NROWAN-DQN: A Stable Noisy Network with Noise Reduction and Online Weight Adjustment for Exploration
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Expert Syst. Appl. 203: 117343 (2022)
Abstract
深度强化学习在当今应用越来越广泛,尤其是在各种复杂的控制任务中。噪声网络的有效探索是深度强化学习中最重要的问题之一。噪声网络往往会为智能体产生稳定的输出。然而,这种趋势并不总是足以为智能体建立稳定的策略,这会降低学习过程中的效率和稳定性。本文在NoisyNets的基础上,提出了一种称为NROWAN-DQN的算法,即降噪和在线权值调整NoisyNet-DQN。首先,我们为NoisyNet-DQN开发了一种新的降噪方法,使代理执行稳定的动作。其次,我们设计了一种用于降噪的在线权重调整策略,该策略提高了智能体的稳定性能并获得了更高的分数。最后,我们在四个标准域中对该算法进行了评估,并分析了超参数的性质。我们的结果表明,NROWAN-DQN在所有这些领域都优于先前的算法。此外,NROWAN-DQN也显示出更好的稳定性。NROWAN-DQN评分的方差显著降低,尤其是在一些动作敏感的环境中。这意味着,在一些需要高稳定性的环境中,NROWAN-DQN将比NoisyNet-DQN更合适。
1. Introduction
2. Related Work
3. Background
3.1. Markov decision process in reinforcement learning
3.2. Deep reinforcement learning and DQN
3.3. DQN with noisy networks
4. Online noise reduction for noisy networks
本节介绍了NROWAN-DQN的两种主要机制,包括降噪和在线权重调整。
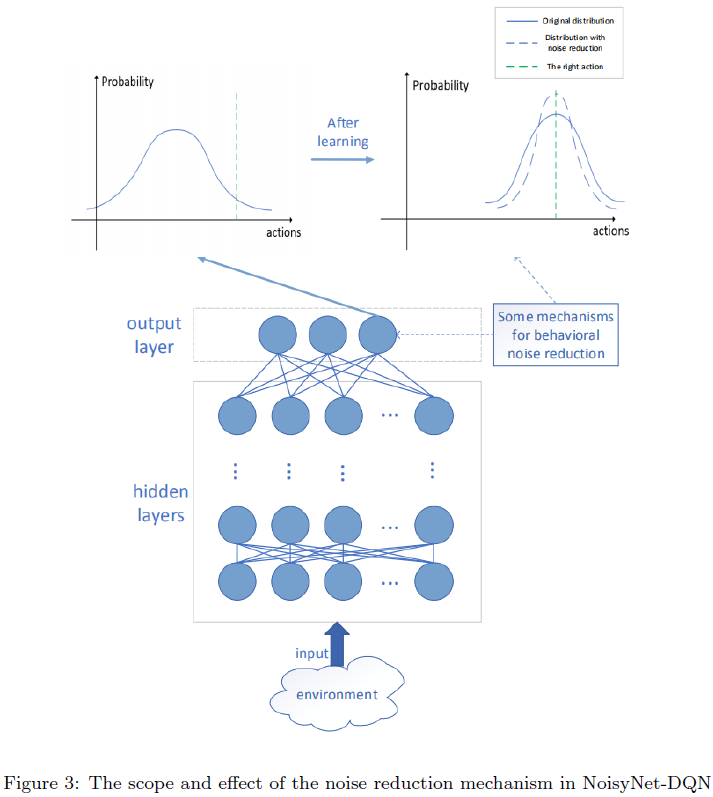
4.1. Noise reduction
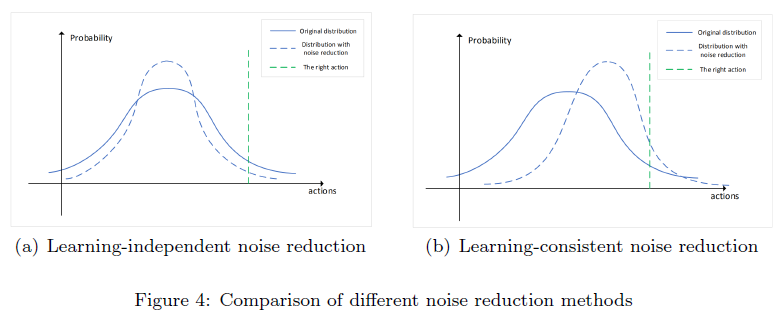
噪声网络在学习过程中的不稳定性主要受噪声方差的影响,因此可以通过降低σ来降低噪声。然而,Fortunato等人指出,在某些环境中,噪声网络隐藏层的σ可能会随着学习的进展而增加,并且在智能体形成稳定的策略后,σ会保持较大的值[25]。这表明噪声网络中较大σ的隐藏层具有正效应。由于输出层的噪声方差直接影响动作噪声,我们通过控制输出层而不是所有层的噪声来限制Q网络的整体噪声水平。降噪机制的范围和效果如图3所示。最后一层中每个神经元的输出概率是正态分布(蓝线)。此时,该神经元输出正确动作的概率(绿色虚线)很小。经过充分的学习,神经元输出的分布均值应该与正确的动作一致。也就是说,神经元在充分学习后应该能够以更高的概率选择正确的值。根据降噪机制,神经元学习的分布(蓝色虚线)应该具有较小的方差。因此,这些神经元选择正确动作的概率更大。
噪声衰减的一般方案是在学习过程中逐渐减少输出层的σ。然而,在噪声网络中,输出层的σ是沿着梯度方向更新的参数。因此,独立地减小其值可能导致该参数不在梯度方向上更新。这可能导致学习效率低下,甚至阻止智能体学习有效的策略。因此,我们需要一种与学习过程相一致的降噪机制。
我们的想法是以可微的形式表示噪声水平。我们使用D来表示NoisyNet输出的稳定性:
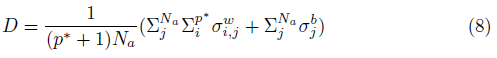
其中p*是最后一层的输入维度,Na是输出动作的数量。D影响智能体的输出动作的噪声水平。值得注意的是,D对σ可微分。降噪的核心思想是适当地降低噪声水平,使智能体具有更好的性能,因此我们可以将噪声水平与TD误差相结合,形成一个新的损失函数。
然后,我们使用原始损失函数和D的和作为新的损失函数。
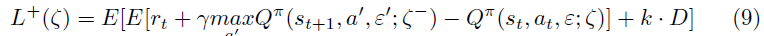
其中k是某个比例系数。k用于控制TD误差梯度方向和衰减方向上的更新比例。我们将在下一节中介绍控制这种比例系数的调整策略。根据(9),我们可以进一步获得我们算法中参数的更新方向。
