
函数
函数入门
1. 初识函数
函数到底是个什么东西?
函数,可以当做是一大堆功能代码的集合。
def 函数名():
函数内编写代码
...
...
函数名()
例如:
# 定义名字叫info的函数
def info():
print("第一行")
print("第二行")
print("第n行...")
info()
什么时候会用到函数?
什么时候会用到函数呢?一般在项目开发中有会有两种应用场景:
-
有重复代码,用函数增加代码的重用性。
def send_email(): # 10行代码 print("欢迎使用计算机监控系统") if CPU占用率 > 90%: send_email() if 硬盘使用率 > 99%: send_email() if 内存使用率 > 98%: send_email() ... -
代码太长,用函数增强代码的可读性。
def calculate_same_num_rule(): """判断是否是豹子""" pass def calculate_same_color_rule(): """判断是否是同花""" pass def calculate_straight_rule(): """判断是否顺子""" pass def calculate_double_card_rule(poke_list): """判断是否对子""" pass def calculate_single_card_rule(): """判断是否单牌""" pass # 1. 生成一副扑克牌 card_color_list = ["红桃", "黑桃", "方片", "梅花"] card_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] # A all_card_list = [[color, num] for color in card_color_list for num in card_nums] # 2.洗牌 random.shuffle(all_card_list) # 3.给玩家发牌 ... # 4.判断牌是:豹子?同花顺?顺子?对子?单点? calculate_same_num_rule() calculate_same_color_rule() calculate_straight_rule() ...
以前我们变成是按照业务逻辑从上到下逐步完成,称为:面向过程编程;现在学了函数之后,利用函数编程称为:函数式编程。
2. 函数的参数
之前说了很好多次发送邮件的案例,下面就来教大家用python发邮件,然后再由此引出函数的参数。
- 注册邮箱
- 基础配置
- 授权码 (IYGSTZDKANSBZVFR ) ttao18779114639@126.com tt951008
- SMTP服务器: smtp.126.com
- SMTP服务器: smtp.126.com
- 代码发送邮件
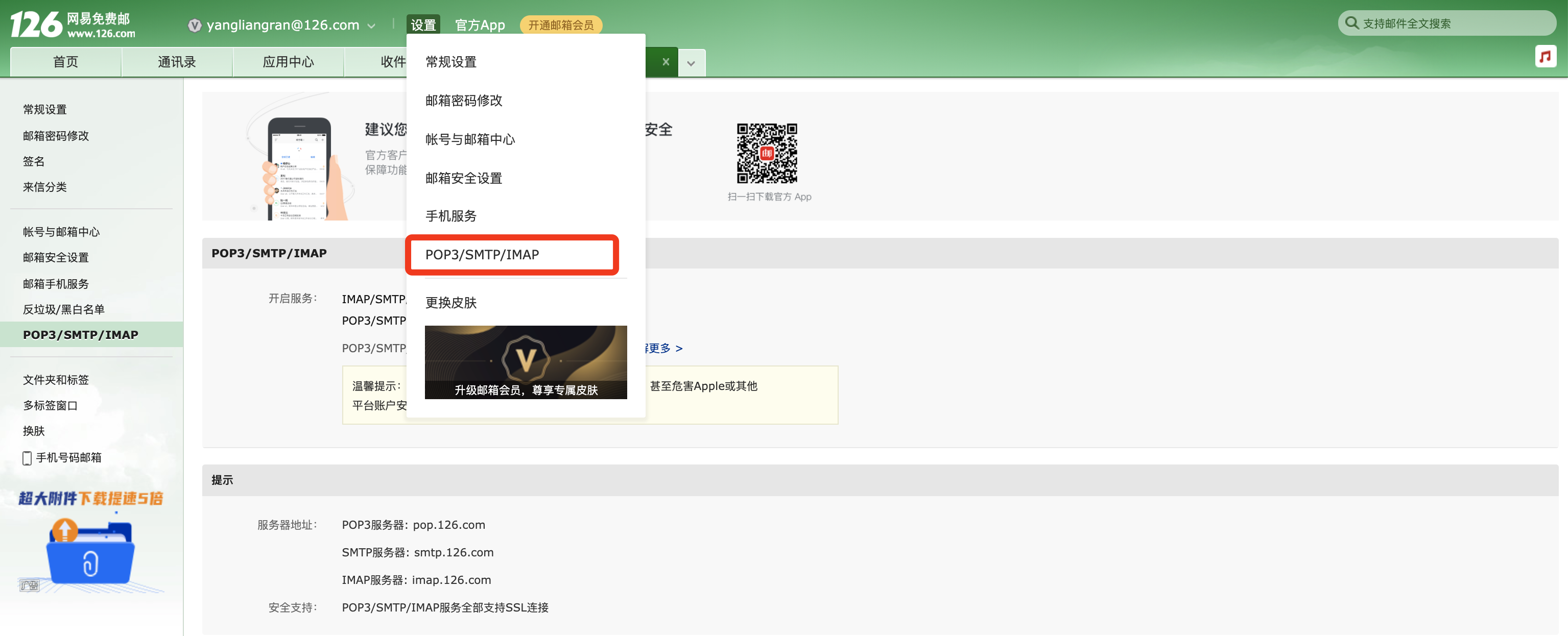
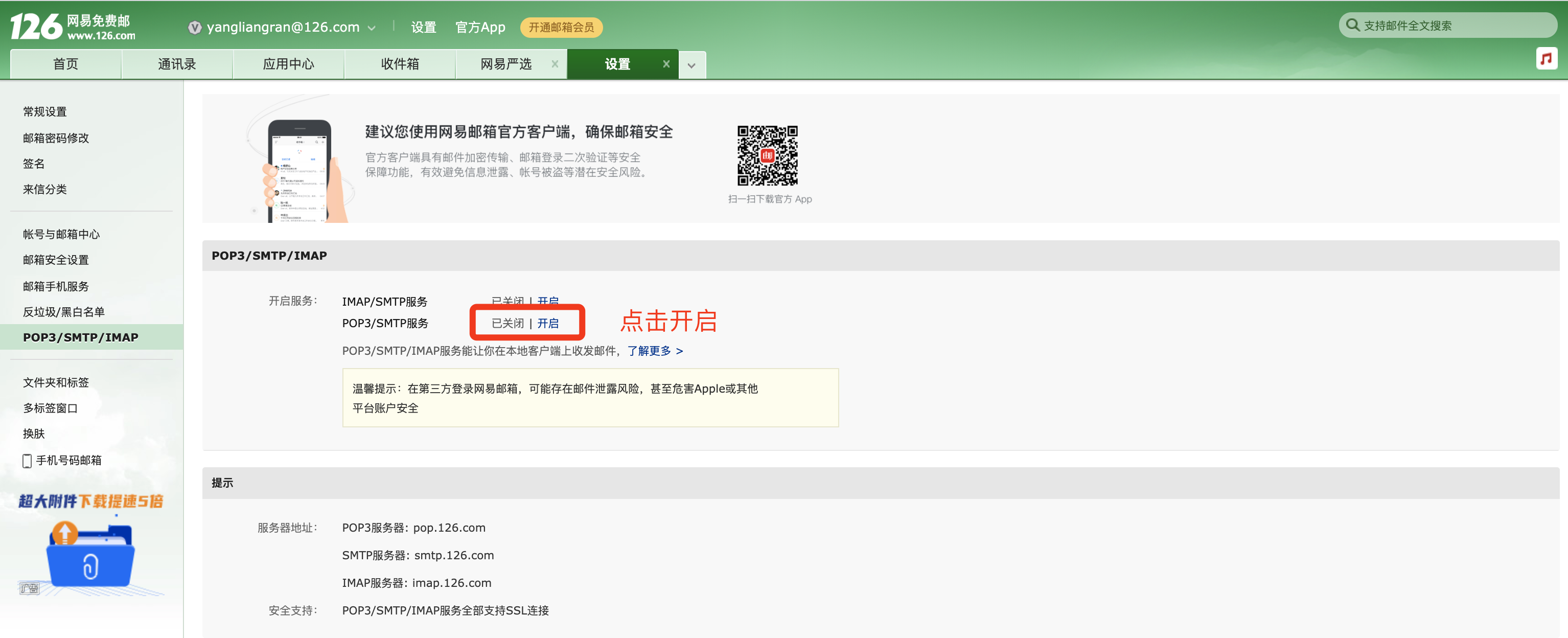
以下是我为大家提供的发邮件的一个函数。
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
# ### 1.邮件内容配置 ###
msg = MIMEText("约吗", 'html', 'utf-8')
msg['From'] = formataddr(["武沛齐", "yangliangran@126.com"])
msg['Subject'] = "180一晚"
# ### 2.发送邮件 ###
server = smtplib.SMTP_SSL("smtp.126.com")
server.login("yangliangran@126.com", "LAYEVIAPWQAVVDEP")
server.sendmail("yangliangran@126.com", "424662508@qq.com", msg.as_string())
server.quit()
那么需求来了,请求大家提一个需求:根据上述代码实现给3个用户发邮件。
v1 = "424662508@qq.com"
v2 = "424662509@qq.com"
v3 = "wupeiqi@live.com"
import smtplib
from email.mime.text import MIMEText
from email.utils import formataddr
def send_email(xx):
# ### 1.邮件内容配置 ###
msg = MIMEText("约吗", 'html', 'utf-8')
msg['From'] = formataddr(["武沛齐", "yangliangran@126.com"])
msg['Subject'] = "180一晚"
# ### 2.发送邮件 ###
server = smtplib.SMTP_SSL("smtp.126.com")
server.login("yangliangran@126.com", "LAYEVIAPWQAVVDEP")
server.sendmail("yangliangran@126.com", xx, msg.as_string())
server.quit()
send_email("424662508@qq.com")
send_email("424662509@qq.com")
send_email("wupeiqi@live.com")
-
思路1
def send_email1(): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", "424662508@qq.com", msg.as_string()) server.quit() def send_email2(): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", "424662509@qq.com", msg.as_string()) server.quit() def send_email3(): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", "wupeiqi@live.com", msg.as_string()) server.quit() send_email1() send_email2() send_email3() -
思路2,基于函数的参数(将代码中动态部分提取到参数位置,让函数可以充分被重用)
def send_email(email): # ### 1.邮件内容配置 ### # 邮件文本 msg = MIMEText("约吗", 'html', 'utf-8') # 邮件上显示的发件人 msg['From'] = formataddr(["武沛齐", "wptawy@126.com"]) # 邮件上显示的主题 msg['Subject'] = "邮件主题" # ### 2.发送邮件 ### server = smtplib.SMTP_SSL("smtp.126.com") server.login("wptawy@126.com", "WIYSAILOVUKPQGHY") server.sendmail("wptawy@126.com", email, msg.as_string()) server.quit() v1 = "424662508@qq.com" send_email(v1) v2 = "424662509@qq.com" send_email(v2) v3 = "wupeiqi@live.com" send_email(v3)
2.1 参数
在定义函数时,如果在括号中添加变量,我们称它为函数的形式参数:
# ###### 定义有三个参数的函数(a1/a2/a3一般称为形式参数-形参) #####
def func(a1,a2,a3):
print(a1+a2+a3)
# 执行函数并传入参数(执行函数传值时一般称为实际参数-实参)
func(11,22,33)
# 执行函数并传入参数
func(9,2,103)
-
位置传参
def add(n1,n2): print(n1+n2) add(1,22) -
关键字传参
def add(n1,n2): print(n1+n2) add(n1=1,n2=22)
"""
1. 形参
2. 实参
3. 位置传参
4. 关键字传参
"""
# ###### 定义有三个参数的函数(a1/a2/a3一般称为形式参数-形参) #####
def func(a1, a2, a3):
print(a1 + a2 + a3)
# 执行函数并传入参数(执行函数传值时一般称为实际参数-实参)
func(11, 22, 33)
# 执行函数并传入参数
func(9, 2, 103)
# 执行函数
func(a1=99, a2=88, a3=1)
func(a1=99, a3=1, a2=88)
2.2 默认参数
def func(a1, a2, a3=10):
print(a1 + a2 + a3)
# 位置传参
func(8, 19)
func(1, 2, 99)
# 关键字传参(位置和关键混合时,关键字传参要在后面)
func(12, 9, a3=90)
func(12, a2=9, a3=90)
func(a1=12, a2=9, a3=90)
file_object = open("xxx.txt")
2.3 动态参数
-
def func(*args): print(args) # 元组类型 (22,) (22,33,99,) () # 只能按照位置传参 func(22) func(22,33) func(22,33,99) func() -
**
def func(**kwargs): print(kwargs) # 字典类型 {"n1":"武沛齐"} {"n1":"武沛齐","age":"18","email":"xxxx"} {} # 只能按关键字传参 func(n1="武沛齐") func(n1="武沛齐",age=18) func(n1="武沛齐",age=18,email="xx@live.com") -
,*
def func(*args,**kwargs): print(args,kwargs) # (22,33,99) {} func(22,33,99) func(n1="武沛齐",age=18) func(22,33,99,n1="武沛齐",age=18) func()提示:是否还记得字符串格式化时的format功能。
v1 = "我叫{},今年{},性别{}".format("武沛齐",18,"男") v2 = "我叫{name},今年{age},性别{gender}".format(name="武沛齐",age=18,gender="男")
注意事项(不重要,听过一遍即可)
# 1. ** 必须放在 * 的后面
def func1(*args, **kwargs):
print(args, **kwargs)
# 2. 参数和动态参数混合时,动态参数只能放在最后。
def func2(a1, a2, a3, *args, **kwargs):
print(a1, a2, a3, args, **kwargs)
# 3. 默认值参数和动态参数同时存在
def func3(a1, a2, a3, a4=10, *args, a5=20, **kwargs):
print(a1, a2, a3, a4, a5, args, kwargs)
func3(11, 22, 33, 44, 55, 66, 77, a5=10, a10=123)
3. 函数返回值
在开发过程中,我们希望函数可以帮助我们实现某个功能,但让函数实现某功能之后有时也需要有一些结果需要反馈给我们,例如:
import requests
from xml.etree import ElementTree as ET
def xml_to_list(city):
data_list = []
url = "http://ws.webxml.com.cn//WebServices/WeatherWebService.asmx/getWeatherbyCityName?theCityName={}".format(city)
res = requests.get(url=url)
root = ET.XML(res.text)
for node in root:
data_list.append(node.text)
return data_list
result = xml_to_list("北京")
print(result)
def func():
return 666
res = func()
print(res) # 666
def magic(num):
result = num + 1000
return result
data = magic(9)
print(data) # 1009
在了解了返回值的基本使用之后,接下来在学3个关键知识:
-
返回值可以是任意类型,如果函数中没写return,则默认返回None
def func(): return [1,True,(11,22,33)] result = func() print(result)def func(): value = 1 + 1 ret = func() print(ret) # None当在函数中
未写返回值或return或return None,执行函数获取的返回值都是None。def func(): value = 1 + 1 return # 或 return None ret = func() print(ret) # None -
return后面的值如果有逗号,则默认会将返回值转换成元组再返回。
def func(): return 1,2,3 value = func() print(value) # (1,2,3) -
函数一旦遇到return就会立即退出函数(终止函数中的所有代码)
