

Adversarial Robust Deep Reinforcement Learning Requires Redefining Robustness
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published in AAAI 2023
Abstract
通过使用深度神经网络,已经有效地实现了通过与给定环境的交互从原始高维数据中学习。然而,观察到的由沿高灵敏度方向的不可察觉的最坏情况下的依赖于策略的转换(即对抗性扰动)导致的策略性能下降引起了人们对深度强化学习策略鲁棒性的担忧。在我们的论文中,我们表明,这些高灵敏度方向不仅存在于特定的最坏情况方向,而且在深度神经策略领域更为丰富,可以在黑盒环境中通过更自然的方式找到。此外,我们还表明,与通过最先进的对抗性训练技术学习的策略相比,普通训练技术有趣地导致学到更鲁棒的策略。我们相信,我们的工作展示了深度强化学习策略流形的有趣性质,我们的结果有助于构建鲁棒且可推广的深度强化学习策略。
1 Introduction
继Mnih等人(2015)的初步工作之后,在强化学习中使用深度神经网络作为函数逼近器,这使得强化学习策略的能力显著提高(Schulman et al. 2017; Vinyals et al. 2019; Schrittwiser et al. 2020)。特别是,这些发展允许从原始的高维输入(即视觉观察)中直接学习强策略。随着这些新方法的成功,深度强化学习智能体的鲁棒性和泛化能力也面临新的挑战。
最初,Szegedy等人(2014)表明,精心制作的不可察觉的扰动会导致图像分类中的错误分类。在这项初步工作之后,出现了一个新的研究领域,研究深度神经网络对抗专门制作的对抗性样本的能力。虽然各种工作研究了许多不同的方法来计算这些样本(Carlini and Wagner 2017; Madry et al. 2018; Goodfellow, Shelens, and Szegedy 2015; Kurakin, Goodfellow, and Bengio 2016),但一些工作专注于研究如何基于存在这种扰动的训练来提高对这种特制扰动的鲁棒性(Madry et al. 2018; Tramèr et al. 2018; Goodfellow, Shelens, and Szegedy 2015; Xie and Yuille 2020)。
由于图像分类遭受这种对输入中的最坏情况分布偏移的脆弱性,在深度强化学习中进行的一系列工作表明,深度神经策略也容易受到专门设计的不可察觉的扰动的影响(Huang et al. 2017; Kos and Song 2017; Pattanaik et al. 2018; Yen-Chen et al. 2017; Korkmaz 2020; Sun et al. 2020; Korkmaz 2021b)。虽然一条工作线致力于探索深度神经策略中的这些漏洞,但另一条平行的工作线则专注于通过对抗性训练使其变得鲁棒且可靠(Pinto et al. 2017; Mandlekar et al. 2017; Gleave et al. 2020)。
虽然对抗性扰动和对抗性训练为训好的深度神经策略提供了鲁棒性的概念,但在本文中,我们从更广泛的角度来处理深度强化学习的弹性问题,并提出沿高灵敏度方向研究深度神经策略流形。沿着这条线,我们主要寻求以下问题的答案:
- 我们如何在感知相似性范围内,用MDP固有的策略独立的高灵敏度方向来探索深度神经策略决策边界?
- 是否MDP固有的策略独立的高灵敏度方向有可能影响在高维状态表征MDP中训练的最先进的深度强化学习策略性能?
- 当存在策略独立的高灵敏度方向时,与直接的普通训练相比,最先进的认证对抗性训练对策略鲁棒性的影响是什么?
