
Linux
Linux介绍
对于初创型的小公司,用户量很少,网站并发数也很低,开发架构不能太复杂,选择网站的黄金架构LNMP(Linux+Nginx+Mysql+PHP/Perl/Python)
shell壳的作用
老王学习python,在cmd里面写入了一段代码 print("隔壁的小孩长得越来越像我...")
↓
交给python翻译官
解释成机器码
↓
机器认识这一段话的作用,开始执行,然后 输出给用户
用户在命令行敲下 ls cd mkdir 这些linux的命令,计算机也是不认识的
↓
shell(linux下的bash脚本语言的解释器,翻译官)
↓
翻译给机器,去执行
图形化软件界面
图形化是linux安装了名为 gnonne的软件
进入到linux界面后,可以输入 ifconfig命令查看网络ip地址
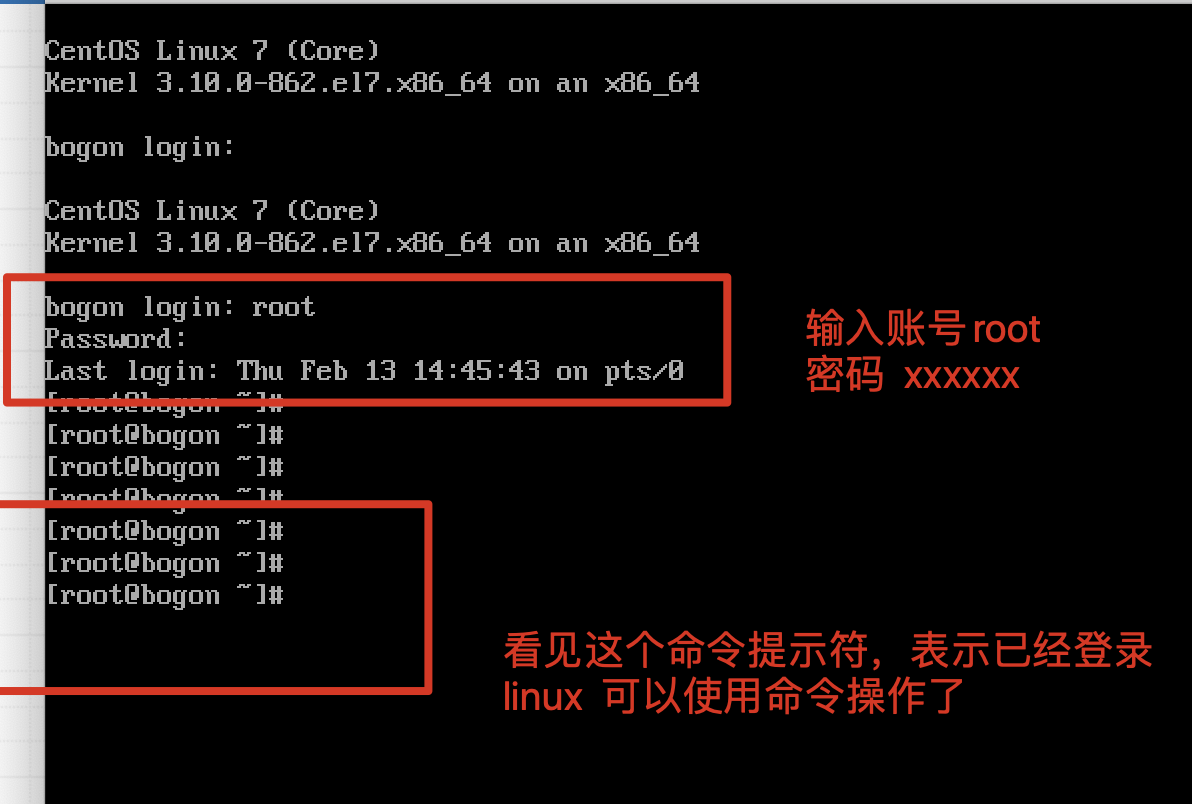
1.登录系统后,需要切换root超级用户,否则权限很低
su - root #需要输入root密码
如果不能用,输入,
yum install net-tools -y #安装软件包 net-tools
2.此时你应该就可以输入ifconfig命令了
切换图形化和纯黑屏的命令
ctrl + alt + f1~f7 代表linux默认的7个终端
f1 是图形化 其他是纯黑屏
这些我们几乎用不上,我们都是用远程连接的方式操作
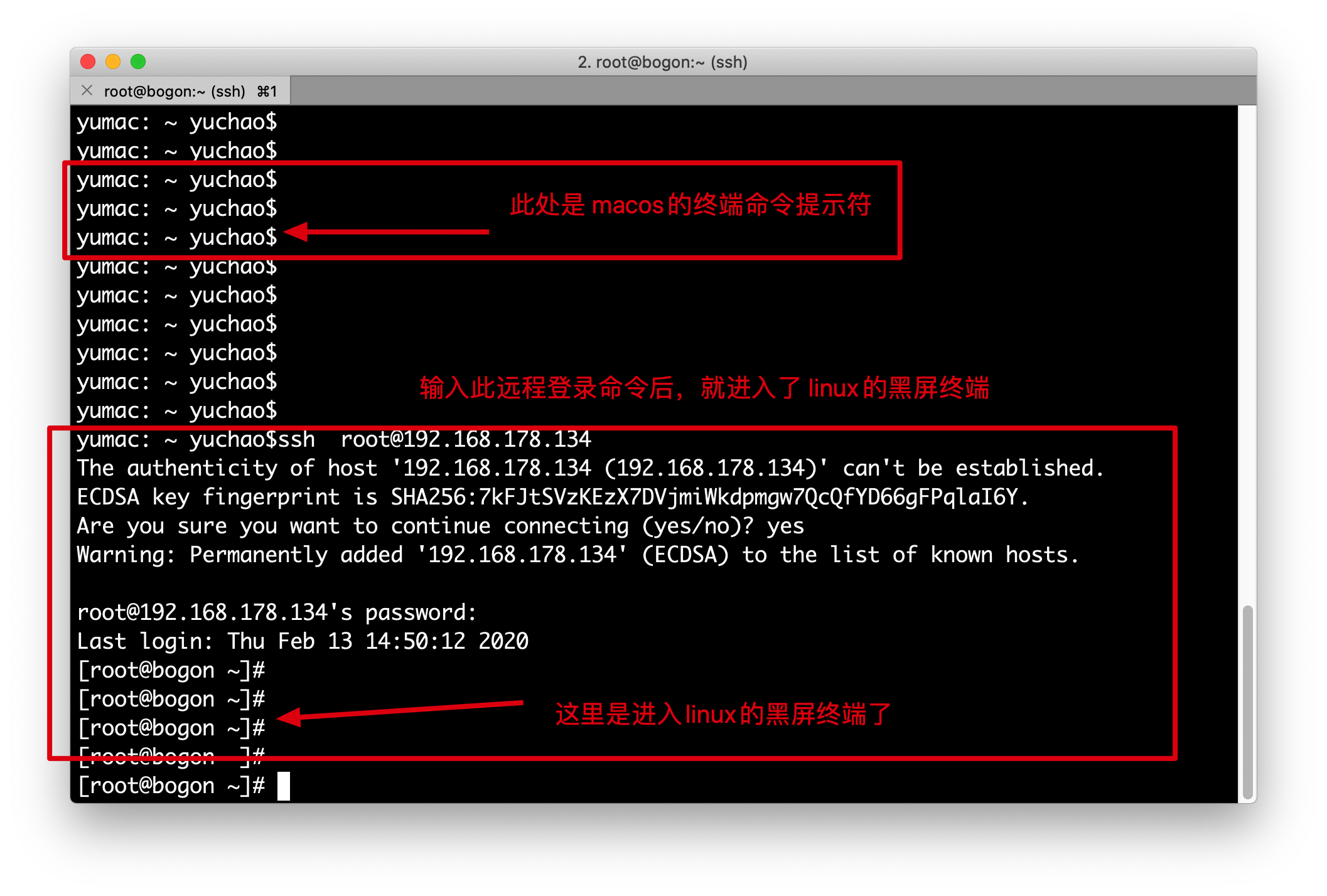
远程连接linux
对于服务器而言,我们不会直接去触碰机器,而是通过网络连接
1.确保你的服务器,正确的获取到了ip地址
ifconfig #查看到讲师的机器ip是 192.168.178.134
2.安装远程连接工具
windows点的同学,安装xshell 或者 secureCRT 或者
这2个软件其实也就是封装了 ssh命令而已
用macos的同学,直接使用ssh命令即可
ssh root@192.168.178.134

ip地址,标识了计算机在网络中的地址信息
123.206.16.61 这是一个公网的ip地址段,全世界都可以访问的
192.168.178.134 这是一个局域网的地址段,只有局域网内可以访问
127.0.0.1 ,本地回环地址,用于测试机器内部间通信的一个ip,只能自己和自己玩的地址
django程序启动在 127.0.0.1:8000
0.0.0.0 这个地址,表示注册绑定一台机器,所有的ip地址
由于一台服务器可能存在多个网卡,比如
linux机器 的2个ip
网卡1:192.168.178.134
网卡2:193.168.178.140
此时我启动django, python3 manage.py runserver
默认启动在 127.0.0.1:8000 windows机器能访问到吗? 答案是不能
那我启动在 python3 manage.py runserver 192.168.178.134:8000
windows怎么访问?直接访问192.168.178.134:8000地址即可
这样启动,192.168.178.140用户就无法访问到django了
所以在服务器上启动项目,一般都直接使用0.0.0.0地址,能够同时注册在
网卡1:192.168.178.134
网卡2:193.168.178.140
这2个ip上,
如此启动python3 manage.py runserver 0.0.0.0:8000
用户访问 192.168.178.134:8000
或者
193.168.178.140:8000 都可以了
port端口的概念,常见端口是?
一个端口对应一个服务
8080 ------自定义用的端口
3306--- mysql默认端口
80 --- http默认端口
443 ---https默认端口
6379 --- redis默认端口
22 ----- 用于远程连接服务器用的端口 22
linux命令提示符
linux命令语法如下
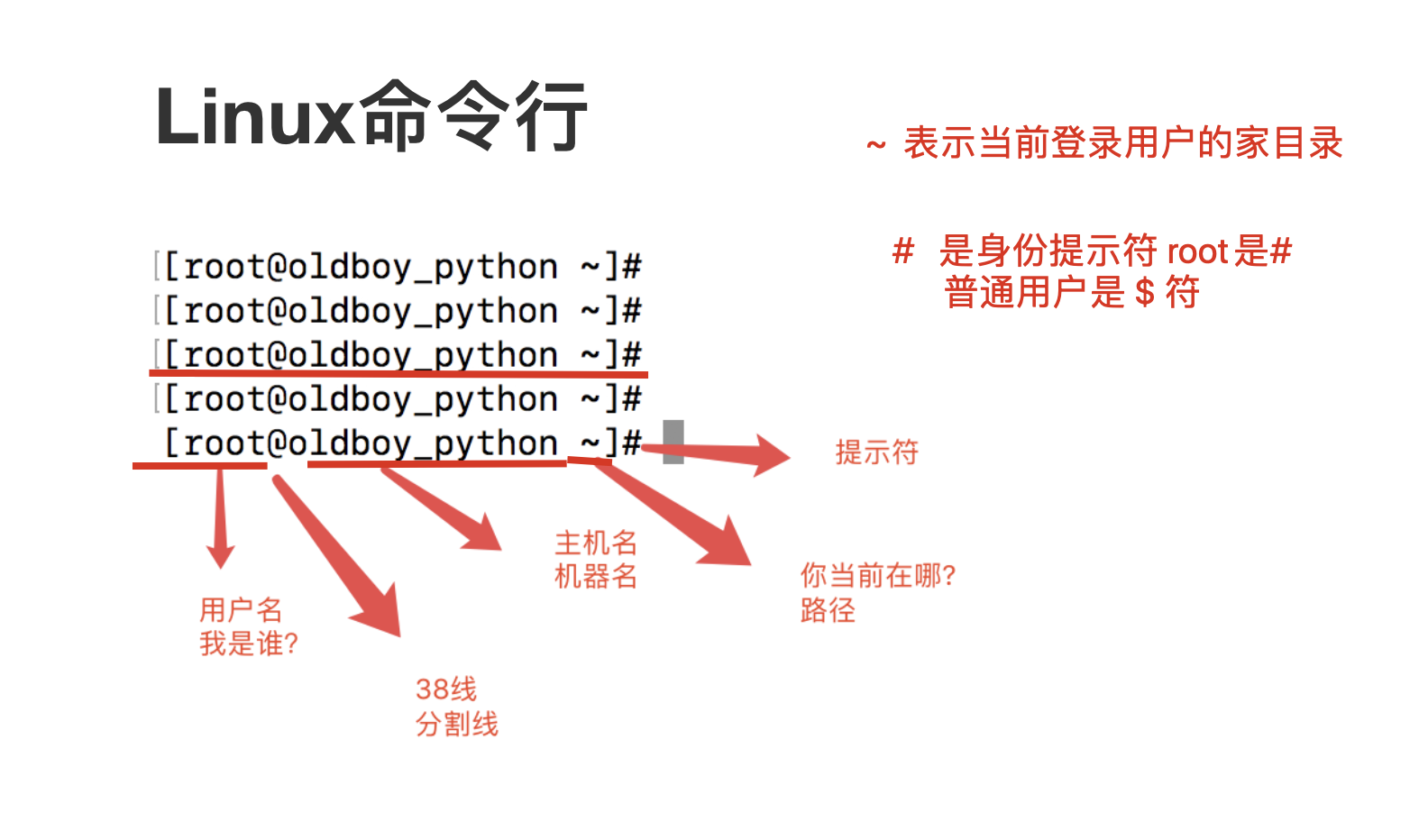
[root@bogon ~]# ls /tmp #这个命令表示,我要查看 /tmp 这个目录下的内容
#第二个简单的命令
#rm 命令 -f 参数(强制性删除) /tmp/oldboy.txt
rm -f /tmp/oldboy.txt
简单的命令 敲打
[root@bogon ~]# cd /home #目录切换,切换到 /home文件夹下
[root@bogon home]#pwd #我在哪 ,能够输出当前所在的绝对路径
[root@bogon home]# pwd
/home
[root@bogon home]# whoami #我是谁
root
[root@bogon pyyu]# pwd
/home/pyyu #linux的路径写法,如此
linux的文件系统 目录结构

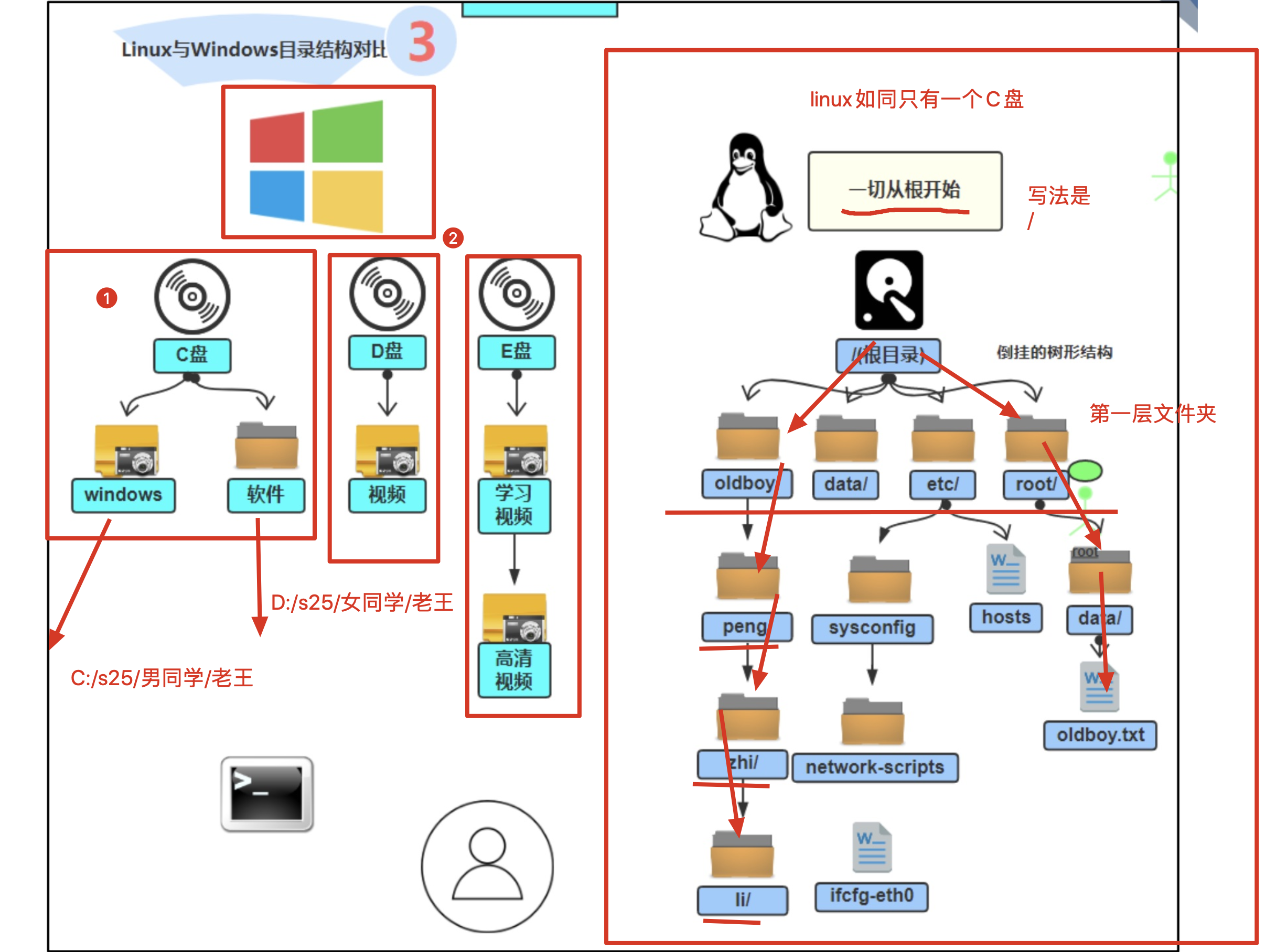
windows的目录
windows的目录结构,是反斜杠的目录分隔符
是
C:\
D:\
E:\
这种多个盘符的形式,可能存在多个目录顶点
linux的目录
只有一个 根目录
/
例如
/home # 根目录下有一个home文件夹
/s25 #根目录下有一个s25文件夹
#根目录下有2个同级的文件夹,男同学和女同学
/s25/男同学/小明.txt
/s25/女同学
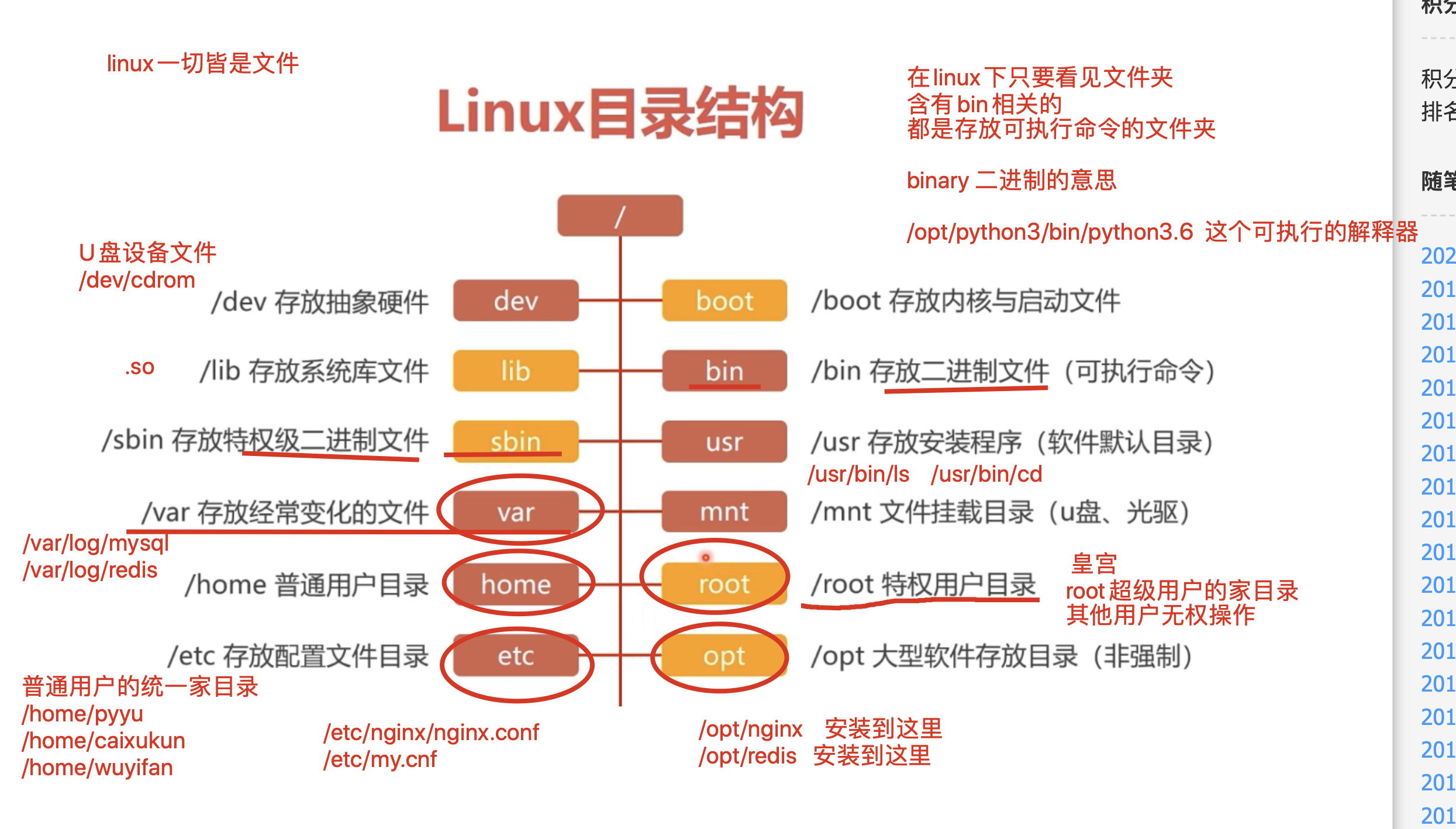
文件目录增删改查操作
linux命令的语法
命令 可选参数 你要操作的对象
修改linux支持文件的命令
export LC_ALL=zh_CN.UTF-8 #设置linux一个全局的中文变量
增
1.创建一个普通文本文件 语法是 touch 文件名
[root@bogon tmp]# touch music.txt
2.创建一个隐藏的文件,创建一个隐藏的 singer.txt
touch .singer.txt #创建隐藏文件
3.创建一个文件夹,名字叫做s25
[root@bogon tmp]# mkdir s25
4.创建一个递归的文件夹,如 /s25/男同学 /s25/女同学
mkdir -p /s25/男同学 /s25/女同学 # -p参数是 创建文件夹及其父文件夹
5.创建一个递归的文件夹 ,如 /s25new/男同学 /s25new/女同学
mkdir -p /s25new/{男同学,女同学} #创建一个/s25文件夹,且创建2个平级的文件夹
删
rm命令,是remove的缩写,删除文件或是文件夹
#语法是
rm 文件/文件夹 #删除文件/文件夹
比如
rm test.txt #删除文件,默认有让用户确认删除的提示
rm -f test.txt #强制删除文件,不需要提示确认
rm -r 文件夹名 #递归删除文件夹,及其内部的文件
#提问,如何强制性删除 文件夹 ,以及其内部的资料
#这是一个危险的命令!!!!请理解后慎用!!!
#这是一个危险的命令!!!!请理解后慎用!!!
#这是一个危险的命令!!!!请理解后慎用!!!
rm -rf /* #叫做删库到跑路,准备被打死吧。。。。万万不得敲。。。。
rm -rf /* #叫做删库到跑路,准备被打死吧。。。。万万不得敲。。。。
rm -rf ./* #强制性删除当前目录下的所有内容
改
cd /home #切换到 /home目录下
ls . #查看相对的home目录下有什么内容
查
#查询当前目录下的内容 ls命令
ls命令,就是list的缩写
[root@bogon /]# ls .
bin dev home lib64 mnt proc run srv tmp var
boot etc lib media opt root sbin sys usr
#查看文件夹中所有内容,以及隐藏的文件,在linux下,以.开头的文件,是隐藏的,默认直接看不到
[root@bogon tmp]# ls -a firefox_pyyu/
几个特殊的目录
. 代表当前的目录
.. 代表上一级的目录 #比如 cd .. 进入上一级目录
~ 代表当前登录用户的家目录,root用户就是/root pyyu用户就是 /home/pyyu
- 代表上一次的工作目录
绝对路径,相对路径
绝对路径:只要是从根目录开始的写法,就是绝对路径
相对路径:非从根目录开始的写法,就是相对路径
#在/home目录下创建 s25文件夹,绝对,相对路径的写法
1.相对路径,以你当前的位置为相对,创建
比如我此时在 /tmp目录下,我的上一级就是 / ,因此可以这么写
[root@bogon tmp]# mkdir ../home/s25
2.绝对路径的写法,一般是绝不会错的,无需考虑你当前所在的位置,直接敲绝对路径即可
mkdir /home/s25
如果开机没有ip怎么办
1.vim编辑网卡配置文件,修改如下参数
[root@s25linux tmp]# cd /etc/sysconfig/network-scripts/
ls 查看 ifcfg-ens33文件
vim修改此文件,找到如下参数,改为yes
ONBOOT="yes"
2.确保vmware 正确选择了 桥接 或是NAT,且已经连接上了
3. 命令重启网络设置
systemctl stop NetworkManager #关闭无线网络服务
systemctl restart network #重启有线网服务
#这2个命令执行都没有任何提示,表示正确的重启了网络配置
4.此时查看ip地址是否存在了
ip addr show
hostname 查看主机名
hostnamectl set-hostname 新的主机名
passwd 用户名 更改/设置用户密码
useradd 用户名
su - 用户名 切换用户
Linux常用命令
mkdir
mkdir 感谢老铁的花花 感谢老铁送上的飞机
mkdir -p 斗鱼/lol 虎牙/王者农药
tree
树的意思,以树状图显示文件目录的层级结构
#确保你的机器可以上网 ,yum如同pip一样,自动的安装东西,解决依赖
# pip 是给python安装模块的工具
# yum 是给linux安装系统软件的工具
yum install tree -y # -y默认yes同意安装
[root@s25linux tmp]# mkdir -p a/b c/d
[root@s25linux tmp]# tree
查看linux命令的帮助信息
1.用man手册,linux提供的帮助文档
man ls
man cp
man mkdir
2.命令加上 --help参数,查看简短帮助信息
mkdir --help
rm --help
3.在线的搜索一些命令查询网站
http://linux.51yip.com/
4.在线询问人工智能---超哥
...
echo命令
echo命令如同python的print一样,能够输出字符串到屏幕给用户看
案例
[root@s25linux tmp]# echo "感谢老铁送上的奥力给"
感谢老铁送上的奥力给
#linux在命令行的变量赋值,是临时生效的
#输出变量的值
#定义变量,中间有空格
name="感谢老铁送上的飞机"
#输出变量的值
[root@s25linux tmp]# echo $name
感谢老铁送上的飞机
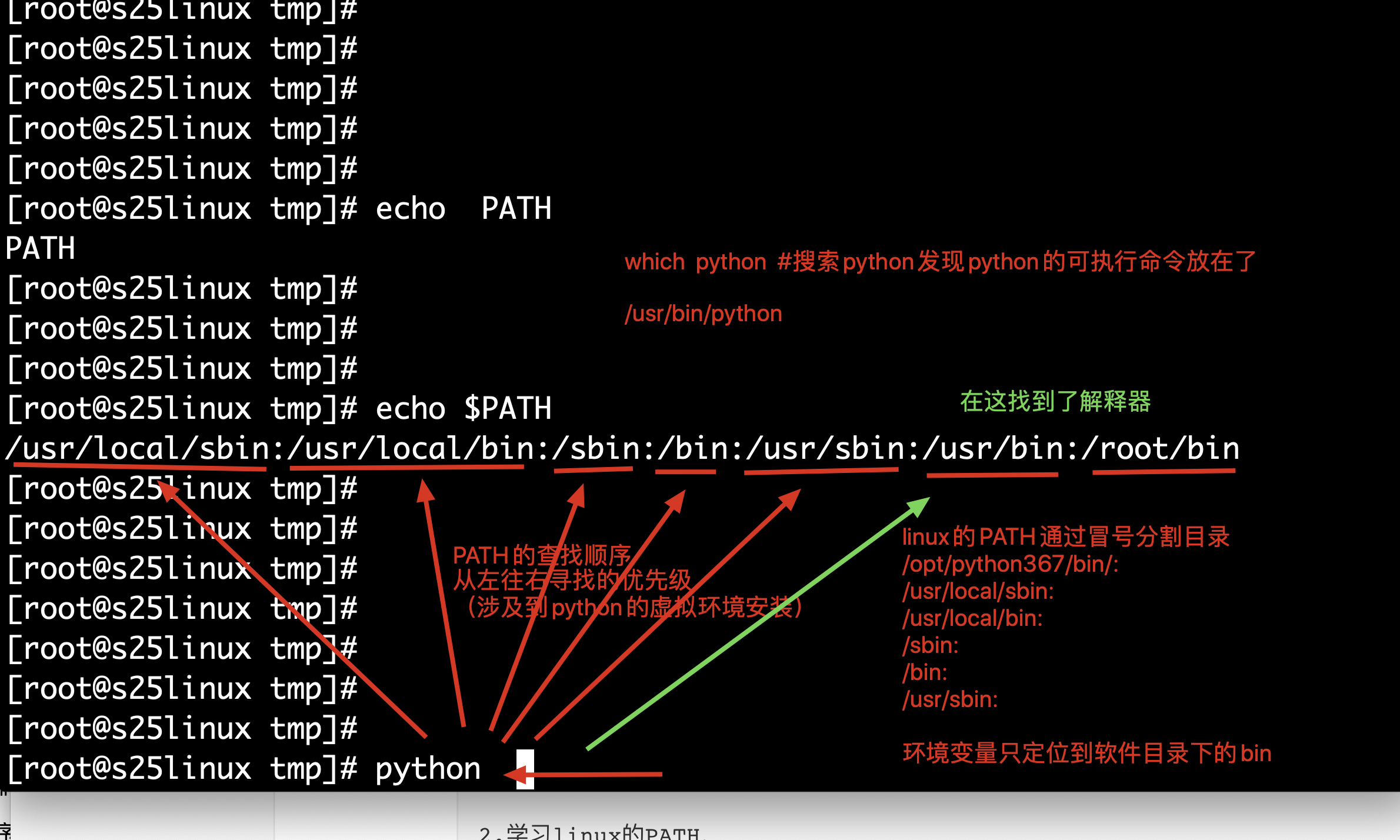
PATH变量
PATH就是定义一些常用的软件可执行命令的目录,放入系统中,可以快捷的查询,而不需要每次都输入绝对路径
1.为什么系统能够直接找到python解释器?