def func(): print(1) return "结束吧" print(2) ret = func() print(ret)def func(): print(1) for i in range(10): print(i) return 999 print(2) result = func() print(result) # 输出 1 0 999def func(): print(1) for i in range(10): print(i) for j in range(100): print(j) return print(2) result = func() print(result) # 输出 1 0 0 None
小结:
-
完成某个结果并希望的到结果。
def send_email(): ... return True v1 = send_email()def encrypt(old): ... return "密文..." data = encrypt("武沛齐") print(data) -
基于return控制让函数终止执行
def func(name): with open("xxx.txt",mode='r',encoding="utf-8") as file_object: for line in file_object: if name in line: return True data = func("武沛齐") if data: print("存在") else: print("不存在")def foo(): while True: num = input("请输入数字(Q):") if num.upper() == "Q": return num = int(num) if num == 99: print("猜对了") else: print("猜错了,请继续!") print("....") foo()
函数进阶
1.参数的补充
在函数基础部分,我们掌握函数和参数基础知识,掌握这些其实完全就可以进行项目的开发。
今天的补充的内容属于进阶知识,包含:内存地址相关、面试题相关等,在特定情况下也可以让代码更加简洁,提升开发效率。
1.1 参数内存地址相关【面试题】
在开始开始讲参数内存地址相关之前,我们先来学习一个技能:
如果想要查看下某个值的在内存中的地址?
v1 = "武沛齐"
addr = id(v1)
print(addr) # 140691049514160
v1 = [11,22,33]
v2 = [11,22,33]
print( id(v1) )
print( id(v2) )
v1 = [11,22,33]
v2 = v1
print( id(v1) )
print( id(v2) )
记住一句话:函数执行传参时,传递的是内存地址。

def func(data):
print(data, id(data)) # 武沛齐 140247057684592
v1 = "武沛齐"
print(id(v1)) # 140247057684592
func(v1)
面试题:请问Python的参数默认传递的是什么?
Python参数的这一特性有两个好处:
-
节省内存
-
对于可变类型且函数中修改元素的内容,所有的地方都会修改。可变类型:列表、字典、集合。
# 可变类型 & 修改内部修改 def func(data): data.append(999) v1 = [11,22,33] func(v1) print(v1) # [11,22,33,666]# 特殊情况:可变类型 & 重新赋值 def func(data): data = ["武沛齐","alex"] v1 = [11,22,33] func(v1) print(v1) # [11,22,33]# 特殊情况:不可变类型,无法修改内部元素,只能重新赋值。 def func(data): data = "alex" v1 = "武沛齐" func(v1)
其他很多编程语言执行函数时,默认传参时会将数据重新拷贝一份,会浪费内存。
提示注意:其他语言也可以通过 ref 等关键字来实现传递内存地址。
当然,如果你不想让外部的变量和函数内部参数的变量一致,也可以选择将外部值拷贝一份,再传给函数。
import copy
# 可变类型 & 修改内部修改
def func(data):
data.append(999)
v1 = [11, 22, 33]
new_v1 = copy.deepcopy(v1) # 拷贝一份数据
func(new_v1)
print(v1) # [11,22,33]
1.2 函数的返回值是内存地址
def func():
data = [11, 22, 33]
return data
v1 = func()
print(v1) # [11,22,33]
上述代码的执行过程:
- 执行func函数
data = [11, 22, 33]创建一块内存区域,内部存储[11,22,33],data变量指向这块内存地址。return data返回data指向的内存地址- v1接收返回值,所以 v1 和 data 都指向
[11,22,33]的内存地址(两个变量指向此内存,引用计数器为2) - 由函数执行完毕之后,函数内部的变量都会被释放。(即:删除data变量,内存地址的引用计数器-1)
所以,最终v1指向的函数内部创建的那块内存地址。
def func():
data = [11, 22, 33]
return data
v1 = func()
print(v1) # [11,22,33]
v2 = func()
print(v2) # [11,22,33]
上述代码的执行过程:
- 执行func函数
data = [11, 22, 33]创建一块内存区域,内部存储[11,22,33],data变量指向这块内存地址 1000001110。return data返回data指向的内存地址- v1接收返回值,所以 v1 和 data 都指向
[11,22,33]的内存地址(两个变量指向此内存,引用计数器为2) - 由函数执行完毕之后,函数内部的变量都会被释放。(即:删除data变量,内存地址的引用计数器-1)
所以,最终v1指向的函数内部创建的那块内存地址。(v1指向的1000001110内存地址)
- 执行func函数
data = [11, 22, 33]创建一块内存区域,内部存储[11,22,33],data变量指向这块内存地址 11111001110。return data返回data指向的内存地址- v2接收返回值,所以 v1 和 data 都指向
[11,22,33]的内存地址(两个变量指向此内存,引用计数器为2) - 由函数执行完毕之后,函数内部的变量都会被释放。(即:删除data变量,内存地址的引用计数器-1)
所以,最终v1指向的函数内部创建的那块内存地址。(v1指向的11111001110内存地址)
def func():
data = [11, 22, 33]
print(id(data))
return data
v1 = func()
print(v1, id(v1)) # [11,22,33]
v2 = func()
print(v2, id(v1)) # [11,22,33]
1.3 参数的默认值【面试题】
这个知识点在面试题中出现的概率比较高,但真正实际开发中用的比较少。
def func(a1,a2=18):
print(a1,a2)
原理:Python在创建函数(未执行)时,如果发现函数的参数中有默认值,则在函数内部会创建一块区域并维护这个默认值。
执行函数未传值时,则让a2指向 函数维护的那个值的地址。
func("root")执行函数传值时,则让a2指向新传入的值的地址。
func("admin",20)
在特定情况【默认参数的值是可变类型 list/dict/set】 & 【函数内部会修改这个值】下,参数的默认值 有坑 。
-
坑
# 在函数内存中会维护一块区域存储 [1,2,666,666,666] 100010001 def func(a1,a2=[1,2]): a2.append(666) print(a1,a2) # a1=100 # a2 -> 100010001 func(100) # 100 [1,2,666] # a1=200 # a2 -> 100010001 func(200) # 200 [1,2,666,666] # a1=99 # a2 -> 1111111101 func(99,[77,88]) # 66 [177,88,666] # a1=300 # a2 -> 100010001 func(300) # 300 [1,2,666,666,666] -
大坑
# 在内部会维护一块区域存储 [1, 2, 10, 20,40 ] ,内存地址 1010101010 def func(a1, a2=[1, 2]): a2.append(a1) return a2 # a1=10 # a2 -> 1010101010 # v1 -> 1010101010 v1 = func(10) print(v1) # [1, 2, 10] # a1=20 # a2 -> 1010101010 # v2 -> 1010101010 v2 = func(20) print(v2) # [1, 2, 10, 20 ] # a1=30 # a2 -> 11111111111 [11, 22,30] # v3 -> 11111111111 v3 = func(30, [11, 22]) print(v3) # [11, 22,30] # a1=40 # a2 -> 1010101010 # v4 -> 1010101010 v4 = func(40) print(v4) # [1, 2, 10, 20,40 ] -
深坑
# 内存中创建空间存储 [1, 2, 10, 20, 40] 地址:1010101010 def func(a1, a2=[1, 2]): a2.append(a1) return a2 # a1=10 # a2 -> 1010101010 # v1 -> 1010101010 v1 = func(10) # a1=20 # a2 -> 1010101010 # v2 -> 1010101010 v2 = func(20) # a1=30 # a2 -> 11111111111 [11,22,30] # v3 -> 11111111111 v3 = func(30, [11, 22]) # a1=40 # a2 -> 1010101010 # v4 -> 1010101010 v4 = func(40) print(v1) # [1, 2, 10, 20, 40] print(v2) # [1, 2, 10, 20, 40] print(v3) # [11,22,30] print(v4) # [1, 2, 10, 20, 40]
1.4 动态参数
动态参数,定义函数时在形参位置用 *或** 可以接任意个参数。
def func(*args,**kwargs):
print(args,kwargs)
func("宝强","杰伦",n1="alex",n2="eric")
在定义函数时可以用 *和**,其实在执行函数时,也可以用。
-
形参固定,实参用
*和**def func(a1,a2): print(a1,a2) func( 11, 22 ) func( a1=1, a2=2 ) func( *[11,22] ) func( **{"a1":11,"a2":22} ) -
形参用
*和**,实参也用*和**def func(*args,**kwargs): print(args,kwargs) func( 11, 22 ) func( 11, 22, name="武沛齐", age=18 ) # 小坑,([11,22,33], {"k1":1,"k2":2}), {} func( [11,22,33], {"k1":1,"k2":2} ) # args=(11,22,33),kwargs={"k1":1,"k2":2} func( *[11,22,33], **{"k1":1,"k2":2} ) # 值得注意:按照这个方式将数据传递给args和kwargs时,数据是会重新拷贝一份的(可理解为内部循环每个元素并设置到args和kwargs中)。
所以,在使用format字符串格式化时,可以可以这样:
v1 = "我是{},年龄:{}。".format("武沛齐",18)
v2 = "我是{name},年龄:{age}。".format(name="武沛齐",age=18)
v3 = "我是{},年龄:{}。".format(*["武沛齐",18])
v4 = "我是{name},年龄:{age}。".format(**{"name":"武沛齐","age":18})
练习题
-
看代码写结果
def func(*args,**kwargs): print(args,kwargs) params = {"k1":"v2","k2":"v2"} func(params) # ({"k1":"v2","k2":"v2"}, ) {} func(**params) # (), {"k1":"v2","k2":"v2"} -
读取文件中的 URL 和 标题,根据URL下载视频到本地(以标题作为文件名)。
模仿,https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog&ratio=720p&line=0 卡特,https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g&ratio=720p&line=0 罗斯,https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg&ratio=720p&line=0# 下载视频示例 import requests res = requests.get( url="https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg&ratio=720p&line=0", headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) with open('rose.mp4', mode='wb') as f: f.write(res.content)
2. 函数和函数名
函数名其实就是一个变量,这个变量只不过代指的函数而已。
name = "武沛齐"
