Spikformer: When Spiking Neural Network Meets Transformer
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published as a conference paper at ICLR 2023(同大组工作)
ABSTRACT
我们考虑了两种生物学合理的结构,脉冲神经网络(SNN)和自注意机制。前者为深度学习提供了一种节能且事件驱动的范式,而后者则能够捕获特征依赖性,使Transformer能够获得良好的性能。凭直觉,探索他们之间的结合是有希望的。在本文中,我们考虑利用SNN的自注意能力和生物学特性,提出了一种新的脉冲自注意力(Spiking Self Attention, SSA)以及一个强大的框架,称为Spiking Transformer(Spikformer)。Spikformer中的SSA机制通过使用不带softmax的脉冲形式Query、Key和Value来对稀疏视觉特征进行建模。由于SSA的计算是稀疏的并且避免了乘法运算,因此SSA是高效的并且具有低的计算能耗。研究表明,在神经形态和静态数据集上,具有SSA的Spikformer在图像分类方面可以优于最先进的类SNN框架。Spikformer(66.3M参数)的大小与SEW-ResNet-152(60.2M,69.26%)相当,使用4个时间步骤,可以在ImageNet上实现74.81%的top1精度,这是直接训练的SNN模型中最先进的。Spikformer提供代码。
1 INTRODUCTION
作为第三代神经网络(Maass,1997),脉冲神经网络(SNN)以其低功耗、事件驱动特性和生物合理性而极具前景(Roy et al.,2019)。随着人工神经网络(ANN)的发展,SNN能够通过借鉴ANN的先进架构来提高性能,如类ResNet SNN(Hu et al.,2021a;Fang et al.,2021;Zheng et al.,2021;Hu et al,2021b)、脉冲循环神经网络(Lotfi Rezaabad & Vishwanath,2020)和脉冲图神经网络(Zhu et al.,2022)。Transformer最初是为自然语言处理而设计的(Vaswani et al.,2017),在计算机视觉的各种任务中蓬勃发展,包括图像分类(Dosovitskiy et al.,2020;Yuan et al.,2021a)、目标检测(Carion et al.,2020;Zhu et al.,2020;Liu et al.,2021),语义分割(Wang et al.,2021;Yuan et al.,2021b)和底层图像处理(Chen et al.,2020)。自注意是Transformer的关键部分,选择性地关注感兴趣的信息,也是人类生物系统的一个重要特征(Whittington et al.,2022;Cauchette & King,2022)。直观地说,考虑到这两种机制的生物学特性,探索在SNN中应用自注意进行更高级的深度学习是很有趣的。
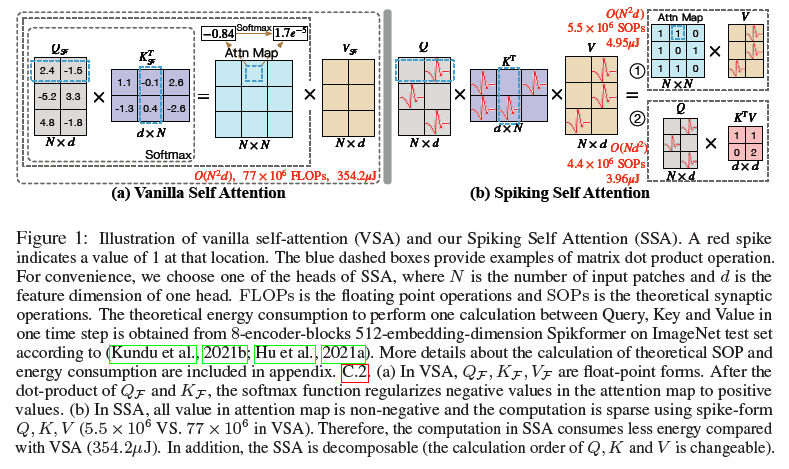
然而,将自注意机制移植到SNN中并非易事。在朴素自注意(VSA)(Vaswani et al.,2017)中,有三个组成部分:查询(Query)、键(Key)和值(Value)。如图1(a)所示,VSA的标准推理首先是通过计算浮点数形式Query和Key的点积来获得矩阵;然后采用包含指数计算和除法运算的softmax对矩阵进行归一化,以给出用于加权值的注意力图。VSA中的上述步骤不符合SNN的计算特性,即避免乘法。此外,VSA繁重的计算开销几乎禁止将其直接应用于SNN。因此,为了在SNN上开发Transformer,我们需要设计一种新的有效且计算高效的自注意变体,它可以避免乘法运算。
