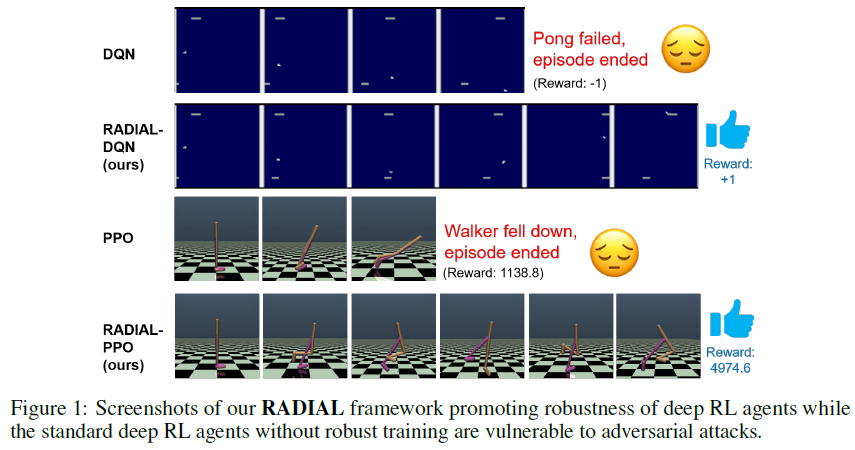
Robust Deep Reinforcement Learning through Adversarial Loss
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

35th Conference on Neural Information Processing Systems (NeurIPS 2021)
Abstract
最近的研究表明,深度强化学习智能体很容易受到智能体输入上的小对抗扰动的影响,这引发了人们对在现实世界中部署此类智能体的担忧。为了解决这个问题,我们提出了RADIAL-RL,这是一个原则性框架,用于训练强化学习智能体,提高其对lp-范数有界对抗攻击的鲁棒性。我们的框架与流行的深度强化学习算法兼容,并通过深度Q学习、A3C和PPO展示了其性能。我们在三个深度RL基准(Atari、MuJoCo和ProcGen)上进行了实验,以展示我们的鲁棒训练算法的有效性。当针对不同强度的攻击进行测试时,我们的RADIAL-RL智能体始终优于先前的方法,并且在训练时计算效率更高。此外,我们提出了一种新的评估方法,称为贪婪最坏情况奖励(GWC),以衡量深度RL智能体的攻击不可知鲁棒性。我们表明,GWC可以被有效地评估,并且是对在最坏对抗攻击序列下奖励的良好估计。用于我们实验的所有代码都可以在https://github.com/tuomaso/radial_rl_v2中获取。
1 Introduction
深度学习在各种具有挑战性的领域取得了巨大成功,从计算机视觉[1]、自然语言处理[2]到强化学习(RL)[3, 4]。然而,对抗样本[5]的存在表明,深度神经网络(DNN)并不像我们预期的那样鲁棒和可信,因为微小且往往难以察觉的扰动可能导致对最先进的DNN的错误分类。不幸的是,对抗攻击在深度强化学习中也被证明是可能的,其中观察空间和/或动作空间中的对抗扰动可能导致深度RL智能体的任意糟糕性能[6, 7, 8]。由于深度RL智能体被部署在许多安全关键应用中,如自动驾驶汽车和机器人,因此开发鲁棒训练算法(也称为防御算法)至关重要,以使最终训练的智能体对于对抗(和非对抗)扰动具有鲁棒性。
已经提出了许多启发式防御来提高DNN对图像分类任务的对抗攻击的鲁棒性,但它们在对抗更强的对抗进攻算法时往往失败。例如,[9]表明,13种这样的防御方法(最近在著名会议上发表)都可以被更先进的攻击打破。启发式防御的一个新兴替代方案是基于鲁棒性验证或认证边界的防御算法2[10, 11, 12, 13]。这些算法产生鲁棒性证书,使得对于指定的lp范数距离内的任何扰动,训好的DNN将在给定的数据点上产生一致的分类结果。沿着这条线的代表性工作包括[11]和[14],其中,通过在具有适当训练计划的损失函数中包括鲁棒性验证边界,学到的模型可以具有更高的认证精度,即使验证器为没有鲁棒训练的模型(也称为标准模型)生成松散的鲁棒性证书[14]。在这里,认证的精度被计算为在给定扰动幅度下保证被正确分类的测试图像的百分比。
然而,大多数防御算法都是为分类任务开发的。很少有防御算法被设计用于深度RL智能体,这可能是因为RL中存在分类任务中不存在的额外挑战,包括信度分配和缺乏固定训练集。为了弥补这一差距,在本文中,我们提出了RADIAL(Robust ADversarIAl Loss)-RL框架来训练鲁棒的深度RL智能体。我们表明,RADIAL可以通过使用精心设计的基于鲁棒性验证边界的对抗损失函数来提高深度RL智能体的鲁棒性。我们的贡献如下:
- 我们提出了一种新的鲁棒深度RL框架RADIAL-RL,它可以应用于不同类型的深度RL算法。我们在三种流行的RL算法DQN[3]、A3C[15]和PPO[16]上演示了RADIAL。
- 我们展示了RADIAL智能体在Atari游戏和MuJoCo中的连续控制任务中的卓越性能:我们的智能体与[17]相比,训练的计算效率高出2-10倍,并且可以比现有工作[18, 17]更好地抵抗多达5倍强的对抗扰动。
- 我们还使用ProcGen基准评估了鲁棒训练对智能体泛化到新水平的能力的影响,并表明我们的训练还提高了对看不见的水平的鲁棒性,即使面对ε=5/255的PGD攻击也能获得高奖励。
- 我们提出了一种新的评估方法,贪婪最坏情况奖励(GWC),用于有效地(在线性时间内)评估RL智能体在最强对手(即最坏情况下的扰动)。