def add(n1,n2):
return n1 + n2
注意:函数必须先定义才能被调用执行(解释型语言)。
# 正确
def add(n1,n2):
return n1 + n2
ret = add(1,2)
print(ret)
# 错误
ret = add(1,2)
print(ret)
def add(n1,n2):
return n1 + n2
2.1 函数做元素
既然函数就相当于是一个变量,那么在列表等元素中是否可以把行数当做元素呢?
def func():
return 123
data_list = ["武沛齐", "func", func , func() ]
print( data_list[0] ) # 字符串"武沛齐"
print( data_list[1] ) # 字符串 "func"
print( data_list[2] ) # 函数 func
print( data_list[3] ) # 整数 123
res = data_list[2]()
print( res ) # 执行函数 func,并获取返回值;print再输出返回值。
print( data_list[2]() ) # 123
注意:函数同时也可被哈希,所以函数名通知也可以当做 集合的元素、字典的键。
掌握这个知识之后,对后续的项目开发有很大的帮助,例如,在项目中遇到根据选择做不同操作时:
-
情景1,例如:要开发一个类似于微信的功能。
def send_message(): """发送消息""" pass def send_image(): """发送图片""" pass def send_emoji(): """发送表情""" pass def send_file(): """发送文件""" pass print("欢迎使用xx系统") print("请选择:1.发送消息;2.发送图片;3.发送表情;4.发送文件") choice = input("输入选择的序号") if choice == "1": send_message() elif choice == "2": send_image() elif choice == "3": send_emoji() elif choice == "4": send_file() else: print("输入错误")def send_message(): """发送消息""" pass def send_image(): """发送图片""" pass def send_emoji(): """发送表情""" pass def send_file(): """发送文件""" pass def xxx(): """收藏""" pass function_dict = { "1": send_message, "2": send_image, "3": send_emoji, "4": send_file, "5": xxx } print("欢迎使用xx系统") print("请选择:1.发送消息;2.发送图片;3.发送表情;4.发送文件") choice = input("输入选择的序号") # "1" func = function_dict.get(choice) if not func: print("输入错误") else: # 执行函数 func() -
情景2,例如:某个特定情况,要实现发送短信、微信、邮件。
def send_msg(): """发送短信""" pass def send_email(): """发送图片""" pass def send_wechat(): """发送微信""" # 执行函数 send_msg() send_email() send_wechat()def send_msg(): """发送短信""" pass def send_email(): """发送图片""" pass def send_wechat(): """发送微信""" pass func_list = [ send_msg, send_email, send_wechat ] for item in func_list: item()
上述两种情景,在参数相同时才可用,如果参数不一致,会出错。所以,在项目设计时就要让程序满足这一点,如果无法满足,也可以通过其他手段时间,例如:
情景1:
def send_message(phone,content):
"""发送消息"""
pass
def send_image(img_path, content):
"""发送图片"""
pass
def send_emoji(emoji):
"""发送表情"""
pass
def send_file(path):
"""发送文件"""
pass
function_dict = {
"1": [ send_message, ['15131255089', '你好呀']],
"2": [ send_image, ['xxx/xxx/xx.png', '消息内容']],
"3": [ send_emoji, ["😁"]],
"4": [ send_file, ['xx.zip'] ]
}
print("欢迎使用xx系统")
print("请选择:1.发送消息;2.发送图片;3.发送表情;4.发送文件")
choice = input("输入选择的序号") # 1
item = function_dict.get(choice) # [ send_message, ['15131255089', '你好呀']],
if not item:
print("输入错误")
else:
# 执行函数
func = item[0] # send_message
param_list = item[1] # ['15131255089', '你好呀']
func(*param_list) # send_message(*['15131255089', '你好呀'])
情景2:
def send_msg(mobile, content):
"""发送短信"""
pass
def send_email(to_email, subject, content):
"""发送图片"""
pass
def send_wechat(user_id, content):
"""发送微信"""
pass
func_list = [
{"name": send_msg, "params": {'mobile': "15131255089", "content": "你有新短消息"}},
{"name": send_email, "params": {'to_email': "wupeiqi@live.com", "subject": "报警消息", "content": "硬盘容量不够用了"}},
{"name": send_wechat, "params": {'user_id': 1, 'content': "约吗"}},
]
# {"name": send_msg, "params": {'mobile': "15131255089", "content": "你有新短消息"}},
for item in func_list:
func = item['name'] # send_msg
param_dict = item['params'] # {'mobile': "15131255089", "content": "你有新短消息"}
func(**param_dict) # send_msg(**{'mobile': "15131255089", "content": "你有新短消息"})
2.2 函数名赋值
-
将函数名赋值给其他变量,函数名其实就个变量,代指某函数;如果将函数名赋值给另外一个变量,则此变量也会代指该函数,例如:
def func(a1,a2): print(a1,a2) xxxxx = func # 此时,xxxxx和func都代指上面的那个函数,所以都可以被执行。 func(1,1) xxxxx(2,2)def func(a1,a2): print(a1,a2) func_list = [func,func,func] func(11,22) func_list[0](11,22) func_list[1](33,44) func_list[2](55,66) -
对函数名重新赋值,如果将函数名修改为其他值,函数名便不再代指函数,例如:
def func(a1,a2): print(a1,a2) # 执行func函数 func(11,22) # func重新赋值成一个字符串 func = "武沛齐" print(func)def func(a1,a2): print(a1+a2) func(1,2) def func(): print(666) func()注意:由于函数名被重新定义之后,就会变量新被定义的值,所以大家在自定义函数时,不要与python内置的函数同名,否则会覆盖内置函数的功能,例如:
id,bin,hex,oct,len...# len内置函数用于计算值得长度 v1 = len("武沛齐") print(v1) # 3 # len重新定义成另外一个函数 def len(a1,a2): return a1 + a2 # 以后执行len函数,只能按照重新定义的来使用 v3 = len(1,2) print(v3)
2.3 函数名做参数和返回值
函数名其实就一个变量,代指某个函数,所以,他和其他的数据类型一样,也可以当做函数的参数和返回值。
-
参数
def plus(num): return num + 100 def handler(func): res = func(10) # 110 msg = "执行func,并获取到的结果为:{}".format(res) print(msg) # 执行func,并获取到的结果为:110 # 执行handler函数,将plus作为参数传递给handler的形式参数func handler(plus) -
返回值
def plus(num): return num + 100 def handler(): print("执行handler函数") return plus result = handler() data = result(20) # 120 print(data)
3.返回值和print
对于初学者的同学,很多人都对print和返回值分不清楚,例如:
def add(n1,n2):
print(n1 + n2)
v1 = add(1,3)
print(v1)
# 输出
4
None
def plus(a1,a2):
return a1 + a2
v2 = plus(1,2)
print(v2)
# 输出
3
这两个函数是完全不同的
- 在函数中使用print,只是用于在某个位置输出内容而已。
- 在函数中使用return,是为了将函数的执行结果返回给调用者,以便于后续其他操作。
在调用并执行函数时,要学会分析函数的执行步骤。
def f1():
print(123)
def f2(arg):
ret = arg()
return ret
v1 = f2(f1)
print(v1)
# 输出
123
None
def f1():
print(123)
def f2(arg):
ret = arg()
return f1
v1 = f2(f1)
v2 = v1()
print(v2)
# 输出
123
123
None
4. 作用域
作用域,可以理解为一块空间,这块空间的数据是可以共享的。通俗点来说,作用域就类似于一个房子,房子中的东西归里面的所有人共享,其他房子的人无法获取。
4.1 函数为作用域
Python以函数为作用域,所以在函数内创建的所有数据,可以此函数中被使用,无法在其他函数中被使用。
def func():
name = "武沛齐"
data_list = [11,22,33,44]
print(name,data_list)
age = 20
print(age)
def handler():
age = 18
print(age)
func()
handler()
学会分析代码,了解变量到底属于哪个作用域且是否可以被调用:
def func():
name = "武沛齐"
age = 29
print(age)
data_list = [11,22,33,44]
print(name,data_list)
for num in range(10):
print(num)
print(num)
if 1 == 1:
value = "admin"
print(value)
print(value)
if 1 > 2:
max_num = 10
print(max_num)
print(max_num)
def handler():
age = 18
print(age)
handler()
func()
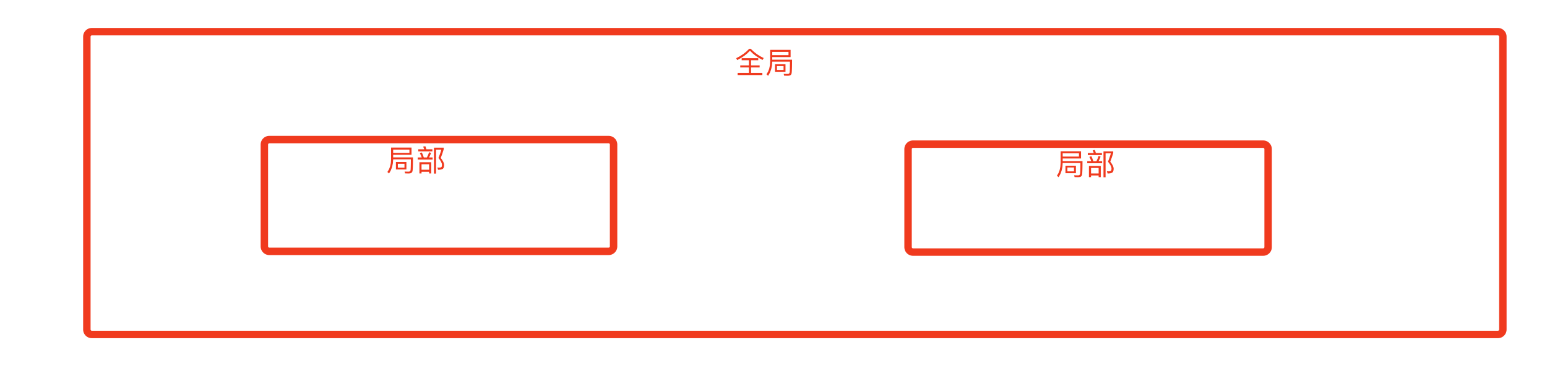
4.2 全局和局部
Python中以函数为作用域,函数的作用域其实是一个局部作用域。
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998}
]
for index in range(len(goods)):
item = goods[index]
print(index + 1, item['name'], item['price'])
while True:
num = input("请输入要选择的商品序号(Q/q):") # "1"
if num.upper() == "Q":
break
if not num.isdecimal():
print("用输入的格式错误")
break
num = int(num)
send_email()
if num > 4 or num < 0:
print("范围选择错误")
break
target_index = num - 1
choice_item = goods[target_index]
print(choice_item["name"], choice_item['price'])
send_email()
# 全局变量(变量名大写)
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
# 局部变量
url = "http://www.xxx.com"
...
