
数据类型
1.整型
整型其实就是十进制整数的统称,比如:1、68、999都属于整型。他一般用于表示 年龄、序号等。
1.1 定义
number = 10
age = 99
1.2 独有功能
无
v1 = 5
print(bin(v1)) # 0b101
# 调用v1(int)的独有功能,获取v1的二进制有多少个位组成。
result1 = v1.bit_length()
print(result1) # 3
v2 = 10
print(bin(10)) # 0b1010
# 调用v2(int)的独有功能,获取v2的二进制有多少个位组成。
result2 = v2.bit_length()
print(result2) # 4
1.3 公共功能
加减乘除
v1 = 4
v2 = 8
v3 = v1 + v2
1.4 转换
在项目开发和面试题中经常会出现一些 "字符串" 和 布尔值 转换为 整型的情况。
# 布尔值转整型
n1 = int(True) # True转换为整数 1
n2 = int(False) # False转换为整数 0
# 字符串转整型
v1 = int("186",base=10) # 把字符串看成十进制的值,然后再转换为 十进制整数,结果:v1 = 186
v2 = int("0b1001",base=2) # 把字符串看成二进制的值,然后再转换为 十进制整数,结果:v1 = 9 (0b表示二进制)
v3 = int("0o144",base=8) # 把字符串看成八进制的值,然后转换为 十进制整数,结果:v1 = 100 (0o表示八进制)
v4 = int("0x59",base=16) # 把字符串看成十六进制的值,然后转换为 十进制整数,结果:v1 = 89 (0x表示十六进制)
# 浮点型(小数)
v1 = int(8.7) # 8
所以,如果以后别人给你一个按 二进制、八进制、十进制、十六进制 规则存储的字符串时,可以轻松的通过int转换为十进制的整数。
1.5 其他
1.5.1 长整型
- Python3:整型(无限制)
- Python2:整型、长整形
在python2中跟整数相关的数据类型有两种:int(整型)、long(长整型),他们都是整数只不过能表示的值范围不同。
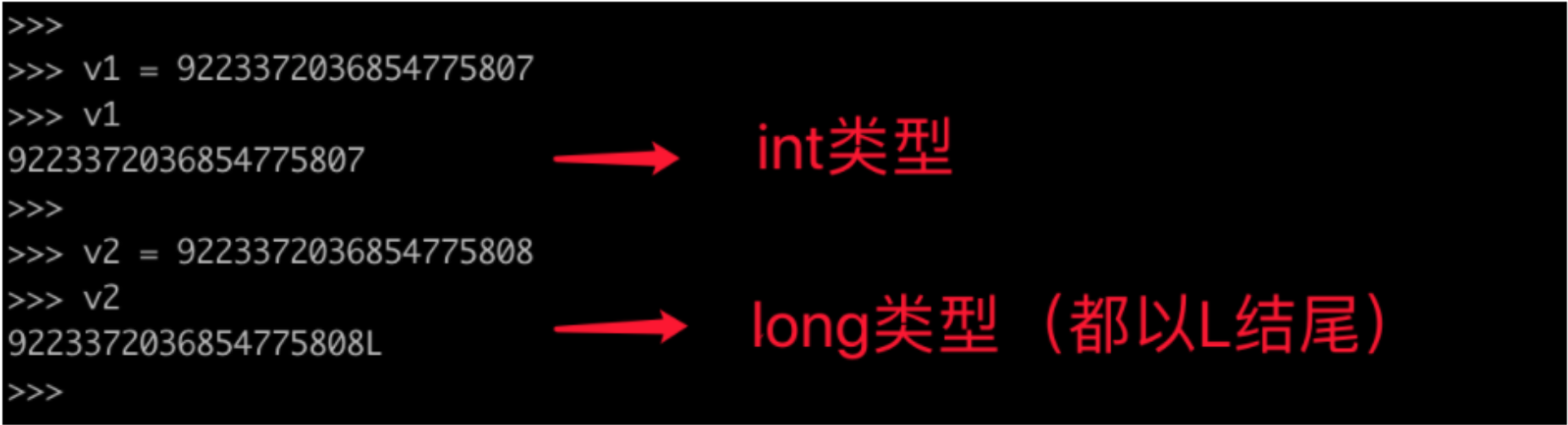
- int,可表示的范围:-9223372036854775808~9223372036854775807
- long,整数值超出int范围之后自动会转换为long类型(无限制)。
在python3中去除了long只剩下:int(整型),并且 int 长度不在限制。
1.5.2 地板除
-
Py3:
v1 = 9/2 print(v1) # 4.5 -
py2:
v1 = 9/2 print(v1) # 4from __future__ import division v1 = 9/2 print(v1) # 4.5
2. 布尔类型
布尔值,其实就是 “真”、“假” 。
2.1 定义
data = False
alex_is_sb = True
2.2 独有功能
无
2.3 公共功能
无
v1 = True + True
print(v1) # 2
2.4 转换
在以后的项目开发中,会经常使用其他类型转换为布尔值的情景,此处只要记住一个规律即可。
整数0、空字符串、空列表、空元组、空字典转换为布尔值时均为False
其他均为True
# 练习题:查看一些变量为True还是False
v1 = bool(0)
v2 = bool(-10)
v3 = bool(10)
v4 = bool("武沛齐")
v5 = bool("")
v6 = bool(" ")
v7 = bool([]) # [] 表示空列表
v8 = bool([11,22,33]) # [11,22,33] 表示非空列表
v9 = bool({}) # {} 表示空字典
v10 = bool({"name":"武沛齐","age":18}) # {"name":"武沛齐","age":18} 表示非空字典
2.5 其他
2.5.1 做条件自动转换
如果在 if 、while 条件后面写一个值当做条件时,他会默认转换为布尔类型,然后再做条件判断。
if 0:
print("太六了")
else:
print(999)
if "武沛齐":
print("你好")
if "alex":
print("你是傻逼?")
else:
print("你是逗比?")
while 1>9:
pass
if 值:
pass
while 值:
pass
3.字符串类型
字符串,我们平时会用他来表示文本信息。例如:姓名、地址、自我介绍等。
3.1 定义
v1 = "包治百病"
v2 = '包治百病'
v3 = "包'治百病"
v4 = '包"治百病'
v5 = """
吵架都是我的错,
因为大家打不过。
"""
# 三个引号,可以支持多行/换行表示一个字符串,其他的都只能在一行中表示一个字符串。
3.2 独有功能(18/48)
"xxxxx".功能(...)
v1 = "xxxxx"
v1.功能(...)