因此,为了能够回答这些问题,在这项工作中,我们专注于深度强化学习策略的鲁棒性概念,并做出了以下贡献:
- 我们通过MDP固有的策略依赖和策略独立的高灵敏度方向来探索深度强化学习流形。
- 我们在具有高维状态表征的各种游戏中的街机学习环境(ALE)中运行了多个实验,并提供了在策略依赖和策略独立的高灵敏度方向下与基础状态的感知相似性之间的关系。
- 我们将策略独立的高灵敏度方向与基于lp-范数变化的最先进的对抗性方向进行了比较,并表明MDP固有的策略独立的高敏感性方向在降低深度强化学习策略的性能方面具有竞争力(使用更小的感知相似距离)。因此,这种对抗性方向和MDP固有的策略独立的高灵敏度方向的对比结果显然表明,在深度强化学习策略流形中存在大量高灵敏度方向。
- 最后,我们在MDP固有的变化下检查了最先进的对抗性训练,并证明与普通训练的模型相比,对抗性训练的模型更容易受到几种不同类型的策略独立的高灵敏度方向的影响。
2 Background and Related Work
2.1 Preliminaries

2.2 Computing Adversarial Directions
Szegedy等人(2014)提出最小化基础图像和对抗性生成的图像之间的距离,以创建对抗性方向。作者使用盒约束L-BFGS来解决这个优化问题。Goodfellow, Shelens和Szegedy (2015)介绍了快速梯度法(FGM),
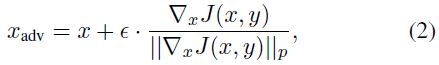
用于通过取用于在输入方向上训练神经网络的代价函数J(x, y)的梯度来制作图像分类中的对抗性样本,其中x是输入,y是输出标签,J(x, y)是代价函数。Carlini和Wagner (2017)在图像分类领域引入了基于对抗性图像和基础图像之间距离最小化的针对性攻击(针对特定标签)。因此,在深度强化学习中,Carlini和Wagner (2017)公式(C&W)将在ε-球![]() 中找出到附近状态的最小距离使得,
中找出到附近状态的最小距离使得,
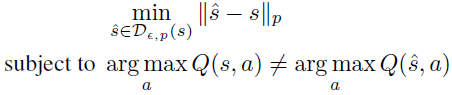
其中s ∈ S表示基础状态,![]() 表示当它沿着对抗性方向移动时的状态。该公式试图最小化到基础状态的距离,该距离被限制为导致由Q网络确定的次优动作的状态。请注意,Carlini和Wagner公式最近被用来证明,最先进的对抗性训练策略与普通训练的深度强化学习策略具有相似甚至在某些情况下相同的对抗性方向(Korkmaz 2022a)。与对抗性攻击相反,在我们提出的威胁模型中,我们不需要任何关于用于训练网络的成本函数、训练的智能体的Q网络或访问访问状态本身的信息。
表示当它沿着对抗性方向移动时的状态。该公式试图最小化到基础状态的距离,该距离被限制为导致由Q网络确定的次优动作的状态。请注意,Carlini和Wagner公式最近被用来证明,最先进的对抗性训练策略与普通训练的深度强化学习策略具有相似甚至在某些情况下相同的对抗性方向(Korkmaz 2022a)。与对抗性攻击相反,在我们提出的威胁模型中,我们不需要任何关于用于训练网络的成本函数、训练的智能体的Q网络或访问访问状态本身的信息。