def upload():
file_name = "rose.zip"
...
COUNTRY和CITY_LIST是在全局作用域中,全局作用域中创建的变量称之为【全局变量】,可以在全局作用域中被使用,也可以在其局部作用域中被使用。
download和upload函数内部维护的就是一个局部作用域,在各自函数内部创建变量称之为【局部变量】,且局部变量只能在此作用域中被使用。局部作用域中想使用某个变量时,寻找的顺序为:优先在局部作用域中寻找,如果没有则去上级作用域中寻找。
注意:全局变量一般都是大写。
示例1:在局部作用域中读取全局作用域的变量。
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
print(url)
print(COUNTRY)
print(CITY_LIST)
def upload():
file_name = "rose.zip"
print(file_name)
print(COUNTRY)
print(CITY_LIST)
print(COUNTRY)
print(CITY_LIST)
downlowd()
upload()
print(file_name) # 报错
print(url) # 报错
示例2:局部作用域和全局作用域变量同名,这算啥?
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
CITY_LIST = ["河北","河南","山西"]
print(url)
print(COUNTRY)
print(CITY_LIST)
def upload():
file_name = "rose.zip"
print(COUNTRY)
print(CITY_LIST)
print(COUNTRY)
print(CITY_LIST)
download()
upload()
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
CITY_LIST = ["河北","河南","山西"]
print(url)
print(COUNTRY)
print(CITY_LIST)
def upload():
file_name = "rose.zip"
print(COUNTRY)
print(CITY_LIST)
print(COUNTRY)
print(CITY_LIST)
download()
upload()
COUNTRY = "中华人民共和共国"
CITY_LIST = [11,22,33]
download()
upload()
# 输出
中国
["北京","上海","深圳"]
http://www.xxx.com
中国
["河北","河南","山西"]
中国
["北京","上海","深圳"]
http://www.xxx.com
中华人民共和共国
["河北","河南","山西"]
中华人民共和共国
[11,22,33]
4.3 global关键字
默认情况下,在局部作用域对全局变量只能进行:读取和修改内部元素(可变类型),无法对全局变量进行重新赋值。
-
读取
COUNTRY = "中国" CITY_LIST = ["北京","上海","深圳"] def download(): url = "http://www.xxx.com" print(COUNTRY) print(CITY_LIST) download() -
修改内部元素(可变类型)
COUNTRY = "中国" CITY_LIST = ["北京","上海","深圳"] def download(): url = "http://www.xxx.com" print(CITY_LIST) CITY_LIST.append("广州") CITY_LIST[0] = "南京" print(CITY_LIST) download() -
无法对全局变量重新赋值
COUNTRY = "中国" CITY_LIST = ["北京","上海","深圳"] def download(): url = "http://www.xxx.com" # 不是对全部变量赋值,而是在局部作用域中又创建了一个局部变量 CITY_LIST 。 CITY_LIST = ["河北","河南","山西"] print(CITY_LIST) def upload(): file_name = "rose.zip" print(COUNTRY) print(CITY_LIST) download() upload()
如果想要在局部作用域中对全局变量重新赋值,则可以基于 global关键字实现,例如:
COUNTRY = "中国"
CITY_LIST = ["北京","上海","深圳"]
def download():
url = "http://www.xxx.com"
global CITY_LIST
CITY_LIST = ["河北","河南","山西"]
print(CITY_LIST)
global COUNTRY
COUNTRY = "中华人民共和国"
print(COUNTRY)
def upload():
file_name = "rose.zip"
print(COUNTRY)
print(CITY_LIST)
download()
upload()
4.3 nolocal关键字
修改函数外层函数包含的名字对应的值(不可变类型)
name = 'root'
def outer():
name = "武沛齐"
def inner():
nonlocal name
name = 123
inner()
print(name)
outer()
print(name)
name = 'root'
def outer():
name = 'alex'
def func():
name = "武沛齐"
def inner():
nonlocal name
name = 123
inner()
print(name)
func()
print(name)
outer()
print(name)
name = 'root'
def outer():
name = 'alex'
def func():
nonlocal name
name = "武沛齐"
def inner():
nonlocal name
name = 123
inner()
print(name)
func()
print(name)
outer()
print(name)
总结
-
函数参数传递的是内存地址。
-
想重新创建一份数据再传递给参数,可以手动拷贝一份。
-
特殊:参数是动态参数时,通过*或**传参时,会将数据循环添加到参数中(类似于拷贝一份)
def fun(*args, **kwargs): print(args, kwargs) fun(*[11, 22, 33], **{"k1": 1, "k2": 2})
-
-
函数的返回值也是内存地址。(函数执行完毕后,其内部的所有变量都会被销毁,引用计数器为0时,数据也销毁)
def func(): name = [11,22,33] data = name func()def func(): name = [11,22,33] return name data = func() while True: print(data) -
当函数的参数有默认值 & 默认值是可变类型 & 函数内部会修改内部元素(有坑)
# 内部会维护一个列表 [],只要b不传值则始终使用都是这个列表。 def func(a,b=[]): b.append(a) -
定义函数写形式参数时可以使用
*和**,执行函数时也可以使用。 -
函数名其实也是个变量,他也可以做列表、字典、集合等元素(可哈希)
-
函数名可以被重新赋值,也可以做另外一个函数的参数和返回值。
-
掌握 print 和 return的区别,学会分析代码的执行流程。
-
python是以函数为作用域。
-
在局部作用域中寻找某数据时,优先用自己的,自己没有就在上级作用域中寻找。
-
基于 global关键字可以在局部作用域中实现对全局作用域中的变量(全局变量)重新赋值。
函数高级
1. 函数嵌套
Python中以函数为作用域,在作用域中定义的相关数据只能被当前作用域或子作用域使用。
NAME = "武沛齐"
print(NAME)
def func():
print(NAME)
func()
1.1 函数在作用域中
其实,函数也是定义在作用域中的数据,在执行函数时候,也同样遵循:优先在自己作用域中寻找,没有则向上一接作用域寻找,例如:
# 1. 在全局作用域定义了函数func
def func():
print("你好")
# 2. 在全局作用域找到func函数并执行。
func()
# 3.在全局作用域定义了execute函数
def execute():
print("开始")
# 优先在当前函数作用域找func函数,没有则向上级作用域中寻找。
func()
print("结束")
# 4.在全局作用域执行execute函数
execute()
此处,有一个易错点:作用域中的值在被调用时到底是啥?
-
情景1
def func(): print("你好") func() def execute(): print("开始") func() print("结束") execute() def func(): print(666) func() -
情景2
def func(): print("你好") func() def execute(): print("开始") func() print("结束") def func(): print(666) func() execute()
1.2 函数定义的位置
上述示例中的函数均定义在全局作用域,其实函数也可以定义在局部作用域,这样函数被局部作用域和其子作用于中调用(函数的嵌套)。
def func():
print("沙河高晓松")
def handler():
print("昌平吴彦祖")
def inner():
print("朝阳大妈")
inner()
func()
print("海淀网友")
handler()
到现在你会发现,只要理解数据定义时所存在的作用域,并根据从上到下代码执行过程进行分析,再怎么嵌套都可以搞定。
现在的你可能有疑问:为什么要这么嵌套定义?把函数都定义在全局不好吗?
