A Tandem Learning Rule for Effective Training and Rapid Inference of Deep Spiking Neural Networks
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS, VOL. 34, NO. 1, JANUARY 2023
Abstract
脉冲神经网络(SNN)代表了神经形态计算(NC)架构中最突出的生物启发计算模型。然而,由于脉冲神经元函数的不可微分性质,标准误差反向传播算法不直接适用于SNN。在这项工作中,我们提出了一个串联学习框架,该框架由SNN和通过权重共享耦合的人工神经网络(ANN)组成。ANN是一种辅助结构,有助于在脉冲序列水平上训练SNN的误差反向传播。为此,我们将脉冲计数作为SNN中的离散神经表征,并设计了一个ANN神经元激活函数,该函数可以有效地近似耦合SNN的脉冲计数。所提出的串联学习规则在传统的基于帧和基于事件的视觉数据集上展示了竞争性的模式识别和回归能力,与其他最先进的SNN实现相比,推理时间和总突触操作至少减少了一个数量级。因此,所提出的串联学习规则为在低计算资源下训练高效、低延迟和高精度的深度SNN提供了一种新的解决方案。
I. INTRODUCTION
深度学习在计算机视觉[1]、语音处理[2]、语言理解[3]等领域大大提高了模式识别性能。然而,深度人工神经网络(ANN)计算量大,内存效率低,因此限制了其在计算预算有限的移动和可穿戴设备中的部署。这促使我们寻找节能解决方案。
人类大脑经过数百万年的进化,在执行复杂的感知和认知任务方面效率极高。尽管分层组织的深层ANN是受大脑启发的,但它们在许多方面与生物大脑有显著不同。从根本上讲,信息是通过大脑中的异步动作电位或脉冲来表示和传达的。为了高效、快速地处理这些脉冲序列所携带的信息,生物神经系统发展了事件驱动的计算策略,从而使能量消耗与感官刺激的活动水平相匹配。
神经形态计算(NC)作为一种新兴的非冯·诺依曼计算范式,旨在利用硅中的脉冲神经网络(SNN)模拟这种异步事件驱动的信息处理[4]。新颖的NC架构(例如TrueNorth[5]和Loihi[6])利用低功耗、密集连接的并行计算单元来支持基于脉冲的计算。此外,托管内存和计算可以有效缓解CPU和内存之间的低带宽问题(即冯·诺伊曼瓶颈)[7]。当在这些神经形态架构上实现时,深度SNN显示出令人信服的能量效率和低延迟[8]。
尽管NC架构提供了有吸引力的节能,但如何训练能够在这些NC架构上高效运行的大规模SNN仍然是一个具有挑战性的研究课题。脉冲神经元表现出丰富的动态行为库[9],如相位脉冲、突发和脉冲频率适应,这显著增加了简化ANN的建模复杂性。此外,由于SNN内突触操作的异步和不连续性质,通常用于ANN训练的误差反向传播算法不直接适用于SNN。
多年来,受神经科学和机器学习研究的启发,越来越多的神经可塑性或学习方法被提出用于SNN[10][11]。生物学上看似合理的Hebbian学习规则[12]和脉冲依赖可塑性(STDP)[13]是计算神经科学研究中有趣的局部学习规则,对新兴非易失性存储设备的硬件实现也很有吸引力[14]。尽管它们最近在小规模图像识别任务上取得了成功[15][16],但由于任务特定信用分配无效和耗时的超参数调整,它们不能直接用于大规模机器学习任务。
最近的研究[17]–[19]表明,将预训练的ANN转换为SNN是可行的,对分类精度几乎没有不利影响。这种间接训练方法假设模拟神经元的激活值等于脉冲神经元的平均方法率,并且只需要解析和归一化训练的ANN的权重。Rueckauer等人[18]对这种方法的性能偏差进行了理论分析,并对用于目标识别任务的卷积神经网络(CNN)模型进行了系统研究。这种转换方法在许多传统的基于帧的视觉数据集上实现了SNN的最佳报告结果,包括具有挑战性的ImageNet-12数据集[18][19]。然而,这种通用转换方法带来了对推理速度和分类精度有影响的折衷,并且需要至少几百个推理时间步骤才能达到最佳分类精度。
其他研究工作还致力于训练约束的ANN,该ANN可以近似SNN的属性[20][21],从而允许将训练好的模型无缝地传输到目标硬件平台。基于基于发放率的脉冲神经元模型,这种先约束后训练的方法将脉冲神经元的稳态发放率转换为连续可微分的形式,可以使用传统的误差反向传播算法进行优化。通过在训练过程中显式逼近SNN的属性,当在目标神经形态硬件上实现时,该方法的性能优于上述通用转换方法。
虽然通用ANN到SNN转换和约束后训练方法都显示了竞争性分类精度,但基于发放率的脉冲神经元模型的基本假设需要长的编码时间窗口(即,图像或样本呈现的时间步长)或高的发放率以达到稳定的神经元发放状态[18][20],从而可以消除预训练的ANN和SNN之间的近似误差。这种稳态要求限制了可以从NC架构获得的计算优势,并且仍然是将这些方法应用于实时模式识别任务的主要障碍。
