DeepMDP: Learning Continuous Latent Space Models for Representation Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Proceedings of the 36 th International Conference on Machine Learning, Long Beach, California, PMLR 97, 2019
Abstract
许多强化学习(RL)任务为智能体提供高维观察,这些观察可以简化为低维连续状态。为了将这个过程形式化,我们引入了DeepMDP的概念,这是一个参数化的潜在空间模型,通过最小化两个可控制的潜在空间损失来训练:奖励预测和下一个潜在状态的分布预测。我们表明,这些目标的优化保证了(1)作为状态空间表征的嵌入函数的质量和(2)作为环境模型的DeepMDP的质量。我们的理论发现得到了实验结果的证实,即经过训练的DeepMDP恢复了合成环境中高维观测的潜在结构。最后,我们表明,在Atari 2600域中,学习DeepMDP作为辅助任务,与无模型RL相比,可以大大提高性能。
1. Introduction
在强化学习(RL)中,通常将环境建模为马尔可夫决策过程(MDP)。然而,对于许多实际任务,这些MDP的状态表征包括大量冗余信息和与任务无关的噪声。例如,来自街机学习环境的图像观察(Bellemare et al., 2013a)由33600个维度的像素阵列组成,但直觉上很清楚,所有游戏都存在较低维度的近似表示。考虑PONG;只观察画面中三个物体的位置和速度就已足够。在学习策略之前将每个帧转换成这样的简化状态,减少呈现给智能体的冗余和无关信息,将有助于学习过程。强化学习的表征学习技术正是通过这样做来提高现有RL算法的学习效率:学习从状态到简化状态的映射。
互模拟度量(Bisimulation metrics)(Ferns et al., 2004; 2011)定义了两个行为相似的状态,如果它们(1)产生了接近的即时奖励,(2)它们转变为行为相似的状态。互模拟度量已经被用于通过聚合状态(表征学习的一种形式)来降低状态空间的维数,但由于其高计算成本而没有受到太多关注。此外,状态聚合技术,无论是基于互模拟还是其他方法(Abel et al., 2017; Li et al., 2006; Singh et al., 1995; Givan et al., 2003; Jiang et al., 2015; Ruan et al., 2015),与函数近似方法的兼容性较差。相反,为了支持基于随机梯度下降的训练过程,我们探索了连续潜在表征的使用。具体而言,对于任何MDP,我们建议利用其对应的DeepMDP的潜在空间。