2 Related work and background
2.1 Adversarial attacks in Deep RL
监督学习任务中的对抗样本主题已经得到了广泛的研究,特别是对于DNN分类器[5, 19]。最近,[6, 7, 8]表明,深度RL智能体也容易受到对抗扰动的影响,包括对智能体的观察和动作的对抗扰动[6, 7, 8]、对环境的错误规范[20]、对智能体的对抗干扰[21]和其他对抗智能体[22]。关于RL中不同攻击和防御设置的综述,请参见Ilahi等人[23]。
在本文中,我们重点关注智能体观测上的lp-范数对抗扰动,因为该威胁模型被许多研究深度RL对抗鲁棒性的现有工作所采用[6, 7, 8, 24, 25, 26, 27, 18, 17]。然而,我们的框架并不局限于lp-范数扰动,事实上,通过利用[28]中提出的技术,可以很容易地扩展到基于视觉的深度RL智能体(例如atari游戏)的语义扰动(例如旋转、颜色/亮度变化等)。
2.2 Formal verification and robust training for Deep RL
DNN分类器的鲁棒性认证方法[12]已应用于深度RL设置:例如,[27]提出了一种在执行过程中选择具有最高认证下界Q值的动作的策略,[24]推导了系统中持续对抗扰动下神经网络策略的更严格鲁棒性证书。这些工作研究了固定神经网络的鲁棒性,而我们的工作集中在训练产生更鲁棒RL策略的神经网络上。
对抗训练的思想已应用于深度RL,以抵御对抗攻击[25,26];然而,这些方法通常具有比标准训练高得多的计算成本。虽然之前的工作,如[21],也在与我们不同的威胁模型下训练了强大的智能体,但我们不会与它们进行比较,因为它们有不同的目标和评估方法。
与我们的工作最相关的文献是两种用于深度Q学习智能体的鲁棒训练方法[18, 17]。RS-DQN[18]将DQN智能体解耦为策略和学生网络,这使得能够在不强烈影响正确Q函数学习的情况下利用对学生DQN的额外约束,而SA-DQN[17]添加了铰链损失正则化子,以鼓励DQN智能体在观察空间中存在扰动时遵循其原始动作。[17]还提出了在连续控制中训练鲁棒RL智能体的SA-PPO和SA-DDPG。相反,在RADIAL中,我们利用昂贵的鲁棒性验证边界来仔细设计正则化子,阻止深度RL智能体的潜在重叠行为。如第4节所示,我们的RADIAL智能体在各种强度的对抗攻击下表现优于[18, 17],同时在训练方面比[17]的计算效率高2-10倍。此外,我们引入了一种新的度量来评估智能体在对抗最坏可能的对手时的性能,这在[18, 17]中没有进行研究。
2.3 Basics of Deep Reinforcement Learning


3 A Robust Deep RL framework with adversarial loss
在本节中,我们提出了RADIAL-RL,这是一个用于训练对抗攻击的深度RL智能体的原则性框架。RADIAL通过利用现有的神经网络鲁棒性形式验证边界来设计对抗损失函数。我们首先介绍了RADIAL的关键思想,然后在第3.1、3.2和3.3节中阐明了为三种经典的深度强化学习算法DQN、A3C和PPO制定对抗损失的几种方法。在第3.4节中,我们提出了一种新的评估指标,贪婪最坏情况奖励(GWC),以有效评估智能体对输入扰动的鲁棒性。
Main idea. RADIAL框架的训练损失LRADIAL由两个项组成:
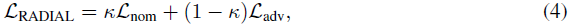
其中,Lnom表示标准损失函数,如公式(1)-(3)用于标准深度RL智能体,Ladv表示对抗损失,我们将仔细设计该损失以考虑对抗扰动。κ是一个超参数,用于控制标准性能和鲁棒性能之间的权衡,其值在0和1之间,并且注意,标准RL训练算法在整个训练过程中具有κ=1。在此,我们提出了两种原则性方法来构建Ladv,这两种方法都是通过神经网络鲁棒性证明边界[14, 12, 13, 11, 31, 32, 33, 34]:
#1. 构造扰动标准损失的严格上界(公式(9), (10), (7));
#2. 设计正则化子以最小化结果差异较大的动作的输出边界之间的重叠(公式(5), (6))。
方法#1的动机很好,因为最小化扰动标准损失的严格上限通常也会降低真正的扰动标准损失,这表明策略在对抗扰动下应该表现良好。或者,方法#2的动机是我们希望避免因为小的输入扰动而选择明显更糟糕的动作。