为了提高整体能量效率和推理速度,理想的SNN学习规则应该支持具有稀疏突触活动的短编码时间窗口。为了利用这一理想特性,已经研究了时间编码,其中第一个脉冲的脉冲时间被用作可微替代,以启用误差反向传播算法[22]–[24]。尽管在MNIST数据集上取得了竞争性的结果,但时间学习规则如何保持神经元发放的稳定性,从而确定衍生物,以及如何将其放大到最先进的深度神经网络的大小,仍然是一个谜。鉴于基于发放率的SNN的稳态需求和基于时间的SNN可扩展性问题,有必要开发新的学习方法,该方法可以有效地训练深度SNN,使其在短编码时间窗口下操作,同时具有稀疏的突触活动。
替代梯度学习[25]最近已成为深度SNN的替代训练方法。利用离散时间公式,脉冲神经元可以被有效地建模为非脉冲循环神经网络(RNN),其中脉冲神经元模型中的泄漏项被公式化为固定权重的自循环连接。通过建立与RNN的等价关系,可以将经典误差穿越时间反向传播(BPTT)算法应用于训练深度SNN。在误差反向传播期间,可以用连续函数代替不可微分脉冲生成函数,由此可以基于每个时间步骤处的瞬时膜电位导出替代梯度。在实践中,替代梯度学习对于静态和时间模式识别任务都表现得非常好[26]–[29]。通过消除基于发放率的SNN的稳态发放率和基于时间的SNN脉冲时序依赖性的约束,替代梯度学习支持SNN的快速高效模式识别。
尽管使用替代梯度学习在MNIST和CIFAR-10[30]数据集上报告了具有竞争性的准确性,但使用BPTT训练深度SNN的存储和计算效率低下,尤其是对于更复杂的数据集和网络结构。此外,对于普通RNN来说众所周知的梯度消失问题[31]可能会对具有长时间持续时间的脉冲模式的学习性能产生不利影响。在本文中,为了提高替代梯度学习的学习效率,我们提出了一种新的串联神经网络学习规则。如图1所示,串联网络架构由SNN和ANN组成,它们通过权重共享分层耦合。ANN是一种辅助结构,有助于在脉冲训练水平上训练SNN的误差反向传播,而SNN用于导出精确的脉冲神经表征。如广泛的实验研究所证明的,这种串联学习规则允许使用SNN进行快速、高效和可扩展的模式识别。
本文的其余部分组织如下。在第二节中,我们制定了所提出的串联学习框架。在第三节中,我们通过与其他SNN实现进行比较,在传统的基于帧的视觉数据集(即MNIST、CIFAR-10和ImageNet-12)和基于事件的视觉数据集中(即N-MNIST和DVSCIFAR10)评估了所提出的串联学习框架。最后,我们在第四节中进行了讨论。
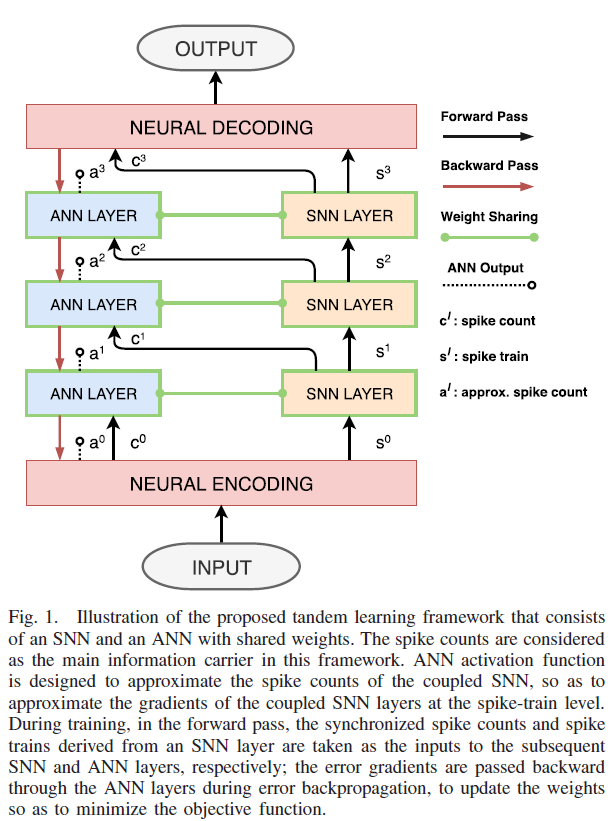
II. LEARNING THROUGH A TANDEM NETWORK
在本节中,我们首先介绍本工作中使用的脉冲神经元模型。然后,我们提出了一种使用脉冲计数作为跨网络层的信息载体的离散神经表征方案,并设计了ANN激活函数,以有效地近似耦合SNN的脉冲计数,用于脉冲序列级的误差反向传播。最后,我们介绍了串联网络及其学习规则,称为串联学习规则,用于深度SNN训练。
A. Neuron Model
脉冲神经元模型描述了大脑中生物神经元的丰富动态行为[32]。一般来说,脉冲神经元模型的计算复杂性随着生物合理性的水平而增加。因此,为了在有效的神经形态硬件上实现,可以提供足够水平的生物细节的简单但有效的脉冲神经元模型是优选的。
在这项工作中,我们使用了可以有效描述具有脉冲计数的感觉信息的最简单的脉冲神经元模型:基于电流的IF神经元[18]和LIF神经元模型[32]。虽然IF和LIF神经元不能模拟生物神经元丰富的脉冲活动频谱,但它们非常适合处理以脉冲发放率或一致脉冲模式编码信息的感觉输入。
层 l 处LIF神经元 i 的亚阈值膜电位![]() 可以通过以下线性微分方程描述:
可以通过以下线性微分方程描述:
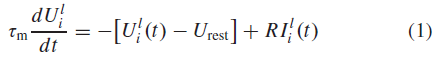
其中τm是膜时间常数。Urest和R分别是脉冲神经元的静息电位和膜电阻。![]() 是指神经元 i 的时序依赖输入电流。通过去除LIF神经元中涉及的膜电位泄漏效应,IF神经元的亚阈值动力学可以描述如下:
是指神经元 i 的时序依赖输入电流。通过去除LIF神经元中涉及的膜电位泄漏效应,IF神经元的亚阈值动力学可以描述如下:

在不失通用性的情况下,我们在这项工作中将静息电位Urest设置为零,将膜电阻R设置为单位大小。每当![]() 超过发放阈值ϑ时,就会产生输出脉冲:
超过发放阈值ϑ时,就会产生输出脉冲:

其中![]() 指示在时间步骤 t 处神经元 i 的输出脉冲的发生。
指示在时间步骤 t 处神经元 i 的输出脉冲的发生。
在实践中,给定小的模拟时间步长dt,LIF神经元的线性微分方程可以通过以下离散时间公式很好地近似:

其中:
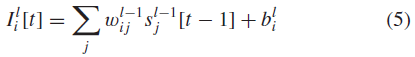
其中α ≡ exp(−dt / τm)。上述公式中使用方括号来反映离散时间建模。![]() 总结了前一层突触前神经元的突触电流贡献。
总结了前一层突触前神经元的突触电流贡献。![]() 表示来自l−1层传入神经元 j 的突触连接强度,