DeepMDP是MDP的一个潜在空间模型,它已被训练为最小化两个可控制的损失:预测奖励和预测下一个潜在状态的分布。DeepMDP可以被视为最近使用神经网络学习环境潜在空间模型的工作的形式化(Ha & Schmidhuber, 2018; Oh et al., 2017; Hafner et al., 2018)。DeepMDP的状态可以解释为原始MDP状态的表征,这样做揭示了与互模拟的深刻理论联系。我们表明,DeepMDP损失的最小化保证了两个非相似状态永远不会崩溃为一个表征。此外,这保证了DeepMDP中的价值函数是原始任务MDP中价值函数的良好近似。这些结果不仅为表征学习提供了一种有理论基础的方法,而且代表着朝着基于潜在空间模型的RL算法迈出了有希望的第一步。
在合成环境中,我们表明DeepMDP学习恢复高维观测的低维潜在结构。然后,我们证明,与基准无模型方法相比,学习DeepMDP作为Atari 2600环境中无模型RL的辅助任务(Bellemare et al., 2013b)可显著提高性能。
2. Background

2.1.Wasserstein Distance


2.2. Lipschitz MDPs


1 MDP平滑度的另一个好处是改善学习动态。Pirotta等人(2015)认为,MDP的Lipschitz常数越小,收敛到接近最优策略的速度越快。
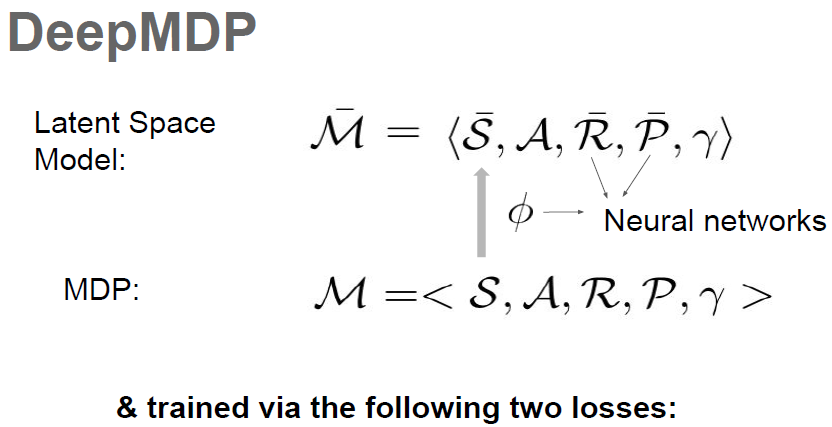
2.3. Latent Space Models
对于某些MDP![]() ,设
,设![]() 是MDP,其中有限D的
是MDP,其中有限D的![]() 和动作空间A在
和动作空间A在![]() 和
和![]() 之间共享。此外,设
之间共享。此外,设![]() 是连接这两个MDP的状态空间的嵌入函数。我们指的
是连接这两个MDP的状态空间的嵌入函数。我们指的![]() 是作为
是作为![]() 的潜在空间模型。
的潜在空间模型。
根据定义,![]() 是一个MDP,因此可以用标准的方式定义价值函数。我们使用
是一个MDP,因此可以用标准的方式定义价值函数。我们使用![]() 表示策略
表示策略![]() 的价值函数,其中
的价值函数,其中![]() 是在状态空间
是在状态空间![]() 上定义的策略集。我们使用
上定义的策略集。我们使用![]() 表示
表示![]() 中的最优策略。相应的最优状态和动作价值函数则为
中的最优策略。相应的最优状态和动作价值函数则为![]() 。为了便于记法,当
。为了便于记法,当![]() 时,我们使用
时,我们使用![]() 来表示首先使用Φ将s映射到
来表示首先使用Φ将s映射到![]() 的状态空间
的状态空间![]() ,然后使用
,然后使用![]() 来生成动作的概率分布。
来生成动作的概率分布。
尽管之前已经研究过潜在空间模型的类似定义(Francois Lavet et al., 2018; Zhang et al., 2018; Ha & Schmidhuber, 2018; Oh et al., 2017; Hafner et al., 2018; Kaiser et al., 2019; Silver et al., 2017),但用于学习此类模型的参数化和训练目标差异很大。例如Ha和Schmidhuber (2018); Hafner等人(2018); Kaiser等人(2019)使用像素预测损失来学习潜在表征,而(Oh et al., 2017)则选择优化模型,以预测具有与采样的下一状态相同价值函数的下一潜在状态。
