
都是假的---生成式对抗网络GAN完全指南终极版(一)
by:https://zhuanlan.zhihu.com/p/28216012

是不是奇怪我为啥子要放一堆室内装修的照片?
因为这些照片都是假的,全是神经网络自动生成的噢,不是拍的实景图。
今天呢,我们就来介绍一下一个现在很火的神经网络Generative Adversarial Networks,中文名叫做生成式对抗网络,以下呢就简称它为GAN。
一句话概况它---能实现无监督的无中生有过程。
还是老样子,从最简单浅显的例子入手开始讲解吧。
假设你是一个可爱又迷人的反派角色---生产假币的坏蛋
(@知乎小管家,这只是个栗子不要把我关小黑屋啊)。
既然是个大坏蛋,那你的目的当然是生产出能够以假乱真的假币拿出去用来赚钱咯。你组建了一个造假团队,但是很不幸,你的团队除了你之外只剩一个人了,还是个什么都不懂的傻小子,最重要的造假任务当然不能交给他,于是你就让他假装警察来鉴别你的钱是不是假的。你要把造好的钱都先交给他检查,确定是真的才能用,假的就不能用。
你负责制造,所以你是生成器,而他负责鉴定真假钱,所以他是辨别器。
你们两个的大脑都是由深度神经网络来组成的。
好的,现在开始你们的邪恶之路。
在最开始的时候,你是很盲目的,要造一张假钱,可是完全不知道怎么造嘛,所以只能乱来,所以你任性地撕了一张纸,在上面写了100,就像这样。

