SNN-RAT: Robustness-enhanced Spiking Neural Network through Regularized Adversarial Training
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

同大组工作,36th Conference on Neural Information Processing Systems (NeurIPS 2022)
Abstract
随着神经形态计算的发展,脉冲神经网络有望在实时和安全关键应用中得到广泛应用。最近的工作已经证明,由于离散的内部信息表征,SNN对小的随机扰动不敏感。与典型的神经网络相比,训练算法的多样性和时间维度的参与对SNN的鲁棒性构成了更大的威胁。我们通过基于不同的可微近似技术构建对手来说明SNN的脆弱性。通过推导专门用于脉冲表征的Lipschitz常数,我们首先从理论上回答了SNN中保留了多少对抗抵御能力的问题。因此,为了抵御广泛的攻击方法,我们提出了一种计算开销较低的正则化对抗训练方案。SNN可以受益于扰动脉冲距离的放大和多个对抗邻域上的泛化的约束。我们在图像识别基准上的实验已经证明,我们的训练方案可以抵御由强可微近似构建的强大对抗攻击。具体来说,我们的方法使投影梯度下降攻击的黑盒攻击几乎无效。我们相信,我们的工作将促进SNN在安全关键应用中的传播,并有助于了解人脑的鲁棒性。代码位于https://github.com/putshua/SNN-RAT。
1 Introduction
与传统的模拟神经网络不同,脉冲神经网络(SNN)通过时空动力学和脉冲表征来模仿生物大脑的神经元行为[Gerstner et al., 2014],这代表了神经网络的前沿[Maass, 1997; Zenke et al., 2021]。神经元随着时间的推移而进化其膜电位,并通过0(无)和1(脉冲)传递离散信息。传输后,膜电位被重置为静息值,并等待输入。由于独特的离散脉冲激活,SNN的训练算法是目前研究的热点。与ANN相比,这导致了训练方法的根本差异。神经形态计算的兴起使SNN能够以更兼容的硬件和更低的能源成本运行[Pei et al., 2019; DeBole et al., 2019; Davies et al., 2018; Nieves and Goodman, 2021; Fang et al., 2020]。SNN和神经形态硬件的结合可以实现许多应用,如时空模式识别和高速检测[Wu et al., 2018a; Xu et al., 2020; Kim et al., 2020; Kheradpisheh and Masquelier, 2020; Zenke and Neftci, 2021]。
对于自动驾驶等安全关键应用,系统的可靠性变得至关重要,尤其是模型对扰动(如加性高斯噪声)的鲁棒性。在所有扰动中,对抗攻击是最强大的类别之一[Szegedy et al., 2014; Goodfellow et al., 2015]。它可以产生人类感知系统通常忽略的细微扰动。然而,扰动会使系统的性能恶化,也就是说,模型很有可能产生不正确的标签。这可能会对那些与安全相关的应用程序产生严重影响,在这些应用程序中,一次故障可能会产生毁灭性的结果。到目前为止,已经提出了各种各样的对抗性攻击方法[Madry et al., 2018]。该漏洞甚至适用于为相同任务但使用不同结构训练的模型。
SNN的运作机制和结构与生物大脑相似,研究其对扰动的反应可以帮助我们了解人类大脑是如何工作的。SNN由于其输入编码和神经元动力学而被认为是一种具有对抗鲁棒性的新潜在候选者[Perez-Nieves et al., 2021; Leontev et al., 2021]。在SNN中常用的编码方案中,恒定输入编码被认为比其他编码更容易受到干扰,如泊松编码[Sharmin et al., 2020]。因此,Kundu等人[2021b]提出恒定输入编码需要仔细训练。在这种情况下,SNN现在面临着比典型的ANN更多的挑战。因为构建基于梯度的SNN攻击的关键是反向传播,这与ANN的反向传播相同。然而,与ANN相比,SNN可以通过各种梯度近似进行学习。因此,将各种可微近似和攻击方法相结合将对SNN构成更严重的威胁[Liang et al., 2021]。
SNN的层间通信是通过具有时间维度的脉冲进行的,这与ANN非常不同。因此,自然会提出一个问题:脉冲通信是否以及在多大程度上保持了对抗抵抗能力?而且,是否有训练工具可以帮助SNN抵御上述威胁?本文旨在将Lipschitz分析理论扩展到脉冲表征,并在此基础上提出一种更鲁棒的训练算法。我们的主要贡献总结如下:
- 我们设计并总结了不同的可微近似,可以部署在基于梯度的攻击中,以显示SNN的脆弱性。时序反向传播和发放率被发现能够构建更强的攻击。
- 我们从理论上分析了脉冲表征上的l2扰动距离,并给出了脉冲Lipschitz常数的数学表达式。
