
快速上手
1.环境搭建
- Python解释器,将程序员编写的python代码翻译成计算机能够识别的指令。
- 主流CPython
- 3.9.0版本
- 学习编程本质上的3件事
- 安装 CPython 3.9.0版本解释器
- 学习Python语法并写代码
- 解释器去运行代码
1.1 安装Python解释器
1.1.1 mac系统
-
去Python官网下载Python解释器(3.9.0版本)
https://www.python.org/ -
安装
默认Python解释器安装目录: /Library/Frameworks/Python.framework/Versions/3.9 有bin目录下有一个 python3.9 文件,他就是Python解释器的启动文件。 解释器路径:/Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -
写一个简单的Python代码并且让解释器去运行。
name = input("请输入用户名:") print("欢迎使用NB系统:",name)将文件保存在:文稿/hello.py【/Users/wupeiqi/Documents/hello.py】
接下来要让解释器去运行代码文件:
- 打开终端 - 在终端输入:解释器 代码文件 /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 /Users/wupeiqi/Documents/hello.py -
【补充】系统环境变量
- 假设你有30个Python文件要运行 /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 /Users/wupeiqi/Documents/hello1.py ... /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 /Users/wupeiqi/Documents/hello30.py - Python解释器的路径每次不用再写这么长。 - 将 /Library/Frameworks/Python.framework/Versions/3.9/bin 添加到系统的环境变量中。 - 以后再使用Python解释器去运行python代码时,就可以这样: python3.9 /Users/wupeiqi/Documents/hello1.py ... python3.9 /Users/wupeiqi/Documents/hello2.py - 如何将 /Library/Frameworks/Python.framework/Versions/3.9/bin 添加到系统的环境变量中 ? - 默认你不用添加,默认Python解释器在安装的过程中已经帮你添加了。 - 自己手动想添加: - 打开用户目录的下的 .bash_profile 文件(.zprofile) - 在文件中写如下内容# Setting PATH for Python 3.9 # The original version is saved in .zprofile.pysave PATH="/Library/Frameworks/Python.framework/Versions/3.9/bin:${PATH}" export PATH
1.1.2 windows系统
-
Python官网下载Python解释器
https://www.python.org/downloads/release/python-390/ -
在自己电脑上进行安装
python解释器安装目录:C:\Python39 python解释器的路径:C:\Python39\python.exe -
编写一个Python代码并交给Python解释器去运行
name = input("请输入用户名") print("欢迎使用NB系统",name)并将文件保存在:Y:\hello.py
怎么让解释器去运行写好的代码文件呢?
- 打开终端 - 在终端输入:解释器路径 代码路径 -
优化配置(让以后操作Python解释器去运行代码时候更加方便)
- 写了30个Python代码,想要使用解释器去运行。 C:\Python39\python.exe Y:\hello1.py C:\Python39\python.exe Y:\hello2.py ... C:\Python39\python.exe Y:\hello10.py - 然你以后可以方便的去运行代码,不用再写Python解释器所在的路径。 只要你将 C:\Python39 路径添加到系统的环境变量中。以后你在终端就可以: python.exe Y:\hello1.py - 如何将 C:\Python39 添加到环境变量呢?【默认在解释器安装的时已自动添加到环境变量了】
1.2 安装Pycharm编辑器(mac)
帮助我们快速编写代码,用Pycharm可以大大的提高咱们写代码的效率。 + 用解释器去运行代码。
print("asdfasdf")
-
下载Pycharm
https://www.jetbrains.com/pycharm/ -
安装
-
快速使用,写代码+运行代码
-
破解Pycharm(专业版)
1.3 安装Pycharm编辑器(win)
-
下载Pycharm
https://www.jetbrains.com/pycharm/download/other.html -
安装
-
快速使用:编写代码 + 运行代码
-
破解Pycharm(专业版)
2.输出
关于输出:
-
默认print在尾部会加换行符
print("看着风景美如画") print("本想吟诗增天下") 输出: 看着风景美如画 本想吟诗增天下 -
想要不换行,则可以这样干
print("看着风景美如画",end="") print("本想吟诗增天下",end="") 输出: 看着风景美如画本想吟诗增天下print("看着风景美如画",end=",") print("本想吟诗增天下",end=".") 输出: 看着风景美如画,本想吟诗增天下.
