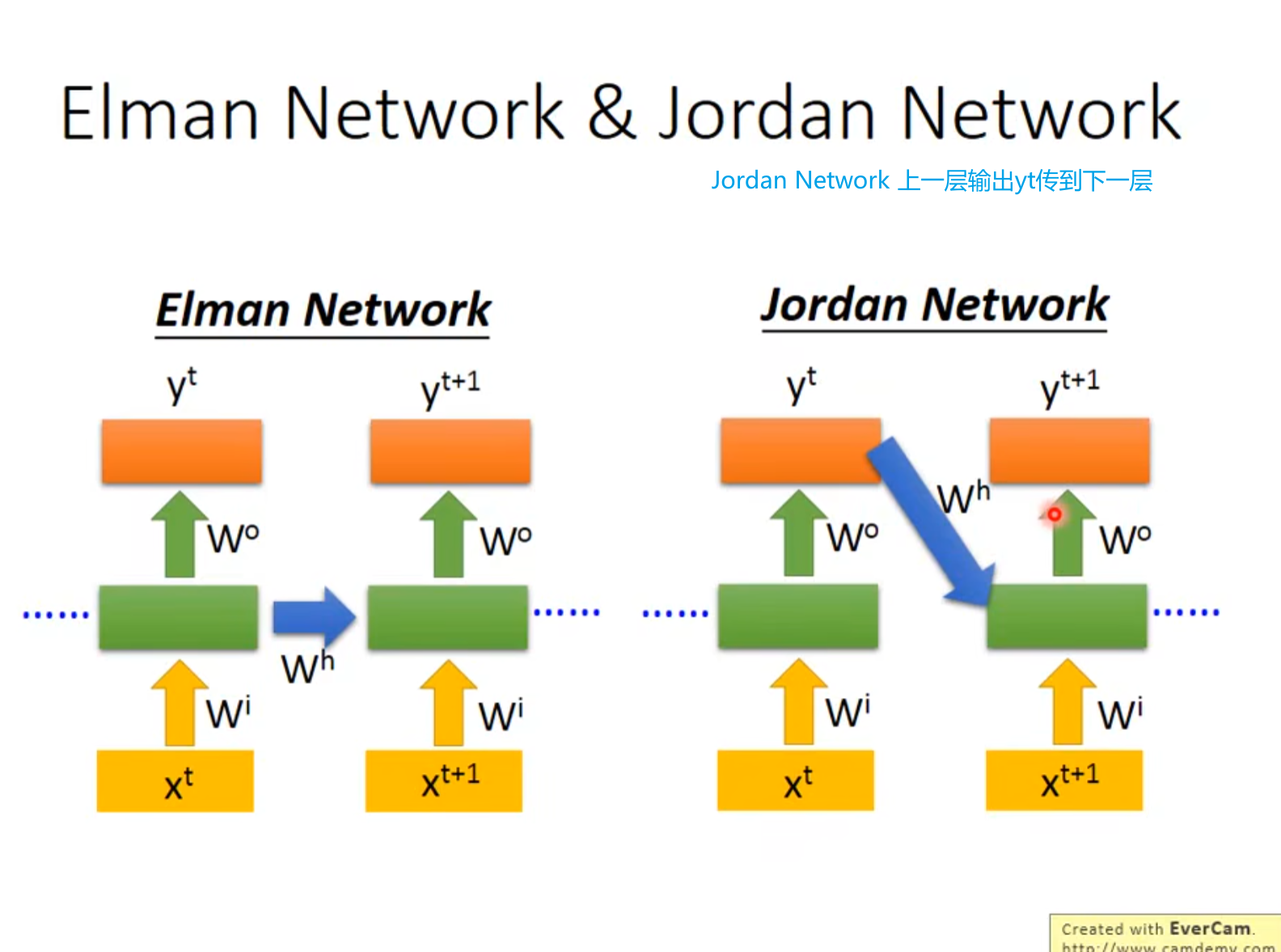
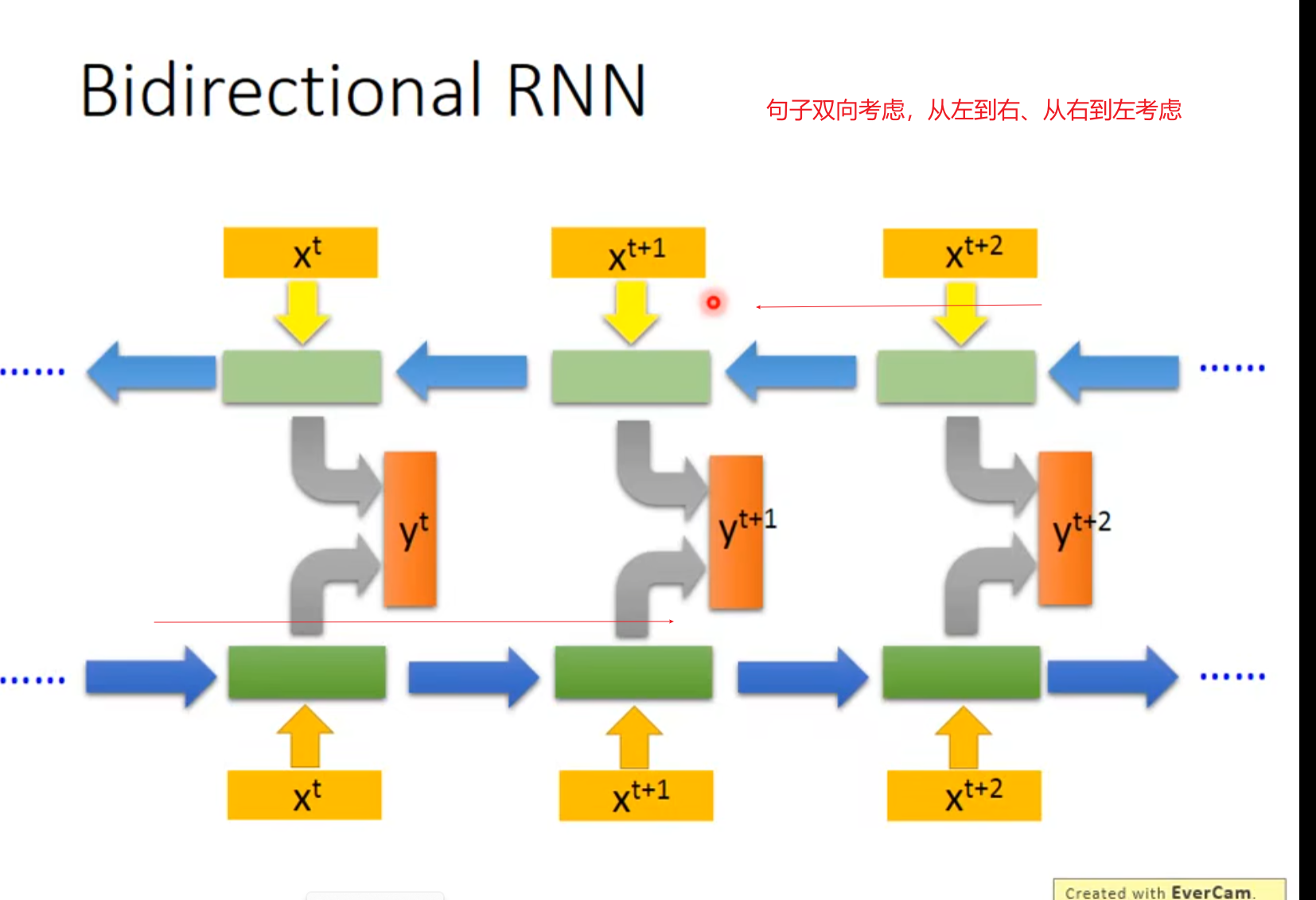
RNN
循环神经网络RNN
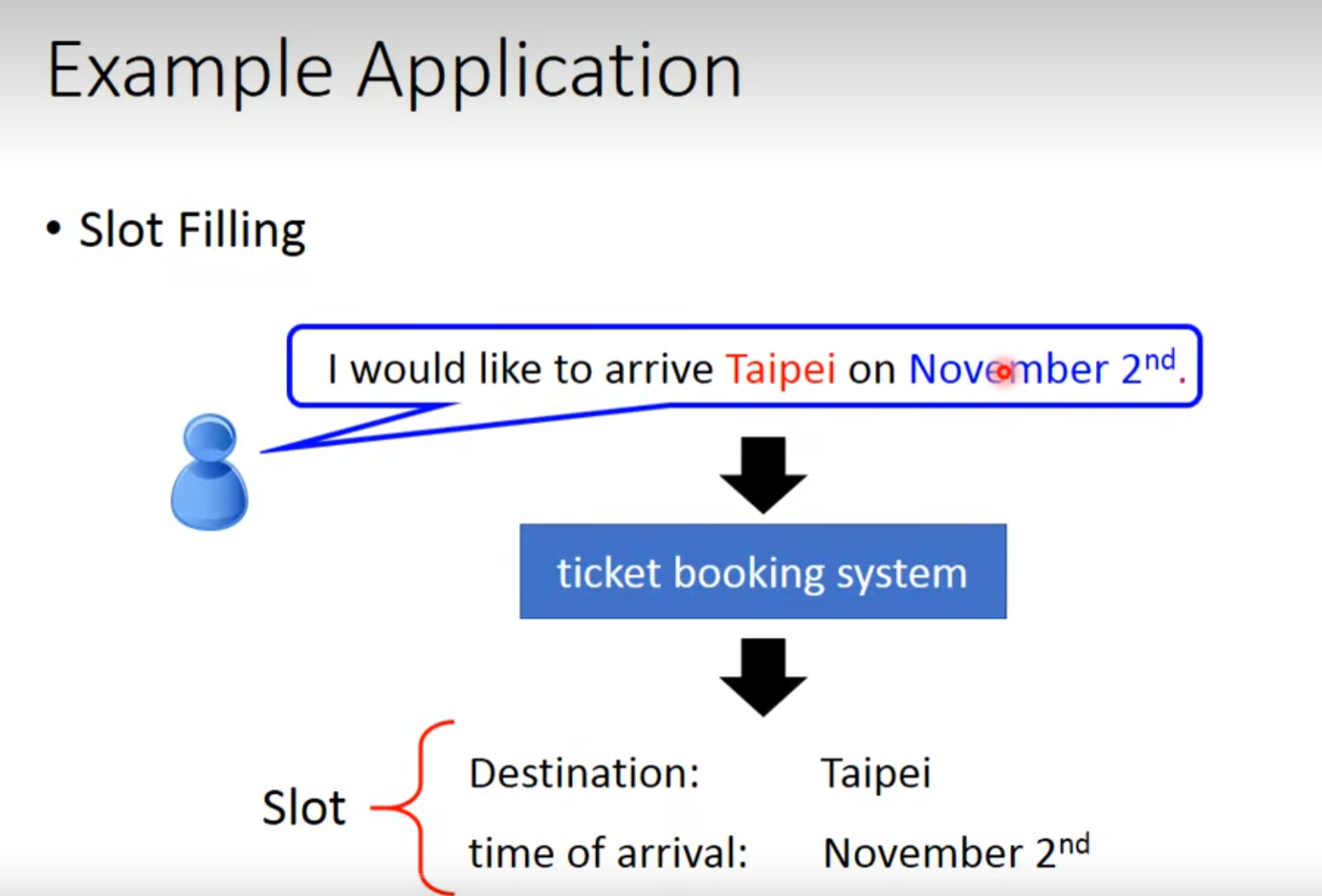
槽过滤
![image]()
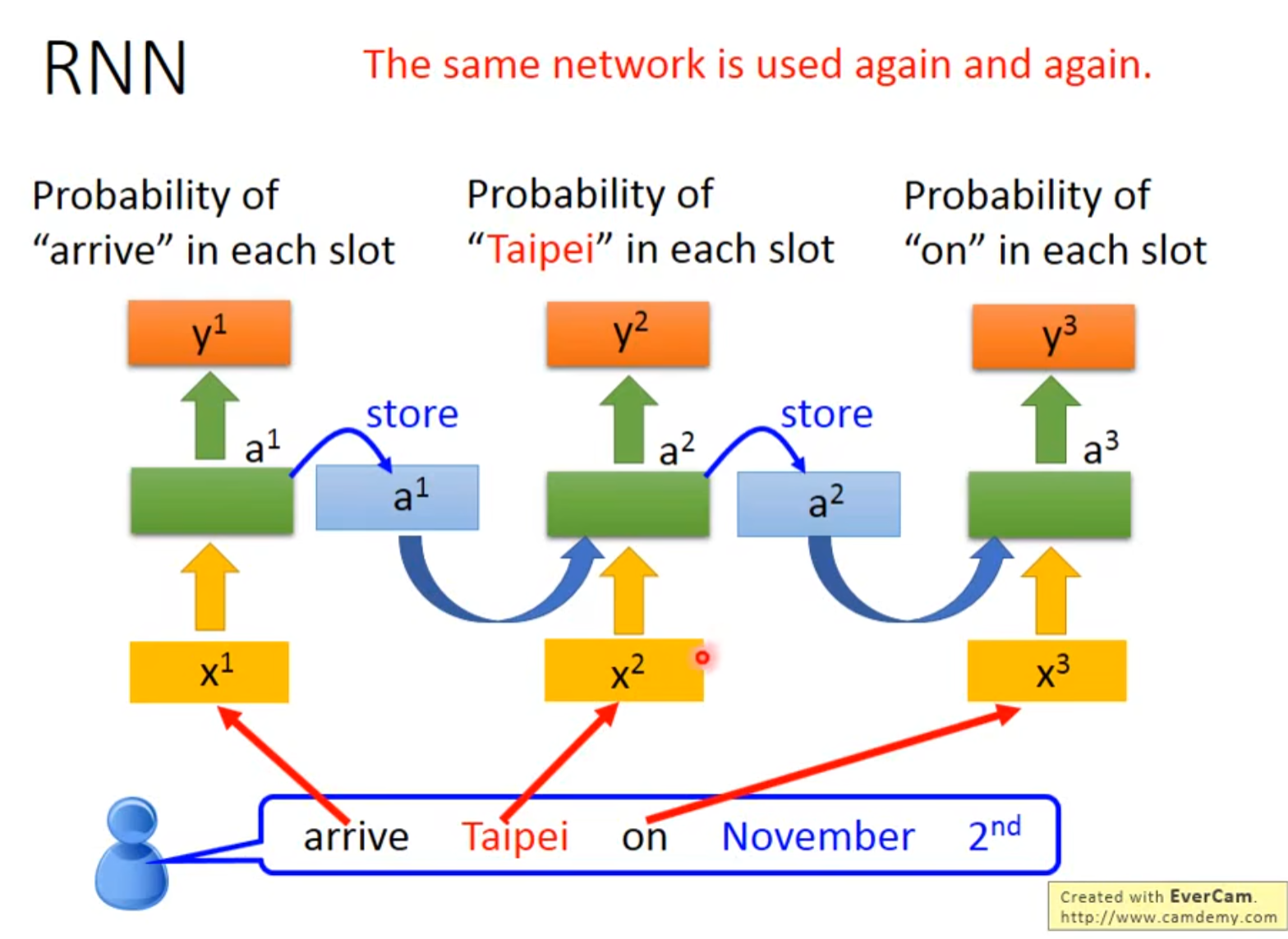
RNN有记忆的神经网络。
![image]()