- 我们提出了一种针对SNN的正则化对抗训练方案。它不仅约束了脉冲Lipschitz常数,而且利用了已识别的强单步对抗攻击的混合。
- 实验表明,该方案可以显著提高图像识别任务中的对抗鲁棒性。与普通模型相比,训练后的模型在更强的投影梯度下降攻击下表现出更好的抵抗力。
2 Background and Related Work
2.1 Robustness of Spiking Neural Networks
脉冲表征的概念是SNN与ANN不同的地方。通常,输入被编码为序列(T × N0),其中T表示时间步骤的总数,N0表示输入节点的数量。SNN中的神经元,就像ANN一样,接收前一层输出的线性组合。泄漏-集成-发放(LIF)机制导致了SNN的非线性特性。总体而言,在时间步骤t(t=1,2,···,T),l层(l=1,2,···,L)神经元的膜电位ml(t)的动态可以描述为:
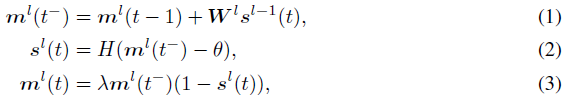
其中sl(t)表示在时间 t 的层 l 中神经元的二值脉冲,如果存在脉冲,则等于1。ml(t−)表示触发脉冲之前膜电压的瞬时状态,这累积来自最后一层突触前神经元的加权输入。当电压超过预定阈值θ时,在时间 t 产生脉冲,并且膜电流ml(t)重置为零。否则,对于LIF模型(λ∈(0, 1)),膜电位ml(t)通过λ泄漏,或者对于集成-发放(IF)模型保持不变(λ=1)。
上面描述的泄漏电压直观地平滑输入电流中的噪声,这是值得信赖的神经网络的一个吸引人的特性。事实上,SNN可以在某些条件下表现出鲁棒性。Sharmin等人[2020]介绍了他们在输入离散化和泄漏率方面的开创性工作。他们强调,特定的输入编码可以提高SNN的鲁棒性。到目前为止,泊松编码、延迟编码和首次脉冲时间编码已被证明对小型数据集有影响[Sharmin et al., 2020; Leontev et al., 2021; Nomura et al., 2022]。Sharmin等人[2019]还发现,通过替代函数训练的SNN可以提高泊松编码的鲁棒性。然而,SNN并不是完全安全的。Marchisio等人[2020]指出,黑盒攻击也可以攻击SNN。El-Allami等人[2021]搜索SNN的结构参数以提高鲁棒性。在发放率编码中,恒定输入编码(或直接编码)被证明具有较小的鲁棒性,这在几篇论文中已经进行了讨论[Kim et al., 2022; Kundu et al., 2021b]。基于仔细的观察,Kundu等人[2021b]断言精细训练对于直接编码SNN的鲁棒性至关重要。受此启发,我们提出了一种正则化子,它可以促进SNN的鲁棒训练方案。
2.2 Gradient-based Adversarial Attacks
大多数对抗攻击都考虑了围绕干净数据x的lp球中的扰动δ,并且可以公式化为优化问题:
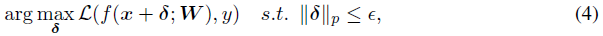
其中,y是目标,L是损失函数,f表示以W为参数的网络,而ε是保证扰动不可察觉的参数。在这里,我们介绍了两种广泛采用的基于梯度的对抗攻击算法:快速梯度符号法(FGSM)和投影梯度下降法(PGD)。
FGSM. 作为最简单的方法之一,FGSM的主要思想是沿着梯度的符号对数据进行扰动,以增加扰动的线性输出,其可以表示如下[Goodfellow et al., 2015]:
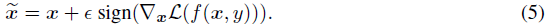
PGD. PGD是FGSM的迭代版本,它提供了更强大的攻击[Madry et al., 2018],并被认为可以合理地近似最优攻击。迭代可以概括为:
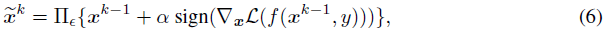
其中k表示迭代步骤的数量,α是每次迭代的步长。![]() 表示每次迭代中的数据应该投影到关于ε的干净数据周围的lp球的空间上。除了这些流行的基于梯度的攻击之外,RFGSM可以被视为FGSM的随机版本[Tramèr et al., 2018],BIM是一种类似于PGD [Kurakin et al., 2017]的迭代攻击。所有这些方法都被用来验证SNN的漏洞。通过在反向传播中应用可微近似,基于梯度的攻击也可以威胁SNN。在这项工作中,我们针对攻击者知道或不知道模型的场景执行白盒(WB)和黑盒(BB)攻击。
表示每次迭代中的数据应该投影到关于ε的干净数据周围的lp球的空间上。除了这些流行的基于梯度的攻击之外,RFGSM可以被视为FGSM的随机版本[Tramèr et al., 2018],BIM是一种类似于PGD [Kurakin et al., 2017]的迭代攻击。所有这些方法都被用来验证SNN的漏洞。通过在反向传播中应用可微近似,基于梯度的攻击也可以威胁SNN。在这项工作中,我们针对攻击者知道或不知道模型的场景执行白盒(WB)和黑盒(BB)攻击。
在没有具体说明的情况下,为了测试的目的,我们将所有方法的ε设置为8/255。对于PGD和BIM等迭代方法,攻击步长α=0.01,步长为7。