方法#1和#2的基础都在于鲁棒性形式验证工具,以导出输入扰动下神经网络的输出边界。具体而言,对于给定的神经网络,假设zi(x)是具有输入x的神经网络的第 i 层的激活。鲁棒性验证算法的目标是计算神经网络的逐层下界和上界,表示为![]() 和
和![]() ,使得
,使得![]() ,对于具有||δ||p ≤ ε的x上的任何加性输入扰动δ。我们将在Q网络(用于DQN)或策略网络(用于A3C和PPO)上应用鲁棒性验证算法,以获得Q和π的逐层输出边界。这些输出边界可用于计算方法#1在最坏情况的对抗扰动Ladv下的原始损失函数的上界。类似地,如方法#2所提出的,逐层边界用于最小化输出间隔的重叠。为了提高训练效率,IBP[14]用于计算神经网络的逐层边界,但也可以直接应用其他可微认证方法[12, 13, 11, 31, 32, 33](尽管可能会产生额外的计算成本)。我们的实验集中在p=∞上,以与基线进行比较,但该方法适用于一般p。
,对于具有||δ||p ≤ ε的x上的任何加性输入扰动δ。我们将在Q网络(用于DQN)或策略网络(用于A3C和PPO)上应用鲁棒性验证算法,以获得Q和π的逐层输出边界。这些输出边界可用于计算方法#1在最坏情况的对抗扰动Ladv下的原始损失函数的上界。类似地,如方法#2所提出的,逐层边界用于最小化输出间隔的重叠。为了提高训练效率,IBP[14]用于计算神经网络的逐层边界,但也可以直接应用其他可微认证方法[12, 13, 11, 31, 32, 33](尽管可能会产生额外的计算成本)。我们的实验集中在p=∞上,以与基线进行比较,但该方法适用于一般p。
3.1 RADIAL-DQN
对于对偶DQN,优势函数AQ用于决定采取哪种动作,而价值函数VQ仅对训练很重要。因此,我们只需要使AQ具有鲁棒性,并且Q函数的上下限为![]() 和
和![]() ,给予输入s界限为ε的扰动。在RADIAL中,我们提出了两种方法来导出对抗损失Ladv;然而,由于空间限制,我们在正文中描述了具有更好经验性能的方法,而在附录中保留了另一种方法。
,给予输入s界限为ε的扰动。在RADIAL中,我们提出了两种方法来导出对抗损失Ladv;然而,由于空间限制,我们在正文中描述了具有更好经验性能的方法,而在附录中保留了另一种方法。
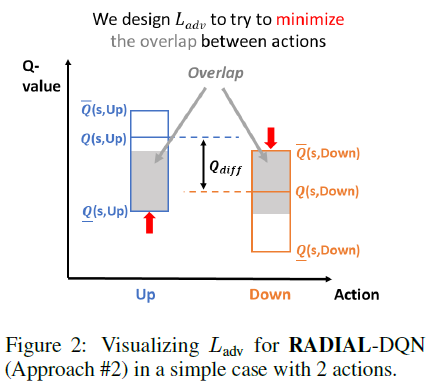
对于DQN,我们发现方法#2的性能更好。方法#2的目标是最小化不同动作的激活边界的加权重叠(图2)。其思想是只最小化鲁棒性能所必需的重叠。如果没有重叠,即使在扰动下,原始动作的Q值也保证高于其他动作,因此智能体不会在扰动下改变其行为。然而,并不是所有的重叠都同样重要。如果两个动作具有非常相似的Q值,重叠是可以接受的,因为在扰动下采取不同但同样好的动作不是问题。为了解决这个问题,我们添加了Qdiff加权,这有助于将与类似Q值的重叠乘以一个小数字,并将与不同Q值的重叠乘以一个大数字。
最终损失函数如下:
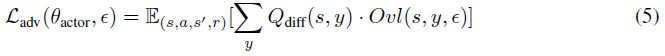
其中:
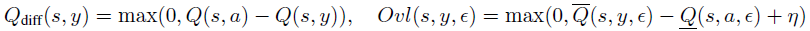
η = 0.5 · Qdiff(s, y),a是所采取的动作。这里Ovl表示两个动作的边界之间的重叠(图2中的灰色区域)。为了提高额外的鲁棒性,激励网络具有裕度η(而不是简单地没有重叠)。我们设置η = 0.5 · Qdiff,使其为可达到的最大裕度的一半。请参阅附录F,了解有关此选项对裕度的重要性的实验和讨论。请注意,Qdiff被视为用于优化的常数(无梯度)。公式(5)在ε=0时减小到零。
3.2 RADIAL-A3C

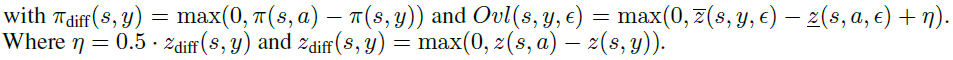
3.3 RADIAL-PPO


3.4 New efficient evaluation metric: Greedy Worst-Case Reward
训练RL智能体对输入扰动具有鲁棒性的目标是确保智能体在任何(有界)对抗扰动下仍能表现良好。这可以转化为最大化最坏情况奖励Rwc,这是在最坏对抗攻击序列下的奖励。我们定义Rwc如下:![]() ,轨迹τ = (s0, a0, ... , sT, aT),其中at, st, rt分别从
,轨迹τ = (s0, a0, ... , sT, aT),其中at, st, rt分别从![]() 中抽取,并且R(τ) =