3. 变量
变量,其实就是我们生活中起别名和外号,让变量名指向某个值,格式为: 【变量名 = 值】,以后可以通过变量名来操作其对应的值。
name = "武沛齐"
print(name) # 武沛齐
age = 18
name = "alex"
flag = 1 > 18
address = "北京昌平" + "沙河"
addr = "北京昌平" + "沙河" + name # "北京昌平沙河alex"
print(addr)
print(flag)
age = 18
number = 1 == 2
注意:
- 给变量赋值
age = 18 - 让age代指值
age=18
3.1 变量名的规范
age = 18
name = "alex"
flag = 1 > 18
address = "北京昌平" + "沙河"
三个规范(只要有一条就会报错):
-
变量名只能由 字母、数字、下划线 组成。
-
不能以数字开头
na9me9 = "alex" -
不能用Python内置的关键字
def = "alex" break = 123[‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘exec’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘not’, ‘or’, ‘pass’, ‘print’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
两个建议:
-
下划线连接命名(小写)
father_name = "wupeiqi" brother_age = 19 -
见名知意
age = 18 color = "red" current_user_name = "吉诺比利"
3.2变量内存指向关系 👍
通过学习上述变量知识让我们对变量了有了初步认识,接下来我们就要从稍稍高级一些的角度来学习变量,即:内存指向(在电脑的内存中是怎么存储的)。
情景一
name = "wupeiqi"
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域。
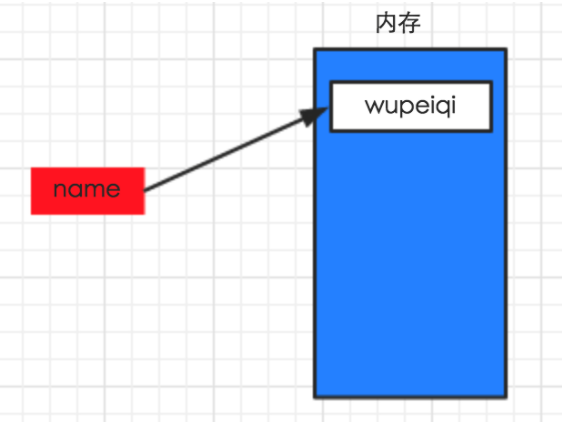
情景二
name = "wupeiqi"
name = "alex"
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域。然后又再内存中创建了一块域保存字符串”alex”,name变量名则指向”alex”所在的区域,不再指向”wupeiqi”所在区域(无人指向的数据会被标记为垃圾,由解释器自动化回收)
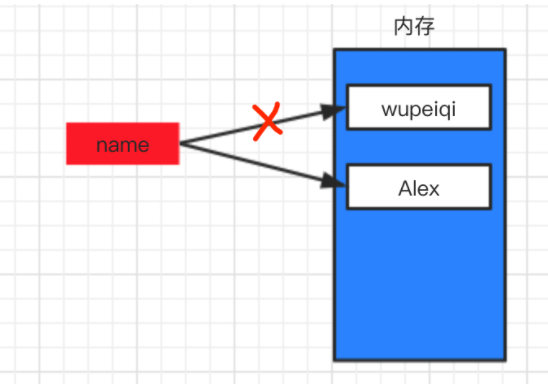
情景三
name = "wupeiqi"
new_name = name
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域。new_name变量名指向name变量,因为被指向的是变量名,所以自动会转指向到name变量代表的内存区域。
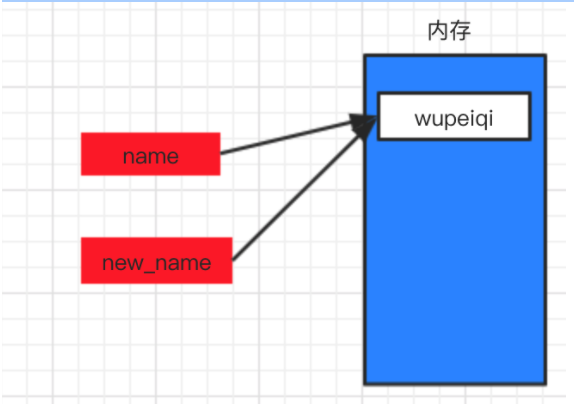
情景四
name = "wupeiqi"
new_name = name
name = "alex"
在计算机的内存中创建一块区域保存字符串”wupeiqi”,name变量名则指向这块区域(灰色线), 然后new_name指向name所指向的内存区域,最后又创建了一块区域存放”alex”,让name变量指向”alex”所在区域.
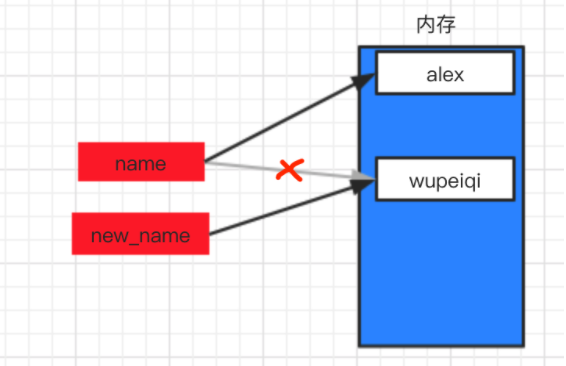
情景五
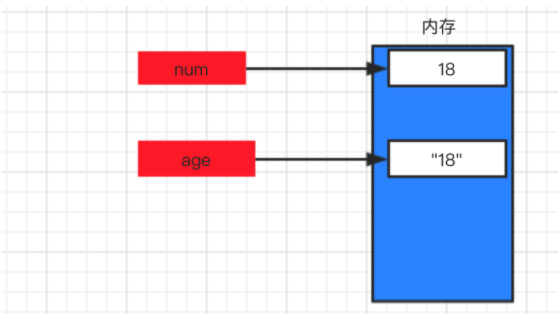
num = 18
age = str(num)
在计算机的内存中创建一块区域保存整型18,name变量名则指向这块区域。通过类型转换依据整型18再在内存中创建一个字符串”18”, age变量指向保存这个字符串的内存区域。
至此,关于变量的内存相关的说明已讲完,由于大家都是初学者,关于变量的内存管理目前只需了解以上知识点即可,更多关于内存管理、垃圾回收、驻留机制等问题在后面的课程中会讲解。
4. 注释
写代码时候,如果想要对某写内容进行注释处理,即:解释器忽略不会按照代码去运行。
-
单行注释
# 声明一个name变量 name = "alex" age = 19 # 这表示当前用户的年龄 注意:快捷点 command + ? 、 control + ? -
多行注释
# 声明一个name变量 # 声明一个name变量 # 声明一个name变量 name = "alex" """ 多行注释内容 多行注释内容 多行注释内容 """ age = 19
5. 输入
输入,可以实现程序和用户之间的交互。
# 1. 右边 input("请输入用户名:") 是让用户输入内容。
# 2. 将用户输入的内容赋值给name变量。
name = input("请输入用户名:")
if name == "alex":
print("登录成功")
else:
print("登录失败")
data = input(">>>")
print(data)
特别注意:用户输入的任何内容本质上都是字符串。
-
提示输入姓名,然后给姓名后面拼接一个“烧饼”,提示输入姓名,然后给姓名后面拼接一个“烧饼”,最终打印结果。
name = input("请输入用户名:") text = name + "烧饼" print(text) -
提示输入 姓名/位置/行为,然后做拼接并打印:xx 在 xx 做 xx 。