表示来自l−1层传入神经元 j 的突触连接强度,![]() 表示神经元 i 的恒定注入电流。如(4)的最后一项所示,不是在每次脉冲产生后将膜电位重置为零,而是从膜电位中减去发放阈值。这有效地保留了超过发放阈值增加的剩余膜电位,并减少了跨层的信息损失[18]。类似地,IF神经元的离散时间公式可以表示如下:
表示神经元 i 的恒定注入电流。如(4)的最后一项所示,不是在每次脉冲产生后将膜电位重置为零,而是从膜电位中减去发放阈值。这有效地保留了超过发放阈值增加的剩余膜电位,并减少了跨层的信息损失[18]。类似地,IF神经元的离散时间公式可以表示如下:

在我们的实验中,对于IF和LIF神经元,在处理每个新的输入示例之前,将![]() 重置并初始化为零。我们将脉冲神经元产生的脉冲总数(即脉冲计数)视为主要信息载体。对于层 l 的神经元 i,可以通过对编码时间窗口T上的所有输出脉冲求和来确定脉冲计数
重置并初始化为零。我们将脉冲神经元产生的脉冲总数(即脉冲计数)视为主要信息载体。对于层 l 的神经元 i,可以通过对编码时间窗口T上的所有输出脉冲求和来确定脉冲计数![]() :
:

在这项工作中,我们使用非脉冲模拟神经元的激活值来近似脉冲神经元的脉冲计数。模拟神经元 i 进行的转换可以描述为:

其中![]() 和
和![]() 分别是模拟神经元的权重和偏置项。
分别是模拟神经元的权重和偏置项。![]() 和
和![]() 对应于模拟输入和输出激活值。f(·)表示模拟神经元的激活函数。使用模拟神经元的脉冲计数近似的细节将在第II-C节中解释。
对应于模拟输入和输出激活值。f(·)表示模拟神经元的激活函数。使用模拟神经元的脉冲计数近似的细节将在第II-C节中解释。
B. Encoding and Decoding Schemes
SNN处理表示为脉冲序列的输入,理想情况下,这些输入应由基于事件的传感器生成,例如,硅视网膜事件摄像机[33]和硅耳蜗音频传感器[34]。然而,与基于帧的传感器相比,从这些事件驱动传感器收集的数据集并不充分可用。为了将基于帧的传感器数据作为输入,SNN将需要额外的神经编码机制来将实值样本转换为脉冲序列。
通常,通常考虑两种神经编码方案:发放率码和时间码。发放率码[17][18]在泊松或伯努利分布之后的每个采样时间步骤将实值输入转换为脉冲序列。然而,它受到采样误差的影响,因此需要长的编码时间窗口来补偿这种误差。因此,发放率码不是将信息编码到我们期望的短时间窗口中的最佳方法。另一方面,时间编码使用单个脉冲的时间来编码信息;实例包括第一次脉冲的时间[22]、相位码[32]等。因此,它具有优越的编码效率和计算优势。然而,解码复杂且对噪声敏感[32]。此外,在神经形态芯片上实现对时间编码至关重要的高时间分辨率也是一项挑战。
或者,我们将实值输入作为与时间相关的输入电流,并在每个时间步长直接应用于(4)和(6)中。这种神经编码方案克服了发放率码的采样误差;因此,它可以支持准确和快速的推断,如早期的工作[28][35]所示。如图1所示,从该神经编码层开始,脉冲序列和脉冲计数分别作为SNN和ANN层的输入。
为了便于模式分类,需要SNN后端将输出脉冲序列解码为模式类。对于解码,可以使用在编码时间窗口T上累积的离散脉冲计数或连续自由聚集膜电位(无脉冲)![]() 对SNN输出层进行解码:
对SNN输出层进行解码:

在我们的初步研究中,如图2所示,我们观察到自由聚集膜电位提供了更平滑的学习曲线,因为它允许在输出层导出连续的误差梯度。此外,自由聚集膜电位可以直接用作回归任务的输出。因此,除非另有说明,我们在这项工作中使用自由聚集膜电位进行神经解码。
C. Spike Count as a Discrete Neural Representation
深度ANN学习用紧凑的潜在表征来描述输入数据。典型的潜在表征形式是连续或离散值向量。尽管大多数研究都集中于连续的潜在表征,但离散表征在解决现实世界问题方面具有独特的优势[36]–[40]。例如,它们可能更自然地适合表示自然语言,自然语言本质上是离散的,也是逻辑推理和预测学习的原生语言。此外,离散神经表征的思想也被用于网络量化[41][42],其中网络权重、激活值和梯度被量化,用于有效的神经网络训练和推理。
在这项工作中,我们将脉冲计数视为深度SNN中的离散潜在表征,并设计ANN激活函数来近似耦合SNN的脉冲计数,从而可以从ANN层有效地导出脉冲序列级替代梯度。利用这种离散的潜在表征,SNN层的有效非线性变换可以表示为:
![]()
其中g(·)表示脉冲神经元进行的有效神经转换。鉴于脉冲生成的状态依赖性,直接确定sl−1到![]() 的解析表达式是不可行的。为了避免这个问题,我们通过假设sl−1产生的突触电流随时间均匀分布来简化脉冲生成过程。通过在整个时间窗口内重复输入相同的输入来实现该假设。它还间接地确保到后续层的输入电流的稳定性。此外,尽管到后续层的输入脉冲序列具有随机性,但CNN内的脉冲神经元通常具有可以补偿这种输入电流可变性的高扇入连接。第三,通过将膜时间常数τm适当设置为适当大的数值,使其与模拟持续时间相比具有相对大的积分时间窗口(因此,在模拟的时间过程中近似IF神经元),脉冲神经元的发放率可以快速适应和稳定。这在每个时间步骤产生恒定的突触电流