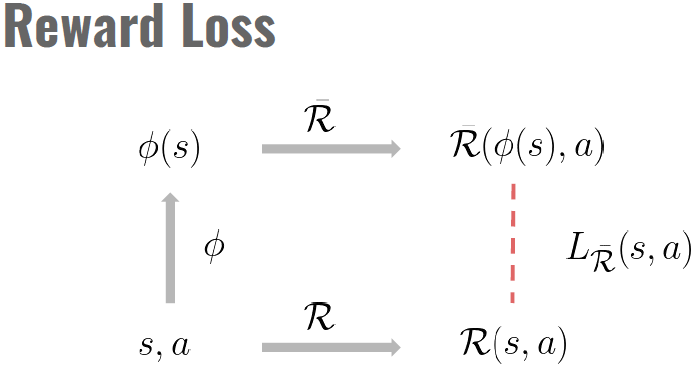
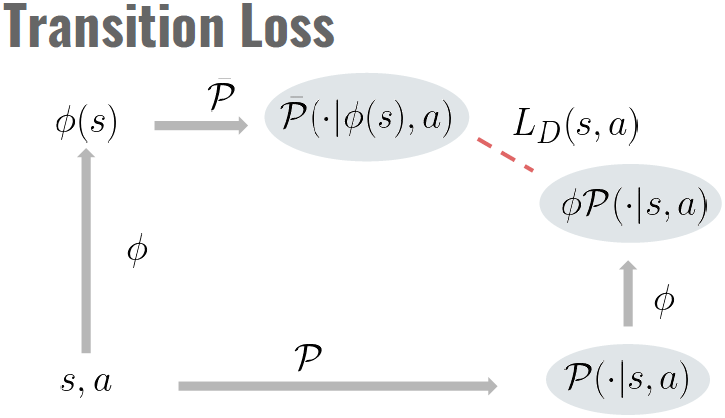
在这项工作中,我们研究了关于潜在空间中的奖励和转换定义的潜在空间损失的最小化:
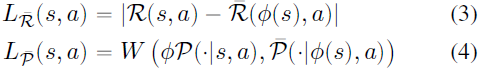
其中我们使用缩写符号![]() 表示第一个采样在
表示第一个采样在![]() 上的概率分布
上的概率分布![]()
![]() ,然后嵌入
,然后嵌入![]() 。Francois Lavet等人(2018)和Chung等人(2019)研究了类似的潜在损失,但据我们所知,我们是第一次将潜在空间模型作为辅助损失进行理论分析。
。Francois Lavet等人(2018)和Chung等人(2019)研究了类似的潜在损失,但据我们所知,我们是第一次将潜在空间模型作为辅助损失进行理论分析。
我们使用术语DeepMDP来指代参数化的潜在空间模型,该模型最小化潜在损失![]() 和
和![]() (有时称为DeepMDP损失)。在第3节中,我们推导了在整个状态空间(我们称之为全局优化)上最小化DeepMDP损失时DeepMDP的理论保证。然而,我们的主要目标是学习由深度网络参数化的DeepMDP,这需要以期望的形式进行损失。我们在第4节中表明,在这种情况下可以获得类似的理论保证。
(有时称为DeepMDP损失)。在第3节中,我们推导了在整个状态空间(我们称之为全局优化)上最小化DeepMDP损失时DeepMDP的理论保证。然而,我们的主要目标是学习由深度网络参数化的DeepMDP,这需要以期望的形式进行损失。我们在第4节中表明,在这种情况下可以获得类似的理论保证。
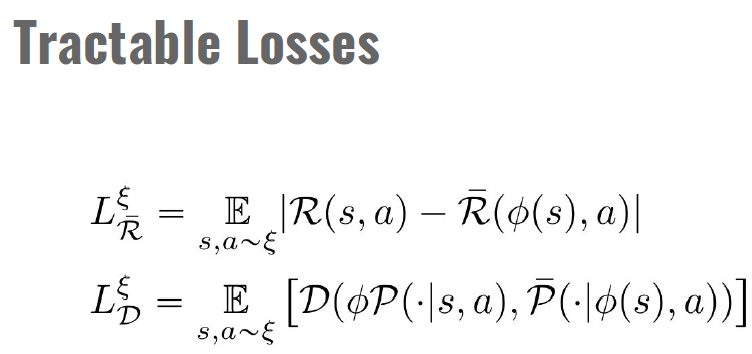
3. Global DeepMDP Bounds
我们将以下损失称为全局DeepMDP损失,以强调其对整个状态和动作空间的依赖:2
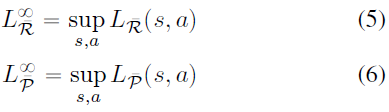
2 ∞符号是对l∞范数的引用
3.1. Value Difference Bound


Asadi等人(2018)也发现了类似的界限,他们使用精确的奖励函数研究非潜在转换模型。我们还注意到,我们的结果可以说更简单,因为我们不需要根据一组确定性分量上的分布来处理MDP转换。
3.2. Representation Quality Bound

3.3. Suboptimality Bound


4. Local DeepMDP Bounds

3 像蒙特祖马的复仇号这样的探险环境就是一个很好的例子。
4.1. Value Difference Bound

4 在策略![]() 很少访问的状态,价值函数可能不准确。
很少访问的状态,价值函数可能不准确。
4.2. Representation Quality Bound