-
判断字符串是否以 XX 开头?得到一个布尔值
v1 = "叨逼叨的一天,烦死了" # True result = v1.startswith("叨逼叨的一天") print(result) # 值为True# 案例 v1 = input("请输入住址:") if v1.startswith("北京市"): print("北京人口") else: print("非北京人口") -
判断字符串是否以 XX 结尾?得到一个布尔值
v1 = "叨逼叨的一天,烦死了" result = v1.endswith("烦死了") print(result) # 值为True# 案例 address = input("请输入地址:") if address.endswith('村'): print("农业户口") else: print("非农户口") -
判断字符串是否为十进制数?得到一个布尔值
v1 = "1238871" result = v1.isdecimal() print(result) # True# 案例,两个数相加。 v1 = input("请输入值:") # ”666“ v2 = input("请输入值:") # ”999“ if v1.isdecimal() and v2.isdecimal(): data = int(v1) + int(v2) print(data) else: print("请正确输入数字")v1 = "123" print(v1.isdecimal()) # True v2 = "①" print(v2.isdecimal()) # False v3 = "123" print(v3.isdigit()) # True v4 = "①" print(v4.isdigit()) # True -
去除字符串两边的 空格、换行符、制表符,得到一个新字符串
data = input("请输入内容:") #武沛齐,武沛齐 print(data)msg = " H e ll o啊,树哥 " data = msg.strip() print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥"msg = " H e ll o啊,树哥 " data = msg.lstrip() print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥 "msg = " H e ll o啊,树哥 " data = msg.rstrip() print(data) # 将msg两边的空白去掉,得到" H e ll o啊,树哥"补充:去除 空格、换行符、制表符。
# 案例 code = input("请输入4位验证码:") # FB87 data = code.strip() if data == "FB87": print('验证码正确') else: print("验证码错误")再补充:去除字符串两边指定的内容
msg = "哥H e ll o啊,树哥" data = msg.strip("哥") print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树"msg = "哥H e ll o啊,树哥" data = msg.lstrip("哥") print(data) # 将msg两边的空白去掉,得到"H e ll o啊,树哥"msg = "哥H e ll o啊,树哥" data = msg.rstrip("哥") print(data) # 将msg两边的空白去掉,得到"哥H e ll o啊,树" -
字符串变大写,得到一个新字符串
msg = "my name is oliver queen" data = msg.upper() print(msg) # my name is oliver queen print(data) # 输出为:MY NAME IS OLIVER QUEEN# 案例 code = input("请输入4位验证码:") # FB88 fb88 value = code.upper() # FB88 data = value.strip() # FB88 if data == "FB87": print('验证码正确') else: print("验证码错误") # 注意事项 """ code的值"fb88 " value的值"FB88 " data的值"FB88" """ -
字符串变小写,得到一个新字符串
msg = "My Name Is Oliver Queen" data = msg.lower() print(data) # 输出为:my name is oliver queen# 案例 code = input("请输入4位验证码:") value = code.strip().lower() if value == "fb87": print('验证码正确') else: print("验证码错误") -
字符串内容替换,得到一个新的字符串
data = "你是个好人,但是好人不合适我" value = data.replace("好人","贱人") print(data) # "你是个好人,但是好人不合适我" print(value) # "你是个贱人,但是贱人不合适我"# 案例 video_file_name = "高清无码爱情动作片.mp4" new_file_name = video_file_name.replace("mp4","avi") # "高清无码爱情动作片.avi" final_file_name = new_file_name.replace("无码","步兵") # "高清步兵爱情动作片.avi" print(final_file_name)# 案例 video_file_name = "高清无码爱情动作片.mp4" new_file_name = video_file_name.replace("mp4","avi") # "高清无码爱情动作片.avi" final_file_name = video_file_name.replace("无码","步兵") # "高清步兵爱情动作片.mp4" print(final_file_name)# 案例 content = input("请输入评论信息") # alex是一个草包 content = content.replace("草","**") # alex是一个**包 content = content.replace("泥马","***") # alex是一个**包 print(content) # alex是一个**包char_list = ["草拟吗","逗比","二蛋","钢球"] content = input("请输入评论信息") for item in char_list: content = content.repalce(item,"**") print(content) -
字符串切割,得到一个列表
data = "武沛齐|root|wupeiqi@qq.com" result = data.split('|') # ["武沛齐","root","wupeiqi@qq.com"] print(data) # "武沛齐|root|wupeiqi@qq.com" print(result) # 输出 ["武沛齐","root","wupeiqi@qq.com"] 根据特定字符切开之后保存在列表中,方便以后的操作# 案例:判断用户名密码是否正确 info = "武沛齐,root" # 备注:字符串中存储了用户名和密码 user_list = info.split(',') # 得到一个包含了2个元素的列表 [ "武沛齐" , "root" ] # user_list[0] # user_list[1] user = input("请输入用户名:") pwd = input("请输入密码:") if user == user_list[0] and pwd == user_list[1]: print("登录成功") else: print("用户名或密码错误")扩展
data = "武沛齐|root|wupeiqi@qq.com" v1 = data.split("|") # ['武沛齐', 'root', 'wupeiqi@qq.com'] print(v1) v2 = data.split("|", 2) # ['武沛齐', 'root|wupeiqi@qq.com'] print(v2)再扩展
data = "武沛齐,root,wupeiqi@qq.com" v1 = data.rsplit(',') print(v1) # ['武沛齐', 'root', 'wupeiqi@qq.com'] v2 = data.rsplit(',',1) print(v2) # ['武沛齐,root', 'wupeiqi@qq.com']应用场景:
file_path = "xxx/xxxx/xx.xx/xxx.mp4" data_list = file_path.rsplit(".",1) # ["xxx/xxxx/xx.xx/xxx","mp4"] data_list[0] data_list[1] -
字符串拼接,得到一个新的字符串
data_list = ["alex","是","大烧饼"] v1 = "_".join(data_list) # alex_是_大烧饼 print(v1) -
格式化字符串,得到新的字符串
name = "{0}的喜欢干很多行业,例如有:{1}、{2} 等" data = name.format("老王","护士","嫩模") print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等 print(name) # "{0}的喜欢干很多行业,例如有:{1}、{2} 等"name = "{}的喜欢干很多行业,例如有:{}、{} 等" data = name.format("老王","护士","嫩模") print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等name = "{name}的喜欢干很多行业,例如有:{h1}、{h2} 等" data = name.format(name="老王",h1="护士",h2="嫩模") print(data) # 老王的喜欢干很多行业,例如有:护士、嫩模 等 -
字符串转换为字节类型
data = "嫂子" # unicode,字符串类型 v1 = data.encode("utf-8") # utf-8,字节类型 v2 = data.encode("gbk") # gbk,字节类型 print(v1) # b'\xe5\xab\x82 \xe5\xad\x90' print(v2) # b'\xc9\xa9 \xd7\xd3' s1 = v1.decode("utf-8") # 嫂子 s2 = v2.decode("gbk") # 嫂子 print(s1) print(s2) -
将字符串内容居中、居左、居右展示
v1 = "王老汉" # data = v1.center(21, "-") # print(data) #---------王老汉--------- # data = v1.ljust(21, "-") # print(data) # 王老汉------------------ # data = v1.rjust(21, "-") # print(data) # ------------------王老汉 -
帮助你填充0
data = "alex" v1 = data.zfill(10) print(v1) # 000000alex# 应用场景:处理二进制数据 data = "101" # "00000101" v1 = data.zfill(8) print(v1) # "00000101"
练习题
-
写代码实现判断用户输入的值否以 "al"开头,如果是则输出 "是的" 否则 输出 "不是的"
-
写代码实现判断用户输入的值否以"Nb"结尾,如果是则输出 "是的" 否则 输出 "不是的"
-
将 name 变量对应的值中的 所有的"l"替换为 "p",并输出结果
-
写代码实现对用户输入的值判断,是否为整数,如果是则转换为整型并输出,否则直接输出"请输入数字"
-
对用户输入的数据使用"+"切割,判断输入的值是否都是数字?