因此,我们提出了Spiking Self Attention(SSA),如图1(b)所示。SSA首次将自注意机制引入到SNN中,该机制使用脉冲序列对相互依赖性进行建模。在SSA中,Query、Key和Value是脉冲形式,只包含0和1。自注意在SNN中应用的障碍主要是由softmax引起的。1)如图1所示,根据脉冲形式Query和Key计算的注意力图具有自然的非负性,忽略了不相关的特征。因此,我们不需要softmax来保持注意力矩阵的非负性,这是它在VSA中最重要的作用(Qin et al.,2022)。2)SSA的输入和值是脉冲形式,其仅由0和1组成,并且与ANN中VSA的浮点输入和值相比,包含较少的细粒度特征。因此,浮点查询和键以及softmax函数对于建模这样的脉冲序列是多余的。表1说明了我们的SSA在处理脉冲序列的效果方面与VSA具有竞争力。基于以上见解,我们放弃了SSA中注意力图的softmax归一化。一些以前的Transformer变体也放弃softmax或用线性函数代替它。例如,在Performer(Choromanski et al.,2020)中,采用正随机特征来近似softmax;CosFormer(Qin et al.,2022)用ReLU和余弦函数代替softmax。
在SSA的这种设计中,脉冲形式的Query、Key和Value的计算避免了乘法运算,并且可以通过逻辑AND运算和加法来完成。此外,它的计算非常有效。由于稀疏的脉冲形式Query,Key和Value(如附录D.1所示)和简单的计算,SSA中的操作次数较少,这使得SSA的能耗非常低。此外,我们的SSA在softmax被弃用后是可分解的,这进一步降低了当序列长度大于一个头的特征维度时的计算复杂度,如图1(b)①②所示。
基于所提出的SSA,它很好地适应了SNN的计算特性,我们开发了Spikformer。Spikformer的概述如图2所示。它提高了在静态数据集和神经形态数据集上训练的性能。据我们所知,这是第一次探索SNN中的自注意机制和直接训练的Transformer。总之,我们的工作有三个方面的贡献:
- 针对SNN的性质,我们设计了一种新的脉冲形式的自注意,称为脉冲自注意(SSA)。使用稀疏脉冲形式的Query、Key和Value而不使用softmax,SSA的计算避免了乘法运算,并且是有效的。
- 我们在提出的SSA的基础上开发了Spikformer。据我们所知,这是第一次在SNN中实现自注意和Transformer。
- 大量实验表明,所提出的结构在静态和神经形态数据集上都优于最先进的SNN。值得注意的是,我们首次使用直接训练的SNN模型,在ImageNet上以4个时间步骤实现了74%以上的准确率。
2 RELATED WORK
Vision Transformers. 对于图像分类任务,标准视觉Transformer(ViT)包括补丁分割模块、Transformer编码器层和线性分类头。Transformer编码器层由一个自关注层和一个多感知层块组成。自注意力是ViT成功的核心因素。通过查询与键的点积和softmax函数对图像补丁特征值进行加权,自注意力可以捕捉全局依赖性和兴趣表征(Katharopoulos et al.,2020;Qin et al.,2022)。已经开展了一些工作来改进ViT的结构。使用卷积层进行补丁分割已被证明能够加速收敛并缓解ViT的数据饥饿问题(Xiao et al.,2021b;Hassani et al.,2021)。有一些方法旨在降低自注意力的计算复杂性或提高其对视觉依赖性建模的能力(Song,2021;Yang et al.,2021;Rao et al.,2021;Choromanski et al.,2020)。本文重点探讨了自注意力在SNN中的有效性,并开发了一个用于图像分类的强大脉冲Transformer模型。