中抽取,并且R(τ) =![]() 。一种想法是评估每一个可能的轨迹τ,找出哪一个轨迹产生的奖励最小。然而,Rwc实际上是不可能评估的,因为对于每个状态st,找到一组可能动作at的最坏扰动δt是NP困难的,并且要评估的轨迹量相对于轨迹长度T呈指数增长,这很难计算。避免直接发现最坏情况扰动的一种可能方法是使用经验证的输出边界[12, 13, 11, 31, 32, 33],这会在最坏情况下产生所有可能动作的超集,因此产生的总累积奖励是Rwc的下界。我们将此奖励命名为绝对最坏情况奖励(AWC)。注意,当策略和环境都是确定性的时,AWC是Rwc的下界。
。一种想法是评估每一个可能的轨迹τ,找出哪一个轨迹产生的奖励最小。然而,Rwc实际上是不可能评估的,因为对于每个状态st,找到一组可能动作at的最坏扰动δt是NP困难的,并且要评估的轨迹量相对于轨迹长度T呈指数增长,这很难计算。避免直接发现最坏情况扰动的一种可能方法是使用经验证的输出边界[12, 13, 11, 31, 32, 33],这会在最坏情况下产生所有可能动作的超集,因此产生的总累积奖励是Rwc的下界。我们将此奖励命名为绝对最坏情况奖励(AWC)。注意,当策略和环境都是确定性的时,AWC是Rwc的下界。
然而,AWC仍然需要评估可能的动作序列的指数数量,这在计算上是昂贵的。为了克服这一限制,我们在算法1中提出了一种称为贪婪最坏情况奖励(GWC)的替代评估方法,该方法近似于期望的Rwc,并且可以以总时间步长T的线性复杂度有效地计算。GWC的想法是避免评估轨迹的指数数量,并使用简单的启发式方法来近似Rwc,方法是在每个状态下贪婪地选择Q值最低的动作(或A3C采取动作的概率)。我们在图4(附录E)中显示,GWC通常接近AWC,同时评估速度要快得多(总时间步长的线性复杂性)。关于基线工作[17, 18]中使用的度量的讨论以及AWC计算算法的完整描述见附录D。
4 Experimental results
Environments and setup 为了与基线工作[17, 18]进行公平的比较,我们在相同的Atari-2600环境[35]和[17, 18]中使用的相同4款游戏上进行了实验。与[17, 18]不同的是,我们在更具挑战性的ProcGen[36]基准上进一步评估了我们的算法,这使我们能够测试智能体的泛化能力。请注意,Atari游戏和ProcGen[36]基准都有高维像素输入和离散动作空间。为了将我们的RL智能体与[17]的连续动作进行比较,我们使用模拟机器人控制的MuJoCo环境,该环境具有相对低维的输入和连续的动作空间。完整的训练细节和超参数设置见附录H。
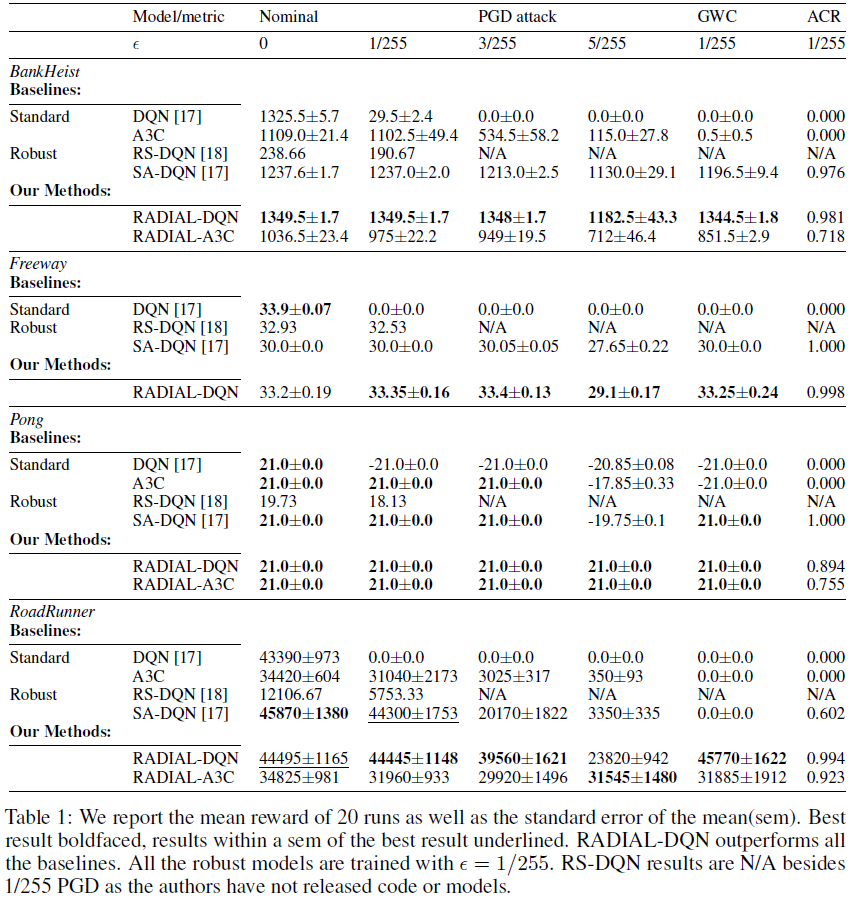
Evaluation. 我们用总共3个指标来评估我们的智能体的性能:(a)在每帧上应用的10步l∞-PGD非目标攻击下的总奖励,(b)GWC和(c)动作认证率(ACR) [17]。对于Atari游戏,RADIAL智能体的方法#2的结果在表1中,方法#1的结果在附录I中。注意,A3C和PPO在训练期间随机采取动作,但我们将其设置为在评估期间决定性地选择概率最高的动作。
4.1 Atari results
表1显示,在[17]中使用相同的评估方法对抗ε=1/255的PGD攻击时,RADIAL-DQN在所有四个游戏中都优于或匹配所有基线。结果表明,RADIAL可以在不牺牲标准性能的情况下训练针对ε=1/255的对抗扰动的鲁棒策略。事实上,我们强大的RADIAL智能体在所有评估指标上都始终优于基线,RoadRunner的裕度也很高。除了更好的奖励外,我们的RADIAL-DQN训练速度比[17]快大约6倍。从实验上讲,如果我们包括标准的训练过程,我们的总运行时间只有17小时,而SA-DQN在我们的硬件上的运行时间为35小时。RADIAL-A3C在对抗攻击下也获得了很高的奖励,并在2/4任务上击败了基线,尽管游戏可能是由以前的工作选择的,因为它们对Q学习智能体来说很容易。如表1所示(A3C被排除在外,因为它没有学习Freeway),RADIAL-A3C的标准奖励略低于RADIAL-DQN,但在对抗大扰动时表现出更鲁棒的性能,甚至在对抗RoadRunner的ε=5/255的PGD攻击时表现优于RADIAL-DQN。这表明RADIAL适用于非常不同类型的RL算法。
一个有趣的发现是,即使没有鲁棒训练,我们的A3C基线实际上也能很好地抵御小型PGD攻击(标准DQN模型在ε=1/255时都表现得很糟糕,而A3C的性能与鲁棒训练的SA-DQN或RS-DQN相当,甚至更好。) 我们认为这是由于两个主要因素造成的:(a)网络架构与DQN略有不同,并使用了最大池化层,这自然使其更能抵抗输入的许多小变化;(b) A3C训练更具随机性,因此它更能抵抗非目标攻击引起的偶尔的随机动作。