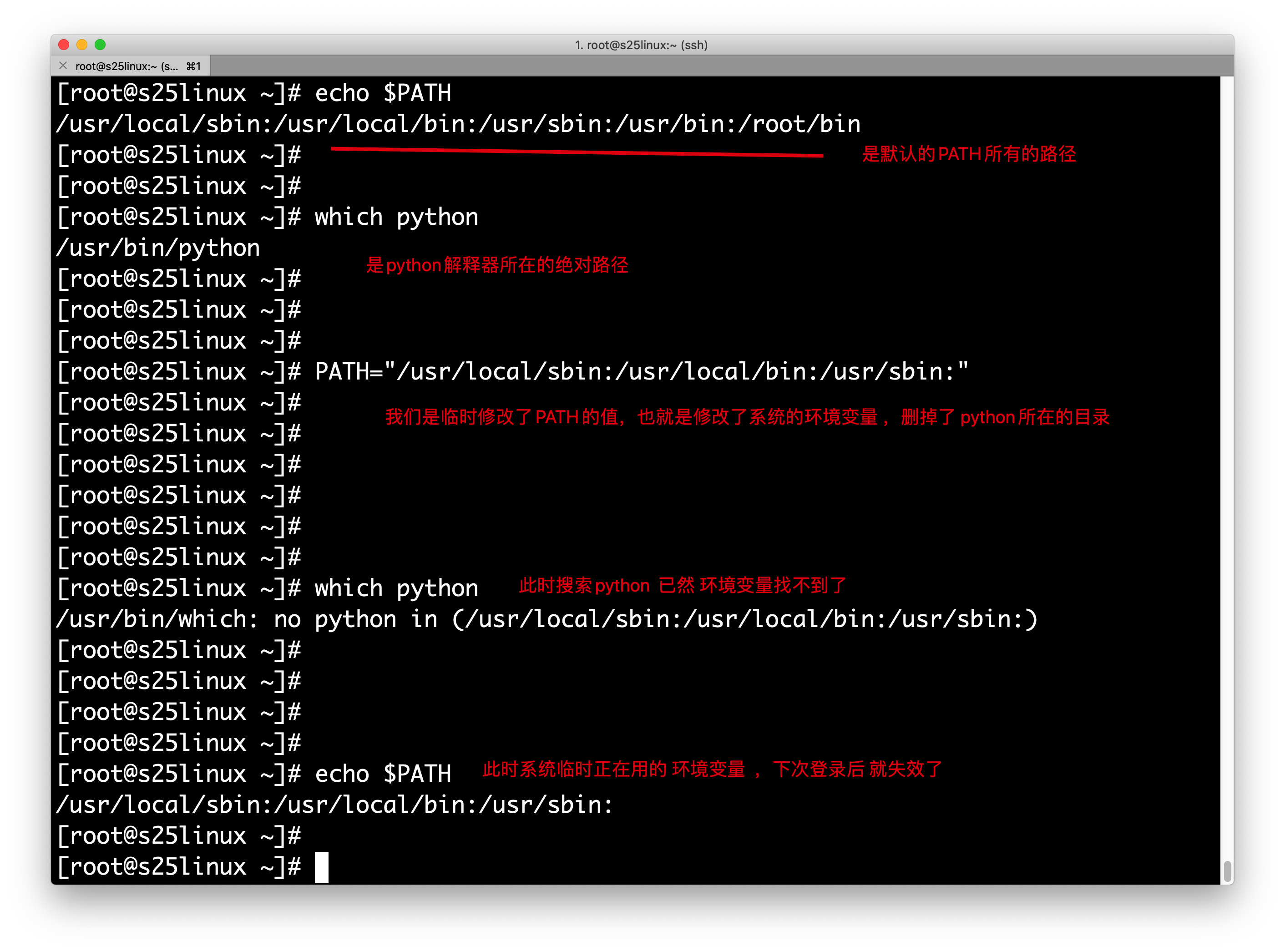
[root@s25linux tmp]# which python #输出命令所在的绝对路径
/bin/python
2.学习linux的PATH,
[root@s25linux tmp]# echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin
注意,PATH的路径,是有先后顺序的,从左往右,读取的
3.如果编译安装了一个python3,装在了 /opt/python36/目录下,怎么添加PATH?
#这个变量赋值的代码,就是添加python3到环境变量中了
PATH="/opt/python36/bin/:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:"
4.由于上述变量赋值的操作,只是临时生效,我们想永久的更改PATH的值,还得修改/etc/profile
vim /etc/profile #打开文件,在文件末尾,添加PATH值的修改
PATH="/opt/python36/bin/:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:"
PATH的寻找原理图

修改linux的全局配置文件
1.名字叫做 /etc/profile,里面是shell脚本语言
2.编辑这个文件,写入你想永久生效的变量和值,系统每次开机都会读取这个文件,让其生效
vim /etc/profile
写入如下内容
###这是自定义的变量,每次开机都能够读取了,第一条是设置系统中文的变量
export LC_ALL=zh_CN.UTF-8 #打开注释,系统支持中文
#export LC_ALL=en_US.UTF-8 #打开注释,系统就支持英文了
linux单引号和双引号的区别
单引号中的内容,仅仅就是个字符串了,不识别任何其他的特殊符号
双引号中的内容,能够识别特殊符号,以及变量
[root@s25linux ~]# echo '$name'
$name
[root@s25linux ~]# echo "$name"
我们是穿越在银河的火箭队
vim编辑器的用法
最基本的编辑器
windows
- 记事本
- sublime
- notapad++
- ....
linux
- vi 等同于记事本,很难用,没有语法颜色提示灯
- vim,等同于Notepad++,有颜色高亮,支持安装第三方插件,语法补全等等高级编辑器
vim使用流程
1. vim 需要单独安装的
yum instal vim -y # 安装
2.vim打开一个不存在的文件,默认会创建此文件
#用vim写一个python脚本,
#vim的使用流程
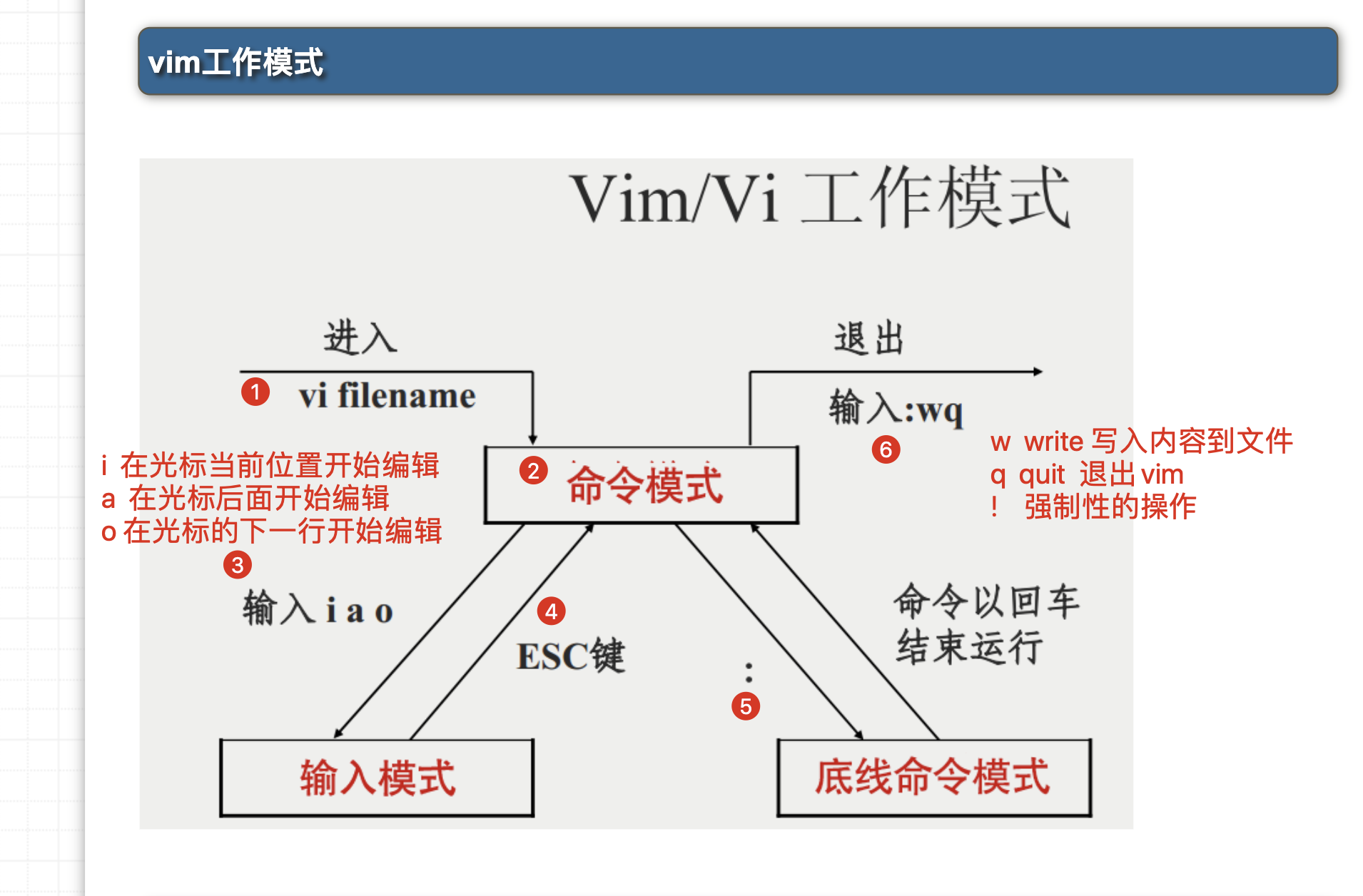
第一步:vim first.py ,此时会进入命令模式,按下字母 i,进入编辑模式
第二步:想要退出编辑模式,按下键盘的esc,回到命令模式
第三部:此时输入 shfit+冒号,输入一个英文的冒号,进入底线命令模式
第四步:输入 :wq! ,write写入内容,quit退出vim ! 强制性的操作
:wq! 强制保存写入退出vim
:q! 强制不保存内容,直接退出
3.此时可以查看一下文件内容
[root@s25linux tmp]# cat first.py
#!coding:utf-8
print ("你看这个灯,它又大又量")
4.如何执行这个脚本?
python fisr.py #即可执行脚本文件了
cat命令
cat 猫,用这个只猫瞄一眼 文件的内容
cat 文件名
[root@s25linux tmp]# cat first.py
print ("你看这个灯,它又大又量")
#读取内容,且显示行号
cat -n 文件名
#利用cat写入文件内容,写一首诗
[root@s25linux tmp]# cat >> second.py << EOF
> #!coding:utf-8
> print("爱的魔力转圈圈")
> EOF
[root@s25linux tmp]#
[root@s25linux tmp]#
[root@s25linux tmp]#
[root@s25linux tmp]#
[root@s25linux tmp]# cat second.py
#!coding:utf-8
print("爱的魔力转圈圈")
linux的重定向符号
> #重定向输出覆盖符 ,如同 python的 with open 中的 w模式
>> #重定向输出 追加符 ,如同 a模式
< #重定向写入覆盖符,用的很少,用在数据导入等操作中,mysql数据导入
<< #用在cat命令中,很少见
案例
1.echo输出一个字符串,内容不在屏幕上打印,写入到一个文件中
[root@s25linux tmp]# echo "左手跟我一起画个龙" > 迪斯科.txt
[root@s25linux tmp]# echo "左手跟我一起画个龙" > 迪斯科.txt
[root@s25linux tmp]# echo "左手跟我一起画个龙" > 迪斯科.txt
[root@s25linux tmp]# echo "左手跟我一起画个龙" > 迪斯科.txt
[root@s25linux tmp]# echo "左手跟我一起画个龙" > 迪斯科.txt
[root@s25linux tmp]#
[root@s25linux tmp]#
[root@s25linux tmp]# cat -n 迪斯科.txt
1 左手跟我一起画个龙
2.追加写入文件内容
[root@s25linux tmp]# echo "右手和我划一道彩虹" >> 迪斯科.txt
cp命令
拷贝
#对于配置文件的修改,或者是代码文件的修改,防止突然写错了,复制一份
#复制文件
[root@s25linux tmp]# cp 木兰诗.txt 新_木兰诗.txt
#复制文件夹,复制文件夹需要添加 -r 递归复制参数
[root@s25linux tmp]# cp -r a new_a
mv命令
mv命令可以 移动文件 ,文件夹的路径
mv命令也能够进行 重命名
1.重命名的功能
语法是
mv 旧文件名 新文件名
[root@s25linux tmp]# mv 木兰诗.txt new_木兰诗.txt
2.移动位置
语法
mv 你要移动的文件或是文件夹 移动之后的目录名(如果文件夹存在,则移动,不存在是改名)
案例
mv test.txt b #移动 test.txt文件 到 b文件夹下(b文件夹得存在,b不存在则test.txt)
alias别名命令
为什么rm命令默认会有一个让用户确认删除的动作呢?
解答是因为 rm 的-i参数作用
alias #直接输入可以查看当前系统的别名
案例
1.给系统添加一个别名
当你敲下start就是在执行后面的长串命令,很方便
alias start="python3 /home/mysite/manager.py runserver 0.0.0.0:8000"
find命令
可以用于搜索机器上所有的资料,按照文件名字搜索,linux一切皆文件
语法
find 你要从哪找 -type 你要的文件类型是什么 -size 你要的文件内容多大 -name 你要的内容名字是什么
-type f 是找普通文本文件
-type d 是找 文件夹 类型
-name 是指定文件的名字内容
#在系统上 全局搜索,所有的.txt文件
find / -name "*.txt"
#指定在etc目录下,进行局部搜索,一个网卡配置文件,网卡名字是以ifcfg开头的 ,文本类型文件
find /etc -type f -name "ifcfg*"
案例2
1.准备好测试的数据,在/tmp目录下
mkdir /tmp/python{1..5} #在/tmp目录下 创建 出 python1 ptyhon2 ... python5
touch /tmp/python_{a..d} #在/tmp目录下创建出 python_a ptyhon_b .. python_d 几个文件
2.查看准备好的测试文件
[root@s25linux tmp]# ls
python1 python3 python5 python_b python_d
python2 python4 python_a python_c
3.在/tmp目录下联系find命令
4.找出/tmp目录下所有的pyton相关内容
[root@s25linux tmp]# find . -name "python*"
./python1
./python2
./python3
./python4
./python5
./python_a
./python_b
./python_c
./python_d
5.找出/tmp 下所有的python相关的文件
[root@s25linux tmp]# find . -type f -name "python*"
./python_a
./python_b
./python_c
./python_d
6.反之找出所有的文件夹
find . -type d -name "python*"
7.全局搜索,超过10M大小的 txt文本
[root@s25linux tmp]# find / -size +10M -name "*.txt"
/tmp/python2.txt
/tmp/python3.txt
查看文件,文件夹大小
ls -lh # -h参数,是显示文件单位,以kb mb gb大小为单位 -l是列表形式,列出文件夹中详细信息
linux的管道符命令
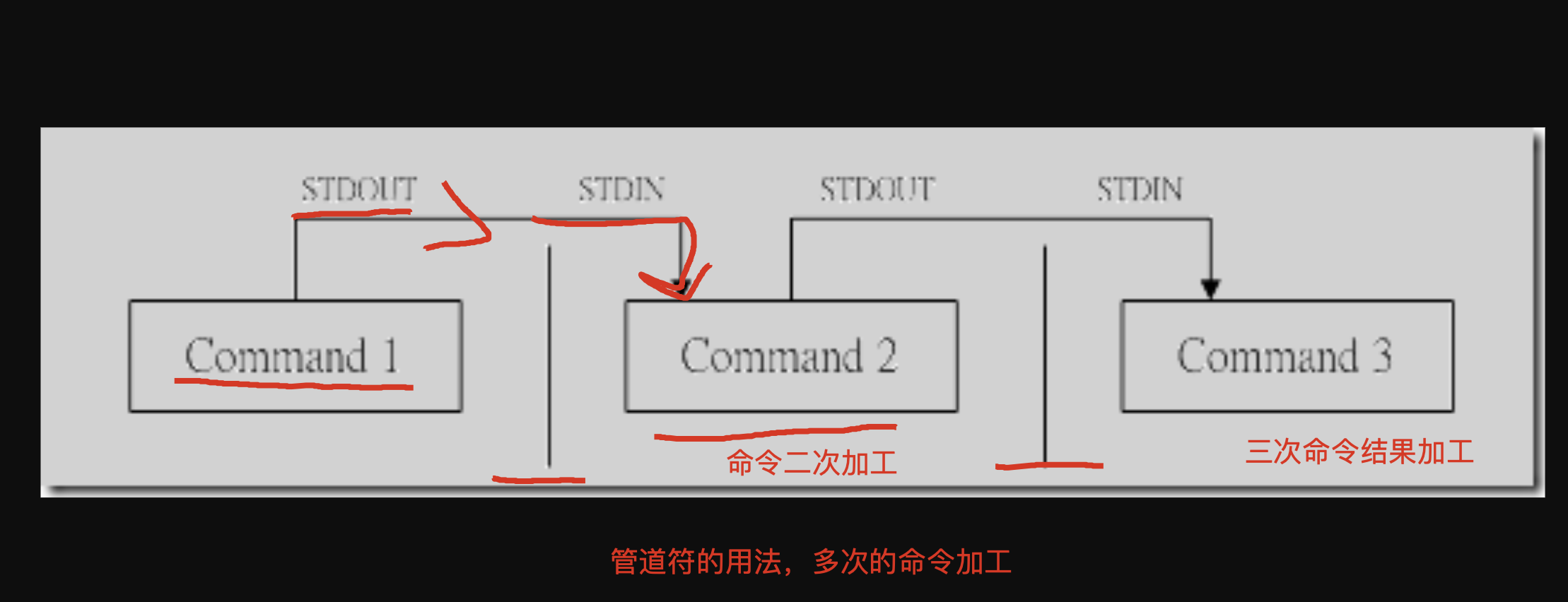
1.例如过滤服务器上的进程信息
2.例如过滤服务器上的端口状态信息
grep命令
grep是linux强大的三剑客之一,从文本中,过滤有用信息的命令
1.语法
grep "你想过滤的字符串" 需要过滤的文件 #用法一
准备一个测试的文件test.txt
[root@s25linux tmp]# cat test.txt
跟着我左右右手一个慢动作
#左右右手慢动作重播
一个大西瓜,送给你,也不送给他
ALLOW_HOSTS=[]
2.过滤文件中的相关内容
#找出文件中含有 "大" 字的行,且显示此内容,在哪一行
grep -n "大" test.txt # -n 参数是显示行号
#忽略大小写,找出ALLOW_HOSTS=[]参数是否被修改
grep -i "al" test.txt
#过滤出此文件非空白行,如何操作?
拆解如下
找出所有的空白行
[root@s25linux tmp]# grep "^$" test.txt # "^$" 以空开头,以空结尾,因此是空白行
# -v 参数是 翻转过滤结果 ,找出 空白行以外的内容
[root@s25linux tmp]# grep -v "^$" test.txt
#过滤掉注释行,和空白行 ,如何操作?
[root@s25linux tmp]# grep -v "^#" test.txt | grep -v "^$"
跟着我左右右手一个慢动作
一个大西瓜,送给你,也不送给他
ALLOW_HOSTS=[]
案例2
cat 文件 | grep "你想要的内容" #用法二
1.找出linux的用户信息文件,中 有关pyyu的行信息 /etc/passwd
[root@s25linux tmp]# cat /etc/passwd | grep "pyyu"
pyyu:x:1000:1000:pyyu:/home/pyyu:/bin/bash
head、tail命令
head和tail都是能够读取文件内容的
语法是
head 文件名 #默认从文件的前10行看
head /etc/passwd #默认看前10行
head -3 /etc/passwd #查看文件的前3行
tail 文件名 #默认从文件的后10行看
tail -2 /etc/passwd #查看文件的后2行
tail命令的 实时监控用法 ,可以用于检测线上的日志文件,检测用户的请求信息
tail -f 文件名 #实时刷新文件内容
tail -f /tmp/test.txt #能够检测文件内容的变化
如何查看文件的,中间20行-30行的内容
head -30 pwd.txt | tail -20 先读取前30行的内容,从后往前读取10行内容
scp命令
在2台linux机器(macos)之间,通过网络安全的传输文件,文件夹
scp命令 语法是
环境准备,准备2台linux机器
确保两台机器能够通信
机器1:192.168.178.134
机器2:192.168.178.235
案例1:
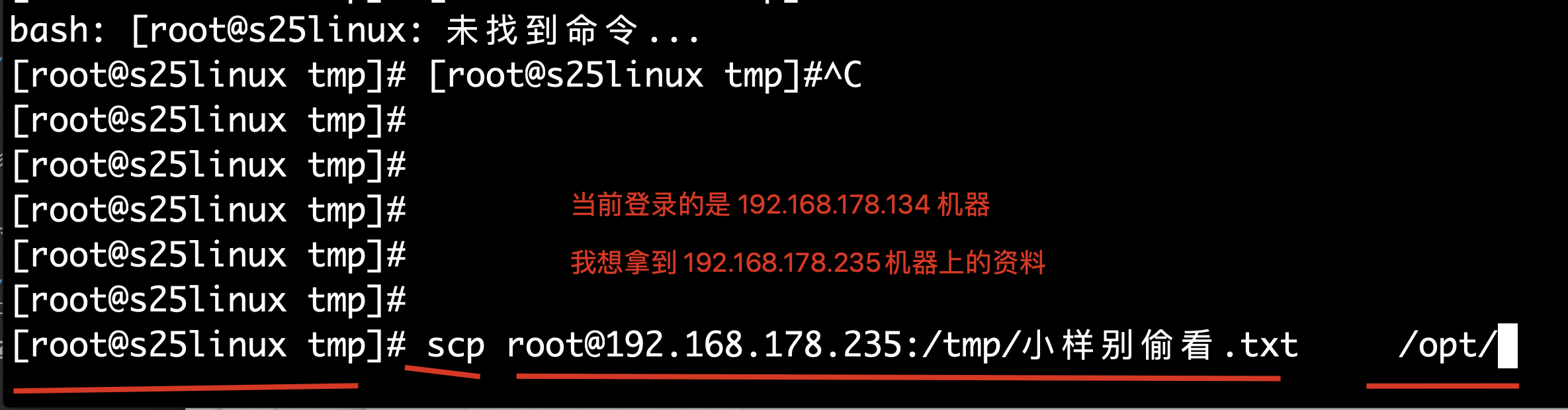
我登录的是 机器1
需求1:将机器1的/tmp/好嗨哦.txt 发送到 机器2的/tmp目录下
[root@s25linux tmp]# scp /tmp/好嗨哦.txt root@192.168.178.235:/tmp/
需求2:把机器2的/tmp目录下的资料 给拿到本地的/opt目录下
scp 你想要的内容 内容发送到哪里
scp root@192.168.178.235:/tmp/小样别偷看.txt /opt/
情况2,我登录的是 机器2
【把别人的资料拿来】
案例1:我想拿到机器1的/opt/test.txt 拿到机器2的/tmp目录下
scp 我想要的内容 内容存放的地点
scp root@192.168.178.134:/opt/test.txt /tmp/
【把自己的资料发给别人】
案例2:我想把本地的/home/fisrst.py 发送给机器1的/home目录下
scp /home/first.py 账号@机器1:/home/
scp /home/first.py root@192.168.178.134:/home/
#如果发送的是整个文件夹,就得加上 -r 递归的拷贝参数
[root@s25linux tmp]# scp -r ./lol root@192.168.178.235:/tmp/
#用通配符发送多个文件
[root@s25linux tmp]# scp -r ./* root@192.168.178.235:/tmp/134bak/
lrzsz工具
用于windows(基于xshell工具)和linux之间互相传递文件
1.安装此工具
yum install lrzsz -y
2.安装好lrzsz之后,就存在了2个命令 一个是 rz 一个是sz
rz #直接输入rz命令,能够蹦出一个弹窗,接收windows的资料
sz 文件 #发送linux的一个文件,发给 windows某个位置,也是出现一个弹窗
du命令
用法
du 【参数】【文件或目录】
-s 显示总计
-h 以k,M,G为单位显示,可读性强
案例
统计/var/log/文件夹大小
du -sh /var/log/
#显示当前目录下 所有文件的大小
[root@s25linux tmp]# du -h ./*
vim命令的用法
1. vim 文件名 # 此时进入命令模式,你敲击键盘的动作都会被识别是一个vim的命令 ,比如 a,i,o 进入插入模式
2.但凡进入插入模式之后,敲击键盘的动作就会被识别为是 普通的字符串了
3.按下esc退出编辑模式之后,又进入命令模式了
4.输入 :wq! 保存vim的写入内容,然后退出vim,结束操作
在命令模式下,常用的指令
$ 快速移动到行尾
0 快速移动到光标的行首
x 删除光标所在的字符
g 移动到文件的第一行
G 移动到文件的最后一行
/string 你要从文件开头寻找的内容,例如 /to 找出文件中所有的to字符,按下n键,跳转到下一个匹配的字符
?string 从文件的第行,向上搜索字符串信息
% 找到括号的另一半
yy 复制光标当前行
3yy 复制光标后3行
p 打印yy所复制的内容
dd 删除光标所在行
4dd 删除光标向下的4行内容
dG 删除光标当前行,到行尾的所有内容
u 就是撤销上一次的动作
如何快速的复制,打印生成多行内容
例如 按下 9999yy 就是 复制 9999行,然后按下p打印,就能够快速的复制N多行了...
