
前端入门01——HTML
漫画引入
前端
什么是前端
"""
任何与用户直接打交道的操作界面都可以称之为前端
比如:电脑界面 手机界面 平板界面
什么是后端
后端类似于幕后操作者(一堆让人头皮发麻的代码)
不直接跟用户打交道
"""
为什么学前端
"""
因为我们是全栈开发工程师
但是前端这一块我们不会学的很详细
只要求做到能够看得懂基本的前端代码以及能够搭建一些简单的页面即可
先打下前端的基础 为后续可能需要扩展做准备
"""
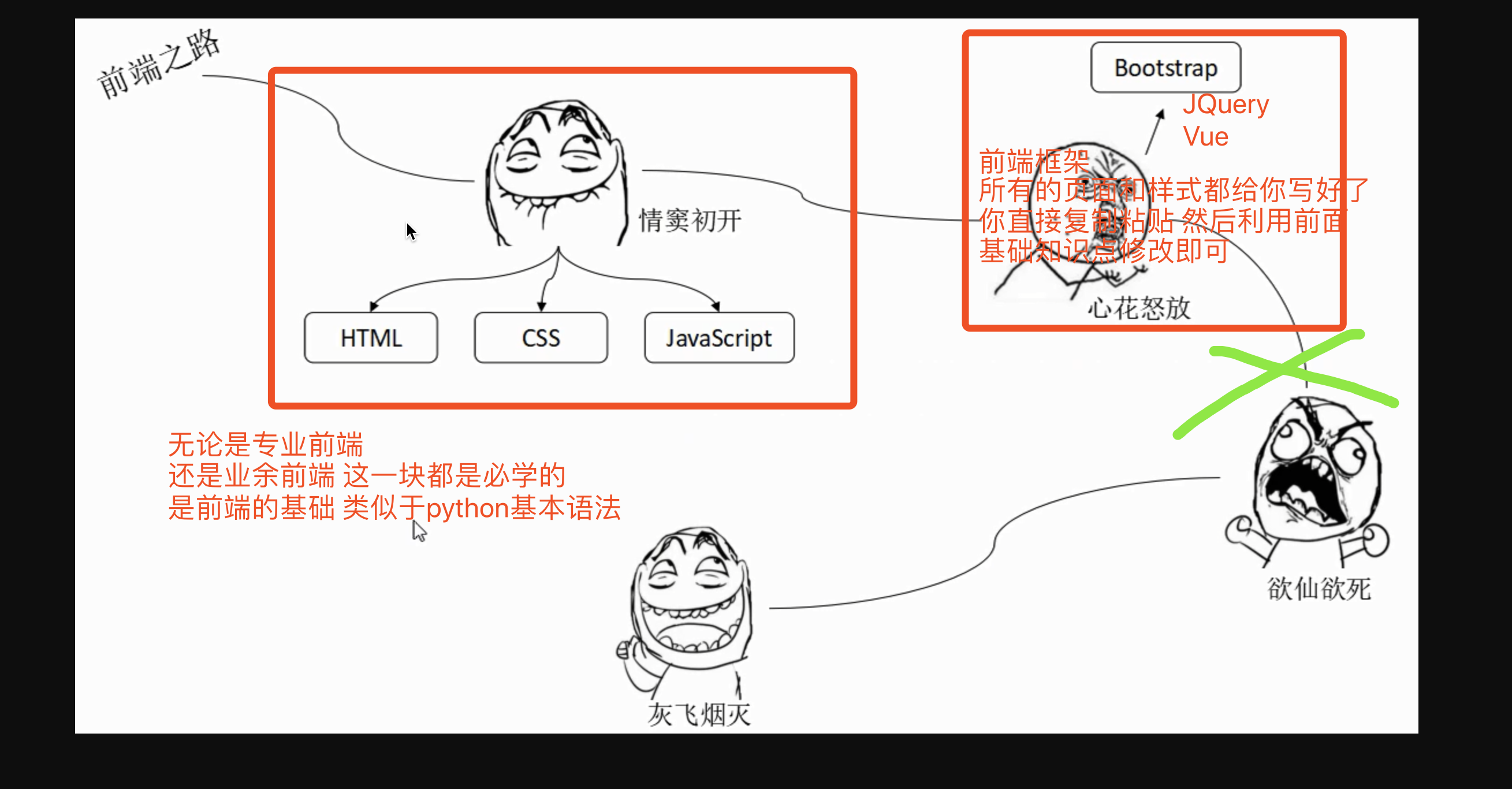
前端学习历程
HTML:网页的骨架 没有任何的样式
CSS:给骨架添加各种样式 变得好看
JS:控制网页的动态效果
前端框架:BOOTSTRAP、JQuery、Vue
提前给你封装好了很多操作 你只需要按照固定的语法调用即可
软件开发架构
cs 客户端 服务端
bs 浏览器 服务端
ps:bs本质也是cs
浏览器窗口输入网址回车发生了几件事
"""
1 浏览器朝服务端发送请求
2 服务端接受请求(eg:请求百度首页)
3 服务端返回相应的响应(eg:返回一个百度首页)
4 浏览器接收响应 根据特定的规则渲染页面展示给用户看
"""
浏览器可以充当很多服务端的客户端
百度 腾讯视频 优酷视频....
如何做到浏览器能够跟多个不同的客户端之间进行数据交互?
1.浏览器很牛逼 能够自动识别不同服务端做不同处理
2.制定一个统一的标准 如果你想要让你写的服务端能够跟客户端之间做正常的数据交互
那么你就必须要遵循一些规则
HTTP协议
"""
超文本传输协议 用来规定服务端和浏览器之间的数据交互的格式...
该协议你可以不遵循 但是你写的服务端就不能被浏览器正常访问 你就自己跟自己玩
你就自己写客户端 用户想要使用 就下载你专门的app即可
"""
# 四大特性
1.基于请求响应
2.基于TCP/IP作用于应用层之上的协议
3.无状态
不保存用户的信息
eg:一个人来了一千次 你都记不住 每次都当他如初见
由于HTTP协议是无状态的 所以后续出现了一些专门用来记录用户状态的技术
cookie、session、token...
4.无/短链接
请求来一次我响应一次 之后我们两个就没有任何链接和关系了
长链接:双方建立连接之后默认不断开 websocket(后面讲项目的时候会讲)
# 请求数据格式
请求首行(标识HTTP协议版本,当前请求方式)
请求头(一大堆k,v键值对)
\r\n不能省略
请求体(并不是所有的请求方式都有get没有post有 存放的是post请求提交的敏感数据)
# 响应数据格式
响应首行(标识HTTP协议版本,响应状态码)
响应头(一大堆k,v键值对)
\r\n不能省略
响应体(返回给浏览器展示给用户看的数据)
# 响应状态码
用一串简单的数字来表示一些复杂的状态或者描述性信息 404:请求资源不存在
1XX:服务端已经成功接收到了你的数据正在处理,你可以继续提交额外的数据
2XX:服务端成功响应了你想要的数据(200 OK请求成功)
3XX:重定向(当你在访问一个需要登陆之后才能看的页面 你会发现会自动跳转到登陆页面)