name = input("请输入用户名:") address = input("请输入位置:") action = input("请输入行为:") text = name + "在" + address + action print(text) -
提示输入两个数字,计算两个数的和。
number1 = input("请输入一个数字:") # "1" number2 = input("请输入一个数字:") # "2" value = int(number1) + int(number2) print(value)
6.条件语句
if 条件 :
条件成立之后的代码...
条件成立之后的代码...
条件成立之后的代码...
else:
条件不成立之后执行的代码...
条件不成立之后执行的代码...
条件不成立之后执行的代码...
name = input("请输入用户名:")
if name == "alex":
print("sb")
else:
print("db")
提醒:统一缩进问题(都是使用四个空格 = tab)。
name = input("请输入用户名:")
if name == "alex":
print("sb")
print("sb")
else:
print("db")
6.1 基本条件语句
-
示例1
print("开始") if True: print("123") else: print("456") print("结束") # 输出结果 开始 123 结束 -
示例2
print("开始") if 5==5: print("123") else: print("456") print("结束") -
示例3
num = 19 if num > 10: print("num变量对应值大于10") else: print("num变量对应值不大于10") -
示例4
username = "wupeiqi" password = "666" if username == "wupeiqi" and password == "666": print("恭喜你,登录成功") else: print("登录失败") -
示例5
username = "wupeiqi" if username == "wupeiqi" or username == "alex": print("VIP大会员用户") else: print("普通用户") -
示例6
number = 19 if number%2 == 1: print("number是奇数") else: print("number是偶数")number = 19 data = number%2 == 1 if data: print("number是奇数") else: print("number是偶数") -
示例7
if 条件: 成立print("开始") if 5 == 5: print("5等于5") print("结束")
6.2 多条件判断
if 条件A:
A成立,执行此缩进中的所有代码
...
elif 条件B:
B成立,执行此缩进中的所有代码
...
elif 条件C:
C成立,执行此缩进中的所有代码
...
else:
上述ABC都不成立。
num = input("请输入数字")
data = int(num)
if data>6:
print("太大了")
elif data == 6:
print("刚刚好")
else:
print("太小了")
score = input("请输入分数")
data = int(score)
if data > 90:
print("优")
elif data > 80:
print("良")
elif data > 70:
print("中")
elif data > 60:
print("差")
else:
print("不及格")
6.3 条件嵌套
if 条件A:
...
elif 条件B:
...
if 条件A:
if 条件A1:
...
else:
...
elif 条件B:
...
模拟10086客服
print("欢迎致电10086,我们提供了如下服务: 1.话费相关;2.业务办理;3.人工服务")
choice = input("请选择服务序号")
if choice == "1":
print("话费相关业务")
cost = input("查询话费请按1;交话费请按2")
if cost == "1":
print("查询话费余额为100")
elif cost == "2":
print("交互费")
else:
print("输入错误")
elif choice == "2":
print("业务办理")
elif choice == "3":
print("人工服务")
else:
print("序号输入错误")
7. 循环语句
- while循环
- for循环(后期)
while 条件:
...
...
...
print("123")
while 条件:
...
...
...
print(456)
7.1 循环语句基本使用
示例1:
print("开始")
while True:
print("Alex是个小都比")
print("结束")
# 输出:
开始
Alex是个小都比
Alex是个小都比
Alex是个小都比
Alex是个小都比
...
示例2:
print("开始")
while 1 > 2:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")
# 输出:
开始
结束
示例3:
data = True
print("开始")
while data:
print("如果祖国遭受到侵犯,热血男儿当自强。")
print("结束")
# 输出:
开始
如果祖国遭受到侵犯,热血男儿当自强。
如果祖国遭受到侵犯,热血男儿当自强。
如果祖国遭受到侵犯,热血男儿当自强。
...