的解析表达式是不可行的。为了避免这个问题,我们通过假设sl−1产生的突触电流随时间均匀分布来简化脉冲生成过程。通过在整个时间窗口内重复输入相同的输入来实现该假设。它还间接地确保到后续层的输入电流的稳定性。此外,尽管到后续层的输入脉冲序列具有随机性,但CNN内的脉冲神经元通常具有可以补偿这种输入电流可变性的高扇入连接。第三,通过将膜时间常数τm适当设置为适当大的数值,使其与模拟持续时间相比具有相对大的积分时间窗口(因此,在模拟的时间过程中近似IF神经元),脉冲神经元的发放率可以快速适应和稳定。这在每个时间步骤产生恒定的突触电流![]() :
:

因此,将恒定的突触电流![]() 代入(2),我们得到IF神经元的脉冲间隔期的以下表达式:
代入(2),我们得到IF神经元的脉冲间隔期的以下表达式:

其中ρ(·)表示整流线性单元(ReLU)的非线性变换。如前一节所述,在本工作中,假定膜电阻R为单位大小,因此略去。输出脉冲计数可进一步近似如下:

通过将![]() 设置为1,(13)采用与模拟神经元的激活函数相同的形式,如(8)所述。具体而言,通过将ρ(·)设置为模拟神经元的激活函数[参见f(·)],将脉冲计数
设置为1,(13)采用与模拟神经元的激活函数相同的形式,如(8)所述。具体而言,通过将ρ(·)设置为模拟神经元的激活函数[参见f(·)],将脉冲计数![]() 设置为输入(参见
设置为输入(参见![]() ),将聚集的恒定注入电流
),将聚集的恒定注入电流![]() 设置为相应模拟神经元的偏置项(参见
设置为相应模拟神经元的偏置项(参见![]() ),该配置允许从耦合的权重共享ANN层来近似脉冲计数并因此近似脉冲序列水平误差梯度。如图3所示,很明显,所提出的ANN激活函数可以有效地近似图像分类任务中耦合SNN层的精确脉冲计数。近似误差可以被视为随机噪声,其被证明可以提高训练神经网络的可推广性[43]。
),该配置允许从耦合的权重共享ANN层来近似脉冲计数并因此近似脉冲序列水平误差梯度。如图3所示,很明显,所提出的ANN激活函数可以有效地近似图像分类任务中耦合SNN层的精确脉冲计数。近似误差可以被视为随机噪声,其被证明可以提高训练神经网络的可推广性[43]。
根据IF神经元的相同近似机制,还可以考虑将(11)中确定的恒定电流注入LIF神经元,通过计算神经元从静息电位上升到发放阈值的充电周期,可以从(1)中确定间隔时间(更多细节见补充材料)。因此,我们得到:
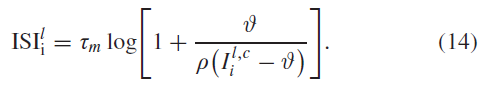
因此,近似脉冲计数可评估为:
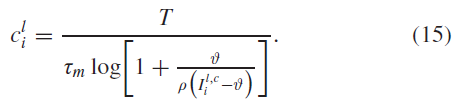
然而,当![]() 时,上述公式是未定义的,并且当
时,上述公式是未定义的,并且当![]() 略微大于零时,上述公式在数值上也是不稳定的。为了解决这个问题,我们将ReLU激活函数ρ(·)替换为平滑的替代函数ρs(·),其定义如下:
略微大于零时,上述公式在数值上也是不稳定的。为了解决这个问题,我们将ReLU激活函数ρ(·)替换为平滑的替代函数ρs(·),其定义如下:
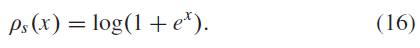
与IF神经元相同,通过将脉冲计数![]() 和聚集的恒定注入电流
和聚集的恒定注入电流![]() 作为模拟神经元的输入,以(15)作为激活函数,LIF神经元的脉冲计数可以通过耦合的模拟神经元很好地近似。使用脉冲计数的离散神经表征及其与权重共享模拟神经元的近似,允许在脉冲序列水平近似替代梯度,并在误差反向传播期间应用。因此,它具有优于在每个时间步骤执行权重更新的其他替代梯度方法[25][27][28]的学习效率。
作为模拟神经元的输入,以(15)作为激活函数,LIF神经元的脉冲计数可以通过耦合的模拟神经元很好地近似。使用脉冲计数的离散神经表征及其与权重共享模拟神经元的近似,允许在脉冲序列水平近似替代梯度,并在误差反向传播期间应用。因此,它具有优于在每个时间步骤执行权重更新的其他替代梯度方法[25][27][28]的学习效率。

D. Credit Assignment in the Tandem Network
由于定制的ANN激活函数可以有效地逼近脉冲神经元的离散神经表征,这促使我们思考是否可以直接训练受约束的ANN,然后将其权重转移到等效SNN,即先约束后训练方法[20][21]。这样,深度SNN的训练可以通过深度ANN来实现,并且可以利用为ANN开发的大量工具和方法。
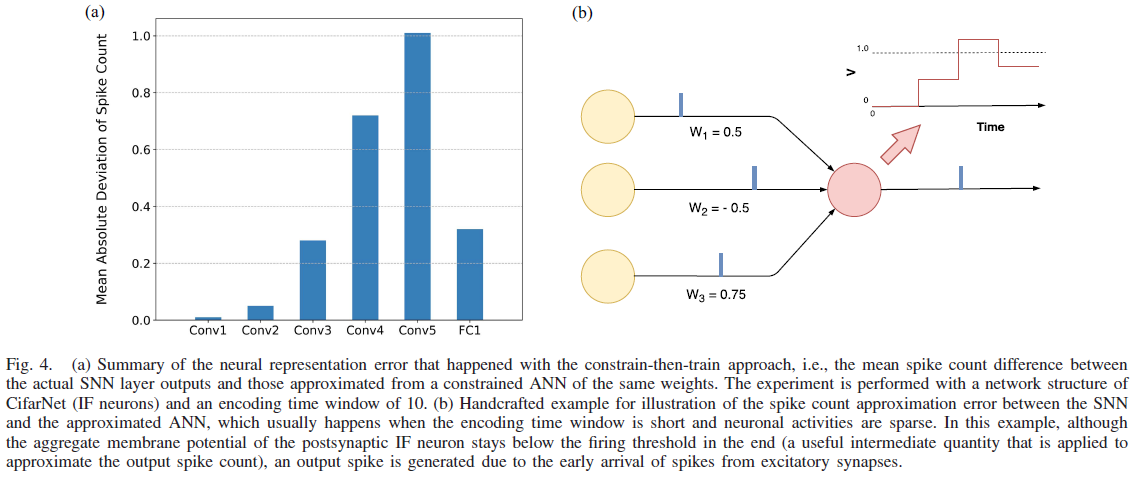
我们将(13)作为约束ANN的激活函数,然后将训练的权重传递给具有IF神经元的SNN。所得网络在MNIST数据集上报告了具有竞争力的分类精度[21]。然而,当将该方法应用于时间窗口为10的更复杂的CIFAR-10数据集时,SNN的分类精度与预训练的ANN相比出现了较大的下降(在我们的实验中约为21%)。通过仔细比较ANN近似的“脉冲计数”与实际SNN脉冲计数,我们观察到ANN和SNN的相同层之间的脉冲计数差异增加,如图4(a)所示。这是由于来自ANN层的近似仅提供输出脉冲计数的平均估计,这忽略了输入脉冲序列的时间结构。因此,它可能会导致实际输出脉冲计数的差异。当脉冲计数穿过层时,差异增大。虽然对于用于MNIST数据集分类的浅层网络[21]或具有非常长的编码时间窗口[20],这种脉冲计数差异可以忽略不计,但面对稀疏的突触活动和短的时间窗口,它具有巨大的影响。