提示:用户输入的格式必须是以下+连接的格式,如 5+9 、alex+999 -
写代码实现一个整数加法计算器(两个数相加)
需求:提示用户输入:5+9或5+9或5+9,计算出两个值的和(提示:先分割再转换为整型,再相加) -
写代码实现一个整数加法计算器(两个数相加)
需求:提示用户输入:5 +9或5+ 9或5 + 9,计算出两个值的和(提示:先分割再去除空白、再转换为整型,再相加) -
补充代码实现用户认证。
需求:提示用户输入手机号、验证码,全都验证通过之后才算登录成功(验证码大小写不敏感)import random code = random.randrange(1000,9999) # 生成动态验证码 msg = "欢迎登录PythonAV系统,您的验证码为:{},手机号为:{}".format(code,"15131266666") print(msg) # 请补充代码 -
补充代码实现数据拼接
data_list = [] while True: hobby = input("请输入你的爱好(Q/q退出):") if hobby.upper() == 'Q': break # 把输入的值添加到 data_list 中,如:data_list = ["小姨子","哥们的女朋友"] data_list.append(hobby) # 将所有的爱好通过符号 "、"拼接起来并输出
3.3 公共功能
-
相加:字符串 + 字符串
v1 = "alex" + "大sb" print(v1) -
相乘:字符串 * 整数
data = "嫂子" * 3 print(data) # 嫂子嫂子嫂子 -
长度
data = "嫂子满身大汉" value = len(data) print(value) # 6 -
获取字符串中的字符,索引
message = "来做点py交易呀" # 0 1 2345 6 7 # ... -3 -2 -1 print(message[0]) # "来" print(message[1]) # "做" print(message[2]) # "点" print(message[-1]) # 呀 print(message[-2]) # 呀 print(message[-3]) # 呀注意:字符串中是能通过索引取值,无法修改值。【字符串在内部存储时不允许对内部元素修改,想修改只能重新创建。】
message = "来做点py交易呀" index = 0 while index < len(message): value = message[index] print(value) index += 1message = "来做点py交易呀" index = len(message) - 1 while index >=0: value = message[index] print(value) index -= 1 -
获取字符串中的子序列,切片
message = "来做点py交易呀" print(message[0:2]) # "来做" print(message[3:7]) # "py交易" print( message[3:] ) # "py交易呀" print( message[:5] ) # "来做点py" print(message[4:-1]) # "y交易" print(message[4:-2]) # "y交" print( message[4:len(message)] ) # "y交易呀"注意:字符串中的切片只能读取数据,无法修改数据。【字符串在内部存储时不允许对内部元素修改,想要修改只能重新创建】
message = "来做点py交易呀" value = message[:3] + "Python" + message[5:] print(value) -
步长,跳着去字符串的内容
name = "生活不是电影,生活比电影苦" print( name[ 0:5:2 ] ) # 输出:生不电 【前两个值表示区间范围,最有一个值表示步长】 print( name[ :8:2 ] ) # 输出:生不电, 【区间范围的前面不写则表示起始范围为0开始】 print( name[ 2::3 ] ) # 输出:不电,活电苦 【区间范围的后面不写则表示结束范围为最后】 print( name[ ::2 ] ) # 输出:生不电,活电苦 【区间范围不写表示整个字符串】 print( name[ 8:1:-1 ] ) # 输出:活生,影电是不 【倒序】name = "生活不是电影,生活比电影苦" print(name[8:1:-1]) # 输出:活生,影电是不 【倒序】 print(name[-1:1:-1]) # 输出:苦影电比活生,影电是不 【倒序】 # 面试题:给你一个字符串,请将这个字符串翻转。 value = name[-1::-1] print(value) # 苦影电比活生,影电是不活生 -
循环
-
while循环
message = "来做点py交易呀" index = 0 while index < len(message): value = message[index] print(value) index += 1 -
for循环
message = "来做点py交易呀" for char in message: print(char) -
range,帮助我们创建一系列的数字
range(10) # [0,1,2,3,4,5,6,7,8,9] range(1,10) # [1,2,3,4,5,6,7,8,9] range(1,10,2) # [1,3,5,7,9] range(10,1,-1) # [10,9,8,7,6,5,4,3,2] -
For + range
for i in range(10): print(i)message = "来做点py交易呀" for i in range(5): # [0,1,2,3,4] print(message[i])message = "来做点py交易呀" for i in range( len(message) ): # [0,1,2,3,4,5,6,7] print(message[i])
一般应用场景:
-
while,一般在做无限制(未知)循环此处时使用。
while True: ...# 用户输入一个值,如果不是整数则一直输入,直到是整数了才结束。 num = 0 while True: data = input("请输入内容:") if data.isdecimal(): num = int(data) break else: print("输入错误,请重新输入!") -
for循环,一般应用在已知的循环数量的场景。
message = "来做点py交易呀" for char in message: print(char)for i in range(30): print(message[i]) -
break和continue关键字
message = "来做点py交易呀" for char in message: if char == "p": continue print(char) # 输出: 来 做 点 y 交 易 呀message = "来做点py交易呀" for char in message: if char == "p": break print(char) # 输出: 来 做 点for i in range(5): print(i)# 0 1 2 3 4 for j in range(3): break print(j) # 0 1 2 # 0 1 2 # 0 1 2 # 0 1 2 # 0 1 2
-
3.4 转换
num = 999
data = str(num)
print(data) # "999"
data_list = ["alex","eric",999]
data = str(data_list)
print(data) # '["alex","eric",999]'
一般情况下,只有整型转字符串才有意义。
3.5 其他
3.5.1 字符串不可被修改
name = "武沛齐"
name[1]
name[1:2]
num_list = [11,22,33]
num_list[0]
num_list[0] = 666
4.列表(list)
列表(list),是一个有序且可变的容器,在里面可以存放多个不同类型的元素。
4.1 定义
user_list = ["苍老师","有坂深雪","大桥未久"]
number_list = [98,88,666,12,-1]
data_list = [1,True,"Alex","宝强","贾乃亮"]
user_list = []
user_list.append("铁锤")
user_list.append(123)
user_list.append(True)
print(user_list) # ["铁锤",123,True]
不可变类型:字符串、布尔、整型(已最小,内部数据无法进行修改)
可变类型:列表(内部数据元素可以修改)
4.2 独有功能
Python中为所有的列表类型的数据提供了一批独有的功能。
在开始学习列表的独有功能之前,先来做一个字符串和列表的对比:
-
字符串,不可变,即:创建好之后内部就无法修改。【独有功能都是新创建一份数据】
name = "alex" data = name.upper() print(name) print(data) -
列表,可变,即:创建好之后内部元素可以修改。【独有功能基本上都是直接操作列表内部,不会创建新的一份数据】
user_list = ["车子","妹子"] user_list.append("嫂子") print(user_list) # ["车子","妹子","嫂子"]
列表中的常见独有功能如下:
-
追加,在原列表中尾部追加值。
data_list = [] v1 = input("请输入姓名") data_list.append(v1) v2 = input("请输入姓名") data_list.append(v2) print(data_list) # ["alex","eric"]# 案例1 user_list = [] while True: user = input("请输入用户名(Q退出):") if user == "Q": break user_list.append(user) print(user_list)# 案例2 welcome = "欢迎使用NB游戏".center(30, '*') print(welcome) user_count = 0 while True: count = input("请输入游戏人数:") if count.isdecimal(): user_count = int(count) break else: print("输入格式错误,人数必须是数字。") message = "{}人参加游戏NB游戏。".format(user_count) print(message) user_name_list = [] for i in range(1, user_count + 1): tips = "请输入玩家姓名({}/{}):".format(i, user_count) name = input(tips) user_name_list.append(name) print(user_name_list) -
批量追加,将一个列表中的元素逐一添加另外一个列表。
tools = ["搬砖","菜刀","榔头"] tools.extend( [11,22,33] ) # weapon中的值逐一追加到tools中 print(tools) # ["搬砖","菜刀","榔头",11,22,33]tools = ["搬砖","菜刀","榔头"] weapon = ["AK47","M6"] #tools.extend(weapon) # weapon中的值逐一追加到tools中 #print(tools) # ["搬砖","菜刀","榔头","AK47","M6"] weapon.extend(tools) print(tools) # ["搬砖","菜刀","榔头"] print(weapon) # ["AK47","M6","搬砖","菜刀","榔头"]# 等价于(扩展) weapon = ["AK47","M6"] for item in weapon: print(item) # 输出: # AK47 # M6 tools = ["搬砖","菜刀","榔头"] weapon = ["AK47","M6"] for item in weapon: tools.append(item) print(tools) # ["搬砖","菜刀","榔头","AK47","M6"] -
插入,在原列表的指定索引位置插入值
user_list = ["苍老师","有坂深雪","大桥未久"] user_list.insert(0,"马蓉") user_list.insert(2,"李小璐") print(user_list)# 案例 name_list = [] while True: name = input("请输入购买火车票用户姓名(Q/q退出):") if name.upper() == "Q": break if name.startswith("刁"): name_list.insert(0, name) else: name_list.append(name) print(name_list) -
在原列表中根据值删除(从左到右找到第一个删除)【慎用,里面没有会报错】
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] user_list.remove("Alex") print(user_list) user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] if "Alex" in user_list: user_list.remove("Alex") print(user_list) user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] while True: if "Alex" in user_list: user_list.remove("Alex") else: break print(user_list)# 案例:自动抽奖程序 import random data_list = ["iphone12", "二手充气女友", "大保健一次", "泰国5日游", "避孕套"] while data_list: name = input("自动抽奖程序,请输入自己的姓名:") # 随机从data_list抽取一个值出来 value = random.choice(data_list) # "二手充气女友" print( "恭喜{},抽中{}.".format(name, value) ) data_list.remove(value) # "二手充气女友" -
在原列表中根据索引踢出某个元素(根据索引位置删除)
