对excel行的操作
import pandas sheet1=pandas.read_excel('成绩.xlsx',sheet_name='Sheet1') sheet2=pandas.read_excel('成绩.xlsx',sheet_name='Sheet2')
连接两张表
students=sheet1.append(sheet2).reset_index(drop=True) #drop指是否删除原index
print(students)
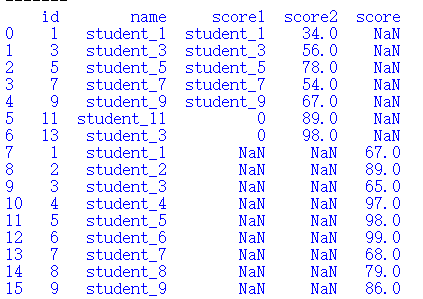
在连接表的最后一行追加一行数据
stu=pandas.Series({'id':10,'name':'student_8','score1':59,'score2':58,'score':78})
a=students.append(stu,ignore_index=True)
print(a)
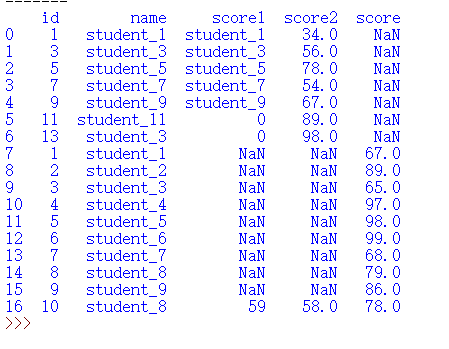
替换一个单元格的数据
a.at[10,'name']='张飞'
print(a)
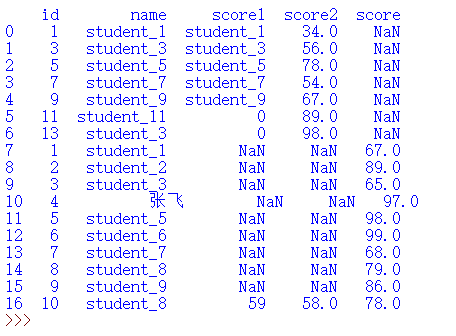
替换一行数据
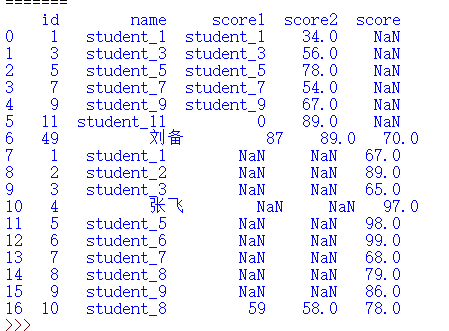
b=pandas.Series({'id':49,'name':'刘备','score1':87,'score2':89,'score':70})
a.iloc[6]=b
print(a)
插入一行数
c=pandas.Series({'id':49,'name':'关羽','score1':87,'score2':89,'score':70})
part1=a[:7]
part2=a[7:]
result=part1.append(c,ignore_index=True).append(part2).reset_index(drop=True)
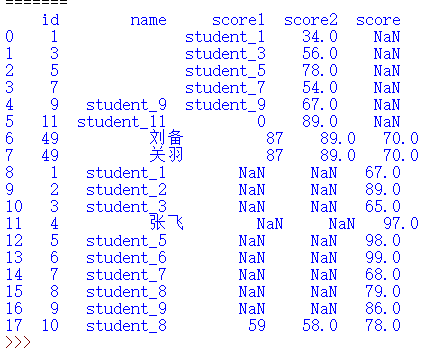
print(result)

把name这列数据部分变为空
for i in range(4): result['name'].at[i]='' print(result)
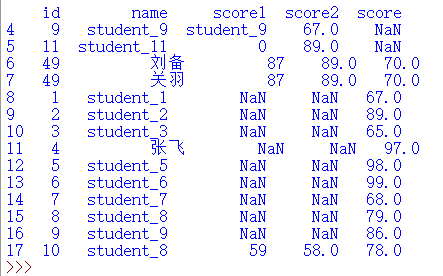
删除name列为空的数据行
#删除行数据
#result.drop(index=[0,1,2],inplace=True)
#result.drop(index=range(0,10),inplace=True)
#result.drop(index=result[0:10].index,inplace=True)
missing=result.loc[result['name']=='']
result.drop(index=missing.index,inplace=True)
print(result)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号