在我们跨不同算法和环境的实验中,另一个有趣的观察结果是,有时应用攻击或增加PGD攻击的幅度会增加所获得的奖励。我们注意到,这种现象并非没有道理,因为PGD攻击旨在简单地改变RL智能体的原始动作;最初的轨迹可能并不是最好的轨迹,而不同的轨迹可以给予更高的奖励。我们在Freeway上观察到了SA-DQN和RADIAL-DQN(表1)以及CoinRun和Jumper上的RADIAL-PPO(表2)的这种现象。我们认为,这表明了非目标PGD攻击的弱点,并突出了RL策略攻击的改进空间。
4.2 ProcGen Results
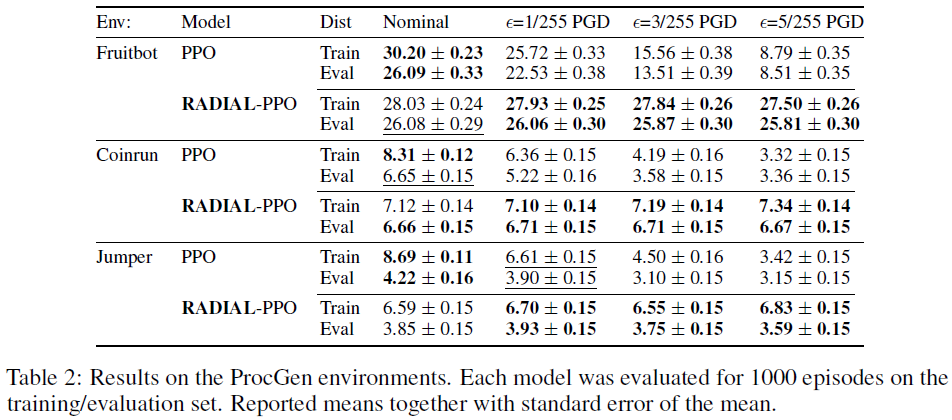
我们在表2中报告了基于ProcGen基准[36]的3种环境的结果。据我们所知,这是首次评估在ProcGen上训练的RL智能体的鲁棒性。我们所有的智能体都接受了2500万步的简单设置训练,接受了200个不同级别的训练,并对全面分布进行了评估。我们使用了IMPALA-CNN架构[36],它比我们的Atari实验中的架构大得多,但我们的算法和训练设置仍然可以成功地扩展到这种更复杂的设置。我们注意到,与A3C一样,最初的PPO策略对小型PGD攻击已经相当鲁棒,但RADIAL-PPO对更强的攻击具有更好的鲁棒性。接下来,我们使用按级别划分的训练/评估来研究我们的鲁棒训练是否适用于新的环境。我们观察到,RADIAL训练在训练和评估集上都能持续提高鲁棒性,并且RADIAL-PPO的训练和评估结果之间的差距通常较小。表2中的结果使用了该策略的确定性版本,随机策略的结果报告在附录I中。
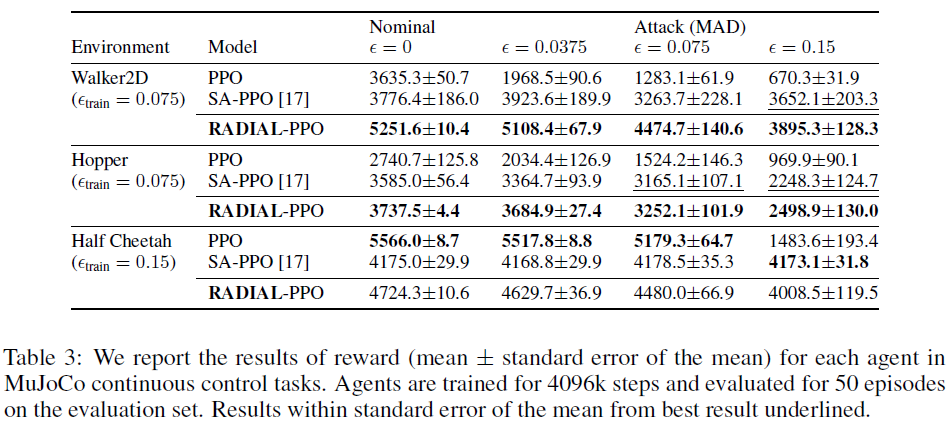
4.3 MuJoCo Results
在表3中,我们展示了我们在MuJoCo[37]的3个环境上的结果,并与朴素PPO方法和SA-PPO[17]凸松弛方法进行了比较。我们直接使用[17]中的实现。我们为所有3种环境训练4096k个步骤,而[17]为Walker2D和Hopper使用大约2000k。对于每种环境,我们比较了不同ε的MAD攻击[17]下的性能。对于Walker2D,我们使用训练ε=0.075,而不是[17]中的ε=0.05,以便在不同攻击下进行更好的比较。对于Walker2D和Hopper,RADIAL-PPO在自然测试和鲁棒测试方面都优于SA-PPO[17]。有趣的是,对于Half-Cheetah来说,我们发现这种环境天生鲁棒(甚至比经过鲁棒训练的智能体更好),可以抵御高达ε=0.075的攻击。
4.4 Evaluating GWC
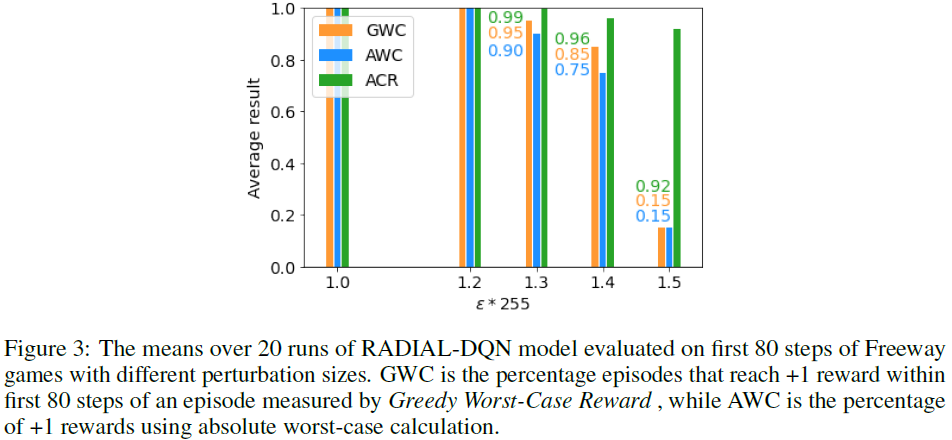
我们的经验表明,GWC确实是AWC奖励的一个很好的近似值。由于AWC的指数复杂性,我们在Freeway上80帧内达到第一个奖励的小规模实验中,将GWC和动作认证率(ACR)与绝对最坏情况奖励(AWC)进行了比较。图见附录D。GWC是由GWC测量的+1奖励的比率,而AWC使用深度优先搜索来使用算法2计算+1奖励的百分比(即,所有可能的动作序列都至少获得+1奖励)。对于我们评估的回合,GWC与AWC完美匹配,ε ∈ {1.3, 1.4}。由于AWC是GWC的下界,ε ∈ {1.0, 1.2, 1.5},GWC在37/40个回合中与AWC匹配,而在3/40个回合中过高估计。ACR(如[17]中所用)与AWC的相关性没有那么强。如表1所示,GWC是比ACR更好的鲁棒性能指标——Freeway和Pong就是这样,SA-DQN的动作认证率更高,但RADIAL-DQN的GWC和PGD奖励更高。综合这些结果,我们相信GWC是一种良好的评估方法。
5 Conclusions and Future works
我们已经证明,使用所提出的RADIAL框架可以显著提高深度RL智能体对基于鲁棒性验证边界的对抗扰动的鲁棒性——我们经过鲁棒训练的智能体在对抗比先前技术状态更大5倍的扰动时都能达到非常好的性能,同时训练的计算效率也高得多。此外,我们还提出了一种新的评估方法,贪婪最坏情况奖励,作为最坏情况奖励的良好替代,来评估深度RL智能体在对抗输入扰动下的性能。未来的工作包括扩展我们的框架,以抵御对比度和亮度变化等语义扰动,这在基于视觉的RL智能体(例如,自动驾驶汽车、基于视觉的机器人)上更为现实。