为了证明这种近似误差在信息前向传播过程中是如何发生的,即神经表示误差,我们手工制作了一个示例,如图4(b)所示。尽管IF神经元在编码时间窗口结束时的自由聚集膜电位保持在发放阈值以下,但由于兴奋性突触的脉冲提前到达,可能会产生输出脉冲。值得一提的是,如图3和图4(a)所示,在单层上可以很好地控制脉冲计数差异(第一层的差异很小)。然而,这种神经表示误差将在各个层之间累积,并显著影响SNN的分类精度(权重从经过训练的ANN传递)。因此,为了有效地训练具有短编码时间窗口和稀疏突触活动的深度SNN,有必要在训练环中导出具有SNN的精确神经表征。
为了解决这个问题,我们提出了一个串联学习框架。如图1所示,使用具有(13)和(15)中定义的激活函数的ANN来实现通过ANN层的误差反向传播,而使用与耦合的ANN共享权重的SNN来确定精确的神经表征(即脉冲计数和脉冲序列)。从SNN层确定的同步脉冲计数和脉冲序列分别传输到后续的ANN和SNN层。值得一提的是,在前向传递中,ANN层将前一SNN层的输出作为输入。这旨在通过交错层使SNN的输入与ANN同步,而不是试图优化ANN的分类性能。
通过在串联网络的训练期间结合脉冲神经元的动态,准确的输出脉冲计数而不是ANN预测的脉冲计数被前向传播到后续的ANN层。所提出的串联学习框架可以有效地防止神经表示误差跨层向前累积。当使用耦合ANN进行误差反向传播时,前向推理在训练后完全在SNN上执行。所提出的串联学习规则的伪码在算法1中给出。

III. EXPERIMENTAL EVALUATION AND DISCUSSION
在本节中,我们首先评估了所提出的串联学习框架在基于帧的对象识别和图像重建任务中的学习能力。我们进一步讨论了为什么可以在串联网络中执行有效的学习。然后,我们评估串联学习规则对由事件驱动的相机传感器生成的异步输入的适用性。最后,我们讨论了使用所提出的串联学习规则可以实现的高学习效率和可扩展性、快速推理和减少突触操作的财产。
A. Experimental Setups
1) Datasets: 为了对所提出的串联学习规则进行全面评估,我们使用了三个传统的基于帧的图像数据集:MNIST、CIFAR-10 [30]和ImageNet-12 [44]。此外,我们还研究了串联学习对事件驱动视觉数据集的适用性:N-MNIST [45]和DVS-CIFR10 [46]。遵循[28]中采用的相同数据预处理程序,我们通过累积N-MNIST和DVS-CIFR10数据集每10ms间隔内出现的脉冲来降低时间分辨率。补充材料中提供了有关实验数据集的更多细节。
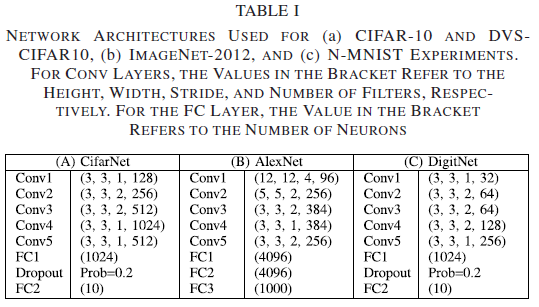
2) Network and Training Configurations: 如表1所示,我们在基于帧的CIFAR-10和基于事件的DVS-CIFR10数据集(即CifarNet)上使用具有七个可学习层的CNN进行目标识别。为了处理DVS-CIFAR10的较高输入维度,我们将第一层的每个卷积层的步长增加到2,核大小增加到7。由于SNN离散时间建模的高计算成本和大存储需求,我们使用AlexNet [1]在大规模ImageNet-12数据集上进行目标识别。对于N-MNIST数据集上的目标识别,我们设计了一个称为DigitNet的七层CNN。对于MNIST数据集上的图像重建任务,我们评估了具有784-256-128-64-128-256-784架构的脉冲自编码器,其中数字是指每层神经元的数量。
3) Implementation Details: 为了减少对权重初始化的依赖性并加速训练过程,我们在每个卷积和全连接层之后添加了一个批归一化层。假设批处理归一化层仅执行仿射变换,我们遵循[18]中介绍的方法,并在将其应用于耦合SNN层之前将其参数集成到前一层的权重中。我们用两个卷积运算的步骤替换了ANN到SNN转换工作中常用的平均池化运算,这不仅以可学习的方式执行维数降低,还降低了计算成本和延迟[47]。对于具有IF神经元的SNN,我们将发放阈值设置为1。对于具有LIF神经元的SNN,我们将发放阈值设置为0.1,膜时间常数τm设置为20个时间步骤。
我们使用Pytorch[48]进行了所有实验,除了在ImageNet-12数据集上的实验,我们使用Tensorpack工具箱[49]。我们遵循Tensorpack中用于ImageNet-12目标识别任务的相同数据预处理程序(裁剪、翻转、均值归一化等)、优化器和学习率衰减计划。对于CIFAR-10数据集,我们遵循与[28]中相同的数据预处理和训练配置。Pytorch源代码可以在这里找到,1和更多的实现细节可以在补充材料中找到。