2.3 Adversarial Approach in Deep Reinforcement Learning
Huang等人(2017)引入的对深度强化学习的第一个对抗性攻击以及Kos和Song (2017)将FGSM从图像分类调整到深度强化学习环境中。随后,Pinto等人(2017)和Gleave等人(2020)专注于将对手和智能体之间的互动建模为零和马尔可夫博弈,而Yen-Chen等人(2017); Sun等人(2020)重点研究了使用Carlini和Wagner对抗性公式计算的扰动攻击智能体的战略时机(即在哪个状态下)。与这一研究方向正交的是,一些研究表明,深度强化学习策略从跨状态、跨MDP和跨算法共享的底层MDP中学习对抗性方向(Korkmaz 2022a)。虽然提出了揭示非鲁棒特征的新技术,但最近的一些研究表明,在最先进的对抗性训练方法中,非鲁棒特征是持续存在的1(Korkmaz 2021b)。
1 参见(Korkmaz 2021a),了解对抗性训练策略学到的状态-动作价值函数的不准确和不一致性。有关反向深度强化学习中鲁棒性问题的更多信息,请参阅(Korkmaz 2022b, c)
2.4 Perceptual Similarity Distance
为高级任务训练的网络的内部激活对应于不同网络架构中的人类感知判断(Krizhevsky, Sutskever, and E.Hinton 2012; Simonyan and Zisserman 2015; Iandola et al. 2016),没有校准(Zhang et al. 2018)。更重要的是,可以通过与人类感知匹配的LPIPS来测量两幅图像之间的感知相似距离。因此,在我们的实验中,我们用LPIPS测量沿着高灵敏度方向从基础状态移动的距离。特别是,![]() 基于网络激活返回s和
基于网络激活返回s和![]() 之间的距离,并产生人类感知的有效近似。更详细地说,LPIPS度量是通过测量神经网络在几个内部层的激活的归一化值之间的l2-距离来给出的。对于每个 l 层,设Wl为宽度,Hl为高度,Cl为通道数。此外,令
之间的距离,并产生人类感知的有效近似。更详细地说,LPIPS度量是通过测量神经网络在几个内部层的激活的归一化值之间的l2-距离来给出的。对于每个 l 层,设Wl为宽度,Hl为高度,Cl为通道数。此外,令![]() 表示卷积层 l 中的激活向量。为了计算两个状态s和
表示卷积层 l 中的激活向量。为了计算两个状态s和![]() 之间的感知相似距离,首先计算通道归一化的内部激活
之间的感知相似距离,首先计算通道归一化的内部激活![]() (分别对应于s和
(分别对应于s和![]() )用于L个内层,并通过相同的固定权重向量
)用于L个内层,并通过相同的固定权重向量![]() 在
在![]() 和
和![]() 中缩放每个通道。最后一步是通过首先在空间维度上对缩放激活之间的l2-距离求平均,然后在L层上求和来计算感知相似距离。