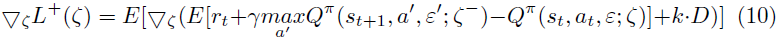
我们在Q网络的损失函数中加入了降噪机制,使降噪过程与学习过程一致。图4(a)显示了与学习相关的降噪过程的动作分布的可预测性。由于降噪过程不会与学习同时发生,因此单独减少输出方差将降低智能体此时选择正确动作的概率。我们的方法不能独立地减少方差。根据公式(10)的NROWAN-DQN的更新过程也抑制了噪声。因此,NROWAN-DQN的降噪过程与学习过程更加一致。在图4(b)中,在减少智能体输出分布方差的同时,总体分布也更接近于正确动作的方向。
4.2. Online weight adjustment
有两种方法可以增加权重k。第一种方法是随着训练帧的数量单调增加k。作为训练帧数增加,k逐渐地变换到某个值。
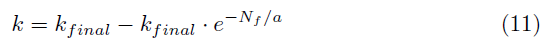
其中,kfinal表示k的最终期望值,Nf表示帧数,a表示控制k的增长率的因子。根据公式(11),当Nf非常小时,k接近0。在这种情况下,智能体倾向于完全探索,ζ的更新方向是TD误差梯度方向。相反,当Nf非常大时,k接近于kfinal。此时,智能体倾向于形成稳定策略。内层的μ和∑仍然沿着TD误差梯度方向更新,最后一层的∑沿着TD误差和D矢量的和梯度方向更新。
增加权重k的第二种方法是根据奖励在线调整:
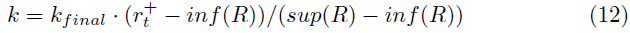
其中,![]() 分别表示当前奖励,sup(R)表示最大奖励,inf(R)表示最小奖励。在学习的早期阶段,智能体通常无法获得高奖励。
分别表示当前奖励,sup(R)表示最大奖励,inf(R)表示最小奖励。在学习的早期阶段,智能体通常无法获得高奖励。![]() 通常接近inf(R),因此k接近0。此时,在TD误差梯度方向上更新参数。当学习达到某一阶段时,内层的μ和∑在TD误差梯度方向上更新,而最后一层的∑在TD误差斜率方向和
通常接近inf(R),因此k接近0。此时,在TD误差梯度方向上更新参数。当学习达到某一阶段时,内层的μ和∑在TD误差梯度方向上更新,而最后一层的∑在TD误差斜率方向和![]() 方向上交替更新。这是因为在每一轮游戏开始时,r接近inf(R),k接近0,并且在TD误差梯度方向上更新∑。随着一轮游戏的进行,当前奖励
方向上交替更新。这是因为在每一轮游戏开始时,r接近inf(R),k接近0,并且在TD误差梯度方向上更新∑。随着一轮游戏的进行,当前奖励![]() 增加,权重k越来越接近kfinal,最后一层的∑向
增加,权重k越来越接近kfinal,最后一层的∑向![]() 方向更新。本轮游戏结束后,下一轮比赛开始。此时,
方向更新。本轮游戏结束后,下一轮比赛开始。此时,![]() 再次变为一个小值,并开始一个新的循环。我们的实验表明,使用这种更新方法进行训练可以产生更稳定的策略。
再次变为一个小值,并开始一个新的循环。我们的实验表明,使用这种更新方法进行训练可以产生更稳定的策略。
inf(R)和sup(R)的选择不需要太严格。在一些虚拟环境中,可以很容易地获得inf(R)和sup(R)。当环境奖励不明确时,inf(R)可以被设置为随机初始化的策略可以实现的奖励,sup(R)可以被设定为当前算法在该环境中可以实现的最高奖励。值得注意的是,inf(R)和sup(R)越接近,越需要仔细地调整参数kfinal。在实验部分,我们只会通过在线权重调整来衰减噪声。
算法1描述了NROWAN-DQN的训练过程。该算法遵循NoisyNet-DQN算法[25]的原始框架。在算法1中,由于k是基于奖励在线调整的,因此需要额外的输入kfinal。获得一定范围的环境奖励也是必要的。当计算第10行中的当前奖励时,还根据公式(12)计算k。在第15行中,计算参数的更新方向。在第16行中,根据更新方向和学习率来更新参数。

5. Experiments
5.1. Environments
5.2. Hyper-parameters
5.3. Score comparison
5.4. Score change in learning
5.5. Final k value and learning rate
6. Discussion and conclusion


 浙公网安备 33010602011771号
浙公网安备 33010602011771号