4XX:请求错误
404:请求资源不存在
403:当前请求不合法或者不符合访问资源的条件
5XX:服务器内部错误(500)
# 请求方式
1.get请求
朝服务端要数据
eg:输入网址获取对应的内容
2.post请求
朝服务端提交数据
eg:用户登陆 输入用户名和密码之后 提交到服务端后端做身份校验
# url:统一资源定位符(大白话 网址)
HTML简介
超文本标记语言
如果你想要让浏览器能够渲染出你写的页面。你就必须遵循HTML语法
我们浏览器看到的页面,内部其实都是HTML代码(所有的网站内部都是HTML代码)
<h1>hello big baby~</h1> <a href="https://www.mzitu.com/">click me!give you some color to see see!</a> <img src="https://dss1.bdstatic.com/70cFuXSh_Q1YnxGkpoWK1HF6hhy/it/u=2159057472,1466656787&fm=26&gp=0.jpg" /> HTML就是书写网页的一套标准 # 注释:注释是代码之母 <!--单行注释--> <!-- 多行注释1 多行注释2 多行注释3 --> 由于HTML代码非常的杂乱无章并且很多,所以我们习惯性的用注释来划定区域方便后续的查找 <!--导航条开始--> 导航条所有的html代码 <!--导航条结束--> <!--左侧菜单栏开始--> 左侧菜单栏的HTMl代码 <!--左侧菜单栏结束-->
HTML文档结构
<html>
<head></head>:head内的标签不是给用户看的 而是定义一些配置主要是给浏览器看的
<body></body>:body内的标签 写什么浏览器就渲染什么 用户就能看到什么
</html>
PS:文件的后缀名其实是给用户看到的,只不过对应不同的 文件后缀名有不同的软件来处理并添加很多功能
注意:HTML代码是没有格式的,可以全部写在一行都没有问题,只不过我们习惯了缩进来表示代码
两种打开HTML文件的方式
-
找到文件所在的位置右键选择浏览器打开
-
在pycharm内部,集成了自动调用浏览器的功能,直接点击即可(前提是你的电脑上安装了对应的浏览器) 直接全部使用谷歌浏览器
标签的分类1
<h1></h1>
<a href="https://www.mzitu.com/"></a>
<img/>
1 双标签
2 单标签(自闭和标签)
head内常用标签
在书写HTML代码的时候 你只需要写标签名 然后tab就能自动补全
<title>Title</title> 网页标题
<style>
h1 {
color: greenyellow;
}
</style> 内部用来书写css代码
<script>
alert(123)
</script> 内部用来书写js代码
<script src="myjs.js"></script> 还可以引入外部js文件
<link rel="stylesheet" href="mycss.css"> 引入外部css文件