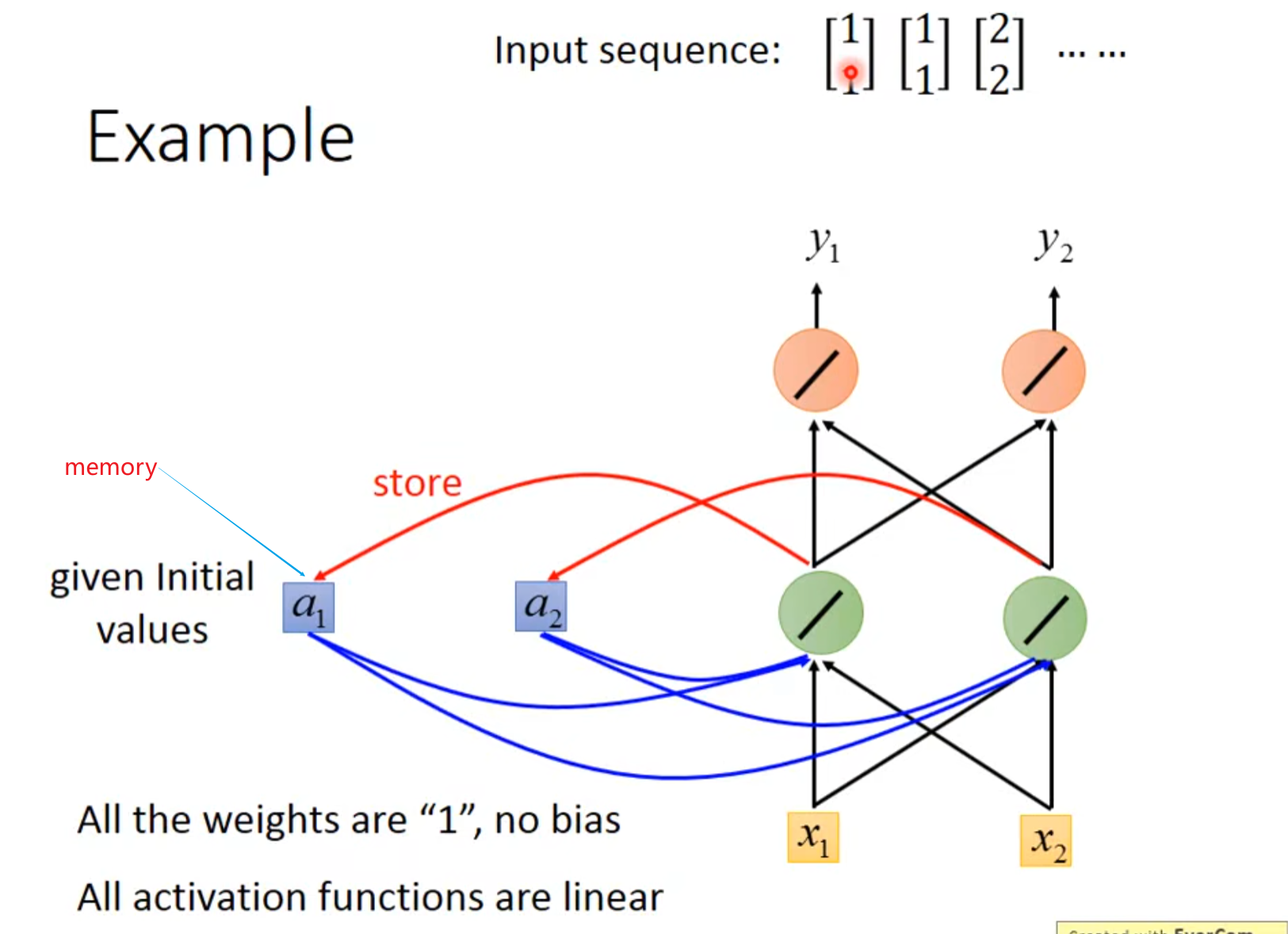
循环神经网络RNN会用内存记录中间值
![image]()
![image]()
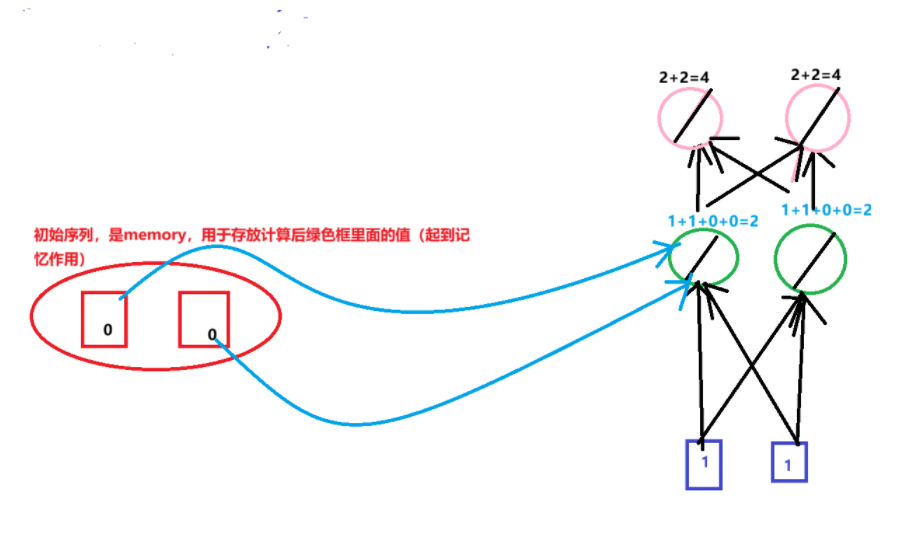
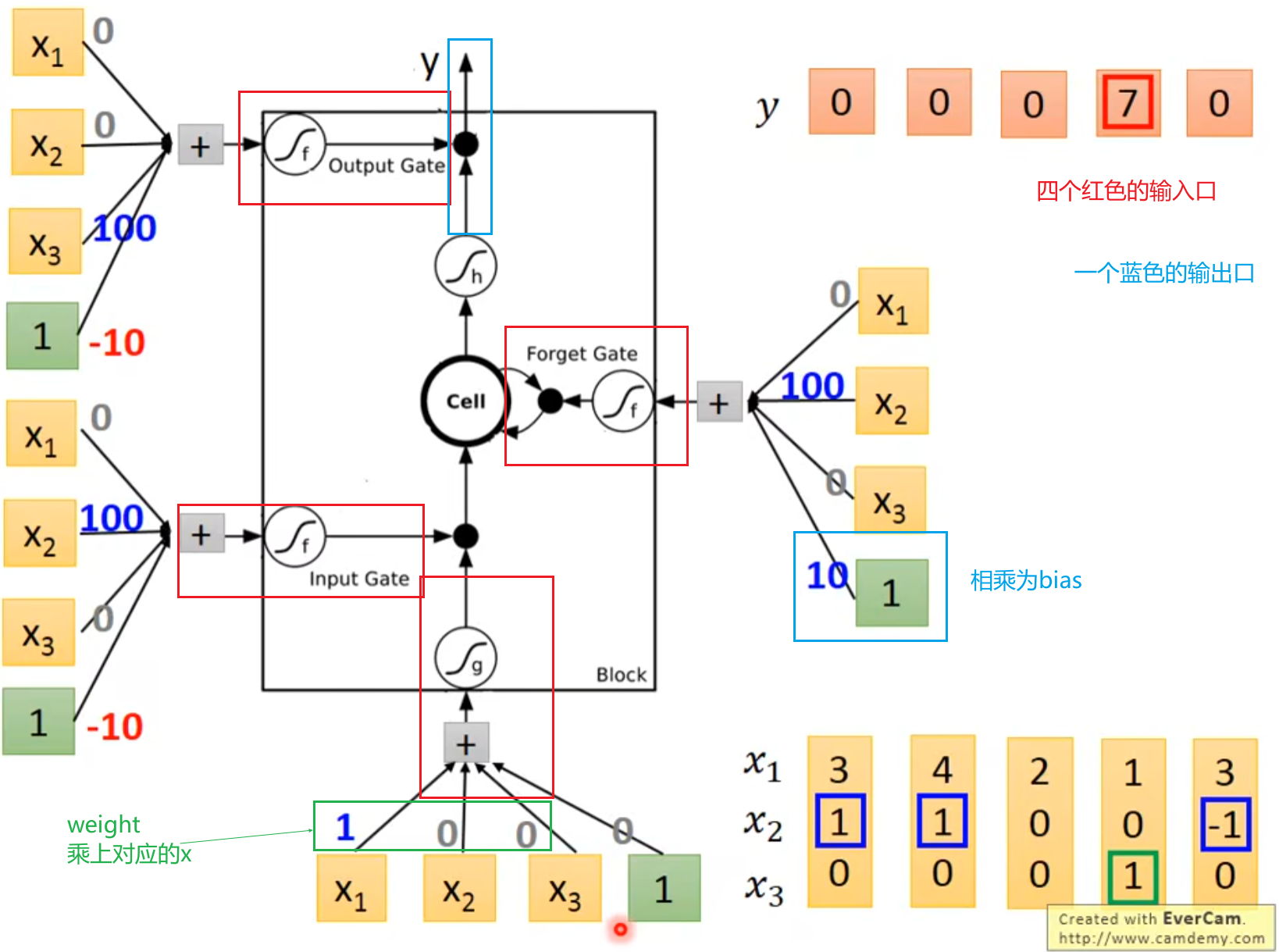
第一次输入1,1输出4,4
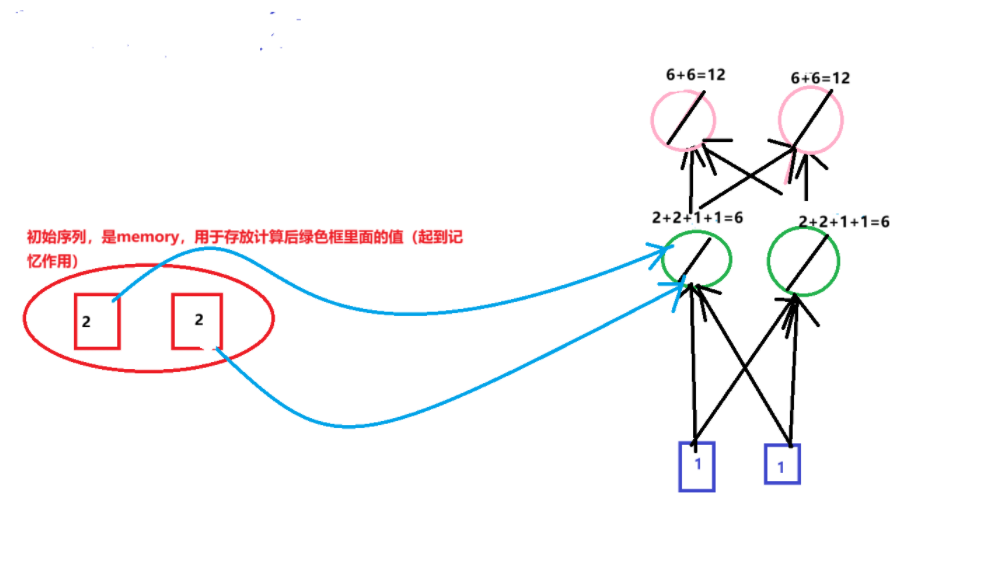
第二次将2,2存入memory,输入1,1;输出12,12