2.3 Defense Methods
早期对ANN的研究发现,对抗攻击会导致激活幅度的放大[Szegedy et al., 2014]。他们测量了清洁激活和扰动激活之间的距离,并提出了一个基于Lipschitz分析的分析框架:
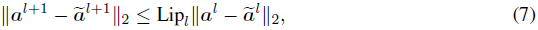
其中Lipl是层 l 的Lipschitz常数。通过惩罚Lipschiitz常数,输入的失真是稳定的[Cisse et al., 2017]。使用Lipschitz界的精确估计来证明ANN的鲁棒性已经很流行[Arjovsky et al., 2017; Fazlyab et al., 2019; Weng et al., 2018; Miyato et al., 2018]。然而,目前还没有关于SNN的Lipschitz界的工作。
除了分析框架之外,对抗训练是最强大的防御工具,它被定义为鞍点问题[Madry et al., 2018]:
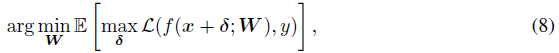
其中可以通过应用不同的攻击方法来实现最大化过程。通过利用对抗输入,对抗训练学会正确地将对抗样本进行分类。所有这些方法都是基于深度神经网络的,深度神经网络是局部可微的,并且具有定义明确的导数。在本文中,我们旨在构建一个不可微SNN的分析框架,并加强对抗训练。
3 Vulnerability of Spiking Neural Networks
3.1 Spiking Neural Network under Attack
尽管在某些情况下,SNN比ANN更鲁棒,但当应用有效的对抗攻击方法时,大多数SNN仍然很脆弱。先前的工作已经通过实验证明,梯度攻击方法(如FGSM)可以应用于SNN [Sharmin et al., 2019, 2020]。然而,由于脉冲神经元的不可微分特性,通过反向传播获得的梯度不一定准确,这可能导致低效的攻击。因此,SNN的这种防御性质可以被认为是模糊的梯度[Athalye et al., 2018],这可能会对SNN产生虚假的安全感。
因此,在本文中,我们首先通过结合攻击方法和梯度近似来重新考虑SNN的攻击。我们遵循反向传播可微近似(BPDA)技术[Athalye et al., 2018]来克服模糊的梯度。BPDA的关键思想是在反向过程中使用可微近似,而前向过程不变。类似的可微近似技术已经被用于训练SNN。在此基础上,我们设计、比较并总结了SNN的不同可微近似。
3.2 Differentiable Approximation for Spiking Neural Networks
Conversion-based Approximation. 基于转换的SNN近似(CBA)首先由Sharmin等人[2019]提出。由于SNN可以从ANN转换[Rueckauer et al., 2017; Han et al., 2020; Deng and Gu, 2021; Ding et al., 2021; Bu et al., 2022a,b],因此对抗样本可以从具有来自源SNN的共享权重和偏差的ANN生成。然而,该方法在前向传播和反向传播上使用ReLU激活函数来近似脉冲神经元,这与BPDA算法的思想相反,并且被证明是无效的[Song et al., 2018]。
Backward Pass Through Time. 最常用的可微近似是具有替代梯度的时序反向传播(BPTT)[Nefcci et al., 2019; Fang et al., 2021b]。在这种方法中,不可微的神经元发放函数被反向通路上的可微函数取代。通过组合公式1-3,反向传播可以描述为:
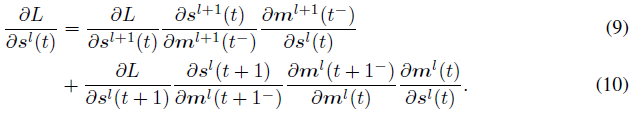
通过在层和时间步长上递归计算该公式,可以计算出最终结果![]() 。由于我们对SNN使用常数输入编码,因此图像的梯度正好是
。由于我们对SNN使用常数输入编码,因此图像的梯度正好是![]() 。用替代梯度函数代替不可微部分
。用替代梯度函数代替不可微部分![]() ,以获得平滑的反向传播。时序反向传播技术使用与时空反向传播训练算法[Wu et al., 2018b]类似的梯度近似。由于这种方法产生的梯度对训练很有用,因此很可能产生有效的梯度。
,以获得平滑的反向传播。时序反向传播技术使用与时空反向传播训练算法[Wu et al., 2018b]类似的梯度近似。由于这种方法产生的梯度对训练很有用,因此很可能产生有效的梯度。
Backward Pass Through Rate. 另一个可微近似是基于发放率的反向传播(BPTR)。在这种方法中,反向传播直接从层之间的脉冲神经元的平均发放率中获得导数。我们认为神经元在每个时间步骤是等效的,导数由平均发放率决定。
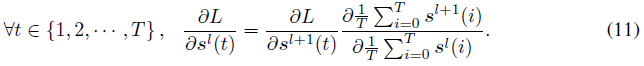