6 Limitations and Potential negative impact
我们的工作的一个重要局限性是,我们的工作只涉及一个特定的鲁棒性轴,即对lp-范数有界扰动的鲁棒性。虽然有一些方法可以将其扩展到语义扰动[28],但我们的方法没有解决其他轴,如对不断变化的环境条件的鲁棒性。我们想强调这一领域使用的常见术语,如认证防御和鲁棒性,对于非专家来说可能听起来很有说服力,但对当前鲁棒训练方法的局限性理解不足,并且过度依赖它们,这就带来了负面社会影响的紧迫潜力。
A Appendix: Radial-DQN

B Appendix: Radial-A3C

C On Approach #2 for continuous actions
在方法#2中,我们设计Ladv以最小化所选动作a的下界和所有其他动作y ∈ A \ {a}的上界之间的重叠。这种方法本质上依赖于动作空间A是离散的。如果我们想将这个想法扩展到连续动作,我们可以用A \ {a}上的积分取代公式6的总和。由于动作a是动作空间A上的一个单点,因此A \ {a}上的积分与在整个动作空间上的积分相同。这是不可取的,因为a总是与自身重叠,这不是我们希望规范化的事情。此外,计算这样的积分通常是不可行的,必须通过均匀分布A的蒙特卡罗采样来近似。
即使我们克服了一体化问题,我们仍然面临着界定重叠项的挑战。对于连续控制,网络不会为每个可能的动作提供单独的输出,这意味着不需要计算重叠的特定动作的上/下限。一种可能性是使用类似![]() 的东西,但由于动作概率与输出均值的距离成比例,我们认为最好简单地使用为连续控制明确设计的Ladv。
的东西,但由于动作概率与输出均值的距离成比例,我们认为最好简单地使用为连续控制明确设计的Ladv。
D Appendix: Discussion on GWC and the metrics used in [17, 18]
以往工作中现有的评价方法并没有直接衡量奖励。例如,[17]使用动作认证率,[18]使用无动作变化的平均可证明区域的大小。这些评估方法主要关注在对抗扰动下不改变智能体的原始动作,这可能是有用的。当大多数动作在攻击下没有改变时,奖励也不太可能改变。然而,这通常是不够的,因为只改变一个早期动作的攻击可能会将智能体推向一个完全不同的轨迹,并产生非常不同的结果。因此,高动作认证率可能不会带来高回报。
为了展示这一点,我们在图3中对GWC、AWC和ACR进行了比较,在第4.4节中进行了更详细的描述。此外,在算法2中提供了AWC的完整描述。

E Appendix: Q-value difference
E.1 Atari results
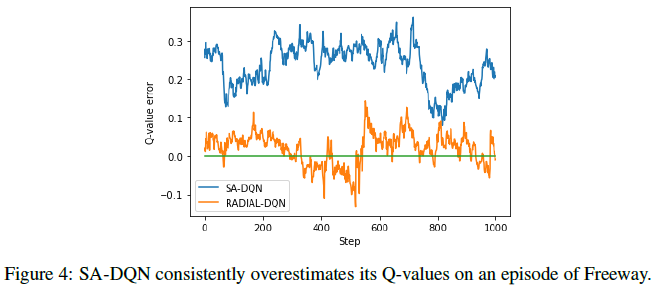
我们的RADIAL-DQN方法#2和SA-DQN之间的主要区别之一是,我们的公式不会导致网络Q值的偏差。这是通过要求两个动作的输出边界之间的间隙为其Q值之间距离的一半来实现的,而SA-DQN要求其为1——当自然Q值相差小于1时,这可能会导致问题。为了实现如此大的间隙,网络需要增加更高的Q值并减少更低的Q值。为了支持我们的论点,图4绘制了SA-DQN和RADIAL-DQN的Q值误差,其定义为(预测Q值) - (理想Q值),理想Q值是该回合其余部分的累积时间折扣奖励。这表明SA-DQN在Q值上确实比我们的有更高的偏差,这是一种不希望的影响,并且可能存在问题。
F Appendix: Alternative Approach 2 loss formulations
F.1 Margin
在公式5中选择裕度的主要思想如下:裕度应该是c·Qdiff,其中0<c<1。如果Margin=Qdiff,则等于边界非常紧的情况(例如,如果ε=0),因此不可能有大于Qdiff的裕度。我们确实注意到,要求裕度c>0很重要,因为我们的c=0实验没有达到所需的鲁棒性。为了简单起见,我们最初使用c=0.5,但没有进行调优,因为它在我们的实验中效果很好。请注意,SA-DQN[38]在与我们的损失函数有些相似的损失函数中使用了恒定裕度要求。当Qdiff小于该裕度时,这会产生不良影响,有关更多讨论,请参阅附录E。
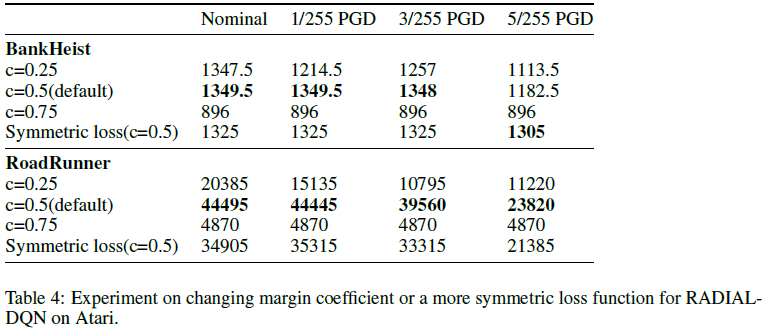
为了理解我们的算法对c的这种选择的敏感性,我们在Roadrunner和BankHeist两个游戏上进行了额外的实验。我们观察到,c的选择确实会影响鲁棒智能体的性能,在一些游戏中(如RoadRunner)会产生显著影响。完整结果见表4。