![image]()
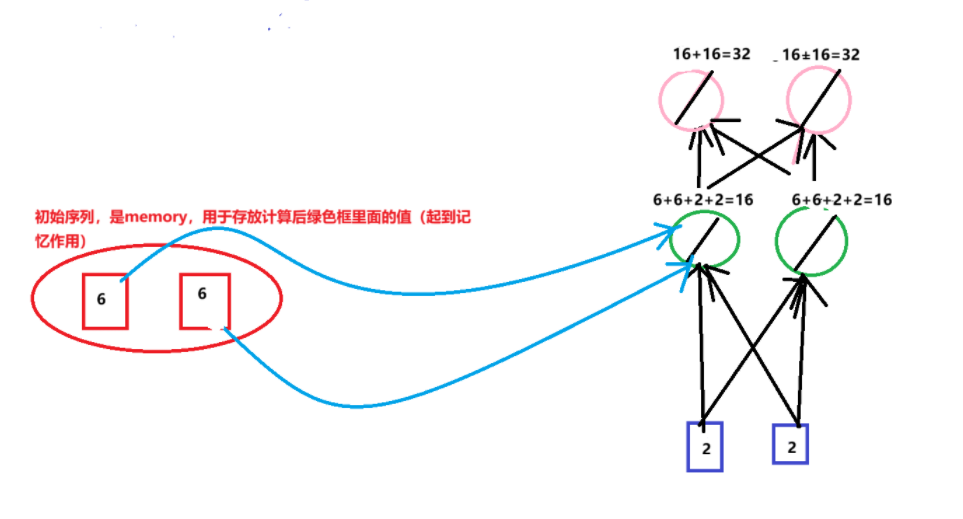
第三次输入2,2,上一轮结束暂存到内存的数字是6,6,输出32,32
![image]()
![image]()
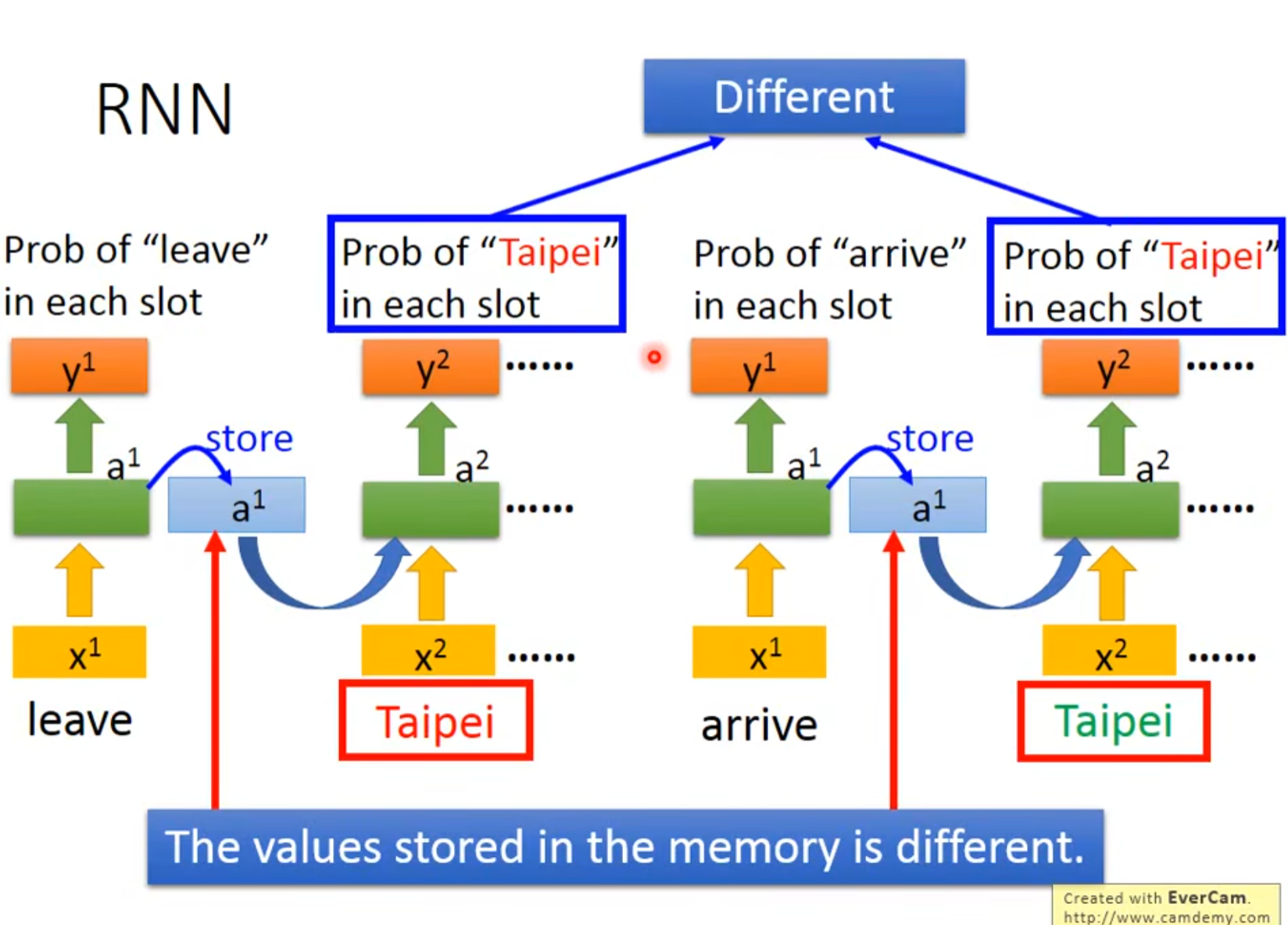
a是概率
![image]()
![image]()
![image]()
![image]()
![image]()
weight、bias是利用training data通过梯度下降计算而来。