<meta name="keywords" content="老男孩教育,老男孩,老男孩培训,Python培训,Linux培训,网络安全培训,Go语言培训,人工智能培训,云计算培训,Linux运维培训,Python自动化运维,Python全栈开发,IT培训"> 当你在用浏览器搜索的时候 只要输入了keywords后面指定的关键字那么该网页都有可能被百度搜索出来展示给用户
<meta name="keyword" content="淘宝,掏宝,网上购物,C2C,在线交易,交易市场,网上交易,交易市场,网上买,网上卖,购物网站,团购,网上贸易,安全购物,电子商务,放心买,供应,买卖信息,网店,一口价,拍卖,网上开店,网络购物,打折,免费开店,网购,频道,店铺">
<meta name="description" content="淘宝网 - 亚洲较大的网上交易平台,提供各类服饰、美容、家居、数码、话费/点卡充值… 数亿优质商品,同时提供担保交易(先收货后付款)等安全交易保障服务,并由商家提供退货承诺、破损补寄等消费者保障服务,让你安心享受网上购物乐趣!"> 网页的描述性信息
body内常用标签
你肉眼能够在浏览器上面看到的花里胡哨的页面。内部都是HTML代码
基本标签
<h1>我是h1</h1> 标题标签 1~6级标题
<b>加粗</b>
<i>斜体</i>
<u>下划线</u>
<s>删除线</s>
<p>段落</p>
<br> 换行
<hr> 水平分割线
标签的分类2
1 块儿级标签:独占一行
h1~h6 p div
1 块儿级标签可以修改长宽 行内标签不可以 修改了也不会变化
2 块儿级标签内部可以嵌套任意的块儿级标签和行内标签
但是p标签虽然是块儿级标签 但是它只能嵌套行内标签 不能嵌套块儿级标签
如果你套了 问题也不大 因为浏览器会自动帮你解开(浏览器是直接面向用户的 不会轻易的报错 哪怕有报错用户也基本感觉不出来)
总结:
只要是块儿级标签都可以嵌套任意的块儿级标签和行内标签
但是p标签只能嵌套行内标签(HTML书写规范)
2 行内标签:自身文本多大就占多大
i u s b span
行内标签不能嵌套块儿级标签 可以嵌套行内标签
特殊符号
空格
> 大于号
< 小于号
& &
¥ ¥
© ©
商标® ®
常用标签
div 块儿级标签
span 行内标签
上述的两个标签是在构造页面初期最常使用的 页面的布局一般先用div和span占位之后再去调整样式 尤其是div使用非常的频繁
div你可以把它看成是一块区域 也就意味着用div来提前规定所有的区域
之后往该区域内部填写内容即可
而普通的文本先用span标签
img标签
# 图片标签
<img src="" alt="">
src
1.图片的路径 可以是本地的也可以是网上的
2.url 自动朝该url发送get请求获取数据
alt="这是我的前女友"
当图片加载不出来的时候 给图片的描述性信息
title="新垣结衣"
当鼠标悬浮到图片上之后 自动展示的提示信息
height="800px"