示例4:
print("开始")
flag = True
while flag:
print("滚滚黄河,滔滔长江。")
flag = False
print("结束")
# 输出:
开始
滚滚黄河,滔滔长江。
结束
示例5:
print("开始")
num = 1
while num < 3:
print("滚滚黄河,滔滔长江。")
num = 5
print("结束")
# 输出:
开始
滚滚黄河,滔滔长江。
结束
示例6:
print("开始")
num = 1
while num < 5:
print("给我生命,给我力量。")
num = num + 1
print("结束")
# 输出:
开始
给我生命,给我力量。
给我生命,给我力量。
给我生命,给我力量。
给我生命,给我力量。
结束
练习题:重复3次输出我爱我的祖国。
num = 1
while num < 4:
print("我爱我的祖国")
num = num + 1
我爱我的祖国
我爱我的祖国
我爱我的祖国
7.2 综合小案例
请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
# 请实现一个用户登录系统,如果密码错误则反复提示让用户重新输入,直到输入正确才停止。
print("开始运行路飞系统")
flag = True
while flag:
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == "wupeiqi" and pwd == "luffy":
print("登录成功")
flag = False
else:
print("用户名或密码错误")
print("系统结束")
7.3 break
break,用于在while循环中帮你终止循环。
print("开始")
while True:
print("1")
break
print("2")
print("结束")
# 输出
开始
1
结束
通过示例来更深入理解break的应用。
示例1:
print("开始")
while True:
print("红旗飘飘,军号响。")
break
print("剑已出鞘,雷鸣电闪。")
print("从来都是狭路相逢勇者胜。")
print("结束")
示例2:
print("开始")
i = 1
while True:
print(i)
i = i + 1
if i == 101:
break
print("结束")
# 输出
开始
1
2
...
100
结束
示例3:
print("开始运行系统")
while True:
user = input("请输入用户名:")
pwd = input("请输入密码:")
if user == 'wupeiqi' and pwd = "oldboy":
print("登录成功")
break
else:
print("用户名或密码错误,请重新登录")
print("系统结束")
# 输出
开始运行系统
>>> 用户名
>>> 密码
正确,登录成功
系统结束
不正确,一直循环输出
所以,以后写代码时候,想要结束循环可以通过两种方式实现了,即:条件判断 和 break关键字,两种在使用时无好坏之分,只要能实现功能就行。
7.4 continue
continue,在循环中用于 结束本次循环,开始下一次循环。
print("开始")
while True:
print(1)
continue
print(2)
print(3)
print("结束")
示例1:
print("开始")
while True:
print("红旗飘飘,军号响。")
continue
print("剑已出鞘,雷鸣电闪。")
print("从来都是狭路相逢勇者胜。")
print("结束")
# 输出
开始
红旗飘飘,军号响。
红旗飘飘,军号响。
红旗飘飘,军号响。
红旗飘飘,军号响。
...
示例2:
print("开始")