由于无泄漏IF神经元的相邻层中的发放率的关系几乎是线性的[Sengupta et al., 2019],因此可以使用直通估计器来近似![]() 的梯度[Bengio et al., 2013]。与Lee等人[2020]类似,在这里,我们使用常数1/T来近似公式11中的
的梯度[Bengio et al., 2013]。与Lee等人[2020]类似,在这里,我们使用常数1/T来近似公式11中的![]() 的值。完整神经元动态的反向传播由一个单一函数近似,并且梯度不会通过时间步骤累积。由于前向传播仍然遵循脉冲神经元的规则,因此获得的梯度将比基于转换的攻击更准确。
的值。完整神经元动态的反向传播由一个单一函数近似,并且梯度不会通过时间步骤累积。由于前向传播仍然遵循脉冲神经元的规则,因此获得的梯度将比基于转换的攻击更准确。
3.3 Effective Attack with Backward Pass through Time and Rate
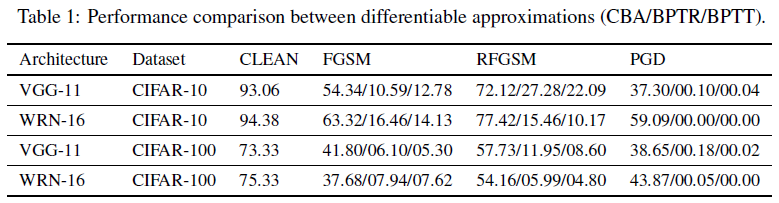
为了比较上述三种可微近似技术在构建SNN基于梯度的攻击方面的有效性,我们将三种基于梯度的方法(FGSM、RFGSM、PGD)和三种可微分近似技术(CBA、BPTR、BPTT)的组合应用于两个基准模型。VGG-11和WideResNet-16这两个模型使用BPTT在CIFAR数据集上进行训练,没有额外的防御。时间步长设置为T=8。
如表1所示,CBA是构造SNN攻击的最无效的可微近似技术。使用CBA的所有受攻击模型的性能都显著高于使用BPTR和BPTT的受攻击模型。正如我们在第3.2节中所讨论的,当使用CBA时,前向传播和反向传播的变化都会导致生成的梯度不准确。BPTT和BPTR方法与不同的攻击方法相结合,都会显著降低给定模型的性能。在所有的单步攻击组合中,FGSM(BPTR)、RFGSM(BPTT)、FGSM(BPTT)和RFGSM(BPTT)可以为所有测试模型生成高效和有效的对抗样本。在所有的多步攻击中,PGD(BPTT)总是击败其他攻击组合。这些结果表明BPTT和BPTR具有不同的性质。BPTT近似包含在使用多步攻击时有用的额外时间信息,而BPTR近似在通过发放率反向传播时节省了更多的计算资源,并且可以在单步攻击中获得可比较的结果。
4 Methods: Perturbation Analysis and Regularized Adversarial Training
上一节确定了来自有效可微近似与基于梯度的攻击相结合的威胁。在本节中,我们将对SNN攻击下的扰动进行理论分析,并提出一种正则化对抗训练方案。
4.1 Perturbation Analysis for Spike Representation
ANN的电流扰动分析考虑了连续激活的距离![]() 和校正后的线性输出的距离
和校正后的线性输出的距离![]() 。Kundu等人[2021b]使用这种基于发放率的距离来桥接ANN和SNN的鲁棒性。SNN中的脉冲序列不仅包含发放率信息,而且具有时序结构。为了评估脉冲序列空间中的距离,各种用于神经元识别和编码的核方法[Weng et al., 2018]被提出。受这些工作的启发,我们提出使用脉冲序列距离对脉冲响应的失真进行建模,这可能为SNN的鲁棒性与神经科学的发现架起桥梁,并且对发放率和时序信息的变化也很敏感。将第 l 层的输出脉冲序列表示为
。Kundu等人[2021b]使用这种基于发放率的距离来桥接ANN和SNN的鲁棒性。SNN中的脉冲序列不仅包含发放率信息,而且具有时序结构。为了评估脉冲序列空间中的距离,各种用于神经元识别和编码的核方法[Weng et al., 2018]被提出。受这些工作的启发,我们提出使用脉冲序列距离对脉冲响应的失真进行建模,这可能为SNN的鲁棒性与神经科学的发现架起桥梁,并且对发放率和时序信息的变化也很敏感。将第 l 层的输出脉冲序列表示为![]() ,其中T是时间步骤的数量,Nl是第 l 层中神经元的数量。然后扰动距离可以公式化为(p≥1):
,其中T是时间步骤的数量,Nl是第 l 层中神经元的数量。然后扰动距离可以公式化为(p≥1):
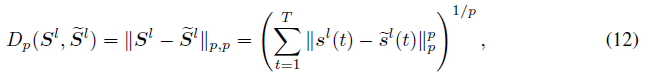
其中,![]() 表示lp入口矩阵范数,而
表示lp入口矩阵范数,而![]() 表示lp向量范数。
表示lp向量范数。![]() 是Sl的扰动版本。由于脉冲激活值(0和1)的p次方是它本身,在不损失一般性的情况下,我们设置p=2。在定理1中,我们得到了脉冲序列距离的Lipschitz常数。
是Sl的扰动版本。由于脉冲激活值(0和1)的p次方是它本身,在不损失一般性的情况下,我们设置p=2。在定理1中,我们得到了脉冲序列距离的Lipschitz常数。
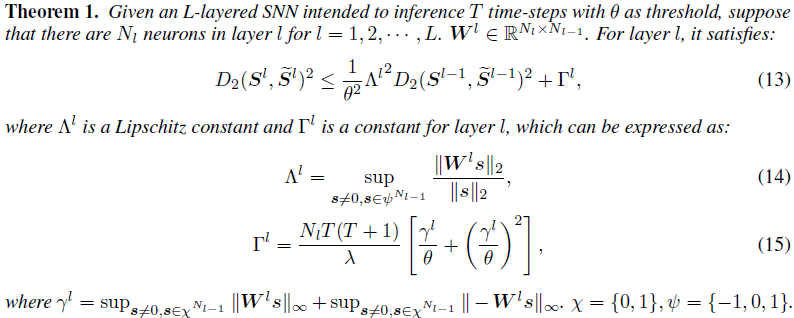