4) Evaluation Metrics: 对于基于帧和基于事件的视觉数据集上的目标识别任务,我们报告了测试集上的分类精度。对于MNIST数据集上的图像重建任务,我们报告了重建的手写数字的均方误差(MSE)。我们对所有任务执行三次独立运行,并报告所有运行的最佳结果,ImageNet-12数据集上的目标识别任务除外,仅报告单个运行的性能。
为了研究SNN模型相对于其ANN模型的计算效率,我们将等效ANN和SNN模型之间的能耗比报告如下:
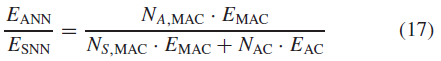
其中EANN和ESNN分别表示ANN和SNN的总能耗。NA,MAC和NS,MAC分别是ANN和SNN使用的MAC操作总数。NAC是SNN使用的AC操作总数。EMAC和EAC分别指每个MAC和AC操作的能源成本。正如Han等人[50]所报道的,[51]中SNN的能耗研究采用的,32位浮点MAC消耗4.6 pJ,而32位浮点AC操作在45 nm工艺技术中仅消耗0.9 pJ。
B. Frame-Based Object Recognition Results
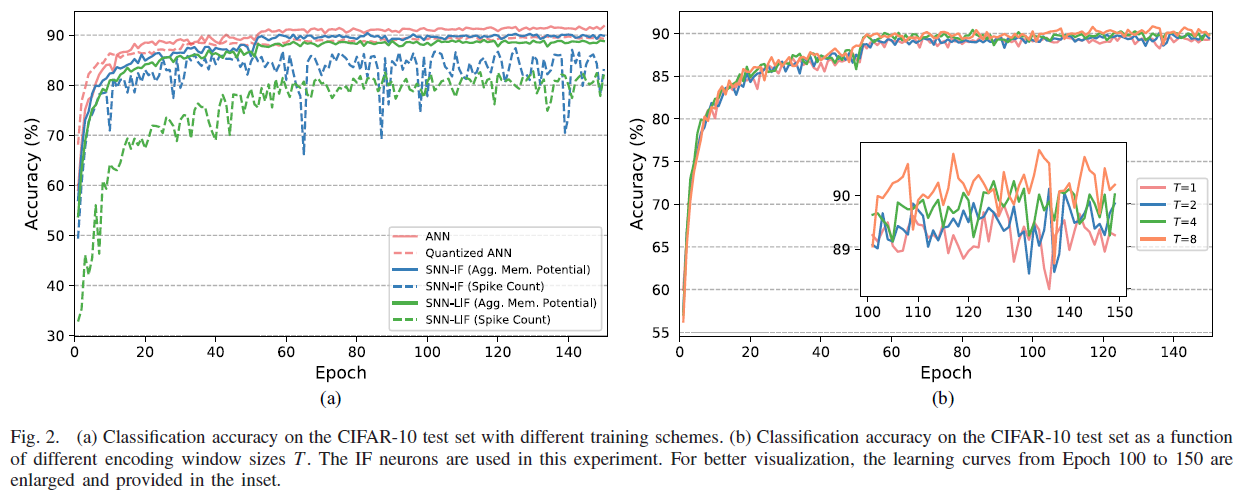
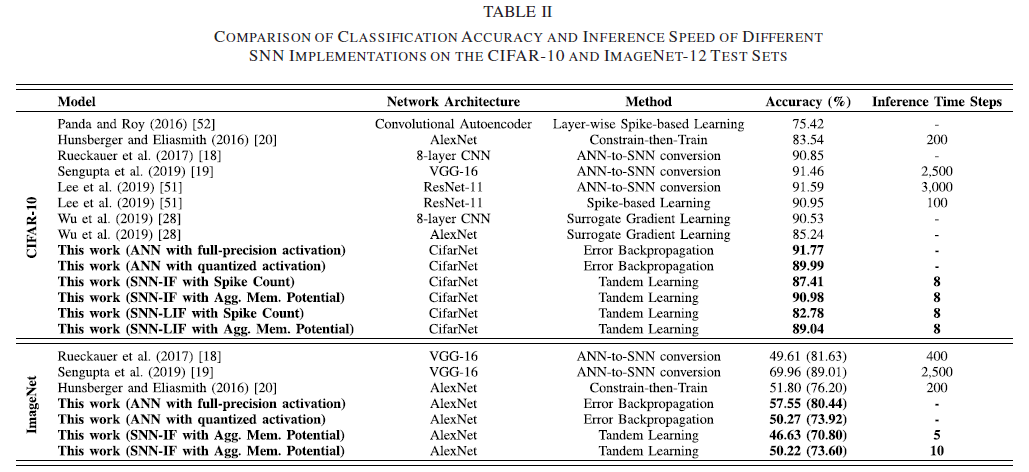
对于CIFAR-10,如表II所示,使用IF神经元的SNN(以下称为SNN-IF)对于脉冲计数和聚合膜电位解码分别达到87.41%和90.98%的测试精度,而对于使用LIF神经元(SNN-LIF)的SNN实现,其结果稍差,其分类精度为89.04%,这可能是由于平滑的替代激活函数的近似误差。然而,通过设计类似的激活函数来近似LIF神经元的发放率[20],约束后训练方法在CIFAR-10数据集上仅实现83.54%的分类精度。这一结果证实了将SNN保持在串联学习网络中提出的训练循环中的必要性。此外,我们的脉冲CifarNet所获得的结果也与最先进的ANN-SNN转换[18][19][51]和基于脉冲的学习[28][51]方法一样具有竞争力。
如图2(a)所示,我们注意到脉冲计数解码的学习动态是不稳定的,这归因于在输出层导出的离散误差梯度。因此,我们在其余的实验中使用聚合膜电位解码。尽管学习收敛慢于具有ReLU激活函数和量化CNN(激活值根据量化感知训练方案量化为3位[42])的普通CNN,但SNN-IF的分类精度最终超过了量化CNN。为了研究编码时间窗口大小T对分类精度的影响,我们使用T范围为1至8的IF神经元重复CIFAR-10实验。如图2(b)所示,分类精度随着时间窗口大小的增大而不断提高。它表明了串联学习在利用编码时间窗口来表示信息方面的有效性,编码时间窗口决定了脉冲计数的上限。值得注意的是,在时间窗口大小仅为1的情况下,可以实现89.83%的准确率,这表明可以同时实现准确和快速的推断。
为了使用基于脉冲的学习规则在大规模ImageNet-12数据集上训练模型,需要大量的计算机存储来存储脉冲神经元的中间状态,并且需要大量的计算成本来进行离散时间模拟。因此,只有少数SNN实现在没有考虑训练过程中脉冲神经元的动力学的情况下,在这一具有挑战性的任务上进行了一些成功的尝试,包括ANN到SNN的转换[18][19]和约束后训练[20]方法。
如表II所示,在十个时间步骤的编码时间窗口下,使用串联学习规则训练的AlexNet分别达到50.22%和73.60%的前1和前5精度。该结果与具有相同AlexNet架构[20]的约束后训练方法的结果相当,总时间步长为200。值得注意的是,所提出的学习规则只需要十个推理时间步骤,比其他报告的方法至少快一个数量级。虽然ANN到SNN的转换方法[18][19]在ImageNet-12上实现了更好的分类精度,但它们的成功很大程度上归功于所使用的更先进的网络模型。
此外,我们注意到,串联学习与完全精确激活的基准ANN实现相比,精度下降了约7%(通过用两个卷积运算的步长替换池层以匹配本工作中使用的AlexNet并添加批量归一化层,对原始AlexNet模型[1]进行了修改)。为了研究对离散神经表示精度的影响(精度的下降有多少是由于激活量化,有多少是因为IF神经元的动力学),我们通过将激活值量化到仅十个级别来修改全精度ANN。在一次试验中,得到的量化ANN分别达到50.27%和73.92%的前1和前5错误率。这一结果与我们的SNN实现非常接近,这表明仅激活函数的量化就占了精度下降的大部分。
C. Event-Based Object Recognition Results
仿生活动摄像机以异步方式捕捉每像素的强度变化,具有高动态范围、高时间分辨率和无运动模糊的引人注目的属性。因此,事件驱动视觉[58]作为传统框架视觉的补充,在计算机视觉界引起了越来越多的关注。事件驱动视觉的早期研究侧重于从捕获的事件流中构建基于帧的特征表示,从而可以通过机器学习模型[56][57]或ANN[59]对其进行有效处理。尽管这些工作取得了令人满意的结果,但基于帧的特征的后处理增加了延迟,即使在低事件率期间也会导致高计算成本。相比之下,异步SNN自然地处理基于事件的感觉输入,因此具有构建完全事件驱动系统的巨大潜力。
