

RAG学习
RAG
大模型面临的问题
- 易出现幻觉
- 利用文档减少幻觉但文档内容太多、大模型寻找答案变难
什么是RAG
RAG,全称Retrieval Augmented Generation,检索增强生成。RAG旨在解决从文档中抽取与用户问题相关的文字片段。
Embedding模型————RAG的基础
将一句话、一段话抽象为一个向量
Chunking(切块)
文档 --> chunking --> embedding
向量数据库
用于存储chunking、embedding后的结果的数据库,利用该数据库寻找与问题向量接近的向量
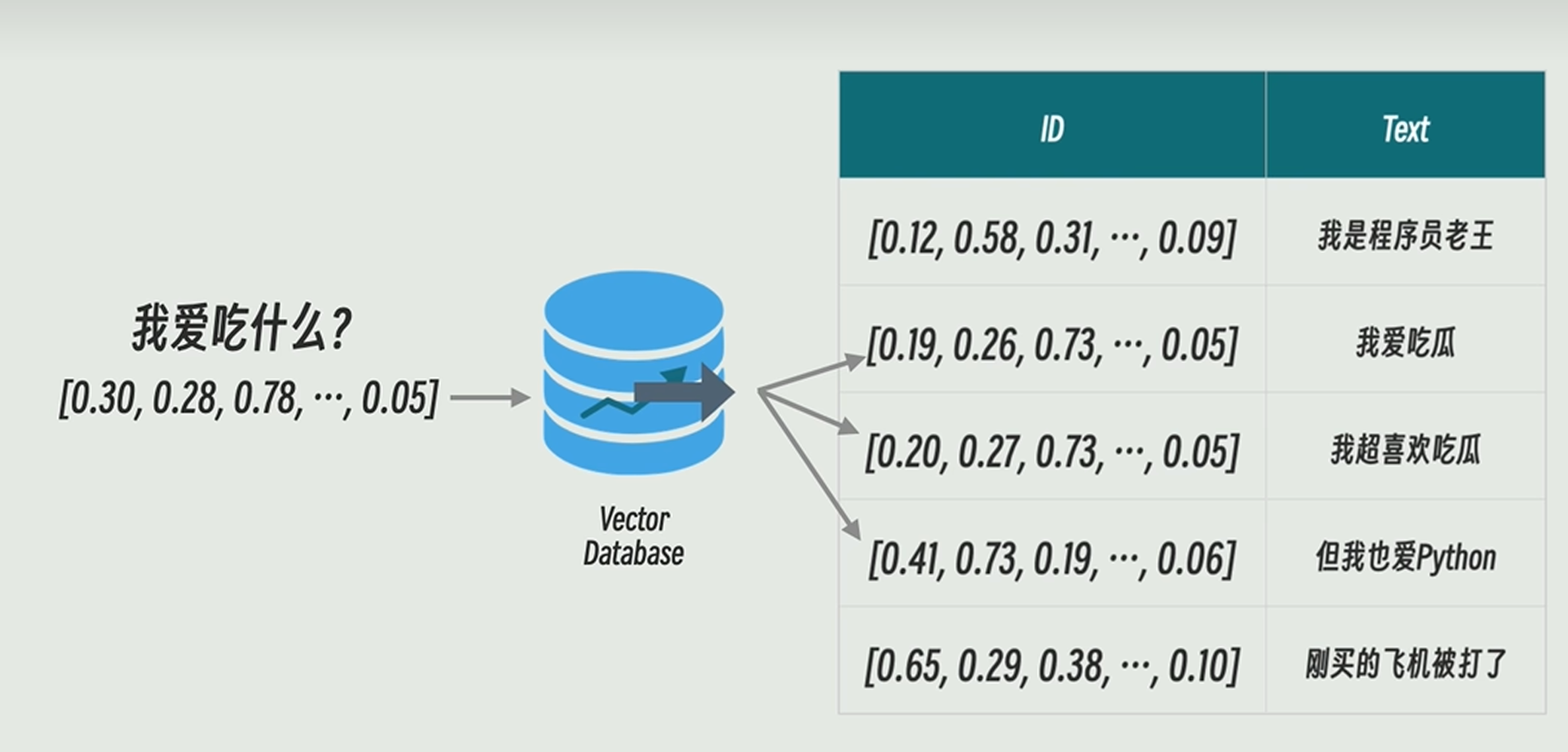
- 常见的数据库有pinecone、chromaDB、PostgreSQL+pgvector
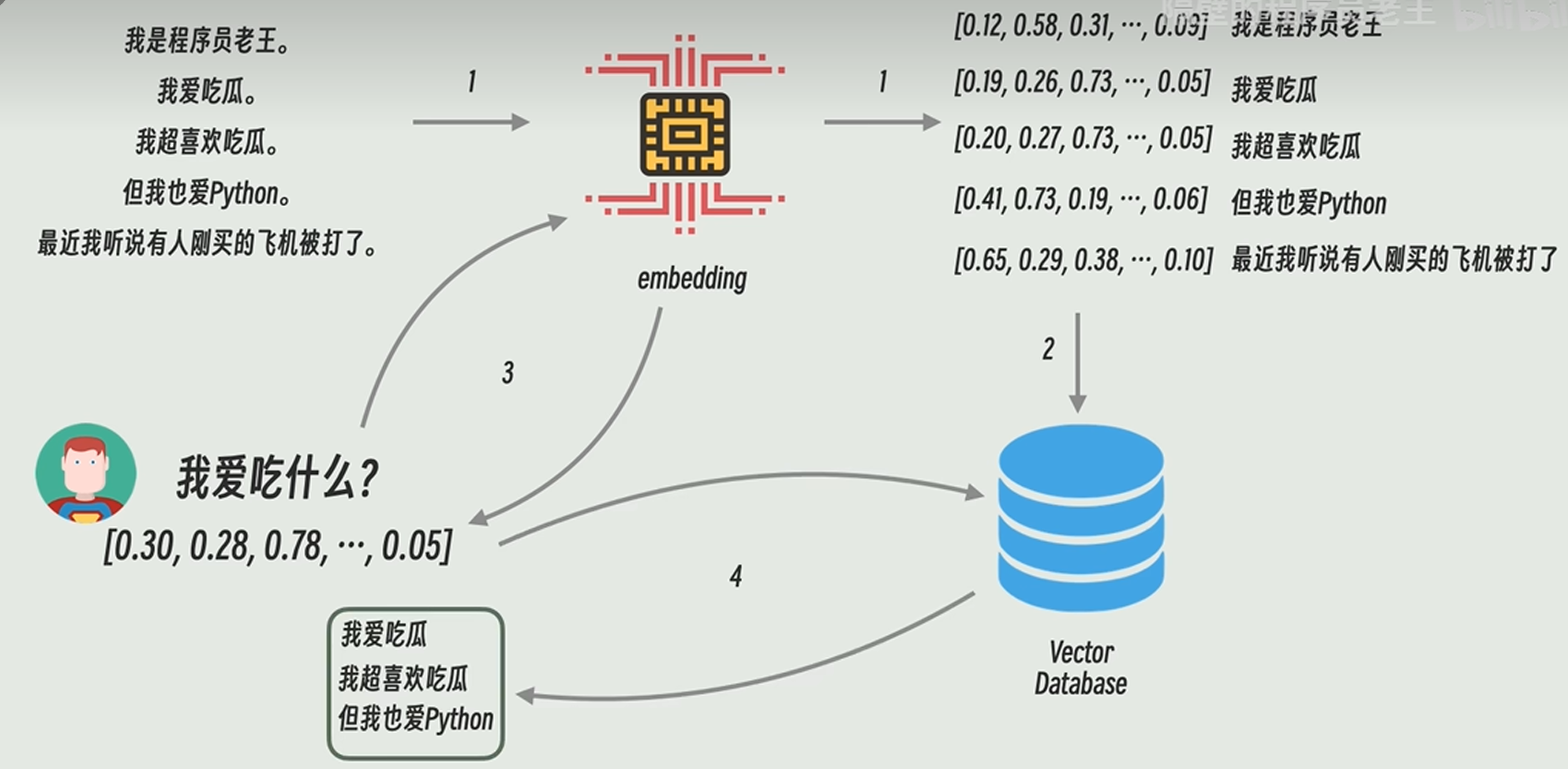
利用RAG的大模型全流程
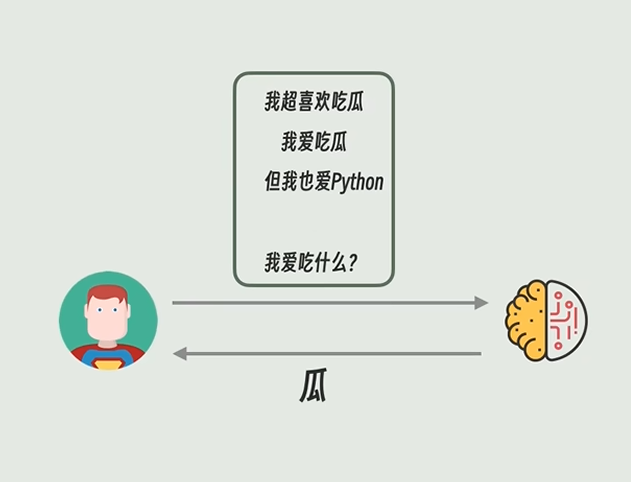
RAG的困境
- 分块可能会将关键信息切割
- RAG缺乏全局的视角

 浙公网安备 33010602011771号
浙公网安备 33010602011771号