底线命令模式下
:wq!
:q! 不保存退出
:数字 快速的定位到某一行
:set nu 显示vim的行号
top命令
windows的任务管理器见过吧
能够显示 动态的进程信息
cpu、内存,网络,磁盘io等使用情况 ,也就是一个资源管理器
那么linux的资源管理器 就是top命令
第一行 (uptime)
系统时间 主机运行时间 用户连接数(who) 系统1,5,15分钟的平均负载
第二行:进程信息
进程总数 正在运行的进程数 睡眠的进程数 停止的进程数 僵尸进程数
第三行:cpu信息
1.5 us:用户空间所占CPU百分比
0.9 sy:内核空间占用CPU百分比
0.0 ni:用户进程空间内改变过优先级的进程占用CPU百分比
97.5 id:空闲CPU百分比
0.2 wa:等待输入输出的CPU时间百分比
0.0 hi:硬件CPU中断占用百分比
0.0 si:软中断占用百分比
0.0 st:虚拟机占用百分比
第四行:内存信息(与第五行的信息类似与free命令)
total:物理内存总量
used:已使用的内存总量
free:空闲的内存总量(free+used=total)
buffers:用作内核缓存的内存量
第五行:swap信息
total:交换分区总量
used:已使用的交换分区总量
free:空闲交换区总量
cached Mem:缓冲的交换区总量,内存中的内容被换出到交换区,然后又被换入到内存,但是使用过的交换区没有被覆盖,交换区的这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
ps命令
用于查看linux进程信息的命令
语法就是
ps -ef # -ef,是一个组合参数,-e -f 的缩写,默认显示linux所有的进程信息,以及pid,时间,进程名等信息
#过滤系统有关vim的进程
[root@s25linux ~]# ps -ef | grep "vim"
root 24277 7379 0 16:09 pts/1 00:00:00 vim ps是怎么用的.txt
1.一个django运行后,如何验证django是否运行了,它会产生些什么内容?
能够产生日志,检测到用户的请求,说明django运行了
查看端口情况,django会占用一个端口
产生一个python相关的进程信息
kill命令
杀死进程的命令
kill 进程的id号
如果遇见卡死的进程,杀不掉,就发送 -9 强制的信号
kill -9 pid
netstat命令
查看linux的网络端口情况
语法如下
常用的参数组合 -t -n -u -l -p
[root@s25linux tmp]# netstat -tunlp #显示机器所有的tcp、udp的所有端口连接情况
#例如验证服务器80端口是否存在
netstat -tunlp | grep 80
#过滤3306端口是否存在
netstat -tunlp |grep 3306
#过滤ssh服务是否正常
[root@s25linux tmp]# netstat -tunlp | grep ssh
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1147/sshd
tcp6 0 0 :::22 :::* LISTEN 1147/sshd
#有些公司为了保护服务器安全,更改了默认的远程连接端口
# ssh端口 26674 ip 是 123.206.16.61 账号是 xiaohu 密码是 xiaohu666
#我怎么登陆服务器呢?用如下的命令去连接服务器
ssh -p 26674 xiaohu@123.206.16.61
ssh -p 22 root@192.168.178.134
root@192.168.178.134's password:
grep是支持正则表达式的
查看系统发行版
不同的发行版,使用命令有所区别,安卓手机----IOS手机--操作方式不一样
centos---常用的命令---yum软件管理工具
ubuntu---常用命令差不多的-----没有yum-只有apt软件管理工具
#此文件,之后红帽系统才有
[root@vm_0_8_centos tmp]# cat /etc/redhat-release
CentOS Linux release 7.6.1810 (Core)
#任何的linux系列都有的一个文件
[root@s25linux ~]# cat /etc/os-release
history 历史记录命令
可以查看用户之前敲打的命令
可以用感叹号,加行号,快速执行之前的命令
centos7用什么命令管理服务
systemctl #这是centos7
systemctl start ngixn # 7系列这么启动
service #这是centos7以下系列系统,使用的命令
service nginx start # 6系列启动命令
Linux用户管理
对于一个qq群而言,有哪些角色划分,权利的划分
群主-----qq群里面,权利最大,想干嘛就干嘛,可以随意的拉人,踢人等等----相当于皇帝----相当于linux的root用户
管理员---他是root赋予的临时的超级权限-在用皇帝的身份狐假虎威---钦差大人---linux系统中的sudo命令--尚方宝剑
吃瓜群众---权利最低的,基本上只能够在自己的家目录,进行增删改查,其他目录,权限都很低-----linux的普通用户
系统创建了用户,同时会创建一个同名的组
例如
useradd caixukun #创建普通用户 caixukun,系统会在/etc/passwd文件中,增加一行用户信息
且同时创建了一个用户组 也叫caixukun ,存放在/etc/group 文件中
id命令
查看用户的账户信息的命令
例如
id root
[root@s25linux tmp]# id root
uid=0(root) gid=0(root) 组=0(root)
id caixukun
[root@s25linux tmp]# id caixukun
uid=1004(caixukun) gid=1004(caixukun) 组=1004(caixukun)
组的概念
对于技术部门,运维需要分配的单个用户的权限太散,太多,人太多了。。。
【权限控制,其实控制的就是,不同的组,不同用户,针对不同的文件夹,文件,操作的权限的不同】
比如说
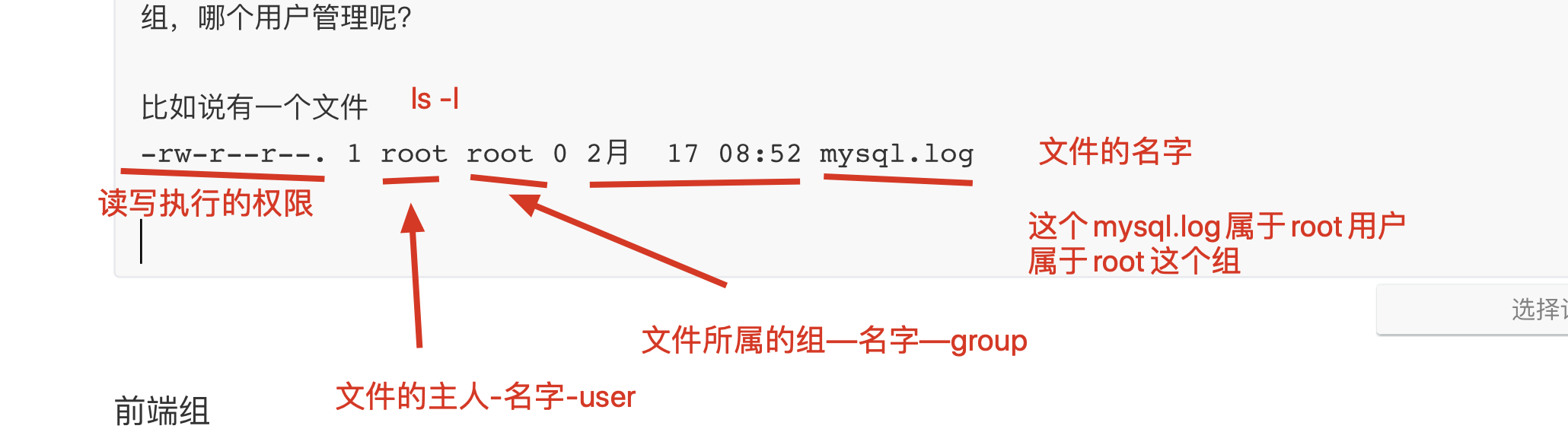
mysql的默认数据存放路径,如 /var/lib/mysql/* 那么这个mysql的数据文件,以及所有的文件夹,是属于哪个组,哪个用户管理呢?
比如说有一个文件
-rw-r--r--. 1 root root 0 2月 17 08:52 mysql.log
前端组
后端组,权利稍微大一点。
运维组,对于服务器操作权限很大,可以使用root的权限
测试部门
安全部门
DB部门
运维都得对上述的人,进行权限控制,对于服务器的操作权限
因此引入组的概念,针对整个组管理,就方便多了,
root而言
root为什么叫root,是因为系统提出了UID的概念,用户id号,用户id为0的就是系统的超级用户
普通用户由root用户创建,默认的UID是从1000开始进行累计,权利很低
普通用户
默认用户家目录都在/home
例如
/home/pyyu/
/home/alex/
/home/wupeiqi/
用户管理的命令
添加删除用户,注意的是,涉及到权限的修改,只能用root去操作,其他人基本上没权限
useradd caixukun #创建用户caixukun
passwd caixukun #给用户修改密码,
userdel caixukun #删掉caixukun这个用户
userdel -rf caixukun #删除用户,且删除用户的家目录
用户登录切换
su - 用户名 #用户登录切换,普通用户切换,需要输入密码,root用户想干嘛都不需要密码
#这个减号必须加上,叫做,完全的环境变量切换,是正确的切换方式
比如
su - pyyu
su - root
尚方宝剑命令sudo
1.当pyyu用户,想要进入/root文件夹,发现权限不够,怎么办
思路:
1.使用sudo命令,默认以root身份去执行命令
例如 sudo cd /root
思路2:
把pyyu用户,加入到root组里,也就拥有了root组的权限,但是还是得查看这个group的权限
思路3:
直接修改/root文件夹的权限,允许其他人,也可以读写执行 ,其他人也就能够进入到/root文件夹了
【sudo命令使用配置流程】
1.使用visudo命令,修改配置文件,添加你允许执行sudo命令的用户
visudo #打开文件后,找到大约在91行的内容,修改为如下
91 ## Allow root to run any commands anywhere
92 root ALL=(ALL) ALL
93 pyyu ALL=(ALL) ALL
2.保存退出之后,即可使用sudo命令了
sudo ls /root
Linux文件、目录权限管理
文件管理的权限-----也就是针对这文件,属于哪个用户,属于哪个组,以及对应的权限是什么
背景:比如武沛奇,有一个手机 iphone7
这个iphone7 属于哪个用户?他的权限应该是怎样的?(他对于这个手机使用的权限)
(这个手机属于 武沛奇,并且他的权限,应该是 最大的权限,可以随意的把玩 )
对于武沛奇自己而言
是可以任意的把玩,用读写执行的权限
武沛奇可以看手机,改手机资料,手机给砸了
那武沛奇的家庭成员(他老婆),对于这个手机而言,属于什么样的关系?并且可能的权限是什么?
读,写,执行(可以看手机,改手机内容,以及砸掉手机)
他老婆属于武沛奇这个家庭组里,可能分配的权限是,读写权限(这个权限都是有权利最大的人分配的,好比一家之主说话才算话)
因此,武沛奇家庭组的人,可能只能读写,,也就是,可以 看手机 ,,玩手机,而不能砸掉
那此时,超哥来了,对于这个武沛奇的手机而言,属于什么身份关系?以及可能用的 读写执行权限是什么??
超哥对于这个手机而言,就属于一个 其他人,没有任何的关系,因此权限一般很低,只能看一看,摸都不给摸
对于如上的比喻做一个总结
对于linux系统而言,文件、文件夹,都是有 user 属主, group属组的一个角色分配,还存在一个other其他人
这三个身份的划分
并且设定了 r w x 三个权利的限制,也就是 读,写,执行(对于文件的读写执行)
场景:
1. root用户在/tmp目录下 创建了一个 文件 叫做 root.txt ,因此这个文件默认就属于root用户,属于root用户组
2.此时 一个普通用户,登录了机器 ,如
ssh chaoge@192.168.178.134 登录机器之后,chaoge对于这个 root.txt文件而言,就是一个其他人的身份了
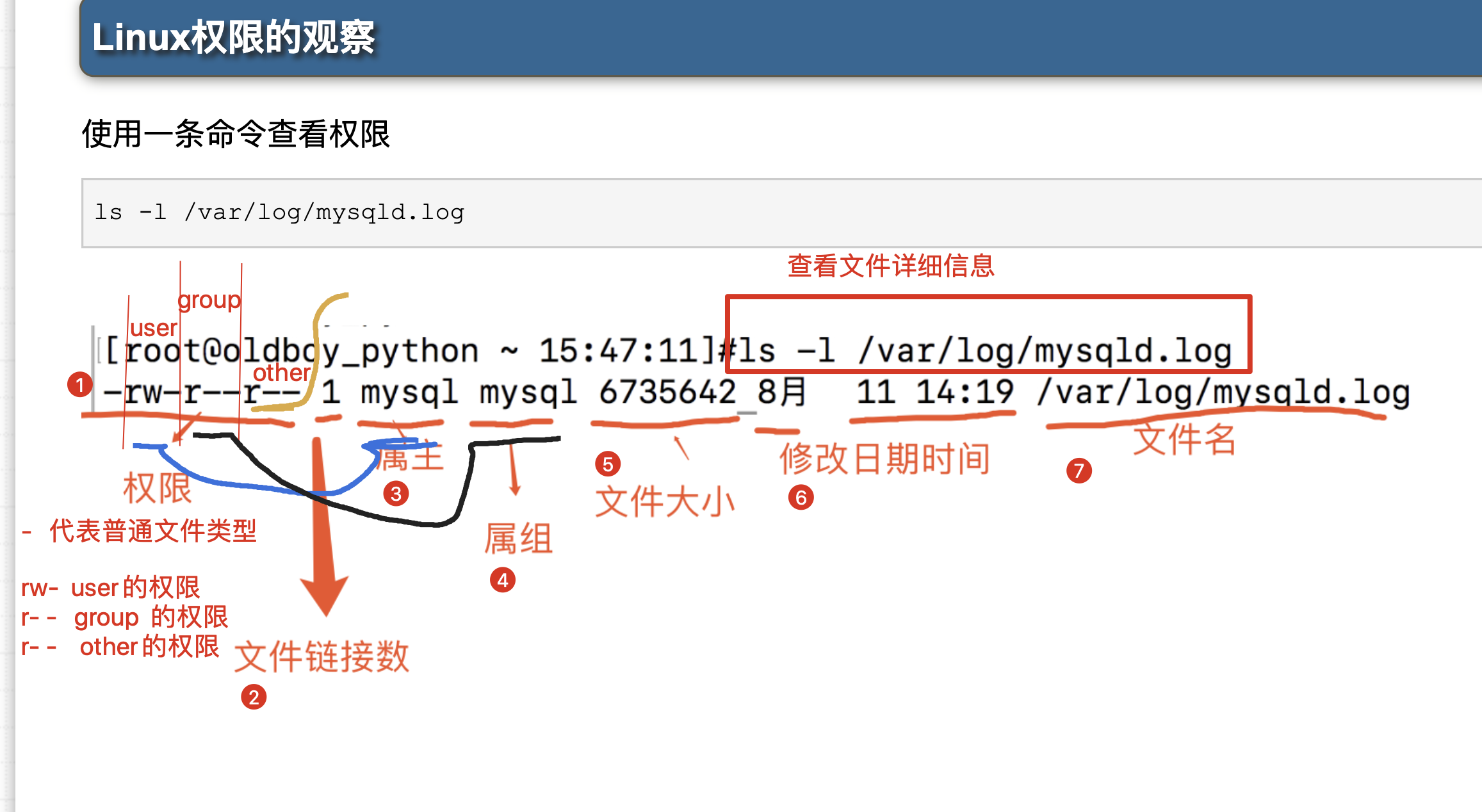

查看文件夹的详细信息
[root@s25linux ~]# ll /tmp
总用量 4
drwxr-xr-x. 2 root root 6 2月 17 11:00 hehe #文件夹
解读它的信息
drwxr-xr-x 拆分如下
d d代表是一个文件夹
rwx user是root,root可以读写执行
r-x group也是root,root组里的成员,可以读,执行
r-x others权限是 读,执行
#文件的权限,必须顺序是 rwx ,没有权限则写一个-号
-rw-r--r--. 1 pyyu pyyu 2328 2月 17 09:15 pwd.txt #文件
#解读如上的权限
- 开头是 -号,就是普通的文本类型
rw- user是pyyu,pyyu这个用户权限是 可读、可写,不可执行
r-- group是pyyu,只读
r-- 此时peiqi这个用户对于pwd.txt这个文件,权限就是 只读的
对于文件的rwx
r cat,more,less,head,等读取文件内容的操作
w vim ,echo,等写入内容的操作
x 可以执行的脚本,例如bash,python等脚本,文件会变成绿色
对于文件夹的rwx
r ls 查看文件夹内容
w 允许在文件夹中创建文件等操作
x 允许cd进入此文件夹
chmod命令总结
chmod 可以更改文件的权限,更改针对 user,group,other的权限修改,例如
chmod u+r file.txt #给文件的user,添加读的权限
chmod g-x file.txt #给文件的group组权限,去掉可执行
chmod o+r,o+w,o+x file.txt #给文件的other身份,最大的权限,读写执行
chmod 000 file.txt #给与文件最低的权限,任何人不得读写执行

chown
change owner缩写
更改文件的拥有者,user
chown 新的属主 file.txt
chgrp
更改文件的拥有组,group
change group 缩写
chgrp 新的属组 file.txt
软连接
windows的一个快捷方式而已
创建命令
ln -s 目标文件绝对路径 软连接绝对路径
[root@s25linux tmp]# ln -s /tmp/test.txt /opt/t.txt #给/tmp/test.txt创建一个快捷方式,放在/opt/t.txt 这里
删除快捷方式,删除软连接是不会影响源文件的
windows下装另一个qq在 D:\qq\qq.exe ,发送快捷方式到桌面
打包、压缩、解压缩
也就是linux的tar命令
打包,不节省空间
压缩,节省磁盘空间
语法
tar 命令
功能参数
-z 调用gzip命令,对文件压缩 ,加上这个参数,才会节省磁盘空间
-x 解包,拆快递
-v 显示整个过程
-f 必须写在参数结尾,指定压缩文件的名字
-c 打包,收拾快递
压缩文件的后缀,本没有意义,只是告诉别人,这个文件是用什么命令压缩/解压缩
*.gz gzip命令解压缩
*.tar 用tar命令解压缩
*.xz 用xz命令解压
*.zip 用unzip命令解压
案例1:打包/opt/目录下所有的内容,打包生成tar包allopt.tar
第一步:打包opt下所有内容
[root@s25linux opt]# tar -cvf allopt.tar ./*
第二步:解包这个tar包
[root@s25linux opt]# tar -xvf allopt.tar ./
案例2:打包,且压缩/opt目录下所有内容,生成tar.gz包allopt.tar.gz
第一步:打包,且压缩,就是加一个-z参数即可
[root@s25linux opt]# tar -zcvf allopt.tar ./*
第二步:解压缩,常见的*.tar.gz,也有人会缩写成 *.tgz ,都可以如此的去解压缩
[root@s25linux opt]# tar -zxvf allopt.tar.gz ./
疑问:必须先打包再压缩吗?能对一个文件夹直接压缩吗?
解答: 打包,压缩是一体的,是调用tar命令,加上-z参数,自动就压缩了
tar -zcvf dir.tar.gz ./testdir/ #压缩此文件夹,放入到一个压缩文件 dir.tar.gz中
.gz是 压缩的常见后缀格式
防火墙
用于控制服务器的出/入流量
防止恶意流量攻击服务器,保护服务器的端口等服务。
在学习阶段是直接关闭的,专业的运维人员需要学习iptables软件的一些指令
云服务器,默认都有一个硬件防火墙,以及软件防火墙(iptables、firewalld)
我在服务器上,运行了django服务,如果开启了防火墙服务器,且没有自定义规则,默认是拒绝所有外来流量 ,导致我们windows无法访问到linux运行的django等程序
1.清空防火墙规则
iptables -F #清空防火墙规则
2.关闭防火墙的服务
systemctl stop firewalld #关闭防火墙服务
systemctl disable firewalld #禁止防火墙开机自启
DNS域名解析
什么是dns解析?
dns解析系统-------手机上的电话簿------- 小王----132xxx 小莉---186xxxx
dns服务器,存储了公网注册的所有(域名----ip)对应的解析关系
linux的dns客户端配置文件/etc/resolv.conf
里面定义了主备的两个dns服务器地址
[root@s25linux ~]# cat /etc/resolv.conf
# Generated by NetworkManager
#search localdomain
nameserver 119.29.29.29 # 改成 223.5.5.5 速度快(阿里巴巴DNS服务器地址)
nameserver 223.5.5.5 # 改成 223.6.6.6 速度快(阿里巴巴DNS服务器地址)
linux的本地dns强制解析文件 /etc/hosts,可以写入一些测试的域名,用于本地机器使用,域名解析优先级更高
[root@s25linux ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
127.0.0.1 pythonav.cn
nslookup命令
域名查找命令
nslookup www.pythonav.cn #寻找dns对应关系
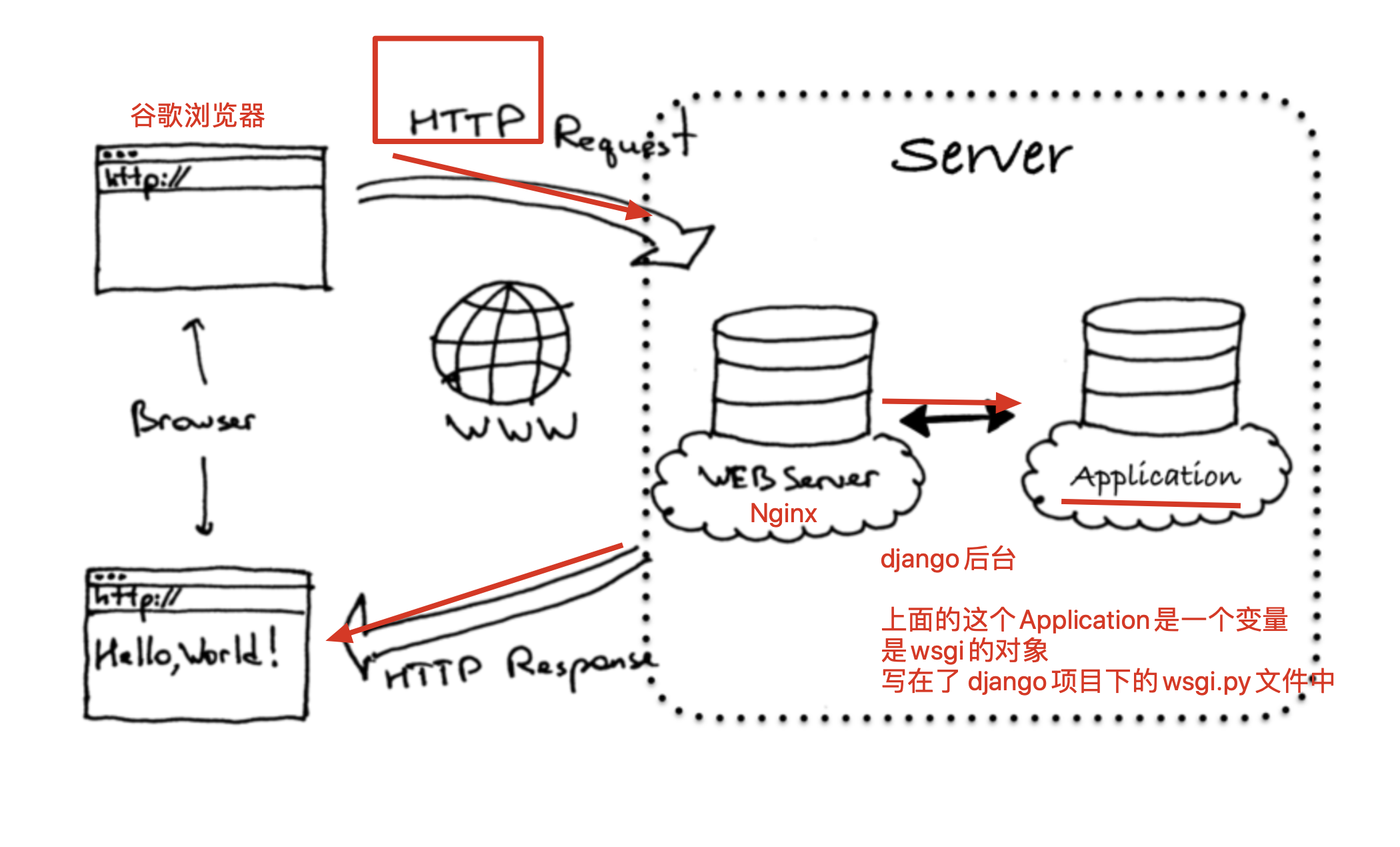
浏览器输入url之后,是怎么解析的?发生了什么事?