在公式14中,![]() 被称为脉冲Lipschitz常数。由于层间脉冲信号不是纯线性的,并且脉冲产生机制的影响不能被忽略,因此公式13表示的不等式关系与经典Lipschitz常数的定义并不完全相同[O'Searcoid, 2006]。尽管如此,这并不影响我们对脉冲距离放大效应的理解。在公式13的右侧,有一个与权重有关的附加常数Γl。Γl的出现与脉冲的产生和电流的边界有关。Γl的确定采用了一个非常宽松的约束(见我们在附录中的证明),并且它对脉冲距离的影响是加性的,因此我们仍然将关注如何在不过度放大加性项的情况下约束脉冲Lipschitz常数。
被称为脉冲Lipschitz常数。由于层间脉冲信号不是纯线性的,并且脉冲产生机制的影响不能被忽略,因此公式13表示的不等式关系与经典Lipschitz常数的定义并不完全相同[O'Searcoid, 2006]。尽管如此,这并不影响我们对脉冲距离放大效应的理解。在公式13的右侧,有一个与权重有关的附加常数Γl。Γl的出现与脉冲的产生和电流的边界有关。Γl的确定采用了一个非常宽松的约束(见我们在附录中的证明),并且它对脉冲距离的影响是加性的,因此我们仍然将关注如何在不过度放大加性项的情况下约束脉冲Lipschitz常数。
4.2 Constraining Spiking Lipschitz Constant
在这里,我们解释了为什么SNN被认为比ANN更鲁棒,以及如何约束公式13中的脉冲Lipschitz常数。Szegedy等人[2014]得出结论,基于ReLU层的Lipschitz常数的上界是权重矩阵的最大奇异值,即,对于层 l,![]() 。经典Lipschiitz常数和脉冲Lipschitz常数之间的差异在于向量域。经典Lipschitz常数是任何向量x≠0的上确界。在SNN层的情况下,其Lipschitz常数被约束在空间
。经典Lipschiitz常数和脉冲Lipschitz常数之间的差异在于向量域。经典Lipschitz常数是任何向量x≠0的上确界。在SNN层的情况下,其Lipschitz常数被约束在空间![]() 中,这是一个x≠0的子空间。受此启发,我们可以导出经典Lipschitz常数和脉冲Lipschitz常数之间的不等式,该不等式在命题1中提出(详细证明见附录)。
中,这是一个x≠0的子空间。受此启发,我们可以导出经典Lipschitz常数和脉冲Lipschitz常数之间的不等式,该不等式在命题1中提出(详细证明见附录)。
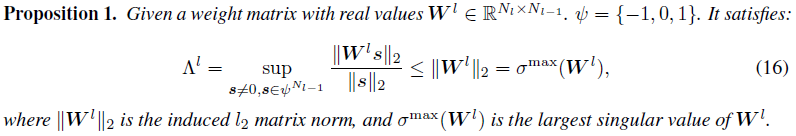
根据公式16,脉冲Lipschitz常数![]() 小于σmax(Wl)。主要目标是通过权重正则化来约束训练。然而,
小于σmax(Wl)。主要目标是通过权重正则化来约束训练。然而,![]() 很难估计,而有许多方法可以调节谱范数σmax(Wl)[Miyato et al., 2018; Cisse et al., 2017; Yoshida and Miyato, 2017]。因此,我们选择在我们提出的训练方案中采用谱范数正则化。正则化的目标是将谱范数控制为接近1:
很难估计,而有许多方法可以调节谱范数σmax(Wl)[Miyato et al., 2018; Cisse et al., 2017; Yoshida and Miyato, 2017]。因此,我们选择在我们提出的训练方案中采用谱范数正则化。正则化的目标是将谱范数控制为接近1:
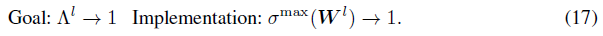
因此,根据公式16,我们还可以满足每个层 l 的![]() 小于1的标准。我们注意到,对
小于1的标准。我们注意到,对![]() 的约束也有助于限制γl,这在命题2中提出(详细证明见附录)。
的约束也有助于限制γl,这在命题2中提出(详细证明见附录)。
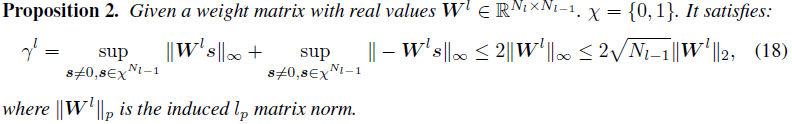
在命题2中,l∞范数和l2范数之间的关系是基于范数不等式理论的。另一方面,在约束空间中定义的γl中的项严格小于Wl的l∞范数。因此,我们可以得出结论,γl有一个由标度σmax(Wl)确定的上界。控制σmax(Wl)足以限制Γl,因为Γl随着γl的增加而单调增加。
4.3 Regularized Adversarial Training (RAT)
Application of regularization (REG). 一旦正则化的目标被设置为控制权重的矩阵范数,接下来的问题是如何找到一个好的正则化子来辅助训练。通过将脉冲神经元的阈值设置为1,脉冲距离的放大主要与Γ有关。鉴于SNN在训练过程中经常遇到梯度问题[Wu et al., 2018b],我们最终确定了一种正交正则化方法,该方法可以帮助防止网络消失梯度[Lin et al., 2021]。当权重矩阵行正交时,奇异值自然等于1。因此,我们建议以β定义的速率将更新权重投影到正交矩阵的目标[Cisse et al., 2017]:
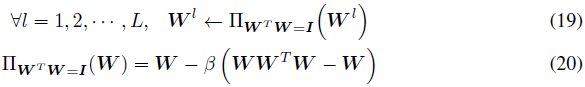
对于具有4维权重矩阵的卷积层![]() ,应首先将这些矩阵重组为