5. Connection to Bisimulation
正如我们现在将看到的,通过优化DeepMDP损失所学到的表征与互模拟密切相关。Givan等人(2003)首次研究了RL背景下的互模拟关系,将其作为状态之间行为对等的形式化。他们建议对等效状态进行分组,以降低MDP的维数。

从本质上讲,如果(1)两个状态对所有行为都有相同的即时奖励,并且(2)它们在下一个状态上的分布都包含它们自己是互模拟的状态,那么这两个状态就是互模拟的。特别令人感兴趣的是最大互模拟关系~,它定义了具有最少元素的分区S/~。
互模拟关系的一个缺点是它们要么全有要么全无的性质。两个几乎相同,但在奖励或转换函数上略有不同的状态,被视为与两个没有共同点的状态一样不相关。Ferns等人(2004)介绍了互模拟度量的使用,这是一种用于量化两个离散状态的行为相似性的伪度量,并提出了在互模拟度量下的状态的聚合。我们提出了将互模拟度量扩展到连续状态空间,如Ferns等人(2011)。

我们推测,基于局部DeepMDP损失,类似的结果应该是可能的,但它们需要将互模拟度量推广到局部设置。
尽管互模拟度量已用于状态聚合(Givan et al., 2003; Ferns et al., 2004; Ruan et al., 2015)、特征发现(Comanici & Precup, 2011)和MDP之间的迁移学习(Castro & Precup,2010),但它们尚未扩展到现代深度强化学习技术。从这个意义上讲,我们的方法作为深度强化学习的实用表征学习方案具有独立的意义,它通过易于计算的学习目标提供了互模拟度量的理想属性。
6. Related Work
我们已经表明,通过最小化潜在空间损失来学习DeepMDP会导致以下表征:
- 考虑到一大套有趣的策略的良好近似性。
- 考虑到这些策略的价值函数的良好近似。
因此,DeepMDP是一种数学上合理的表征学习方法,与神经网络兼容,易于实现。
Parr等人(2008)在线性设置中的表示质量和基于模型的目标之间建立了类似的联系。有大量关于利用转换函数结构进行表征学习的文献(Mahadevan & Maggioni, 2007; Barreto et al., 2017),但这些工作并不依赖于奖励函数。最近,Bellemare等人(2019)从一个角度探讨了表征学习问题,即一个好的表征是允许通过价值函数多面体(Dadashi et al., 2019)中任何可能的价值函数的线性映射进行预测的表征。其他辅助任务,在没有相同理论论证的情况下,已被证明可以提高RL智能体的性能(Jaderberg et al., 2016; van den Oord et al., 2018; Mirowski et al., 2017)。Lyle等人(2019)认为,分布式RL的性能增益(Bellemare et al., 2017a)也可以解释为一种辅助任务。
7. Empirical Evaluation
我们的结果取决于最小化期望损失,这是深度网络适用的主要要求。然而,当将这些理论结果转化为实际算法时,会出现两个主要障碍:
(1) Minimization of the Wasserstein Arjovsky等人(2017)首次提出通过其对偶公式将Wasserstein距离用于生成对抗网络(GAN)(见公式1)。他们的方法包括训练一个网络,约束为1-Lipschitz,以获得对偶的上确界。一旦达到这个最高值,就可以通过网络进行区分来最小化Wasserstein。分位数回归已被提议作为Wasserstein最小化的替代解决方案(Dabney et al., 2018b), (Dabney et al., 2018a),并已被证明在分布RL中表现良好。读者可能会注意到,Bellemare等人(2017b)和Bikowski等人(2018)发现了Wasserstein距离随机最小化的问题。在我们的实验中,我们通过假设![]() 和
和![]() 都是确定性的来规避这些问题。这减少了Wasserstein距离
都是确定性的来规避这些问题。这减少了Wasserstein距离![]() 到
到![]() ,其中
,其中![]() 和
和![]() 表示确定性转换函数。
表示确定性转换函数。
2) Control the Lipschitz constants ![]() and
and ![]() :我们还转向Wasserstein GAN领域,寻找将深度网络约束为Lipschitz的方法。最初,Arjovsky等人(2017)使用投影步骤将鉴别器函数约束为1-Lipschitz。Gulrajani等人(2017a)提出使用梯度惩罚,并提出了改进的学习动态。Gouk等人(2018)也提出了Lipschitz连续性作为一种正则化方法,他提供了一种计算神经网络Lipschitz-常数上界的方法。在我们的实验中,我们遵循Gulrajani等人(2017a)并利用梯度惩罚。
:我们还转向Wasserstein GAN领域,寻找将深度网络约束为Lipschitz的方法。最初,Arjovsky等人(2017)使用投影步骤将鉴别器函数约束为1-Lipschitz。Gulrajani等人(2017a)提出使用梯度惩罚,并提出了改进的学习动态。Gouk等人(2018)也提出了Lipschitz连续性作为一种正则化方法,他提供了一种计算神经网络Lipschitz-常数上界的方法。在我们的实验中,我们遵循Gulrajani等人(2017a)并利用梯度惩罚。
7.1. DonutWorld Experiments
为了评估我们是否可以学习有效的表征,我们在一个称为DonutWorld的简单合成环境中研究DeepMDP学到的表征。DonutWorld由一个智能体组成,该智能体因在固定轨道上顺时针运行而获得奖励。保持在赛道中心会使运动速度更快。观测是根据32×32灰度像素阵列给出的,但有一个简单的2D潜在状态空间(智能体的x-y坐标)。我们研究在学习二维表征时,x-y坐标是否正确恢复。
这项任务体现了Atari 2600游戏典型的低维动力学、高维观测结构,同时实验起来足够简单。我们使用Tensorflow实现了DeepMDP训练过程,并将其与简单的自编码器基准进行了比较。有关完整的环境规范、实验设置和其他实验,请参见附录B。补充材料中包含了复制所有实验的代码。