中缩放每个通道。最后一步是通过首先在空间维度上对缩放激活之间的l2-距离求平均,然后在L层上求和来计算感知相似距离。
3 Moving Through the Deep Neural Policy Manifold via High-Sensitivity Directions
为了研究深度神经策略流形,我们将通过对抗性方向和状态表征固有的方向来探索深度强化学习决策边界。如第2.3节所述,对抗性方向是深度神经策略格局中在不可感知范围内特别优化的高灵敏度方向(即最坏情况下的分布偏移),而自然方向代表不可感知距离内状态表征的内在语义变化。

直观地说,如果状态s用![]() 转换会导致执行策略π时期望累积奖励显著下降,则
转换会导致执行策略π时期望累积奖励显著下降,则![]() 是一个高灵敏度的方向函数。请注意,定义3.1中的函数
是一个高灵敏度的方向函数。请注意,定义3.1中的函数![]() 将策略π作为输入,因此能够使用有关处于状态s的行为信息π来计算方向。接下来,我们将介绍定义3.1的限制版本,其中函数不允许使用有关的任何信息。
将策略π作为输入,因此能够使用有关处于状态s的行为信息π来计算方向。接下来,我们将介绍定义3.1的限制版本,其中函数不允许使用有关的任何信息。

为了探索深度强化学习策略格局,我们将利用定义3.1中所述的策略依赖的最坏情况高灵敏度方向(即对抗性扰动),以及定义3.2中所述MDP固有的策略独立的方向。这种探索方法本质上将对抗性方向和策略独立方向并列在一起,即它们与基础状态的感知相似距离(见第2.4节)及其对策略性能的影响程度。更重要的是,我们质疑“lp-范数有界对抗性方向”在感知相似距离方面的不可感知性,并将这种不可感知的概念与MDP固有的策略独立的高灵敏度方向进行比较。MDP固有的策略独立的高灵敏度方向可以在感知相似距离内最终实现类似或更高的期望累积奖励下降,这一事实使专注于对抗性方向的研究受到质疑。更重要的是,如第4节所示,经过训练以抵御这些对抗性方向并声称“认证”鲁棒的策略基本上不如经过简单训练的深度强化学习策略鲁棒,这一事实使训练过程中的内在权衡受到质疑。
虽然可以将最坏情况下策略依赖的高灵敏度方向(即对抗性方向)和策略独立的高敏感性方向的对比结果解释为从安全角度来看非常令人惊讶2,但我们的目标是通过使用对抗性攻击和训练技术来提供精确的基本权衡。事实上,在深度强化学习研究中,在没有明确成本和这些设计选择的权衡的情况下,对最坏情况的方向进行了大量研究,这可能会在影响未来的研究方向上产生偏见。
为了通过策略独立的高灵敏度方向来探索深度神经策略流形,我们专注于在高维状态表征MDP中尽可能简单的内在变化。我们根据频谱对这些变化进行分类,下面我们将精确解释如何计算这些高灵敏度方向。
2 从安全角度来看,在最坏情况下进行的深度强化高灵敏度方向的研究
Low Frequency Policy-Independent High-Sensitivity Directions: 对于低频研究,我们在状态表征中使用了亮度和对比度的变化(Brightness and Contrast change, B&C)。我们一直沿着高灵敏度方向前进,尽可能地与基础状态的线性变换一样简单,