浏览器里面输入 www.pythonav.com发生了什么
1.浏览器进行dns查找,解析 域名对应的ip机器,找到之后浏览器访问此ip地址
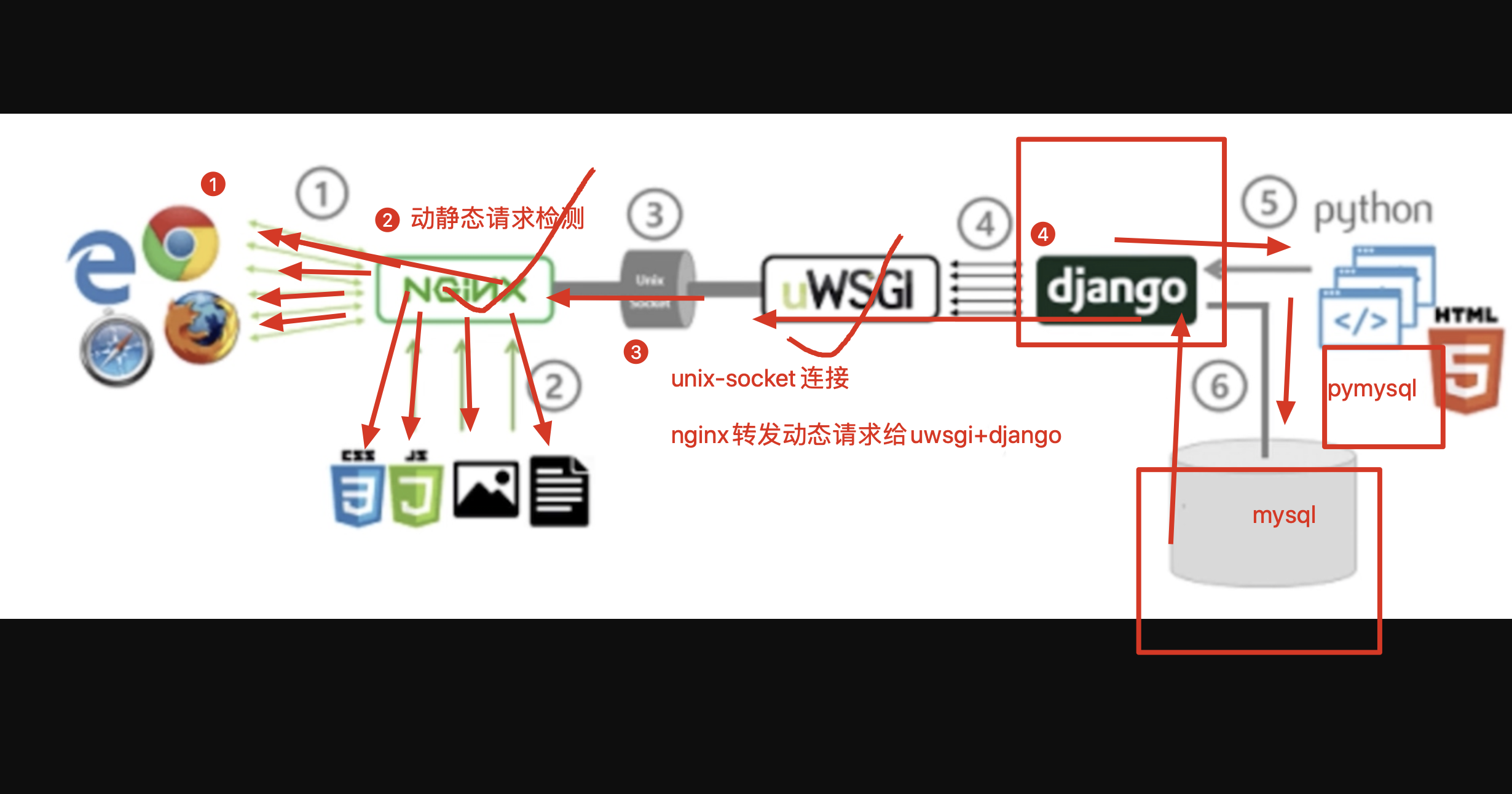
2.用户请求,发送到了服务器之后,优先是发给了nginx(web服务器),用户请求的是静态资源(jpg,html,css,jquery)nginx直接从磁盘上找到资料给与用户查看
如果nginx检测到用户请求是一个动态请求,登录,注册,读取数据库,例如 .php 例如 .aspx ,通过url匹配发现是动态请求,转发给后端的应用服务器(php,tomcat,django)
3.django处理完用户的动态请求之后,如果发现需要读取数据库,再通过pymysql向mysql读取数据
4.如果django处理请求,发现读取的是redis,再通过pyredis向redis拿数据
5.django处理完毕之后,返回给nginx
6.nginx返回给用户浏览器
7.浏览器渲染数据之后,给与用户查看页面
大型网站技术架构,很nb,好好看,面试可劲吹
crontab定时任务
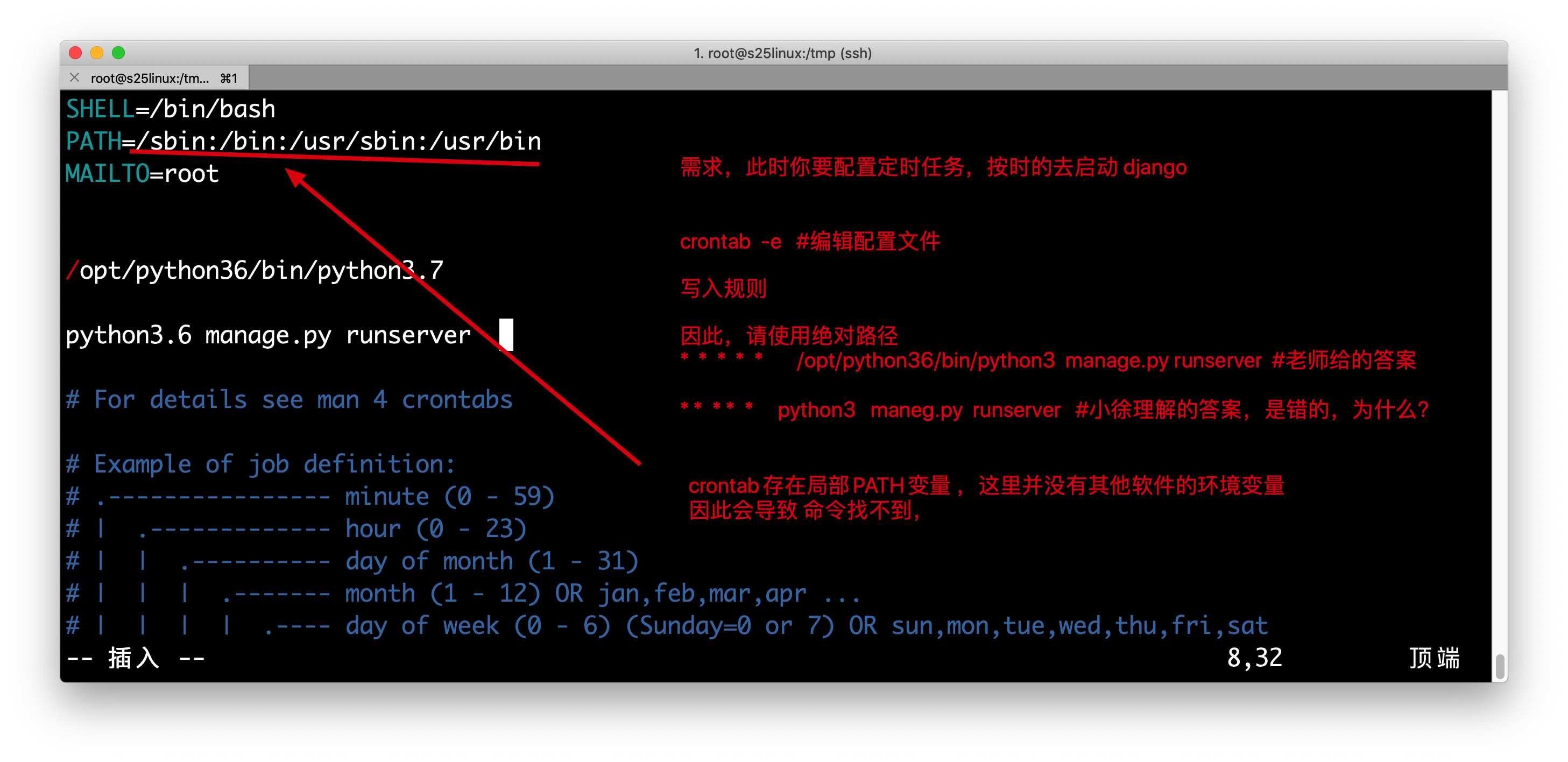
crond定时任务服务,提供了一个客户端管理命令crontab
crontab -e #编辑定时任务配置文件
crontab -l #查看定时任务的规则
定时任务,注意的是 ,几号,和星期几不得共用
案例
1.每分钟,将一句话,追加写入到一个文件中
第一步:crontab -e #打开配置文件
写入如下内容,用的是vim编辑器命令
* * * * * /usr/bin/echo "有人问王思聪,钱是万能的吗?王思聪答:钱是万达的" >> /tmp/wsc.txt
2.检查定时任务
crontab -l
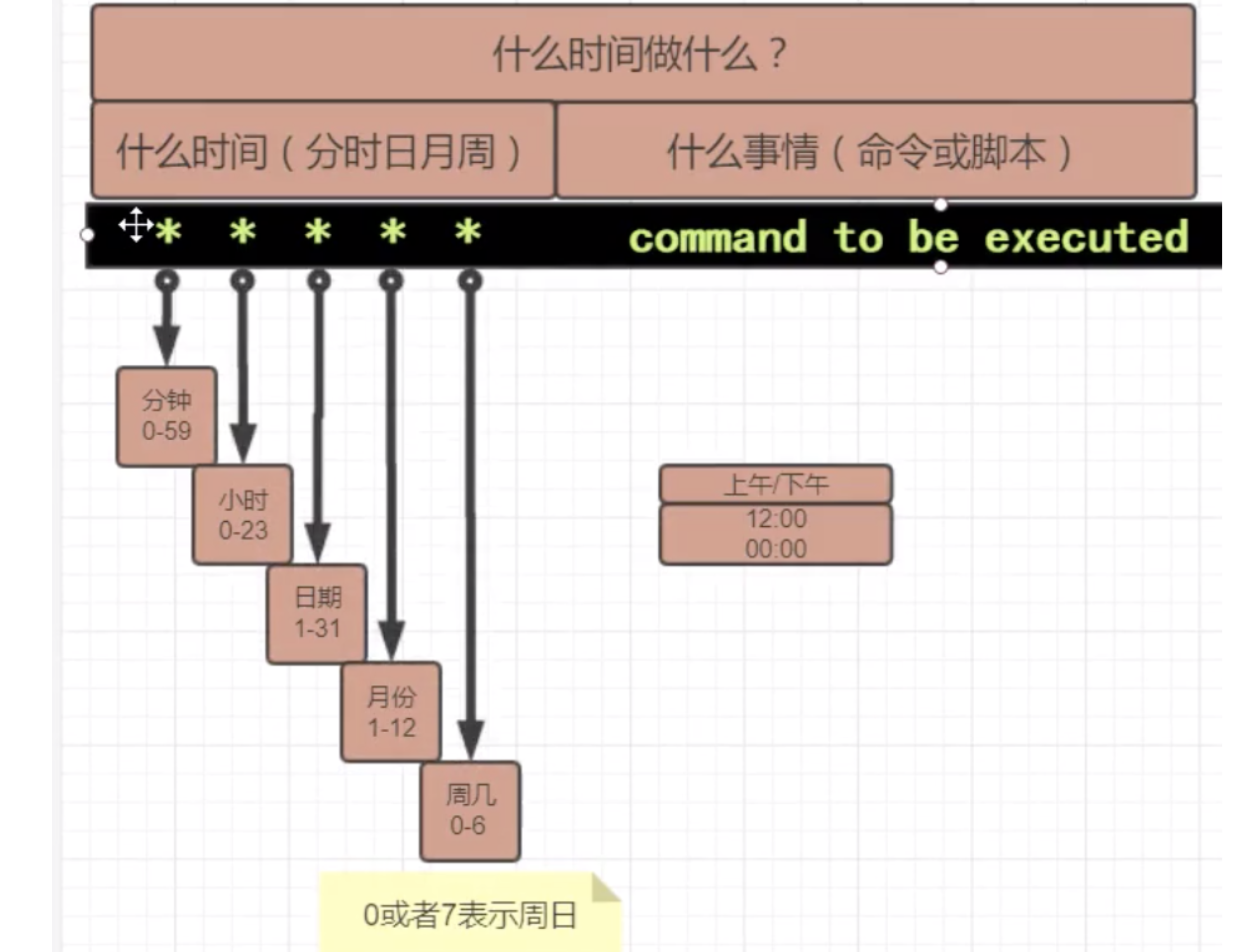
定时任务的语法规则
* * * * * 命令的绝对路径
分 时 日 月 周
3,5 * * * * #每小时的第3,第5分钟执行命令
15 2-5 * * * ¥每天的2点一刻,3点一刻,4点一刻,5点一刻,执行命令
每天8.30上班
30 08 * * * 去上班
每天12下班回家睡觉
00 00 * * * 回家睡觉
定时任务语法练习
#每分钟执行一次命令
* * * * * 命令的绝对路径
分 时 日 月 周
#每小时的3,15分钟执行命令
* * * * * 命令的绝对路径
分 时 日 月 周
3,15 * * * * 命令
#在上午8-11点的第3和第15分钟执行
* * * * * 命令的绝对路径
分 时 日 月 周
3,15 8-11 * * *
#每晚9:30执行命令
* * * * * 命令的绝对路径
分 时 日 月 周
30 21 * * *
#每周六、日的下午1:30执行命令
* * * * * 命令的绝对路径
分 时 日 月 周
30 13 * * 6,7
#每周一到周五的凌晨1点,清空/tmp目录的所有文件,注意执行的命令请用绝对路径,否则会执行失败
* * * * * 命令的绝对路径
分 时 日 月 周
0 1 * * 1-5 /usr/bin/rm -rf /tmp/*
#每晚的零点重启nginx
0 0 * * * /usr/bin/systemctl restart nginx
#每月的1,10,22日的4:45重启nginx
* * * * *
分 时 日 月 周
45 4 1,10,22 * * /usr/bin/systemctl restart nginx
#每个星期一的上午8点到11点的第3到15分钟执行命令
* * * * *
分 时 日 月 周
3-15 8-11 * * 1 命令绝对路径
记住一句话,服务器上操作,用绝对路径,基本不会出错了,除非手误,单词写错了。。。。
能用绝对路径,别用相对路径!
休息一下,4点来,配置好yum环境
linux软件包管理
windows的软件管理,安装文件的后缀 *.exe
macos的应用程序安装 后缀 *.dmg
linux的二进制软件包 都是 *.rpm 格式的
软件的依赖关系
pip install flask #仅仅就安装了flask模块吗?肯定不是,会安装一堆依赖的模块,比如jinja2等模块
那么在linux平台,一个软件想要正确的运行,也得解决系统的开环库环境,解决依赖关系
linux平台的软件安装形式,有3个
- 源代码编译安装,此方式较为麻烦,但是可以自由选择软件的版本(因为是去官网下载最新版本代码),也可以扩展第三方额外的功能(五颗星)
- 扩展第三方功能
- 指定软件安装目录
- rpm包手动安装,此方式拒绝,需要手动解决依赖关系,贼恶心(两颗星)
- yum自动化安装软件,需要配置好yum源,能够自动搜索依赖关系,下载,安装,处理依赖关系(五颗星)
- 不好的地方在于,yum源仓库的软件,版本可能较低
- 无法指定安装路径,机器数量较多的时候,不容易控制
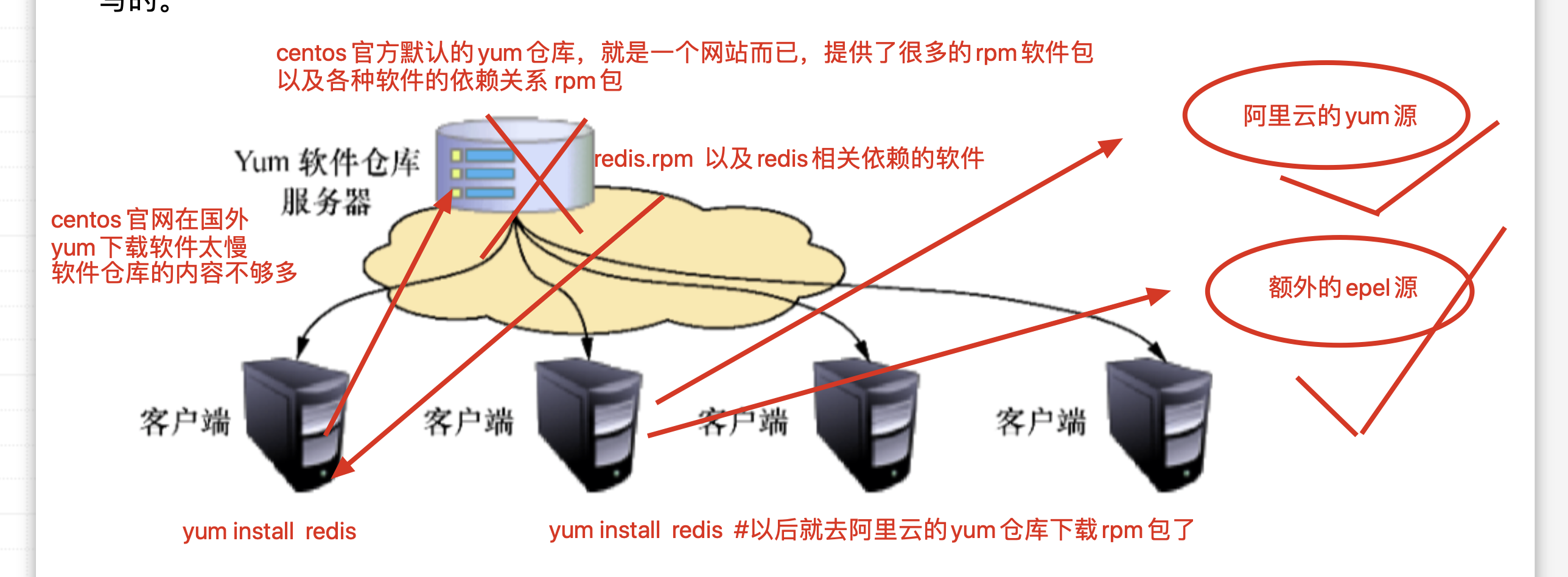
更换yum源
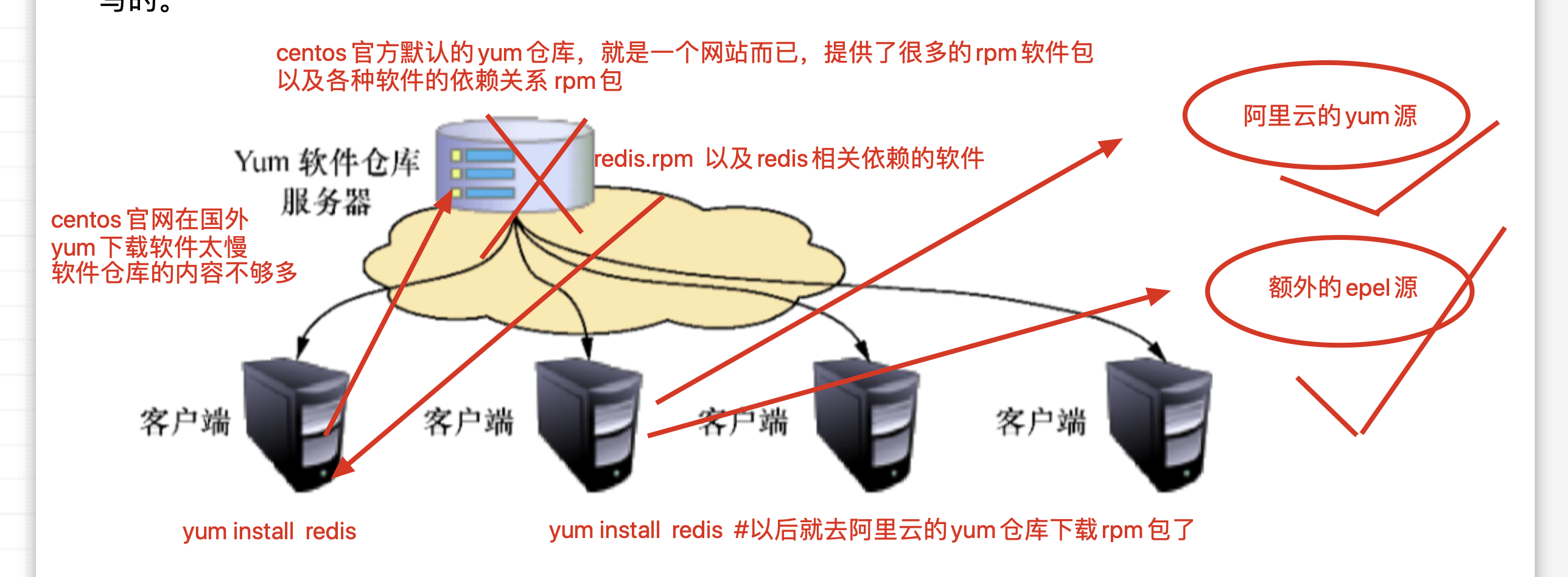
配置笔记
yum源的默认仓库文件夹是 /etc/yum.repos.d/,只有在这个目录第一层的*.repo结尾的文件,才会被yum读取
1.下载wget命令
yum install wget -y #wget命令就是在线下载一个url的静态资源
2.备份旧的yum仓库源
cd /etc/yum.repos.d
mkdir repobak
mv *.repo repobak #备份repo文件
3.下载新的阿里的yum源仓库,阿里的开源镜像站https://developer.aliyun.com/mirror/
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
4.继续下载第二个仓库 epel仓库
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
5.此时已经配置完毕,2个新的yum仓库,可以自由的嗨皮,下载软件了
[root@s25linux yum.repos.d]# ls
CentOS-Base.repo epel.repo repobak
6.下载一个redis玩一玩
[root@s25linux yum.repos.d]# yum install redis -y #就能够自动的下载redis,且安装redis
7.此时可以启动redis软件了,通过yum安装的redis,这么启动
systemctl start redis
systemctl enable redis #设置redis开机自启
systemctl disable redis #禁止redis开机自启
8.使用redis的客户端命令,连接redis数据库
[root@s25linux yum.repos.d]# redis-cli
127.0.0.1:6379> ping
PONG
9.用yum安装mysql服务且启动,在centos7系列系统上,mysql以及更名了,叫做mariadb数据库
yum install mariadb-server mariadb -y #安装2个有关mariadb的软件包
systemctl start mariadb #启动mysql数据库服务
mysql -uroot -p #初次进入不用密码,直接回车进入数据库
Linux编译python3开发环境
发博客,尝试是否能照着博客,搭建出python3的开发环境
https://www.cnblogs.com/pyyu/p/7402145.html
编译安装python3的步骤
编译安装python3的步骤
1.很重要,必须执行此操作,安装好编译环境,c语言也是编译后运行,需要gcc编译器golang,对代码先编译,再运行,python是直接运行
yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel -y
2.获取python的源代码,下载且安装,下载源代码包的形式,自由选择
用windows的迅雷极速下载,下载完了之后,发送给linux机器即可
mac的同学,可以用scp或者等传输工具
windows的同学可以用lrzsz(yum install lrzsz -y ),xftp(自行去网站下载,支持断点续传,大文件传输)等文件传输工具
wget https://www.python.org/ftp/python/3.6.9/Python-3.6.9.tgz
3.下载完源代码包之后,进行解压缩
tar -zxvf Python-3.6.9.tgz
4.解压缩完毕之后,生成了python369的源代码目录,进入源代码目录准备开始编译
cd Python-3.6.9
5.此时准备编译三部曲 ,编译的第一曲:指定python3的安装路径,以及对系统的开发环境监测,使用如下命令
#命令解释
# configure 是一个脚本文件,用于告诉gcc编译器,python3即将安装到哪里,以及对基础的开发环境检查,检查openssl,检查sqllite,等等
# 编译第一曲,结束后,主要是生成makefile,用于编译的
[root@s25linux Python-3.6.9]# ./configure --prefix=/opt/python369/
#编译第二曲:开始进行软件编译
直接输入 make指令即可
#编译第三曲:编译安装,生成python3的可执行程序,也就是生成/opt/python369/
make install
#编译的第二曲,和第三曲,可以简写成 make && make install #代表make成功之后,继续make install
6.等待出现如下结果,表示python3编译安装结束了
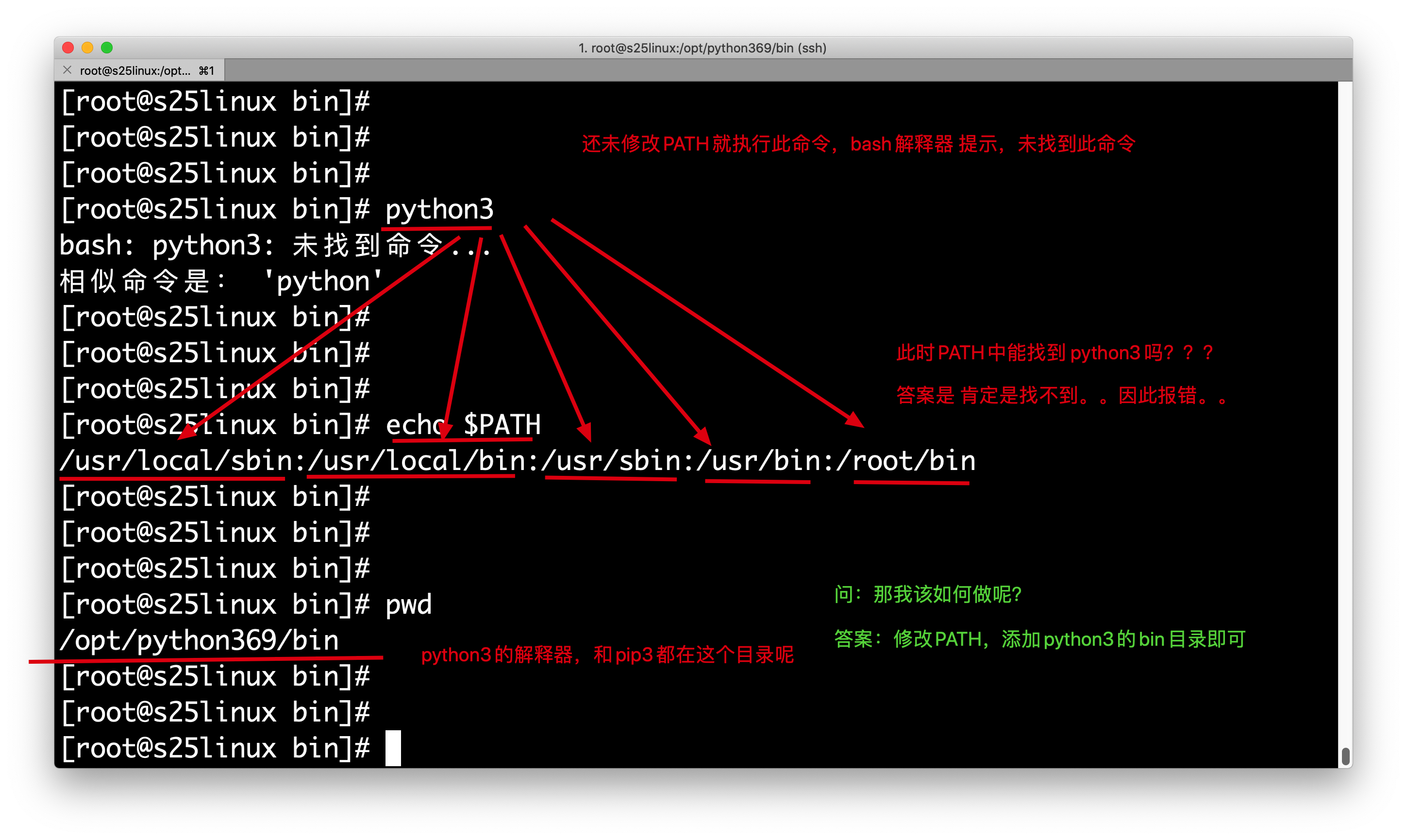
Successfully installed pip-18.1 setuptools-40.6.2
7.此时可以去检查python3的可执行程序目录
[root@s25linux bin]# pwd
/opt/python369/bin
8.配置PATH环境变量 ,永久修改PATH,添加Python3的bin目录放入PATH开头位置
vim /etc/profile
写入如下内容
PATH="/opt/python369/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:"
9.手动读取/etc/profile,加载文件中的所有变量
source /etc/profile
10.检查python3的目录,以及pip3的绝对路径
[root@s25linux bin]# which pip3
/opt/python369/bin/pip3
[root@s25linux bin]# which python3
/opt/python369/bin/python3

window上安装lol的过程
1.下载lol可执行安装文件 lol.ext
2.双击安装 ,首次应该是指定lol的安装位置
3.下一步开始安装,lol会检查系统的微软的基础游戏运行组件,如果缺少某组件,游戏会安装失败(缺少什么就安装什么即可),如果微软的开发环境正常,则正常安装
4.直到游戏安装完毕,生成可执行的游戏执行程序
5.进入游戏安装目录,开始使用
linux平台安装软件,也是这个过程,只不过用命令行代替了点点的操作
创建django项目,linux运行django
注意你的python3版本,和django的版本,是否合适!!
python3.6.9
django选择用1.11.25
1.安装django模块
pip3 install -i https://pypi.douban.com/simple django==1.11.25
#检查一下pip3的模块信息
pip3 list
2.升级pip3工具
pip3 install -i https://pypi.douban.com/simple --upgrade pip
3.在linux平台,使用命令创建django项目了
django-admin startproject dj1
4.创建一个app01
[root@s25linux dj1]# django-admin startapp app01
5.编写一个视图函数,hello视图,修改app01,【访问hello视图,返回字符串,s25期的靓仔们很强】
5.1 修改django的settings.py ,注册app01 ,修改如下
#并且修改允许访问的主机列表
# 默认只允许 本地 127.0.0.1访问
# 启动在了linux的机器上 ,如果不修改windows无法访问
# 写一个 * 表示允许所有的主机访问
ALLOWED_HOSTS = ["*"]
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01',
]
5.2 先修改django的 urls.py
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^hello/', views.hello),
]
5.3 编写django的app01.views,添加如下代码
from django.shortcuts import render,HttpResponse
def hello(requests):
return HttpResponse("s25期的靓仔们很强")
6. 进行数据库迁移
[root@s25linux dj1]# python3 manage.py migrate
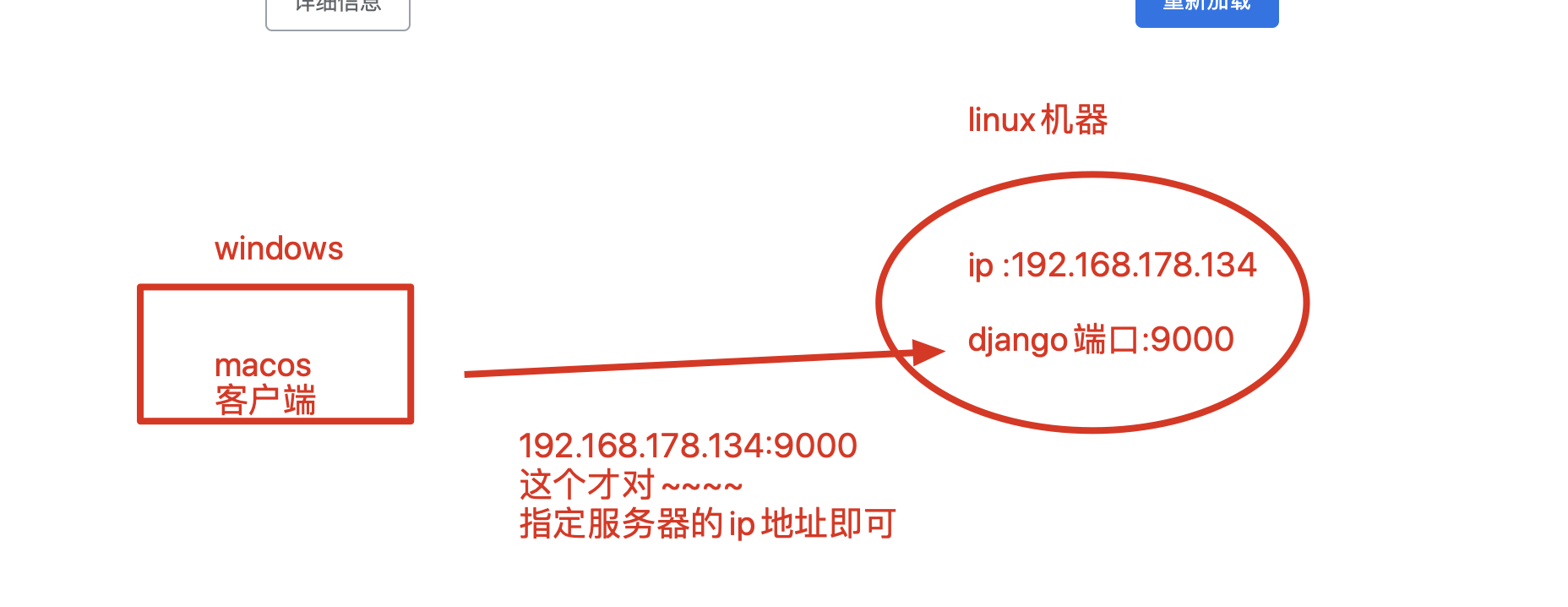
6.1.指定ip和端口,启动django
[root@s25linux mysite]# python3 manage.py runserver 0.0.0.0:9000
7.如何访问django项目?