其实,大多数情况下我们都会将函数定义在全局,不会嵌套着定义函数。不过,当我们定义一个函数去实现某功能,想要将内部功能拆分成N个函数,又担心这个N个函数放在全局会与其他函数名冲突时(尤其多人协同开发)可以选择使用函数的嵌套。
def f1():
pass
def f2():
pass
def func():
f1()
f2()
def func():
def f1():
pass
def f2():
pass
f1()
f2()
"""
生成图片验证码的示例代码,需要提前安装pillow模块(Python中操作图片中一个第三方模块)
pip3 install pillow
"""
import random
from PIL import Image, ImageDraw, ImageFont
def create_image_code(img_file_path, text=None, size=(120, 30), mode="RGB", bg_color=(255, 255, 255)):
""" 生成一个图片验证码 """
_letter_cases = "abcdefghjkmnpqrstuvwxy" # 小写字母,去除可能干扰的i,l,o,z
_upper_cases = _letter_cases.upper() # 大写字母
_numbers = ''.join(map(str, range(3, 10))) # 数字
chars = ''.join((_letter_cases, _upper_cases, _numbers))
width, height = size # 宽高
# 创建图形
img = Image.new(mode, size, bg_color)
draw = ImageDraw.Draw(img) # 创建画笔
def get_chars():
"""生成给定长度的字符串,返回列表格式"""
return random.sample(chars, 4)
def create_lines():
"""绘制干扰线"""
line_num = random.randint(*(1, 2)) # 干扰线条数
for i in range(line_num):
# 起始点
begin = (random.randint(0, size[0]), random.randint(0, size[1]))
# 结束点
end = (random.randint(0, size[0]), random.randint(0, size[1]))
draw.line([begin, end], fill=(0, 0, 0))
def create_points():
"""绘制干扰点"""
chance = min(100, max(0, int(2))) # 大小限制在[0, 100]
for w in range(width):
for h in range(height):
tmp = random.randint(0, 100)
if tmp > 100 - chance:
draw.point((w, h), fill=(0, 0, 0))
def create_code():
"""绘制验证码字符"""
if text:
code_string = text
else:
char_list = get_chars()
code_string = ''.join(char_list) # 每个字符前后以空格隔开
# Win系统字体
# font = ImageFont.truetype(r"C:\Windows\Fonts\SEGOEPR.TTF", size=24)
# Mac系统字体
# font = ImageFont.truetype("/System/Library/Fonts/SFNSRounded.ttf", size=24)
# 项目字体文件
font = ImageFont.truetype("MSYH.TTC", size=15)
draw.text([0, 0], code_string, "red", font=font)
return code_string
create_lines()
create_points()
code = create_code()
# 将图片写入到文件
with open(img_file_path, mode='wb') as img_object:
img.save(img_object)
return code
code = create_image_code("a2.png")
print(code)
1.3 嵌套引发的作用域问题
基于内存和执行过程分析作用域。
name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
inner()
run()

name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return inner
v1 = run()
v1()
v2 = run()
v2()

name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return [inner,inner,inner]
func_list = run()
func_list[2]()
func_list[1]()
funcs = run()
funcs[2]()
funcs[1]()
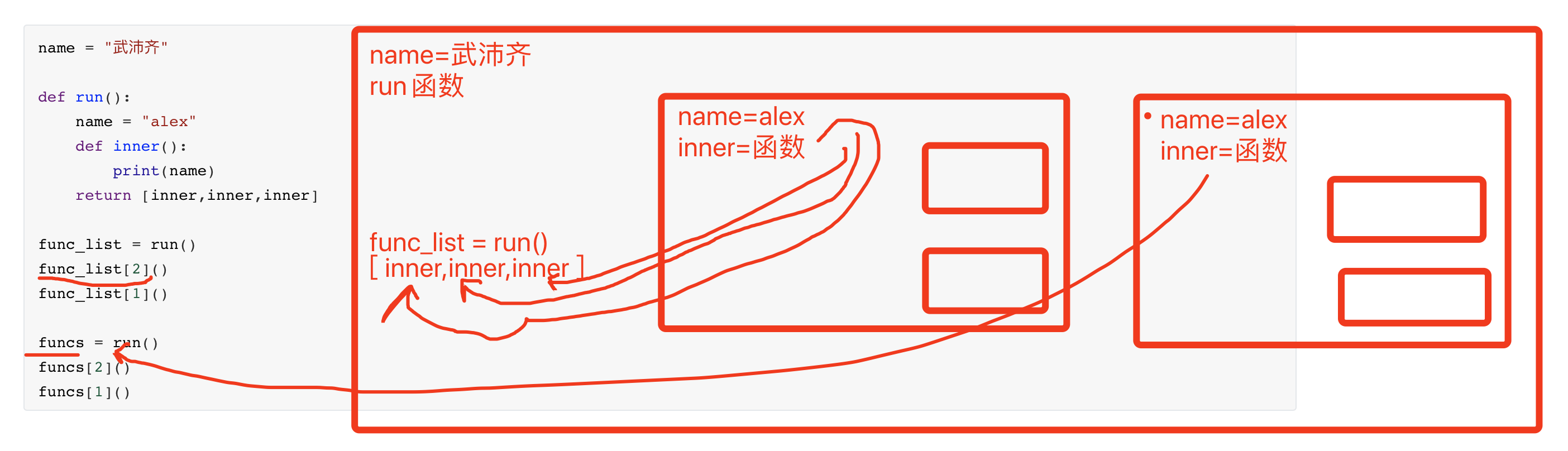
三句话搞定作用域:
- 优先在自己的作用域找,自己没有就去上级作用域。
- 在作用域中寻找值时,要确保此次此刻值是什么。
- 分析函数的执行,并确定函数
作用域链。(函数嵌套)
2.闭包
闭包,简而言之就是将数据封装在一个包(区域)中,使用时再去里面取。(本质上 闭包是基于函数嵌套搞出来一个中特殊嵌套)
-
闭包应用场景1:封装数据防止污染全局。
name = "武沛齐" def f1(): print(name, age) def f2(): print(name, age) def f3(): print(name, age) def f4(): passdef func(age): name = "武沛齐" def f1(): print(name, age) def f2(): print(name, age) def f3(): print(name, age) f1() f2() f3() func(123) -
闭包应用场景2:封装数据封到一个包里,使用时在取。
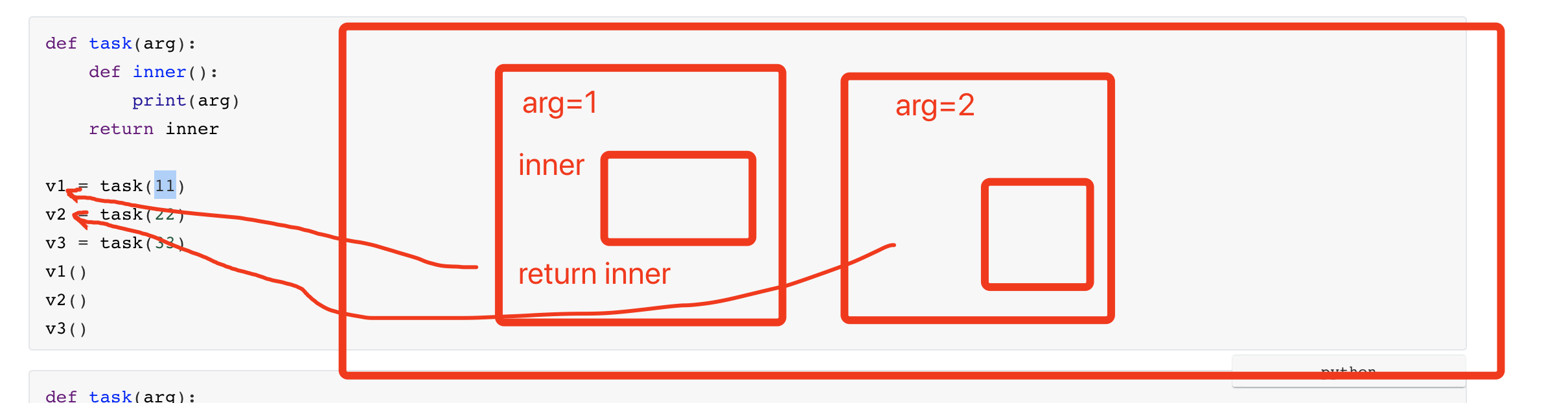
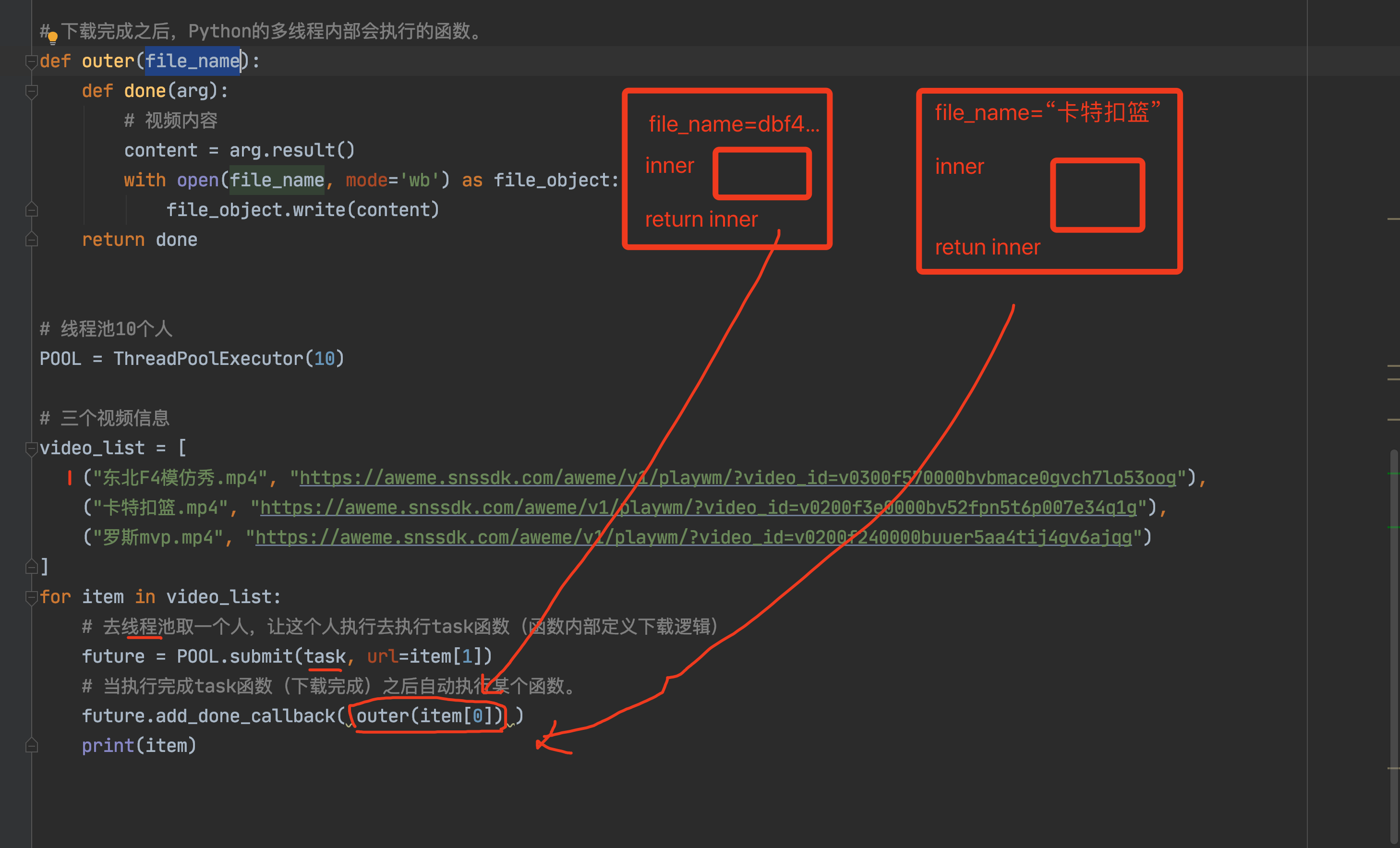
def task(arg): def inner(): print(arg) return inner v1 = task(11) v2 = task(22) v3 = task(33) v1() v2() v3()def task(arg): def inner(): print(arg) return inner inner_func_list = [] for val in [11,22,33]: inner_func_list.append( task(val) ) inner_func_list[0]() # 11 inner_func_list[1]() # 22 inner_func_list[2]() # 33""" 基于多线程去下载视频 """ from concurrent.futures.thread import ThreadPoolExecutor import requests def download_video(url): res = requests.get( url=url, headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) return res.content def outer(file_name): def write_file(response): content = response.result() with open(file_name, mode='wb') as file_object: file_object.write(content) return write_file POOL = ThreadPoolExecutor(10) video_dict = [ ("东北F4模仿秀.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"), ("卡特扣篮.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"), ("罗斯mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg") ] for item in video_dict: future = POOL.submit(download_video, url=item[1]) future.add_done_callback(outer(item[0])) POOL.shutdown()
3.装饰器
现在给你一个函数,在不修改函数源码的前提下,实现在函数执行前和执行后分别输入 "before" 和 "after"。
def func():
print("我是func函数")
value = (11,22,33,44)
return value
result = func()
print(result)
3.1 第一回合
你的实现思路:
def func():
print("before")
print("我是func函数")
value = (11,22,33,44)
print("after")
return value
result = func()
我的实现思路:
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
def outer(origin):
def inner():
print('inner')
origin()
print("after")
return inner
func = outer(func)
result = func()
处理返回值:
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
def outer(origin):
def inner():
print('inner')
res = origin()
print("after")
return res
return inner
func = outer(func)
result = func()
3.2 第二回合
在Python中有个一个特殊的语法糖:
def outer(origin):
def inner():
print('inner')
res = origin()
print("after")
return res