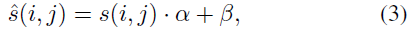
其中s(i, j)是状态s的第ij个像素,α和β是线性亮度参数。状态表征的透视变换(Perspective Transform, PT)包括四个不同的源像素和目标像素之间的映射,给定:
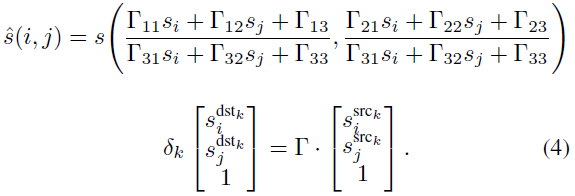
透视变换的范数被定义为正方形的一个角在该映射下移动的最大距离。请注意,透视变换对高频和低频都有影响,如第5节所述。
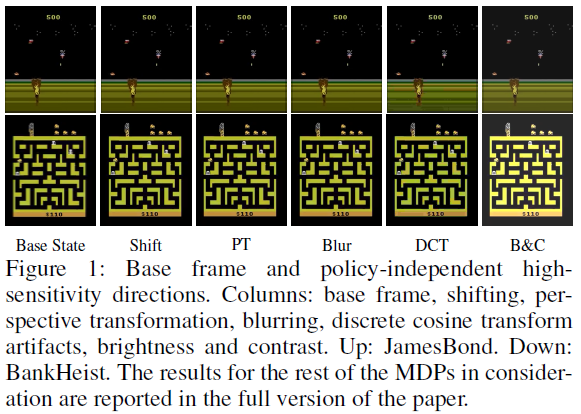

High Frequency Policy-Independent High-Sensitivity Directions: 在高频方面,我们包括了由离散余弦变换(Discrete Cosine Transform, DCT)引起的压缩伪影,导致高频分量的损失,也称为振铃和阻塞伪影。在频谱的高频侧考虑的另一个高灵敏度方向是模糊(Blurring)3。特别是中值模糊(Median Blurring),它是一种非线性噪声去除技术,用其相邻像素的中值代替基础像素值。在这一类别中,核大小k是指在基础像素的k×k邻域上计算中值的事实。导致高频变化的最基本的几何变换之一使状态观测围绕中心像素旋转(Rotation),相应的旋转角度报告为度。最后,在几何变换中,包括移位(Shifting),它在x或y方向上移动输入,移动的像素尽可能少。这用[ti, tj]表示为偏移的距离,其中ti在x方向上,tj在y方向上。
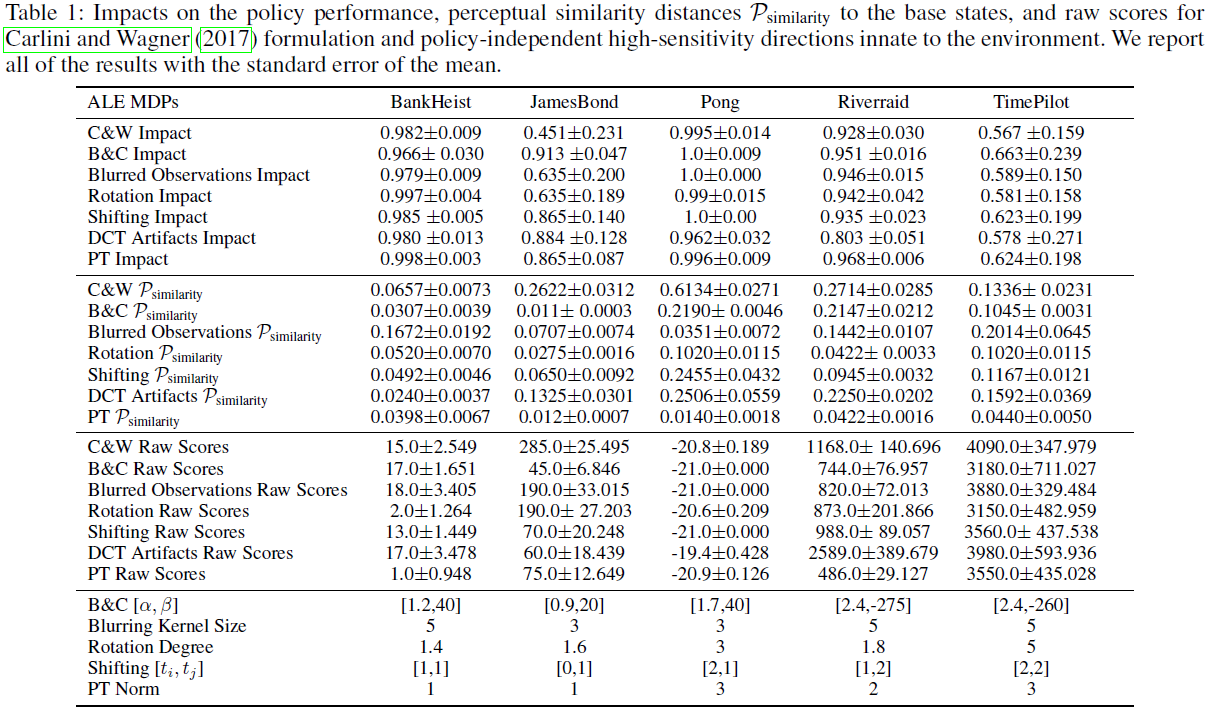
图1展示了沿着上述环境固有的策略独立的高灵敏度方向前进的视觉解释。虽然沿着这些策略独立的方向移动在视觉上是不可察觉的,但我们也在表1中报告了算法1计算的与基础状态的精确感知相似距离。更详细地说,表1显示了策略依赖(即对抗性)和策略独立高灵敏度方向的原始分数、相应的性能下降、与基础状态的感知相似性以及相应的超参数。因此,表1中的结果表明,在相似的感知相似距离内,策略独立的高灵敏度方向导致策略性能的相当或更高的退化。为了计算表1中的结果,使用了第3节中描述的算法1。
4 Moving Along High-Sensitivity Directions in the Adversarially Trained Neural Manifold
在本节中,我们研究了最先进的对抗性训练的深度强化学习策略,该策略具有第3节中描述的策略独立的高灵敏度方向。特别是,我们测试了状态对抗性双深度Q网络,这是一种最先进的算法(Huan et al. 2020)。在这篇文章中,作者提出使用他们所说的状态对抗性MDP来对深度强化学习中的对抗性攻击进行建模。基于这个模型,他们开发了正则化双深度Q网络策略的方法,以证明其对于对抗性攻击是鲁棒的。更详细地说,令B(s)是半径为ε的lp-范数球,这种正则化是通过添加
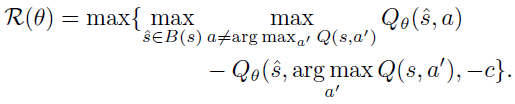