,应首先将这些矩阵重组为![]() 中的2维矩阵,以完成更新,其中k是核大小,Cin, Cout是输入和输出通道的数量。
中的2维矩阵,以完成更新,其中k是核大小,Cin, Cout是输入和输出通道的数量。
Generalizing strong SNN adversarial examples (MIX). 如第3节所示,SNN在反向传播的不同近似下也很脆弱。为了使训练后的SNN具有更好的抵抗性,我们根据观察结果对具有更强对抗扰动的训练数据集进行了论证。第3节中的分析和结果表明,单步FGSM和RFGSM可以以相对较低的计算成本为我们提供足够的对手。值得注意的是,RFGSM被认为是对抗学习中PGD的有效替代品[Wong et al., 2019]。与CBA相比,BPTT和BPTR近似进一步允许数据集扩展到其具有强大对手的l∞球。因此,我们的模型是用从{FGSM(BPTT), RFGSM(BPTT), FGSM(BPTR), RFGSM(BPTR)}中随机采样的对抗样本来训练的。每一小批图像在被馈送到网络之前,都被四种方法中的一种选择以相等的概率扰动。网络学习在由四个对手定义的异构邻域的混合中进行推广。为了获得更好的网络训练性能,我们选择了主流方法,其中网络由具有替代函数的BPTT产生的梯度更新[Nefcci et al., 2019; Zheng et al., 2021; Fang et al., 2021a]。
5 Experiments
5.1 Experimental Setup
我们在图像分类任务上验证了我们提出的鲁棒SNN训练方案,其中使用了CIFAR-10和CIFAR-100数据集。我们为T=8的两个数据集训练VGG-11和WideResNet16的SNN版本(加宽因子设置为4)。此外,我们分别为VGG-11和WideResNet-16设置了β=0.001和0.004。当训练模型时,扰动边界ε被设置为2/255。具体实现见附录。
图像被直接输入SNN。我们包括几种基于梯度的攻击方法来全面评估对抗性能:FGSM [Goodfellow et al., 2015]、RFGSM [Tramèr et al., 2018]、PGD [Madry et al., 2018]、BIM [Kurakin et al., 2017]。高斯噪声(GN)也用于测试在相同的情况下对随机扰动的性能。
5.2 Results
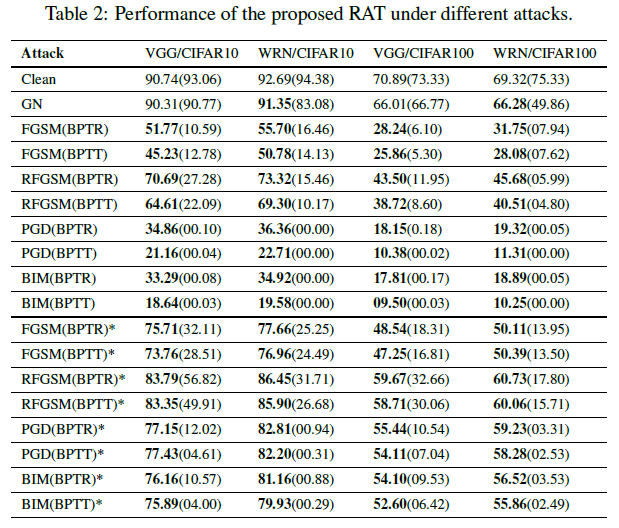
Performance under attacks. 表2报告了我们提出的RAT方案的性能。所有梯度攻击都与强大的SNN攻击(BPTT, BPTR)相结合。括号中的分类精度是没有所提出的训练方案的精度。黑盒攻击在表中用“*”标记。观察到,对于所有的攻击方法,我们的RAT都可以提高模型的鲁棒性,这体现在精度的提高上。与VGG相比,朴素WideResNet更容易受到RFGSM攻击。然而,有了RAT,它甚至比VGG更强大。黑盒攻击对RAT训练的模型几乎无效。对于更强的白盒迭代攻击,我们的RAT提高了鲁棒性,避免了几乎完全错误的分类。例如,VGG-11模型在CIFAR-10数据集上用RAT训练后,在PGD(BPTR)攻击下,其精度提高了34.76%。
Performance with larger ϵ. 我们在图1中绘制了PGD(BPTT)攻击下白盒和黑盒场景的精度。对于白盒攻击,在ε=4/255之后,两个模型都收敛到几乎为零,而RAT训练的模型的精度随着ε的增加而下降。黑盒攻击比白盒攻击弱。从图中可以看出,如图1(b)和(d)所示,RAT训练模型的精度与朴素模型的精度相比下降得较慢。
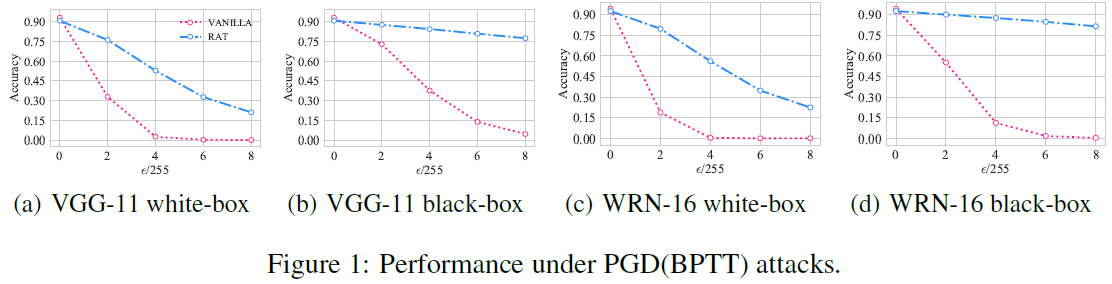
5.3 Ablation Studies
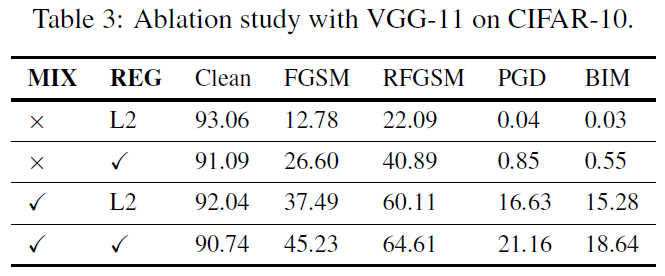
第4.3节中提出的RAT方案由控制脉冲Lipschitz常数的正则化子和用于对抗训练的混合对抗邻域组成。我们基于使用CIFAR-10数据集训练的VGG-11进行消融研究。结果如表3所示。攻击方法均为BPTT攻击。当在没有RAT的情况下训练时,在单步FGSM和RFGSM下的性能低于25%,PGD和BIM的精度几乎为零。仅通过正则化的应用,FGSM和RFGSM的性能就分别提高到26.6%和40.9%。单一部署的混合对抗训练显著提高了鲁棒性,因为异构邻域的组合增强了数据的泛化能力。当同时使用正则化子和对抗训练时,模型获得了最佳的鲁棒性。这些结果表明,RAT中的每个组件单独使用可以提高模型的对抗性能,并且它们组合后大大提高了模型的鲁棒性。
5.4 Effects of Regularized Adversarial Learning
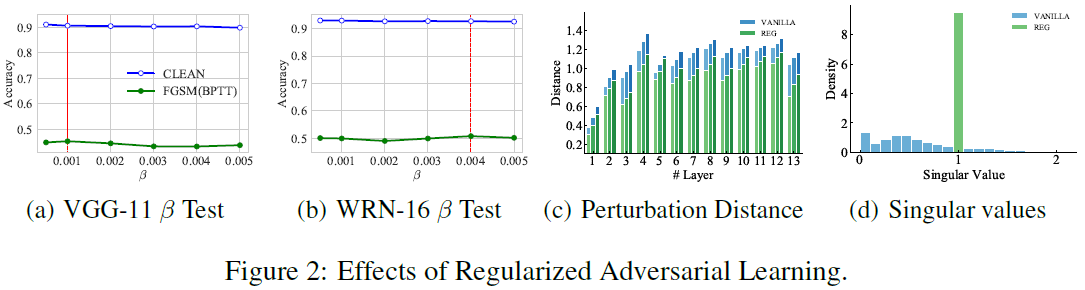