![image]()
![image]()
综上:可以直接使用Keras
![image]()
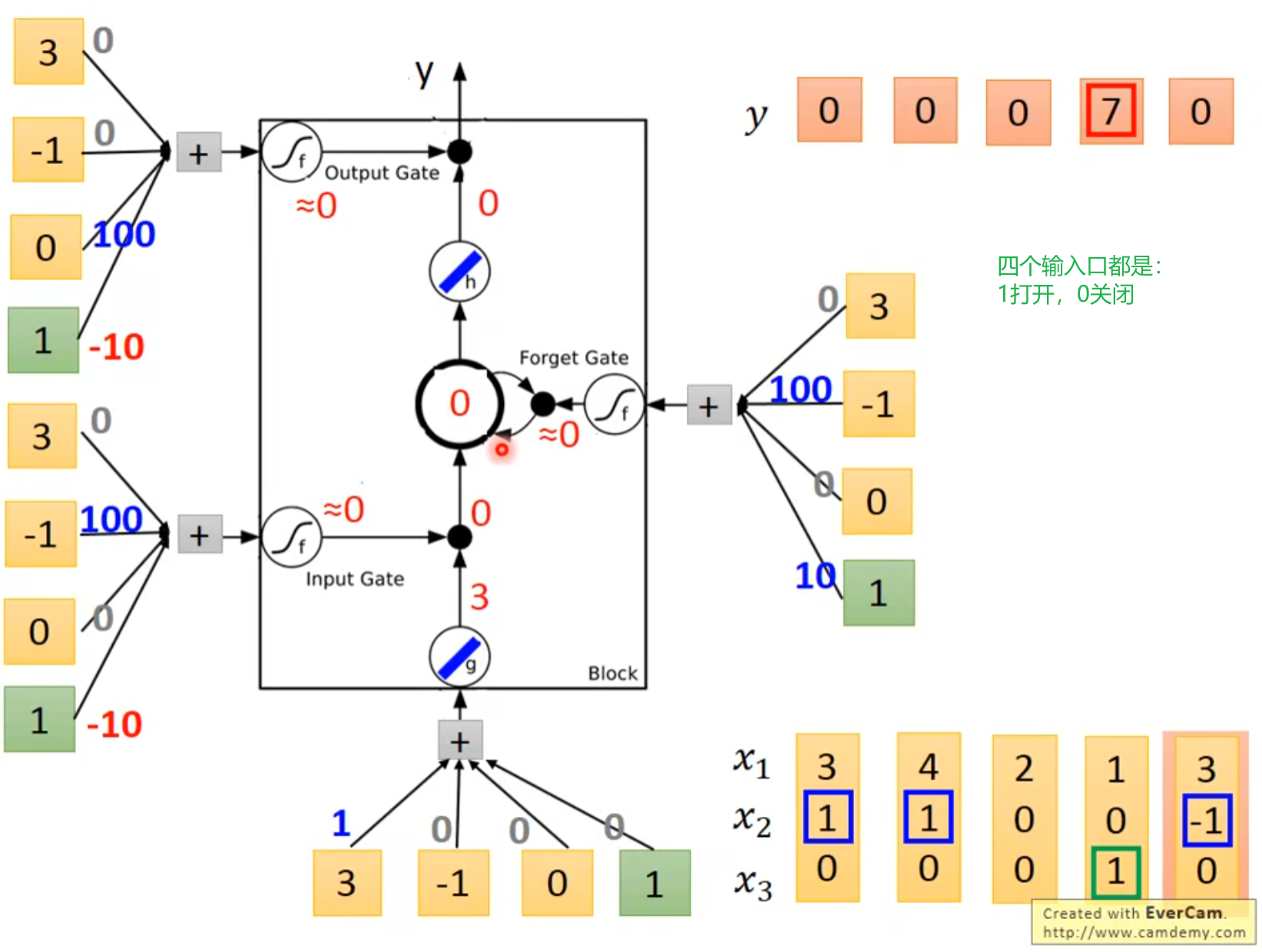
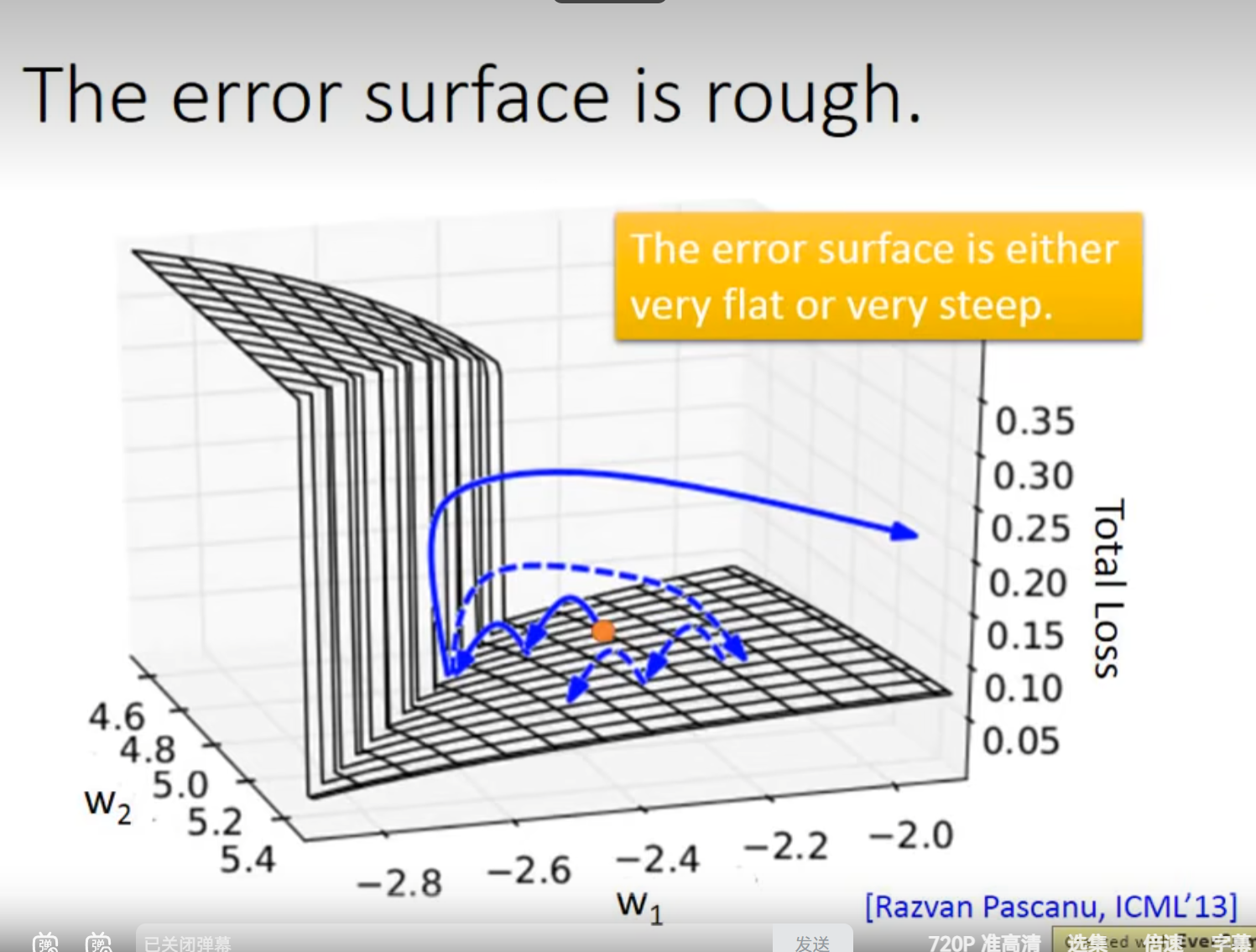
RNN梯度消失与梯度爆炸问题:
![image]()
揭示 RNN 在训练时因长期依赖下权重的微小变化引发输出剧烈波动,导致梯度消失或爆炸,进而使模型难以稳定学习。