到标准DQN中使用的时序差分损失。特别是,对于形式(s, a, r, s')的样本,损失为:
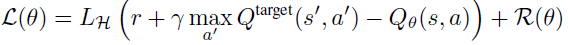
其中LH是Huber损失。此外,我们还测试了最新的对抗性训练技术RADIAL。特别地,RADIAL方法利用区间界传播(Interval Bound Propagation, IBP)来计算范数ε扰动下Q函数的上界和下界。特别地,当状态s被最多为ε的lp-范数扰动时,令Qupper(s, a, ε)和Qlower(s, a, ε)分别是Q函数的上界和下界。对于给定的状态s和动作a,RADIAL方法利用由下式给出的动作-价值差以及重叠:
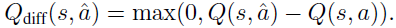
重叠定义为:
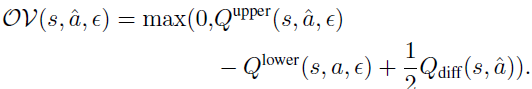
RADIAL中使用的对抗性损失由对一个小批量转换的期望给出:
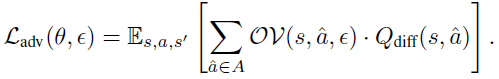
在训练过程中,对抗性损失Ladv(θ, ε)被添加到标准时序差分损失中。请注意,这两种对抗性训练算法SA-DDQN和RADIAL分别出现在NeurIPS 2020和NeurIPS 2021的重点宣讲上。因此,在人工智能安全方面,以及在影响整体研究进展和努力方面,概述这些算法的局限性和实际鲁棒性能力具有重要意义。
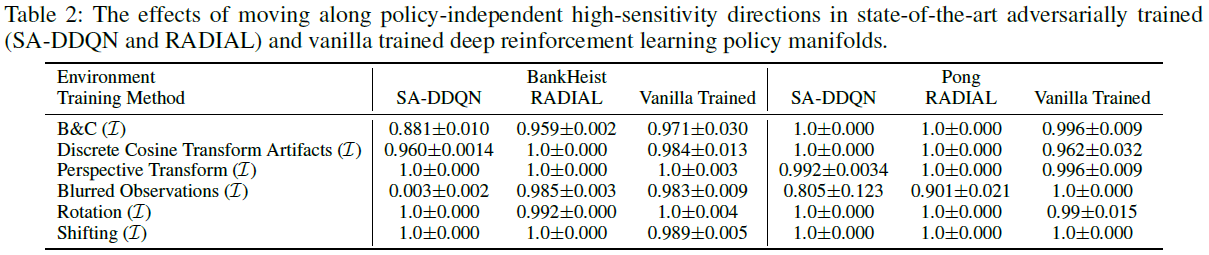
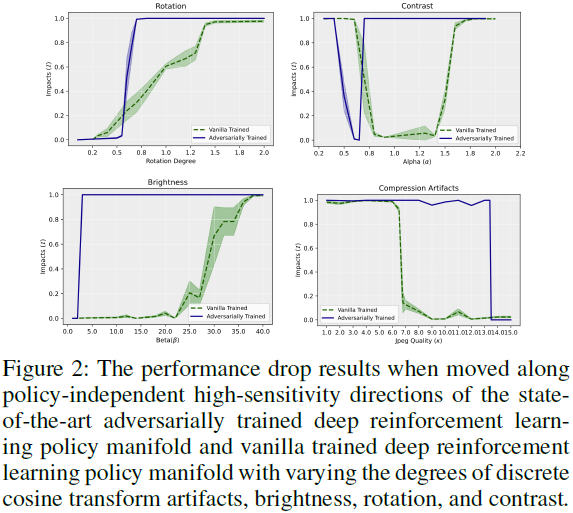
表2报告了在普通训练的深度强化学习策略和最先进的对抗训练(SA-DDQN和RADIAL)的深度强化学习策略中引入策略独立的高灵敏度方向的影响值。注意,为了一致性,表2的超参数与表1中的超参数相同。因此,表2中的结果并没有被专门优化以影响对抗性训练。然而,图2报告了沿策略独立的非鲁棒方向改变移动量的影响,其中α表示对比度,β表示亮度,κ表示离散余弦变换引起的伪影水平。有趣的是,由于高灵敏度方向的这些参数各不相同,图2表明,与最先进的对抗性训练策略相比,简单训练的深度强化学习策略更鲁棒。例如,在3.1到20.0的范围内修改亮度会对对抗性训练的策略造成接近1.0的影响(即策略的完全崩溃),但对普通训练的策略的影响可以忽略不计。
图2中的结果表明,在广泛的参数范围内,对抗性训练的神经策略对MDP固有的自然方向的鲁棒性不如普通训练的策略。尽管对抗性训练的中心目的是提高对不可感知扰动的鲁棒性,而不可感知性是通过lp-范数来衡量的,但这种情况还是会发生。我们的结果表明,对lp-范数有界扰动的鲁棒性的增加可能是以对其他自然类型的难以察觉的高灵敏度方向的鲁棒性损失为代价的。这些结果对使用对抗性训练来创建鲁棒的深度强化学习策略提出了质疑,尤其是使用lp-范数界限作为不可感知性的度量。