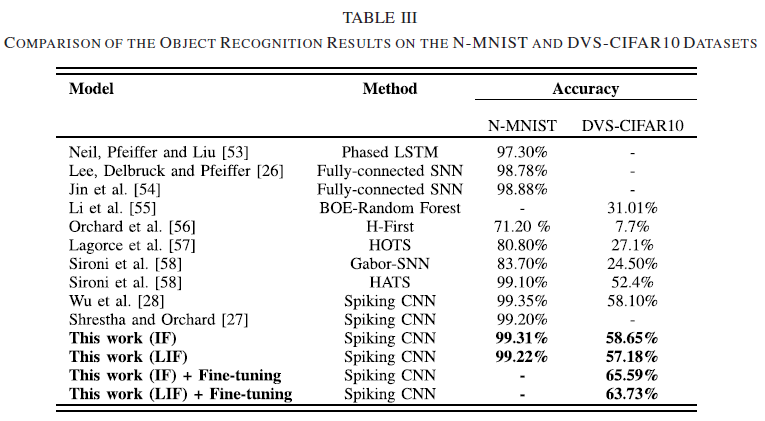
在这项工作中,我们研究了串联学习在训练SNN以处理事件摄像机的输入中的适用性。为此,我们在N-MNIST和DVS-CIFR10数据集上执行目标识别任务。如表III所示,对于N-MNIST数据集,我们的脉冲神经网络对SNN-IF和SNN-LIF的准确率分别为99.31%和99.22%。这些结果优于许多现有的SNN实现[26][27][46][54]和机器学习模型[53][56][57],同时与最近引入的基于脉冲的学习方法[28]中获得的最佳报告结果相当。
同样,我们的SNN模型也报告了DVS-CIFR10数据集的最先进性能。这证明了所提出的串联学习规则在处理事件驱动的相机数据中的有效性。为了解决DVS-CIFAR10数据集的数据稀缺性,我们通过微调SNN模型(在基于帧的CIFAR10数据集上预训练),在DVS-CIAFR10数据集中进一步探索了迁移学习。值得注意的是,以这种方式训练的SNN模型实现了大约7%的精度改进。值得注意的是,尽管忽略了脉冲序列的时间结构,仅将脉冲计数作为信息载体,但串联学习规则在这些数据集上表现得非常好,这可以通过在收集这些数据集期间添加可忽略的时间信息来解释[60]。
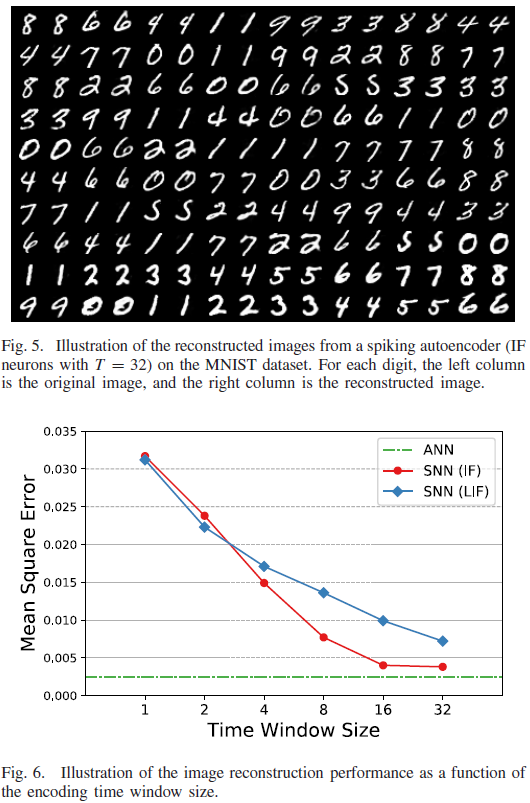
D. Superior Regression Capability
为了探索回归任务的串联学习能力,我们使用全连接的脉冲自编码器在MNIST数据集上执行图像重建任务。如图5所示,使用所提出的串联学习规则训练的自编码器可以有效地重建高质量的图像。当时间窗口大小为32时,SNN-IF和SNN-LIF的MSE分别为0.0038和0.0072,与等效ANN的0.0025相比略有下降。然而,值得一提的是,通过利用脉冲序列的稀疏性,SNN可以提供比ANN的高精度浮点数表示更高的数据压缩率。如图6所示,具有更大的时间窗口大小,网络性能接近基准ANN,这与目标识别任务中的观察一致。
E. Activation Direction Preservation and Weight-Activation Dot Product Proportionality Within the Interlaced Layers
在展示了所提出的串联学习规则对目标识别和图像重建任务的有效性之后,我们希望解释为什么可以通过交错的网络层有效地执行学习。为了回答这个问题,我们借用了最近的二值神经网络理论工作中的想法[61],其中学习也在交错的网络层上执行(二值激活正向传播到后续层)。在所提出的串联网络中,第l−1层的ANN层激活值al−1被从耦合SNN层导出的脉冲计数cl−1代替。我们进一步分析了这两个量之间的失配程度及其对激活正向传播和误差反向传播的影响。
在我们对CIFAR-10进行的数值实验中,我们随机抽取了256个测试样本,计算了所有卷积层的矢量化cl−1和al−1之间的余弦角。如图7所示,它们的平均余弦角小于24°,这种关系在整个学习过程中保持一致。虽然这些角度在低维度上看起来很大,但在高维度空间中却非常小。根据超维计算理论[62]和二值神经网络的理论研究[61],任意两个高维随机向量之间的余弦角近似正交。同样值得注意的是,用cl−1替换al−1的失真比对随机高维向量进行二值化要小得多,后者理论上会使余弦角改变37°。假设从后续ANN层反向传播的激活函数和误差梯度保持相等,则误差反向传播的失真局部受限于al−1和cl−1之间的差异。
此外,我们计算了权重激活点积cl · W和al · W之间的皮尔逊相关系数(PCC),这是我们当前网络配置中的一个重要中间量(输入到批量归一化层)。PCC范围从−1到1,测量两个变量之间的线性相关性。值1表示完美的正线性关系。如图7所示,在大多数样本的学习过程中,PCC始终保持在0.9以上,这表明权重激活点积的线性关系大致保持不变。

F. Efficient Learning Through Spike-Train Level Surrogate Gradient
在本节中,我们将所提出的串联学习规则的学习效率与流行的替代梯度学习方法家族进行比较[25]。替代梯度学习方法描述了具有RNN的脉冲神经元的时序依赖性动态,从而使用基于BPTT的训练方法来优化网络参数。在误差反向传播阶段,用连续替代函数代替不可微分脉冲生成函数,从而可以为每个时间步骤确定替代梯度。相比之下,串联学习确定了脉冲训练水平的误差梯度;因此,它可以显著提高学习效率。
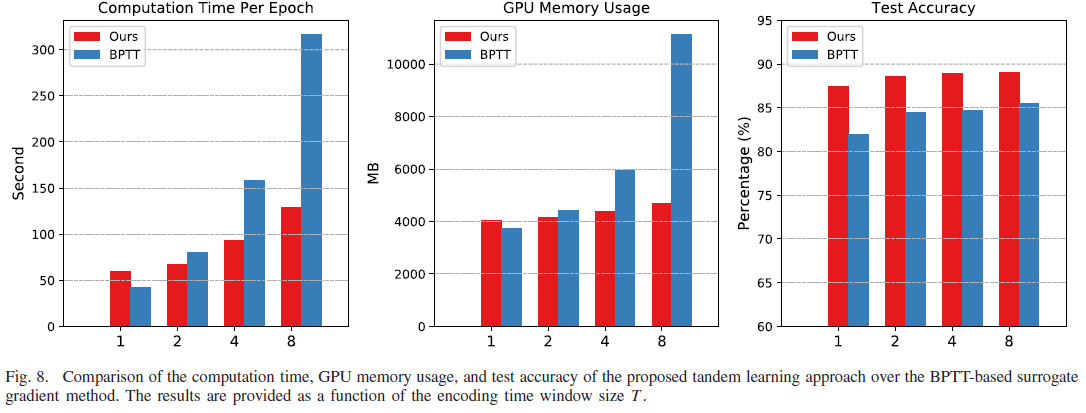