访问linux的ip地址+django的端口
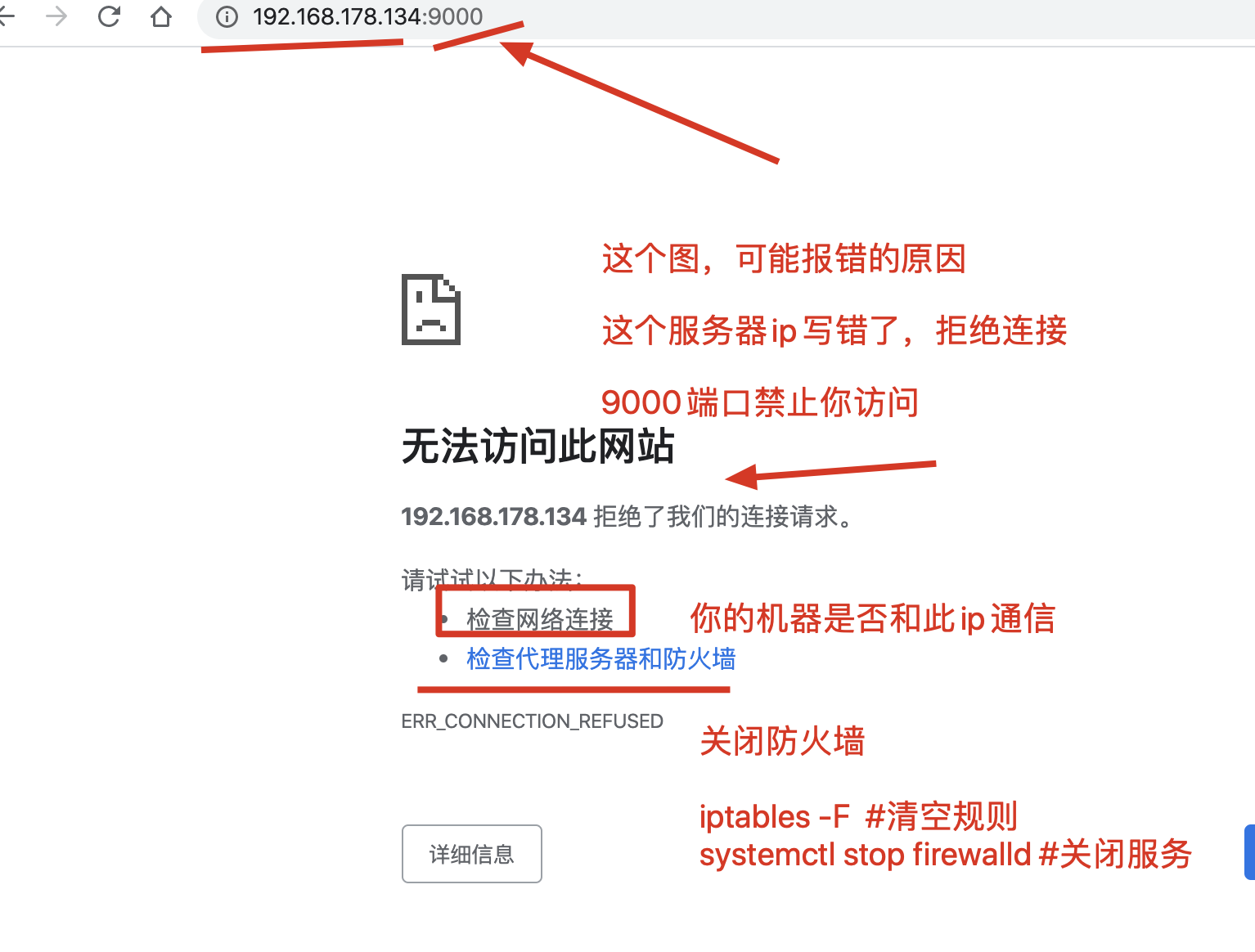
8.出现无法访问的问题,要根据报错去思考,到底是什么问题
网站直接是白屏,白花花什么都看不见,
virtualenv虚拟环境工具
需要用虚拟环境的背景
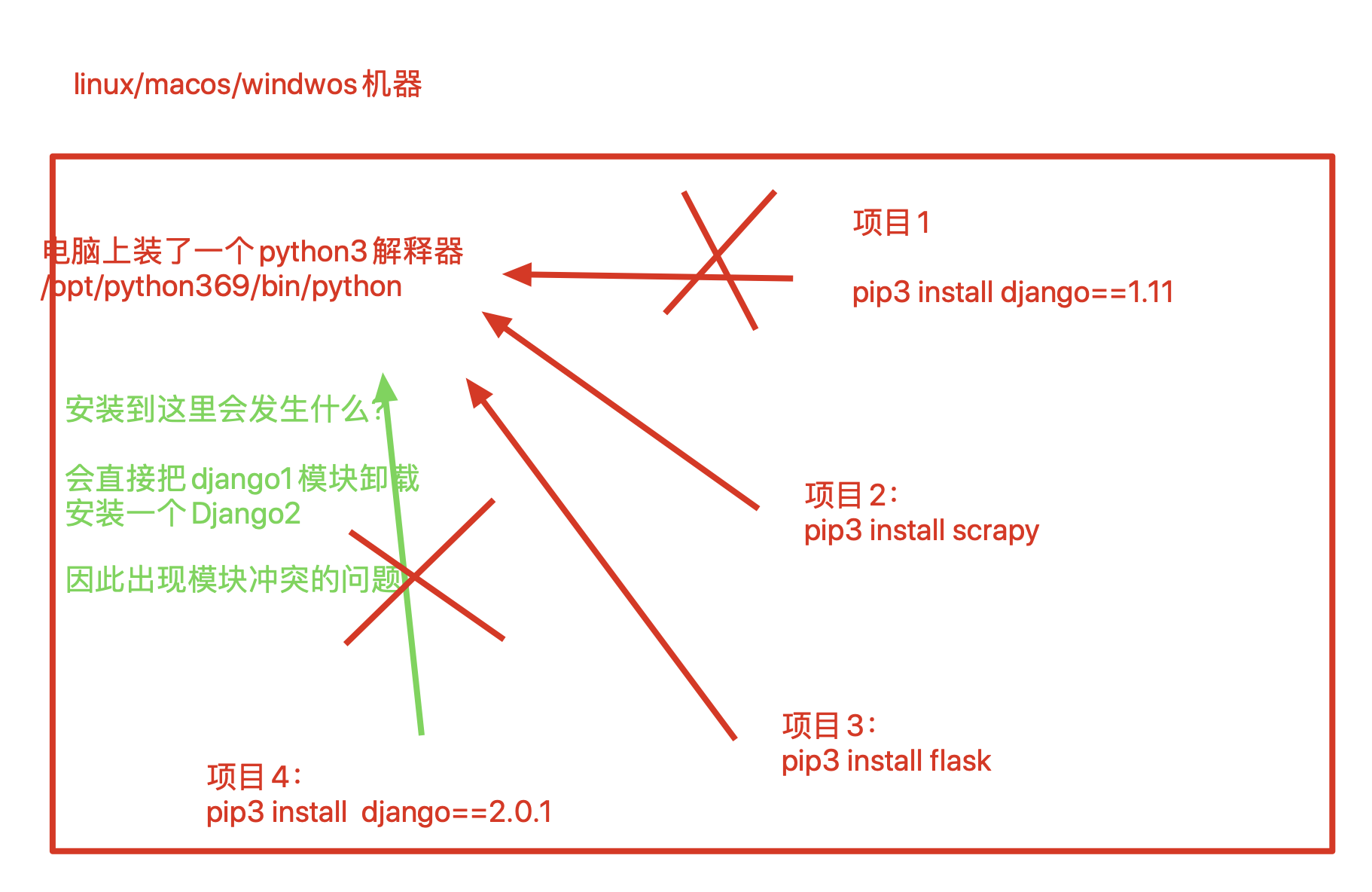
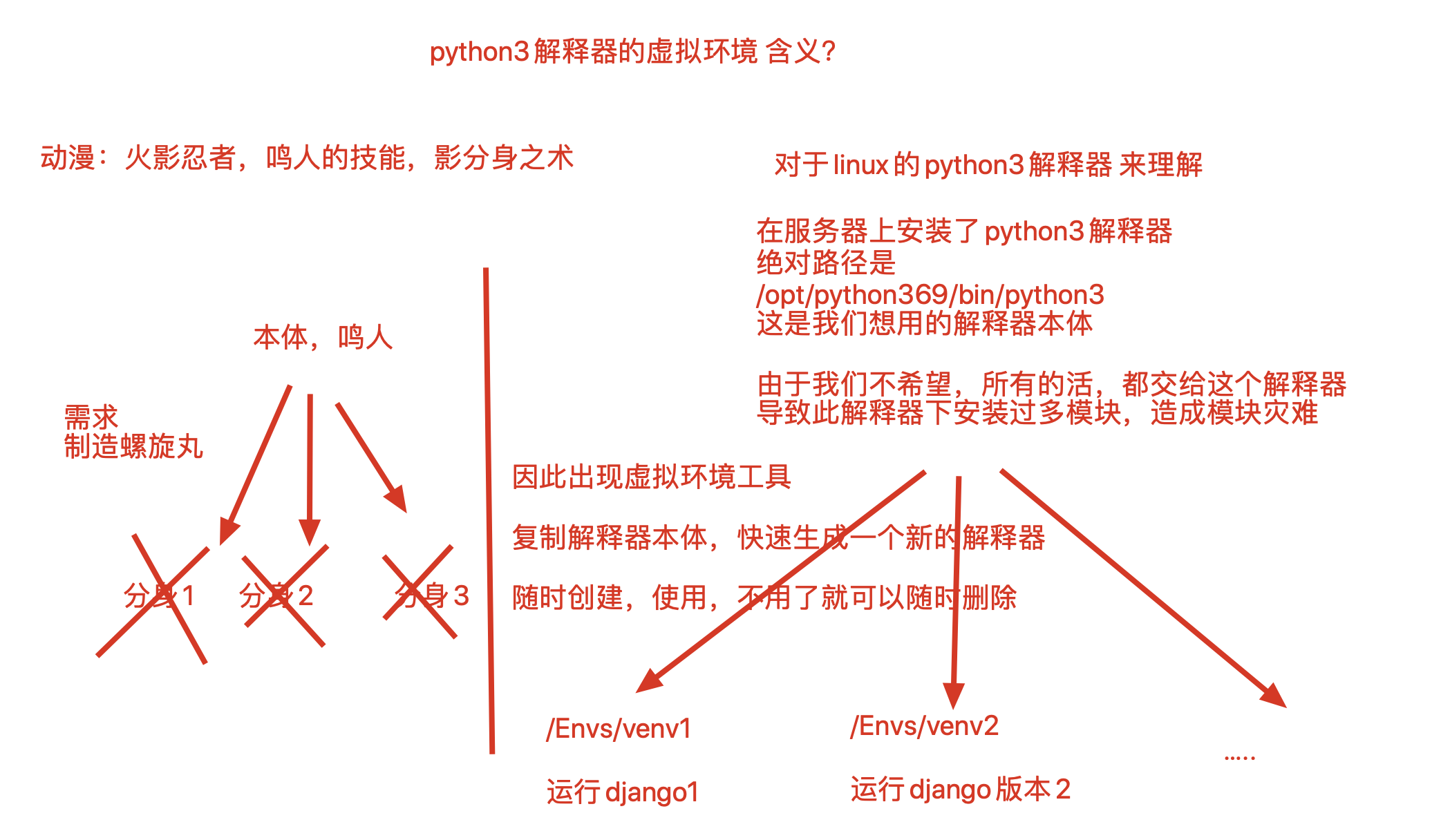
virtualenv 可以在系统中建立多个不同并且相互不干扰的虚拟环境。
python3的虚拟环境工具配置
1.下载虚拟环境工具
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple virtualenv
2.通过命令行创建虚拟环境
#pip3安装的模块会放在这里
[root@s25linux ~]# find /opt/python369/ -name site-packages
/opt/python369/lib/python3.6/site-packages
# --python=python3 指定venv虚拟解释器,以哪个解释器为本体
# 这个命令如果你用相对路径,就得注意你在哪敲打的此命令
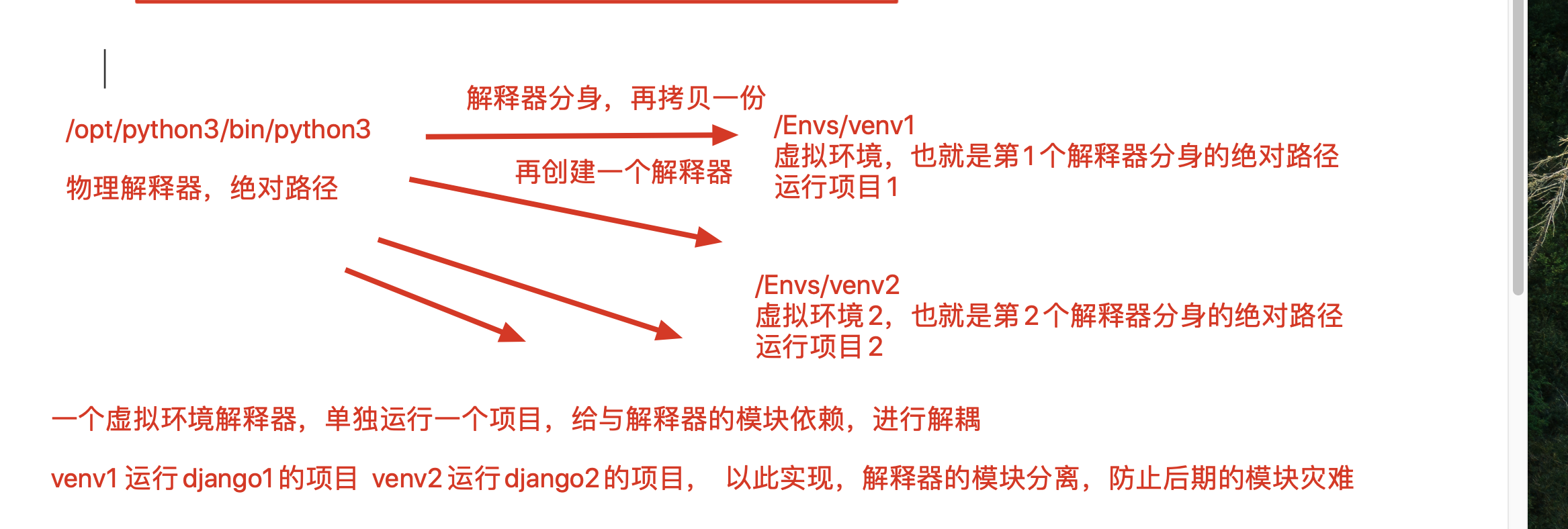
[root@s25linux opt]# virtualenv --python=python3 venv1
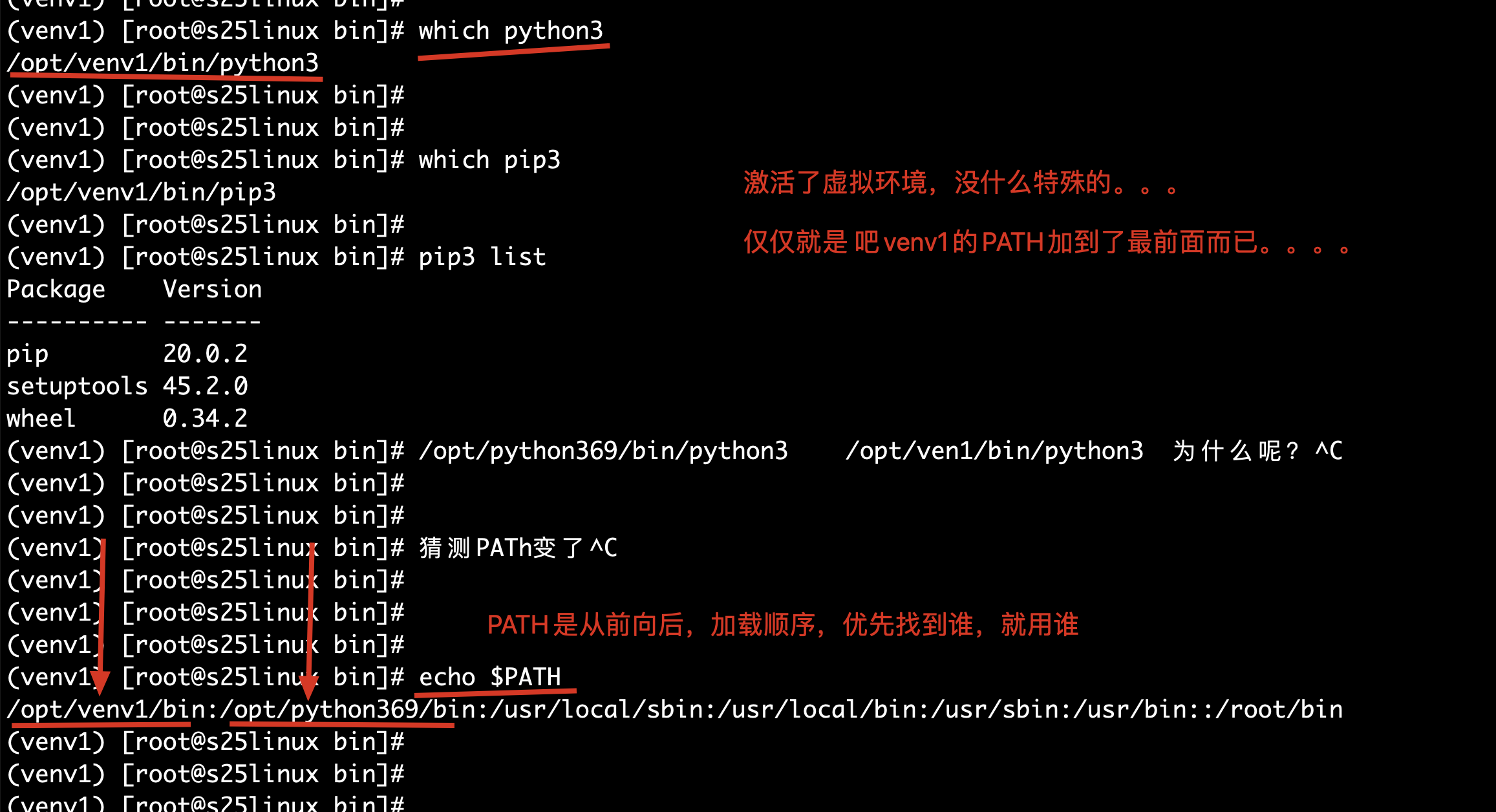
3.创建好venv1之后,需要激活方可使用,这个激活其实就是在修改PATH而已
[root@s25linux bin]# source /opt/venv1/bin/activate
(venv1) [root@s25linux bin]#
4.明确虚拟环境下venv1的解释器是干净隔离的
(venv1) [root@s25linux bin]# which python3
/opt/venv1/bin/python3
(venv1) [root@s25linux bin]#
(venv1) [root@s25linux bin]#
(venv1) [root@s25linux bin]# which pip3
/opt/venv1/bin/pip3
(venv1) [root@s25linux bin]#
(venv1) [root@s25linux bin]# pip3 list
Package Version
---------- -------
pip 20.0.2
setuptools 45.2.0
wheel 0.34.2
5.在venv1中安装django1
(venv1) [root@s25linux opt]# pip3 install -i https://pypi.douban.com/simple django==1.11.9
(venv1) [root@s25linux opt]# django-admin startproject venv1_dj119
6.再开一个ssh窗口,再创建venv2,用于运行django2 版本
virtualenv --python=python3 venv2
激活虚拟环境venv2
[root@s25linux opt]# source /opt/venv2/bin/activate
创建django版本2的项目
pip3 install -i https://pypi.douban.com/simple django==2.0.1
创建diango2项目
django-admin startproject venv2_dj2
7.分别启动2个版本的django,浏览器访问效果
8.deactivate #直接执行此命令,退出虚拟环境,系统会自动删除venv的PATH,也就表示退出了
激活虚拟环境的原理图
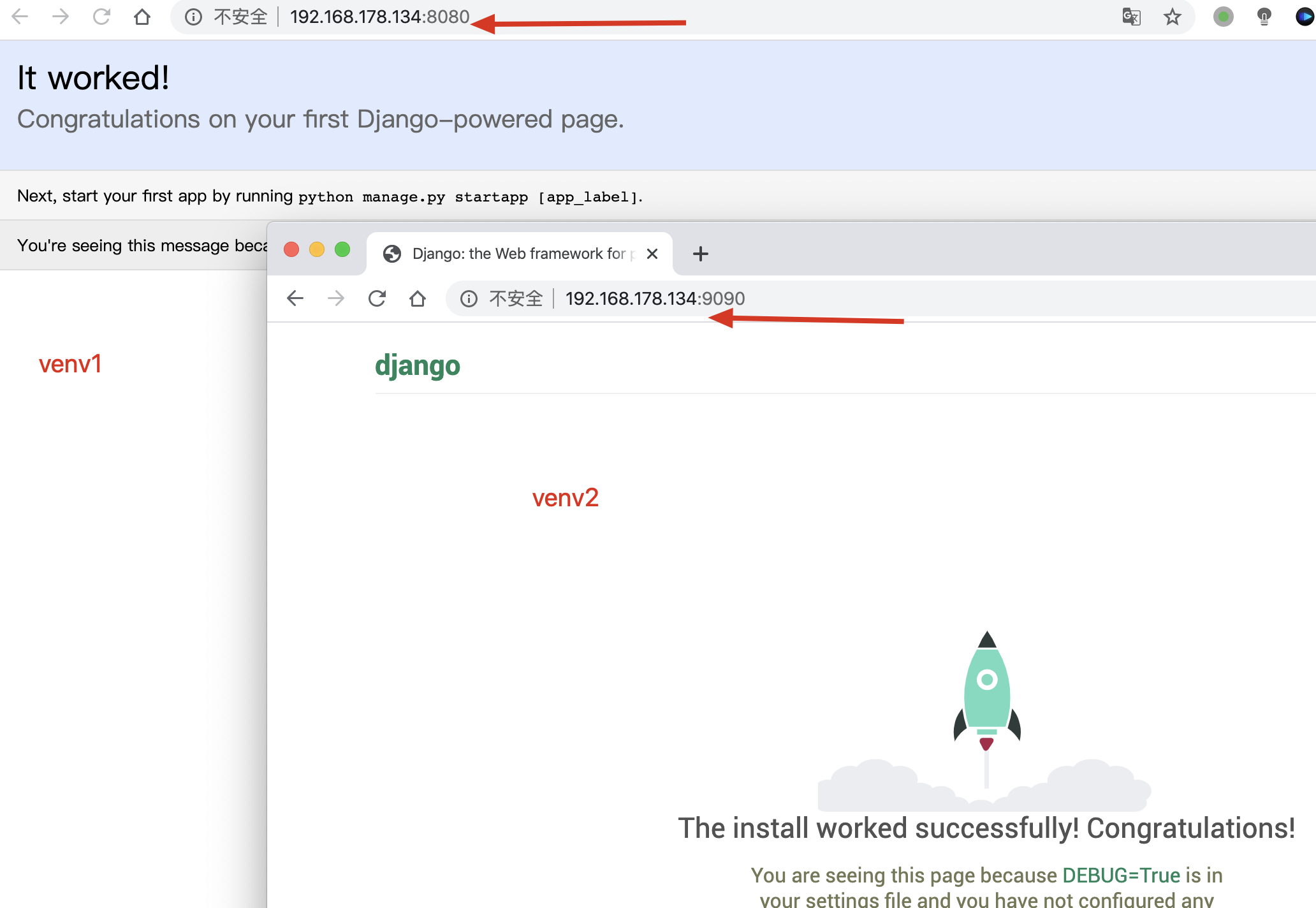
利用了虚拟环境,可以分别运行多个干净、隔离的python web环境
保证开发环境,生产环境python模块一致性
软件开发的环境
小公司,服务器环境可能没那么严格(本地开发人员+测试环境+线上环境)
大公司,(本地环境+测试环境+预生产环境+线上环境)
Python web开发组
-
开发环境(windows,macOS,ubuntu,本地开发代码的一个环境),装python3 pip3项目依赖的模块
- python3环境
- mysql环境
- redis环境
- vue
- nginx
-
测试服务器,代码测试bug,以上的环境,还得再搭一遍,测试服务器才能运行项目
-
线上服务器,还得环境搭建一遍,,,,很难受。。
如何解决环境问题?