对抗性训练不能提供鲁棒性这一事实具有多方面的含义。特别是,从安全的角度来看,制定鲁棒可靠策略的努力被误导了,导致策略实际上不如简单的普通训练那么鲁棒。从一致性的角度来看,虽然对抗性训练旨在针对对抗性方向并使策略安全,但它实际上导致这些策略与人类感知不一致。就对正在制定的策略的基本理解而言,我们的论文对“鲁棒性”一词提出了质疑。“认证鲁棒”对抗性训练方法遇到的对总体分布变化的恢复力下降表明,需要进一步研究如何定义鲁棒性。

5 The Frequency Spectrum of the High-sensitivity Directions
在本节中,我们提供了高维状态表征MDP固有的策略依赖的最坏情况高灵敏度方向和策略独立的高灵敏度方向的频率分析。这项分析的目的是提供定量证据,证明策略独立的高灵敏度方向涵盖了更广泛的范围;因此,与单独依赖于策略的对抗性方向相比,提供了更广泛的鲁棒性视角。特别是,图4和图3中的结果表明,每个方向如何在傅立叶谱中具有明显不同的影响,无论是策略依赖的还是策略独立的。更详细地说,频谱是:
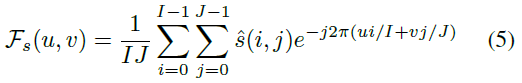
其中![]() 。此外,我们通过测量每种类型的高灵敏度方向在每个空间频率水平上的总傅立叶能量的变化来量化这些影响。
。此外,我们通过测量每种类型的高灵敏度方向在每个空间频率水平上的总傅立叶能量的变化来量化这些影响。
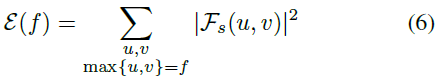
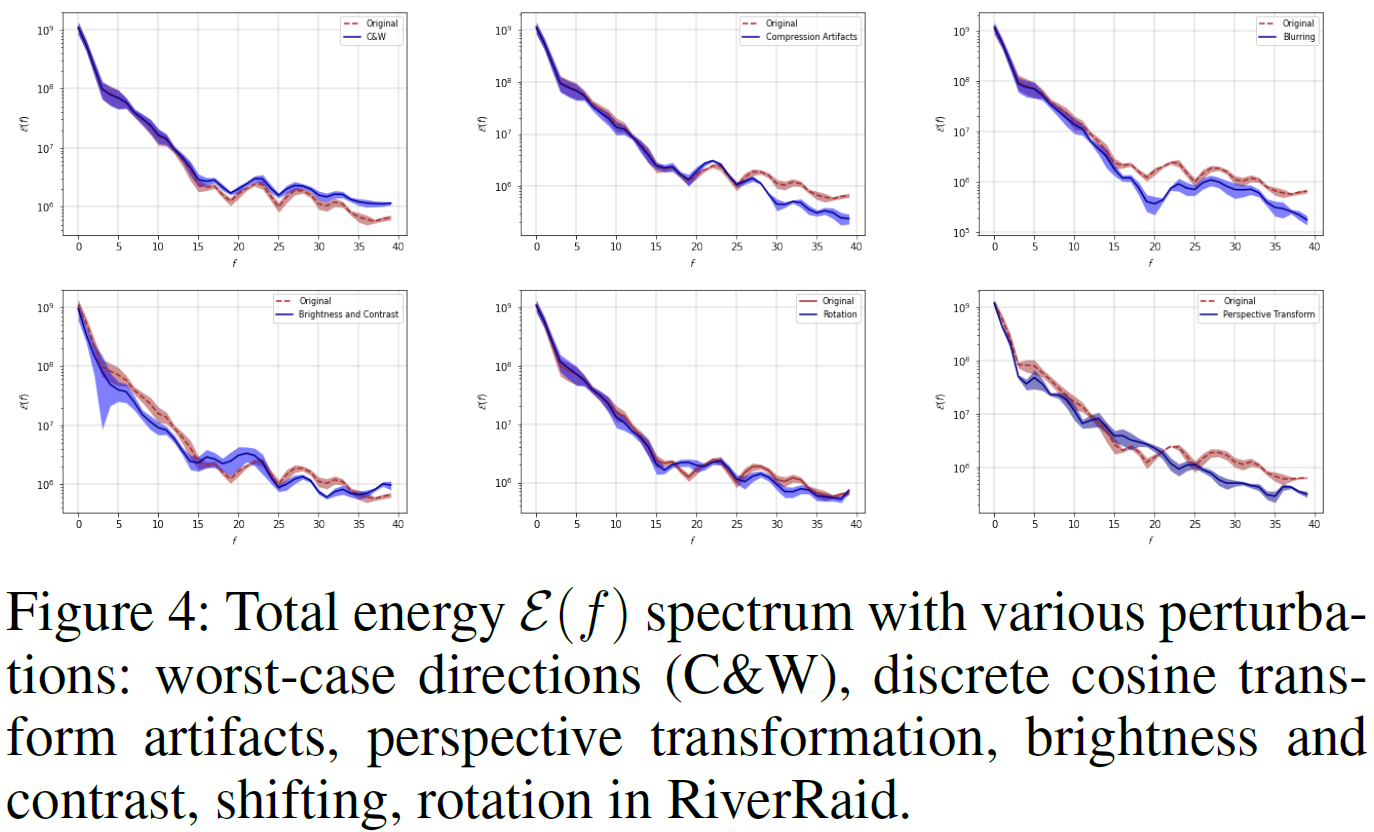
在图3中,我们显示了基础状态s和从基础状态s向高灵敏度方向移动的状态的傅立叶谱,其中既有与策略独立的对抗性方向(Carlini and Wagner 2017),也有MDP固有的高灵敏度方向。在这些光谱中,空间频率的幅度通过从中心向外移动而增加,并且图像的中心表示空间频率为零的傅立叶基函数。为了研究哪种类型的高灵敏度方向占据傅立叶域中的哪个频带,我们计算其最大空间频率为 f 的所有基函数的总能量![]() ,图4显示了与沿着高灵敏度方向偏离基础状态的状态相比,基础状态的功率谱密度,通过算法1计算出策略独立的高灵敏度方向和策略依赖的对抗性方向(Carlini and Wagner 2017)。
,图4显示了与沿着高灵敏度方向偏离基础状态的状态相比,基础状态的功率谱密度,通过算法1计算出策略独立的高灵敏度方向和策略依赖的对抗性方向(Carlini and Wagner 2017)。
除了概述我们的方法外,第5节的目的是解释第4节中获得的结果。特别地,仅专注于建立对高空间频率腐蚀的鲁棒性的训练技术(例如对抗性训练)变得更容易受到不同频谱频带中的腐蚀的影响。图4表明,每个策略独立的高灵敏度方向在频域中占据不同的特定频带。更详细地说,虽然依赖于策略的对抗性方向增加了更高的频率,但离散余弦变换引起的伪影降低了高频带的幅度。沿着这条线,公式(3)中描述的线性变换和公式(4)中描述的透视变换都减小了低频带的幅度。事实上,图4表明,高灵敏度方向确实在频域中捕捉到了更广泛的方向集,这有助于提供更广泛的鲁棒性概念,而不仅仅依赖于更糟糕的相位分布变化。
6 Experimental Details