return inner
@outer
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
func()
3.3 第三回合
请在这3个函数执行前和执行后分别输入 "before" 和 "after"
def func1():
print("我是func1函数")
value = (11, 22, 33, 44)
return value
def func2():
print("我是func2函数")
value = (11, 22, 33, 44)
return value
def func3():
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1()
func2()
func3()
你的实现思路:
def func1():
print('before')
print("我是func1函数")
value = (11, 22, 33, 44)
print("after")
return value
def func2():
print('before')
print("我是func2函数")
value = (11, 22, 33, 44)
print("after")
return value
def func3():
print('before')
print("我是func3函数")
value = (11, 22, 33, 44)
print("after")
return value
func1()
func2()
func3()
我的实现思路:
def outer(origin):
def inner():
print("before 110")
res = origin() # 调用原来的func函数
print("after")
return res
return inner
@outer
def func1():
print("我是func1函数")
value = (11, 22, 33, 44)
return value
@outer
def func2():
print("我是func2函数")
value = (11, 22, 33, 44)
return value
@outer
def func3():
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1()
func2()
func3()
装饰器,在不修改原函数内容的前提下,通过@函数可以实现在函数前后自定义执行一些功能(批量操作会更有意义)。
优化
优化以支持多个参数的情况。
def outer(origin):
def inner(*args, **kwargs):
print("before 110")
res = origin(*args, **kwargs) # 调用原来的func函数
print("after")
return res
return inner
@outer # func1 = outer(func1)
def func1(a1):
print("我是func1函数")
value = (11, 22, 33, 44)
return value
@outer # func2 = outer(func2)
def func2(a1, a2):
print("我是func2函数")
value = (11, 22, 33, 44)
return value
@outer # func3 = outer(func3)
def func3(a1):
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1(1)
func2(11, a2=22)
func3(999)
其中,我的那种写法就称为装饰器。
-
实现原理:基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行函数时再在内层函数中执行闭包中的原函数。
-
实现效果:可以在不改变原函数内部代码 和 调用方式的前提下,实现在函数执行和执行扩展功能。
-
适用场景:多个函数系统统一在 执行前后自定义一些功能。
-
装饰器示例
def outer(origin): def inner(*args, **kwargs): # 执行前 res = origin(*args, **kwargs) # 调用原来的func函数 # 执行后 return res return inner @outer def func(): pass func()
伪应用场景
在以后编写一个网站时,如果项目共有100个页面,其中99个是需要登录成功之后才有权限访问,就可以基于装饰器来实现。
pip3 install flask
基于第三方模块Flask(框架)快速写一个网站:
from flask import Flask
app = Flask(__name__)
def index():
return "首页"
def info():
return "用户中心"
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index)
app.add_url_rule("/info/", view_func=info)
app.add_url_rule("/login/", view_func=login)
app.run()
基于装饰器实现的伪代码:
from flask import Flask
app = Flask(__name__)
def auth(func):
def inner(*args, **kwargs):
# 在此处,判断如果用户是否已经登录,已登录则继续往下,未登录则自动跳转到登录页面。
return func(*args, **kwargs)
return inner
@auth
def index():
return "首页"
@auth
def info():
return "用户中心"
@auth
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index, endpoint='index')
app.add_url_rule("/info/", view_func=info, endpoint='info')
app.add_url_rule("/order/", view_func=order, endpoint='order')
app.add_url_rule("/login/", view_func=login, endpoint='login')
app.run()
重要补充:functools
你会发现装饰器实际上就是将原函数更改为其他的函数,然后再此函数中再去调用原函数。
def handler():
pass
handler()
print(handler.__name__) # handler
def auth(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # inner
import functools
def auth(func):
@functools.wraps(func)
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # handler
其实,一般情况下大家不用functools也可以实现装饰器的基本功能,但后期在项目开发时,不加functools会出错(内部会读取__name__,且__name__重名的话就报错),所以在此大家就要规范起来自己的写法。
import functools
def auth(func):
@functools.wraps(func)
def inner(*args, **kwargs):
"""巴巴里吧"""
res = func(*args, **kwargs) # 执行原函数
return res
return inner
总结
-
函数可以定义在全局、也可以定义另外一个函数中(函数的嵌套)
-
学会分析函数执行的步骤(内存中作用域的管理)
-
闭包,基于函数的嵌套,可以将数据封装到一个包中,以后再去调用。
-
装饰器
-
实现原理:基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行函数时再在内层函数中执行闭包中的原函数。
-
实现效果:可以在不改变原函数内部代码 和 调用方式的前提下,实现在函数执行和执行扩展功能。
-
适用场景:多个函数系统统一在 执行前后自定义一些功能。
-
装饰器示例
import functools def auth(func): @functools.wraps(func) def inner(*args, **kwargs): """巴巴里吧""" res = func(*args, **kwargs) # 执行原函数 return res return inner
-
内置函数和推导式
1. 匿名函数
传统的函数的定义包括了:函数名 + 函数体。
def send_email():
pass
# 1. 执行
send_email()
# 2. 当做列表元素
data_list = [send_email, send_email, send_email ]
# 3. 当做参数传递
other_function(send_email)
匿名函数,则是基于lambda表达式实现定义一个可以没有名字的函数,例如:
data_list = [ lambda x:x+100, lambda x:x+110, lambda x:x+120 ]
print( data_list[0] )
f1 = lambda x:x+100
res = f1(100)
print(res)
基于Lambda定义的函数格式为:lambda 参数:函数体
-
参数,支持任意参数。
lambda x: 函数体 lambda x1,x2: 函数体 lambda *args, **kwargs: 函数体 -
函数体,只能支持单行的代码。
def xxx(x): return x + 100 lambda x: x + 100 -
返回值,默认将函数体单行代码执行的结果返回给函数的执行这。
func = lambda x: x + 100 v1 = func(10) print(v1) # 110
def func(a1,a2):
return a1 + a2 + 100
foo = lambda a1,a2: a1 + a2 + 100
匿名函数适用于简单的业务处理,可以快速并简单的创建函数。
练习题
根据函数写写出其匿名函数的表达方式
def func(a1,a2):
return a1 + a2
func = lambda a1,a2: a1+a2
def func(data):
return data.replace("苍老师","***")
func= lambda data: data.replace("苍老师","***")
def func(data):
name_list = data.replace(".")