width=""
高度和宽度当你只修改一个的时候 另外一个参数会等比例缩放
如果你修改了两个参数 并且没有考虑比例的问题 那么图片就会失真
a标签
# 链接标签
<a href=""></a>
"""
当a标签指定的网址从来没有被点击过 那么a标签的字体颜色是蓝色
如果点击过了就会是紫色(浏览器给你记忆了)
"""
href
1.放url,用户点击就会跳转到该url页面
2.放其他标签的id值 点击即可跳转到对应的标签位置
target
默认a标签是在当前页面完成跳转 _self
你也可以修改为新建页面跳转 _blank
# a标签的锚点功能
"""eg:点击一个文本标题 页面自动跳转到标题对应的内容区域"""
<a href="" id="d1">顶部</a>
<h1 id="d111">hello world</h1>
<div style="height: 1000px;background-color: red"></div>
<a href="" id="d2">中间</a>
<div style="height: 1000px;background-color: greenyellow"></div>
<a href="#d1">底部</a>
<a href="#d2">回到中间</a>
<a href="#d111">回到中间</a>
标签具有的两个重要书写
1.id值
类似于标签的身份证号 在同一个html页面上id值不能重复
2.class值
该值有点类似于面向对象里面的继承 一个标签可以继承多个class值
标签既可以有默认的书写也可以有自定义的书写
<p id="d1" class="c1" username="jason" password="123"></p>
列表标签
-
无序列表(较多)
<ul> <li>第一项</li> <li>第二项</li> <li>第二项</li> <li>第二项</li> </ul> 虽然ul标签很丑 但是在页面布局的时候 只要是排版一致的几行数据基本上用的都是ul标签
-
有序列表(了解)
<ol type="1" start="5"> <li>111</li> <li>222</li> <li>333</li> </ol> 1 A I a ... 参考博客了机即可
-
标题列表(了解)
<dl> <dt>标题1</dt> <dd>内容1</dd> <dt>标题2</dt> <dd>内容2</dd> <dt>标题3</dt> <dd>内容3</dd> </dl>
总结
"""
学习前端就是死记硬背 思想关联一定要改变
学习HTML的时候 它是一门标记语言
你在学的时候 你就记每一个标签到底表示什么意思
p
h
"""
前端参考博客:https://www.cnblogs.com/Dominic-Ji/p/10864457.html
作业
1.总结学习方法,心态调整
2.HTTP协议默写
3.前端标签分类有几种
4.自己从头到尾将HTML标签敲一遍争取全部记忆

 浙公网安备 33010602011771号
浙公网安备 33010602011771号