我们可以看到,c=0.75产生了较差的标准性能,我们认为这是因为这一要求过于严格,并且策略崩溃为一些奖励较低的简单策略。对于c=0.25,由此产生的鲁棒性策略运行良好,并且只比BankHeist中的默认策略的鲁棒性稍差;然而,对于RoadRunner,结果比c=0.5时差得多。
F.2 Symmetric Loss Function
在当前损失函数(公式5)中,如果我们偶然采取具有最低Q值的动作,Ladv项简单地变为零,这可能是不可取的。受审稿人建议的启发,我们进行了以下实验,以设计损失函数公式5的更对称版本,看看它是否可以提高RADIAL-DQN的性能。
新的损失如下:我们在公式5的总和中添加了第二项,当a的Q值低于y时,项翻转为具有相同的正则化,即![]()
![]() 和
和![]() 。那么完整损失就是:
。那么完整损失就是:
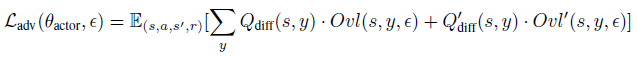
我们在Atari的BankHeist和RoadRunner上测试了这一新损失。对于BankHeist,它的标称性能比我们默认的RADIAL-DQN稍差,但与5/255 PGD相比性能稍好。完整结果总结如下表4。
我们假设,稍差的性能可能是由于在这一新损失中更严格地执行输出之间的差额造成的,如果在某个时候达到错误的Q值,这可能会使策略更难纠正。
G Compounding attack on MuJoCo

H Appendix: Training details
H.1 Atari training details
RADIAL-DQN & RADIAL-A3C. 对于Atari游戏,我们首先在没有经过鲁棒训练的情况下训练标准智能体,然后使用RADIAL训练对模型进行微调。我们发现,这种训练流程通常可以提高训练的有效性,并使智能体能够获得高额的名义奖励。对于DQN,我们使用与[17]相同的架构及其发布的标准(非鲁棒)模型作为微调的起点,以进行公平的比较——这确保了性能的差异是由鲁棒训练过程引起的。对于A3C,我们训练了自己的标准型号。
标准DQN进行6M步的训练,然后进行4.5M步的RADIAL训练。对于RADIAL-DQN训练,我们使用κ=0.8,并在[17]中使用平滑的线性ε计划,在前4M步中将攻击从0增加到1/255。对于A3C,我们首先用标准训练对A3C模型进行20M步的训练,然后进行10M步的RADIAL-A3C训练,这需要与我们的DQN训练类似的计算成本。对于RADIAL-A3C训练,在使用平滑线性时间表的前2/3训练步骤中,从0增加到1/255,其余步骤保持在1/255,我们设置了κ ∈ {0.8, 0.9}。
DQN architechture DQN架构从具有8x8核、步长为4和32个通道的卷积层开始,然后是具有4x4核、步长分别为2和64个通道的卷积层,然后是带有3x3核、步长依次为1和64个通道的卷积层。然后将其压平并馈送到两个单独的512个单位的全连接层中,其中一个连接到1个单位值输出,另一个连接至具有动作空间大小的优势输出。每一层(输出层除外)之后都是非线性ReLU激活。
A3C architechture A3C使用以下架构:两个具有5x5核的卷积层,步长分别为1和32个通道,然后分别是2x2最大池层,然后是一个具有4x4核的卷积层,步长为1和64个通道,之后是2x2的最大池,然后是具有3x3核的卷积层,步长再次为1和4个通道,随后是2x2个最大池。最后,它后面是一个具有512个单元的全连接层,该层连接到两个输出层,一个用于值输出V的1个单元的输出层,该输出层没有激活函数,以及一个策略输出,后面是softmax激活。此外,在每个最大池化层和全连接层之后应用ReLU非线性。
Environment details 我们所有的模型每4帧采取一个动作或步骤,跳过其他帧。网络输入是84x84x1的灰度像素,没有帧堆叠,缩放到0-1之间。所有奖励都在[-1, 1]之间。
Computing infrastructure 模型在不同的环境中进行了训练。对于报告的DQN训练时间,我们使用了一个具有两个AMD Ryzen 9 3900X 12核CPU和一个具有8GB内存的GeForce RTX 2080 GPU的系统。