在此,我们将串联学习的学习效率与[28]中提出的替代学习方法进行了比较。如图8所示,对于具有LIF神经元的CIFAR-10数据集的实验,基于BPTT的方法的计算时间和GPU存储使用量随着时间窗口大小T线性增长,因为它需要使用中间神经元状态进行存储和计算。值得注意的是,采用这种基于BPTT的方法,当T=8时,SNN无法安装在具有11 GB存储空间的单个Nvidia Geforce GTX 1080Ti GPU卡上。因此,它阻止了这种方法在其他工作中也提到的更具挑战性的任务中的大规模部署[25]。相反,串联学习不需要存储每个时间步骤的中间神经元状态;因此,与基于BPTT的方法相比,它的速度提高了2.45倍,在T=8时GPU存储使用量减少了2.37倍。对于更大的时间窗口大小,预计计算效率的提高将进一步提高。此外,与基于BPTT的方法相比,使用串联学习方法训练的SNN在所有不同的T中一致地获得了更高的测试精度。这可以通过以下事实来解释:替代梯度方法的无偏近似通常随着时间窗口T的增加而改善,而所提出的串联学习规则并非如此。此外,串联学习规则有效地避免了基于BPTT的方法中存在的梯度消失和爆炸问题,并允许容易地集成批量归一化方法以提高训练收敛性。因此,所提出的串联学习方法显示出更好的学习效果、效率和可扩展性。
G. Rapid Inference With Reduced Synaptic Operations
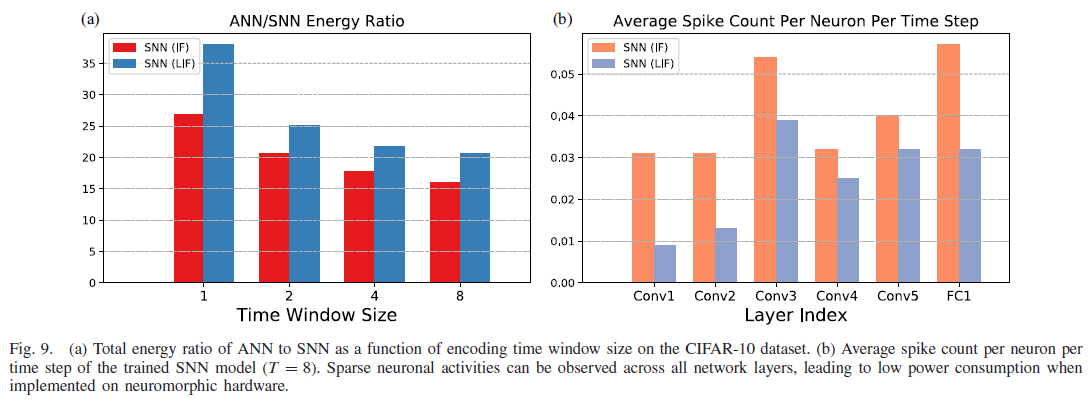
如表II所示,用所提出的学习规则训练的SNN可以比其他学习规则更快地执行至少一个数量级的推理,而不损害分类精度。此外,如图2和图6所示,所提出的串联学习规则可以处理和利用不同的编码时间窗口大小T。在最具挑战性的情况下,当只允许传输一个脉冲(即T=1)时,我们能够为目标识别和图像重建任务实现令人满意的结果。具体地说,对于Cifar10数据集上的目标识别任务,我们对IF和LIF神经元的准确率分别达到89.52%和88.82%。它远高于最近为NC硬件引入的二值神经网络实现,精度为84.67%[63]。这可以部分归功于我们所采用的编码方案,由此可以在第一个时间步骤中对全部输入信息进行编码。此外,在每次卷积之后添加的批量归一化层和全连接层确保了到顶层的有效信息传输。通过增加时间窗口大小可以进一步改善结果;因此,可以根据不同的应用需求在推理速度和准确性之间进行权衡。
为了研究训练的SNN的能量效率,我们遵循惯例,在CIFAR-10数据集上计算ANN与SNN的总能量比。值得注意的是,ANN所需的总能耗是一个固定的数字,与时间窗口大小无关,而SNN的总能耗几乎随时间窗口大小线性增长,如图9(a)所示。由于分类精度相当,ANN模型需要SNN-IF和SNN-LIF(T=8)的总能量分别为15.96和20.67倍。这可以通过SNN所需的短推断时间和稀疏的突触活动来解释,如图9(b)所示。相比之下,在类似的VGGNet-9网络上,采用ANN到SNN转换和基于脉冲的学习方法的最先进SNN实现分别需要0.18倍和1.4倍的总能量比[51]。这表明我们的SNN实现至少效率高一个数量级。在ImageNet数据集上,由于第一个卷积层所消耗的能量的很大百分比需要昂贵的MAC操作,能量比略微降低到4.79和3.39倍,T分别等于5和10。
IV. DISCUSSION AND CONCLUSION
在这项工作中,我们引入了一种新的串联神经网络及其学习规则,以有效地训练用于分类和回归任务的SNN。在串联神经网络中,SNN被用于确定激活前向传播的精确脉冲计数和脉冲序列,而与耦合SNN共享权重的ANN被用于近似脉冲计数,从而在脉冲序列水平上近似耦合SNN的梯度。假设误差反向传播是在简化的ANN上执行的,所提出的学习规则在记忆和计算上都比在每个时间步骤执行梯度近似的流行替代梯度学习方法更有效[25][27]-[29]。
为了理解为什么可以在串联学习框架内有效地执行学习,我们研究了串联网络的学习动态,并将其与完整的ANN进行了比较。对CIFAR-10的实证研究表明,矢量化ANN输出al和耦合SNN输出脉冲计数cl之间的余弦距离在高维空间中非常小,并且这种关系在整个训练过程中都保持。此外,在激活前向传播中的重要中间量,权重激活点积cl · W和al · W之间表现出强正PCC,这表明权重激活点乘积的线性关系保持良好。
使用所提出的串联学习规则训练的SNN在基于帧和基于事件的目标识别任务上都表现出具有竞争力的分类精度。通过有效利用确定脉冲计数上限的时间窗口大小来表示信息,并添加批量标准化层以确保有效的信息流;我们的实验证明了快速推断,与其他SNN实现相比至少节省了一个数量级的时间。此外,通过利用稀疏的神经元活动和短的编码时间窗口,总突触操作也比基准ANN和其他最先进的SNN实现减少了至少一个数量级。
对于未来的工作,我们将探索通过为LIF神经元设计更有效的逼近函数和评估更先进的网络结构来缩小基准ANN和使用LIF神经元的SNN之间的精度差距的策略。此外,我们想承认,忽略脉冲序列的时间结构的串联学习规则不适用于时间序列学习,因为需要为每个时间步长或脉冲而不是脉冲计数水平确定误差函数。为了解决时间结构很重要的任务,例如手势识别和光流估计[64],我们有兴趣研究包括用于特征提取的前馈网络和用于序列建模的递归网络的混合网络结构是否有用。具体而言,通过串联学习训练的前馈SNN可以在短时间尺度上作为一个强大的基于发放率的特征提取器[65],而随后的脉冲RNN[35]可以用于在较长时间尺度上显式处理底层模式的时间结构。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号