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] # 0 1 2 3 4 user_list.pop(1) print(user_list) # ["王宝强","Alex","贾乃亮","Alex"] user_list.pop() print(user_list) # ["王宝强","Alex","贾乃亮"] item = user_list.pop(1) print(item) # "Alex" print(user_list) # ["王宝强","贾乃亮"]# 案例:排队买火车票 # ["alex","李杰","eric","武沛齐","老妖","肝胆"] user_queue = [] while True: name = input("北京~上海火车票,购买请输入姓名排队(Q退出):") if name == "Q": break user_queue.append(name) ticket_count = 3 for i in range(ticket_count): username = user_queue.pop(0) message = "恭喜{},购买火车票成功。".format(username) print(message) # user_queue = ["武沛齐","老妖","肝胆"] faild_user = "、".join(user_queue) # "武沛齐、老妖、肝胆" faild_message = "非常抱歉,票已售完,以下几位用户请选择其他出行方式,名单:{}。".format(faild_user) print(faild_message) -
清空原列表
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] user_list.clear() print(user_list) # [] -
根据值获取索引(从左到右找到第一个删除)【慎用,找不到报错】
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] # 0 1 2 3 4 if "Alex" in user_list: index = user_list.index("Alex") print(index) # 2 else: print("不存在") -
列表元素排序
# 数字排序 num_list = [11, 22, 4, 5, 11, 99, 88] print(num_list) num_list.sort() # 让num_list从小到大排序 num_list.sort(reverse=True) # # 让num_list从大到小排序 print(num_list) # 字符串排序 user_list = ["王宝强", "Ab陈羽凡", "Alex", "贾乃亮", "贾乃", "1"] # [29579, 23453, 24378] # [65, 98, 38472, 32701, 20961] # [65, 108, 101, 120] # [49] print(user_list) """ sort的排序原理 [ "x x x" ," x x x x x " ] """ user_list.sort() print(user_list)注意:排序时内部元素无法进行比较时,程序会报错(尽量数据类型统一)。
-
反转原列表
user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] user_list.reverse() print(user_list)
4.3 公共功能
-
相加,两个列表相加获取生成一个新的列表。
data = ["赵四","刘能"] + ["宋晓峰","范德彪"] print(data) # ["赵四","刘能","宋晓峰","范德彪"] v1 = ["赵四","刘能"] v2 = ["宋晓峰","范德彪"] v3 = v1 + v2 print(v3) # ["赵四","刘能","宋晓峰","范德彪"] -
相乘,列表*整型 将列表中的元素再创建N份并生成一个新的列表。
data = ["赵四","刘能"] * 2 print(data) # ["赵四","刘能","赵四","刘能"] v1 = ["赵四","刘能"] v2 = v1 * 2 print(v1) # ["赵四","刘能"] print(v2) # ["赵四","刘能","赵四","刘能"] -
运算符in包含
由于列表内部是由多个元素组成,可以通过in来判断元素是否在列表中。user_list = ["狗子","二蛋","沙雕","alex"] result = "alex" in user_list # result = "alex" not in user_list print(result) # True if "alex" in user_list: print("在,把他删除") user_list.remove("alex") else: print("不在")user_list = ["狗子","二蛋","沙雕","alex"] if "alex" in user_list: print("在,把他删除") user_list.remove("alex") else: print("不在") text = "打倒小日本" data = "日" in text# 案例 user_list = ["狗子","二蛋","沙雕","alex"] if "alex" in user_list: print("在,把他删除") user_list.remove("alex") else: print("不在")# 案例 user_list = ["王宝强","陈羽凡","Alex","贾乃亮","Alex"] if "Alex" in user_list: index = user_list.index("Alex") user_list.pop(index)# 案例:敏感词替换 text = input("请输入文本内容:") # 按时打发第三方科技爱普生豆腐啊;了深刻的房价破阿偶打飞机 forbidden_list = ["草","欧美","日韩"] for item in forbidden_list: text = text.replace(item,"**") print(text)注意:列表检查元素是否存在时,是采用逐一比较的方式,效率会比较低。
-
获取长度
user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( len(user_list) ) -
索引,一个元素的操作
# 读 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( user_list[0] ) print( user_list[2] ) print( user_list[3] ) # 报错# 改 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] user_list[0] = "武沛齐" print(user_list) # ["武沛齐","刘华强",'尼古拉斯赵四']# 删 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] del user_list[1] user_list.remove("刘华强") ele = user_list.pop(1)注意:超出索引范围会报错。
提示:由于字符串是不可变类型,所以他只有索引读的功能,而列表可以进行 读、改、删 -
切片,多个元素的操作(很少用)
# 读 user_list = ["范德彪","刘华强",'尼古拉斯赵四'] print( user_list[0:2] ) # ["范德彪","刘华强"] print( user_list[1:] ) print( user_list[:-1] )# 改 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[0:2] = [11, 22, 33, 44] print(user_list) # 输出 [11, 22, 33, 44, '尼古拉斯赵四'] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[2:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[3:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[10000:] = [11, 22, 33, 44] print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44] user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] user_list[-10000:1] = [11, 22, 33, 44] print(user_list) # 输出 [11, 22, 33, 44, '刘华强', '尼古拉斯赵四']# 删 user_list = ["范德彪", "刘华强", '尼古拉斯赵四'] del user_list[1:] print(user_list) # 输出 ['范德彪'] -
步长
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] # 0 1 2 3 4 print( user_list[1:4:2] ) print( user_list[0::2] ) print( user_list[1::2] ) print( user_list[4:1:-1] )# 案例:实现列表的翻转 user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] new_data = user_list[::-1] print(new_data) data_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] data_list.reverse() print(data_list) # 给你一个字符串请实现字符串的翻转? name = "武沛齐" name[::-1] -
for循环
user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] for item in user_list: print(item)user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] for index in range( len(user_list) ): item = user_index[index] print(item)切记,循环的过程中对数据进行删除会踩坑【面试题】。
# 错误方式, 有坑,结果不是你想要的。 user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"] for item in user_list: if item.startswith("刘"): user_list.remove(item) print(user_list)# 正确方式,倒着删除。 user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"] for index in range(len(user_list) - 1, -1, -1): item = user_list[index] if item.startswith("刘"): user_list.remove(item) print(user_list)
4.4 转换
-
int、bool无法转换成列表
-
str
name = "武沛齐" data = list(name) # ["武","沛","齐"] print(data) -
超前
v1 = (11,22,33,44) # 元组 vv1 = list(v1) # 列表 [11,22,33,44] v2 = {"alex","eric","dsb"} # 集合 vv2 = list(v2) # 列表 ["alex","eric","dsb"]
4.5. 其他
4.5.1 嵌套
列表属于容器,内部可以存放各种数据,所以他也支持列表的嵌套,如:
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,[999,123],33,44],"宋小宝" ]
对于嵌套的值,可以根据之前学习的索引知识点来进行学习,例如:
data = [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝" ]
print( data[0] ) # "谢广坤"
print( data[1] ) # ["海燕","赵本山"]
print( data[0][2] ) # "坤"
print( data[1][-1] ) # "赵本山"
data.append(666)
print(data) # [ "谢广坤",["海燕","赵本山"],True,[11,22,33,44],"宋小宝",666]
data[1].append("谢大脚")
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],"宋小宝",666 ]
del data[-2]
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,22,33,44],666 ]
data[-2][1] = "alex"
print(data) # [ "谢广坤",["海燕","赵本山","谢大脚"],True,[11,"alex",33,44],666 ]
data[1][0:2] = [999,666]
print(data) # [ "谢广坤",[999,666,"谢大脚"],True,[11,"alex",33,44],666 ]
# 创建用户列表
# 用户列表应该长: [ ["alex","123"],["eric","666"] ]
# user_list = [["alex","123"],["eric","666"],]
# user_list.append(["alex","123"])
# user_list.append(["eric","666"])
user_list = []
while True:
user = input("请输入用户名:")
pwd = input("请输入密码:")
data = []
data.append(user)
data.append(pwd)
user_list.append(data)
user_list = []
while True:
user = input("请输入用户名(Q退出):")
if user == "Q":
break
pwd = input("请输入密码:")
data = [user,pwd]
user_list.append(data)
print(user_list)
5.元组
列表(list),是一个有序且可变的容器,在里面可以存放多个不同类型的元素。
元组(tuple),是一个有序且不可变的容器,在里面可以存放多个不同类型的元素。
如何体现不可变呢?