return name_list[-1]
func = lambda data: data.replace(".")[-1]
在编写匿名函数时,由于受限 函数体只能写一行,所以匿名函数只能处理非常简单的功能。
扩展:三元运算
简单的函数,可以基于lambda表达式实现。
简单的条件语句,可以基于三元运算实现,例如:
num = input("请写入内容")
if "苍老师" in num:
data = "臭不要脸"
else:
data = "正经人"
print(data)
num = input("请写入内容")
data = "臭不要脸" if "苍老师" in num else "正经人"
print(data)
# 结果 = 条件成立时 if 条件 else 不成立
lambda表达式和三元运算没有任何关系,属于两个独立的知识点。
掌握三元运算之后,以后再编写匿名函数时,就可以处理再稍微复杂点的情况了,例如:
func = lambda x: "大了" if x > 66 else "小了"
v1 = func(1)
print(v1) # "小了"
v2 = func(100)
print(v2) # "大了"
2. 生成器
生成器是由函数+yield关键字创造出来的写法,在特定情况下,用他可以帮助我们节省内存。
-
生成器函数,但函数中有yield存在时,这个函数就是生产生成器函数。
def func(): print(111) yield 1def func(): print(111) yield 1 print(222) yield 2 print(333) yield 3 print(444) -
生成器对象,执行生成器函数时,会返回一个生成器对象。
def func(): print(111) yield 1 print(222) yield 2 print(333) yield 3 print(444) data = func() # 执行生成器函数func,返回的生成器对象。 # 注意:执行生成器函数时,函数内部代码不会执行。def func(): print(111) yield 1 print(222) yield 2 print(333) yield 3 print(444) data = func() v1 = next(data) print(v1) v2 = next(data) print(v2) v3 = next(data) print(v3) v4 = next(data) print(v4) # 结束或中途遇到return,程序爆:StopIteration 错误data = func() for item in data: print(item)
生成器的特点是,记录在函数中的执行位置,下次执行next时,会从上一次的位置基础上再继续向下执行。
应用场景
-
假设要让你生成 300w个随机的4位数,并打印出来。
- 在内存中一次性创建300w个
- 动态创建,用一个创建一个。
import random val = random.randint(1000, 9999) print(val)import random data_list = [] for i in range(300000000): val = random.randint(1000, 9999) data_list.append(val) # 再使用时,去 data_list 中获取即可。 # ...import random def gen_random_num(max_count): counter = 0 while counter < max_count: yield random.randint(1000, 9999) counter += 1 data_list = gen_random_num(3000000) # 再使用时,去 data_list 中获取即可。 -
假设让你从某个数据源中获取300w条数据(后期学习操作MySQL 或 Redis等数据源再操作,了解思想即可)。
所以,当以后需要我们在内存中创建很多数据时,可以想着用基于生成器来实现一点一点生成(用一点生产一点),以节省内存的开销。
扩展
def func():
print(111)
v1 = yield 1
print(v1)
print(222)
v2 = yield 2
print(v2)
print(333)
v3 = yield 3
print(v3)
print(444)
data = func()
n1 = data.send(None)
print(n1)
n2 = data.send(666)
print(n2)
n3 = data.send(777)
print(n3)
n4 = data.send(888)
print(n4)
yield from
在生成器部分我们了解了yield关键字,其在python3.3之后有引入了一个yield from。
def foo():
yield 2
yield 2
yield 2
def func():
yield 1
yield 1
yield 1
yield from foo() # 执行func函数时可以跳转到foo函数继续执行
yield 1
yield 1
for item in func():
print(item)
3.内置函数
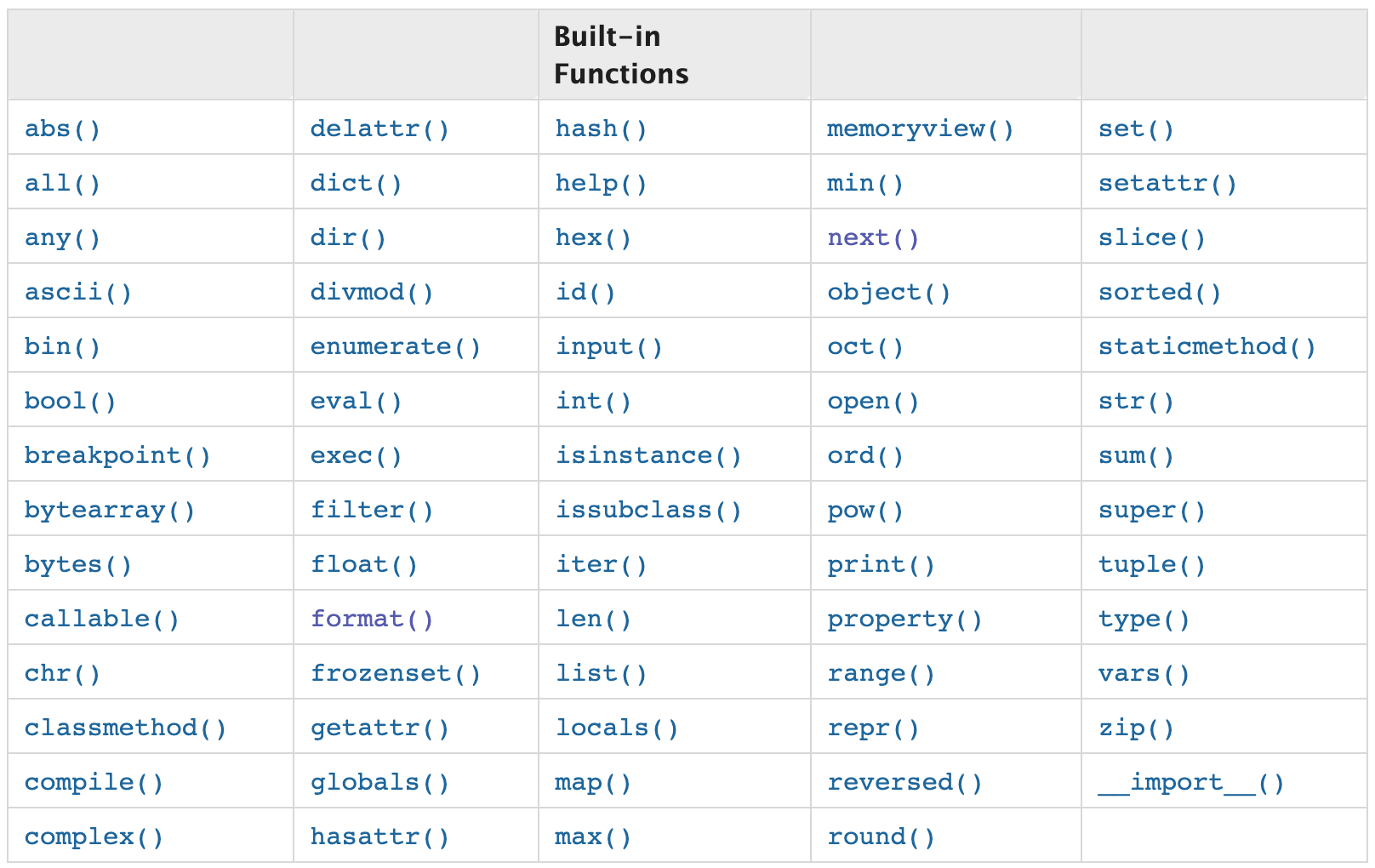
Python内部为我们提供了很多方便的内置函数,在此整理出来36个给大家来讲解。
-
第1组(5个)
-
abs,绝对值
v = abs(-10) -
pow,指数
v1 = pow(2,5) # 2的5次方 2**5 print(v1) -
sum,求和
v1 = sum([-11, 22, 33, 44, 55]) # 可以被迭代-for循环 print(v1) -
divmod,求商和余数
v1, v2 = divmod(9, 2) print(v1, v2) -
round,小数点后n位(四舍五入)
v1 = round(4.11786, 2) print(v1) # 4.12
-
-
第2组:(4个)
-
min,最小值
v1 = min(11, 2, 3, 4, 5, 56) print(v1) # 2v2 = min([11, 22, 33, 44, 55]) # 迭代的类型(for循环) print(v2)v3 = min([-11, 2, 33, 44, 55], key=lambda x: abs(x)) print(v3) # 2 -
max,最大值
v1 = max(11, 2, 3, 4, 5, 56) print(v1) v2 = max([11, 22, 33, 44, 55]) print(v2)v3 = max([-11, 22, 33, 44, 55], key=lambda x: x * 10) print(v3) # 55 -
all,是否全部为True
v1 = all( [11,22,44,""] ) # False -
any,是否存在True
v2 = any([11,22,44,""]) # True
-
-
第3组(3个)
- bin,十进制转二进制
- oct,十进制转八进制
- hex,十进制转十六进制
-
第4组(2个)
-
ord,获取字符对应的unicode码点(十进制)
v1 = ord("武") print(v1, hex(v1)) -
chr,根据码点(十进制)获取对应字符
v1 = chr(27494) print(v1)
-
-
第5组(9个)
-
int
-
foat
-
str,unicode编码
-
bytes,utf-8、gbk编码
v1 = "武沛齐" # str类型 v2 = v1.encode('utf-8') # bytes类型 v3 = bytes(v1,encoding="utf-8") # bytes类型 -
bool
-
list
-
dict
-
tuple
-
set
-
-
第6组(13个)
-
len
-
print
-
input
-
open
-
type,获取数据类型
v1 = "123" if type(v1) == str: pass else: pass -
range
range(10) -
enumerate
v1 = ["武沛齐", "alex", 'root'] for num, value in enumerate(v1, 1): print(num, value) -
id
-
hash
v1 = hash("武沛齐") -
help,帮助信息
- pycharm,不用
- 终端,使用
-
zip
v1 = [11, 22, 33, 44, 55, 66] v2 = [55, 66, 77, 88] v3 = [10, 20, 30, 40, 50] result = zip(v1, v2, v3) for item in result: print(item) -
callable,是否可执行,后面是否可以加括号。
v1 = "武沛齐" v2 = lambda x: x def v3(): pass print( callable(v1) ) # False print(callable(v2)) print(callable(v3)) -
sorted,排序
v1 = sorted([11,22,33,44,55])info = { "wupeiqi": { 'id': 10, 'age': 119 }, "root": { 'id': 20, 'age': 29 }, "seven": { 'id': 9, 'age': 9 }, "admin": { 'id': 11, 'age': 139 }, } result = sorted(info.items(), key=lambda x: x[1]['id']) print(result)data_list = [ '1-5 编译器和解释器.mp4', '1-17 今日作业.mp4', '1-9 Python解释器种类.mp4', '1-16 今日总结.mp4', '1-2 课堂笔记的创建.mp4', '1-15 Pycharm使用和破解(win系统).mp4', '1-12 python解释器的安装(mac系统).mp4', '1-13 python解释器的安装(win系统).mp4', '1-8 Python介绍.mp4', '1-7 编程语言的分类.mp4', '1-3 常见计算机基本概念.mp4', '1-14 Pycharm使用和破解(mac系统).mp4', '1-10 CPython解释器版本.mp4', '1-1 今日概要.mp4', '1-6 学习编程本质上的三件事.mp4', '1-18 作业答案和讲解.mp4', '1-4 编程语言.mp4', '1-11 环境搭建说明.mp4' ] result = sorted(data_list, key=lambda x: int(x.split(' ')[0].split("-")[-1]) ) print(result)