为了研究所学到的表征是否与现实很好地对应,我们绘制了各种状态的表征接近度热图。图1(a)显示,DeepMDP表征从高维像素观测中有效地恢复了智能体的基本状态,即其2D位置。相比之下,即使自编码器几乎完美地解决了任务,自动编码器的表征也没有那么有意义。
在图1(b)中,我们修改了环境:环境现在有四个相同的轨道,而不是一个轨道。智能体程序以随机的方式统一启动,并且不能在轨道之间移动。DeepMDP隐藏状态正确地将所有状态与不可区分的价值函数合并,学习深度状态表征,该状态表征几乎完全不变于智能体所在的轨道。

7.2. Atari 2600 Experiments
在本节中,我们展示了在Arcade学习环境(Bellemare et al., 2013a)中近似学习DeepMDP的实际好处。我们关于表征相似性的结果表明,学习DeepMDP是学习高质量表征的一种原则性方法。因此,我们将DeepMDP损失作为一项辅助任务,与无模型强化学习一起最小化,学习两个任务之间共享的单一表征。我们提出的算法的实现基于Dopamine(Castro et al., 2018)。
我们采用分布式Q学习方法来实现无模型RL;特别地,我们使用C51智能体作为基准(Bellemare et al., 2017a),该智能体估计离散支撑上的概率质量,并最小化估计分布和目标分布之间的KL偏差。C51使用卷积神经网络对输入帧进行编码:![]() ,输出密集向量表征
,输出密集向量表征![]() 。C51 Q函数是一个前馈神经网络,它将
。C51 Q函数是一个前馈神经网络,它将![]() 映射到奖励分布的logits的估计。
映射到奖励分布的logits的估计。
为了将学习DeepMDP作为辅助学习目标,我们定义了深度奖励函数和深度转换函数。这些都被实现为前馈神经网络,该网络分别使用![]() 来估计即时奖励和下一个状态表征。总体目标函数是标准C51损失和由公式7和8给出的局部DeepMDP损失的基于Wasserstein距离的近似值的简单线性组合。有关实验细节,请参见附录C。
来估计即时奖励和下一个状态表征。总体目标函数是标准C51损失和由公式7和8给出的局部DeepMDP损失的基于Wasserstein距离的近似值的简单线性组合。有关实验细节,请参见附录C。
通过优化Φ以联合最小化C51和DeepMDP损失,我们希望学习有意义的![]() ,这是学习良好价值函数的基础。在以下小节中,我们旨在回答以下问题:(1)DeepMDP的学习如何影响C51在Atari 2600游戏上的整体性能?(2)DeepMDP目标与类似的表征学习方法相比如何?
,这是学习良好价值函数的基础。在以下小节中,我们旨在回答以下问题:(1)DeepMDP的学习如何影响C51在Atari 2600游戏上的整体性能?(2)DeepMDP目标与类似的表征学习方法相比如何?
7.3. DeepMDPs as an Auxiliary Task
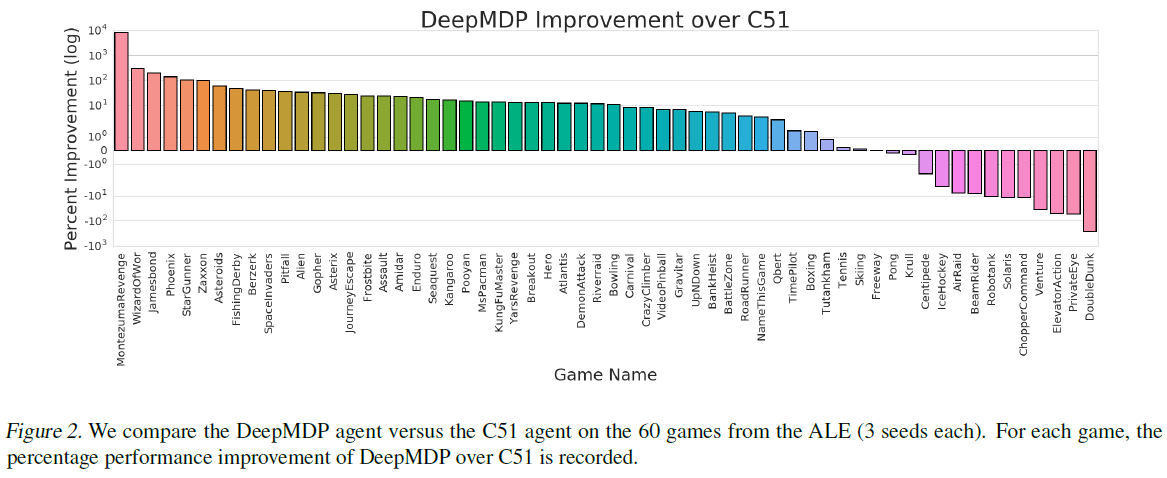