记住一句话:《"我儿子永远不能换成是别人,但我儿子可以长大"》
元组的元素不能被替换,但元组的元素如果是可变类型,可变类型内部是可以修改的。
5.1 定义
v1 = (11,22,33)
v2 = ("李杰","Alex")
v3 = (True,123,"Alex",[11,22,33,44])
# 建议:议在元组的最后多加一个逗v3 = ("李杰","Alex",)
d1 = (1) # 1
d2 = (1,) # (1,)
d3 = (1,2)
d4 = (1,2)
注意:建议在元组的最后多加一个逗号,用于标识他是一个元组。
# 面试题
1. 比较值 v1 = (1) 和 v2 = 1 和 v3 = (1,) 有什么区别?
2. 比较值 v1 = ( (1),(2),(3) ) 和 v2 = ( (1,) , (2,) , (3,),) 有什么区别?
(1,2,3)
5.2 独有功能
无
5.3 公共功能
-
相加,两个列表相加获取生成一个新的列表。
data = ("赵四","刘能") + ("宋晓峰","范德彪") print(data) # ("赵四","刘能","宋晓峰","范德彪") v1 = ("赵四","刘能") v2 = ("宋晓峰","范德彪") v3 = v1 + v2 print(v3) # ("赵四","刘能","宋晓峰","范德彪") -
相乘,列表*整型 将列表中的元素再创建N份并生成一个新的列表。
data = ("赵四","刘能") * 2 print(data) # ("赵四","刘能","赵四","刘能") v1 = ("赵四","刘能") v2 = v1 * 2 print(v1) # ("赵四","刘能") print(v2) # ("赵四","刘能","赵四","刘能") -
获取长度
user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( len(user_list) ) -
索引
user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( user_list[0] ) print( user_list[2] ) print( user_list[3] ) -
切片
user_list = ("范德彪","刘华强",'尼古拉斯赵四',) print( user_list[0:2] ) print( user_list[1:] ) print( user_list[:-1] ) -
步长
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") print( user_list[1:4:2] ) print( user_list[0::2] ) print( user_list[1::2] ) print( user_list[4:1:-1] )# 字符串 & 元组。 user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") data = user_list[::-1] # 列表 user_list = ["范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能"] data = user_list[::-1] user_list.reverse() print(user_list) -
for循环
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for item in user_list: print(item)user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for item in user_list: if item == '刘华强': continue print(name)目前:只有 str、list、tuple 可以被for循环。 "xxx" [11,22,33] (111,22,33)
# len + range + for + 索引 user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能") for index in range(len(user_list)): item = user_list[index] print(item)
5.4 转换
其他类型转换为元组,使用tuple(其他类型),目前只有字符串和列表可以转换为元组。
data = tuple(其他)
# str / list
name = "武沛齐"
data = tuple(name)
print(data) # 输出 ("武","沛","齐")
name = ["武沛齐",18,"pythonav"]
data = tuple(name)
print(data) # 输出 ("武沛齐",18,"pythonav")
5.5 其他
5.5.1 嵌套
由于元组和列表都可以充当容器,他们内部可以放很多元素,并且也支持元素内的各种嵌套。
tu = ( '今天姐姐不在家', '姐夫和小姨子在客厅聊天', ('姐夫问小姨子税后多少钱','小姨子低声说道说和姐夫还提钱') )
tu1 = tu[0]
tu2 = tu[1]
tu3 = tu[2][0]
tu4 = tu[2][1]
tu5 = tu[2][1][3]
print(tu1) # 今天姐姐不在家
print(tu2) # 姐夫和小姨子在客厅聊天
print(tu3) # 姐夫问小姨子税后多少钱
print(tu4) # 小姨子低声说道说和姐夫还提钱
练习题1:判断是否可以实现,如果可以请写代码实现。
li = ["alex", [11,22,(88,99,100,),33], "WuSir", ("ritian", "barry",), "wenzhou"]
# 0 1 2 3 4
# 1.请将 "WuSir" 修改成 "武沛齐"
li[2] = "武沛齐"
index = li.index("Wusir")
li[index] = "武沛齐"
# 2.请将 ("ritian", "barry",) 修改为 ['日天','日地']
li[3] = ['日天','日地']
# 3.请将 88 修改为 87
li[1][2][0] = 87 # (报错,)
# 4.请将 "wenzhou" 删除,然后再在列表第0个索引位置插入 "周周"
# li.remove("wenzhou")
# del li[-1]
li.insert(0,"周周")
练习题2:记住一句话:《"我儿子永远不能换成是别人,但我儿子可以长大"》
data = ("123",666,[11,22,33], ("alex","李杰",[999,666,(5,6,7)]) )
# 1.将 “123” 替换成 9 报错
# 2.将 [11,22,33] 换成 "武沛齐" 报错
# 3.将 11 换成 99
data[2][0] = 99
print(data) # ("123",666,[99,22,33], ("alex","李杰",[999,666,(5,6,7)]) )
# 4.在列表 [11,22,33] 追加一个44
data[2].append(44)
print(data) # ("123",666,[11,22,33,44], ("alex","李杰",[999,666,(5,6,7)]) )
练习题3:动态的创建用户并添加到用户列表中。
# 创建用户 5个
# user_list = [] # 用户信息
user_list = [ ("alex","132"),("admin","123"),("eric","123") ]
while True:
user = input("请输入用户名:")
if user == "Q":
brek
pwd = input("请输入密码:")
item = (user,pwd,)
user_list.append(item)
# 实现:用户登录案例
print("登录程序")
username = input("请输入用户名:")
password = input("请输入密码:")
is_success = False
for item in user_list:
# item = ("alex","132") ("admin","123") ("eric","123")
if username == item[0] and password == item[1]:
is_success = True
break
if is_success:
print("登录成功")
else:
print("登录失败")
6.集合(set)
集合是一个 无序 、可变、不允许数据重复的容器。
6.1 定义
v1 = { 11, 22, 33, "alex" }
-
无序,无法通过索引取值。
-
可变,可以添加和删除元素。
v1 = {11,22,33,44} v1.add(55) print(v1) # {11,22,33,44,55} -
不允许数据重复。
v1 = {11,22,33,44} v1.add(22) print(v1) # {11,22,33,44}
一般什么时候用集合呢?