i = 1
while i < 101:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
print("结束")
# 输出
开始
1
2
3
4
5
6
8
9
10
...
100
结束
示例3:
print("开始")
i = 1
while True:
if i == 7:
i = i + 1
continue
print(i)
i = i + 1
if i == 101:
break
print("结束")
# 输出
开始
1
2
3
4
5
6
8
9
10
...
100
结束
写在最后,对于break和continue都是放在循环语句中用于控制循环过程的,一旦遇到break就停止所有循环,一旦遇到continue就停止本次循环,开始下次循环。
当然,通过如果没有了break和continue,我们用while条件的判断以及其他协助也能完成很多功能,有了break和continue可以在一定程度上简化我们的代码逻辑。
7.5 while else
当while后的条件不成立时,else中的代码就会执行。
while 条件:
代码
else:
代码
while False:
pass
else:
print(123)
num = 1
while num < 5:
print(num)
num = num + 1
else:
print(666)
# 输出
1
2
3
4
666
while True:
print(123)
break
else:
print(666)
# 输出
123
8.字符串格式化
字符串格式化,使用跟便捷的形式实现字符串的拼接。
8.1 %
8.1.1 基本格式化操作
name = "武沛齐"
# 占位符
# text = "我叫%s,今年18岁" %"武沛齐"
text = "我叫%s,今年18岁" %name
name = "武沛齐"
age = 18
# text = "我叫%s,今年%s岁" %("武沛齐",18)
# text = "我叫%s,今年%s岁" %(name,age)
text = "我叫%s,今年%d岁" %(name,age)
https://www.cnblogs.com/wupeiqi/articles/5484747.html
message = "%(name)s你什么时候过来呀?%(user)s今天不在呀。" % {"name": "死鬼", "user": "李杰"}
print(message)
8.1.2 百分比
text = "兄弟,这个片我已经下载了90%了,居然特么的断网了"
print(text)
text = "%s,这个片我已经下载了90%%了,居然特么的断网了" %"兄弟"
print(text)
# 输出:
兄弟,这个片我已经下载了90%了,居然特么的断网了
一旦字符串格式化中存现百分比的显示,请一定要呀加 %% 以实现输出 %。
8.2 format(推荐)
text = "我叫{0},今年18岁".format("武沛齐")
text = "我叫{0},今年{1}岁".format("武沛齐",18)
text = "我叫{0},今年{1}岁,真是的姓名是{0}。".format("武沛齐",18)
text = "我叫{},今年18岁".format("武沛齐")
text = "我叫{},今年{}岁".format("武沛齐",18)
text = "我叫{},今年{}岁,真是的姓名是{}。".format("武沛齐",18,"武沛齐")
text = "我叫{n1},今年18岁".format(n1="武沛齐")
text = "我叫{n1},今年{age}岁".format(n1="武沛齐",age=18)
text = "我叫{n1},今年{age}岁,真是的姓名是{n1}。".format(n1="武沛齐",age=18)
text = "我叫{0},今年{1}岁"