我们在具有VGG-11和WideResNet-16结构的CIFAR-10数据集上测试了正交投影率β的灵敏度。如图2(a)和(b)所示,β对清洁精度几乎没有影响。对于这两种结构,0.001和0.004分别在FGSM(BPTT)攻击下给出了最佳精度。为了验证正则化的效果,对WideResNet-16中每个神经元层的扰动距离进行了可视化。在图2(c)中,颜色范围从亮到暗表示ε=2,4,8。可以看出,正则化模型的距离始终小于朴素模型的距离,这表明正则化抑制了脉冲距离的放大。图2(d)显示了WideResNet-16模型奇异值的分布。正则化使得权重的奇异值如预期的那样聚集在1。
5.5 Comparison with State-of-the-art Work on Adversarial Robustness of SNN
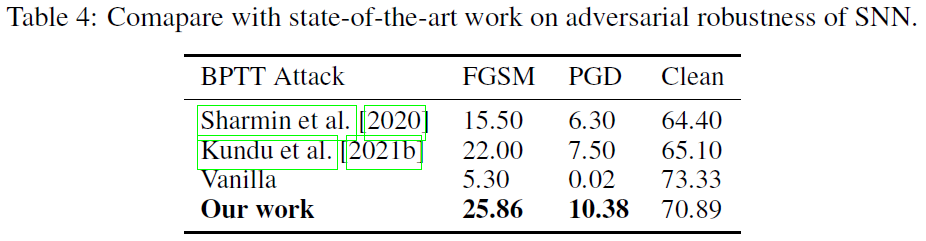
我们将我们的方法与最先进的模型进行了比较,并在表4中报告了结果。评估基于CIFAR-100数据集上的VGG-11实验。对于FGSM,噪声预算已固定为ε=8/255,对于PGD,噪声预算固定为α=0.01,步长=7。该攻击基于BPTT产生的替代梯度。我们的工作中,FGSM攻击的精度性能为25.86%,高于Sharmin等人[2020]提出的性能(15.5%)和Kundu等人[2021b](22.0%)。除此之外,我们的干净精度(70.89%)高于Sharmin等人[2020](64.4%)和Kundu等人[2021b](65.1%)。这意味着与SOTA鲁棒模型相比,我们提出的方法可以带来更好的泛化能力。
值得注意的是,尽管我们的训练算法提高了SNN的鲁棒性,但它会付出额外的代价。成本主要体现在训练时间上。首先,每次更新都要计算权重的正则化。减少正则化时间消耗的解决方案包括采样较少的权重进行正则化,或减少正则化更新的次数。
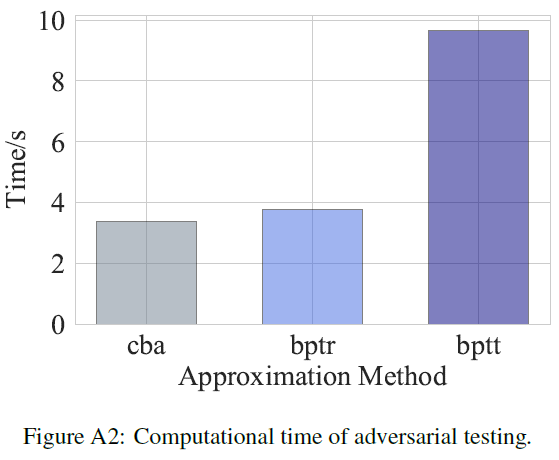
此外,Kundu等人[2021b]中也包括了对抗噪声的产生,这需要一些时间。对抗学习是提高鲁棒性的常用方案,在SNN中仅使用BPTT可微近似生成对抗样本是一项耗时的操作。我们的算法通过混合更快但有效的BPTR近似来缓解训练时间的增加。为了验证这一点,我们评估了对抗测试的计算时间,详细设置见附录。结果表明:BPTR的效率几乎与CBA一样高,而BPTT的成本几乎是CBA和BPTR完成测试所需成本的3倍。
6 Conclusions and Discussions
在这项工作中,我们首次给出了硬件友好SNN扰动的Lipschitz理论分析。SNN由于其多样且可行的梯度方法而更容易受到攻击。因此,我们提出了一种专门的正则化SNN对抗训练方案。我们的实验表明,基于该方案训练的模型可以获得很大的鲁棒性,尤其是在黑盒攻击中。我们相信这项工作将为SNN在节能和安全关键应用中铺平道路。此外,最近的工作表明,在没有BN的情况下,SNN可以获得良好的结果[Kundu et al., 2021a]。请注意,BN被包括在我们的模型中,这可能对鲁棒性有害[Wang et al., 2022]。因此,未来有价值的研究方向将包括如何训练鲁棒的SNN,同时消除BN的不利影响。

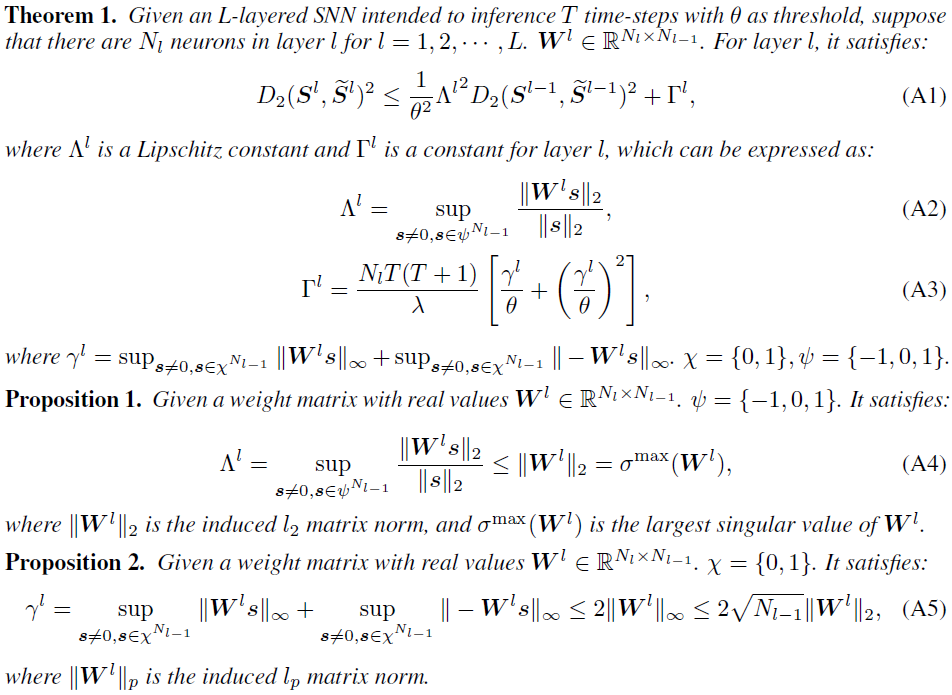
A Proofs
Proof for Theorem 1
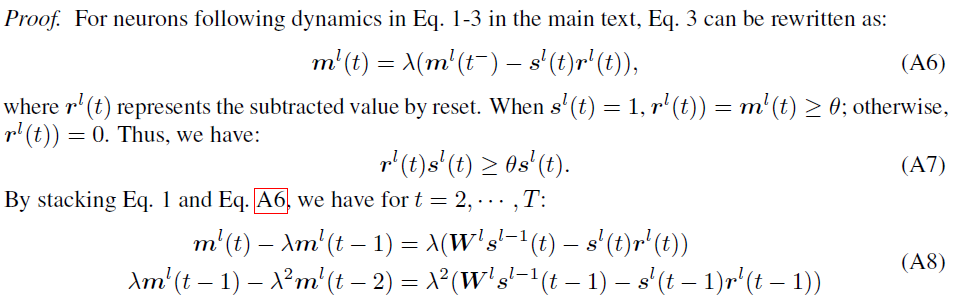

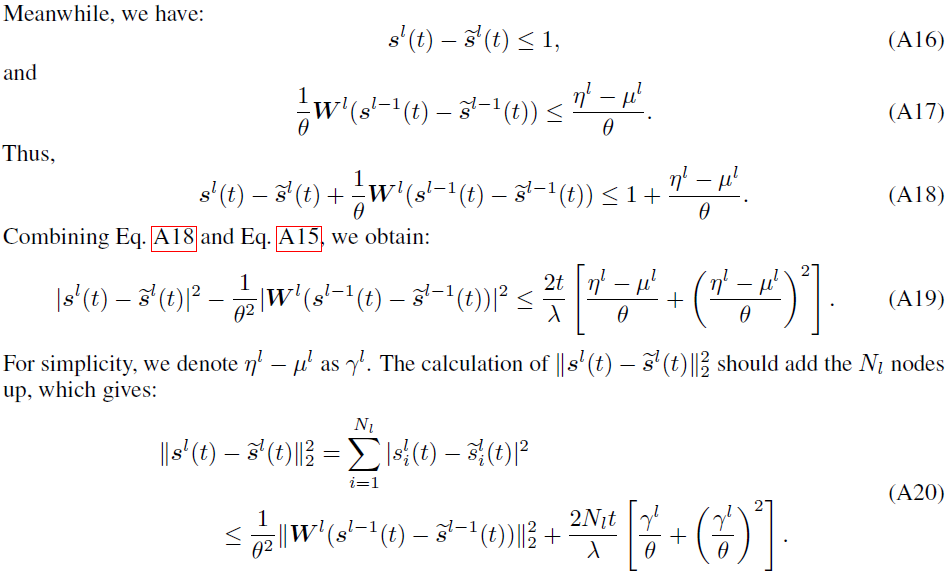

Proof for Proposition 1

Proof for Proposition 2
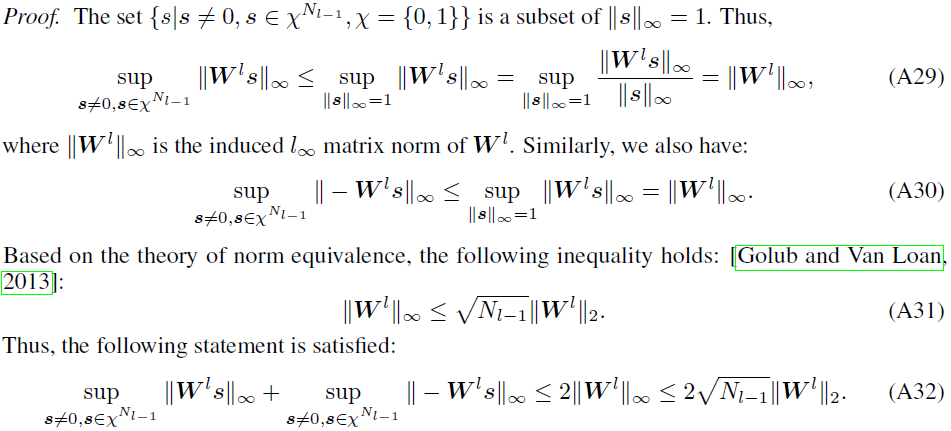
B Details of Implementation
用于说明正文第3节中漏洞的结构是VGG-111和WideResNet-162,推理时间步长T=8。SNN中的泄漏系数λ设置为1.0。他们在CIFAR-10和CIFAR-100数据集上进行训练[Crizhevsky et al., 2009]。在正文的第5节中,我们的方法的验证也基于上述两种架构。训练过程持续了200个epoch。如Zheng等人[2021]所建议的,在网络中使用批量归一化来克服深度SNN的梯度消失或爆炸。在训练过程中,部署了随机梯度下降,初始学习率设置为0.1。学习率使用余弦退火调度,其中Tmax等于epoch的最大数。朴素模型在没有正则化对抗训练方案的情况下进行训练,因此在每个训练迭代中添加5e-4的权重衰减,以提高整体精度。图像数据首先通过三个通道的均值和方差进行归一化,然后被馈送到SNN中以触发脉冲。所有实验都是在NVIDIA GeForce RTX 3090上的PyTorch平台[Paszke et al., 2019]上进行的。
为了克服不可微问题并实现SNN训练,应用替代梯度函数为训练和BPTT攻击提供梯度。
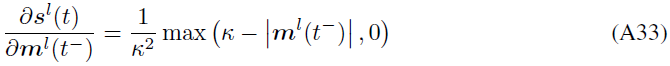