就是想要维护一大堆不重复的数据时,就可以用它。比如:做爬虫去网上找图片的链接,为了避免链接重复,可以选择用集合去存储链接地址。
注意:定义空集合时,只能使用v = set(),不能使用 v={}(这样是定义一个空字典)。
v1 = []
v11 = list()
v2 = ()
v22 = tuple()
v3 = set()
v4 = {} # 空字典
v44 = dict()
6.2 独有功能
-
添加元素
data = {"刘嘉玲", '关之琳', "王祖贤"} data.add("郑裕玲") print(data)data = set() data.add("周杰伦") data.add("林俊杰") print(data) -
删除元素
data = {"刘嘉玲", '关之琳', "王祖贤","张曼⽟", "李若彤"} data.discard("关之琳") print(data) -
交集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s4 = s1.intersection(s2) # 取两个集合的交集 print(s4) # {"⽪⻓⼭"} s3 = s1 & s2 # 取两个集合的交集 print(s3) -
并集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s4 = s1.union(s2) # 取两个集合的并集 {"刘能", "赵四", "⽪⻓⼭","刘科⻓", "冯乡⻓", } print(s4) s3 = s1 | s2 # 取两个集合的并集 print(s3) -
差集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s4 = s1.difference(s2) # 差集,s1中有且s2中没有的值 {"刘能", "赵四"} s6 = s2.difference(s1) # 差集,s2中有且s1中没有的值 {"刘科⻓", "冯乡⻓"} s3 = s1 - s2 # 差集,s1中有且s2中没有的值 s5 = s2 - s1 # 差集,s2中有且s1中没有的值 print(s5,s6)
6.3 公共功能
-
减,计算差集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 - s2 s4 = s2 - s1 print(s3) print(s4) -
&,计算交集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 & s2 print(s3) -
|,计算并集
s1 = {"刘能", "赵四", "⽪⻓⼭"} s2 = {"刘科⻓", "冯乡⻓", "⽪⻓⼭"} s3 = s1 | s2 print(s3) -
长度
v = {"刘能", "赵四", "尼古拉斯"} data = len(v) print(data) -
for循环
v = {"刘能", "赵四", "尼古拉斯"} for item in v: print(item)
6.4 转换
其他类型如果想要转换为集合类型,可以通过set进行转换,并且如果数据有重复自动剔除。
提示:int/list/tuple/dict都可以转换为集合。
v1 = "武沛齐"
v2 = set(v1)
print(v2) # {"武","沛","齐"}
v1 = [11,22,33,11,3,99,22]
v2 = set(v1)
print(v2) # {11,22,33,3,99}
v1 = (11,22,3,11)
v2 = set(v1)
print(v2) # {11,22,3}
提示:这其实也是去重的一个手段。
data = {11,22,33,3,99}
v1 = list(data) # [11,22,33,3,99]
v2 = tuple(data) # (11,22,33,3,99)
6.5 其他
6.5.1 集合的存储原理

6.5.2 元素必须可哈希
因存储原理,集合的元素必须是可哈希的值,即:内部通过通过哈希函数把值转换成一个数字。
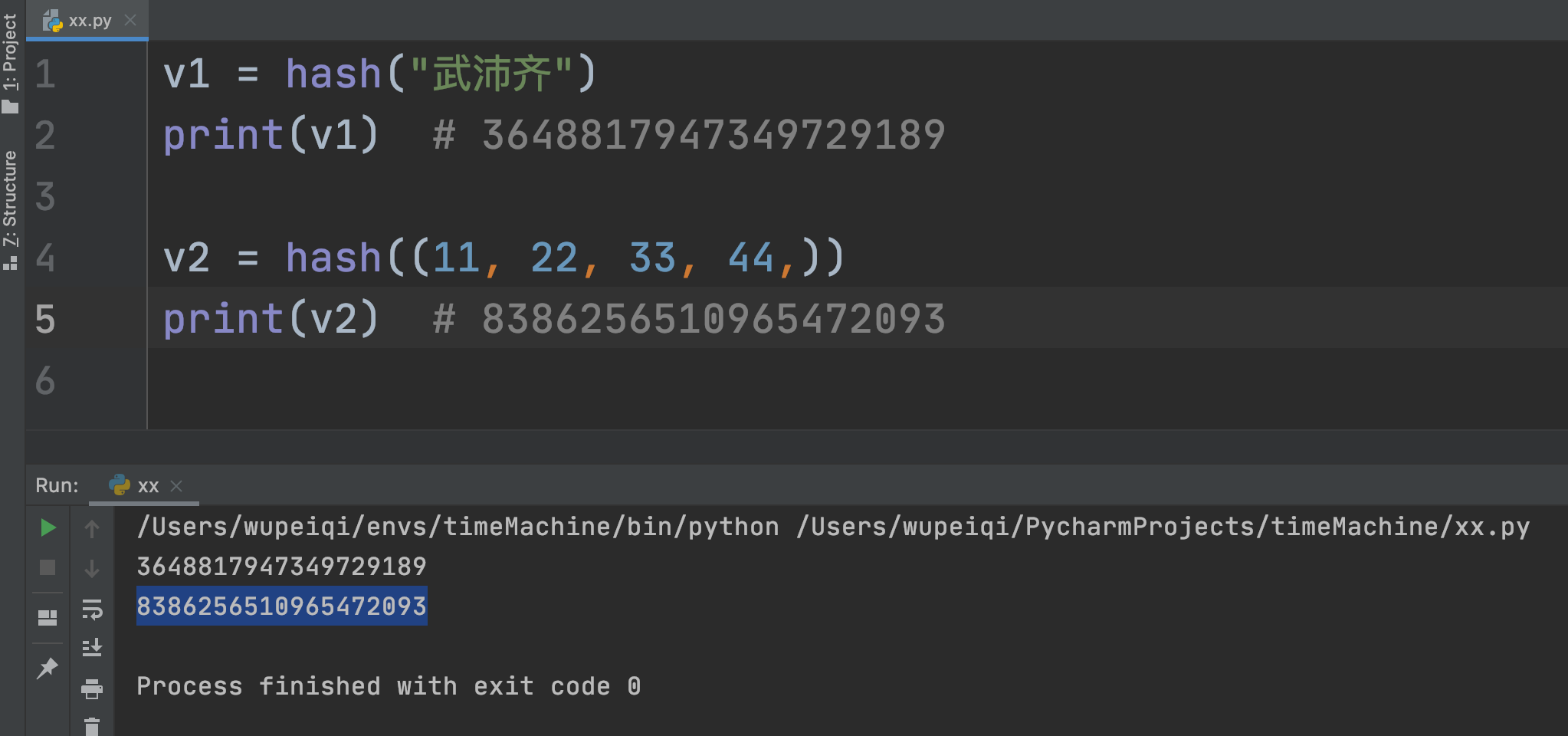
目前可哈希的数据类型:int、bool、str、tuple,而list、set是不可哈希的。
总结:集合的元素只能是 int、bool、str、tuple 。
-
转换成功
v1 = [11,22,33,11,3,99,22] v2 = set(v1) print(v2) # {11,22,33,3,99} -
转换失败
v1 = [11,22,["alex","eric"],33] v2 = set(v1) # 报错 print(v2)
6.5.3 查找速度特别快
因存储原理特殊,集合的查找效率非常高(数据量大了才明显)。
-
低
user_list = ["武沛齐","alex","李璐"] if "alex" in user_list: print("在") else: print("不在") user_tuple = ("武沛齐","alex","李璐") if "alex" in user_tuple: print("在") else: print("不在") -
效率高
user_set = {"武沛齐","alex","李璐"} if "alex" in user_set: print("在") else: print("不在")
6.5.4 对比和嵌套
| 类型 | 是否可变 | 是否有序 | 元素要求 | 是否可哈希 | 转换 | 定义空 |
|---|---|---|---|---|---|---|
| list | 是 | 是 | 无 | 否 | list(其他) | v=[]或v=list() |
| tuple | 否 | 是 | 无 | 是 | tuple(其他) | v=()或v=tuple() |
| set | 是 | 否 | 可哈希 | 否 | set(其他) | v=set() |
data_list = [
"alex",
11,
(11, 22, 33, {"alex", "eric"}, 22),
[11, 22, 33, 22],
{11, 22, (True, ["中国", "北京"], "沙河"), 33}
]
注意:由于True和False本质上存储的是 1 和 0 ,而集合又不允许重复,所以在整数 0、1和False、True出现在集合中会有如下现象:
v1 = {True, 1}
print(v1) # {True}
v2 = {1, True}
print(v2) # {1}
v3 = {0, False}
print(v3) # {0}
v4 = {False, 0}
print(v4) # {False}
练习题
-
写代码实现
v1 = {'alex','武sir','肖大'} v2 = [] # 循环提示用户输入,如果输入值在v1中存在,则追加到v2中,如果v1中不存在,则添加到v1中。(如果输入N或n则停止循环) while True: name = input("请输入姓名(N/n退出):") if name.upper() == "Q": break if name in v1: v2.append(name) else: v1.add(name) -
下面那些值不能做集合的元素
"" 0 [11,22,33] # 不能 [] # 不能 (123) {1,2,3} # 不能 -
模拟用户信息录入程序,已录入则不再创建。
user_info_set = set() while True: name = input("请输入姓名:") age = input("请输入年龄:") item = (name,age,) if item in user_info_set: print("该用户已录入") else: user_info_set.add(item) -
给你个列表去重。
v = [11,22,11,22,44455] data = set(v) # {11,22,44455} result = list(data) # [11,22,44455]
强插:None类型
Python的数据类型中有一个特殊的值None,意味着这个值啥都不是 或 表示空。 相当于其他语言中 null作用一样。
在一定程度上可以帮助我们去节省内存。例如:
v1 = None
v2 = None
..