在我们的实验中,普通训练的深度神经策略是用(Hasselt, Guez, and Silver 2016)提出的具有双Q学习的深度Q网络训练的,具有优先经验重放(Schaul et al. 2016),而对抗训练的深度神经元策略是通过理论上合理的状态对抗MDP建模的状态对抗双深度Q网络(SA-DDQN)训练的,以及RADIAL(见第4节)和Arcade学习环境(Bellemare et al. 2013)的OpenAI Gym包装版本(Brockman et al. 2016)的优先体验回放(Schaul et al. 2016)。注意,所有的实验都是在用高维状态表征训练的策略中进行的。为了能够在不同的算法和不同的游戏之间进行比较,深度强化学习策略的性能退化被定义为对手对智能体的归一化影响:
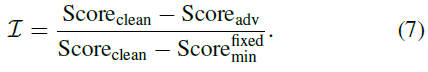
![]() 是游戏的固定最低分数,Scoreadv和Scoreclean分别是在对智能体的观察系统进行任何修改和不进行任何修改的情况下智能体的分数。论文中报告的所有结果都来自10次独立运行。在我们所有的表格和图中,我们包括了平均值的均值和标准差。关于第5节中讨论的问题的更多结果在论文的完整版本中提供,其中包括对策略梯度技术的额外高灵敏度分析、基础状态的可视化以及沿着MDP固有的高灵敏度方向前进。
是游戏的固定最低分数,Scoreadv和Scoreclean分别是在对智能体的观察系统进行任何修改和不进行任何修改的情况下智能体的分数。论文中报告的所有结果都来自10次独立运行。在我们所有的表格和图中,我们包括了平均值的均值和标准差。关于第5节中讨论的问题的更多结果在论文的完整版本中提供,其中包括对策略梯度技术的额外高灵敏度分析、基础状态的可视化以及沿着MDP固有的高灵敏度方向前进。
7 Conclusion
在本文中,我们专注于通过高维状态表征MDP固有的策略依赖的特别优化的最坏情况高灵敏度方向和策略独立的高灵敏度方向来探索深度神经策略决策边界。我们将通过最先进的技术计算的这些最坏情况下的对抗性方向与街机学习环境(ALE)中策略独立的根深蒂固的方向进行了比较。我们质疑“lp-范数有界对抗性方向”的不可感知性概念,并证明与对抗性方向相比,具有最小根深蒂固高灵敏度方向的状态在感知上更类似于基础状态。此外,我们证明了策略独立的高灵敏度方向在不访问策略训练细节、实时访问策略的记忆和感知系统的情况下,以较低的感知相似距离对策略性能产生更高的影响,并且计算同时扰动的计算要求高的对抗性公式证明了高灵敏度方向在深度强化学习策略流形中自然丰富。最重要的是,我们表明,与普通训练的深度神经策略相比,为解决深度强化学习中的鲁棒性问题而提出的最先进的方法更为脆弱。我们认为,从鲁棒性在未来研究方向上造成的偏见来看,对鲁棒性的解释具有重要意义。此外,虽然我们强调了在更多样化的范围内研究训练好的深度神经策略的鲁棒性的重要性,但我们相信,我们的研究可以为理解深度强化学习决策边界的有趣属性提供基础,并有助于构建更鲁棒和可推广的深度神经策略。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号