DQN hyper-parameters 对于所有DQN模型,我们使用了Adam优化器[39],学习率为1.25·10-4和β1=0.9、β2=0.999。我们使用了对偶DQN,回放缓存为2·105,除RoadRunner的0.01外,所有游戏的εexp结束为0.05。每执行8个步骤后,以128的批量大小更新神经网络,每执行2000个步骤更新目标网络。
超参数包括从{6.25·10-5, 1.25·10-4, 2.5·10-4, 5·10-4}中选择的学习率,εexp选自{0.01, 0.02, 0.05, 0.1},批量选自{32, 64, 128, 256},κ选自{0.5, 0.7, 0.8, 0.9, 0.95, 0.98},是根据在Pong训练中表现最好的设置进行选择的,除了RoadRunner的εexp结束之外,其他任务都保持相同。
A3C hyper-parameters A3C模型使用所有16个CPU和4个GPU进行梯度更新训练,其中设置训练运行需要大约4个小时才能进行标准和鲁棒训练。对于所有A3C模型,我们以0.0001的学习率,β1=0.9,β2=0.999使用Amsgrad优化器。我们的β控制熵正则化被设置为0.01,并且优势函数中的k被设置为20。除了RoadRunner使用了κ=0.8之外,我们在所有游戏中都使用了κ=0.9。为了优化,我们分别基于Pong标准和鲁棒训练的表现从{5 · 10-5, 1 · 10-4, 2 · 10-4}中选择了最优学习率和从{0.5, 0.8, 0.9}中选择k。
H.2 Procgen training details
RADIAL-PPO模型是从头开始训练的,首先是2.5M步的标准训练,然后是22.5M步的鲁棒训练。我们尝试像Atari的结果一样微调标准智能体,但发现结果与从头开始的训练相似。我们选择报告从头开始训练的结果,因为它们的总计算成本较低。对于鲁棒训练,我们使用了一个从ε=10-10开始的指数增长ε-时间表,并且在ε=1/255处趋于平稳之前平稳地过渡到线性时间表。关于ε-时间表和超参数的全部细节可以在我们的代码提交中找到。我们对所有模型都使用了常数κ=0.5,因为这个默认值运行良好,我们没有尝试对其进行调整。模型在使用GeForce RTX-2080 GPU或NVIDIA Tesla P100 GPU的服务器上进行训练,在这两种情况下,每个标准智能体大约需要4小时,每个RadialL智能体大约需要8小时。总的来说,我们估计Procgen实验(包括初始调整和测试)的计算成本约为200-300 GPU小时。
H.3 MuJoCo training details
对于MuJoCo环境,我们总共使用4096k个步骤,包括1024k个标准步骤和3072k个对抗步骤。与Procgen的设置类似,指数增长时间表之后是用于鲁棒训练的线性时间表。κ=0.5用于MuJoCo模型。由于MuJoCo智能体的紧凑尺寸,所有计算都在CPU上执行。对于每个训练4096k步的型号,在AMD 3700X CPU上大约需要1.5小时。值得注意的是,RADIAL-PPO基于更快的IBP扰动,在这种环境下,计算时间是基于CROWN-IBP的SA-PPO方法的2/3。
I Additional results
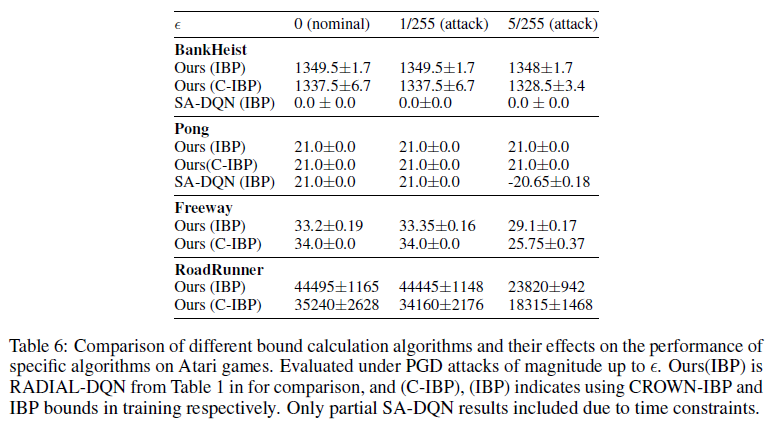
表6比较了界限计算算法对Atari游戏模型性能的影响。我们可以看到,我们的算法在使用更便宜的IBP边界时的表现与在计算成本高昂的CROWN-IBP上的表现类似,而SA-DQN在Pong上仍然使用IBP边界,但在更具挑战性的BankHeist环境中完全失败。
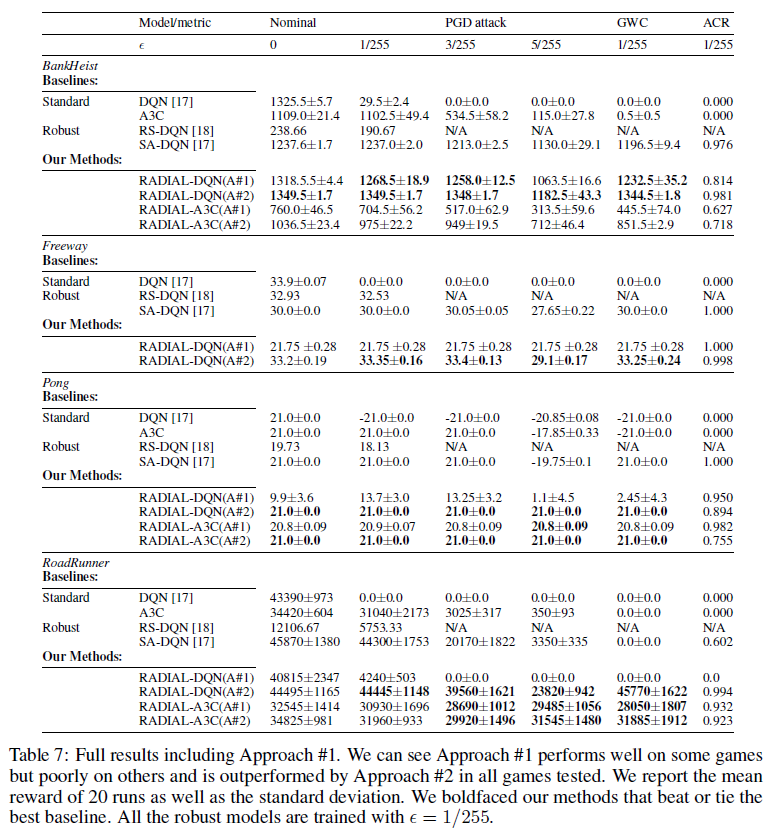
在表7中,我们展示了Atari的结果,包括我们的方法#1。A#1的性能各不相同,但通常比A#2差。表8显示了用随机策略评估相同智能体时的Procgen结果。
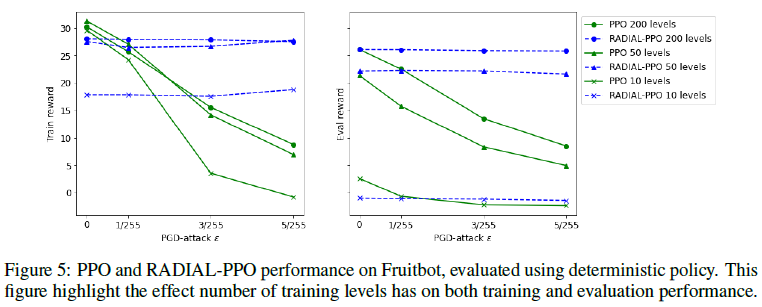
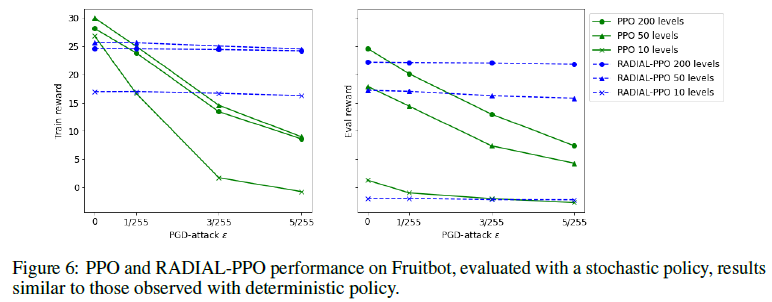
最后,图5和图6显示了训练级别的数量对训练和评估性能的影响。50个级别的训练会产生最佳的训练表现,而数量最多的训练级别(200个)会使评估表现最大化,这不足为奇。RADIAL-PPO在评估集中的标准表现与原始PPO具有竞争力,但只有10个级别的训练除外,这对RADIAL-PAO来说是一个挑战。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号