v1 = [11,22,33,44]
v2 = [111,22,43]
v3 = []
v4 = []
...
v3 = [11,22,33,44]
v4 = [111,22,43]
注意:暂不要考虑Python内部的缓存和驻留机制。
目前所有转换为布尔值为False的值有:
0
""
[] or list()
() or tuple()
set()
None
if None:
pass
7.字典(dict)
字典是 无序、键不重复 且 元素只能是键值对的可变的 个 容器。
data = { "k1":1, "k2":2 }
-
容器
-
元素必须键值对
-
键不重复,重复则会被覆盖
data = { "k1":1, "k1":2 } print(data) # {"k1":2} -
无序(在Python3.6+字典就是有序了,之前的字典都是无序。)
data = { "k1":1, "k2":2 } print(data)
7.1 定义
v1 = {}
v2 = dict()
data = {
"k1":1,
"k2":2
}
info = {
"age":12,
"status":True,
"name":"wupeiqi",
"hobby":['篮球','足球']
}
字典中对键值得要求:
- 键:必须可哈希。 目前为止学到的可哈希的类型:int/bool/str/tuple;不可哈希的类型:list/set/dict。(集合)
- 值:任意类型。
data_dict = {
"武沛齐":29,
True:5,
123:5,
(11,22,33):["alex","eric"]
}
# 不合法
v1 = {
[1, 2, 3]: '周杰伦',
"age" : 18
}
v2 = {
{1,2,3}: "哈哈哈",
'name':"alex"
}
v3 = {
{"k1":123,"k2":456}: '呵呵呵',
"age":999
}
data_dict = {
1: 29,
True: 5
}
print(data_dict) # {1: 5}
一般在什么情况下会用到字典呢?
当我们想要表示一组固定信息时,用字典可以更加的直观,例如:
# 用户列表
user_list = [ ("alex","123"), ("admin","666") ]
...
# 用户列表
user_list = [ {"name":"alex","pwd":"123"}, {"name":"eric","pwd":"123"} ]
7.2 独有功能
-
获取值
info = { "age":12, "status":True, "name":"武沛齐", "data":None } data1 = info.get("name") print(data1) # 输出:武沛齐 data2 = info.get("age") print(data2) # 输出:12 data = info.get("email") # 键不存在,默认返回 None """ if data == None: print("此键不存在") else: print(data) if data: print(data) else: print("键不存在") """ """ # 字典的键中是否存在 email if "email" in info: data = info.get("email") print(data) else: print("不存在") """ data = info.get("hobby",123) print(data) # 输出:123# 案例: user_list = { "wupeiqi": "123", "alex": "uk87", } username = input("请输入用户名:") password = input("请输入密码:") # None,用户名不存在 # 密码,接下来比较密码 pwd = user_list.get(username) if pwd == None: print("用户名不存在") else: if password == pwd: print("登录成功") else: print("密码错误")# 案例: user_list = { "wupeiqi": "123", "alex": "uk87", } username = input("请输入用户名:") password = input("请输入密码:") # None,用户名不存在 # 密码,接下来比较密码 pwd = user_list.get(username) if pwd: if password == pwd: print("登录成功") else: print("密码错误") else: print("用户名不存在")# 案例: user_list = { "wupeiqi": "123", "alex": "uk87", } username = input("请输入用户名:") password = input("请输入密码:") # None,用户名不存在 # 密码,接下来比较密码 pwd = user_list.get(username) if not pwd: print("用户名不存在") else: if password == pwd: print("登录成功") else: print("密码错误") # 写代码的准则:简单的逻辑处理放在前面;复杂的逻辑放在后面。 -
所有的键
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} data = info.keys() print(data) # 输出:dict_keys(['age', 'status', 'name', 'email']) py2 -> ['age', 'status', 'name', 'email'] result = list(data) print(result) # ['age', 'status', 'name', 'email']注意:在Python2中 字典.keys()直接获取到的是列表,而Python3中返回的是
高仿列表,这个高仿的列表可以被循环显示。# 循环 info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} for ele in info.keys(): print(ele)# 是否存在 info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} # info.keys() # dict_keys(['age', 'status', 'name', 'email']) if "age" in info.keys(): print("age是字典的键") else: print("age不是") -
所有的值
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} data = info.values() print(data) # 输出:dict_values([12, True, 'wupeiqi', 'xx@live.com'])注意:在Python2中 字典.values()直接获取到的是列表,而Python3中返回的是高仿列表,这个高仿的列表可以被循环显示。
# 循环 info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} for val in info.values(): print(val)# 是否存在 info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} if 12 in info.values(): print("12是字典的值") else: print("12不是") -
所有的键值
info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} data = info.items() print(data) # 输出 dict_items([ ('age', 12), ('status', True), ('name', 'wupeiqi'), ('email', 'xx@live.com') ])for item in info.items(): print(item[0],item[1]) # item是一个元组 (键,值)for key,value in info.items(): print(key,value) # key代表键,value代表值,将兼职从元组中直接拆分出来了。info = {"age":12, "status":True, "name":"wupeiqi","email":"xx@live.com"} data = info.items() if ('age', 12) in data: print("在") else: print("不在") -
设置值
data = { "name": "武沛齐", "email": 'xxx@live.com' } data.setdefault("age", 18) print(data) # {'name': '武沛齐', 'email': 'xxx@live.com', 'age': 18} data.setdefault("name", "alex") print(data) # {'name': '武沛齐', 'email': 'xxx@live.com', 'age': 18} -
更新字典键值对
info = {"age":12, "status":True} info.update( {"age":14,"name":"武沛齐"} ) # info中没有的键直接添加;有的键则更新值 print(info) # 输出:{"age":14, "status":True,"name":"武沛齐"} -
移除指定键值对
info = {"age":12, "status":True,"name":"武沛齐"} data = info.pop("age") print(info) # {"status":True,"name":"武沛齐"} print(data) # 12 -
按照顺序移除(后进先出)
info = {"age":12, "status":True,"name":"武沛齐"} data = info.popitem() # ("name","武沛齐" ) print(info) # {"age":12, "status":True} print(data) # ("name","武沛齐")- py3.6后,popitem移除最后的值。
- py3.6之前,popitem随机删除。
# 练习题
"""
结合下面的两个变量 header 和 stock_dict实现注意输出股票信息,格式如下:
SH601778,股票名称:中国晶科、当前价:6.29、涨跌额:+1.92。
SH688566,股票名称:吉贝尔、当前价:... 。
...