在我们的实现中,我们为所有实验选择κ=1.0。请注意,我们调整和修改了torchattacks Python包[Kim, 2020]的基于梯度的攻击的实现,因为我们需要对SNN进行成功的攻击。
1 使用的VGG-11遵循https://github.com/nitin-rathi/hybrid-snn-conversion中的实现。
2 使用的WideResNet-16遵循https://github.com/xternalz/WideResNet-pytorch中的实现(MIT license)。
C Comparison with State-of-the-art Work on Adversarial Robustness of SNN
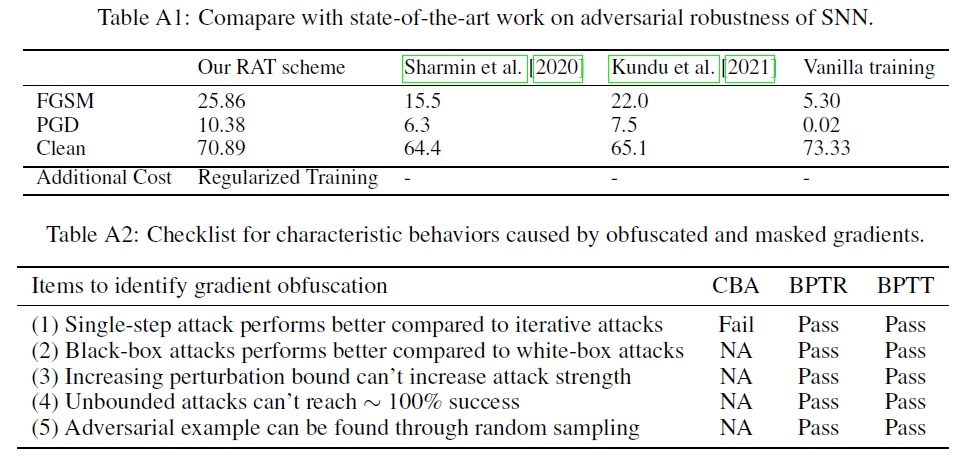
我们将我们的方法与最先进的模型进行了比较,并在表A1中报告了结果。可以发现,我们提出的训练方案在干净精度和扰动精度方面都优于其他方案。评估基于CIFAR-100数据集上的VGG-11实验。对于FGSM,噪声预算已固定为ε=8/255,对于PGD,噪声预算固定为α=0.01,步长=7。该攻击基于BPTT产生的替代梯度。在我们的工作中,FGSM攻击的精度性能为25.86%,高于Sharmin等人[2020](15.5%)和Kundu等人[2021](22.0%)提出的性能。除此之外,我们的干净精度(70.89%)高于Sharmin等人[2020](64.4%)和Kundu等人[2021](65.1%)提出的精度。这意味着与SOTA鲁棒模型相比,我们提出的方法可以带来更好的泛化能力。
值得注意的是,尽管我们的训练算法提高了SNN的鲁棒性,但与Sharmin等人[2020]和Kundu等人[2021]的工作相比,这是有代价的。成本主要体现在训练时间上。首先,我们的训练包括产生对抗噪声的时间。对抗学习是提高鲁棒性的常用方案,在SNN中仅使用BPTT可微近似生成对抗样本是一项耗时的操作。我们的算法通过混合更快但有效的BPTR近似来缓解训练时间的增加。此外,每次更新都要计算权重的正交正则化,这也增加了训练时间。减少正则化时间消耗的解决方案包括采样较少的权重进行正则化,或减少正则化更新的次数。
D Analysis of Gradient Obfuscation
我们设计并总结了三种可微近似,即CBA、BPTT、BPTR,它们可以部署在基于梯度的攻击中,以显示SNN的脆弱性。梯度模糊的主要问题在于更新梯度的不准确。特别是,与Kundu等人[2021]中所做的可以识别梯度模糊的五个测试相比,检查了三个可微近似的性能。我们的分析主要基于正文中表1和表2中的量化结果。此外,这将解释为什么我们在混合训练过程中选择BPTT和BPTR。
如表1所示,对于所有试验,除了CIFAR-100的WRN-16实验的性能外,单步FGSM的性能都比迭代对应的PGD差(攻击精度:FGSM 37.68%vs.s.PGD 43.87%)。因此,CBA近似可能无法提供足够强大的攻击。
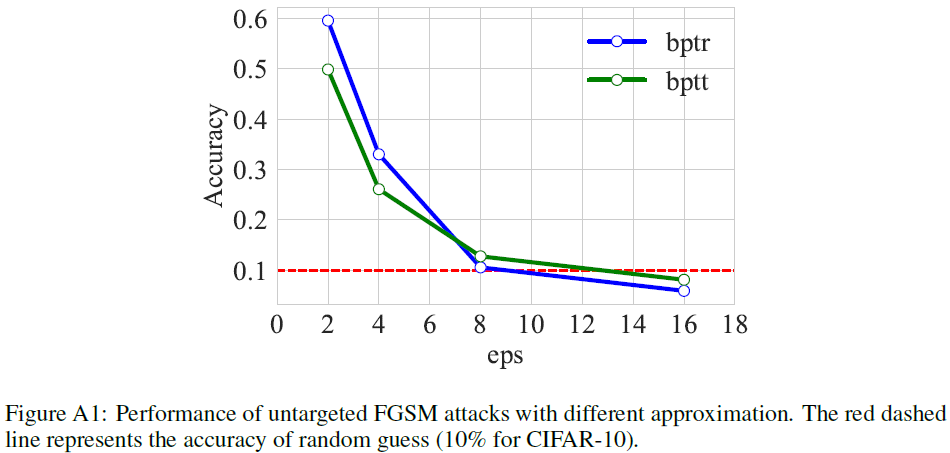
因此,剩下的分析是关于BPTT和BPTR的。表1和表2中的结果证明了根据表R2中的测试(1),BPTT和BPTR近似的成功。为了验证测试(2),我们对所提出的模型和普通模型进行了黑盒攻击。黑盒扰动在表2中表现较弱,并且满足测试(2)。为了验证测试(3)(4),我们分析了攻击界增加的CIFAR-10上的VGG-11。在图A1中,分类精度随着我们增加而降低,最终达到随机猜测的精度。正如Kundu等人[2021]所建议的,测试(5)“只有在基于梯度的攻击不能为模型提供错误分类的对抗样本的情况下才会失败”。总之,我们没有发现适用于对抗训练和测试的BPTT和BPTR近似的梯度模糊。
E Analysis of Computational Cost
SNN对抗训练的额外计算成本主要体现在梯度近似的选择上。在这里,我们评估对抗测试的计算时间。对抗测试意味着模型应该前向两次,反向一次。在测试过程中,我们将小批量大小固定为64,并在NVIDIA 3090 GPU上运行测试。结果如表A2所示。我们发现,在提出的三种近似中,CBA是最有效的,因为它只通过脉冲神经元传播,就好像只有ReLU激活一样。BPTR的效率几乎和CBA一样高。考虑到BPTR比CBA更强大,BPTR对SNN来说是一个相当好的攻击。然而,BPTT的成本几乎是CBA完成测试所需成本的3倍。
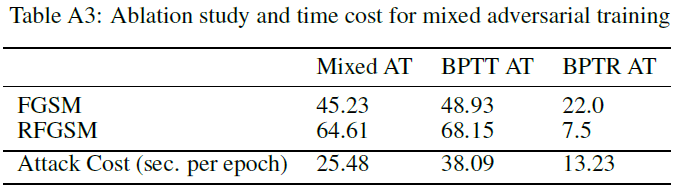
F Societal Impact and Limitations
由于我们的工作是评估和加强SNN的鲁棒性,因此没有明显的负面社会影响。我们提出的方法提高了对抗鲁棒性,这具有更积极的社会影响。关于局限性,当遇到看不见的对抗攻击时,我们的方法可能会失去鲁棒性。因此,对抗训练可能需要更多类型的攻击。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号