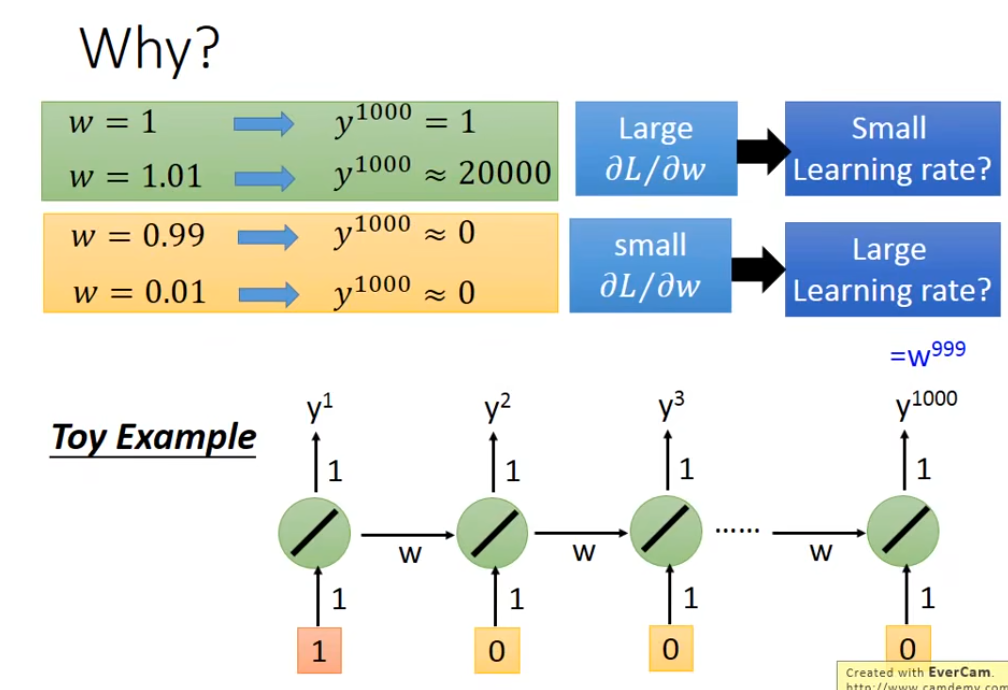
- 梯度爆炸场景:当权重w=1.01时,经过 1000 步(y1000)后输出约为 20000(指数级增长);而w=1时输出保持为 1。
- 梯度消失场景:当权重w=0.99或w=0.01时,经过 1000 步后输出几乎为 0(指数级衰减)。
- 若梯度∂L/∂w大(对应梯度爆炸风险),需配小学习率以避免参数更新幅度过大;
- 若梯度∂L/∂w小(对应梯度消失风险),需配大学习率以保证参数有效更新。