- 虚拟机的模板克隆,打包好一个基础开发环境,克隆多份,生产多个部署环境
- 利用docker容器技术的,一个镜像打包技术
在这里,是看一下
在windows开发一个项目,pip3 安装了很多的模块,最终该项目才可以运行,比如crm代码
代码上传到一个新的服务器,是一个空的环境,还得在部署一遍,比如crm代码
土办法:运行代码,查看报错,一个一个模块单独去安装解决
不那么土的办法:
pip3 freeze > requirements.txt #把你当前解释器所有用到的模块,信息导出到一个文件中
1.在windows的cmd命令行中,通过此命令导出模块信息
pip3 freeze > requirements.txt
2.把此文件发送给linux机器,或者直接拷贝其内容,也可以
在linux机器上,安装此文件即可,自动读取文件每一行的模块信息,自动安装
pip3 install -i https://pypi.douban.com/simple -r requirements.txt
本质用法:这个命令其实就是,将一个解释器的模块信息导出,丢给其他人去安装
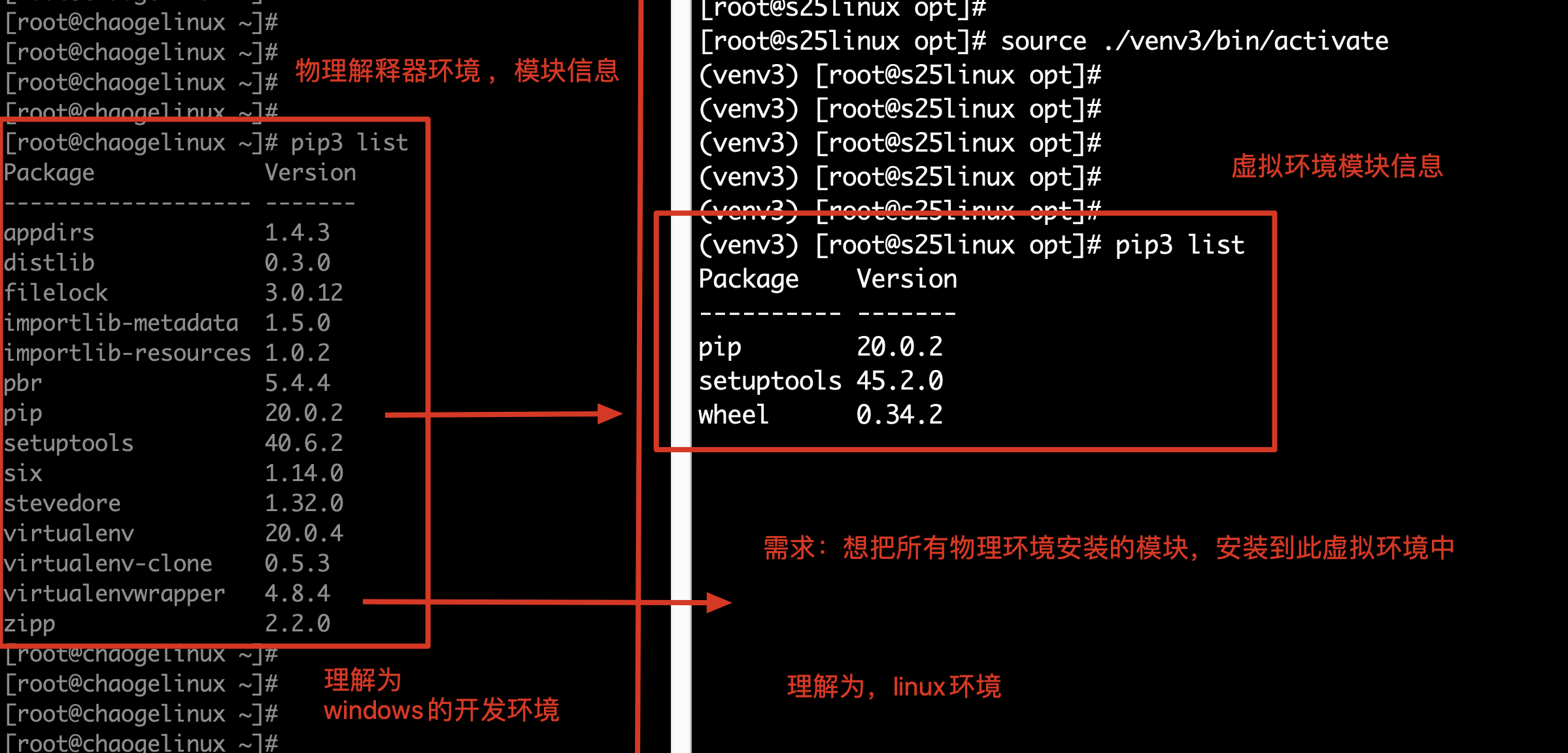
学习阶段,模拟使用
1.在物理解释器下,安装各种模块
2.在虚拟环境下,安装此模块文件
linux启动crm项目
1.准备好crm代码,讲师的,或是自己所写的,上传至linux服务器中
lrzsz
xftp
scp
上传至服务器的代码是tf_crm.zip ,zip用unzip命令解压缩
unzip tf_crm.zip
2.新建一个虚拟环境,用于运行crm
在项目下,生成虚拟环境,便于管理此文件夹
[root@s25linux tf_crm]# virtualenv --python=python venv_crm
source venv_crm/bin/activate
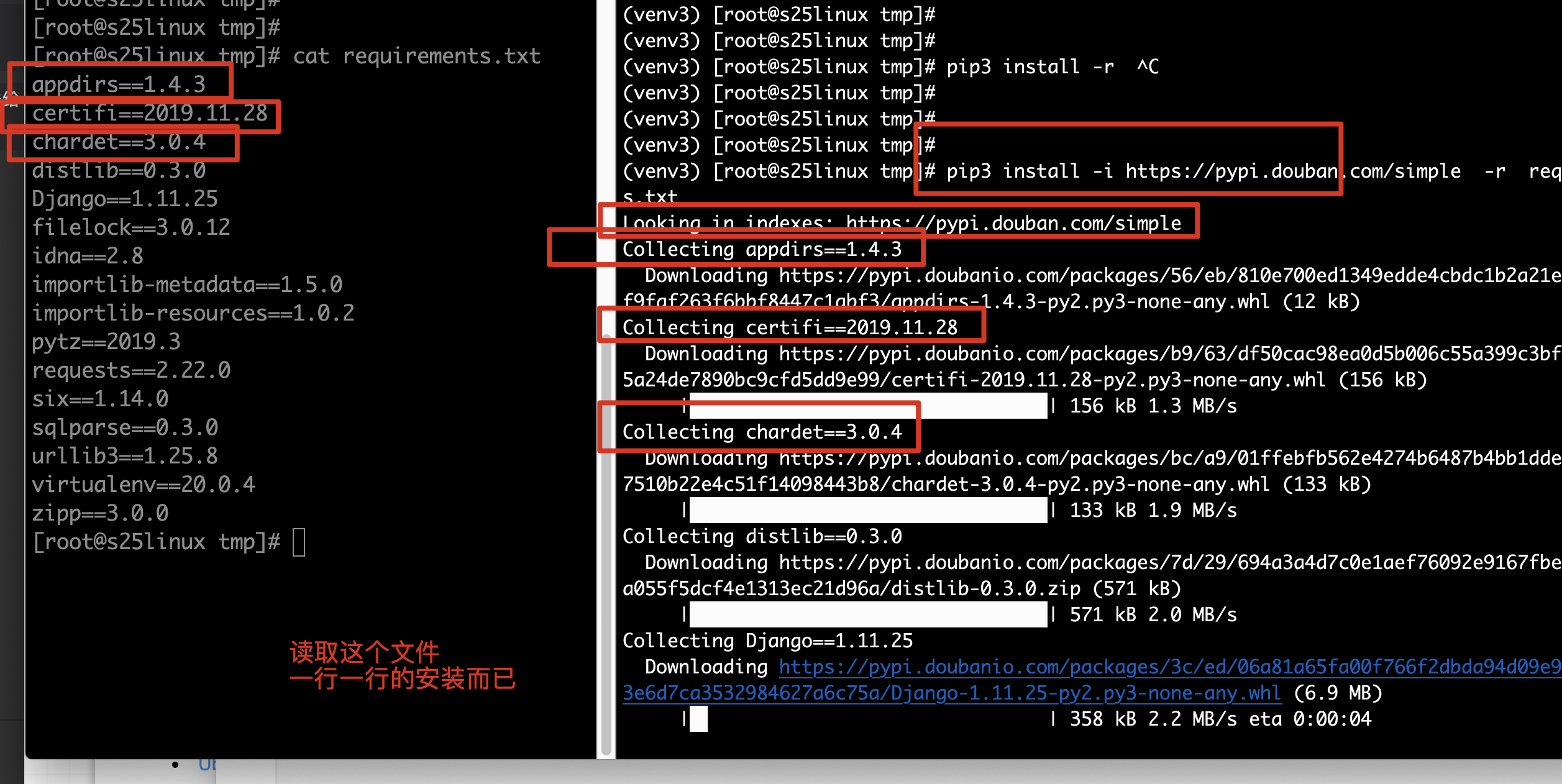
3.立即解决crm运行所需的模块依赖
pip3 freeze > requirements.txt
上传至linux服务器
在venv_crm虚拟环境中,安装此文件即可
如果没有此模块依赖文件,那么就手动解决吧,。。。。
此时你要注意
python3 manage.py runserver 这个命令,并不是让你启动django项目的!!!
因为此命令,调用的是python 内置的wsgiref单机socket模块,性能低下,单进程单线程。。。
#手动安装所有模块
pip3 install -i https://pypi.douban.com/simple django==1.11.25
(venv_crm) [root@s25linux tf_crm]# pip3 install -i https://pypi.douban.com/simple pymysql
(venv_crm) [root@s25linux tf_crm]# pip3 install -i https://pypi.douban.com/simple django-multiselectfield
4.缺少mysql,因此需要安装mariadb,且启动
(venv_crm) [root@s25linux tf_crm]# yum install mariadb-server mariadb -y
是否激活虚拟环境,会影响yum工具吗?
不会,因为激活虚拟环境,只是添加了一个PATH而已,只会影响python相关的操作,不会影响到其他的linux命令....
无论是否激活虚拟环境,也不会影响yum等等..
5.启动mariadb数据库
(venv_crm) [root@s25linux tf_crm]# systemctl start mariadb
6.注意可能需要修改django的settings.py有关数据库连接的账密信息等
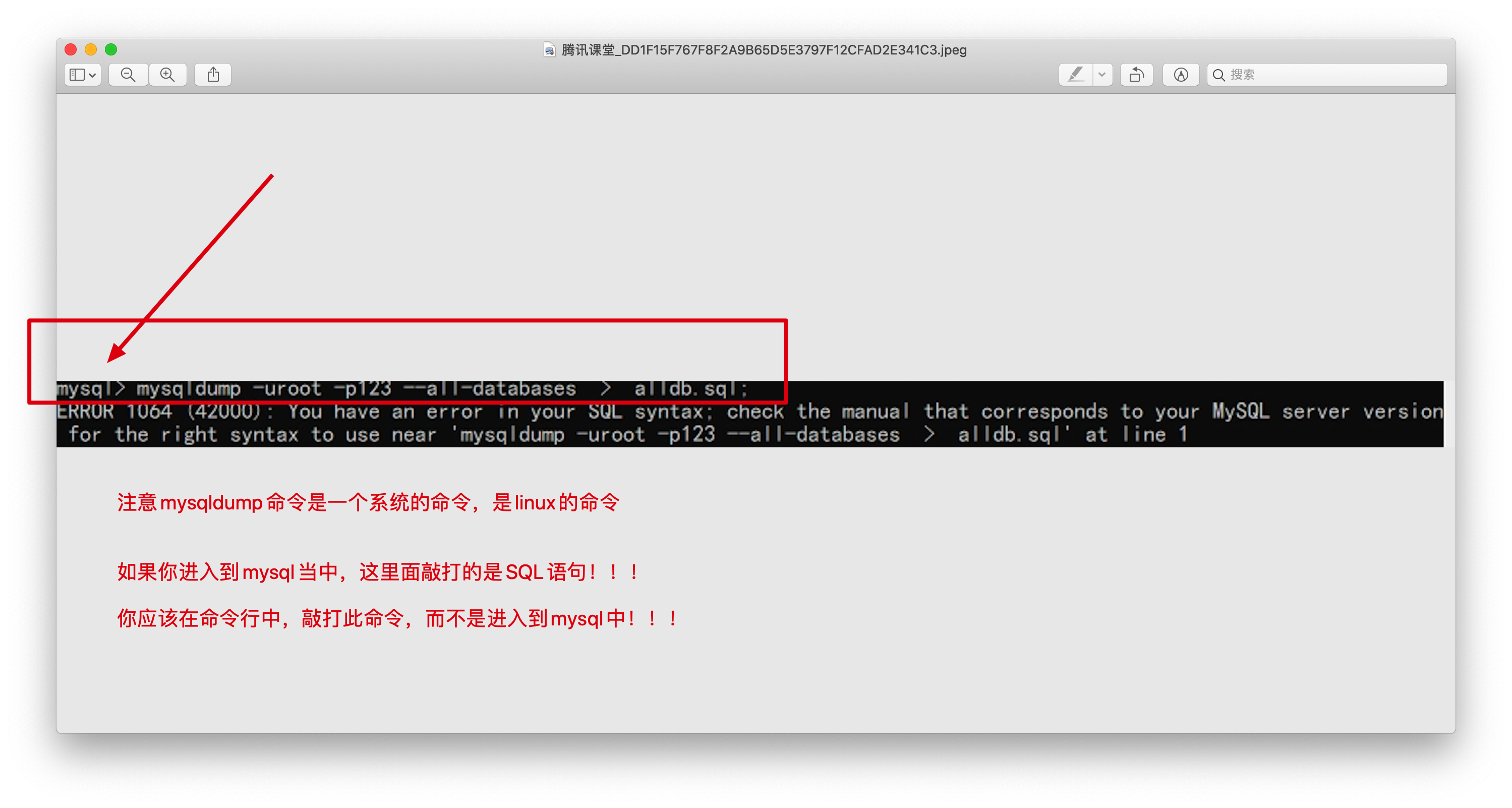
7.还要注意,由于数据库是空的,还得进行数据库表的导入,导出本地数据库表,导出
# 参数--all-databases能够导出所有的数据库,表,也可以指定某一个数据库。表导出
大家使用此命令行就可以了!!!!导出所有的库表,然给交给linux导入
大家使用此命令行就可以了!!!!导出所有的库表,然给交给linux导入
大家使用此命令行就可以了!!!!导出所有的库表,然给交给linux导入
mysqldump -uroot -p --all-databases > alldb.sql
#冯浩敲打的命令,如下,指定数据库导出
# -d 参数是只导出表结构,不要表中的数据
mysqldump -uroot -p123 -d tf_crm > tf_crm.sql
8.发送此alldb.sql文件,给linux机器,再进行数据导入
就是将第七步的SQL文件,通过lrzsz、scp、xftp等方式,发送此文件,给linux
mysql -uroot -p < /opt/alldb.sql
9.此时再次尝试启动crm项目
(venv_crm) [root@s25linux tf_crm]# python3 manage.py runserver 0.0.0.0:9090
mysql导出数据的命令
数据库备份与恢复
mysqldump命令用于备份数据库数据
[root@master ~]# mysqldump -u root -p --all-databases > /tmp/db.dump
2.导出db1、db2两个数据库的所有数据
mysqldump -uroot -proot --databases db1 db2 >/tmp/user.sql
部署步骤并不难,做好笔记,按照流水线来操作即可
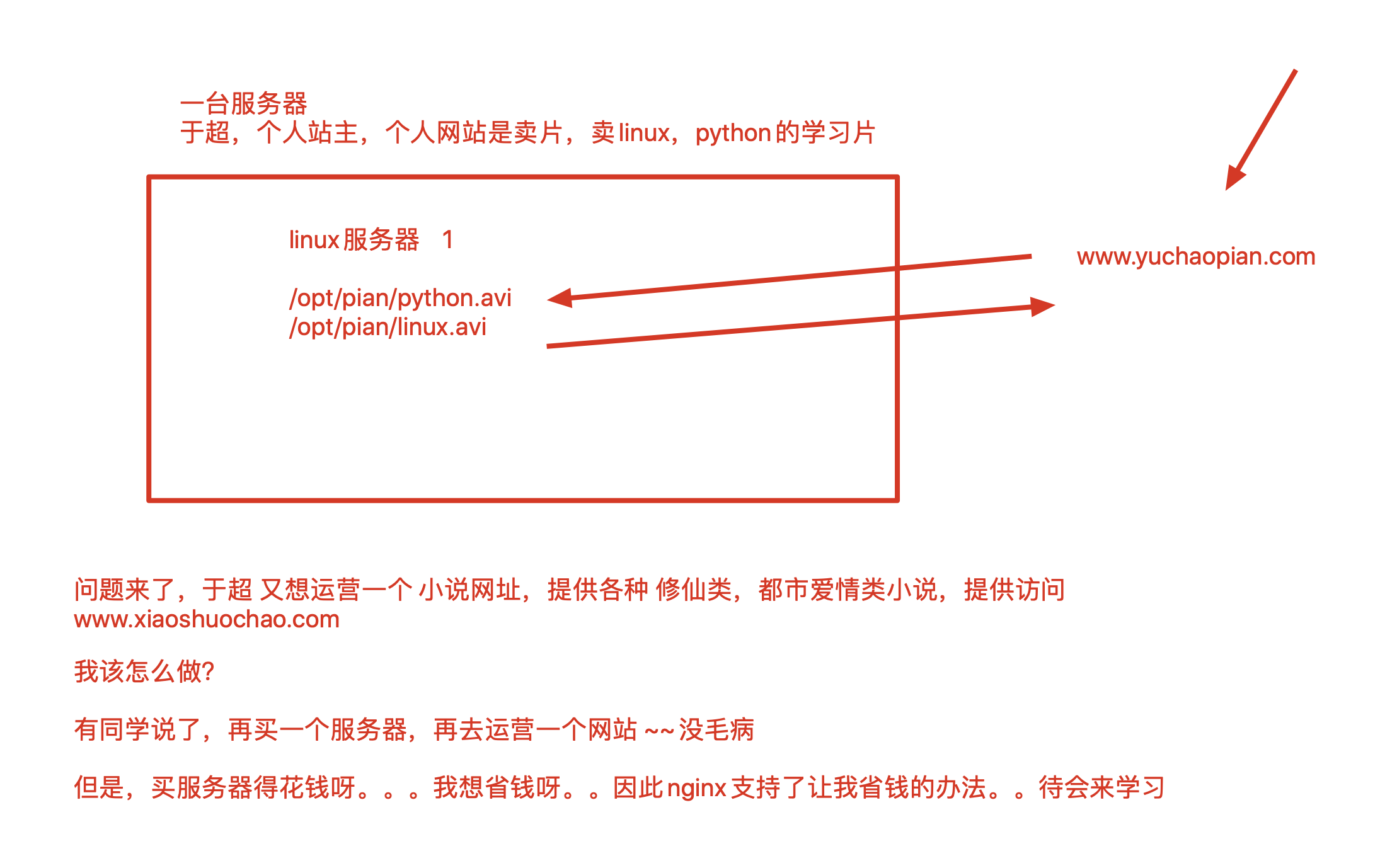
vue前后端分离的部署,难度会+1
virtualenvwrapper是吧,那个是virtualenv的升级版,用哪个都一样,都是创建多个虚拟环境
virtualenv不支持查看所有虚拟环境,virtualenvwrapper支持,是 lsvirtualenv命令
uwsgi启动python web
让你的django在linux上,支持并发形式启动,支持多进程,多线程,乃至于协程的一个C语言编写的高性能工具
1.安装uwsgi工具
pip3 install -i https://pypi.douban.com/simple uwsgi
2.编写uwsgi.ini配置文件,以多进程形式启动luffy_crm
cd /opt/luffy_crm 下创建 uwsgi.ini文件, touch uwsgi.ini #手动创建此uwsgi的配置文件,写入如下的内容参数,去启动crm
# 写入如下的功能性的参数配置,用于启动项目
# 这些部署的流程,是国外的uwsgi官网,给与的用法,我们照着用即可
# 注意要根据你自己的目录,修改如下的参数
[uwsgi]
# Django-related settings
# the base directory (full path)
# 1.填写crm项目的第一层绝对路径
chdir = /opt/luffy_crm
# Django's wsgi file
# 2.填写crm项目第二层的相对路径,找到第二层目录下的wsgi.py
# 这里填写的不是路径,是以上一个参数为相对,找到第二层项目目录下的wsgi.py文件
module = luffy_crm.wsgi
# the virtualenv (full path)
# 3.填写虚拟环境解释器的第一层工作目录
home = /opt/luffy_crm/venv_crm
# process-related settings
# master
master = true
# maximum number of worker processes
# 代表定义uwsgi运行的多进程数量,官网给出的优化建议是 2*cpu核数+1 ,单核的cpu填写几?
# 如果是单进程,十万个请求,都丢给一个进程去处理
# 4.分配3个工作进程,十万个请求,就分给了3个进程去分摊处理
processes = 3
# the socket (use the full path to be safe
# 这里的socket参数,是用于和nginx结合部署的unix-socket参数,这里临时先暂停使用
# socket = 0.0.0.0:8000
# 线上不会用http参数,因为对后端是不安全的,使用socket参数是安全的连接,用nginx反向代理去访问
# 后端程序是运行在防火墙内部,外网是无法直接访问的
# 临时使用http参数,便于我们用浏览器调试访问
http = 0.0.0.0:8000
# ... with appropriate permissions - may be needed
# chmod-socket = 664
# clear environment on exit
vacuum = true
3.此时可以用命令,基于uwsgi协议的一个高性能web后端启动了
uwsgi --ini ./uwsgi.ini #指定配置文件启动后端
4.此时crm项目,已经用uwsgi支持了3个进程的启动了,但是由于uwsgi对静态文件的解析性能很弱,线上是丢给nginx去处理的
5.未完待续。。。留在部署时候再讲
supervisor工具
目前你所学的linux技能,对crm的进程进行管理,启停
ps -ef | grep python3
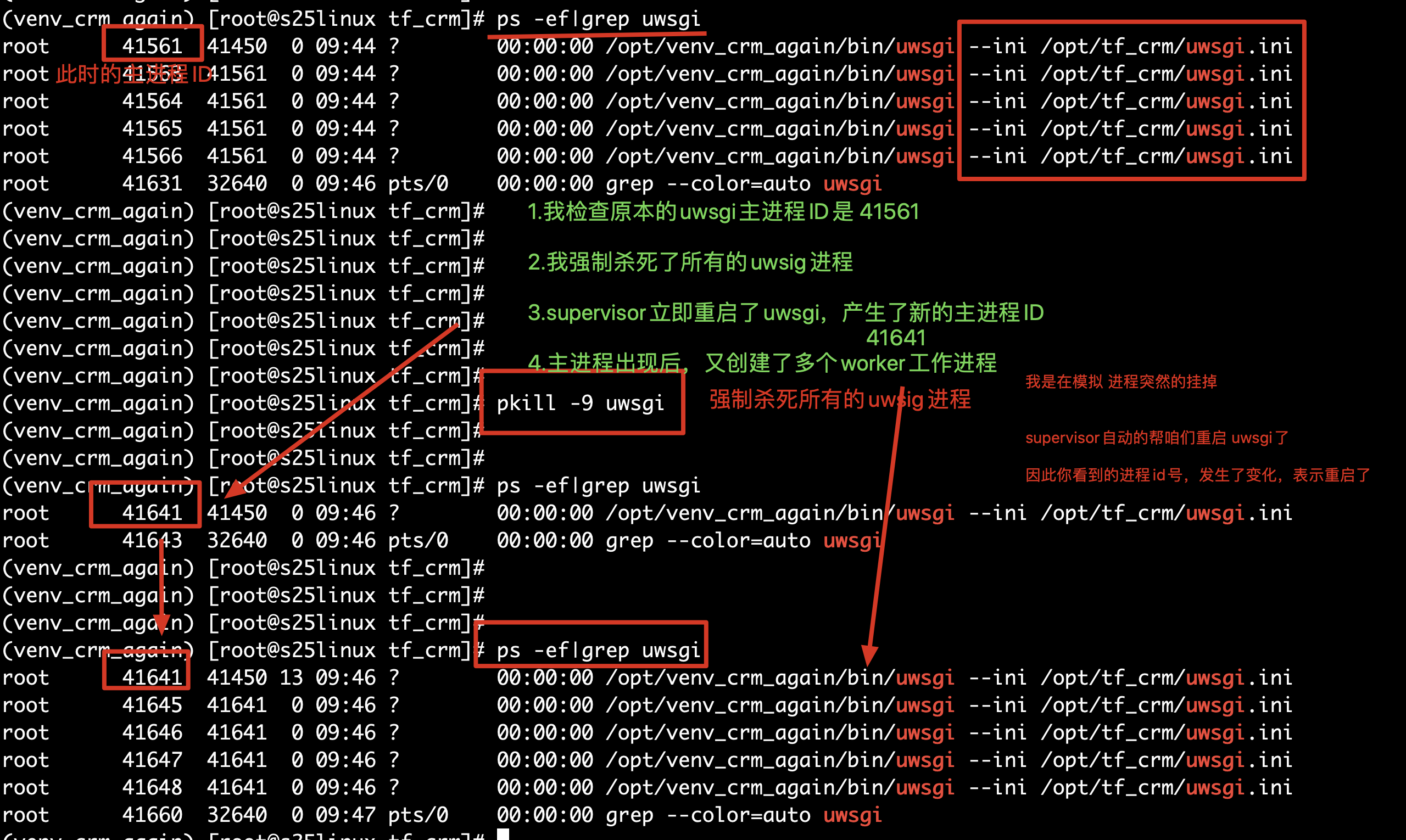
ps -ef | grep uwsgi 检查uwsgi的进程,确认django是否存活,假如检测到pid是 5999
停止uwsgi,kill -9 5999 杀死主进程
pkill -9 uwsgi 杀死uwsgi进程组
检测uwsgi如果挂掉之后,自动帮你重启
使用supervisor这个python开发的进程管理工具,用它启动uwsgi之后,uwsgi进程挂掉后,自动会再启动
比如,crm的部署技术栈
nginx+uwsgi+django+mysql ,我们可以手动的,单独启动每一个进程
还可以通过supervisor一键启动这四个进程,进行批量管理,批量启停 ,很好用
安装supervisor工具
1.使用yum命令即可直接安装
[root@s25linux ~]# yum install supervisor -y
2.生成supervisor的配置文件
[root@s25linux ~]# echo_supervisord_conf > /etc/supervisord.conf
3.修改supervisor的配置文件,添加管理crm的任务
vim /etc/supervisor.conf #再最底行,添加如下内容
#[program:xx]是被管理的进程配置参数,xx是进程的名称
[program:s25crm]
command=写入启动uwsgi的命令 ;supervisor其实就是在帮你执行命令而已!
autostart=true ; 在supervisord启动的时候也自动启动
startsecs=10 ; 启动10秒后没有异常退出,就表示进程正常启动了,默认为1秒
autorestart=true ; 程序退出后自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启
stopasgroup=true ;默认为false,进程被杀死时,是否向这个进程组发送stop信号,包括子进程
killasgroup=true ;默认为false,向进程组发送kill信号,包括子进程
master--工头进程,主人进程--突然工头挂了..
worker---主进程突然挂了,工作进程就变为了僵尸进程,
worker
worker
因此,杀死uwsgi,需要向这个进程组,发送终止信号,杀死一组进程
linux系统使用uwsgi部署crm(完整版)👍
1.编译安装好python3的开发环境
讲师机器环境是:/opt/python369/bin/python3
以及pip3的绝对路径:/opt/python369/bin/pip3
2.生成一个新的虚拟环境,去运行crm,以及uwsgi
pip3 install -i https://pypi.douban.com/simple virtualenv #安装虚拟环境工具
通过命令生成新的虚拟环境
virtualenv --python=python3 venv_crm_again
[root@s25linux opt]# source venv_crm_again/bin/activate
(venv_crm_again) [root@s25linux opt]# echo $PATH
/opt/venv_crm_again/bin:/opt/python369/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin::/root/bin
3.在虚拟环境下,安装,crm所需的模块信息
pip3 install -i https://pypi.douban.com/simple -r requirements.txt
#此模块依赖文件的信息,如下,大家也可以手动的复制粘贴,也可以~~~
(venv_crm_again) [root@s25linux tf_crm]# cat requirements.txt
Django==1.11.25
django-multiselectfield==0.1.11
PyMySQL==0.9.3
pytz==2019.3
uWSGI==2.0.18
4.模块依赖解决了,检查你是否需要修改crm项目的settings.py
修改如下参数ALLOWED_HOSTS = ["*"]
5.注意需要启动mysql,提前配置好yum源,阿里云的yum源,如果下载过慢,怎么办?