Spiking Neural Networks. 与使用连续十进制值传递信息的传统深度学习模型不同,SNN使用离散脉冲序列来计算和传输信息。脉冲神经元接收连续值并将其转换为脉冲序列,包括Leaky Integration-and-Fire(LIF)神经元(Wu et al.,2018)、PLIF(Fang et al.,2021b)等。有两种方法可以获得深度SNN模型:ANN到SNN的转换和直接训练。在ANN到SNN的转换中(Cao et al.,2015;Hunsberger & Eliasmith,2015;Rueckauer et al.,2017;Bu et al.,2021;Meng et al.,2022;Wang et al.,2022),通过用脉冲神经元取代ReLU激活层,将高性能预训练的ANN转换为SNN。转换后的SNN需要大的时间步长来准确近似ReLU激活,这会导致大的延迟(Han et al.,2020)。在直接训练领域,SNN在模拟时间步长上展开,并以时间反向传播的方式进行训练(Lee et al.,2016;Shrestha & Orchard,2018)。由于脉冲神经元中的事件触发机制是不可微分的,因此使用替代梯度进行反向传播(Lee et al.,2020;Neftci et al.,2019)。Xiao等人(2021a)在平衡状态上采用隐式微分来训练SNN。来自ANN的各种模型已经移植到SNN。然而,关于SNN的自注意力研究目前还处于空白状态。Yao等人(2021)提出了时间注意以减少冗余时间步长。Zhang等人(2022a;b)都使用ANN-Transformer来处理脉冲数据,尽管他们在标题中有“脉冲Transformer”。Mueller等人(2021)提供了一种ANN-SNN转换Transformer,但仍然是朴素的自关注力,不符合SNN的特性。在本文中,我们将探索在SNN中实现自注意力和Transformer的可行性。
作为SNN的基本单元,脉冲神经元接收产生的电流并积累膜电位,膜电位用于与阈值进行比较以确定是否产生脉冲。我们在工作中统一使用LIF脉冲神经元。LIF的动态模型描述为:
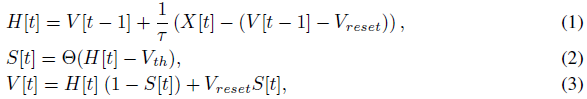
其中 τ 是膜时间常数,X[t]是时间步骤 t 的输入电流。当膜电位H[t]超过发放阈值Vth时,脉冲神经元将触发脉冲S[t]。Θ(v)是Heaviside阶跃函数,当v≥0时等于1,否则为0。V[t]表示触发事件之后的膜电压,如果没有产生脉冲,则等于H[t],否则等于重置电压Vreset。
3 METHOD
我们提出了Spiking Transformer(Spikformer),它将自注意力机制和Transformer结合到脉冲神经网络(SNN)中,以增强学习能力。现在我们逐一解释Spikformer的概述和组件。
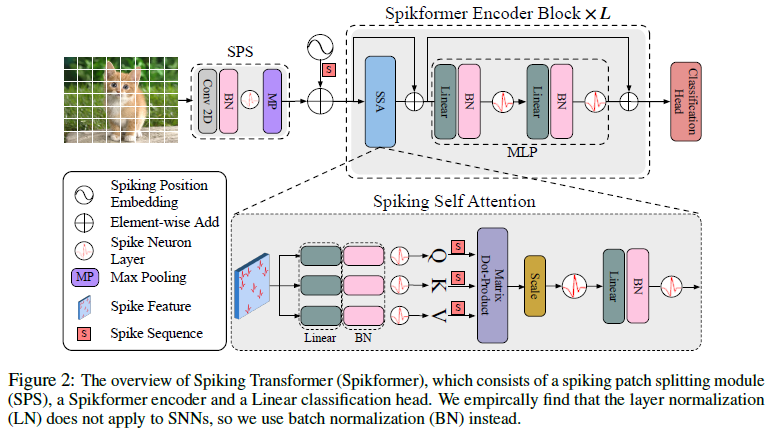
3.1 OVERALL ARCHITECTURE