然后把它交给对方,注意我们前面说过了,他啥也不懂,你是新手的同时对方也很烂啊,他完全不知道该怎么辨别,鉴定结果也无法出来
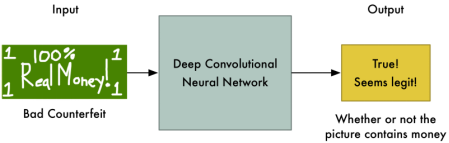
这样可不行,全乱套了,这时你们觉得,他应该去看看真的钱长啥样啊,小警察马上看了一眼真的钱,哎?不对啊,真的钱上面应该有个人头像,你这没有,肯定是假的。
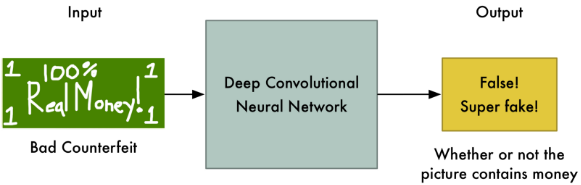
很不幸,你的假币立马被识破了,但是有收获!因为你知道,原来小警察判别的依据就是人头像啊,那我画一个上去不就得了。于是你又马上造了一张新的假币。
再去交给他来看。
他一看,“嚯!有人头像了,好像是真的哎,但是不行,我得再对比一下。”于是他又拿出自己的真钱来看,“不对不对,钱上面有印花,你这没有,肯定是假的。”
可怜的假币再一次被驳回了,于是你只好回去再修改,再交给他看,再被驳回,再修改,再拿给他看........
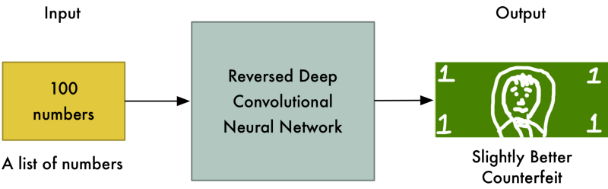
就这么日复一日的改下去,虽然过程很坚信,你一直没有被认可,但是!你在这段过程中学习到了很多,你从一开始完全不知道怎么造造币到现在掌握了一张假币应该有的所有特征。
同样的,你的搭档从一个什么都不懂的小屁孩一次次的进步,变成一个非常老练的人形验钞机。日子一天天过去,你们之间的博弈从未停止,突然有一天,你造出了已经满足所有条件的假币了!!
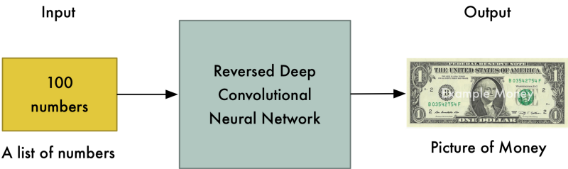
而这时,就算已经是经验丰富的他也看不出它到底是不是假的了。
因为他已经无法辨别了,所以你的钱完全可以拿出来瞒天过海了!
终于,你成为了一个优秀的生成器,而他也变成一个优秀的鉴别器。
你们变成一个优秀的造假团队!
好了,以上就是GAN的工作原理。
在上述栗子中我们可以看到,整个生成式对抗网络分为两个部分,生成器Generator(简称G)和辨别器Discriminator(简称D),其中G负责造假,D负责鉴别。
最朴素的框架如下图所示:
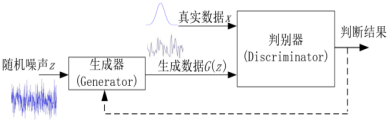
生成器接收一组随机噪声开始伪造数据,将生成地数据交给辨别器,它为了更好的判别结果,同时还会接收真实数据用来比较,如果判断结果通过了表示伪造可用,如果没有通过则说明造假技术还有待提高,需要修改。
为了让整个系统工作的更好,必须得G和D同时工作的很好,但G和D的目的又是对抗的,G想造假,就得让自己造的数据和真实数据在D那里分不出来,也就是说差距尽量小;同时D的目的是能判别出来,就是说差距尽量大。
随机噪声z,输入生成器G中,产生的生成数据是G(z),再将它输入判别器,判别的结果是D(G(z)) , 真实数据输入为x,它的判别结果是D(x)。
因此二者的判别结果之间的差距就是
D(x) - D(G(z))
这个是系统优化的依据,因为G想要这个距离越小越好,因此目标函数是
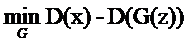
但是D想要这个距离越大越好,它的目标函数就是
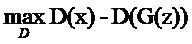
作为整个系统来看,G和D的目标都要满足啊。所以直接合并在一起
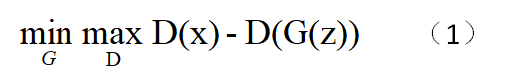
这就是GAN的目标函数啦。
但是可能会有已经看过论文的小伙伴们会说,乱讲!!论文里不是这样写的啊,那个公式可复杂了呢,如下:
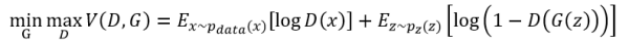
记为公式(2)
哎哟看到这个公式我头都大了,不过不要怕不要怕,我来解释下,为什么论文里的公式会变成这样,其实呢,它是我们上面推到出来的那个简单公式的变形,可以观察看一下,公式(2)对于(1)来说有什么不同,可以发现三点改动
1、加入了求对数,原来直接的D(X)变成了logD(X),这里数算子的变换可以缓解数据分布偏差问题,比如减少数据分布的单边效应的影响,减少数据分布形式上的波动等,程序实现中,对数算子也可以避免许多数值问题。
2、加入求期望E x~pdata(x),这是希望生成数据的分布Pg(G(z))能够与真实数据的分布Pdata(x)一致,换句话说,相当于在数据量无限的条件下,通过拟合G(z)得到的分布与通过拟合x得到的分布尽量一致,这一点不同于要求各个G(z)本身和各个真实数据x本身相同,这样才能保证G产生出的数据既与真实数据有一定相似性,同时又不同于真实数据;
3、-D(G(z))变成了1-D(G(z)):直观上来说,加了对数操作以后,要求logf的f必须是正数,所以不能直接用-D(G(z)),这一点并不影响最终的最优解。
对于初学的小朋友们,我还是觉得你们我上面写的公式(1)理解了就好,毕竟本质性的东西都在里面了,而且看起来也简单顺眼了嘛。
以上,公式推导完成了。
那啥...感觉最重要的理论基础原理已经就算讲完了吧 = =
里面的细节,G和D的内部网络架构,具体优化什么的,下次再说吧...
对了,我们最后来看看它的运用方面吧。
话说现在GAN真的超级火哎!!!简直是神经网络界的新生代大明星,之前在网上看到有人说无监督学习在未来几年一定会快速发展,并且超过有监督学习,而GAN,正是无监督学习的典型代表,它的应用也都很让人不明觉厉。

就像上图显示的,它可以对图像进行语义标注;可以实现一张图的白天到夜晚的转变;任意画一副边缘图自动转为实物图;等等等等.......
先到这里吧~~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号