择优dns选择,不同的dns服务器,解析速度也有快慢之分,就好比移动,联通信号由快慢一样
可以在腾讯,阿里云,114的dns服务器之间做选择
dns劫持,dns被人劫持了,你访问baidu.com ,强制给你解析到某恶意网站的ip上,因此浏览器看到不一样的内容了
#填入2个阿里的dns服务器地址
vim /etc/resolv.conf
nameserver 223.5.5.5
nameserver 223.6.6.6
yum install mariadb-server mariadb -y
#启动mysql
systemctl start mariadb
systemctl status mariadb
#从windows中导出数据
mysqldump -uroot -p --database tf_crm > tf_crm.sql #这个命令是在cmd命令行敲的!!!!
#发送此sql文件,给linux,进行数据导入
mysql -uroot -p tf_crm < tf_crm.sql #数据导入的命令,注意,你linux的机器,得提前创建tf_crm库!!
6.尝试调试crm,是否能够运行
python3 manage.py runserver 0.0.0.0:7777 #可以查看到页面后,表示此项目可以用uwsgi部署了
7.下载安装uwsgi工具,写好uwsgi.ini配置文件
pip3 install -i https://pypi.douban.com/simple uwsgi -y
touch uwsgi.ini #写入如下内容
[uwsgi]
# Django-related settings
# the base directory (full path)
# 填写crm项目的第一层绝对路径
chdir = /opt/tf_crm/
# Django's wsgi file
# 填写crm项目第二层的相对路径,找到第二层目录下的wsgi.py
# 这里填写的不是路径,是以上一个参数为相对,找到第二层项目目录下的wsgi.py文件
module = tf_crm.wsgi
# the virtualenv (full path)
# 填写虚拟环境解释器的第一层工作目录
home = /opt/venv_crm_again
# process-related settings
# master
master = true
# maximum number of worker processes
# 代表定义uwsgi运行的多进程数量,官网给出的优化建议是 2*cpu核数+1 ,单核的cpu填写几?
# 如果是单进程,十万个请求,都丢给一个进程去处理
# 3个工作进程,十万个请求,就分给了3个进程去分摊处理
processes = 3
# the socket (use the full path to be safe
# 这里的socket参数,是用于和nginx结合部署的unix-socket参数,这里临时先暂停使用
# socket = 0.0.0.0:8000
# 线上不会用http参数,因为对后端是不安全的,使用socket参数是安全的连接,用nginx反向代理去访问
# 后端程序是运行在防火墙内部,外网是无法直接访问的
# 临时使用http参数,便于我们用浏览器调试访问
http = 0.0.0.0:8000
# ... with appropriate permissions - may be needed
# chmod-socket = 664
# clear environment on exit
vacuum = true

接着上面的笔记
8.uwsgi和uwsgi.ini都配置完毕之后,开始使用supervisor工具进行管理了
先明确,启动uwsgi的绝对路径命令是什么
8.1 找到uwsgi的绝对路径 /opt/venv_crm_again/bin/uwsgi
8.2 找到uwsgi.ini的绝对路径 /opt/tf_crm/uwsgi.ini
8.3 因此 启动 crm项目的 完整绝对路径命令是
/opt/venv_crm_again/bin/uwsgi --ini /opt/tf_crm/uwsgi.ini
9.修改supervisor的配置文件
vim /etc/supervisord.conf #写入如下
[program:s25crm]
command=/opt/venv_crm_again/bin/uwsgi --ini /opt/tf_crm/uwsgi.ini ;supervisor其实就是在帮你执行命令而已!
autostart=true ; 在supervisord启动的时候也自动启动
startsecs=10 ; 启动10秒后没有异常退出,就表示进程正常启动了,默认为1秒
autorestart=true ; 程序退出后自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启
stopasgroup=true ;默认为false,进程被杀死时,是否向这个进程组发送stop信号,包括子进程
killasgroup=true ;默认为false,向进程组发送kill信号,包括子进程
10.启动supervisor,默认就会直接启动uwsgi了
supervisord -c /etc/supervisord.conf #启动supervisor服务端,指定配置文件启动
启动完毕supervisor之后,检查进程信息
ps -ef|grep supervisor #检查supervisor是否存在了进程,是否启动
ps -ef|grep uwsgi #检查uwsgi是否启动
11.进度supervisor任务管理终端
看到如下的结果,表示你自定义的任务s25crm,也就是uwsgi进程,正确的启动了
supervisorctl -c /etc/supervisord.conf
(venv_crm_again) [root@s25linux tf_crm]# supervisorctl -c /etc/supervisord.conf
s25crm RUNNING pid 41451, uptime 0:01:34
supervisor>
12.看到了没有静态文件的 crm界面,就是正确的了
13.supervisorctl的管理命令
提供了如下命令
(venv_crm_again) [root@s25linux tf_crm]# supervisorctl -c /etc/supervisord.conf
s25crm RUNNING pid 41451, uptime 0:01:34
supervisor>
supervisor>start s25crm
supervisor>stop s25crm
supervisor>status
supervisor>start all
supervisor>stop all
14.uwsgi异常崩溃的话,supervisor会立即重启uwsgi
15.如果要运行多个 uwsgi项目,在supervisor中定义多个任务即可
nginx学习
需要装2个虚拟机
nginx 官方nginx
tenginx 淘宝nginx
这2个一模一样,淘宝的nginx,官方文档更详细
小提示: 如果你想删除 编译安装的软件 1,清空PATH 2,删除文件夹即可
注意,编译软件之前,还是需要解决系统的开发环境,例如如下
yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel openssl openssl-devel -y
1.进入淘宝nginx官网,下载源代码,进行编译安装
http://tengine.taobao.org/index_cn.html
2.在linux的opt目录下,下载nginx源代码
wget http://tengine.taobao.org/download/tengine-2.3.2.tar.gz
3.解压缩源代码,准备编译三部曲
[root@s25linux opt]# tar -zxvf tengine-2.3.2.tar.gz
4.进入源码目录,指定nginx的安装位置
[root@s25linux tengine-2.3.2]# ./configure --prefix=/opt/tngx232/
5.编译且编译安装,生成nginx的可执行命令目录
make && make install
6.安装完毕后,会生成/opt/tngx232/文件夹,nginx可以使用的配置都在这里了
[root@s25linux tngx232]# ls
conf html logs sbin
conf 明显是存放*.conf配置文件的
html 存放网页的静态文件的目录
logs 日志
sbin 存放nginx的可执行命令
7.添加nginx到PATH中,可以快捷执行命令
永久修改PATH,开机就去读
vim /etc/profile
写入PATH="/opt/tngx232/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:"
source /etc/profile
8.首次启动nginx,注意要关闭防火墙
直接输入nginx命令即可启动
有关nginx的命令
nginx #首次输入是直接启动,不得再次输入
nginx -s reload #平滑重启,重新读取nginx的配置文件,而不重启进程
nginx -s stop #停止nginx进程
nginx -t #检测nginx.conf语法是否正确
9.默认访问nginx的首页站点url是
http://192.168.178.140:80/index.html
nginx的配置文件
nginx的配置文件是c语言的代码风格
以; 号 表示每一行配置的结束
nginx.conf中 是以代码块形式 编写的
例如 主要的几个代码块
http{ } #里面定义了多个代码,是nginx的核心功能配置点
server{ } #虚拟主机代码块,定义了网站的目录地址,以及首页文件名字,监听的端口,等等功能
location { } #域名匹配代码块。。

nginx.conf 注释如下:
#user nobody;
# 定义nginx的工作进程数,以cpu核数 为准
worker_processes 5;
# 想用哪个用能,直接打开注释,或者写进来即可
error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#error_log "pipe:rollback logs/error_log interval=1d baknum=7 maxsize=2G";
# pid文件的作用是,pid是用于启停进程的号码
# ps -ef去获取nginx的进程id
# 吧pid写入到 此 nginx.pid文件中,
pid logs/nginx.pid;
events {
worker_connections 1024;
}
# 这个http区域,是nginx的核心功能区域
http {
include mime.types;
default_type application/octet-stream;
#打开此nginx的访问日志功能,即可查看日志
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#nginx开启静态资源压缩,比如nginx返回磁盘的html文件特别大,里面包含了诸多的js css,图片引用
# 一个html文件 达到4m大小
# 传输图片 等等都是高兴的 1080p图片
# 打开此功能,能够极大的提升网站访问,以及静态资源压缩
gzip on;
# 提供静态资源缓存功能,第一次访问过网页之后,nginx能够让图片js等静态资源,缓存到浏览器上
# 浏览器下次访问网站,速度就几乎是秒开了
# 想要用这些功能,只需要在nginx里打开某些配置即可,作者都已经写好了该功能
#
#这里的server区域配置,就是虚拟主机的核心配置
# nginx支持编写多个server{} 区域块,以达到多虚拟主机,多个站点的功能
# server{} 区域块,可以存在多个,且默认是自上而下去加载,去匹配的
# 目前这里是第一个server {} 区域块,端口是85
server {
# 定义该网站的端口
listen 85;
#填写域名,没有就默认即可
server_name localhost;
#更改nginx的编码支持
charset utf-8;
# 如此添加一行参数,当用户请求出错,出现404的时候,就返回 root定义的目录去寻找40x.html文件
# 讲师机器的配置,也就是去 /s25python/ 这个目录下 寻找 40x.html
error_page 404 /40x.html;
#access_log logs/host.access.log main;
#access_log "pipe:rollback logs/host.access_log interval=1d baknum=7 maxsize=2G" main;
# nginx的域名匹配,所有的请求,都会进入到这里
# 例如 192.168.178.140:85/lubenwei.jpg
# 192.168.178.140:85/menggededianhua.txt
location / {
#这个root参数,是定义该虚拟主机,资料存放路径的,可以自由修改
# 当用户访问 192.168.178.140:85的时候,就返回该目录的资料
root /s25python/;
# index参数,用于定义nginx的首页文件名字 ,只要在/s25nginx目录下存在index.html文件即可
index index.html index.htm;
}
}
#这里就是上一个Server{}的标签闭合处了,,可以写入第二个server{}
# 注意 ,注意,server{} 标签快,是平级的关系,不得嵌套,检查好你的花括号
# 这里是第二个虚拟主机的配置了
server {
listen 89;
server_name _;
#nginx的域名匹配
# 当用户访问 192.168.178.140:89的时候,返回该目录的内容
location / {
root /s25linux/;
index index.html;
}
}
}
nginx的web站点功能
也称之为是nginx的虚拟主机站点配置
指的就是在nginx中,能够通过文件目录的不同,可以定义多个不同的网站
修改nginx的首页内容,你们信不信我,一分钟做出一个dnf(腾讯的游戏官网)的官网~ 相信的扣1,觉得我在吹牛皮的,扣2
1.如何修改nginx的首页地址,进入html目录下,找到index.html文件,默认读取的是这个文件
[root@s25linux html]# pwd
/opt/tngx232/html
[root@s25linux html]# ls
50x.html index.html
2.在自己的站点下,存放一些静态资料,如gif,jpg等
[root@s25linux html]# ls
50x.html 55kai.jpg index.html s25.html
nginx的多站点功能
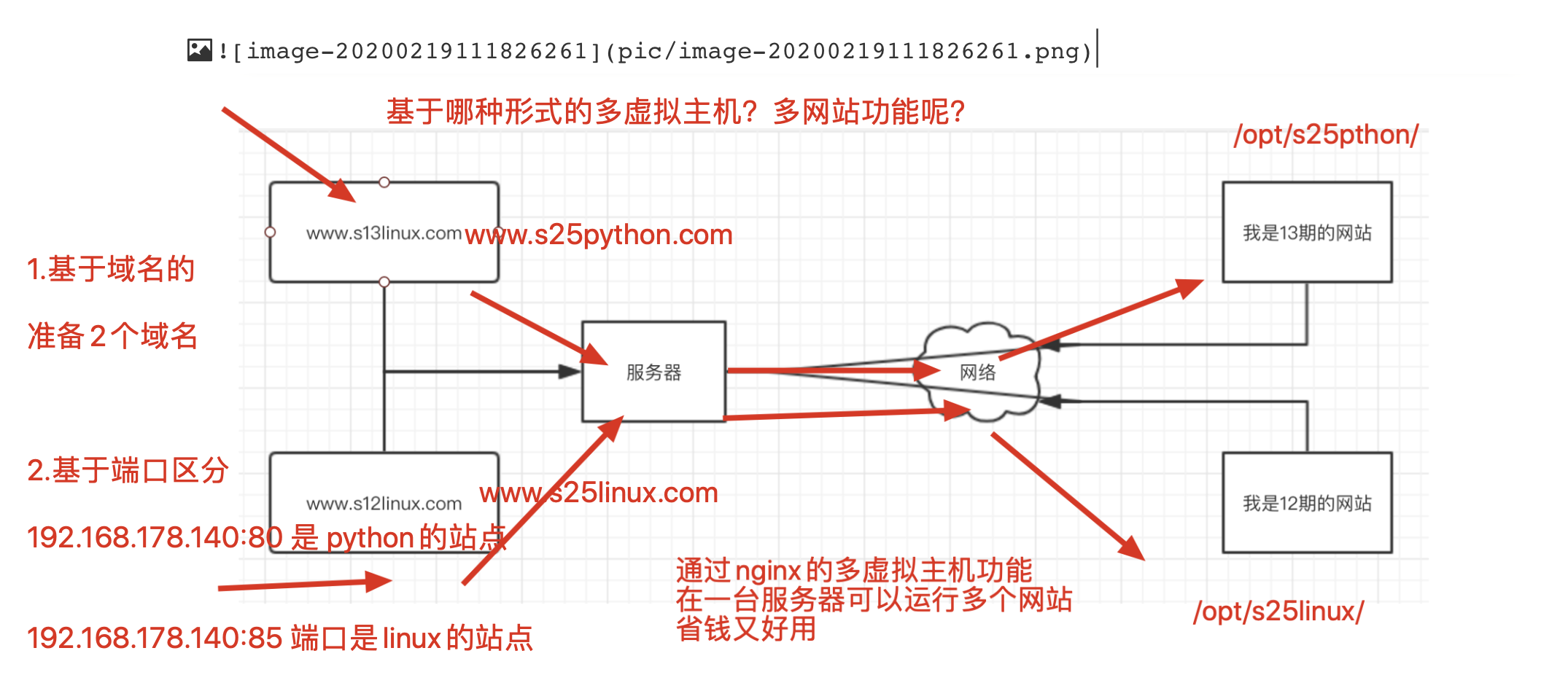
- 基于域名的多虚拟主机
修改hosts文件,强制写入域名对应关系,比较麻烦
- 基于端口的多虚拟主机
1.修改nginx.conf配置如下,定义2个server{} 区域块即可
第一个虚拟主机的配置
# 目前这里是第一个server {} 区域块,端口是85
server {
# 定义该网站的端口
listen 85;
#填写域名,没有就默认即可
server_name localhost;
#更改nginx的编码支持
charset utf-8;
#access_log logs/host.access.log main;
#access_log "pipe:rollback logs/host.access_log interval=1d baknum=7 maxsize=2G" main;
# nginx的域名匹配,所有的请求,都会进入到这里
# 例如 192.168.178.140:85/lubenwei.jpg
# 192.168.178.140:85/menggededianhua.txt
location / {
#这个root参数,是定义该虚拟主机,资料存放路径的,可以自由修改
# 当用户访问 192.168.178.140:85的时候,就返回该目录的资料
root /s25python/;
# index参数,用于定义nginx的首页文件名字 ,只要在/s25nginx目录下存在index.html文件即可
index index.html index.htm;
}
}
第二个虚拟主机的配置
#这里就是上一个Server{}的标签闭合处了,,可以写入第二个server{}
# 注意 ,注意,server{} 标签快,是平级的关系,不得嵌套,检查好你的花括号
# 这里是第二个虚拟主机的配置了
server {
listen 89;
server_name _;
#nginx的域名匹配
# 当用户访问 192.168.178.140:89的时候,返回该目录的内容
location / {
root /s25linux/;
