

分布式缓存
分布式缓存
hdfs+mapreduce
本案例:
就是已知一个日志文件信息和每个城市对应的ip
现在需要利用mapreduce实现对日志文件进行信息提取得到每个城市名和他对应的总响应内容大小
所以ip2locale.txt放入缓存的目的是方便在map的时候取出来将ip换为城市名称
思路:
首先利用map方法对日志进行处理提取出
所以map函数的输入key为行偏移量,value为行文本
map函数的输出key为城市名称,value为日志对象
然后reduce函数是按照同一ip进行遍历对响应内容求和
reduce输入key为城市名称,value为日志对象
reduce输出key为城市名称,value为总响应内容大小
下面是完整代码:
(1)日志对象-->每一行是一个日志对象
package com.simple;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
/*
* 代表日志信息的对象
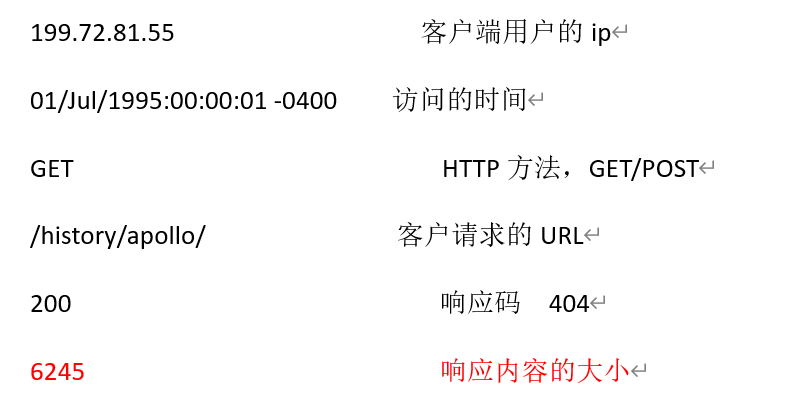
199.72.81.55 - - [01/Jul/1995:00:00:01 -0400] "GET /history/apollo/ HTTP/1.0" 200 6245
其中:
199.72.81.55 客户端用户的ip
01/Jul/1995:00:00:01 -0400 访问的时间
GET HTTP方法,GET/POST
/history/apollo/ 客户请求的URL
200 响应码 404
6245 响应内容的大小
*/
public class LogWritable implements WritableComparable<LogWritable> {
private Text userIP, timestamp, request;
private IntWritable responseSize;
public LogWritable() {//构造方法
this.userIP = new Text();
this.timestamp = new Text();
this.request = new Text();
this.responseSize = new IntWritable();
this.status = new IntWritable();
}
//设置所以属性值
public void set(String userIP, String timestamp, String request, int bytes, int status) {
this.userIP.set(userIP);
this.timestamp.set(timestamp);
this.request.set(request);
this.responseSize.set(bytes);
this.status.set(status);
}
//获取响应内容大小
public IntWritable getResponseSize() {
return responseSize;
}
}
(2)mapper类
要进行的操作有1.通过ip2locale.txt文件得到城市ip和城市名称对应关系的 HashMap,2.处理日志文件map函数
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class LogProcessorMap extends Mapper<LongWritable, Text, Text, LogWritable > {
LogWritable outValue = new LogWritable();
Text outKey = new Text();
URI[] localCachePath;
// 存储解析后的ip与城市名映射关系
HashMap<String,String> maps = new HashMap<String,String>();
//目的获得ip和城市名称对应关系
@Override
public void setup(Context context) throws IOException {
URI[] localCachePath = context.getCacheFiles();//先得拿到分布式缓存
//再利用hdfs取数据
FileSystem fs = FileSystem.get(localCachePath[0], context.getConfiguration());
FSDataInputStream hdfsInStream = fs.open(new Path(localCachePath[0].getPath()));
String line = "";
line = hdfsInStream.readLine();
while (line != null) {
String[] items = line.split(" ");
maps.put(items[0], items[1]);
line = hdfsInStream.readLine();
}
hdfsInStream.close();
}
//map函数实现提取每一行的城市ip并转为对应的城市名称,和城市内容
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String logEntryPattern = "^(\\S+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+\\-]\\d{4})\\] \"(.+?)\" (\\d{3}) (\\d+)";
Pattern p = Pattern.compile(logEntryPattern);
Matcher matcher = p.matcher(value.toString());
if (!matcher.matches()) {
System.err.println("Bad Record : "+value);
return;
}
String userIP = matcher.group(1);
String timestamp = matcher.group(4);
String request = matcher.group(5);
int status = Integer.parseInt(matcher.group(6));
int bytes = Integer.parseInt(matcher.group(7));
if(maps.get(userIP) != null) {
userIP = maps.get(userIP);
}
outKey.set(userIP);
outValue.set(userIP, timestamp, request, bytes,status);
context.write(outKey,outValue);
}
}
(3)reducer类实现每一个城市求和响应量(跟单词统计非常相似)
package com.simple;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class LogProcessorReduce extends Reducer<Text, LogWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<LogWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for (LogWritable val : values) {
sum += val.getResponseSize().get();
}
result.set(sum);
context.write(key, result);
}
}
(4)
主启动类
package com.simple;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class LogProcessorDriver extends Configured implements Tool {
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new LogProcessorDriver(), args);
System.exit(res);
}
@Override
public int run(String[] args) throws Exception {
String inputPath = "/hadoop/nasa/NASA_log_sample.txt";
String outputPath = "/hadoop/nasa/log-output";
Job job = Job.getInstance(getConf(), "log-analysis");
//这里体现分布式缓存
// 添加指定资源到分布式缓存
job.addCacheFile(new URI("hdfs://192.168.190.129:8020/data/nasa/ip2locale.txt"));
job.setJarByClass(LogProcessorDriver.class);
job.setMapperClass(LogProcessorMap.class);
job.setReducerClass(LogProcessorReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LogWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(inputPath));
FileOutputFormat.setOutputPath(job, new Path(outputPath));
int exitStatus = job.waitForCompletion(true) ? 0 : 1;
return exitStatus;
}
}
总结:利用分布式缓存,将城市ip和城市名称关系放入缓存可以加快map里的查询ip对应城市名称并替换的速度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号