data1 = text.format("武沛齐",666)
data2 = text.format("alex",73)
text = "我叫%s,今年%d岁"
data1 = text %("武沛齐",20)
data2 = text %("alex",84)
8.3 f
到Python3.6版本,更便捷。
text = f"嫂子喜欢{'跑步'},跑完之后满身大汗"
action = "跑步"
text = f"嫂子喜欢{action},跑完之后满身大汗"
name = "喵喵"
age = 19
text = f"嫂子的名字叫{name},今年{age}岁"
print(text)
text = f"嫂子的名字叫喵喵,今年{19 + 2}岁"
print(text)
# 在Python3.8引入
text = f"嫂子的名字叫喵喵,今年{19 + 2=}岁"
print(text)
# 进制转换
v1 = f"嫂子今年{22}岁"
print(v1)
v2 = f"嫂子今年{22:#b}岁"
print(v2)
v3 = f"嫂子今年{22:#o}岁"
print(v3)
v4 = f"嫂子今年{22:#x}岁"
print(v4)
# 理解
text = f"我是{'alex'},我爱大铁锤"
name = "alex"
text = f"我是{name},我爱大铁锤"
name = "alex"
text = f"我是{ name.upper() },我爱大铁锤"
# 输出:我是ALEX,我爱大铁锤
9. 运算符
提到运算符,我想大家首先想到的就是加、减、乘、除之类, 本节要系统的跟大家来聊一聊,我们写代码时常见的运算符可以分为5种:
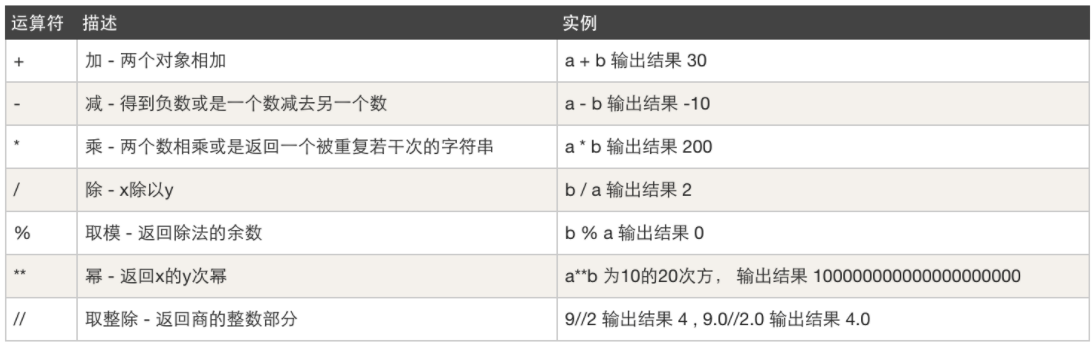
- 算数运算符,例如:加减乘除
- 比较运算符,例如:大于、小于

注意:python3中不支持 <>
if 1 >2:
pass
while 1>2:
pass
data = 1 == 2
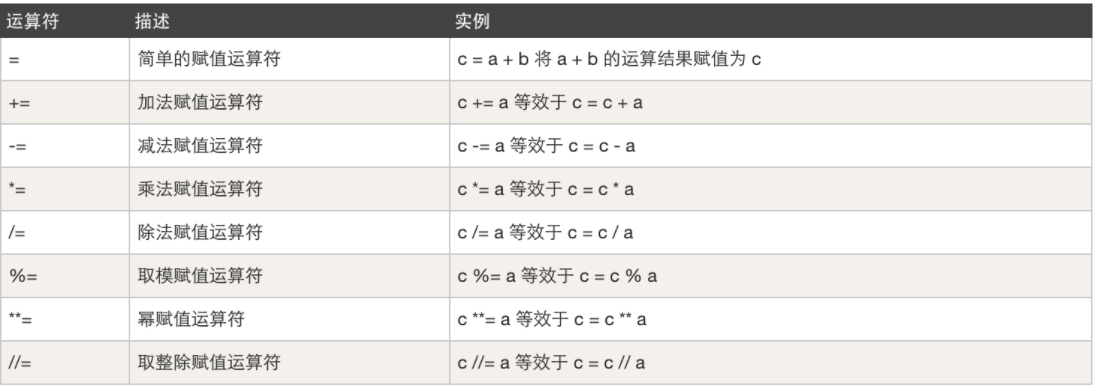
- 赋值运算,例如:变量赋值
num = 1
while num < 100:
print(num)
# num = num + 1
num += 1
- 成员运算,例如:是否包含

v1 = "le" in "alex" # True/False
# 让用户输入一段文本,检测文本中是否包含敏感词。
text = input("请输入内容:")
if "苍老师" in text:
print("少儿不宜")
else:
print(text)
- 逻辑运算,例如:且或非

if username == "alex" and pwd == "123":
pass
data = 1 > 2
if not data:
pass
9.1 运算符优先级
运算符的优先级有很多,常见的没几个,推荐你记住3个即可:
-
算数优先级优先级 大于 比较运算符
if 2 + 10 > 11: print("真") else: print("假") -
比较运算符优先级 大于 逻辑运算符
if 1>2 and 2<10: print("成立") else: print("不成立") -
逻辑运算符内部三个优先级 not > and > or
if not 1 and 1>2 or 3 == 8: print("真") else: print("假")
上述这3个优先级从高到低总结:加减乘除 > 比较 > not and or 。绝招:加括号。
9.2 面试题
逻辑运算中:and or
v1 = name == "alex" and pwd == "123"
# v1 = True and False
if name == "alex" and pwd == "123":
pass
v2 = "wupeiqi" and "alex"
