SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
本文介绍了一种用于基于神经的文本处理(包括神经机器翻译)的与语言相关的子词标记器(tokenizer)和去标记器(detokenizer)。它为子字单元提供了开源C++和Python实现。虽然现有的子词分割工具假设输入被预先标记为单词序列,但SentencePiece可以直接从原始句子中训练子词模型,这使我们能够建立一个完全端到端且独立于语言的系统。我们在英日机器翻译中进行了NMT的验证实验,发现它可以实现与从原始句子中直接训练子词相当的准确性。我们还比较了不同配置的子词训练和分割的性能。SentencePiece在Apache 2许可证下提供,网址为https://github.com/google/sentencepiece。
1 Introduction
深度神经网络对自然语言处理产生了巨大的影响。神经机器翻译(NMT)(Bahdanau et al., 2014; Luong et al., 2015; Wu et al., 2016; Vaswani et al., 2017)尤其越来越受欢迎,因为它可以利用神经网络以简单的端到端架构直接执行翻译。NMT在几个共享任务中表现出了显著的效果(Denkowski and Neubig, 2017; Nakazawa et al., 2017),其有效方法对其他相关的NLP任务产生了强烈的影响,如对话框生成(Vinyals and Le, 2015)和自动摘要(Rush et al., 2015)。
尽管NMT可以潜在地执行端到端翻译,但许多NMT系统仍然依赖于依赖于语言的前处理器和后处理器,这些处理器已在传统的统计机器翻译(SMT)系统中使用。Moses1是SMT的一个事实上的标准工具包,它实现了一个相当有用的前处理器和后处理器。然而,它是建立在手工制作的和依赖于语言的规则之上的,这些规则对NMT的有效性尚未得到证明。此外,这些工具主要是为欧洲语言设计的,在欧洲语言中,单词用空格进行分割。要为中文、韩语和日语等非分段语言训练NMT系统,我们需要独立运行分词器。这种依赖于语言的处理也使得训练多语言NMT模型变得困难(Johnson et al., 2016),因为我们必须仔细管理每种语言的前处理器和后处理器的配置,而内部深度神经架构是独立于语言的。
随着NMT方法的标准化和向更不与语言相关的架构发展,NLP社区开发一种简单、高效、可复制且与语言无关的前处理器和后处理器变得越来越重要,该处理器可以很容易地集成到基于神经网络的NLP系统中,包括NMT。
在这篇演示论文中,我们描述了SentencePiece,这是一种简单且与语言无关的文本标记器和去标记器,主要用于基于神经网络的文本生成系统,其中在神经模型训练之前预先确定词汇的大小。SentencePiece实现了两种子词分割算法,即字节对编码(BPE)(Sennrich et al., 2016)和单格语言模型(Kudo, 2018),并扩展了原始句子的直接训练。SentencePiece能够构建一个完全端到端的系统,不依赖于任何特定语言的处理。
1 http://www.statmt.org/moses/

2 System Overview
SentencePiece包括四个主要组件:归一化器、训练器、编码器和解码器。归一化器是一个模块,用于将语义相等的Unicode字符归一化为规范形式。训练器从标准化语料库中训练子词分割模型。我们指定一种类型的子词模型作为训练器的参数。编码器在内部执行归一化器来归一化输入文本,并使用训练器训练的子单词模型将其标记为子单词序列。解码器将子单词序列转换为标准文本。
编码器和解码器的作用分别对应于预处理(标记化)和后处理(去标记化)。然而,我们称之为编码和解码,因为SentencePiece管理词汇表到id的映射,并可以直接将文本转换为id序列,反之亦然。直接编码和解码到id序列/从id序列解码对于大多数NMT系统是有用的,因为它们的输入和输出是id序列。
图1给出了SentencePiece训练(spm_train)、编码(spm_encode)和解码(spm_decode)的端到端示例。我们可以看到,输入文本通过spm_encode和spm_decode进行可逆转换。
3 Library Design
本节通过命令行和代码片段描述了SentencePiece的设计和实现细节。
3.1 Lossless Tokenization
以下原始和标记化的句子是依赖于语言的预处理的一个例子。
- 原文:Hello world.
- 标记化:[Hello] [world] [.]
一个观察结果是,原始文本和标记化序列是不可逆转换的。"world"和"."之间不存在空格的信息不保存在标记化序列中。由于这些不可逆的操作,去标记化是从标记化序列中恢复原始输入的过程,必须依赖于语言。例如,虽然在大多数欧洲语言中,去标记器通常在原始标记之间放置空格,但在日语和汉语中不需要空格。
- 原文:[こんにちは世界。] (Hello world.)
- 标记化:[こんにちは] [世界] [。]
这种特定于语言的处理通常是在手工编制的规则中实现的,这些规则的编写和维护成本很高。
SentencePiece将解码器实现为编码器的反向操作,即
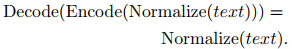
我们称这种设计为无损标记化,其中用于再现归一化文本的所有信息都保留在编码器的输出中。无损标记化的基本思想是将输入文本视为Unicode字符序列。甚至空白也被当作一个正常的符号来处理。为了清楚起见,SentencePiece首先用元符号_(U+2581)转义空白,并将输入标记为任意子单词序列,例如:
- 原文:Hello_world.
- 标记化:[Hello] [_wor] [ld] [.]
由于标记文本中保留了空白,我们可以使用以下Python代码去标记,而不会有任何歧义。
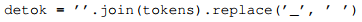
应当注意的是,subword-nmt2对于子字单元采用不同的表征。它专注于如何将单词分割成子单词,并使用@@作为单词内边界标记。
- 标记化:[Hello] [wor] [@@ld] [@@.]
这种表征不能总是执行无损标记化,因为在处理空白空间时仍然存在歧义。更具体地说,不可能用这种表征对连续的空白空间进行编码。
2 https://github.com/rsennrich/subword-nmt
3.2 Efficient subword training and segmentation
3.3 Vocabulary id management
3.4 Customizable character normalization
3.5 Self-contained models
3.6 Library API for on-the-fly processing
4 Experiments
4.1 Comparison of different preprocessing
4.2 Segmentation performance
5 Conclusions


 浙公网安备 33010602011771号
浙公网安备 33010602011771号