-
4.推导式
推导式是Python中提供了一个非常方便的功能,可以让我们通过一行代码实现创建list、dict、tuple、set 的同时初始化一些值。
请创建一个列表,并在列表中初始化:0、1、2、3、4、5、6、7、8、9...299 整数元素。
data = []
for i in range(300):
data.append(i)
-
列表
num_list = [ i for i in range(10)] num_list = [ [i,i] for i in range(10)] num_list = [ [i,i] for i in range(10) if i > 6 ] -
集合
num_set = { i for i in range(10)} num_set = { (i,i,i) for i in range(10)} num_set = { (i,i,i) for i in range(10) if i>3} -
字典
num_dict = { i:i for i in range(10)} num_dict = { i:(i,11) for i in range(10)} num_dict = { i:(i,11) for i in range(10) if i>7} -
元组,不同于其他类型。
# 不会立即执行内部循环去生成数据,而是得到一个生成器。 data = (i for i in range(10)) print(data) for item in data: print(item)
练习题
-
去除列表中每个元素的
.mp4后缀。data_list = [ '1-5 编译器和解释器.mp4', '1-17 今日作业.mp4', '1-9 Python解释器种类.mp4', '1-16 今日总结.mp4', '1-2 课堂笔记的创建.mp4', '1-15 Pycharm使用和破解(win系统).mp4', '1-12 python解释器的安装(mac系统).mp4', '1-13 python解释器的安装(win系统).mp4', '1-8 Python介绍.mp4', '1-7 编程语言的分类.mp4', '1-3 常见计算机基本概念.mp4', '1-14 Pycharm使用和破解(mac系统).mp4', '1-10 CPython解释器版本.mp4', '1-1 今日概要.mp4', '1-6 学习编程本质上的三件事.mp4', '1-18 作业答案和讲解.mp4', '1-4 编程语言.mp4', '1-11 环境搭建说明.mp4' ] result = [] for item in data_list: result.append(item.rsplit('.',1)[0]) result = [ item.rsplit('.',1)[0] for item in data_list] -
将字典中的元素按照
键-值格式化,并最终使用;连接起来。info = { "name":"武沛齐", "email":"xxx@live.com", "gender":"男", } data_list [] for k,v in info.items(): temp = "{}-{}".format(k,v) temp.append(data_list) resutl = ";".join(data) result = ";".join( [ "{}-{}".format(k,v) for k,v in info.items()] ) -
将字典按照键从小到大排序,然后在按照如下格式拼接起来。(微信支付API内部处理需求)
info = { 'sign_type': "MD5", 'out_refund_no': "12323", 'appid': 'wx55cca0b94f723dc7', 'mch_id': '1526049051', 'out_trade_no': "ffff", 'nonce_str': "sdfdffd", 'total_fee': 9901, 'refund_fee': 10000 } data = "&".join(["{}={}".format(key, value) for key, value in sorted(info.items(), key=lambda x: x[0])]) print(data) -
看代码写结果
def func(): print(123) data_list = [func for i in range(10)] print(data_list) -
看代码写结果
def func(num): return num + 100 data_list = [func(i) for i in range(10)] print(data_list) -
看代码写结果(执行出错,通过他可以让你更好的理解执行过程)
def func(x): return x + i data_list = [func for i in range(10)] val = data_list[0](100) print(val) -
看代码写结果(新浪微博面试题)
data_list = [lambda x: x + i for i in range(10)] # [函数,函数,函数] i=9 v1 = data_list[0](100) v2 = data_list[3](100) print(v1, v2) # 109 109
小高级
-
推导式支持嵌套
data = [ i for i in range(10)]data = [ (i,j) for j in range(5) for i in range(10)] data = [] for i in range(10): for j in range(5): data.append( (i,j) ) data = [ [i, j] for j in range(5) for i in range(10)]# 一副扑克牌 poker_list = [ (color,num) for num in range(1,14) for color in ["红桃", "黑桃", "方片", "梅花"]] poker_list = [ [color, num] for num in range(1, 14) for color in ["红桃", "黑桃", "方片", "梅花"]] print(poker_list) -
烧脑面试题
def num(): return [lambda x: i * x for i in range(4)] # 1. num()并获取返回值 [函数,函数,函数,函数] i=3 # 2. for循环返回值 # 3. 返回值的每个元素(2) result = [m(2) for m in num()] # [6,6,6,6] print(result)def num(): return (lambda x: i * x for i in range(4)) # 1. num()并获取返回值 生成器对象 # 2. for循环返回值 # 3. 返回值的每个元素(2) result = [m(2) for m in num()] # [0,2,4,6 ] print(result)
总结
- 匿名函数,基于lambda表达式实现一行创建一个函数。一般用于编写简单的函数。
- 三元运算,用一行代码实现处理简单的条件判断和赋值。
- 生成器,函数中如果yield关键字
- 生成器函数
- 生成器对象
- 执行生成器函数中的代码
- next
- for(常用)
- send
- 内置函数(36个)
- 推导式
- 常规操作
- 小高级操作
深浅拷贝 👍
-
浅拷贝
-
不可变类型,不拷贝。
import copy v1 = "武沛齐" print(id(v1)) # 140652260947312 v2 = copy.copy(v1) print(id(v2)) # 140652260947312按理说拷贝v1之后,v2的内存地址应该不同,但由于python内部优化机制,内存地址是相同的,因为对不可变类型而言,如果以后修改值,会重新创建一份数据,不会影响原数据,所以,不拷贝也无妨。
-
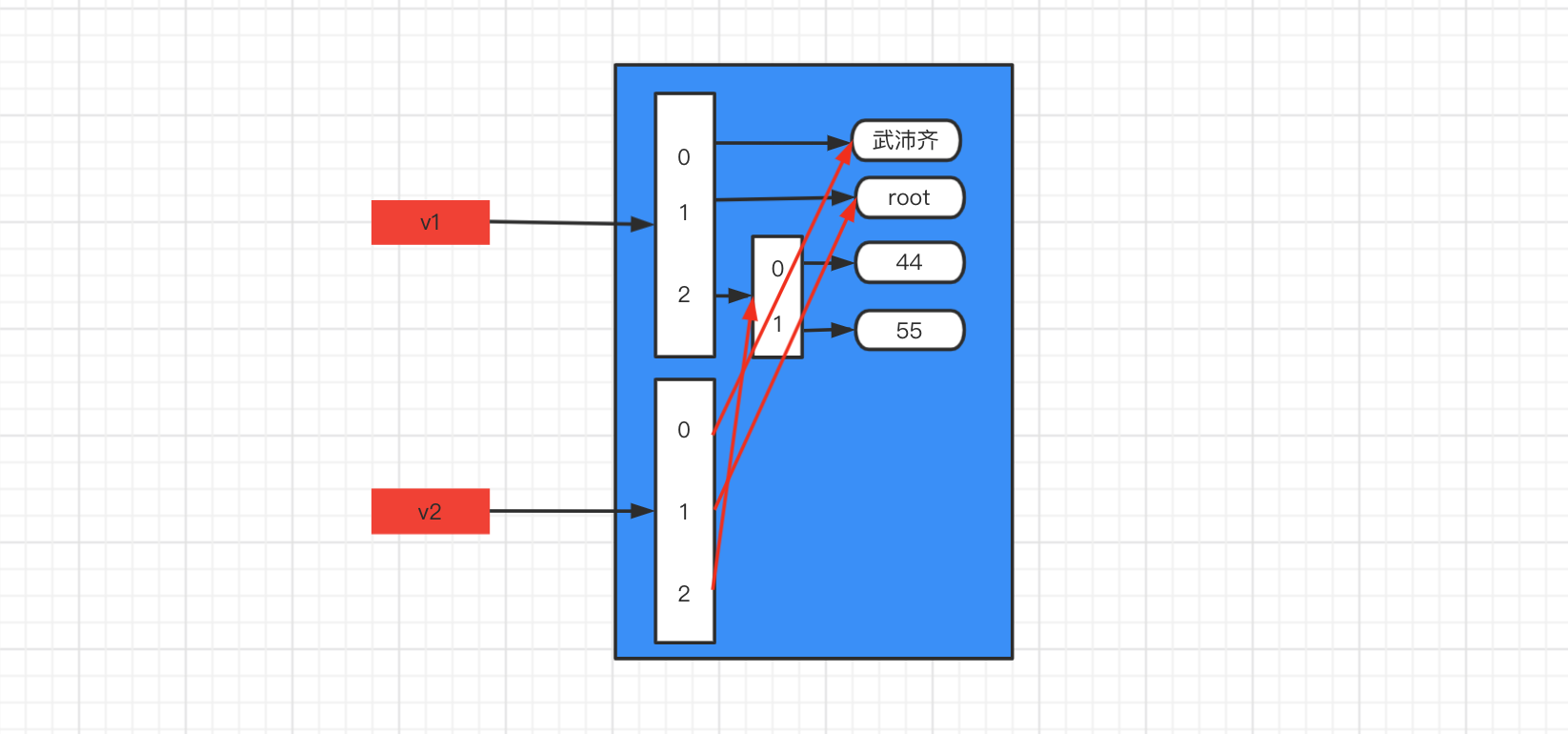
可变类型,只拷贝第一层。
import copy v1 = ["武沛齐", "root", [44, 55]] print(id(v1)) # 140405837216896 print(id(v1[2])) # 140405837214592 v2 = copy.copy(v1) print(id(v2)) # 140405837214784 print(id(v2[2])) # 140405837214592
-
-
深拷贝
-
不可变类型,不拷贝
import copy v1 = "武沛齐" print(id(v1)) # 140188538697072 v2 = copy.deepcopy(v1) print(id(v2)) # 140188538697072特殊的元组:
-
元组元素中无可变类型,不拷贝
import copy v1 = ("武沛齐", "root") print(id(v1)) # 140243298961984 v2 = copy.deepcopy(v1) print(id(v2)) # 140243298961984 -
元素元素中有可变类型,找到所有【可变类型】或【含有可变类型的元组】 均拷贝一份
import copy v1 = ("武沛齐", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]) v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784
-
-
可变类型,找到所有层级的 【可变类型】或【含有可变类型的元组】 均拷贝一份
import copy v1 = ["武沛齐", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]] v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784import copy v1 = ["武沛齐", "root", [44, 55]] v2 = copy.deepcopy(v1) print(id(v1)) # 140405837216896 print(id(v2)) # 140405837214784 print(id(v1[2])) # 140563140392256 print(id(v2[2])) # 140563140535744
-
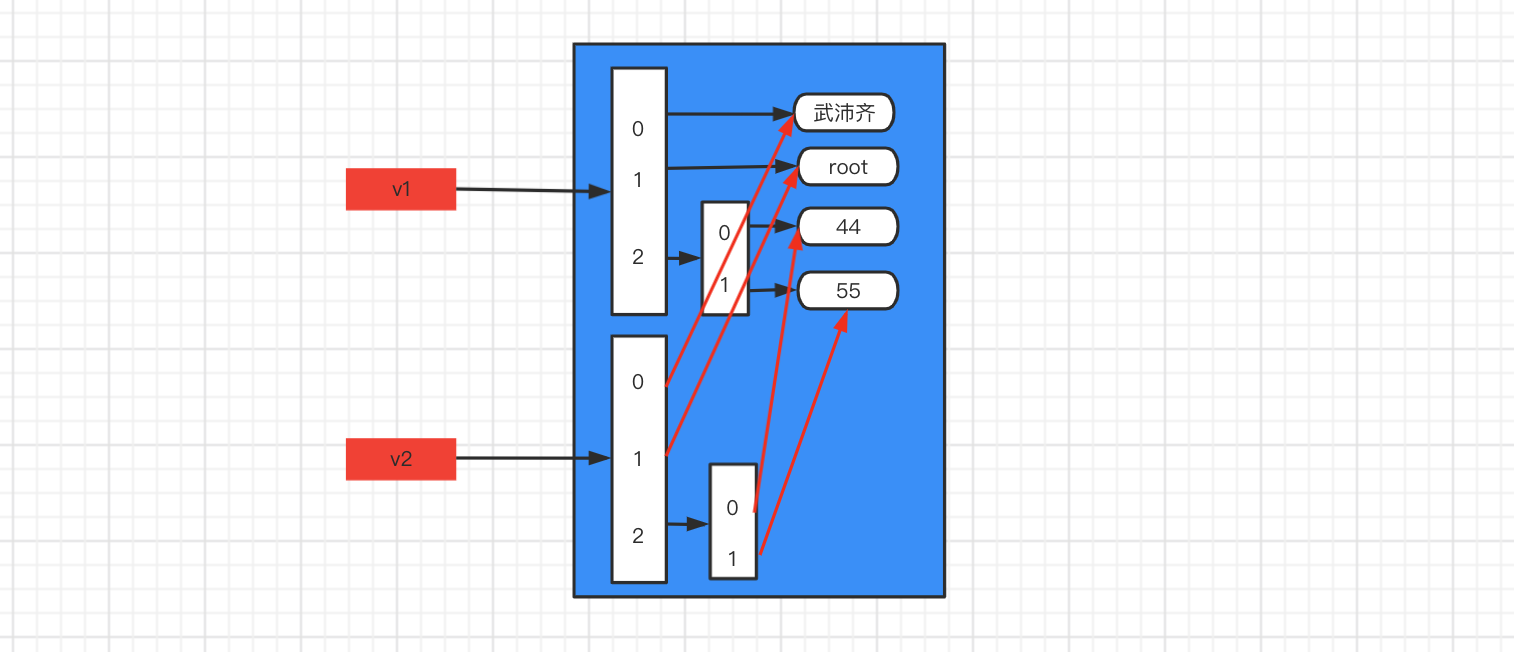

 浙公网安备 33010602011771号
浙公网安备 33010602011771号