index index.html;
}
}
改完配置文件后,分别创建2个站点的资源目录
[root@s25linux conf]#
[root@s25linux conf]# mkdir /s25linux /s25python
[root@s25linux conf]#
[root@s25linux conf]#
[root@s25linux conf]# echo "i like linux ,i very happy" > /s25linux/index.html
[root@s25linux conf]#
[root@s25linux conf]#
[root@s25linux conf]# echo "i use python,i very nb" > /s25python/index.html
#注意,改了配置文件,一定要平滑重启,否则不生效
[root@s25linux conf]# nginx -s reload
#此时分贝访问2个站点,即可看到2个站点的资料
192.168.178.140:85
192.168.178.140:85
nginx的404页面优化
如果nginx不做404优化,那么页面是非常丑的。。
1.修改nginx.conf,修改一行参数即可
server {
# 定义该网站的端口
listen 85;
#填写域名,没有就默认即可
server_name localhost;
#更改nginx的编码支持
charset utf-8;
# 如此添加一行参数,当用户请求出错,出现404的时候,就返回 root定义的目录去寻找40x.html文件
# 讲师机器的配置,也就是去 /s25python/ 这个目录下 寻找 40x.html
error_page 404 /40x.html; #注意别忘了分号
......
手动创建一个40x.html,咱们也可以去网上搜索404的html模板,修改此40x.html即可
[root@s25linux conf]# cat /s25python/40x.html
<meta charset=utf8>
我是自定义的404页面,你看我美不美...
注意还得重启nginx
nginx -s reload
Nginx的访客日志
nginx的方可日志,能够记录,分析用户的请求行为
-什么时间点,访问的最频繁,比如路飞的网站,网站的流量,基本都在晚上,学生下了班,在线学习各种技术
-记录用户的请求频率,以此检测是否是爬虫等恶意请求,进行封禁。
-检测躲在代理ip后的 真实用户ip
-检测用户ip,请求时间,请求的url内容,等等。。。。
如何配置日志呢
修改nginx.conf 在 http{}代码块中,打开如下注释即可
#打开此nginx的访问日志功能,即可查看日志
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
#如果25期所有学生,在班级,同时访问路飞官网
# nginx日志检测到的ip地址是一样,还是不一样的?
# 答案是一样的,因为大家都从同一路由器转发出去的公网
# 我们都是通过同一个宽带运营商提供的公网ip和路飞通信的
access_log logs/access.log main;
日志变量解释
$remote_addr 记录客户端ip
$remote_user 远程用户,没有就是 “-”
$time_local 对应[14/Aug/2018:18:46:52 +0800]
$request 对应请求信息"GET /favicon.ico HTTP/1.1"
$status 状态码
$body_bytes_sent 571字节 请求体的大小
$http_referer 对应“-” 由于是直接输入浏览器就是 -
$http_user_agent 客户端身份信息,以此可以nginx判断,用户客户端是手机浏览器,就转发移动端页面给与用户如果是pc的客户端,就转发给pc页面给与用查看
$http_x_forwarded_for 记录客户端的来源真实ip 97.64.34.118,机器A用机器B的ip去访问,可以抓出机器A的地址,这个参数不是万能的,爬虫和反扒是相互的
重启nginx -s reload
实时监测访客日志的信息
tail -f logs/access.log
nginx反向代理
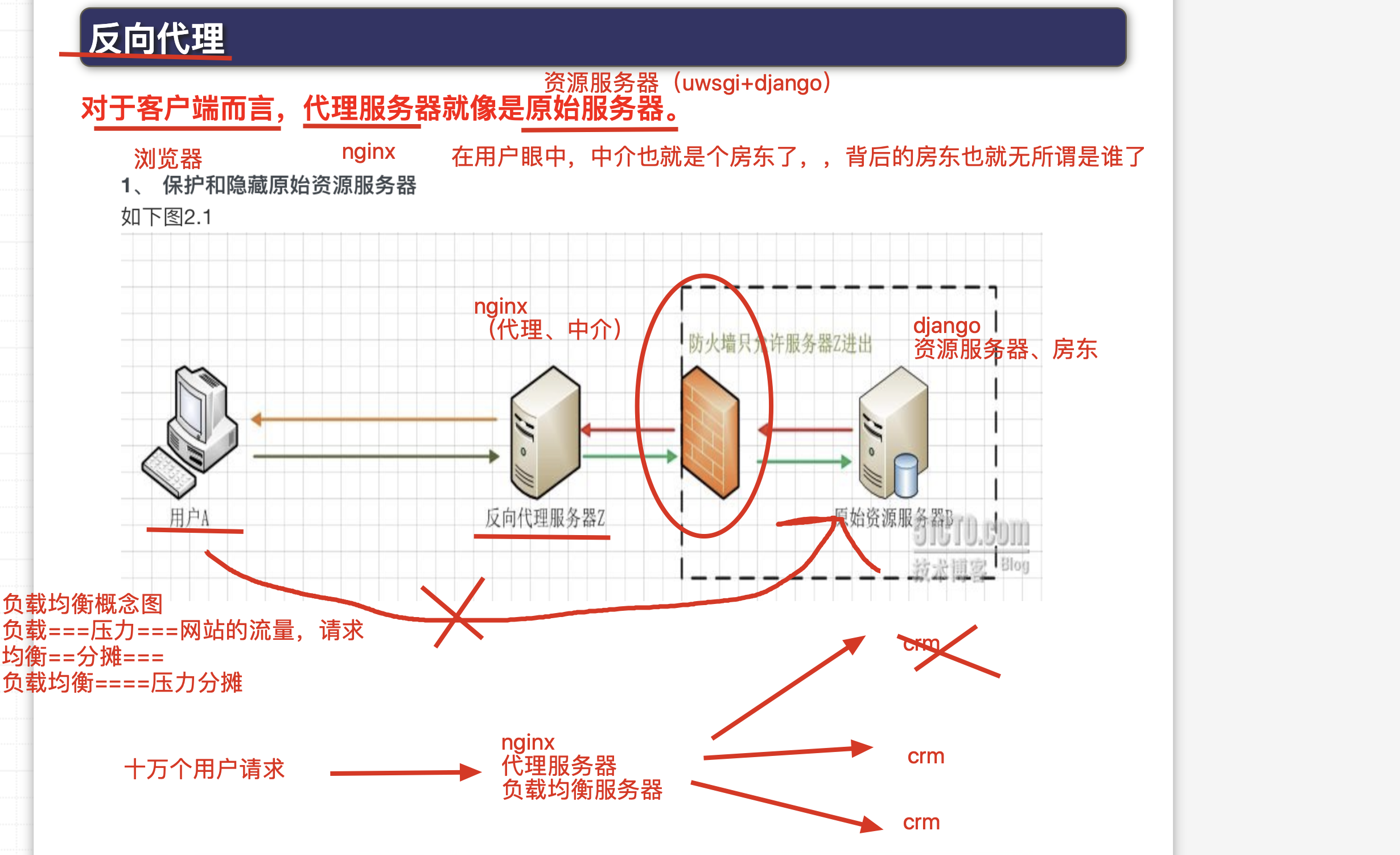
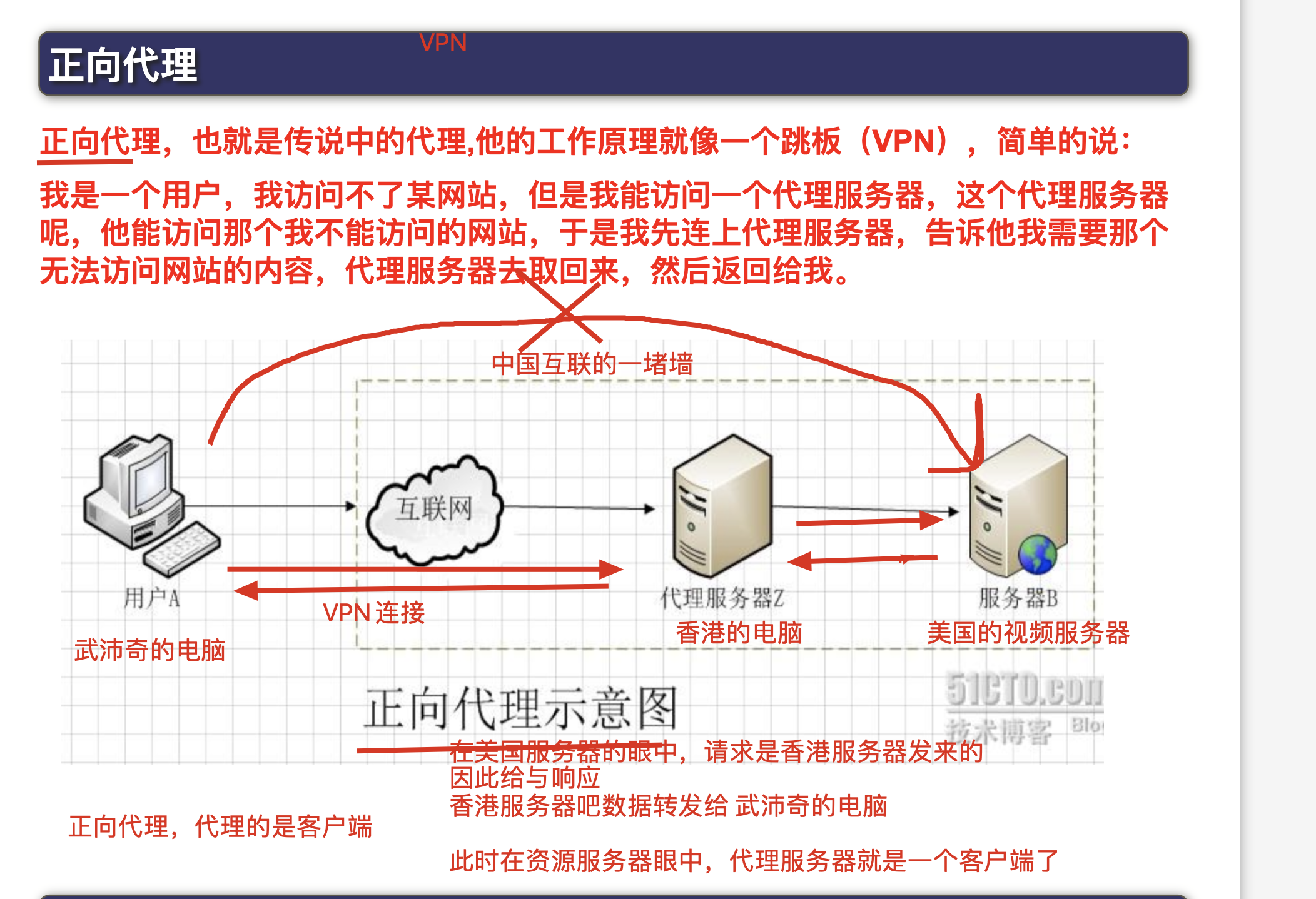
正向代理,,代理服务器,代理的是客户端
反向代理,,代理服务器,,代理的是服务端
反向代理,实验配置
讲道理,需要准备2台linux服务器
192.168.178.134
192.168.178.140
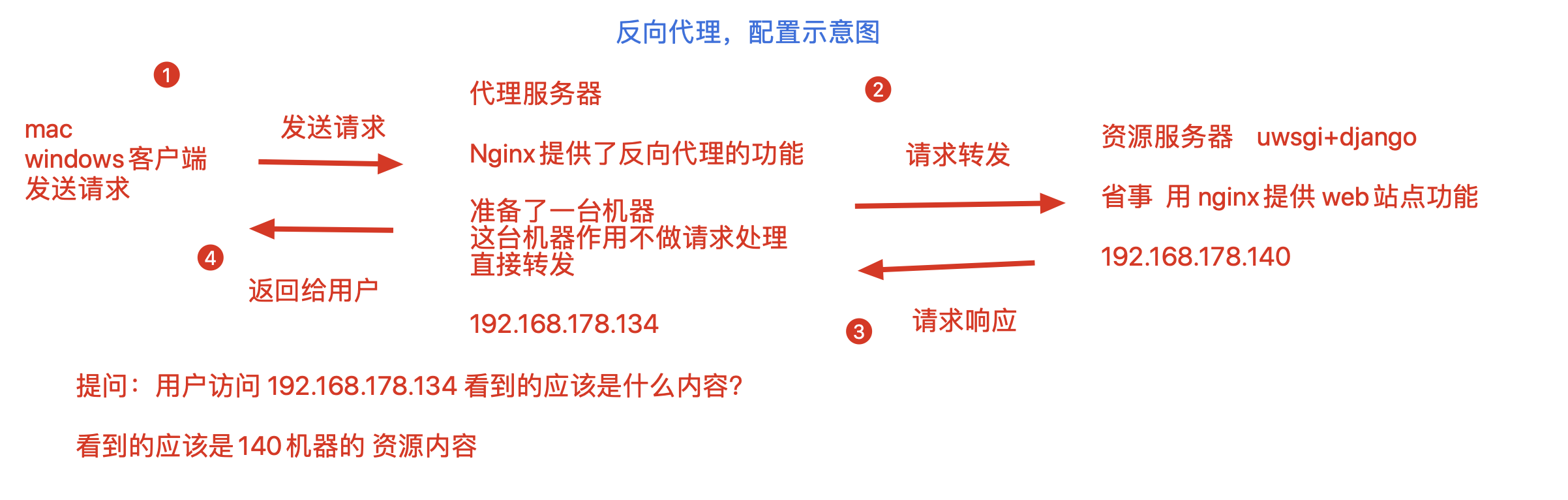
考虑到咱们同学的笔记本,安装2个虚拟机会比较卡,
因此决定用如下的方案,很巧妙,用到了nginx支持的多虚拟主机功能
准备1台机器即可
如192.168.178.140 ,基于端口的不同,运行不同的站点
1.准备一台linux机器,安装好nginx之后,,修改nginx.conf如下,配置好2个server{}标签
第一个server{}标签,用于反向代理的作用,修改nginx.conf如下
# 第一个虚拟主机的配置,作用是反向代理了
#
server {
listen 80;
server_name localhost;
charset utf-8;
error_page 404 /40x.html;
# 这里的locaiton 路径匹配,如果你写的是root参数,就是一个web站点功能
# 如果你写的是proxy_pass参数,就是一个请求转发,反向代理功能
location / {
#当请求发送给 192.168.178.140:80的时候
#直接通过如下的参数,转发给90端口
proxy_pass http://192.168.178.140:90;
}
}
第二个server{}标签,作用是返回机器上的资料,也就是一个web站点的功能
#第二个虚拟主机,作用是web站点功能,资源服务器,提供页面的
server {
listen 90;
server_name _;
#当请求来到 192.168.178.140:90的时候,就返回/s25proxy目录下的index.html
location / {
root /s25proxy/;
index index.html;
}
}
创建资源文件夹,以及html页面内容
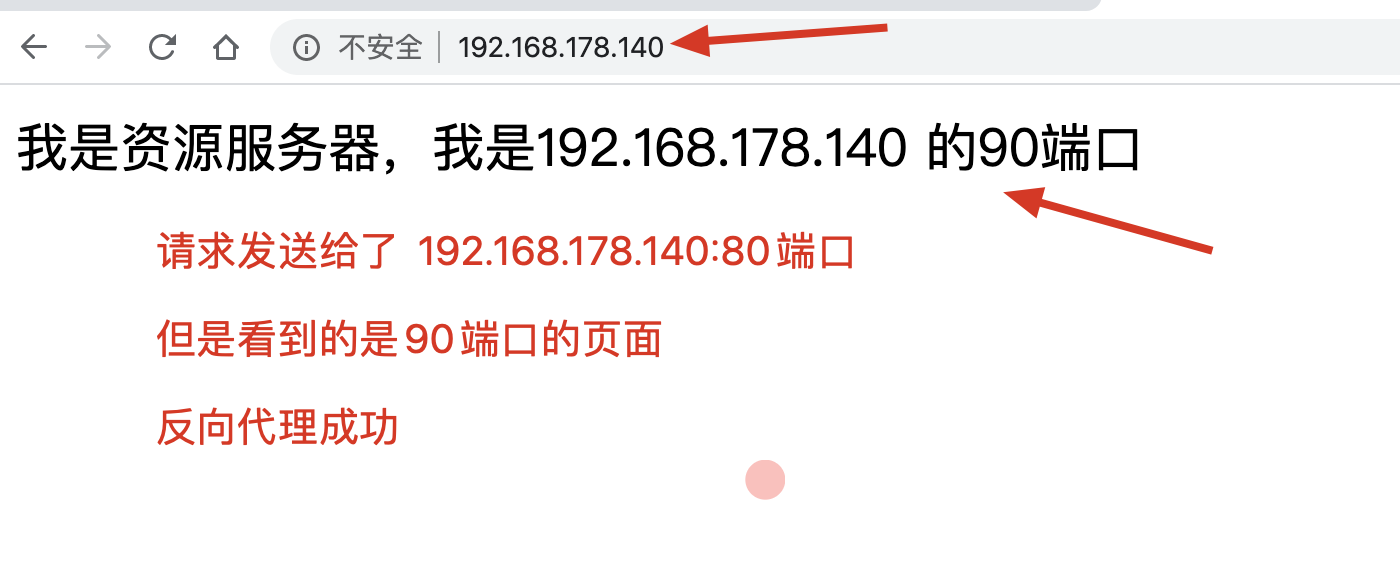
[root@s25linux conf]# cat /s25proxy/index.html
<meta charset=utf8>
我是资源服务器,我是192.168.178.140 的90端口
重启nginx
nginx -s reload
测试访问代理服务器,查看页面效果
反向代理对于项目部署的意义

nginx负载均衡

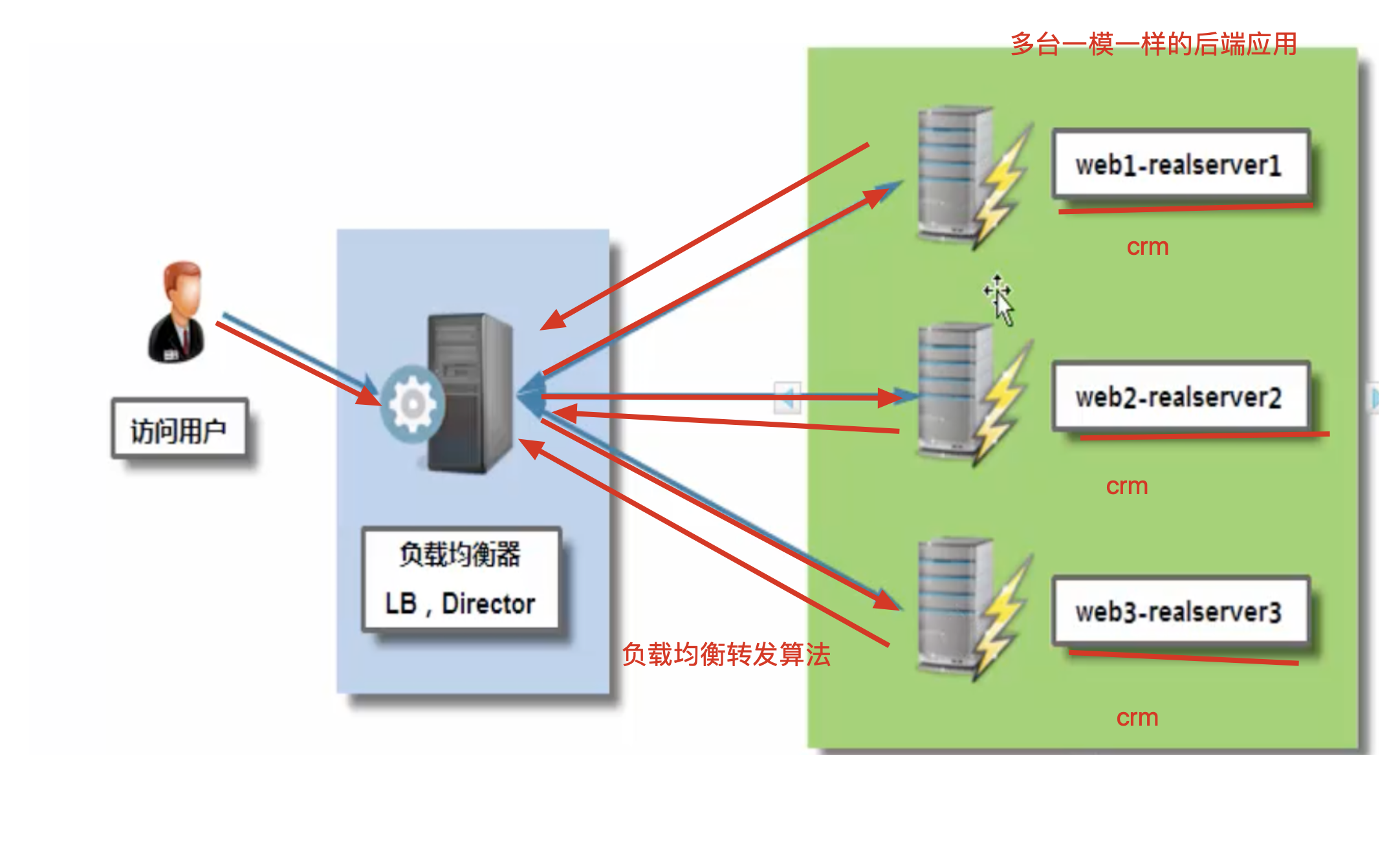
nginx负载均衡实验的搭建,修改nginx.conf如下
第一个虚拟主机server{}的作用,是反向代理,80端口
# 用upstream关键词定义负载均衡池,写入资源服务器的地址
# 负载均衡的算法,默认是轮询机制,一台服务器处理一次
upstream s25real_server {
server 192.168.178.140:90;
server 192.168.178.140:95;
}
server {
listen 80;
server_name localhost;
charset utf-8;
error_page 404 /40x.html;
# 这里的locaiton 路径匹配,如果你写的是root参数,就是一个web站点功能
# 如果你写的是proxy_pass参数,就是一个请求转发,反向代理功能
location / {
#当请求发送给 192.168.178.140:80的时候
#直接通过如下的参数,转发给90端口
proxy_pass http://s25real_server;
}
}
第二个server{}标签的配置,作用是提供资源给用户看的,90端口
#第二个虚拟主机,作用是web站点功能,资源服务器,提供页面的
server {
listen 90;
server_name _;
#当请求来到 192.168.178.140:90的时候,就返回/s25proxy目录下的index.html
location / {
root /s25lol/;
index index.html;
}
}
第三个server{}标签的作用,同样是返回资源页面,查看负载均衡效果的,95端口
#第三个server{}虚拟主机,作用是 提供资源服务器的内容的
server {
listen 95;
server_name _;
location / {
root /s25dnf/;
index index.html;
}
}
此时分别准备2个资源服务器的内容
准备好 /s25lol/index.html
准备好 /s25dnf/index.html
最终访问效果如下
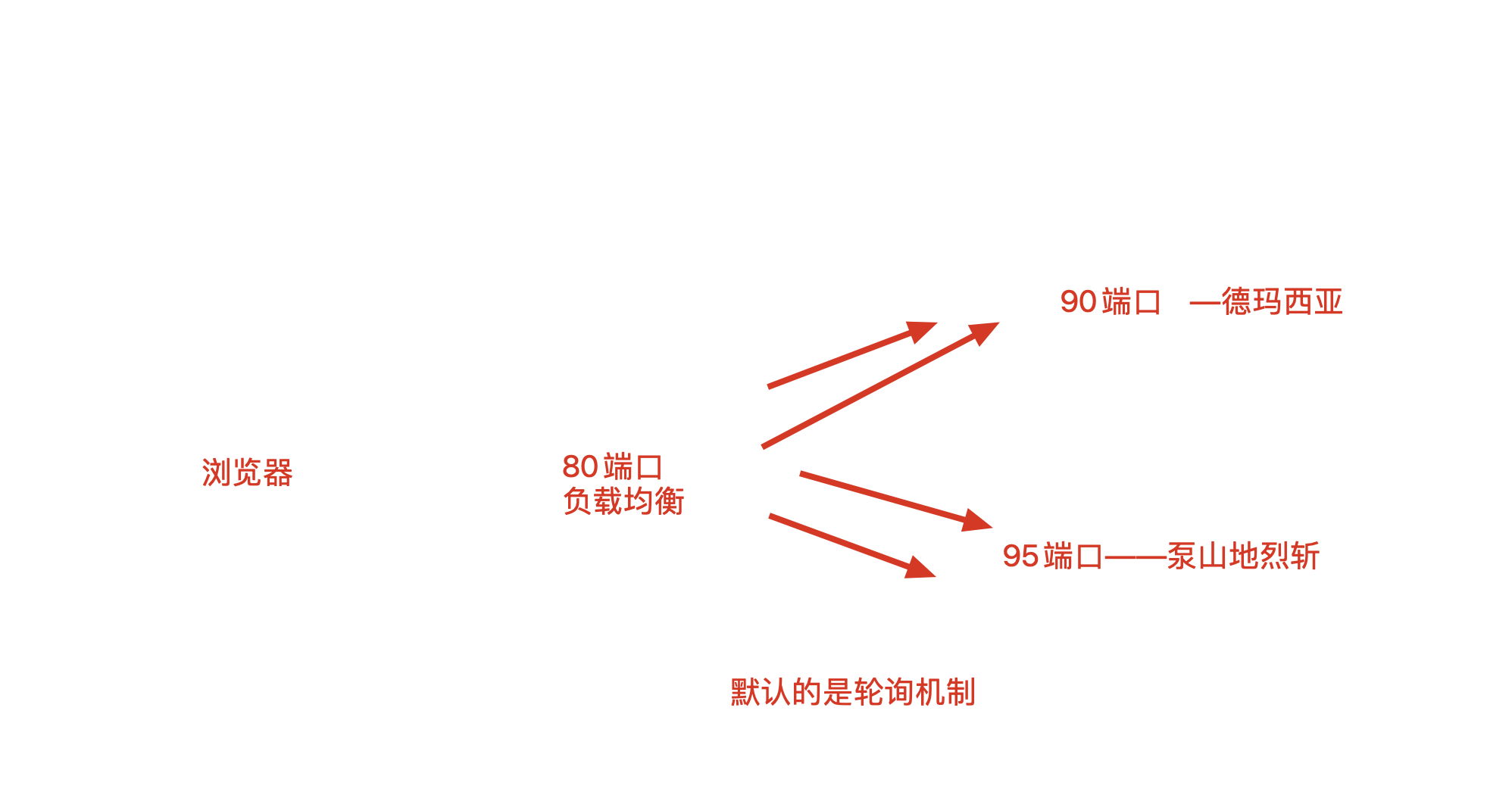
负载均衡实验原理图

nginx负载均衡算法
1.默认是轮询机制,每台服务器处理一次
2.加权轮询,修改nginx.conf如下,给与机器不同的权重
upstream s25real_server {
server 192.168.178.140:90 weight=4;
server 192.168.178.140:95 weight=1;
}
django项目部署
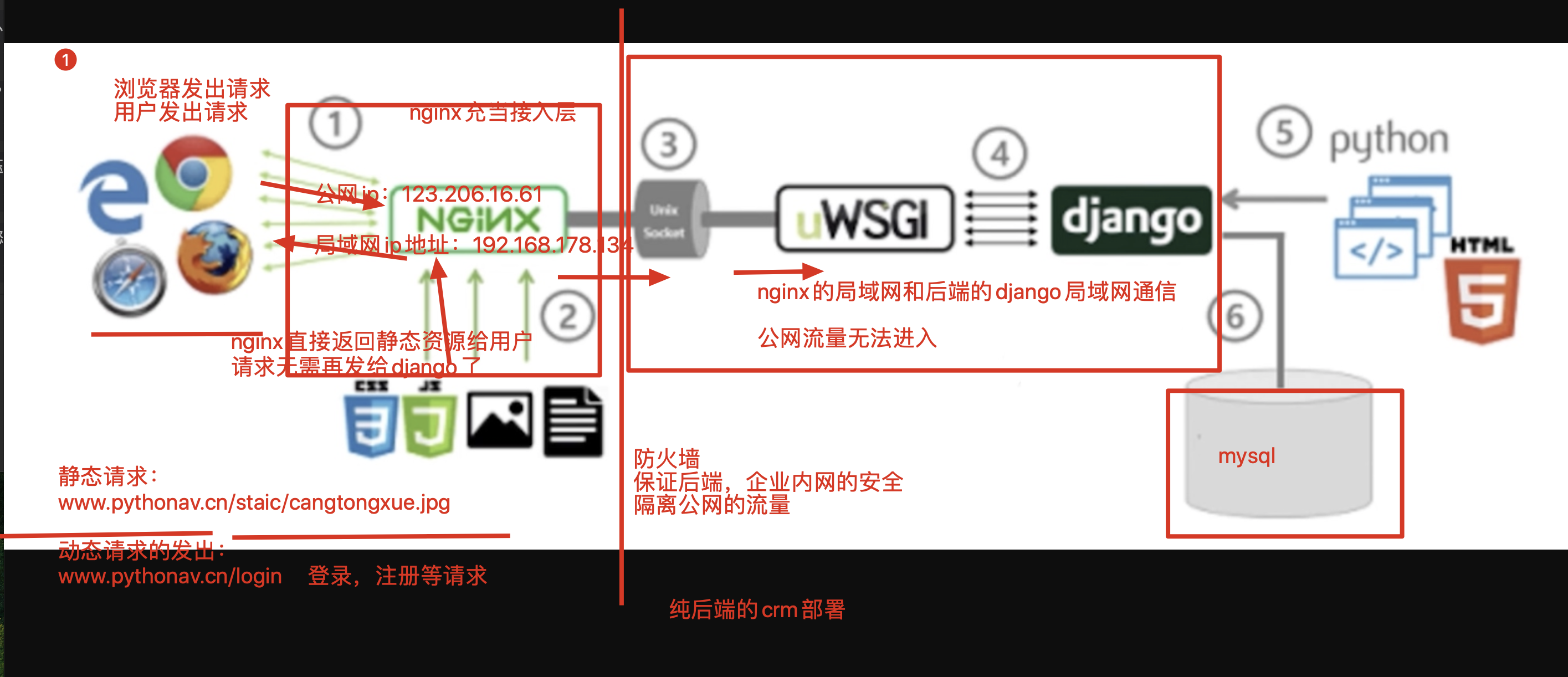
crm纯后端部署
supervisor+nginx+uwsgi+django+virtualenv+mariadb
crm部署流程
crm是通过模板语言进行和前端通信的 ,前端代码写在后端中
{{static.el}}
如何停止supervisor以及uwsgi
1.必须得先停止supervisor才可以停止uwsgi
pkill -9 supervisor
2.杀死uwsgi
pkill -9 uwsgi
kill命令,是基于pid杀死进程,如 kill 5888
pkill命令, 是基于进程的名字 杀死进程 pkill uwsgi
crm部署的史上最详细的流程部署笔记
#先从后端搞起 uwsgi+crm进行项目运行
老师电脑的环境变量
PATH="/opt/python369/bin:/opt/tngx232/sbin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:"
1.先创建虚拟环境,用于运行crm
(s25_crm) [root@s25linux s25crm]#
2.上传代码到linux中,调试项目是否能够运行
pip3 install -i https://pypi.douban.com/simple django==1.11.25
pip3 install -i https://pypi.douban.com/simple pymysql
pip3 install -i https://pypi.douban.com/simple django-multiselectfield
3.在调试好crm的模块依赖,以及mariadb数据库的安装,以及数据导入之后(数据导入出错了,基本事sql文件的问题,单独找我),crm调试可以正确运行了
4.在线上,是使用uwsgi结合uwsgi.ini配置文件,启动crm的,因此 ,启动方式如下
pip3 install -i https://pypi.douban.com/simple uwsgi #安装uwsgi
#今日的线上部署,uwsgi.ini需要修改的地方是,添加如下参数,关闭http参数
#今日的线上部署,uwsgi.ini需要修改的地方是,添加如下参数,关闭http参数
#今日的线上部署,uwsgi.ini需要修改的地方是,添加如下参数,关闭http参数
# 这里的socket参数,是用于和nginx结合部署的unix-socket参数,这里临时先暂
停使用
# 使用此协议运行后台,就无法通过浏览器访问了,协议不一样
socket = 0.0.0.0:8000
# 线上不会用http参数,因为对后端是不安全的,使用socket参数是安全的连接>,用nginx反向代理去访问
# 后端程序是运行在防火墙内部,外网是无法直接访问的
# 临时使用http参数,便于我们用浏览器调试访问
#http = 0.0.0.0:8000
5.使用supervisor启动uwsgi进程,需要修改supervisord.conf配置文件了,看好文件的名字!!!!
vim /etc/supervisord.conf #修改如下参数
[program:again_s25crm]
command=/s25crm/s25_crm/bin/uwsgi --ini /s25crm/tf_crm/uwsgi.ini
autostart=true ; 在supervisord启动的时候也自动启动
startsecs=10 ; 启动10秒后没有异常退出,就表示进程正常启动了,默认为1秒
autorestart=true ; 程序退出后自动重启,可选值:[unexpected,true,false],默认为unexpected,表示进程意外杀死后才重启
stopasgroup=true ;默认为false,进程被杀死时,是否向这个进程组发送stop信号,包括子进程
killasgroup=true ;默认为false,向进程组发送kill信号,包括子进程
6.检查后台的状态,以及启动命令
【但凡supervisor这里无法正常启动,立即去检查 supervisord.conf里面定义的任务参数是否正确】
(s25_crm) [root@s25linux tf_crm]# supervisord -c /etc/supervisord.conf
Unlinking stale socket /tmp/supervisor.sock
(s25_crm) [root@s25linux tf_crm]# supervisorctl -c /etc/supervisord.conf
again_s25crm STARTING
supervisor>
supervisor>
supervisor> status
again_s25crm STARTING
supervisor> status
again_s25crm RUNNING pid 64285, uptime 0:00:13
7.此时配置好nginx.conf就完事了,修改如下,配置nginx,请求转发给后台即可
server {
listen 80;
server_name localhost;
#这是一个局部的变量,只对当前这个server{}代码块生效,编码设置为utf-8
charset utf-8;
error_page 404 /40x.html;
# 这里的locaiton 路径匹配,如果你写的是root参数,就是一个web站点功能
# 基于uwsgi协议的一个高性能的反向代理转发,新的参数
location / {
#当请求发送给 192.168.178.140:80的时候
#通过uwsgi_pass把请求转发给后端的uwsgi服务器
uwsgi_pass 0.0.0.0:8000;
#这个参数,是固定的,是添加一些转发请求头内容
include uwsgi_params;
}
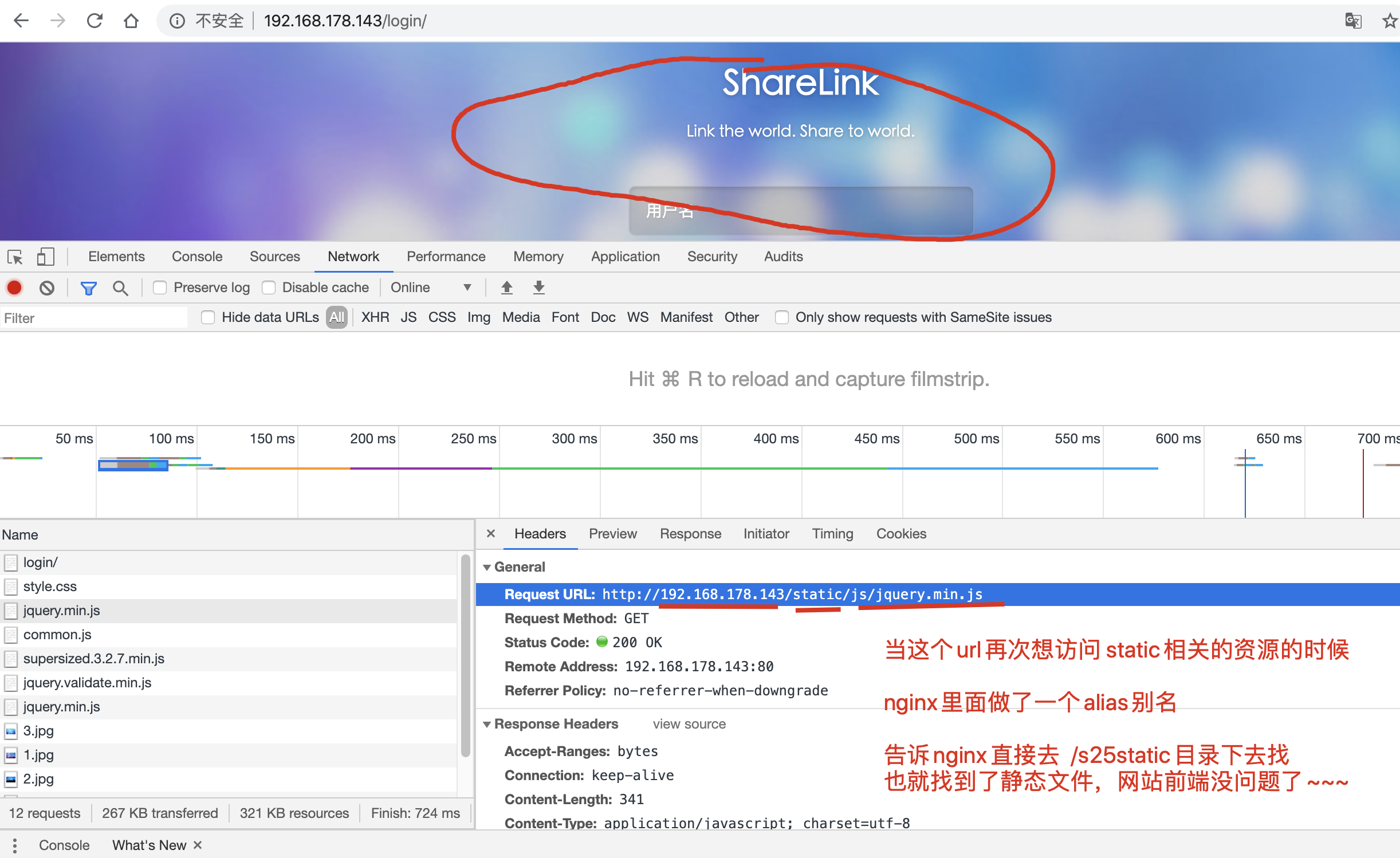
#这个配置的意义就是当请求的url是192.168.178.143/static/js
# 192.168.178.143/static/css
# 如此之类以/static开头的url,都告诉nginx,去linux的/s25static目录下寻找静态文件
location /static {
alias /s25static;
}
}
8.重启nginx
nginx -s reload
8.1 此时发现静态文件丢失,例如如下的静态文件
http://192.168.178.143/static/js/common.js
http://192.168.178.143/static/css/style.css
http://192.168.178.143/static/js/jquery.validate.min.js
9.还得配置nginx接收所有的django静态文件,修改命令如下
第一步:修改django的配置文件,收集所有的静态文件,放入一个统一管理的目录
vim settings.py #添加如下内容
STATIC_ROOT='/s25static/' #作用是定义一个统一管理的目录,收集所有crm的静态文件
第二步:用命令收集静态文件
python3 manage.py collectstatic
10.通过nginx去找到如下的静态文件即可
在nginx.conf文件中加入如下配置:
location /static {
alias /s25static;
}

nginx找到crm的静态文件原理图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号