"""
header = ['股票名称', '当前价', '涨跌额']
stock_dict = {
'SH601778': ['中国晶科', '6.29', '+1.92'],
'SH688566': ['吉贝尔', '52.66', '+6.96'],
'SH688268': ['华特气体', '88.80', '+11.72'],
'SH600734': ['实达集团', '2.60', '+0.24']
}
7.3 公共功能
-
求
并集(Python3.9新加入)v1 = {"k1": 1, "k2": 2} v2 = {"k2": 22, "k3": 33} v3 = v1 | v2 print(v3) # {'k1': 1, 'k2': 22, 'k3': 33} -
长度
info = {"age":12, "status":True,"name":"武沛齐"} data = len(info) print(data) # 输出:3 -
是否包含
info = { "age":12, "status":True,"name":"武沛齐" } v1 = "age" in info print(v1) v2 = "age" in info.keys() print(v2) if "age" in info: pass else: passinfo = {"age":12, "status":True,"name":"武沛齐"} v1 = "武佩奇" in info.values() print(v1)info = {"age": 12, "status": True, "name": "武沛齐"} # 输出info.items()获取到的 dict_items([ ('age', 12), ('status', True), ('name', 'wupeiqi'), ('email', 'xx@live.com') ]) v1 = ("age", 12) in info.items() print(v1) -
索引(键)
字典不同于元组和列表,字典的索引是键,而列表和元组则是0、1、2等数值。info = { "age":12, "status":True, "name":"武沛齐"} print( info["age"] ) # 输出:12 print( info["name"] ) # 输出:武沛齐 print( info["status"] ) # 输出:True print( info["xxxx"] ) # 报错,通过键为索引去获取之后时,键不存在会报错(以后项目开发时建议使用get方法根据键去获取值) value = info.get("xxxxx") # None print(value) -
根据键 修改值 和 添加值 和 删除键值对
上述示例通过键可以找到字典中的值,通过键也可以对字典进行添加和更新操作info = {"age":12, "status":True,"name":"武沛齐"} info["gender"] = "男" print(info) # 输出: {"age":12, "status":True,"name":"武沛齐","gender":"男"}info = {"age":12, "status":True,"name":"武沛齐"} info["age"] = "18" print(info) # 输出: {"age":"18", "status":True,"name":"武沛齐"}info = {"age":12, "status":True,"name":"武沛齐"} del info["age"] # 删除info字典中键为age的那个键值对(键不存在则报错) print(info) # 输出: {"status":True,"name":"武沛齐"}info = {"age": 12, "status": True, "name": "武沛齐"} if "agea" in info: # del info["age"] data = info.pop("age") print(info) print(data) else: print("键不存在") -
for循环
由于字典也属于是容器,内部可以包含多个键值对,可以通过循环对其中的:键、值、键值进行循环;info = {"age":12, "status":True,"name":"武沛齐"} for item in info: print(item) # 所有键info = {"age":12, "status":True,"name":"武沛齐"} for item in info.key(): print(item)info = {"age":12, "status":True,"name":"武沛齐"} for item in info.values(): print(item)info = {"age":12, "status":True,"name":"武沛齐"} for key,value in info.items(): print(key,value)
7.4 转换
想要转换为字典.
v = dict( [ ("k1", "v1"), ["k2", "v2"] ] )
print(v) # { "k1":"v1", "k2":"v2" }
info = { "age":12, "status":True, "name":"武沛齐" }
v1 = list(info) # ["age","status","name"]
v2 = list(info.keys()) # ["age","status","name"]
v3 = list(info.values()) # [12,True,"武沛齐"]
v4 = list(info.items()) # [ ("age",12), ("status",True), ("name","武沛齐") ]
7.5 其他
7.5.1 存储原理
7.5.2 速度快
info = {
"alex":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
for "alex" in info:
print("在")
info = {
"alex":["肝胆","铁锤"],
"老男孩":["二蛋","缺货"]
}
v1 = info["alex"]
v2 = info.get("alex")
7.5.3 嵌套
我们已学了很多数据类型,在涉及多种数据类型之间的嵌套时,需注意一下几点:
-
字典的键必须可哈希(list/set/dict不可哈希)。
info = { (11,22):123 } # 错误 info = { (11,[11,22,],22):"alex" } -
字典的值可以是任意类型。
info = { "k1":{12,3,5}, "k2":{"xx":"x1"} } -
字典的键和集合的元素在遇到 布尔值 和 1、0 时,需注意重复的情况。
-
元组的元素不可以被替换。
dic = {
'name':'汪峰',
'age':48,
'wife':[ {'name':'国际章','age':38},{'name':'李杰','age':48} ],
'children':['第一个娃','第二个娃']
}
"""
1. 获取汪峰的妻子名字
d1 = dic['wife'][0]['name']
print(d1)
2. 获取汪峰的孩子们
d2 = dic['children']
print(d2)
3. 获取汪峰的第一个孩子
d3 = dic['children'][0]
print(d3)
4. 汪峰的媳妇姓名变更为 章子怡
dic['wife'][0]['name] = "章子怡"
print(dic)
5. 汪峰再娶一任妻子
dic['wife'].append( {"name":"铁锤","age":19} )
print(dic)
6. 给汪峰添加一个爱好:吹牛逼
dic['hobby'] = "吹牛逼"
print(dic)
7. 删除汪峰的年龄
del dic['age']
或
dic.pop('age')
print(dic)
"""
8.浮点型(float)
浮点型,一般在开发中用于表示小数。
v1 = 3.14
v2 = 9.89
关于浮点型的其他知识点如下:
-
在类型转换时需要,在浮点型转换为整型时,会将小数部分去掉。
v1 = 3.14 data = int(v1) print(data) # 3 -
想要保留小数点后N位
v1 = 3.1415926 result = round(v1,3) print(result) # 3.142 -
浮点型的坑(所有语言中)

底层原理视频:https://www.bilibili.com/video/BV1354y1B7o1/
在项目中如果遇到精确的小数计算应该怎么办?
import decimal v1 = decimal.Decimal("0.1") v2 = decimal.Decimal("0.2") v3 = v1 + v2 print(v3) # 0.3
总结
-
集合,是 无序、不重复、元素必须可哈希、可变的一个容器(子孙元素都必须是可哈希)。
-
集合的查找速度比较快(底层是基于哈希进行存储)
-
集合可以具有 交并差 的功能。
-
字典是 无序、键不重复 且 元素只能是键值对的可变的一个容器(键子孙元素都必须是可哈希)。
-
py3.6+之后字典就变为有序了。
-
py3.9 新增了一个
{} | {}运算。 -
字典的常见功能。
-
在python2和python3中,字典的 keys() 、values()、items() 三个功能获取的数据类型不一样。
-
None是代表内存中的一个空值。
0 "" [] or list() () or tuple() set() None {} or dict() -
浮点型用于表示小数,但是由于其内部存储原理可能会引发数据存储不够精准。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号