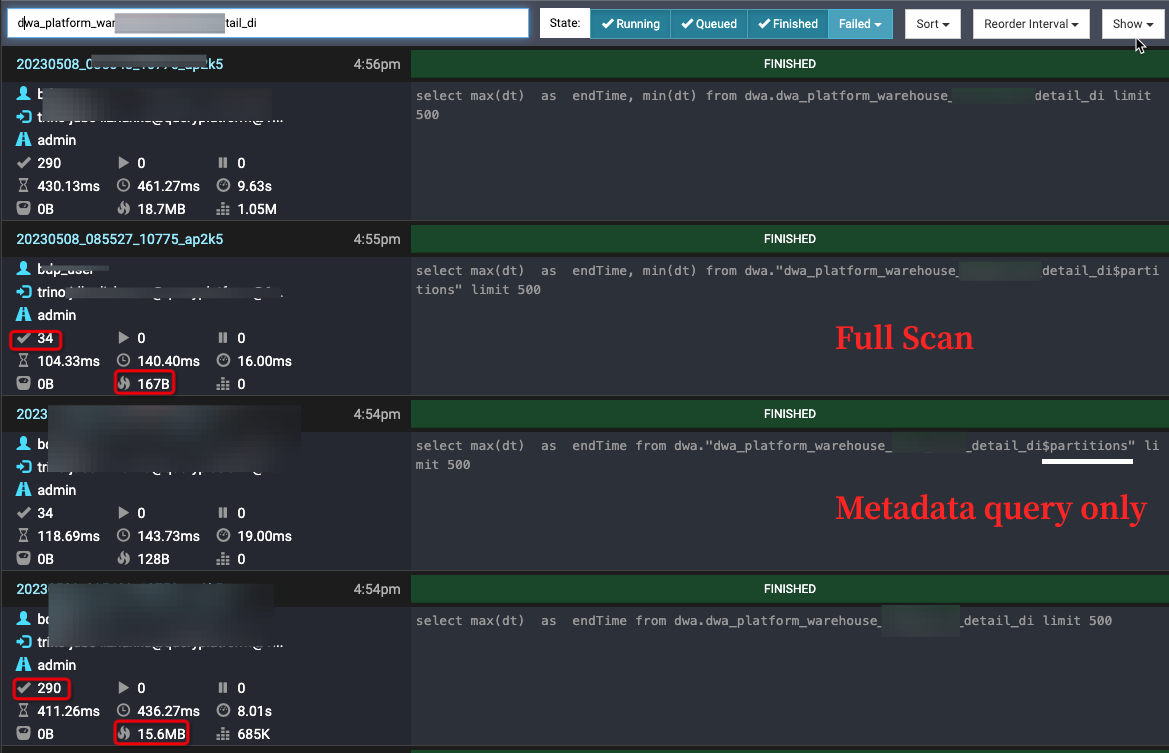
重点来啦,只需要在表名后添加$partitions即可。详情可看 Presto 0.280 Documentation, 另外也可查看https://github.com/trinodb/trino/issues/3014


翻译一下就是:
- 分区表现在有一个包含分区值的隐藏系统表,名为 example 的表将有一个名为 example$partitions 的分区表,这提供了与 SHOW PARTITIONS 相同的功能和数据。
- 通过 $partitions 表和使用 SHOW PARTITIONS 列出的分区名称不再受 hive.max-partitions-per-scan 配置选项定义的限制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号