Spikformer的概述如图2所示。给定2D图像序列I ∈ RT×C×H×W 1,Spiking Patch Spliting(SPS)模块将其线性投影到D维脉冲形状特征向量,并将其分割为N个平坦的脉冲形状补丁的序列x。浮点形式的位置嵌入不能用于SNN。我们使用条件位置嵌入生成器(Chu et al.,2021)来生成脉冲形式的相对位置嵌入(RPE),并将RPE添加到补丁序列x以获得X0。条件位置嵌入生成器包含核大小为3的2D卷积层(Conv2d)、批处理归一化(BN)和脉冲神经元层(SN)。然后我们将X0传递给L块Spikformer编码器。类似于标准ViT编码器块,Spikformer编码器块由Spiking Self Attention(SSA)和MLP块组成。SSA和MLP区块均采用残差连接。作为Spikformer编码器块中的主要组件,SSA提供了一种有效的方法,使用脉冲形式的Query(Q)、Key(K)和Value(V)对图像的局部全局信息进行建模,而不使用softmax,这将在第3.3节中进行详细分析。全局平均池化(GAP)用于Spikformer编码器的处理后的特征,并输出将被发送到全连接层分类头(CH)以输出预测Y的D维特征。Spikformer可以写如下:
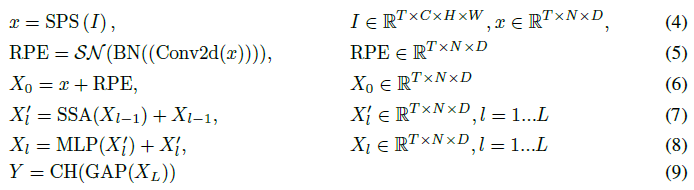
1 在神经形态数据集中,数据形状为I ∈ RT×C×H×W,其中T、C、H和W分别表示时间步长、通道、高度和宽度。静态数据集中的2D图像Is ∈ RC×H×W需要重复T次才能形成图像序列。
3.2 SPIKING PATCH SPLITTING
如图2所示,脉冲贴片分割(SPS)模块旨在将图像线性投影到D维脉冲形状特征,并将该特征分割为具有固定大小的贴片。SPS可以包含多个块。类似于Vision Transformer(Xiao et al.,2021b;Hassani et al.,2021)中的卷积主干,我们在每个SPS块中应用卷积层,以将归纳偏置引入Spikformer。具体地,给定图像序列I ∈ RT×C×H×W:
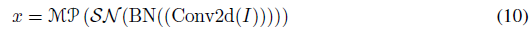
其中Conv2d和MP分别表示2D卷积层(步长1,3×3核大小)和最大池化。SPS块的数量可以超过1个。当使用多个SPS块时,这些卷积层中的输出通道的数量逐渐增加,并最终匹配补丁的嵌入维度。例如,给定输出嵌入维度D和四块SPS模块,四个卷积层中的输出信道数量为D/8、D/4、D/2、D。而2D最大池化层被应用于对具有固定大小的SPS块之后的特征大小进行下采样。经过SPS处理后,将I分解为图像块序列x ∈ RT×N×D。
3.3 SPIKING SELF ATTENTION MECHANISM
Spikformer编码器是整个结构的主要组成部分,它包含了Spiking Self Attention(SSA)机制和MLP块。在本节中,我们将重点介绍SSA,首先回顾一下朴素自注意力(VSA)。给定输入特征序列X ∈ RT×N×D,ViT中的VSA有三个浮点关键分量,即查询(QF)、密钥(KF)和值(VF),它们由可学习线性矩阵WQ、WK、WV ∈ RD×D和X计算:
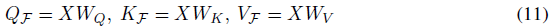
其中F表示浮点形式。朴素自注意力的输出可以计算为:
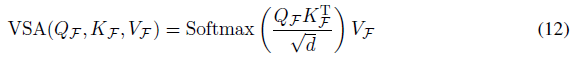
其中d = D/H是一个头的特征尺寸,H是头编号。将浮点形式的值(VF)转换为脉冲形式(V)可以实现VSA在SNN中的直接应用,可以表示为:
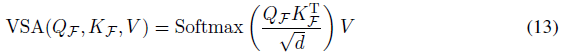
然而,由于两个原因,VSA的计算不适用于SNN。1) QF、KF和softmax函数的浮点矩阵乘法包含指数计算和除法运算,不符合SNN的计算规则。2) VSA序列长度的二次空间和时间复杂度不能满足SNN的高效计算要求。
我们提出了Spiking Self Attention(SSA),它比VSA更适合SNN,如图1(b)和图2底部所示。首先通过可学习矩阵计算查询(Q)、密钥(K)和值(V)。然后,它们通过不同的脉冲神经元层成为脉冲序列:
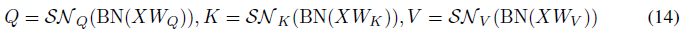
其中Q,K,V ∈ RT×N×D。我们认为注意力矩阵的计算过程应该使用纯脉冲形式的Query和Key(只包含0和1)。受朴素自注意力的启发(Vaswani et al.,2017),我们添加了一个缩放因子s来控制矩阵乘法结果的大值。s不影响SSA的属性。如图2所示,脉冲友好SSA定义为:
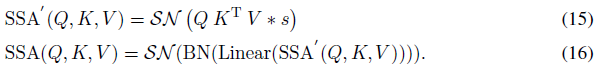
这里介绍的单头SSA可以很容易地扩展到多头SSA,详见附录A。SSA在每个时间步骤上独立进行,详见附录B。如公式(15)所示,SSA取消了使用softmax来规范公式(12)中的注意力矩阵,并直接乘以Q、K和V。直观的计算示例如图1(b)所示。softmax在我们的SSA中是不必要的,它甚至阻碍了对SNN的自注意力的实现。形式上,基于公式(14),脉冲神经元层SNQ和SNk分别输出的脉冲序列Q和K自然是非负的(0或1),从而产生非负的注意力图。SSA只聚合了这些相关的特征,而忽略了不相关的信息。因此,它不需要softmax来确保注意力图的非负性。此外,与神经网络中的浮点数形式XF和VF相比,神经网络中自注意力的输入X和值V是脉冲形式,包含的信息有限。具有浮点形式QF、KF和softmax的朴素自注意力(VSA)对于脉冲形式X、V的建模是多余的,其不能从X、V获得比SSA更多的信息。也就是说,SSA比VSA更适合SNN。
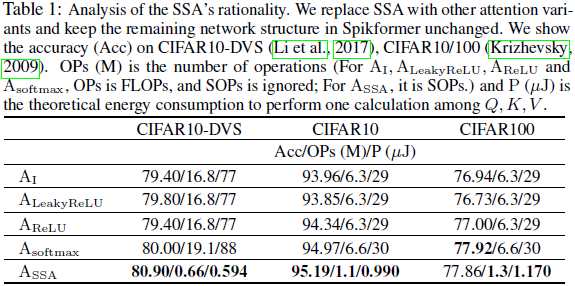
我们通过将所提出的SSA与注意力图的四种不同计算方法进行比较来验证上述见解,如表1所示。AI表示将浮点Q和K直接相乘以获得注意力图,该注意力图保持正相关和负相关。AReLU使用ReLU(Q)和ReLU(K)之间的乘积来获得注意力图。AReLU保留Q、K的正值,并将负值设置为0,而ALeakyReLU仍然保留负值。Asoftmax意味着注意力图是根据VSA生成的。以上四种方法使用相同的Spikformer框架,并对脉冲形式V进行加权。从表1中可以看出,我们的ASSA优于AI和ALeakyReLU的性能证明了SN的优越性。ASSA优于AReLU的原因可能是ASSA在自注意方面具有更好的非线性。与Asoftmax相比,ASSA具有竞争力,在CIFAR10DVS和CIFAR10上甚至超过了Asoftmax。这可以归因于SSA比VSA更适合于信息有限的脉冲序列(X和V)。此外,ASSA完成Q、K、V计算所需的运算次数和理论能耗远低于其他方法。
SSA是专门为脉冲序列建模而设计的。Q、K和V都是脉冲形式,这将矩阵点积计算降级为逻辑AND运算和求和运算。我们以一行Query q和一列Key k作为计算示例: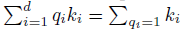 。此外,如表1所示,由于稀疏脉冲形式Q、K和V(图4)和简化的计算,SSA具有较低的计算负担和能耗。此外,Q、K和V之间的计算顺序是可变的:首先是QKT然后是V,或者首先是KTV然后是Q。当序列长度N大于一个头维度d时,上面的第二个计算顺序将比第一个计算顺序(O(N2d))产生更小的计算复杂度(O(Nd2))。SSA在整个计算过程中保持了生物学合理性和计算效率特性。
。此外,如表1所示,由于稀疏脉冲形式Q、K和V(图4)和简化的计算,SSA具有较低的计算负担和能耗。此外,Q、K和V之间的计算顺序是可变的:首先是QKT然后是V,或者首先是KTV然后是Q。当序列长度N大于一个头维度d时,上面的第二个计算顺序将比第一个计算顺序(O(N2d))产生更小的计算复杂度(O(Nd2))。SSA在整个计算过程中保持了生物学合理性和计算效率特性。