# 第一步:将and前后的只转换为布尔值 True and True
# 第二步:判断本次操作取悦于谁?由于前面的是True,所以本次逻辑判断取决于后面的值。
# 所以,后面的只等于多少最终结果就是多少。 v2 = "alex"
v3 = "" and "alex"
# 第一步:将and前后的只转换为布尔值 False and True
# 第二步:判断本次操作取悦于谁?由于前面的是False,所以本次逻辑判断取决于前面的值。
# 所以,前面的只等于多少最终结果就是多少。 v2 = ""
v4 = 1 or 8
# 第一步:将and前后的只转换为布尔值 True or True
# 第二步:判断本次操作取悦于谁?由于前面的是True,所以本次逻辑判断取决于前面的值。
# v4 = 1
v5 = 0 or 8
# 第一步:将and前后的只转换为布尔值 False or True
# 第二步:判断本次操作取悦于谁?由于前面的是False,所以本次逻辑判断取决于后面的值。
# v5 = 8
and,看第一个值,如果第一个值真,结果就应该是第二个值,否则结果就是第一个值。
or,看第一个值,如果第一个值为真,结果就应该是第一个值,否则就结果就是第二个值。
not,先计算not,在计算and,最后计算or。
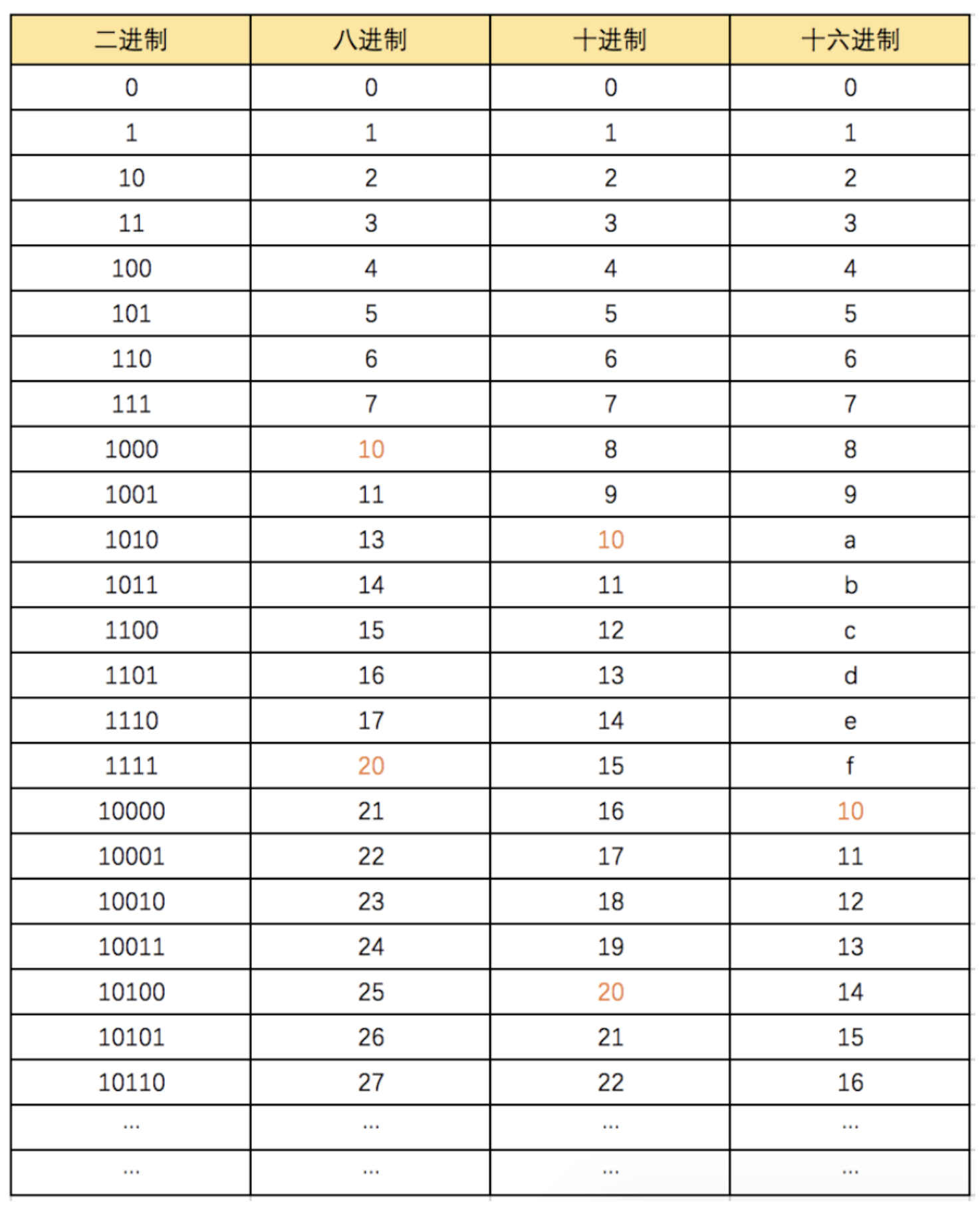
10.进制
计算机中底层所有的数据都是以 010101的形式存在(图片、文本、视频等)。
-
二进制
0 1 10 -
八进制
-
十进制
-
十六进制
10.1 进制转换 👍
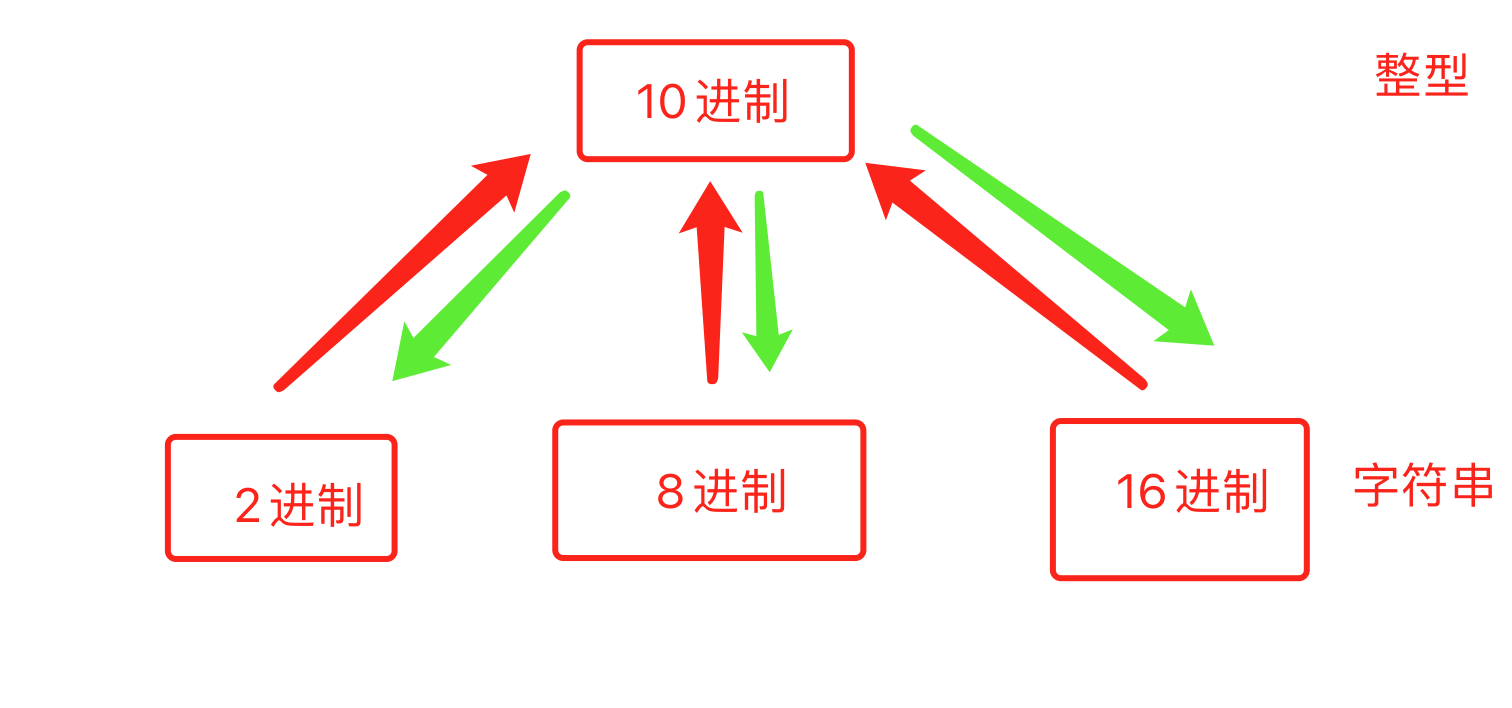
v1 = bin(25) # 十进制转换为二进制
print(v1) # "0b11001"
v2 = oct(23) # 十进制转换为八进制
print(v2) # "0o27"
v3 = hex(28) # 十进制转换为十六进制
print(v3) # "0x1c"
i1 = int("0b11001",base=2) # 25
i2 = int("0o27",base=8) # 23
i3 = int("0x1c",base=16) # 28
11. 计算机中的单位
由于计算机中本质上所有的东西以为二进制存储和操作的,为了方便对于二进制值大小的表示,所以就搞了一些单位。
-
b(bit),位
1,1位 10,2位 111,3位 1001,4位 -
B(byte),字节
8位是一个字节。 10010110,1个字节 10010110 10010110,2个字节 -
KB(kilobyte),千字节
1024个字节就是1个千字节。 10010110 11010110 10010111 .. ,1KB 1KB = 1024B= 1024 * 8 b -
M(Megabyte),兆
1024KB就是1M 1M= 1024KB = 1024 * 1024 B = 1024 * 1024 * 8 b -
G(Gigabyte),千兆
1024M就是1G 1 G= 1024 M= 1024 *1024KB = 1024 * 1024 * 1024 B = 1024 * 1024 * 1024 * 8 b -
T(Terabyte),万亿字节
1024个G就是1T -
...其他更大单位 PB/EB/ZB/YB/BB/NB/DB 不再赘述。
做个小练习:
-
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么1G流量可以通过网络传输多少汉字呢?(计算机传输本质上也是二进制)
1G = 1024M = 1024 * 1024KB = 1024 * 1024 * 1024 B 每个汉字需要2个字节表示 1024 * 1024 * 1024/2 = ? -
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么500G硬盘可以存储多少个汉字?
