

pytorch加载数据集
pytorch加载数据集
一、核心组件说明
二、加载内置数据集(以torchvision为例)
步骤:
例:加载torchvision下的数据集MNIST手写数字数据集(0-9)
import torch
from torch.utils.data import DataLoader
from torchvision import datasets,transforms#transforms预处理工具
transform=transforms.Compose(
[
transforms.ToTensor(),#转张量,归一化
#Normalize将经过ToTensor转换后的图像数据调整为 “均值接近 0、标准差接近 1” 的分布
transforms.Normalize((0.1307,), (0.3081,))#(0.1307,)均值, (0.3081,)标准差
]#预处理
)#流水线工作Compose多个工作合并
#定义训练数据集
train_data=datasets.MNIST(
root='./data',
download=True,#如果本地没有,就会自动将数据集下载到data目录下(data目录自动生成)
train=True,#训练集
transform=transform#预处理
)
#定义测试数据集
test_data=datasets.MNIST(
root='./data',
transform=transform,#加工
download=True,
train=False
)
#批量加载训练数据集
train_loader=DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,#训练打乱
num_workers=2
)
#批量加载测试数据集
test_loader=DataLoader(
dataset=test_data,
batch_size=64,
shuffle=False,#测试不打乱
num_workers=2#并行进程数
)
if __name__=='__main__':
#循环次数是批量数=总样本数(60000)/批量大小(64)
for batch_idx,(data,target) in enumerate(train_loader):#enumerate作用产生索引batch_idx
print(f'批量大小是{batch_idx}')
print(f'数据形状{data.shape}')
print(f'标签{target.shape}')三.自定义数据集
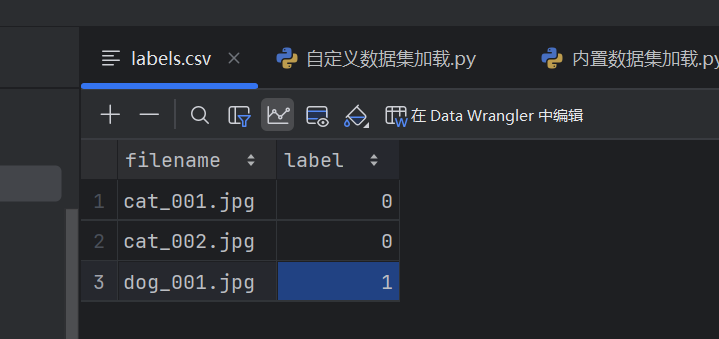
例:猫狗数据集
提前准备好猫狗图片以及csv文件记录图片名和标签

import torch
import os#系统路径
import pandas as pd
from PIL import Image #处理图片
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
# 1. 自定义Dataset类
class CustomImageDataset(Dataset):#这三个方法要写
def __init__(self, img_dir, label_file, transform=None):
self.img_dir = img_dir # 图片文件夹路径
self.labels = pd.read_csv(label_file) # 读取标签文件,labels实例属性
self.transform = transform # 预处理方法
def __len__(self):
# 返回数据集总样本数
return len(self.labels)
def __getitem__(self, idx):
# 根据索引idx返回单条数据和标签
img_name = self.labels.iloc[idx, 0] # 第idx行第0列:文件名
img_path = os.path.join(self.img_dir, img_name) # 图片完整路径
image = Image.open(img_path).convert('RGB') # 用PIL打开图像,并强制转为RGB三通道(避免灰度图通道不一致)
label = self.labels.iloc[idx, 1] # 第idx行第1列:标签
# 应用预处理(若有)
if self.transform:
image = self.transform(image)
return image, label # 返回(数据,标签)
# 2. 定义预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 缩放为224x224
transforms.ToTensor(), # 转为Tensor
#为什么均值、方差都是三维?因为转为rgb图像
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # ImageNet均值/标准差
])
# 3. 实例化自定义Dataset
custom_dataset = CustomImageDataset(
img_dir=r'F:\masterleaning\custom_data\images',
label_file=r'F:\masterleaning\custom_data\labels.csv',
transform=transform
)
# 4. 用DataLoader加载
custom_loader = DataLoader(
dataset=custom_dataset,
batch_size=32,
shuffle=True,
num_workers=2
)
if __name__=='__main__':
# 5. 迭代验证
for data, labels in custom_loader:
#批量大小batch_size=labels.shape因为一批多少样本就要打多少标签
print(f"数据形状: {data.shape}") # (32, 3, 224, 224)(batch_size, 通道, 高, 宽)
print(f"标签形状: {labels.shape}") # (32,)
break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号