4 EXPERIMENTS
我们在静态数据集CIFAR、ImageNet(Deng et al.,2009)和神经形态数据集CIFAR10-DVS、DVS128 Gesture(Amir et al.,2017)上进行了实验,以评估Spikformer的性能。进行实验的模型是基于Pytorch(Paszke et al.,2019)、SpikingJelly2和Pytorch图像模型库(Timm)3实现的。我们从头开始训练Spikformer,并将其与第4.1节和第4.2节中的当前SNN模型进行比较。我们在第4.3节中进行了消融研究,以显示SSA模块和Spikformer的影响。
2 https://github.com/fangwei123456/spikingjelly
3 https://github.com/rwightman/pytorch-image-models
4.1 STATIC DATASETS CLASSIFICATION
ImageNet
CIFAR
4.2 NEUROMORPHIC DATASETS CLASSIFICATION
4.3 ABLATION STUDY
Time step 脉冲神经元不同模拟时间步长的准确性如表5所示。当时间步长为1时,我们的方法比CIFAR10上T=4的网络低1.87%。1个时间步长的Spikformer-8-512仍然达到70.14%。以上结果表明Spikformer在低延迟(较少的时间步长)条件下是鲁棒的。
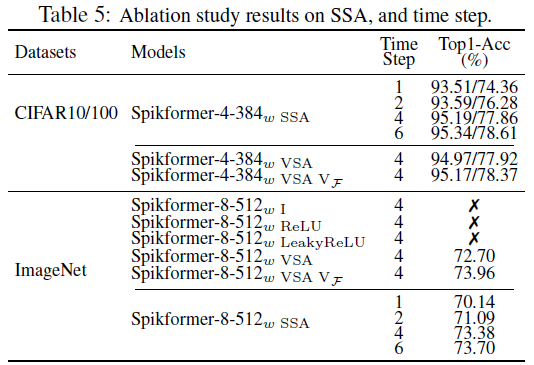
SSA 我们对SSA进行了消融研究,以进一步确定其优势。我们首先通过用标准的朴素自注意力代替SSA来测试它的效果。我们测试了Value为浮点形式(Spikformer-L-Dw VSA VF)和脉冲形式(Spikformer-L-Dw VSA)的两种情况。我们还在ImageNet上测试了不同的注意力变体,如下表1所示。在CIFAR10上,具有SSA的Spikformer的性能与Spikformer-4-384w VSA甚至Spikformer-4-384w VSA VF相比具有竞争力。在ImageNet上,我们的Spikformer-8-512w SSA比Spikformer-8-512w VSA高0.68%。Spikformer-8-512w I、Spikformer-8-512w ReLU和Spikformer-8-512w LeakyReLU不收敛的原因是Query、Key和Value的点积值较大,这使得输出脉冲神经元层的替代梯度消失。更多细节见附录D.4。相比之下,所设计的SSA的点积值在可控范围内,由稀疏脉冲形式Q、K和V决定,并使Spikformerw SSA易于收敛。
5 CONCLUSION
在这项工作中,我们探索了在脉冲神经网络中实现自注意力机制和Transformer的可行性,并提出了一种基于新的脉冲自注意力(SSA)的Spikformer。与神经网络中的朴素自注意力机制不同,SSA是专门为神经网络和脉冲数据设计的。我们放弃了SSA中softmax的复杂运算,而是直接对脉冲形式Query、Key和Value执行矩阵点积,这是高效的,避免了乘法运算。此外,这种简单的自注意力机制使Spikformer在静态和神经形态数据集上都能令人惊讶地工作。通过直接从头开始的训练,Spiking Transformer的性能优于最先进的SNN模型。我们希望我们的研究为进一步研究基于Transformer的SNN模型铺平道路。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号