500G = 500 * 1024M = 500 * 1024 * 1024KB = 500 * 1024 * 1024 * 1024 B 500 * 1024 * 1024 * 1024 / 2 = ?
12.编码
编码,文字和二进制之间的一个对照表。
12.1 ascii编码
ascii规定使用1个字节来表示字母与二进制的对应关系。
00000000
00000001 w
00000010 B
00000011 a
...
11111111
2**8 = 256
12.2 gb-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)。
gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。
在与二进制做对应关系时,由如下逻辑:
- 单字节表示,用一个字节表示对应关系。2**8 = 256
- 双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性。
12.3 unicode
unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。
-
ucs2
用固定的2个字节去表示一个文字。 00000000 00000000 悟 ... 2**16 = 65535 -
ucs4
用固定的4个字节去表示一个文字。 00000000 00000000 00000000 00000000 无 ... 2**32 = 4294967296
文字 十六进制 二进制
ȧ 0227 1000100111
ȧ 0227 00000010 00100111 ucs2
ȧ 0227 00000000 00000000 00000010 00100111 ucs4
乔 4E54 100111001010100
乔 4E54 01001110 01010100 ucs2
乔 4E54 00000000 00000000 01001110 01010100 ucs4
😆 1F606 11111011000000110
😆 1F606 00000000 00000001 11110110 00000110 ucs4
无论是ucs2和ucs4都有缺点:浪费空间?
文字 十六进制 二进制
A 0041 01000001
A 0041 00000000 01000001
A 0041 00000000 00000000 00000000 01000001
unicode的应用:在文件存储和网络传输时,不会直接使用unicode,而在内存中会unicode。
12.4 utf-8编码
包含所有文字和二进制的对应关系,全球应用最为广泛的一种编码(站在巨人的肩膀上功成名就)。
本质上:utf-8是对unicode的压缩,用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8
0000 ~ 007F 用1个字节表示
0080 ~ 07FF 用2个字节表示
0800 ~ FFFF 用3个字节表示
10000 ~ 10FFFF 用4个字节表示
具体压缩的流程:
-
第一步:选择转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "武" 对应的unicode码位为 6B66,则应该选择第三个模板。 "沛" 对应的unicode码位为 6C9B,则应该选择第三个模板。 "齐" 对应的unicode码位为 9F50,则应该选择第三个模板。 😆 对应的unicode码位为 1F606,则应该选择第四个模板。 注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 -
第二步:在模板中填入数据
- "武" -> 6B66 -> 110 101101 100110 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”武“ 11100110 10101101 10100110 - 😆 -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110
12.5 Python相关的编码
字符串(str) "alex媳妇叫铁锤" unicode处理 一般在内存
字节(byte) b"alexfdsfdsdfskdfsd" utf-8编码 or gbk编码 一般用于文件或网络处理
v1 = "武"
v2 = "武".encode("utf-8")
v2 = "武".encode("gbk")
将一个字符串写入到一个文件中。
name = "嫂子热的满身大汗"
data = name.encode("utf-8")
# 打开一个文件
file_object = open("log.txt",mode="wb")
# 在文件中写内容
file_object.write(data)
# 关闭文件
file_object.close()
总结
本章的知识点属于理解为主,了解这些基础之后有利于后面知识点的学习,接下来对本节所有的知识点进行归纳总结:
-
计算机上所有的东西最终都会转换成为二进制再去运行。
-
ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。
- ascii,字符和二进制的对照表。
- unicode,字符和二进制(码位)的对照表。
- utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。
-
ucs2和ucs4指的是使用多少个字节来表示unicode字符集的码位。
-
目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对码位进行压缩了)。
-
二进制、八进制、十进制、十六进制其实就是进位的时机不同。
-
基于Python实现二进制、八进制、十进制、十六进制之间的转换。
-
一个字节8位
-
计算机中常见单位b/B/KB/M/G的关系。
-
汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。
-
基于Python实现将字符串转换为字节(utf-8编码)
# 字符串类型 name = "武沛齐" print(name) # 武沛齐 # 字符串转换为字节类型 data = name.encode("utf-8") print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90' # 把字节转换为字符串 old = data.decode("utf-8") print(old) -
基于Python实现将字符串转换为字节(gbk编码)
# 字符串类型 name = "武沛齐" print(name) # 武沛齐 # 字符串转换为字节类型 data = name.encode("gbk") # print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90' utf8,中文3个字节 print(data) # b'\xce\xe4\xc5\xe6\xc6\xeb' gbk,中文2个字节 # 把字节转换为字符串 old = data.decode("gbk") print(old)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号