我们表明,当使用附录C.2中描述的性能最佳的DeepMDP架构时,我们在60款Atari 2600游戏套件上获得了与C51相比几乎一致的性能改进(见图2)。
7.4. Comparison to Alternative Objectives
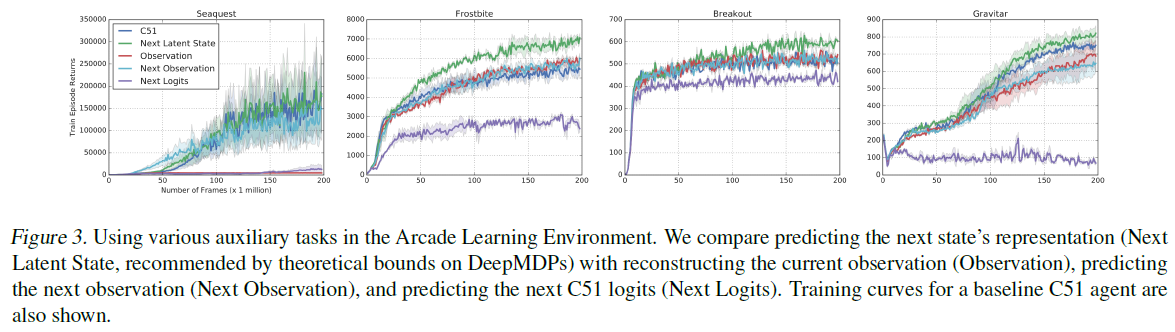
我们根据经验将DeepMDP辅助目标对C51智能体性能的影响与各种替代方法进行了比较。在本节的实验中,我们将DeepMDP边界所建议的深度转换损失替换为以下各项:
(1) Observation Reconstruction: 我们训练一个状态解码器来从![]() 重建观察
重建观察![]() 。该框架类似于(Ha & Schmidhuber, 2018),他们使用自编码器学习环境的潜在空间表征,并使用它来训练RL智能体。
。该框架类似于(Ha & Schmidhuber, 2018),他们使用自编码器学习环境的潜在空间表征,并使用它来训练RL智能体。
(2) Next Observation Prediction: 我们训练一个转换模型来根据当前状态表征![]() 预测下一个观察
预测下一个观察![]() 。该框架类似于预测未来观测结果的基于模型的RL算法(Xu et al., 2018)。
。该框架类似于预测未来观测结果的基于模型的RL算法(Xu et al., 2018)。
(3) Next Logits Prediction: 我们训练转换模型来预测下一个状态表征,使得Q函数正确地预测(s', a')的logits,其中a'是与s'的最大Q值相关联的动作。这可以理解为价值预测网络VPN的分布式模拟(Oh et al., 2017)。注意,该辅助损失仅用于更新表示编码器和转换模型的参数,而不是Q函数。
我们的实验表明,DeepMDP边界(即预测下一个状态的表征)所建议的深度转换损失优于所有三种消融(见图3)。无论是通过观测重建还是下一次观测预测,对Atari 2600帧进行精确建模,都会迫使表征对与底层任务无关的信息进行编码。VPN类型的损失已被证明在使用学到的预测模型进行规划时是有帮助的(Oh et al., 2017);然而,我们发现,对于分布式RL智能体,将其用作辅助任务往往会损害性能。
8. Conclusions
我们引入了DeepMDP的概念:通过最小化可处理的潜在空间损失来训练的参数化潜在空间模型。对DeepMDP的理论分析揭示了一些见解。与互模拟度量的新连接保证了我们的分析适用于一大组有趣的策略。此外,该表征允许可以预测这些策略的价值函数。总之,这些发现为表征学习提供了一种新的方法。我们的结果得到了Atari 2600大规模实验的强大性能的证实,表明基于模型的DeepMDP辅助损失在无模型RL中是有用的辅助任务。将DeepMDP的转换和奖励模型用于基于模型的RL(例如规划、探索)是一个很有前途的未来研究方向。此外,扩展DeepMDP以适应与原始MDP不同的动作空间或时间尺度,这可能是学习环境层次模型的一条很有前途的途径。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号