Spectrum Random Masking for Generalization in Image-based Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Advances in Neural Information Processing Systems (NeurIPS), 2022
同组工作
Abstract
基于图像的强化学习(RL)中的泛化旨在学习一种可以直接应用于看不见的视觉环境的鲁棒策略,这是一项具有挑战性的任务,因为智能体通常倾向于过拟合其训练环境。为了解决这个问题,一种自然的方法是通过基于图像的增强来增加数据的多样性。然而,与分类和检测等大多数视觉任务不同,由于环境动力学和视觉外观的纠缠,RL任务并不总是对基于空间的增强保持不变。在本文中,我们讨论了RL中增强的两个原则:首先,增强的观察应该有助于学习一个通用的策略,该策略对各种分布变化都是鲁棒的。其次,增强数据应该对学习信号(如动作和奖励)保持不变。遵循这些规则,我们从频域的角度重新审视了基于图像的RL任务,并提出了一种新的增强方法,即频谱随机掩蔽(Spectrum Random Masking, SRM),它能够帮助智能体学习观察的整个频谱,以应对各种分布,并与预收集的原始观察对应的动作和奖励相兼容。在DMControl泛化基准上进行的大量实验表明,所提出的SRM具有强大的泛化潜力,达到了最先进的性能。
1 Introduction
从基于图像的观察中进行强化学习(RL)是一项从视觉信号中联合学习表征和决策的任务。尽管由于深度卷积神经网络(CNN)的发展,这种类型的RL方法已经取得了重大进展,但它们中的大多数在以前看不见的环境中性能急剧下降[24, 44, 4],尤其是在基于图像的输入中[44, 32, 4, 48, 27]。原因是经典的RL方法假设训练和测试的环境是相同的[17]。然而,在现实世界中,它们之间通常存在显著的分布差异。视觉输入的高维性加上环境分布的变化,使得RL任务的泛化更加具有挑战性[30]。
为了应对这一挑战,一种自然的方法是通过模拟训练中测试环境的多样性来减少训练和测试数据的分布差距。最近的研究表明,适当的数据扩充可以促进策略网络的泛化[41]。这些数据扩充方法大多直接在空间域中进行[19],如翻转和旋转。然而,环境的动态具有对这种基于空间的数据增强缺乏敏感性的缺点[28]。一个例子如图1所示:当对观察应用水平翻转时,相应的左右动作应该颠倒,因此收集的奖励不能反映正确的反应。
考虑到上述问题,我们的目标不是在空间域中工作,而是从频域的角度研究基于图像的RL的泛化。我们的动机源于最近的计算机视觉傅立叶分析研究[42]:不同类型的空间腐蚀会影响模型在不同频率范围内的鲁棒性。例如,诸如随机高斯噪声之类的高频数据增强使模型偏向于利用输入中的低频信息,并提高了对高频腐蚀的鲁棒性。此外,基于单一空间的数据扩充很少能提高具有不同频率特性的腐败类型的模型鲁棒性。受这一现象的启发,我们推测同一RL任务的观测值的傅立叶统计在不同的环境分布中也有所不同。在图2中,我们在DeepMind Control套件[34]上可视化了原始环境的观测光谱幅度以及4个移动环境分布之间的平均delta。偏移后的环境与原始环境表现出明显的频谱差异,每个环境在不同的频率区域变化。知道深度模型通常倾向于偏向于特定的频带[39],我们假设跨环境分布的不同频谱模式是基于图像的RL泛化的关键挑战。
基于上述分析,我们通过引入频谱随机掩蔽(SRM)正则化来关注基于频率的增强,而不是基于空间的增强,如图所示。3。我们提出的SRM可以很容易地与大多数现有的RL基准兼容。为了防止模型关注输入图像上的特定频率范围,SRM在训练阶段随机丢弃观测的部分频率,并强制策略使用剩余信息选择适当的动作。通过这种方式,我们可以通过考虑整个频率分布来提高对不同腐蚀(高频、中频或低频特性)的鲁棒性。具体而言,输入观测由三个步骤操作:(1)快速傅立叶变换(FFT)、(2)频谱随机掩蔽和(3)傅立叶逆变换(IFFT),这在保持主要内容的同时增强了训练观测的多样性。
总之,本文有以下贡献:(1)我们为RL中的数据增强提供了一个新的频率视角。与以前的基于空间的方法相比,所提出的SRM在任务不可知的RL环境中是一致的,并且可以通过关注整个频率信息来处理不同的分布。(2) 所提出的SRM是一种即插即用的方法,不需要任何额外的参数或来自环境的任何额外观察。此外,它是对现有数据扩充和正则化方法的补充。(3) 我们进行了全面的实验,以证明SRM可以在各种具有高泛化潜力的基于图像的环境中带来性能提升。
2 Background

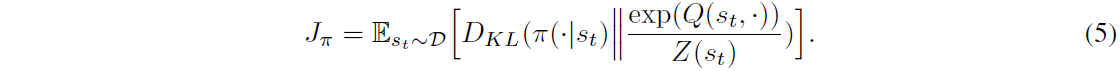
3 Methodology
3.1 Spectrum Random Masking


 浙公网安备 33010602011771号
浙公网安备 33010602011771号