但 RNN 中梯度波动极端,难以用固定学习率同时适配两种情况,加剧了训练难度。
![image]()
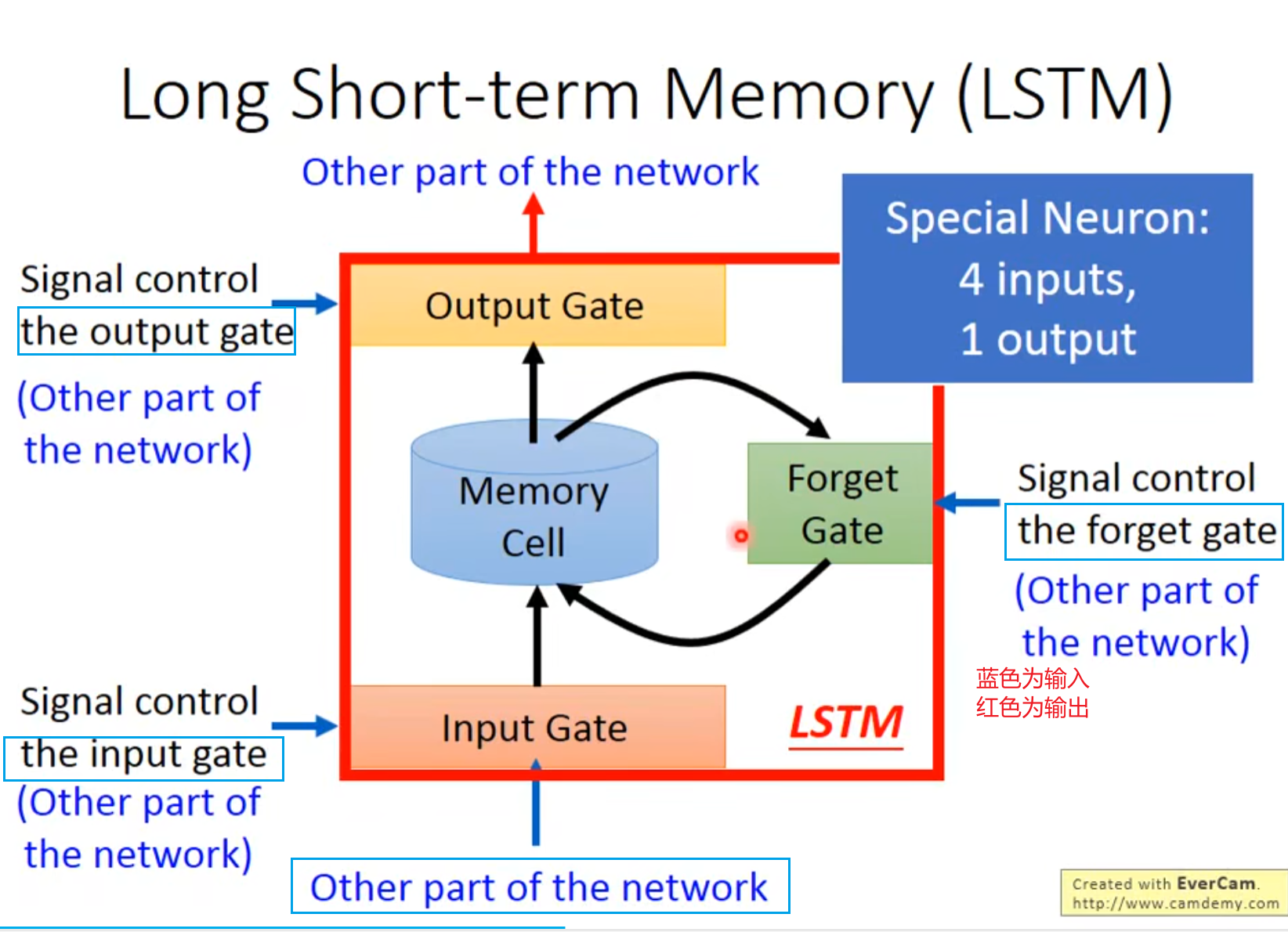
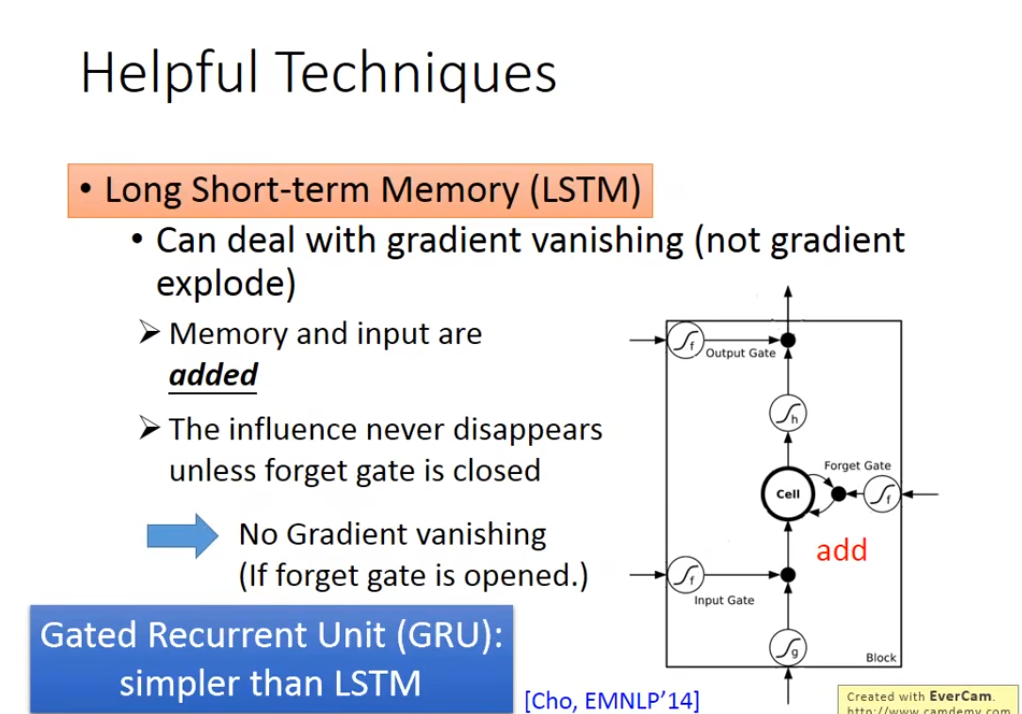
这是关于解决 RNN 梯度问题的两种循环神经网络变体技术的说明,分点解读如下:
- 核心作用:解决 RNN 的梯度消失问题(对梯度爆炸缓解有限)。
- 原理机制:
- 记忆与输入通过加法操作融合,信息不会无意义衰减,除非 “遗忘门” 关闭。
- 由输入门、遗忘门、输出门和记忆单元(Cell)组成,通过门控机制精准控制信息的存储与输出。
- 应用价值:使模型能捕捉长序列的长期依赖关系,适用于机器翻译、文本生成等长序列任务。
- 核心特点:结构比 LSTM 更简洁,是 LSTM 的简化变体。
- 原理机制:融合 LSTM 的部分门控(如输入门与遗忘门整合),在保证效果的同时降低计算复杂度。
- 来源:由 Cho 等人在 EMNLP 2014 会议提出,平衡了模型性能与计算效率。
二者均为解决 RNN 长序列训练中梯度缺陷的技术。LSTM 结构更复杂但对长期依赖捕捉更精细,GRU 以简洁结构实现近似效果,在资源受限场景(如移动端)或对效率要求高的任务中更具优势,而对长依赖要求极高的场景(如长文本理解)LSTM 表现更稳定。


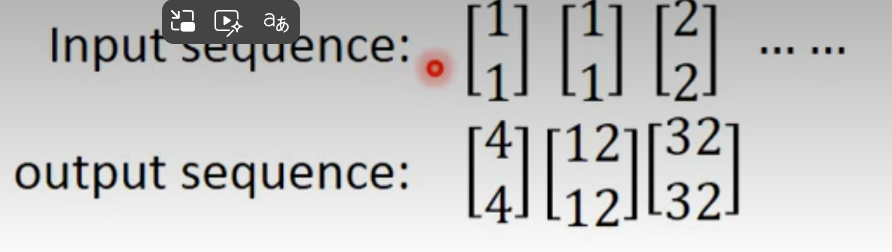


 浙公网安备 33010602011771号
浙公网安备 33010602011771号